文章目录
- 引言
- 一、项目搭建:依赖配置与应用初始化
-
- [1.1 Maven 依赖配置](#1.1 Maven 依赖配置)
- [1.2 应用启动类配置](#1.2 应用启动类配置)
- [1.3 配置文件:接入通义千问](#1.3 配置文件:接入通义千问)
- [二、基础对话:ChatClient 的同步调用](#二、基础对话:ChatClient 的同步调用)
- [三、流式输出:Flux 与 SSE 的三种实现方式](#三、流式输出:Flux 与 SSE 的三种实现方式)
-
- [3.1 方案一:Flux 流式响应](#3.1 方案一:Flux 流式响应)
- [3.2 方案二:SseEmitter 自定义编码](#3.2 方案二:SseEmitter 自定义编码)
- [3.3 方案三对比:何时选择哪个方案](#3.3 方案三对比:何时选择哪个方案)
- [四、系统提示词:定义 AI 的角色与行为](#四、系统提示词:定义 AI 的角色与行为)
- [五、结构化输出:从 JSON 到 Java 对象](#五、结构化输出:从 JSON 到 Java 对象)
-
- [5.1 方案一:BeanOutputConverter + PromptTemplate](#5.1 方案一:BeanOutputConverter + PromptTemplate)
- [5.2 方案二:entity() 直接转换](#5.2 方案二:entity() 直接转换)
- [5.3 两种方案对比](#5.3 两种方案对比)
- [六、深入理解:ChatClient 的架构设计](#六、深入理解:ChatClient 的架构设计)
-
- [6.1 Builder 模式与链式调用](#6.1 Builder 模式与链式调用)
- [6.2 ChatClient 内部工作原理](#6.2 ChatClient 内部工作原理)
- [6.3 流式调用的底层机制](#6.3 流式调用的底层机制)
- 七、生产级别的实战建议
-
- [7.1 错误处理](#7.1 错误处理)
- [7.2 请求超时配置](#7.2 请求超时配置)
- [7.3 成本控制](#7.3 成本控制)
- 八、常见问题解答
-
- Q1:如何确保中文显示不乱码?
- [Q2:Flux 和 SseEmitter 有什么区别?](#Q2:Flux 和 SseEmitter 有什么区别?)
- [Q3:如何切换不同的 LLM 模型?](#Q3:如何切换不同的 LLM 模型?)
- [Q4:如何监控和日志记录 LLM 调用?](#Q4:如何监控和日志记录 LLM 调用?)
- 九、性能优化建议
-
- [9.1 连接复用](#9.1 连接复用)
- [9.2 缓存策略](#9.2 缓存策略)
- [9.3 批量处理](#9.3 批量处理)
- 十、总结与展望
引言
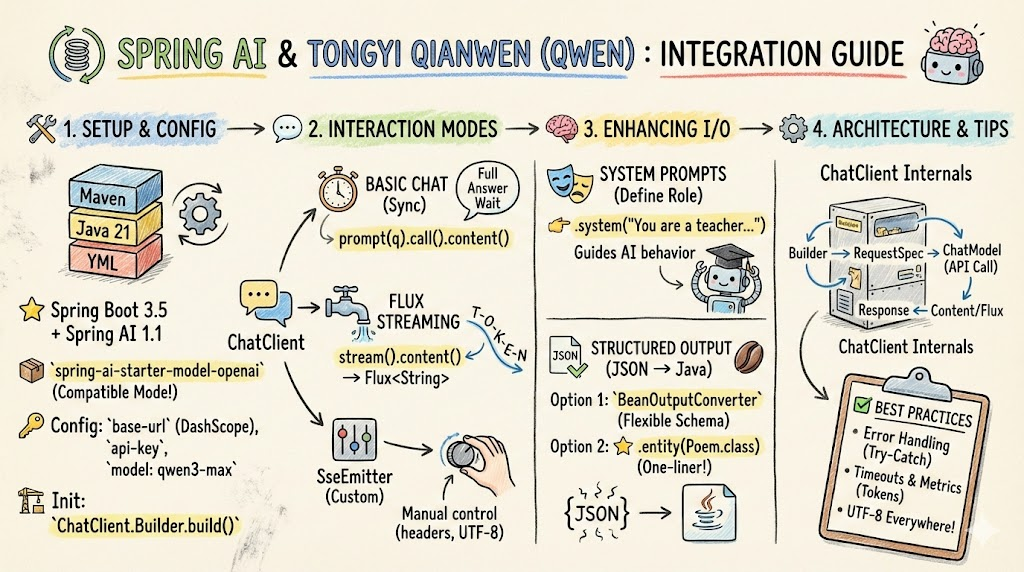
在 AI 快速发展的今天,集成大语言模型(LLM)成为了现代应用开发的必备技能。Spring AI 是 Spring 官方提供的一套标准化框架,用于简化与 LLM 的集成开发。本文通过 Spring Boot 3.5.0 + Spring AI 1.1.0 + 通义千问(Qwen)的技术栈,深入讲解 Spring AI 的基础使用方法。
我们以真实的课程项目为例,展示如何从项目构建、基础对话、流式输出、系统提示词,到结构化输出的完整开发流程。无论你是初学者还是有一定经验的 Java 开发者,都能从本文获得实用的开发经验。
一、项目搭建:依赖配置与应用初始化
1.1 Maven 依赖配置
首先,我们需要在 pom.xml 中配置 Spring AI 的相关依赖。这是项目的基石,关系到后续所有功能的可用性。
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0">
<parent>
<groupId>org.artisan</groupId>
<artifactId>artisan-ai-agent</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>spring-ai-demo</artifactId>
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- Spring Web 支持 REST 接口 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI OpenAI 集成(支持兼容模式) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<!-- Spring AI 聊天内存管理 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<!-- Spring AI 向量存储(Elasticsearch) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId>
