MemFly:当智能体的记忆学会了"断舍离"------信息瓶颈驱动的即时记忆优化
📖 论文标题:MemFly: On-the-Fly Memory Optimization via Information Bottleneck
🔗 论文链接:https://arxiv.org/abs/2602.07885
👥 作者:Zhenyuan Zhang, Xianzhang Jia, Zhiqin Yang, Zhenbo Song, Wei Xue, Sirui Han, Yike Guo
📅 发表时间:2026年2月
🎯 一句话总结
MemFly 把信息论里经典的**信息瓶颈(Information Bottleneck)**原理搬到了 LLM 智能体的长期记忆管理中,让智能体像一个高效的图书管理员一样------该压缩的压缩,该保留的保留,该建立索引的建立索引,最终实现了"记得少但记得准"的效果。
🤔 为什么需要这篇论文?
智能体记忆的"囤积症"困境
想象一下你是一个秘书,老板每天和你聊上百句话。半年后老板突然问你:"我三月份跟谁讨论过那个项目来着?"如果你把所有对话一字不漏地记下来,翻找起来会累死;如果你只记关键词摘要,很多细节就丢了。
LLM 智能体面临的正是这个困境。现有的记忆管理方案大致分两类:
| 方案 | 代表方法 | 优点 | 痛点 |
|---|---|---|---|
| 检索中心型 | LoCoMo, ReadAgent | 保留原始信息完整度 | 冗余越积越多,检索效率下降 |
| 记忆增强型 | MemGPT, A-MEM, Mem0 | 主动压缩和组织信息 | 压缩过程中丢失精细信息 |
一边是"什么都不扔"的数字囤积症,另一边是"扔错东西"的过度整理。有没有一个理论框架,能告诉我们到底该保留什么、压缩什么?
信息瓶颈:一个来自信息论的优雅答案
1999年,以色列物理学家 Naftali Tishby 提出了**信息瓶颈(Information Bottleneck, IB)**原理。这个理论的直觉很简单:
给你一堆输入数据 XXX,你要把它压缩成一个紧凑的表示 MMM,但这个 MMM 必须对预测目标 YYY 尽可能有用。
用公式说就是:最小化 I(X;M)I(X; M)I(X;M)(压缩)的同时最大化 I(M;Y)I(M; Y)I(M;Y)(相关性)。这像极了我们对记忆的要求------忘掉废话,记住干货。
MemFly 的作者正是从这个理论出发,把智能体记忆的构建过程形式化为一个在线信息瓶颈优化问题,然后用 LLM 本身作为"无梯度优化器"来求解。
🏗️ MemFly 架构全景
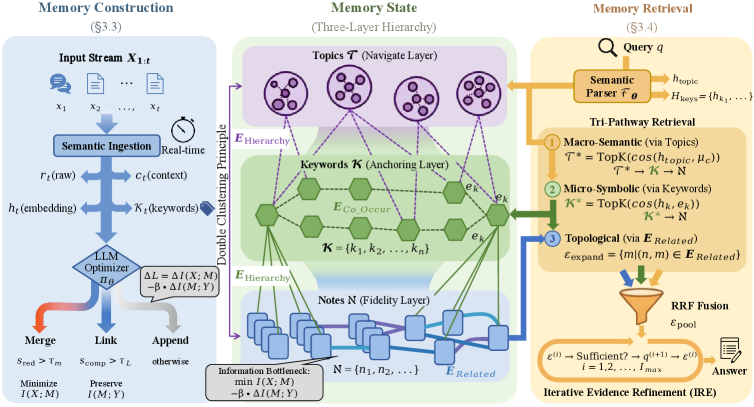
图1:MemFly 的完整架构。左侧是记忆构建流程(接收输入流、去噪、门控更新),中间是三层分层记忆结构(Note-Keyword-Topic),右侧是三通路混合检索机制(语义、符号、拓扑)加上迭代证据细化。
这张架构图信息量很大,我们拆开来看。MemFly 包含三大核心模块:
- 记忆构建(Memory Construction):实时处理输入流,决定"新信息怎么存"
- 记忆状态(Memory State):维护 Note→Keyword→Topic 的三层层级结构
- 记忆检索(Memory Retrieval):三条通路并行检索,加迭代细化
🧠 核心方法:把记忆变成一道优化题
优化目标:压缩与相关性的拉锯战
MemFly 的理论核心是这个拉格朗日目标函数:
