三大模型深度对比:Zhipu GLM-5 vs MiniMax M2.5 vs Qwen3-Coder-Next
- 本文基于智谱AI、MiniMax和阿里千问的官方文档,对三个最新模型进行全面对比分析。*

2026年2月,中国AI大模型领域迎来了新一轮的发布潮。三大厂商相继推出了新一代模型:智谱AI的GLM-5、MiniMax的M2.5、以及阿里千问的Qwen3-Coder-Next。这三个模型各有侧重:GLM-5定位为旗舰级通用Agent,M2.5聚焦生产力场景,Qwen3-Coder-Next则主打小而美的开源编程模型。
本文将从编程能力、Agent能力、性能指标、成本效益和适用场景五个维度对这三个模型进行深入对比,帮助开发者和企业选择最适合自己需求的模型。
模型概览
| 项目 | GLM-5 | MiniMax M2.5 | Qwen3-Coder-Next |
|---|---|---|---|
| 发布时间 | 2026年2月11日 | 2026年2月12日 | 2026年2月4日 |
| 参数规模 | 744B总/40B激活 | 未公开(推测~10B激活) | 80B总/3B激活 |
| 上下文窗口 | 200K | 未公开 | 未公开 |
| 定位 | 旗舰级通用Agent | 生产力导向前沿模型 | 小型混合线性MoE编程模型 |
| SWE-Bench Verified | 77.8% | 80.2% | 70%+ |
| 开源状态 | 部分开源 | 未开源 | 完全开源 |
从参数规模上看,GLM-5 的 744B 总参数(40B激活)远超其他两个模型,体现了其在通用智能上的野心。而 Qwen3-Coder-Next 仅激活 3B 参数,是三者中最轻量的。MiniMax M2.5 的参数规模处于中间位置,未公开具体数值。
编程能力对比
SWE-Bench成绩
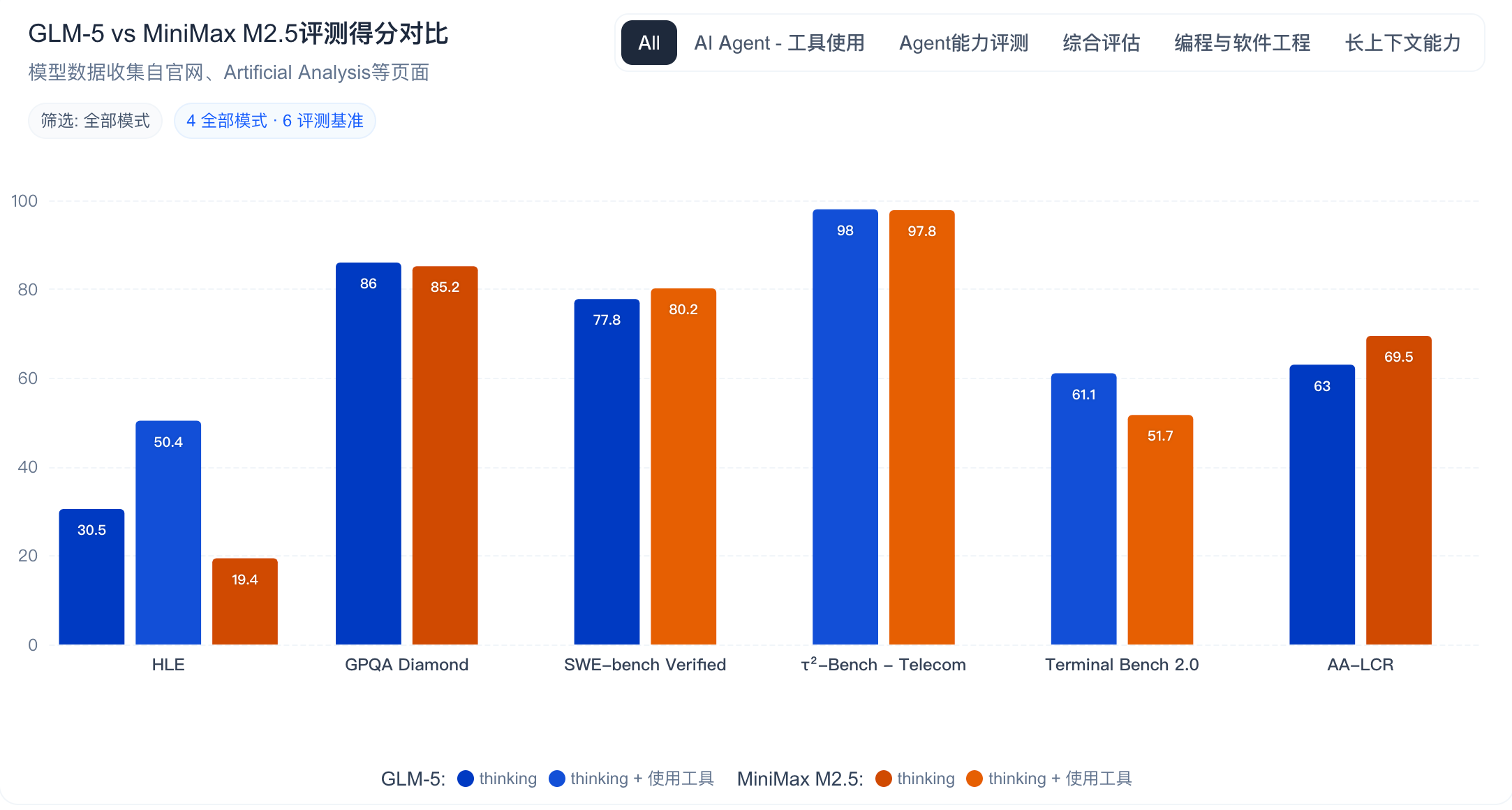
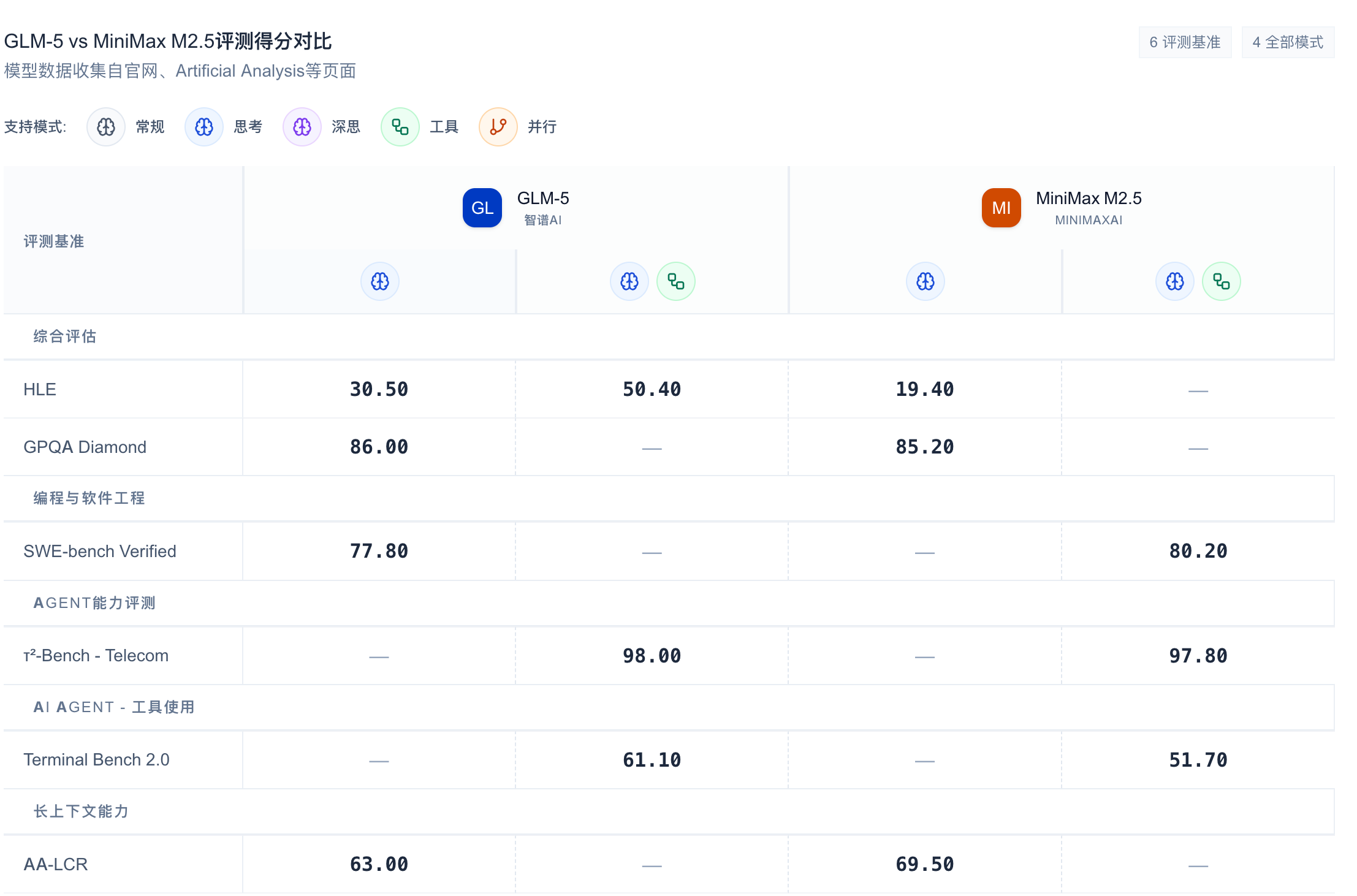
在编程能力的权威测试 SWE-Bench Verified 上,三个模型的表现如下:
| 模型 | SWE-Bench Verified | Multi-SWE-Bench |
|---|---|---|
| GLM-5 | 77.8% | 未公开 |
| MiniMax M2.5 | 80.2% | 51.3% |
| Qwen3-Coder-Next | 70%+ | 未公开 |
MiniMax M2.5 在 SWE-Bench Verified 上以 80.2% 的成绩领先,比 GLM-5 高出 2.4 个百分点。GLM-5 的 77.8% 也是一个相当优秀的成绩,表明其在代码工程能力上已经接近国际一流水平。Qwen3-Coder-Next 虽然仅激活 3B 参数,但仍达到了 70%+ 的成绩,展现了其高效参数利用能力。
在多语言编程测试 Multi-SWE-Bench 上,MiniMax M2.5 取得了 51.3% 的成绩,表明其在多语言场景下具有显著优势。
代码质量与特色能力