</dependency>
<!-- Spring AI RAG 框架 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>
</dependencies>
<!-- Spring AI BOM 管理版本 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.1.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>关键说明:
- spring-ai-starter-model-openai:虽然名称包含 "openai",但它使用 OpenAI 协议标准,支持任何兼容 OpenAI API 的服务,包括阿里云 DashScope、DeepSeek 等。
- spring-ai-bom:通过 Bill of Materials 统一管理 Spring AI 生态中所有模块的版本,避免版本冲突。
- Java 21:Spring AI 1.1.0 要求 Java 17+,我们选择 Java 21 以获得最新特性。
1.2 应用启动类配置
应用启动类的职责是初始化 Spring AI 的核心组件,特别是 ChatClient。
java
package com.artisan;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepository;
import org.springframework.ai.tool.execution.DefaultToolExecutionExceptionProcessor;
import org.springframework.ai.tool.execution.ToolExecutionExceptionProcessor;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
public class SpringAIApplication {
/**
* ChatClient 是 Spring AI 的核心,用于与 LLM 交互
* ChatClient.Builder 由 Spring 自动配置,我们只需调用 build() 完成初始化
*/
@Bean
public ChatClient chatClient(ChatClient.Builder chatClientBuilder) {
return chatClientBuilder.build();
}
/**
* 聊天内存管理
* MessageWindowChatMemory 维护一个消息窗口,避免历史消息无限增长
*/
@Bean
public ChatMemory chatMemory(JdbcChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.build();
}
/**
* 工具执行异常处理器
* DefaultToolExecutionExceptionProcessor(false) 表示不重新抛出异常
*/
@Bean
ToolExecutionExceptionProcessor toolExecutionExceptionProcessor() {
return new DefaultToolExecutionExceptionProcessor(false);
}
public static void main(String[] args) {
SpringApplication.run(SpringAIApplication.class, args);
}
}设计要点:
- ChatClient:这是一个高级抽象,内部集成了模型调用、流处理、内存管理等功能。通过 Builder 模式提供灵活的配置接口。
- ChatMemory:基于消息窗口的内存管理策略,自动维护最近的 N 条消息,既能保留上下文,又能避免 token 浪费。
- ToolExecutionExceptionProcessor :当 LLM 调用工具出现异常时的处理策略,设为
false表示优雅处理,不中断流程。
1.3 配置文件:接入通义千问
Spring AI 的配置集中在 application.yml 中。关键是通过 OpenAI 兼容模式接入阿里云 DashScope。
yaml
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/my_db?useUnicode=true&characterEncoding=utf-8
username: root
password: artisan123456...