minπLIB(Mt)=I(X1:t;Mt)⏟压缩项−βI(Mt;Y)⏟相关性项\min_{\pi} \mathcal{L}{\text{IB}}(M_t) = \underbrace{I(X{1:t}; M_t)}{\text{压缩项}} - \beta \underbrace{I(M_t; Y)}{\text{相关性项}}πminLIB(Mt)=压缩项 I(X1:t;Mt)−β相关性项 I(Mt;Y)
翻译成人话:
- 压缩项 I(X1:t;Mt)I(X_{1:t}; M_t)I(X1:t;Mt):记忆状态 MtM_tMt 保留了多少原始输入的信息。这个值越小,说明压缩得越狠------把冗余都挤掉了。
- 相关性项 I(Mt;Y)I(M_t; Y)I(Mt;Y):记忆状态 MtM_tMt 对未来任务 YYY 有多大帮助。这个值越大越好------关键信息都在。
- β\betaβ:平衡因子,控制"宁可多记点"还是"宁可压狠点"的倾向。
这就像收拾衣柜:你希望衣柜尽可能精简(压缩项小),但明天要穿的衣服一件不能少(相关性项大)。
不过直接优化整段历史 X1:tX_{1:t}X1:t 不现实------数据是流式到达的。所以 MemFly 采用贪婪增量策略 :每来一条新数据 xtx_txt,只优化增量拉格朗日成本 ΔL\Delta \mathcal{L}ΔL,决定这条新信息该合并、链接还是独立存储。
三层记忆结构:"笔记-关键词-主题"层级
为什么要搞三层?因为不同层级服务于不同的检索需求。
Layer 1:Notes(笔记层 / 保真层)
这是最底层的存储单元,每条 Note 包含四个部分:
- 原始观测 rir_iri(一字不漏的原文)
- 去噪上下文 cic_ici(LLM 提炼的干净语义)
- 密集嵌入 hi\mathbf{h}_ihi(向量表示)
- 关键词集合 Ki\mathcal{K}_iKi(符号锚点)
设计目标:尽可能保留原始观测的保真度,I(N;X)≈H(X)I(\mathcal{N}; X) \approx H(X)I(N;X)≈H(X)。
Layer 2:Keywords(关键词层 / 锚定层)
关键词是连接"连续向量空间"和"离散符号推理"的桥梁。为什么需要它?
向量检索有个老毛病:高维空间很稀疏,语义相近的向量可能离得很远。而关键词提供了一种分布鲁棒的特征空间------"张三"就是"张三",不管它出现在什么上下文里。
Layer 3:Topics(主题层 / 导航层)
主题是通过关键词共现关系聚合出来的高层语义质心。把记忆空间划分为若干可导航的区域,实现 O(1)O(1)O(1) 的宏观语义定位。
打个比方:如果说 Note 是书里的每一页内容,Keyword 是页码和索引词,那 Topic 就是目录章节。你要找某个知识点,先看目录定位到章节(Topic),再看索引定位到页码(Keyword),然后翻到那一页(Note)。
记忆构建:门控更新的"断舍离"
每来一条新信息 xtx_txt,MemFly 的处理流程:
第一步:语义摄入与去噪
把原始输入 xtx_txt 投影为结构化 Note nt=(rt,ct,ht,Kt)n_t = (r_t, c_t, \mathbf{h}_t, \mathcal{K}_t)nt=(rt,ct,ht,Kt)。其中 ctc_tct 是 LLM 去除噪声后的上下文------比如把"嗯嗯好的"之类的口水话清理掉。
第二步:门控结构更新
LLM 作为策略 Πθ\Pi_{\theta}Πθ,评估新 Note ntn_tnt 和已有 Note 的关系,产生两个分数:
- 冗余分数 sreds_{\text{red}}sred:这条新信息和旧信息有多重叠?
- 互补分数 scomps_{\text{comp}}scomp:这条新信息和旧信息有逻辑关联吗?