GLM-5 的特色在于其 Agentic Engineering 定位。它不单善于生成前端网页,更善于处理后端任务、系统重构、深度调试,摒弃了"重前端审美、轻底层逻辑"的模式。GLM-5 具备极强的自我反思与纠错机制,能在编译失败或运行报错时,自主分析日志、定位根因并迭代修复,直到系统跑通。
MiniMax M2.5 的核心优势是 Spec-writing 能力。在动手写代码前,M2.5 以架构师的视角主动拆解功能、结构和 UI 设计,实现完整的前期规划。M2.5 经过 200,000+ 真实环境训练,覆盖了从 0-1 系统设计到 90-100 code review 的完整开发生命周期。
Qwen3-Coder-Next 的优势在于其混合线性 MoE 架构。它采用了边思考边编程的训练路线,模型在真实可执行环境中学习,能够从环境反馈中"边干边学",从而学习到程序员处理现实编程问题的"精髓"。Qwen3-Coder-Next 的推理成本仅为同等性能模型的 5%-10%,特别适合家用电脑、轻量服务器等低成本智能体部署场景。
多语言支持
| 模型 | 支持语言数量 | 典型语言 |
|---|---|---|
| GLM-5 | 未明确 | 通用(Python、JavaScript等) |
| MiniMax M2.5 | 10+ 种 | Go、C、C++、TS、Rust、Kotlin、Python、Java、JS、PHP、Lua、Dart、Ruby |
| Qwen3-Coder-Next | 未明确 | 通用(Python等) |
MiniMax M2.5 在多语言支持上表现最为突出,明确列出了 10+ 种编程语言,这对于需要处理多语言代码库的企业级应用是一个重要优势。
Agent能力对比
长程任务执行
GLM-5 在长程 Agent 任务上具有优势。它能够跑长程任务,即多阶段、长步骤的复杂任务,可以自主拆分需求,自动化连续运行长达数小时,并保持上下文连贯与目标一致性。其 Slime 训练框架支持更大模型规模及更复杂的强化学习任务。
MiniMax M2.5 同样具备强大的长程任务执行能力。其在数百个真实复杂环境中的强化学习训练,使其在处理需要多步骤、多工具调用的复杂任务时表现出色。M2.5 优化了任务拆解能力,相比 M2.1 将 SWE-Bench Verified 任务完成时间缩短了 37%。
Qwen3-Coder-Next 虽然参数量小,但通过大规模可执行任务合成、环境交互与强化学习进行智能体训练,在长上下文推理、工具使用、从执行失败中恢复等对现实世界中的编程智能体至关重要的能力上都有所提升。
工具调用与搜索能力
在工具调用和搜索能力上,三个模型各有特色:
GLM-5:在 BrowseComp、MCP-Atlas 和 τ²-Bench 等三项 Agent 评测中均取得开源领域最优表现,表明其在工具使用和多步骤任务执行上具有综合优势。
MiniMax M2.5:在 BrowseComp 上取得 76.3% 的成绩。MiniMax 构建了 RISE(Realistic Interactive Search Evaluation)来衡量模型在真实世界专业任务上的搜索能力。M2.5 以更低的轮次消耗取得了更好的结果,相比 M2.1 使用约少 20% 的搜索轮次,表明模型学会了用更精准的搜索轮次和更优的 token 效率去解决问题。
