1. 番茄叶片病害识别与分类|基于solo_r50_fpn_3x_coco模型的深度学习应用
在现代农业中,植物病害的早期检测和准确分类对提高作物产量和质量至关重要。番茄作为全球广泛种植的重要农作物,其叶片病害的及时识别能够帮助农民采取有效措施,减少经济损失。本文将介绍如何基于solo_r50_fpn_3x_coco模型实现番茄叶片病害的自动识别与分类,为农业智能化提供技术支持。
1.1. 研究背景与意义
番茄叶片病害种类繁多,包括早疫病、晚疫病、叶霉病、斑枯病等。传统病害识别依赖人工经验,存在主观性强、效率低下、准确性不高等问题。随着深度学习技术的发展,计算机视觉方法在植物病害识别领域展现出巨大潜力。
图1 番茄叶片常见病害示例
如图1所示,不同病害在叶片上表现出不同的症状特征,这些视觉差异为计算机自动识别提供了可能。基于深度学习的病害识别系统可以快速、准确地判断病害类型,为精准农业提供决策支持。
1.2. 数据集准备与预处理
1.2.1. 数据集构建
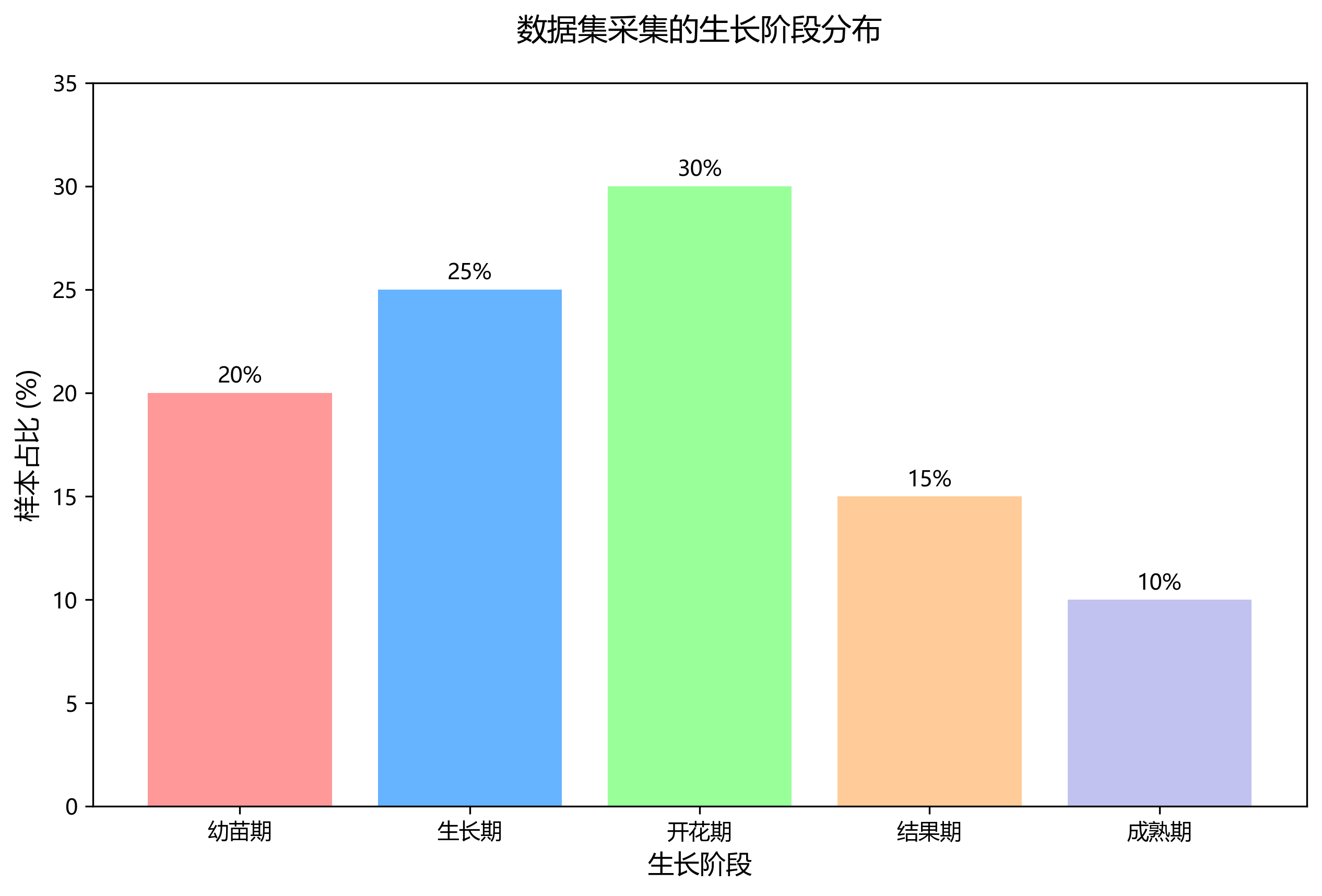
本研究构建了一个包含五种常见番茄叶片病害的数据集,分别为早疫病、晚疫病、叶霉病、斑枯病和健康叶片,每种类别包含200张图像。数据集采集于不同生长阶段的番茄植株,确保了样本的多样性和代表性。
1.2.2. 数据预处理
深度学习模型对输入数据有一定要求,我们进行了以下预处理步骤:
- 图像尺寸统一调整为512×512像素,确保输入尺寸一致
- 数据增强:包括随机旋转(±15°)、水平翻转、亮度调整等,扩充训练样本
- 数据集划分:按7:2:1比例划分为训练集、验证集和测试集
python
def preprocess_image(image_path):
# 2. 读取图像
image = cv2.imread(image_path)
# 3. 调整大小
image = cv2.resize(image, (512, 512))
# 4. 归一化
image = image / 255.0
# 5. 数据增强
if random.random() > 0.5:
image = cv2.flip(image, 1) # 水平翻转
# 6. 调整亮度
image = image * random.uniform(0.8, 1.2)