然后执行三种操作之一:
| 条件 | 操作 | 含义 | 对IB的作用 |
|---|---|---|---|
| sred>τms_{\text{red}} > \tau_msred>τm | Merge(合并) | 新旧信息高度重叠 | 最小化 I(X;M)I(X; M)I(X;M),消除冗余 |
| scomp>τls_{\text{comp}} > \tau_lscomp>τl | Link(链接) | 有逻辑/主题关联 | 保持 I(M;Y)I(M; Y)I(M;Y),建立推理路径 |
| 其他 | Append(追加) | 全新信息 | 扩展记忆覆盖范围 |
这个设计很巧妙:Merge 做减法(压缩),Link 做加法(建关系),Append 做保底(不遗漏)。三种操作恰好对应了信息瓶颈的两端优化。
第三步:主题演化
用 Leiden 算法对关键词共现图做社区检测,自动发现和更新 Topic 层级。Leiden 算法是 Louvain 算法的改进版,保证了社区划分的连通性,跑起来也更快。
记忆检索:三条路一起走
查询来了怎么找?MemFly 设计了三条并行的检索通路:
通路1:宏观语义定位(via Topics)
把查询解析出主题向量 htopic\mathbf{h}_{\text{topic}}htopic,和 Topic 质心做余弦相似度匹配,定位到相关的记忆区域,再从这些区域里捞出相关的 Note。
适合什么查询?"我们之前讨论过的那个投资策略"------这种模糊的、需要大范围扫描的问题。
通路2:微观符号锚定(via Keywords)
从查询里抽出关键实体,直接在关键词索引里精确匹配。
适合什么查询?"张三的电话号码是多少?"------这种指向明确、一跳就能到的问题。
通路3:拓扑扩展(via Related Edges)
从前两步的锚点出发,沿着 Link 边做一跳扩展,抓到向量距离远但逻辑上关联的证据。
适合什么查询?"张三推荐的那个人后来怎么样了?"------这种需要链式推理的多跳问题。
三条通路的结果用 **Reciprocal Rank Fusion(RRF)**融合。RRF 是信息检索领域常用的排名融合方法,公式很直观:
RRF(d)=∑r∈R1k+rankr(d)\text{RRF}(d) = \sum_{r \in R} \frac{1}{k + \text{rank}_r(d)}RRF(d)=r∈R∑k+rankr(d)1
每个文档在不同排名列表里的位置取倒数再求和,k 是平滑常数(通常取 60)。在多个列表里排名都靠前的文档得分最高。这比简单取交集或并集要稳健得多。
迭代证据细化(IER)
对于复杂查询,一轮检索可能不够。MemFly 引入了迭代细化机制:
- 拿到初始证据池 ε(0)\varepsilon^{(0)}ε(0)
- 判断证据是否充分------不够?生成子查询
- 用子查询再检索一轮,补充证据
- 重复直到满足条件或达到最大迭代次数 ImaxI_{\max}Imax
这个思路和 DeepResearch 类型的智能体很像------遇到回答不了的问题就自动分解、追问、补充证据。区别在于 MemFly 的检索对象是自己的结构化记忆,不是外部搜索引擎。
🧪 实验:打了谁?打赢了没?
实验设置
- 数据集:LoCoMo benchmark------专门评估 LLM 智能体长对话记忆能力的基准,来自 ACL 2024
- 五类查询:Multi-Hop(多跳推理)、Temporal(时间推理)、Open Domain(开放域)、Single Hop(单跳)、Adversarial(对抗干扰)
- 指标:F1(精确度与召回率的调和平均)、BLEU-1(词汇保真度)
- 对比方法:LoCoMo、ReadAgent、MemoryBank、MemGPT、A-MEM、Mem0
- 骨干模型:GPT-4o-mini、GPT-4o、Qwen3-8B、Qwen3-14B
主实验结果:闭源模型
| 方法 | GPT-4o-mini Avg F1 | GPT-4o-mini Avg BLEU | GPT-4o Avg F1 | GPT-4o Avg BLEU |
|---|---|---|---|---|
| MemFly | 32.11 | 24.48 | 35.89 | 29.24 |
| Mem-0 | 34.72 | 25.13 | 35.13 | 27.56 |
| A-mem | 27.02 | 20.09 | 32.86 | 23.76 |
| MemGPT | 26.65 | 17.72 | 30.36 | 22.83 |
| LoCoMo | 25.02 | 19.75 | 28.00 | 18.47 |
| ReadAgent | 9.15 | 6.48 | 14.61 | 9.95 |
| MemoryBank | 5.00 | 4.77 | 6.49 | 4.69 |
等等,GPT-4o-mini 上 Mem-0 的平均 F1 是 34.72,比 MemFly 的 32.11 还高?