Qwen3-Coder-Next:虽然专门面向编程,但其 Agent 训练扩展使其在需要长程推理、工具使用和从执行失败中恢复的场景下都能从容应对。
决策能力
三个模型都通过不同的训练框架来优化决策能力:
- GLM-5:Slime 框架 + 异步智能体强化学习算法
- MiniMax M2.5:Forge RL 框架 + CISPO 算法 + 过程奖励机制
- Qwen3-Coder-Next:异步智能体强化学习算法 + 多轮决策优化
性能指标对比
推理速度
| 模型 | 输出速度 | 推理效率 |
|---|---|---|
| GLM-5 | 未公开 | 高(40B激活参数) |
| MiniMax M2.5 | 100 TPS(Lightning),50 TPS(标准) | 优化(减少20%搜索轮次) |
| Qwen3-Coder-Next | 未公开 | 极高(3B激活参数) |
MiniMax M2.5 在推理速度上有明确的优势:100 TPS 的 Lightning 版本几乎是其他前沿模型的两倍,50 TPS 的标准版也能满足大多数应用需求。相比前代 M2.1,M2.5 在 SWE-Bench Verified 上将任务完成时间缩短了 37%。
Qwen3-Coder-Next 虽然只激活 3B 参数,但其推理效率极高,推理成本仅为同等性能模型的 5%-10%。
上下文窗口
| 模型 | 上下文窗口 |
|---|---|
| GLM-5 | 200K tokens |
| MiniMax M2.5 | 未公开 |
| Qwen3-Coder-Next | 未公开 |
GLM-5 在上下文窗口上有明确优势,200K 的上下文长度对于需要处理长文档、长代码库的复杂任务非常重要。
成本效益对比
API定价
| 模型 | 输入价格 | 输出价格 | 相对成本 |
|---|---|---|---|
| GLM-5 | $2/M input(推断) | $6/M output(推断) | 中等 |
| MiniMax M2.5-Lightning | $0.30/M input | $2.40/M output | 最低 |
| MiniMax M2.5 | $0.15/M input | $1.20/M output | 极低 |
| Qwen3-Coder-Next | 开源免费 | 开源免费 | 部署成本 |
MiniMax M2.5 在成本上具有绝对优势。M2.5-Lightning 的 0.30/M 输入价格和 2.40/M 输出价格,仅为其他前沿模型的 1/10 到 1/20。在每秒输出 100 Token 的情况下,M2.5 连续工作一小时只需花费 1 美金。以这种价格,可以支持四个 M2.5 实例连续工作一整年,成本仅为 10,000 美元。
GLM-5 的定价为 2/M 输入和 6/M 输出,处于中等水平。Qwen3-Coder-Next 完全开源免费,但需要自行部署和运维,适合本地部署场景。
部署成本与ROI
从 ROI 角度分析:
- MiniMax M2.5:API模式下性价比最高,无需关注基础设施成本。适合高频调用、成本敏感的应用。
- GLM-5:中等定价,强大的综合能力。适合需要长上下文、复杂 Agent 任务的企业级应用。
