📖标题:PhyCritic: Multimodal Critic Models for Physical AI
🌐来源:arXiv, 2602.11124v1
🌟摘要
随着大型多模态模型的快速发展,可靠的判断和批评模型已经成为开放式评估和偏好对齐的关键,为评估模型生成的反应提供成对偏好、数字分数和解释性理由。然而,现有的批评者主要在一般视觉领域接受训练,如字幕或图像问答,使得涉及感知、因果推理和规划的物理人工智能任务在很大程度上没有得到充分开发。我们引入了PhyCritic,这是一个通过两阶段RLVR管道针对物理人工智能优化的多模态批评家模型:物理技能预热阶段,增强面向物理的感知和推理,然后是自我引用的批评家微调,批评家在判断候选人反应之前生成自己的预测作为内部参考,提高判断稳定性和物理正确性。在物理和通用多模态判断基准中,PhyCritic实现了比开源基线更高的性能提升,当作为策略模型应用时,进一步改善了物理接地任务中的感知和推理。
🛎️文章简介
🔸研究问题:如何为物理AI任务(如因果推理、动作规划、具身感知)设计一个能准确判断模型响应是否符合物理规律的多模态评判模型?
🔸主要贡献:论文提出了PhyCritic------首个专为物理AI设计的自参照式多模态评判模型,通过两阶段RLVR训练框架,使评判过程根植于模型自身的物理理解,显著提升判断稳定性与物理正确性。
📝重点思路
🔸提出"先求解、再评判"的自参照范式:评判前先生成自身对问题的物理感知与推理预测,以此作为内部参考标准。
🔸设计两阶段强化学习训练流程:第一阶段用物理问答数据进行技能热身(RLVR),增强基础物理感知与推理能力;第二阶段进行自参照评判微调,联合优化自我预测准确率与偏好判断准确率。
🔸构建面向物理AI的专用评测基准PhyCritic-Bench,覆盖机器人操作、自动驾驶等真实具身场景,含高质量配对响应与可验证偏好标签。
🔸采用结构化评判提示模板,明确要求模型输出自推理(<pred_think>)、自答案()、对比分析()及最终判决(\boxed{}),并引入格式奖励约束输出规范性。
🔸使用Group Relative Policy Optimization(GRPO)算法,避免价值网络依赖,通过组内轨迹比较计算优势函数,提升训练稳定性。
🔎分析总结
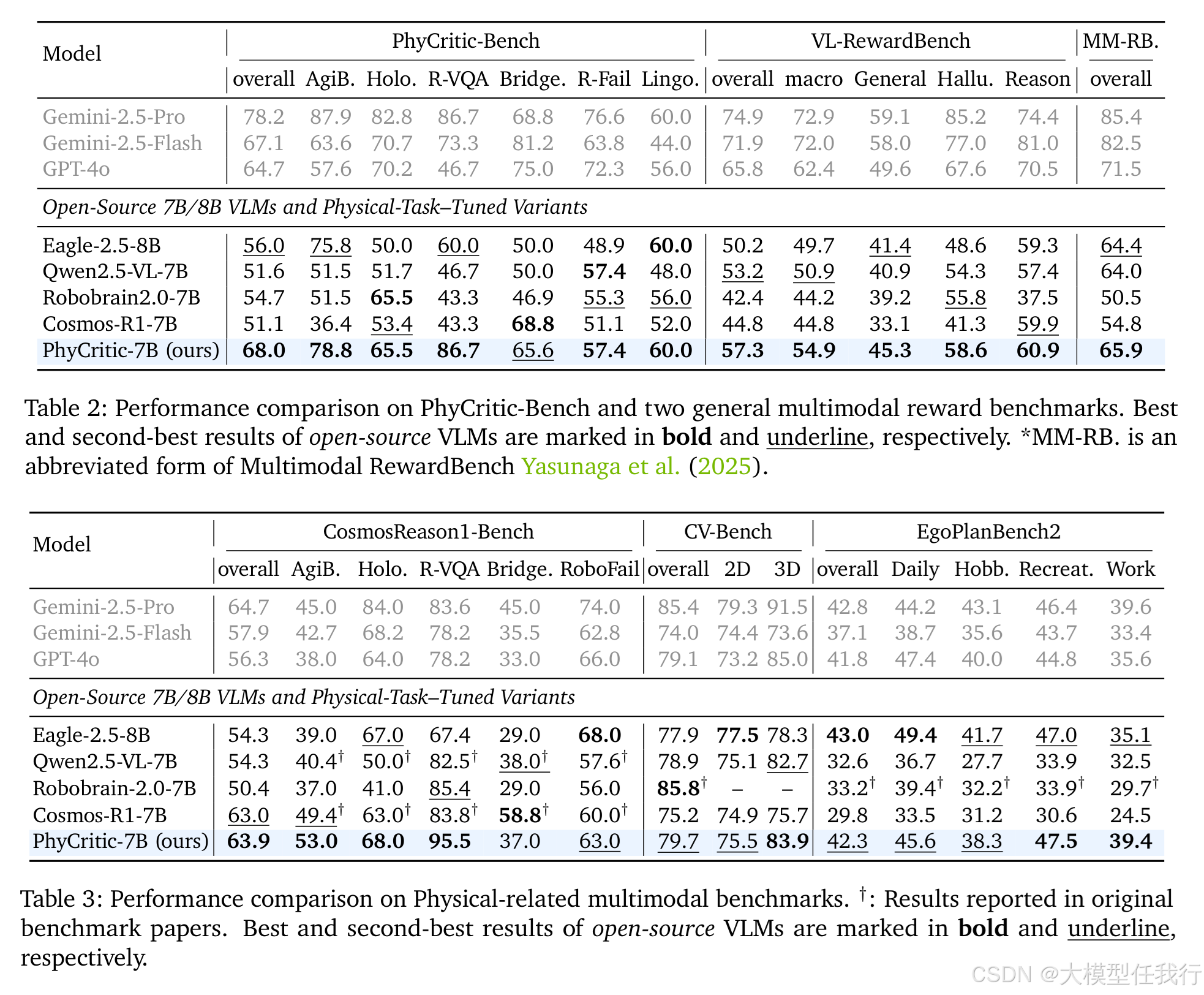
🔸PhyCritic在物理评判基准PhyCritic-Bench上以68.0%准确率超越所有开源7B/8B基线(最高+16.9点),且在AgiBot、RoboVQA等子集达最优或并列最优。
🔸其物理评判能力可泛化至通用多模态奖励基准(VL-RewardBench、Multimodal RewardBench),在未见领域仍稳定提升判断性能。
🔸作为策略模型时,PhyCritic在CosmosReason1-Bench等物理推理任务上也表现优异(63.9%),证明评判训练反向增强了物理推理能力。
🔸消融实验证明:去除自参照机制导致性能下降3.6点;仅移除自我预测奖励亦下降2.2点,证实"自我求解"是提升判断一致性的关键。
🔸卡方检验显示,自我预测正确性与最终判断质量呈强正相关(p < 1e-36),验证"解题能力决定评判质量"的核心假设。
💡个人观点
论文将人类批判性思维(先独立思考、再对照评估)形式化为可训练的机器学习范式,强调评判能力源自求解能力。
🧩附录