一、LSTM模型
概念
LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是传统RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象 ,处理长序列数据效果差的问题。同时LSTM的结构更复杂
传统RNN 各种求导、偏导累乘。有可能导致 梯度值 极大或者极小,梯度爆炸,LSTM并没有彻底解决。
LSTM内部结构分析
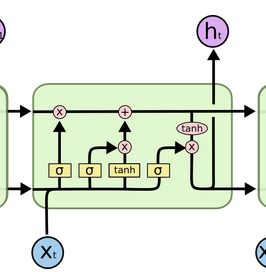
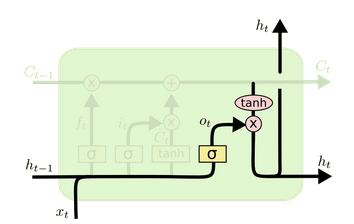
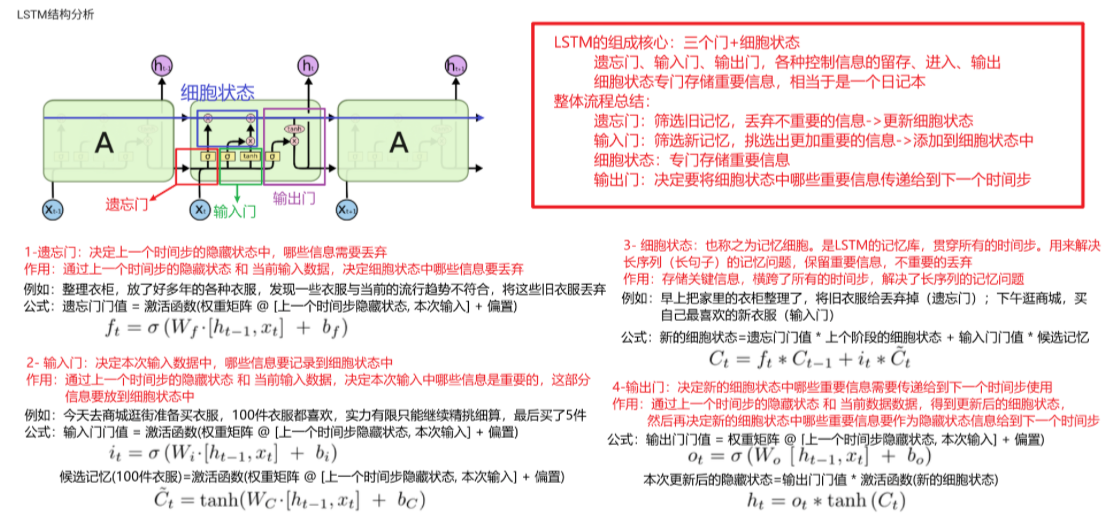
LSTM由四个部分组成
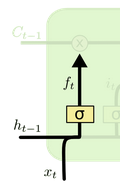
- 遗忘门
决定上一个时间步输出的细胞状态中,哪些内容需要丢弃掉
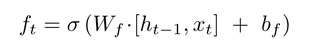
- 输入门
当前输入的数据中,哪些要记录到细胞状态中
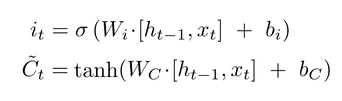
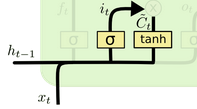
- 细胞状态
是 LSTM 的记忆库,贯穿整个序列,用来解决长序列记忆问题
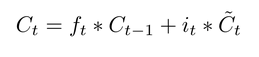
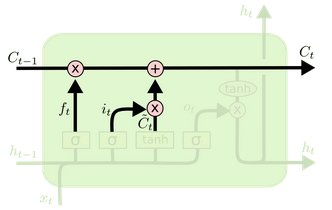
- 输出门
决定本次隐藏状态要输出哪些信息
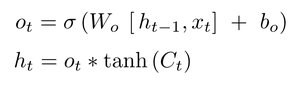
代码
python
import torch
import torch.nn as nn
def demo():
# 1.创建LSTM网络结构
"""
参数1: 输入词向量的维度
参数2:隐藏层的维度
参数3:LSTM 的层数
参数4: bidirectional 是否开启双向LSTM
False 表示 LSTM
True 表示 Bi-LSTM
"""
lstm = nn.LSTM(
input_size=4,
hidden_size=5,
num_layers=1,
bidirectional=False
)
# 2. 准备输入层数据
"""
input 形状
【seq_len 单句子词的个数, batch_size 句子个数, input_size 向量维度】
"""
input = torch.randn(6, 3, 4)
"""
h0 形状
【num_layers LSTM层数, batch_size 句子个数, hidden_size 隐藏层维度】
隐藏状态 和 细胞状态 的张量形状是相同的
实际工作中,一般对隐藏状态 和 细胞状态全都使用全0初始化
"""
h0 = torch.zeros(1, 3, 5)
c0 = torch.zeros(1, 3, 5)
# 3. 调用LSTM
"""
API:
>>> output, (hn, cn) = rnn(input, (h0, c0))
output 形状
[seq_len, batch_size, hidden_size]
hn 形状 跟h0 一致
[num_layers, batch_size, hidden_size]
"""
output, (hn,cn) = lstm(input, h0, c0)
if __name__ == '__main__':
demo()结构总结
LSTM 核心:三门 + 细胞状态
遗忘门、输入门、输出门,各种控制信息的留存、进入、输出
细胞状态专门存储重要信息,相当于日记本
① 遗忘门:筛选旧记忆,丢弃不重要的信息 -> 更新细胞状态