- Qwen3-Coder-Next:零 API 成本,但需自行部署。适合数据敏感、需要本地化、有充足算力资源的场景。
适用场景对比
企业级部署
| 场景 | GLM-5 | MiniMax M2.5 | Qwen3-Coder-Next |
|---|---|---|---|
| 复杂系统工程 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 长程Agent任务 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 需要长上下文 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 成本敏感 | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
GLM-5 是企业级部署的首选推荐。其 200K 上下文窗口、强大的长程 Agent 能力和在多个 benchmark 上的开源 SOTA 表现,使其非常适合需要处理复杂系统工程、长周期任务的企业应用。
个人开发者
| 场景 | GLM-5 | MiniMax M2.5 | Qwen3-Coder-Next |
|---|---|---|---|
| 快速原型开发 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 高频API调用 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 学习成本 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 本地部署需求 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
MiniMax M2.5 是个人开发者的理想选择。其极低的 API 成本、SOTA 级别的编程能力(80.2% SWE-Bench)和快速响应速度,使其成为性价比最高的选择。对于个人开发者或小团队,M2.5 提供了无需担心成本的"智能太廉价,无法计费"的体验。
本地部署
| 场景 | GLM-5 | MiniMax M2.5 | Qwen3-Coder-Next |
|---|---|---|---|
| 数据隐私要求 | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 离线使用 | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 部署便捷性 | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 资源需求 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
Qwen3-Coder-Next 是本地部署的不二选择。完全开源、仅 3B 激活参数的低资源需求,使其可以在家用电脑或轻量服务器上流畅运行。对于数据敏感场景、需要本地化、或希望完全控制部署环境的用户,Qwen3-Coder-Next 是最佳选择。