ai:
openai:
# DashScope 提供的 OpenAI 兼容端点
base-url: https://dashscope.aliyuncs.com/compatible-mode
# 从环境变量读取 API Key,避免硬编码
api-key: ${DASHSCOPE_API_KEY}
chat:
options:
# 通义千问最强模型
model: qwen3-max
embedding:
options:
# 向量化模型
model: text-embedding-v4
server:
port: 8081理解兼容模式:
阿里云 DashScope 提供的 OpenAI 兼容模式使得开发者无需修改代码就能切换模型提供商。当需要切换到其他服务(如 DeepSeek)时,仅需修改 base-url 即可:
yaml
# 切换到 DeepSeek
ai:
openai:
base-url: https://api.deepseek.com
api-key: ${DEEPSEEK_API_KEY}
chat:
options:
model: deepseek-chat二、基础对话:ChatClient 的同步调用
最简单的方式是进行同步对话。用户发送问题,等待 LLM 返回完整的回答。
java
@RestController
public class artisanController {
@Autowired
private ChatClient chatClient;
/**
* 最基础的对话接口
* GET /chat?question=hello
*/
@GetMapping("/chat")
public String chat(String question) {
// chatClient.prompt() 开始构建一个提示词
// .call() 执行同步调用
// .content() 提取 LLM 的文本响应
return chatClient.prompt(question).call().content();
}
}工作流程:
1. chatClient.prompt(question)
└─> 创建一个 PromptRequest 对象,包含用户问题
2. .call()
└─> 发起同步 HTTP 请求到 DashScope API
└─> 阻塞等待 LLM 返回完整响应
3. .content()
└─> 从 ChatClientResponse 中提取消息内容
└─> 返回字符串格式的回答DashScope AI (LLM) ChatClient (Spring AI) Application / Controller DashScope AI (LLM) ChatClient (Spring AI) Application / Controller 1. 请求构建 2. 发起同步调用 内部推理中 (DashScope) 3. 内容提取 最终结果: "春风拂过绿田野..." prompt(question) 1 封装 PromptRequest (UserMessage + Options) 2 返回 ChatClientRequestSpec (链式声明) 3 call() 4 发送同步 HTTP POST (API 请求) 5 返回完整生成的 ChatResponse (200 OK) 6 返回 ChatClientResponse 7 .content() 8
-
同步阻塞 (Blocking):在第 5 步到第 6 步之间,call() 方法会使当前线程处于等待状态,直到 DashScope 返回完整的 JSON 响应。这适用于简单的 Web 接口,但不适用于长文本生成的流式场景。
-
链式 API 设计:prompt() 方法返回的是一个配置说明符(Spec),允许你随后链式调用 .system(...)、.advisors(...) 等方法,直到 .call() 触发真正的网络 IO。
-
抽象层隔离:ChatClient 作为 Spring AI 的统一抽象,屏蔽了 DashScope 特有的协议细节,使得更换模型提供商(如从 DashScope 切换到 OpenAI)无需修改核心逻辑。
优缺点分析:
| 特性 | 说明 |
|---|---|
| 优点 | 实现简单,逻辑清晰,适合后端批处理 |
| 缺点 | 阻塞等待,响应时间长,用户体验差 |
| 适用场景 | 异步任务、定时任务、消息队列处理 |
测试命令:
bash
curl "http://localhost:8081/chat?question=你好,请自我介绍"三、流式输出:Flux 与 SSE 的三种实现方式
现代 AI 应用需要实时显示 LLM 的输出过程,而不是等待完整响应。Spring AI 提供了两种流式处理方案。
3.1 方案一:Flux 流式响应
最简洁的方案是直接返回 Flux,由 Spring WebFlux 负责流式传输。
java
/**
* 返回 Flux 流,Spring 自动转换为 Server-Sent Events
* 注意 produces 指定了 Content-Type,包含 UTF-8 编码声明
*/
@GetMapping(value = "/stream", produces = "text/html;charset=UTF-8")
public Flux<String> stream(String question) {
// stream().content() 返回一个 Flux<String>
// 每个元素是一个 token(通常是一个词或一个字)
return chatClient.prompt(question).stream().content();
}工作流程:
java
chatClient.prompt(question)
└─> .stream() # 切换到流式调用模式
└─> 与 LLM 建立长连接
