神经网络的学习
在神经网络中,为了让模型能够准确进行预测,我们需要利用优化算法不断迭代权重,使衡量预测值与真实值差异的损失函数降至极小值。本篇内容将完整梳理神经网络中基于梯度下降的学习和训练全流程。
一.梯度下降中的两个关键问题
回顾:梯度向量
梯度向量是多元函数上,各个自变量的偏导数组成的向量,比如损失函数是L(w1,w2,b)L(w_1, w_2, b)L(w1,w2,b),在损失函数上对w1,w2,bw_1, w_2, bw1,w2,b这三个自变量求偏导数,求得的梯度向量的表达式就是∂L∂w1,∂L∂w2,∂L∂bT\\frac{\\partial L}{\\partial w_1}, \\frac{\\partial L}{\\partial w_2}, \\frac{\\partial L}{\\partial b}^T∂w1∂L,∂w2∂L,∂b∂LT,简写为gradL(w1,w2)grad L(w_1, w_2)gradL(w1,w2)或者∇L(w1,w2)\nabla L(w_1, w_2)∇L(w1,w2)。
在优化流程中,一旦给定一组权重 www,结合数据中的特征张量 XXX 和真实标签 yyy,就能计算出具体的损失函数数值。梯度下降的核心就是在以 www 为横坐标、L(w)L(w)L(w) 为纵坐标的图像上,从初始随机设定的权重 w(0)w_{(0)}w(0) 开始,逐步向下寻找损失函数的最小值。
在此过程中存在两个最关键的问题:
1.怎么找出梯度向量的方向和大小?
2.怎么让坐标点按照梯度向量的反方向移动?
1.找出梯度向量的方向和大小
- 梯度的定义: 梯度向量是多元函数上,各个自变量的偏导数组成的向量,例如损失函数 L(w1,w2)L(w_1, w_2)L(w1,w2) 的梯度可简写为 ∇L(w1,w2)\nabla L(w_1, w_2)∇L(w1,w2)。
- 计算依赖: 梯度的大小(模长)和方向对于每个具体的坐标点而言都是独一无二的,必须将当前点的坐标值代入偏导数表达式中才能计算得出。
- 核心难点: 求解过程的最大难点在于如何获取复杂的损失函数对各个自变量(权重)求偏导后的数学表达式。
2.让坐标点移动起来(进行一次迭代)
- 移动逻辑: 找出当前点的梯度向量后,让坐标点向其"反方向"移动与梯度向量大小相等的距离,以此不断逼近极小值。
- 权重迭代公式: w(t+1)=w(t)−η∂L∂ww_{(t+1)} = w_{(t)} - \eta \frac{\partial L}{\partial w}w(t+1)=w(t)−η∂w∂L
- 步长的作用: 公式中的 η\etaη 代表步长(或学习率),用于控制每次移动距离的大小。偏导数前的减号决定了移动方向为梯度的反方向。
二.找出距离和方向:反向传播
1.反向传播的定义与价值
- 复杂网络的求导困境: 单层神经网络的导数还可以强行推导,但在多层深度网络中,嵌套的函数极多,逐个直接令导数为0或强行求导的工作量是无法想象的。
- 链式法则的引入: 反向传播算法利用高等数学中的"链式法则" ∂u∂w=∂u∂z∗∂z∂w\frac{\partial u}{\partial w} = \frac{\partial u}{\partial z} * \frac{\partial z}{\partial w}∂w∂u=∂z∂u∗∂w∂z,成功实现了复杂网络求导的简单化。
- 反向传播的本质: 在计算图中,从左向右计算出各节点张量的值称为"正向传播"。而反向传播则是"从右向左"(从输出层向输入层),不断复用正向传播中已经计算好的元素,逐步向前求解梯度表达式的方法。
2.PyTorch实现反向传播
在 PyTorch 中,极其复杂的求导过程可以通过底层自动微分机制一键完成。