仔细看各类别数据会发现,Mem-0 在 Multi-Hop 上拿了 45.93 的高分,但在 Single Hop 上只有 30.15。而 MemFly 在 Single Hop 上打出了 51.48,Adversarial 上也到了 43.76。MemFly 的优势在于各类查询上更均衡------不会在某一类上特别拉胯。
在 GPT-4o 上,MemFly 以 35.89 的平均 F1 稳坐第一。
主实验结果:开源模型
这组结果更能说明问题:
| 方法 | Qwen3-8B Avg F1 | Qwen3-8B Avg BLEU | Qwen3-14B Avg F1 | Qwen3-14B Avg BLEU |
|---|---|---|---|---|
| MemFly | 38.62 | 22.76 | 30.80 | 23.13 |
| A-mem | 24.30 | 16.90 | 21.36 | 14.98 |
| LoCoMo | 25.09 | 15.73 | 33.37 | 24.26 |
| Mem-0 | 23.04 | 19.74 | 20.98 | 16.27 |
| MemGPT | 22.13 | 13.44 | 24.12 | 15.41 |
| MemoryBank | 21.25 | 14.53 | 25.97 | 18.16 |
| ReadAgent | 13.17 | 9.30 | 13.16 | 9.61 |
Qwen3-8B 上的数据很亮眼:MemFly 拿到 38.62 的 F1,比第二名 LoCoMo(25.09)高出 13.5 个点,比 A-mem(24.30)高出 14.3 个点。这个差距大得惊人。
这说明什么?开源小模型的上下文推理能力相对较弱,而 MemFly 的结构化记忆组织(三层层级 + 门控更新)恰好补偿了这一短板。好的记忆架构可以让小模型也有不错的长期记忆表现。
不过 Qwen3-14B 上的故事不太一样------LoCoMo 反而以 33.37 略超 MemFly 的 30.80。可能的原因是 14B 模型的推理能力更强,能够从更冗余的原始数据中自行提取有用信息,结构化压缩的边际收益就小了。
消融实验:每个组件到底有多重要?
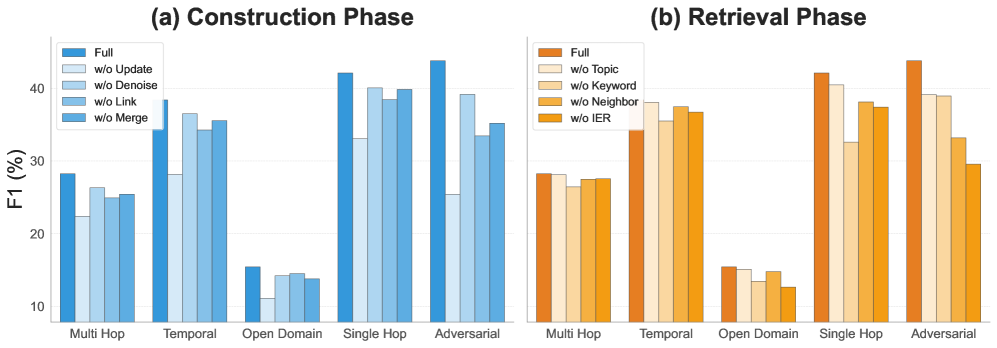
图2:消融实验。(a) 构建阶段各组件的贡献,(b) 检索阶段各组件的贡献。在 Qwen3-8B 上基于 LoCoMo 评估。
消融实验的数据非常清晰:
| 阶段 | 变体 | F1 | BLEU | Recall | Hit Rate |
|---|---|---|---|---|---|
| - | MemFly (Full) | 38.62 | 36.85 | 62.22 | 67.12 |
| 构建 | w/o Update | 27.97 | 27.10 | 42.11 | 48.20 |
| 构建 | w/o Denoise | 36.07 | 34.68 | 57.42 | 62.55 |
| 构建 | w/o Link | 33.57 | 32.35 | 53.19 | 56.18 |
| 构建 | w/o Merge | 34.79 | 33.62 | 54.85 | 59.42 |
| 检索 | w/o Topic | 36.79 | 34.66 | 53.30 | 58.91 |
| 检索 | w/o Keyword | 32.69 | 33.94 | 51.28 | 54.26 |
| 检索 | w/o Neighbor | 34.26 | 32.85 | 51.28 | 54.35 |