└─> 每当 LLM 生成一个 token,发出一个事件
└─> .content() # 只提取文本内容(忽略元数据)
└─> 返回 Flux<String>,Spring WebFlux 自动转换为 SSEDashScope API (LLM) ChatClient (Spring AI) Spring WebFlux Controller 前端浏览器 (EventSource) DashScope API (LLM) ChatClient (Spring AI) Spring WebFlux Controller 前端浏览器 (EventSource) 1. 发起流式请求 2. 建立响应流 3. Token 持续推送 (Chunks) loop 持续生成中 4. 连接关闭 (Complete) GET /chat/stream?q=... (Accept: text/event-stream) 1 prompt(question).stream() 2 发送 HTTP POST (Streaming Mode) 3 Data: {"delta": "春", ...} 4 Flux<ChatResponse> 元素 5 SSE Event: "春" 6 Data: {"delta": "风", ...} 7 Flux<ChatResponse> 元素 8 SSE Event: "风" 9
客户端使用示例:
html
<script>
const eventSource = new EventSource('/stream?question=请写一首诗');
eventSource.addEventListener('message', (event) => {
// event.data 包含每个 token
document.body.innerHTML += event.data;
});
eventSource.addEventListener('error', () => {
console.error('连接异常');
eventSource.close();
});
</script>3.2 方案二:SseEmitter 自定义编码
某些场景下需要完全控制 HTTP 响应头,特别是确保 UTF-8 编码。此时使用 SseEmitter 并自定义响应头。
java
/**
* 使用 SseEmitter 提供更细粒度的控制
* 通过重写 extendResponse 方法设置自定义 Content-Type
*/
@GetMapping(value = "/sse")
public SseEmitter sse(String question) {
// 创建 SseEmitter,支持自定义响应头
SseEmitter sseEmitter = new SseEmitter() {
@Override
protected void extendResponse(ServerHttpResponse outputMessage) {
HttpHeaders headers = outputMessage.getHeaders();
// 显式指定 Content-Type 和字符集,确保中文不乱码
headers.setContentType(new MediaType("text", "event-stream", StandardCharsets.UTF_8));
}
};
// 获取流
Flux<String> stream = chatClient.prompt(question).stream().content();
// 订阅流,将每个 token 发送给客户端
stream.subscribe(
// onNext:每当收到一个 token,发送给客户端
token -> {
try {
sseEmitter.send(token);
} catch (IOException e) {
// 网络异常,终止发送
sseEmitter.completeWithError(e);
}
},
// onError:流出现异常
sseEmitter::completeWithError,
// onComplete:流完成
sseEmitter::complete
);
return sseEmitter;
}关键实现细节:
- 响应头自定义 :通过
extendResponse()方法在发送第一个 SSE 消息前设置响应头,确保 UTF-8 编码。 - Flux 订阅:使用 Reactor 的三参数订阅方式,分别处理成功、错误、完成三种事件。
- 异常处理 :网络异常时主动调用
completeWithError()通知客户端。
3.3 方案三对比:何时选择哪个方案
| 方案 | 实现复杂度 | 控制粒度 | 推荐场景 |
|---|---|---|---|
| Flux 直接返回 | 低 | 低 | 简单场景、不需要特殊编码处理 |
| SseEmitter | 中 | 高 | 需要自定义响应头、特殊编码处理 |
四、系统提示词:定义 AI 的角色与行为
系统提示词(System Prompt)是指导 LLM 行为的关键。通过在每次请求前明确定义 LLM 的身份与行为准则,可以显著提升回答质量。
java
/**
* 在提示词中加入系统级别的指令
* GET /system?question=你好
*/
@GetMapping("/system")
public String system(String question) {
return this.chatClient
.prompt() // 不传入问题,而是手动构建提示词
.system("你是周瑜老师") // 设置系统提示词
.user(question) // 设置用户问题
.call()
.content();
}工作流程:
java
chatClient.prompt()