- 核心方法: 对于深层神经网络,直接使用 PyTorch 提供的
loss.backward()即可对损失函数求取全部 www 的梯度。 - 前置条件: 在调用
backward()之前,必须先实例化模型,完成一次正向传播得到预测值,并通过损失函数类计算出loss标量。 - 提取梯度: 执行反向传播后,可以通过
net.linear1.weight.grad查看对应权重层计算出的具体梯度值。 - 计算图与叶子节点:
backward()只会为requires_grad=True的叶子节点(通常是网络自动生成的权重)计算梯度。
三.移动坐标点 - 动量法(Momentum)
1.走出第一步
- 基础迭代: 获取梯度(
dw)后,通过自定义的步长(lr),可以直接对权重执行扣减:w -= lr * dw。 - 基础梯度的局限: 普通的梯度下降速度非常缓慢,因为每次只能走一小步,如果步长设置过大又容易跳过真正的最小值。
2.从第一步到第二步:动量法(Momentum)
-
思想:传统梯度下降像是一个没有记忆的盲人。如果长期保持向同一个方向移动,小步慢走是浪费计算资源的,应该大胆迈出大步。
-
动量的原理: 将上一步的梯度向量与当前的梯度向量(的反方向)以"加权求和"的方式结合,得出受历史动量影响的"真实下降方向"。
-
**迭代公式: **
v(t)=γv(t−1)−η∂L∂wv_{(t)} = \gamma v_{(t-1)} - \eta \frac{\partial L}{\partial w}v(t)=γv(t−1)−η∂w∂L
w(t+1)=w(t)+v(t)w_{(t+1)} = w_{(t)} + v_{(t)}w(t+1)=w(t)+v(t)
-
动量参数 γ\gammaγ: 也叫做衰减力度,历史累计动量能够加速方向一致的迭代,并减小方向不一致时的震荡,这被称为动量法(Momentum)。
在第一步中,没有历史梯度方向,因此第一步的真实方向就是起始点梯度的反方向,v0=0v_0 = 0v0=0。其中v(t−1)v_{(t-1)}v(t−1)代表了之前所有步骤所累积的动量和。在这种情况下,梯度下降的方向有了"惯性",受到历史累计动量的影响,当新坐标点的梯度反方向与历史累计动量的方向一致时,历史累计动量会加大实际方向的步子,相反,当新坐标点的梯度反方向与历史累计动量的方向不一致时,历史累计动量会减小实际方向的步子。
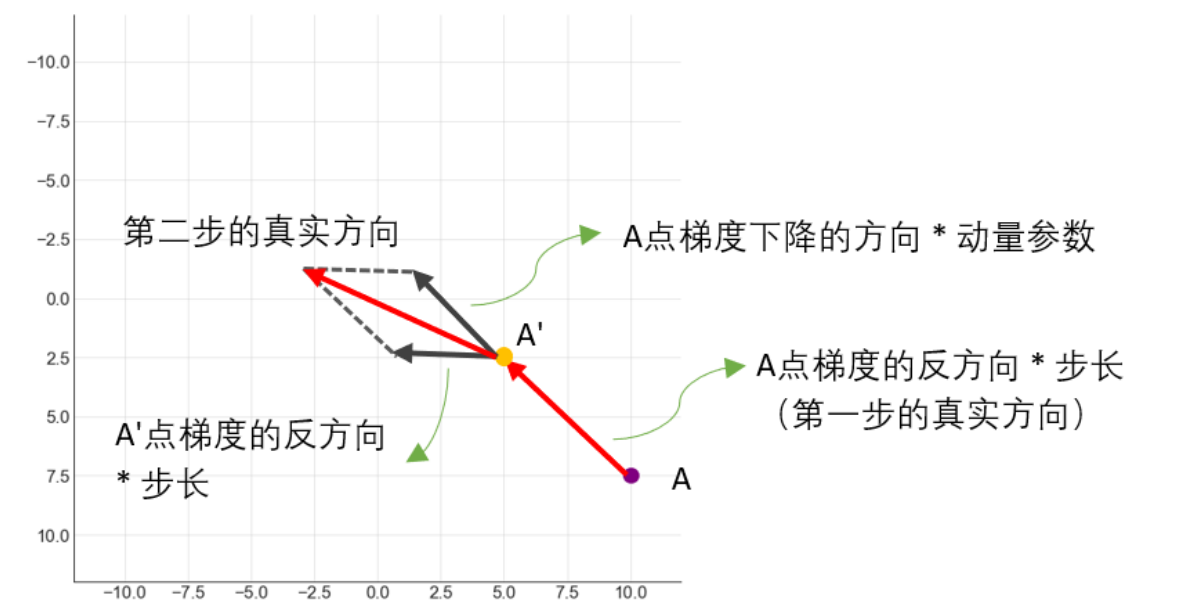
-
代码示例:
假设我们有500条数据,20个特征,标签为3分类。我们现在要实现一个三层神经网络,这个神经网络的架构如下:第一层有13个神经元,第二层有8个神经元,第三层是输出层。其中,第一层的激活函数是relu,第二层是sigmoid。
python# 简单动量法代码表示,不是完整神经网络学习代码 import torch import torch.nn as nn import torch.nn.functional as F class Model(nn.Module): def __init__(self,in_features=10, out_features=2): """ in_features: 输入该神经网络的特征数目(输入层上的神经元的数目) out_features:神经网络的输出的数目(输出层上的神经元的数目) """ # 1. 重点:必须继承父类的初始化方法! super().__init__() # 2. 