| 检索 | w/o IER | 32.94 | 30.86 | 46.29 | 51.26 |
几个关键发现:
1. 门控更新是命根子
去掉 Update(包含 Merge 和 Link),F1 从 38.62 暴跌到 27.97,跌了 10.65 个点。这是所有消融中影响最大的。没有门控更新,记忆就是一堆无组织的碎片------和简单堆叠原始数据没啥区别。
2. Link 比 Merge 更重要
去掉 Link(F1 降 5.05)比去掉 Merge(F1 降 3.83)的影响更大。这有点反直觉------你可能以为"合并冗余"是最关键的操作。但 Link 建立的关联边是多跳推理的基础设施,没有它,拓扑检索通路就瘫痪了。特别是在 Adversarial 类型查询中,Link 的缺失让模型更容易被干扰项误导。
3. 迭代证据细化(IER)影响深远
去掉 IER 后 Recall 从 62.22 跌到 46.29,Hit Rate 从 67.12 跌到 51.26。IER 对 Adversarial 和 Open Domain 类型查询的帮助最大------这些查询通常需要多轮检索才能凑齐完整证据。
4. Keyword 是 Single Hop 的命脉
从图2(b) 可以看到,去掉 Keyword 后 Single Hop 类别下降最明显。符号锚定对于"张三的电话多少"这种精确实体查询是不可替代的------向量检索在这种场景下反而不如关键词匹配靠谱。
💡 技术亮点与个人思考
亮点一:理论优美,落地务实
信息瓶颈理论在深度学习领域一直有争议------Tishby 2017年那个"DNN压缩阶段"的说法至今没有被广泛接受。但 MemFly 用它来指导记忆管理的设计决策(什么时候该压缩、什么时候该保留),这个应用场景倒是很贴切。而且它没有真的去算互信息(那在高维空间是 intractable 的),而是用 LLM 的判断力作为"无梯度优化器"来近似------这种理论指导 + 工程落地的结合方式很聪明。
亮点二:三层结构设计有章法
Note-Keyword-Topic 的三层结构不是随便拍脑袋想的,每层对应一种检索模式:
- Topic → 模糊语义匹配("大概是关于什么的")
- Keyword → 精确符号匹配("具体提到了谁")
- Note → 完整信息保真("原话怎么说的")
这和人类记忆的工作方式有异曲同工之处:你回忆某件事,脑子里先浮现大主题,接着想到关键人物或细节,再还原具体场景。
亮点三:混合检索 + 拓扑扩展
纯向量检索的问题在业界已经被吐槽很久了------语义相近不代表逻辑相关。MemFly 的拓扑扩展通路(沿着 Link 边做一跳扩展)是一个很实用的补充。这对于多跳推理场景("A 推荐了 B,B 后来做了 C")特别有用,因为 A 和 C 的向量表示可能毫无相似性,但通过关联边它们是可达的。
几个值得关注的问题
成本问题:每条新信息进来都要调 LLM 做去噪、评估冗余分数、评估互补分数。如果输入流很大(比如客服场景每天几万条对话),这个 LLM 调用成本不容小觑。论文没有报告每条信息的平均处理延迟和 token 消耗,这是工程落地时必须关注的。
β\betaβ 的选择 :信息瓶颈的 β\betaβ 参数控制压缩和相关性的平衡,但论文似乎没有详细讨论 β\betaβ 对性能的影响。在不同场景下(比如法律场景需要高保真、聊天场景可以多压缩),β\betaβ 的最优值可能差异很大。
Qwen3-14B 上的反常表现:MemFly 在 8B 上碾压对手,在 14B 上却输给了 LoCoMo,这暗示结构化记忆组织的收益和模型自身推理能力之间存在交互效应。模型越强,对记忆结构的依赖越低------这个现象值得后续研究深入探讨。