② 输入门:筛选新几亿,挑选出更加重要的信息 -> 添加到细胞状态中
③ 细胞状态:存储
④ 输出门: 决定要讲细胞状态中哪些重要信息传递给下一个时间步
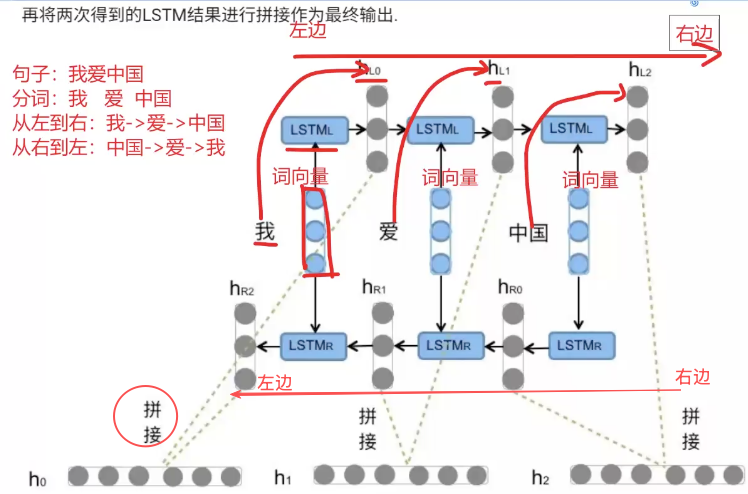
BI-LSTM
Bi-LSTM即双向LSTM, 它没有改变LSTM本身任何的内部结构, 只是将LSTM应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出.
模型参数和计算复杂度也随之增加了一倍
直接举例
LSTM总结
优点:
-
能够处理更长的句子
-
缓解梯度消失或爆炸的问题 -> 训练更稳定.
-
能够抓取复杂的特征.
缺点:
-
计算慢, 消耗资源大.
-
调参相对较难.
-
可解释性稍差.
二、GRU模型
概念
GRU(Gated Recurrent Unit)也称门控循环单元结构, 它也是传统RNN的变体, 同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象 . 同时它的结构和计算要比LSTM更简单
GRU核心结构
更新门
重置门
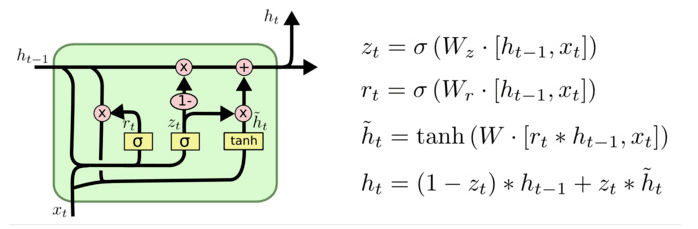
内部结构原理

代码
和RNN代码一致。把RNN改为GRU
python
import torch.nn as nn
import torch
def gru_init():
"""
定义数据
batch_size: 3个句子,
seq_len: 每个句子 4个词 (时间步数)
input_size: 每个词的向量维度 5
"""
x = torch.randn(size=(3, 4, 5)) #(batch_size, seq_len, input_size)
"""
定义ho 初始值 全0
num_layers: GRU层数 默认1 层
batch_size: 3 个句子
hidden_size : 6 个隐藏层维度
"""
h0 = torch.zeros(size=(1, 3, 6)) #(num_layers, batch_size, hidden_size)
gru = nn.GRU(input_size=5, #输入数据的向量维度,也就是词的向量维度 embed_dim
hidden_size=6, #隐藏状态向量维度
num_layers=1, #隐藏层GRU的层数
batch_first=True) #输入/输出张量的0轴是否为batch轴,默认为False, 设为True时,输入和输出张量的0轴为batch轴
output, hn = gru(x, h0)
"""
输出 output 的形状是 (batch_size, seq_len, hidden_size)
隐藏状态 hn 的形状是 (num_layers, batch_size, hidden_size)
"""
print(f'{output.shape} \n')
print(f'{hn.shape} \n')
print(f'output last: {output[...,-1,:][-1]} \n')
print(f'hn last: {hn[...,-1,:][-1]} \n')
print(f'输出层的最后一个值 output last 和 隐藏层的最后一个值 相同h0 last')
if __name__ == '__main__':
gru_init()总结
对比LSTM,GRU优点:
① LSTM内部有三个门+1个细胞状态,复杂,运行效率低,调参麻烦,容易过拟合
② GRU 是讲LSTM中细胞状态的功能,直接使用隐藏状态ht
③ 使用推荐
<1> 追求运行效率,推荐GRU
<2> 倾向于准确率,推荐LSTM