├─> .system("你是周瑜老师")
│ └─> 向消息列表中插入 system role 消息
│
├─> .user(question)
│ └─> 向消息列表中插入 user role 消息
│
└─> 最终消息结构:
[
{"role": "system", "content": "你是周瑜老师"},
{"role": "user", "content": "实际问题"}
]LLM (DashScope/OpenAI) Message List (内部状态) ChatClientRequestSpec 业务代码 LLM (DashScope/OpenAI) Message List (内部状态) ChatClientRequestSpec 业务代码 1. 角色设定 {"role": "system", "content": "..."} 2. 用户输入 system, {"role": "user", "content": "..."} 3. 提交请求 .system("你是周瑜老师") 1 add(SystemMessage) 2 .user("实际问题") 3 add(UserMessage) 4 .call() / .stream() 5 POST /chat/completions { messages: ... } 6 返回响应结果 7
- 内部状态维护:ChatClientRequestSpec 在链式调用的过程中,实际上是在维护一个消息集合。每一次 .system() 或 .user() 都是在向这个集合追加元素。
- 消息顺序性:在 LLM 交互中,消息的顺序至关重要。通常 System Message 置于首位,用于设定模型的行为边界、语气(如"周瑜老师"的特定人设)或知识背景。
- 角色映射:
.system() ----> SystemMessage(控制模型底层的指令) - .
user() ----> UserMessage(用户的具体提问) .messages() (底层 API) ----> 允许手动插入 AssistantMessage 或 ToolMessage以重建历史对话。
系统提示词的最佳实践:
java
// 不推荐:过于简单
.system("你是一个助手")
// 推荐:详细的角色定义与行为约束
.system("""
你是一名资深的 Java 开发者。
你的目标是帮助我学习 Spring AI 框架。
回答时请遵循以下原则:
1. 提供代码示例时必须能正常运行
2. 解释复杂概念时,先给出直观理解,再深入细节
3. 如果不确定答案,请明确说明
""")五、结构化输出:从 JSON 到 Java 对象
LLM 通常返回文本,但应用需要结构化数据。Spring AI 提供了两种方案来解决这个问题。
5.1 方案一:BeanOutputConverter + PromptTemplate
这是最灵活的方案,允许完全控制 LLM 的输出格式。
java
/**
* 定义输出数据结构
*/
static class Poem {
private String title; // 诗名
private String author; // 诗人
private String content; // 诗的内容
// getter/setter 省略
}
/**
* 通过 BeanOutputConverter 和 PromptTemplate 实现结构化输出
* GET /output?topic=春天
*/
@GetMapping("/output")
public Poem output(String topic) {
// 1. 创建输出转换器,指定目标类型
BeanOutputConverter<Poem> outputConverter =
new BeanOutputConverter<>(new ParameterizedTypeReference<Poem>() {});
// 2. 创建提示词模板,包含占位符
PromptTemplate promptTemplate =
new PromptTemplate("写一首关于{topic}的七言绝句,{format}");
// 3. 渲染模板
// outputConverter.getFormat() 返回 JSON Schema 格式说明
// 这告诉 LLM 应该按照什么格式返回数据
String prompt = promptTemplate.render(Map.of(
"topic", topic,
"format", outputConverter.getFormat()
));
// 4. 调用 LLM
String content = chatClient.prompt(prompt).call().content();
// 5. 转换 JSON 字符串为 Java 对象
return outputConverter.convert(content);
}outputConverter.getFormat() 返回的格式说明示例:
json
{
"type": "object",
"properties": {
"title": {"type": "string", "description": "诗的标题"},
"author": {"type": "string", "description": "诗人名字"},
"content": {"type": "string", "description": "诗的正文"}
},
"required": ["title", "author", "content"]
}工作流程图:
java
1. 用户请求:/output?topic=春天
2. BeanOutputConverter.getFormat()
└─> 生成 Poem 类的 JSON Schema
└─> "请按照以下 JSON 格式回答..."