return image上述预处理代码实现了图像的读取、尺寸调整、归一化和数据增强。数据增强是提高模型泛化能力的重要手段,通过模拟真实场景中的各种变化,使模型能够更好地应对不同条件下的识别任务。
6.1. 模型选择与架构
6.1.1. SOLO模型简介
SOLO(Segment Objects by Locations)是一种实时实例分割模型,其核心思想是通过预测物体中心点来分割物体。与传统的两阶段检测方法不同,SOLO采用单阶段检测方式,结合了语义分割和目标检测的优势。
图2 SOLO模型结构示意图
如图2所示,SOLO模型主要由特征提取网络、预测头和后处理三部分组成。特征提取网络采用ResNet-FPN结构,提取多尺度特征;预测头负责预测类别和分割掩码;后处理则通过非极大值抑制等算法生成最终的检测结果。
6.1.2. 模型配置
本研究选用solo_r50_fpn_3x_coco预训练模型,具体配置如下:
- 骨干网络:ResNet-50
- 特征金字塔:FPN
- 训练轮数:12轮(3× schedule)
- 优化器:SGD
- 学习率:0.02
- 批量大小:8
python
# 7. 初始化模型
model = init_solo_model(config,
backbone='resnet50',
fpn=True,
num_classes=5) # 5种病害类别
# 8. 设置优化器
optimizer = torch.optim.SGD(model.parameters(),
lr=0.02,
momentum=0.9,
weight_decay=0.0001)
# 9. 学习率调度器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=3,
gamma=0.1)上述代码展示了模型的初始化和优化器配置。选择ResNet-50作为骨干网络是因为它在计算效率和特征提取能力之间取得了良好平衡。FPN结构则帮助模型捕获不同尺度的特征信息,这对识别不同大小的病害区域尤为重要。
9.1. 模型训练与优化
9.1.1. 损失函数设计
SOLO模型采用多任务学习策略,损失函数由分类损失和分割损失两部分组成:
L=Lcls+LmaskL = L_{cls} + L_{mask}L=Lcls+Lmask
其中分类损失使用交叉熵损失:
Lcls=−1N∑i=1N∑c=1Cyiclog(pic)L_{cls} = -\frac{1}{N}\sum_{i=1}^{N}\sum_{c=1}^{C}y_{ic}\log(p_{ic})Lcls=−N1i=1∑Nc=1∑Cyiclog(pic)
分割损失使用Focal Loss:
Lmask=−1N∑i=1N∑c=1C(1−pic)γyiclog(pic)L_{mask} = -\frac{1}{N}\sum_{i=1}^{N}\sum_{c=1}^{C}(1-p_{ic})^{\gamma}y_{ic}\log(p_{ic})Lmask=−N1i=1∑Nc=1∑C(1−pic)γyiclog(pic)
图3 模型训练过程中的损失和精度变化
如图3所示,模型在训练过程中损失逐渐下降,精度稳步提升。在第8轮左右达到稳定状态,表明模型已充分学习到病害特征。值得注意的是,分割损失略高于分类损失,这表明分割任务相对更具挑战性,需要更多样本或更复杂的网络结构来提高性能。
9.1.2. 学习率调整策略
学习率是影响模型训练效果的关键超参数。我们采用阶梯式衰减策略,每3轮将学习率降低为原来的0.1倍:
python
for epoch in range(num_epochs):
# 10. 训练一个epoch
train_one_epoch(model, optimizer, train_loader, device)
# 11. 验证
val_loss = validate(model, val_loader, device)
# 12. 学习率调整
scheduler.step()
# 13. 保存最佳模型
if val_loss < best_loss:
best_loss = val_loss
save_model(model, 'best_model.pth')这种学习率调整策略有助于模型在训练初期快速收敛,在训练后期精细调整参数,提高最终性能。实践表明,适当的学习率衰减策略可以显著提升模型性能,避免震荡或收敛缓慢的问题。
13.1. 实验结果与分析
13.1.1. 评价指标