📊 与其他方法的横向对比
把 MemFly 和现有主流智能体记忆方案放在一起看:
| 维度 | MemFly | MemGPT | A-MEM | Mem0 |
|---|---|---|---|---|
| 理论基础 | 信息瓶颈 | 操作系统虚拟内存 | 自主记忆进化 | 动态记忆图 |
| 记忆结构 | Note-Keyword-Topic 三层 | Main/Archival 两层 | 自组织记忆块 | 图+向量混合 |
| 压缩策略 | 门控 Merge(有理论指导) | 基于规则的摘要 | LLM 自主决定 | 实体提取+去重 |
| 检索方式 | 三通路混合 + RRF + IER | 基于嵌入的搜索 | 语义检索 | 图遍历+语义 |
| 多跳推理 | ✅ 拓扑扩展 | ❌ | 部分支持 | ✅ 图遍历 |
| 理论保证 | 信息瓶颈最优性 | 无 | 无 | 无 |
MemFly 的核心差异化在于有理论支撑的压缩决策------不是随便压的,而是在信息瓶颈框架下的最优压缩。加上三层结构和三通路检索的全面设计,形成了一个相对完整的记忆管理体系。
🔧 工程落地建议
如果你想把 MemFly 的思路应用到自己的项目中,几个建议:
1. 三层结构可以按需裁剪
不是所有场景都需要三层。如果你的查询以精确实体匹配为主(比如客户信息查询),Keyword 层 + Note 层可能就够了。Topic 层更适合开放域、探索性的查询场景。
2. 门控更新的阈值需要调优
论文用的 τm=0.7\tau_m = 0.7τm=0.7(合并阈值)和 τl=0.5\tau_l = 0.5τl=0.5(链接阈值)。实际场景中,这两个值对最终效果影响很大。偏高会导致"不敢合并"、记忆膨胀;偏低会导致"合并过度"、信息丢失。建议在目标数据集上做网格搜索。
3. RRF 融合是低成本高回报的技巧
即使不用 MemFly 的完整框架,单独把 RRF 加到你的 RAG 系统里(融合向量检索和关键词检索的结果)通常就能提升几个点。实现简单,效果稳定。
4. 考虑分级调用 LLM
门控更新中的冗余/互补判断可以用小模型(如 Qwen3-8B)来做,不一定非要上 GPT-4o。毕竟判断"这两段话是否重复"不需要太强的推理能力。
📝 总结
MemFly 做了一件很漂亮的事:把信息瓶颈这个经典理论从信息论搬到了 LLM 智能体的记忆管理中。三层分层结构(Note-Keyword-Topic)、门控更新机制(Merge/Link/Append)、三通路混合检索加迭代细化------每个设计都有明确的理论动机和实证支撑。
在 LoCoMo 基准上,MemFly 在多个骨干模型上都展现了竞争力,尤其在开源小模型(Qwen3-8B)上的优势非常突出------F1 比第二名高了 13+ 个点。这说明好的记忆架构可以显著弥补模型推理能力的不足。
不过也别忘了它的局限:LLM 调用成本、β\betaβ 参数敏感性、以及在更强模型上边际收益递减的现象。这些都是后续工作值得探索的方向。
记忆管理是智能体走向真正"长期自主"的关键基础设施。MemFly 用信息瓶颈给出了一个理论上优雅、工程上可行的方案,为这个方向提供了一个不错的参照系。
🔗 相关资源
- 论文:https://arxiv.org/abs/2602.07885
- LoCoMo Benchmark:https://github.com/snap-research/LoCoMo
- 信息瓶颈理论原始论文:Tishby et al., "The Information Bottleneck Method", 1999