3. 提示词模板渲染
└─> "写一首关于春天的七言绝句,{JSON Schema}"
4. LLM 生成的响应
└─> {
"title": "春日游",
"author": "周瑜",
"content": "春风拂过绿田野,..."
}
5. BeanOutputConverter.convert()
└─> 将 JSON 字符串解析为 Poem 对象
└─> 返回 Java 对象Poem (Java Bean) 大语言模型 (LLM) PromptTemplate BeanOutputConverter 用户/控制器 Poem (Java Bean) 大语言模型 (LLM) PromptTemplate BeanOutputConverter 用户/控制器 1. 初始化与 Schema 生成 2. 提示词组装 3. 模型推理 4. 结构化解析 (Deserialization) 5. 业务逻辑处理 (如: poem.getTitle()) getFormat() 1 返回指令: "请按此 JSON Schema 格式回答..." 2 填充变量 (topic="春天") + 注入 Format 指令 3 最终 Prompt: "写一首关于春天的诗,{JSON...}" 4 发送完整 Prompt 5 返回 JSON 字符串: {"title": "春日游", ...} 6 convert(jsonString) 7 解析 JSON 并映射至 Poem.class 8 返回 Poem 实例 (POJO) 9
-
反射与 Schema 生成 (Step 2):BeanOutputConverter 内部利用 Jackson 或类似库反射 Poem 类,生成精确的 JSON Schema。这是确保 LLM "听话"的关键。
-
Prompt 注入 (Step 3):将格式要求作为 System Message 或 User Message 的一部分,强迫模型进入"API 模式"而非"聊天模式"。
-
类型安全 (Step 5):通过 convert() 方法,将不可控的字符串转换为开发人员熟悉的 Java 对象,极大降低了后端解析报错的风险。
5.2 方案二:entity() 直接转换
Spring AI 1.1.0 新增了 entity() 方法,可以一行代码实现对象转换。
java
/**
* 更简洁的方式:使用 entity() 直接转换
* GET /entity?topic=冬天
*/
@GetMapping("/entity")
public Poem entity(String topic) {
PromptTemplate promptTemplate =
new PromptTemplate("写一首关于{topic}的七言绝句");
String prompt = promptTemplate.render(Map.of("topic", topic));
// entity() 内部自动使用 BeanOutputConverter
// Spring AI 自动分析 Poem 类的结构,生成 JSON Schema
// 附加到提示词末尾,然后解析返回值
return chatClient.prompt(prompt).call().entity(Poem.class);
}entity() 方法的优势:
- 简洁:一行代码完成转换
- 安全:类型检查在编译期完成
- 智能:Spring AI 自动处理格式说明生成
5.3 两种方案对比
| 特性 | BeanOutputConverter | entity() |
|---|---|---|
| 代码简洁度 | 较复杂 | 简洁 |
| 定制灵活性 | 高(完全控制格式说明) | 低(自动生成) |
| 适用场景 | 复杂嵌套对象、特殊格式要求 | 简单对象、快速开发 |
六、深入理解:ChatClient 的架构设计
6.1 Builder 模式与链式调用
Spring AI 的 ChatClient 采用 Builder 模式和流式接口(Fluent Interface)设计,使代码更易读且易于扩展。
java
// 基础链式调用
chatClient
.prompt() // 1. 创建 PromptRequest
.system("系统提示词") // 2. 添加系统消息
.user("用户问题") // 3. 添加用户消息
.call() // 4. 执行同步调用
.content(); // 5. 提取响应内容
// 流式调用
chatClient
.prompt("问题")
.stream() // 切换到流式模式
.content(); // 返回 Flux<String>设计优势:
- 可读性:每个方法名清晰表达其意图
- 扩展性:新增选项时只需在链中插入新方法
- 编译检查:返回类型明确,IDE 能提供自动补全
6.2 ChatClient 内部工作原理
虽然 ChatClient 的使用很简单,但内部实现却相当复杂。
java
用户代码:
chatClient.prompt(question).call().content()
↓
┌─────────────────────────────────────────┐
│ ChatClientRequestSpec 构建请求 │
│ - 添加系统消息 │
│ - 添加用户消息 │
│ - 应用 Advisors(拦截器) │
│ - 配置模型选项(温度、max_tokens 等) │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 通过 ChatModel 调用 LLM API │
│ - 序列化为 OpenAI 格式 │
│ - 发送 HTTP 请求到 DashScope │