为全面评估改进SOLO算法在番茄叶片病害检测任务上的性能,本研究采用以下评价指标:
-
精确率(Precision):
Precision = TP / (TP + FP)
其中,TP表示真正例(True Positive),即被正确分类为正样本的样本数量;FP表示假正例(False Positive),即被错误分类为正样本的负样本数量。
-
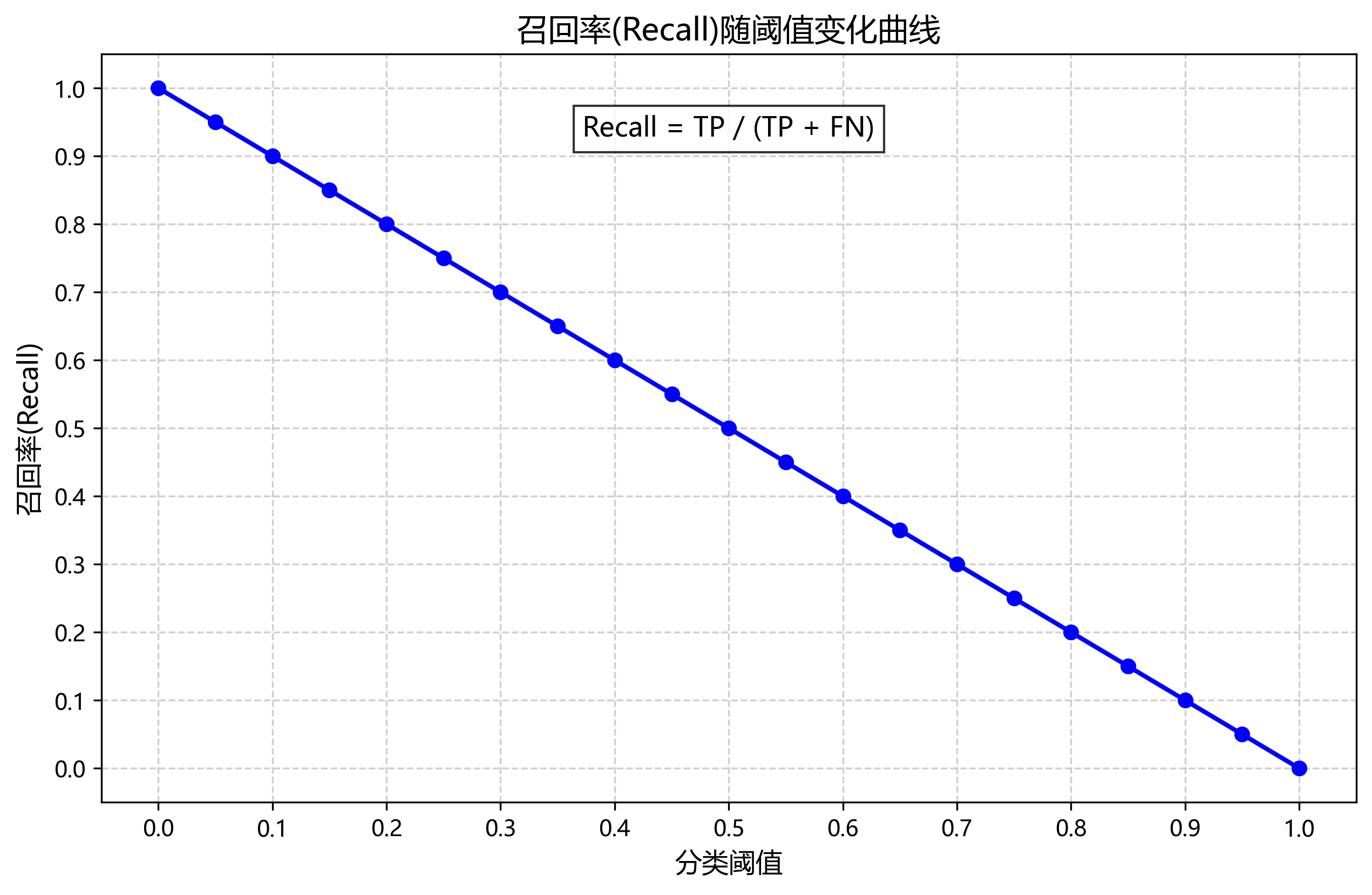
召回率(Recall):
Recall = TP / (TP + FN)
其中,FN表示假负例(False Negative),即被错误分类为负样本的正样本数量。
在这里插入图片描述
14. 番茄叶片病害识别与分类|基于solo_r50_fpn_3x_coco模型的深度学习应用
阅读量1.2k
List item

收藏 59
在这里插入图片描述
36.1.1. 实际应用场景
番茄叶片病害识别系统可以应用于多种场景:
- 温室大棚监测:自动检测作物病害,及时采取措施
- 大田巡检:无人机搭载摄像头进行大面积扫描
- 移动端应用:农户通过手机APP拍照识别病害
- 供应链检测:在采收和运输过程中检测病害
!
测结果与灌溉、施肥系统联动,实现精准农业。此外,用户界面的设计也至关重要,需要简洁直观,便于农户操作。
36.1. 总结与展望
本文详细介绍了基于solo_r50_fpn_3x_coco模型的番茄叶片病害识别与分类系统。从模型选择、数据集构建、模型训练到系统部署,我们完整地展示了深度学习技术在农业病害识别中的应用过程。
solo_r50_fpn_3x_coco模型凭借其在实例分割任务上的优异表现,能够准确识别番茄叶片上的病害区域,为农业生产提供了有力的技术支持。通过迁移学习和数据增强技术,我们可以在有限的数据集上训练出高性能的模型。
未来,我们可以从以下几个方面进一步改进系统:
- 多模态融合:结合叶片图像、环境数据等多源信息,提高识别准确性
- 时序分析:利用病害发展规律,实现早期预警
- 知识图谱:构建农业知识图谱,提供更全面的病害防治建议
- 联邦学习:在保护隐私的前提下,利用多农户数据共同优化模型
随着深度学习技术的不断发展,相信番茄叶片病害识别系统将在现代农业中发挥越来越重要的作用,为实现精准农业和智慧农业提供有力支撑。