多语言项目
| 场景 | GLM-5 | MiniMax M2.5 | Qwen3-Coder-Next |
|---|---|---|---|
| 多语言代码库 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 跨语言集成 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
MiniMax M2.5 在多语言支持上表现突出,明确支持 10+ 种编程语言,适合需要处理多语言代码库的项目。
中文语境优化
| 场景 | GLM-5 | MiniMax M2.5 | Qwen3-Coder-Next |
|---|---|---|---|
| 中文理解能力 | ⭐⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
GLM-5 和 MiniMax M2.5 作为国内厂商的模型,在中文理解和表达上都有优势。Qwen3-Coder-Next 虽然也是阿里千问的产品,但更专注于代码生成场景。
综合推荐
适合 GLM-5 的场景和人群
推荐场景:
- 需要处理复杂系统工程的企业
- 长周期、多步骤的复杂 Agent 任务
- 需要 200K 长上下文的应用
- 需要在多个 benchmark 上都有稳定表现的场景
推荐人群:
- 企业技术团队
- 需要复杂系统开发的团队
- 对成本不敏感但对综合能力要求高的用户
理由:GLM-5 在复杂系统工程、长程 Agent 能力、长上下文等关键维度上表现最强,虽然定价中等,但对于企业级应用来说,综合优势最为明显。
适合 MiniMax M2.5 的场景和人群
推荐场景:
- 需要高频调用 API 的应用
- 对成本敏感的生产力工具
- 编程密集型应用
- 多语言开发项目
- 需要快速响应的场景
推荐人群:
- 个人开发者
- 初创团队
- Agent 应用开发者
- 对成本敏感但需要高性能的用户
理由:MiniMax M2.5 在编程能力上达到 SOTA(80.2% SWE-Bench),成本仅为其他模型的 1/10 到 1/20,推理速度领先(100 TPS),是性价比最高的选择。
适合 Qwen3-Coder-Next 的场景和人群
推荐场景:
- 需要本地部署的场景
- 数据隐私要求高的应用
- 需要离线使用的场景
- 算力资源有限的环境
- 需要完全控制部署环境的用户
推荐人群:
- 数据敏感的企业
- 需要本地化的政府/金融行业
- 拥有自有算力的团队
- 对数据隐私有严格要求的个人开发者
理由:Qwen3-Coder-Next 完全开源、仅 3B 激活参数的低资源需求,推理成本仅为同等性能模型的 5%-10%,是本地部署的理想选择。
总结
三大模型各有侧重:
- GLM-5:综合能力最强,适合企业级复杂应用和长程 Agent 任务
- MiniMax M2.5:性价比最高,编程能力 SOTA,适合高频 API 调用和成本敏感场景
- Qwen3-Coder-Next:最佳开源选择,适合本地部署和数据敏感场景
开发者可以根据自己的具体需求(成本预算、是否需要本地部署、任务复杂度、多语言需求等)选择最适合的模型。