│ - 解析返回的 JSON 响应 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ ChatClientResponse 包装返应 │
│ - 消息内容 │
│ - 元数据(模型名、token 数等) │
│ - 工具调用信息 │
└─────────────────────────────────────────┘
↓
.content() 提取文本内容6.3 流式调用的底层机制
流式调用的关键是利用 Reactor 框架的 Flux。
java
// 调用链
chatClient.prompt().stream().content()
↓
// 内部实现伪代码
Flux<String> streamContent() {
// 1. 创建长连接到 LLM API
// 2. 监听服务器发来的事件
// 3. 将每个 token 作为一个元素发出
return Flux.create(emitter -> {
// 当 LLM 发送一个 token 时
// emitter.next(token)
});
}关键特点:
- 非阻塞:使用 Flux 而不是传统的 Thread.sleep() 或 BlockingQueue
- 背压处理:Reactor 自动处理生产者速度 > 消费者速度的情况
- 异常传播 :流中任何异常都会触发
onError回调
七、生产级别的实战建议
7.1 错误处理
java
@GetMapping("/chat")
public ResponseEntity<?> chat(String question) {
try {
String response = chatClient.prompt(question).call().content();
return ResponseEntity.ok(response);
} catch (IllegalStateException e) {
// API Key 配置错误
return ResponseEntity.status(500)
.body("AI 服务配置错误: " + e.getMessage());
} catch (HttpClientErrorException e) {
// API 调用失败(流量限制、模型不存在等)
if (e.getStatusCode() == HttpStatus.TOO_MANY_REQUESTS) {
return ResponseEntity.status(429)
.body("请求过于频繁,请稍后再试");
}
return ResponseEntity.status(500)
.body("AI 服务异常: " + e.getMessage());
}
}7.2 请求超时配置
yaml
spring:
ai:
openai:
base-url: https://dashscope.aliyuncs.com/compatible-mode
api-key: ${DASHSCOPE_API_KEY}
chat:
options:
model: qwen3-max
# 单次请求超时时间(秒)
temperature: 0.7
max-tokens: 20487.3 成本控制
java
/**
* 统计 token 使用情况
*/
@GetMapping("/chat-with-metrics")
public Map<String, Object> chatWithMetrics(String question) {
ChatClientResponse response = chatClient
.prompt(question)
.call();
Map<String, Object> result = new HashMap<>();
result.put("answer", response.getResult().getOutput().getContent());
// 获取 token 统计信息
if (response.getMetadata() != null) {
result.put("tokenUsage", Map.of(
"promptTokens", response.getMetadata().getUsage().getPromptTokens(),
"completionTokens", response.getMetadata().getUsage().getCompletionTokens(),
"totalTokens", response.getMetadata().getUsage().getTotalTokens()
));
}
return result;
}八、常见问题解答
Q1:如何确保中文显示不乱码?
A: 在以下三个地方确保使用 UTF-8:
- 项目编码:
pom.xml中设置<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> - 响应头:使用 SseEmitter 时显式指定
MediaType("text", "event-stream", StandardCharsets.UTF_8) - 数据库连接:MySQL URL 中加入
useUnicode=true&characterEncoding=utf-8
Q2:Flux 和 SseEmitter 有什么区别?
A:
| 方面 | Flux | SseEmitter |
|---|---|---|
| 是否阻塞 | 非阻塞,基于 Reactor | 非阻塞,基于 Servlet 异步 |
| 响应头控制 | 自动处理 | 可完全自定义 |
| 客户端兼容性 | 需要支持 Server-Sent Events | 标准 SSE,广泛支持 |
| 推荐使用 | Spring Boot 3.0+ | 需要特殊控制时 |
Q3:如何切换不同的 LLM 模型?
A: 修改 application.yml 中的配置:
yaml
# 切换到 DeepSeek
spring:
ai:
openai:
base-url: https://api.deepseek.com
api-key: ${DEEPSEEK_API_KEY}
chat:
options:
model: deepseek-chat
# 或切换到 OpenAI
spring:
ai:
openai:
base-url: https://api.openai.com/v1
api-key: ${OPENAI_API_KEY}
chat:
options:
model: gpt-4-turboQ4:如何监控和日志记录 LLM 调用?
A: Spring AI 支持通过 Spring AI 的日志观察机制:
yaml
spring:
ai:
chat:
client:
observations:
log-prompt: true # 记录发送给 LLM 的提示词
log-completion: true # 记录 LLM 的响应或通过编程方式:
java
@Bean
public CallAdvisor loggingAdvisor() {
return new CallAdvisor() {
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
logger.info("请求内容: {}", request.prompt());
ChatClientResponse response = chain.nextCall(request);
logger.info("响应内容: {}", response.getResult().getOutput().getContent());
return response;
}
@Override
public String getName() {
return "LoggingAdvisor";
}
};
}九、性能优化建议
9.1 连接复用
ChatClient 是线程安全的,建议全局使用单一实例:
java
// 推荐:全局单例
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder.build();
}
// 不推荐:每次创建新实例
public void chat() {
ChatClient client = new ChatClient(); // 错误做法
}9.2 缓存策略
对于相同的问题,可以使用缓存避免重复调用 LLM:
java
private final Cache cache = new ConcurrentHashMapCache();
@GetMapping("/cached-chat")
public String cachedChat(String question) {
return cache.computeIfAbsent(question, q -> {
return chatClient.prompt(q).call().content();
});
}9.3 批量处理
对于批量处理任务,使用异步流处理:
java
@PostMapping("/batch-chat")
public ResponseEntity<?> batchChat(@RequestBody List<String> questions) {
return ResponseEntity.ok(
questions.parallelStream()
.map(q -> chatClient.prompt(q).call().content())
.collect(Collectors.toList())
);
}十、总结与展望
- 项目搭建:通过 Maven 依赖和配置文件快速集成 Spring AI
- 三种调用模式:同步调用、Flux 流式、SseEmitter 自定义
- 系统提示词:指导 LLM 行为的强大工具
- 结构化输出:使用 BeanOutputConverter 和 entity() 获取 Java 对象
- 架构理解:ChatClient 的 Builder 模式与内部工作原理
- 生产级建议:错误处理、超时、成本控制、监控
Spring AI 生态极其丰富,本文只涉及核心基础。后续可深入学习:
- RAG(检索增强生成):结合向量数据库,让 LLM 能够查询知识库
- 函数调用:让 LLM 能够主动调用外部工具和 API
- 多模态:支持图像、音频等非文本输入
- 智能体(Agent):让 LLM 能够自主规划和执行任务
- 记忆管理:构建具有长期记忆的对话系统
参考资源
完整示例项目
bash
# 1. 设置环境变量
export DASHSCOPE_API_KEY=your-api-key
# 2. 启动应用
cd spring-ai-demo
mvn spring-boot:run
# 3. 测试接口
curl "http://localhost:8081/chat?question=你好"
curl "http://localhost:8081/stream?question=请写一首诗"
curl "http://localhost:8081/entity?topic=春天"关键代码速查表
| 功能 | 代码片段 | 说明 |
|---|---|---|
| 基础对话 | chatClient.prompt(q).call().content() |
同步获取完整回答 |
| 流式输出(Flux) | chatClient.prompt(q).stream().content() |
返回 Flux |
| 流式输出(SSE) | new SseEmitter() + stream.subscribe() |
完全控制响应头 |
| 系统提示词 | .system("你是...").user(q) |
定义 AI 角色 |
| 结构化输出 | outputConverter.convert(json) |
JSON 转 Java 对象 |
| 直接转换 | .call().entity(Poem.class) |
一行代码转换 |