定义网络的各个层 (此时并不执行计算,只是声明有这些组件) self.linear1 = nn.Linear(in_features,13,bias=False) self.linear2 = nn.Linear(13,8,bias=False) self.output = nn.Linear(8,out_features,bias=True) def forward(self,x): #神经网络的向前传播 # 3. 定义数据x的流向和激活过程 sigma1 = torch.relu(self.linear1(x)) sigma2 = torch.sigmoid(self.linear2(sigma1)) zhat = self.output(sigma2) return zhat # 4. 实例化模型并进行前向传播和反向传播 # 假设我们有500条数据,20个特征,标签为3分类。 X = torch.rand((500,20),dtype=torch.float32)*100 #防止X经过sigmod后数值太小,乘不乘100都行 y = torch.randint(low = 0,high=3,size=(500,),dtype=torch.float32) input_ = X.shape[1] #输入层神经元个数,即特征数量 output_ = len(y.unique()) #对y中内容去重,得到标签一共有几类 torch.random.manual_seed(420) # 实例化模型 net = Model(in_features=input_,out_features=output_) # 前向传播 zhat = net(X) # 定义损失函数 criterion = nn.CrossEntropyLoss() loss = criterion(zhat,y.long()) loss.backward(retain_graph=True) # 定义学习率 lr = 0.1 # 定义动量参数 gama = 0.9 # 一次迭代 w = net.linear1.weight.data dw = net.linear1.weight.grad # v(t) = gama * v(t-1) - lr * dw # w(t+1) = w(t)+ v(t) v = torch.zeros_like(dw) v = gama * v - lr * dw w += v
3. optim.SGD类 - 随机梯度下降优化器
PyTorch 提供了 torch.optim 模块,专门用于实现包括带动量在内的各类优化算法。
optim.SGD类是optim.Optimizer类的子类
(1). optim.SGD类类型
作用:
optim.SGD 是 PyTorch 中用于实现随机梯度下降(Stochastic Gradient Descent)及其变体(如带有动量的 SGD)的核心优化器。它的核心作用是根据反向传播计算出的梯度(.grad)自动更新神经网络的参数。使用这个类,我们不需要再手动编写像 w = w - lr * dw 这样的参数更新代码,也不需要手动维护动量矩阵(如你之前代码中手动定义的 v),PyTorch 会在底层安全、高效地替我们完成所有可学习参数的迭代更新。
python
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)参数:
- 待优化参数 (params):这是一个可迭代对象,包含了所有需要被优化器更新的参数(通常直接传入
model.parameters())。优化器只会更新这里面包含的且requires_grad=True的张量。 - 学习率 (lr):即我们在数学公式中常说的步长 η\etaη (float类型)。它控制了每次参数更新的幅度。这是必填参数,深度学习中最核心的超参数之一。
- 动量因子 (momentum):即你之前在手写代码中定义的
gama参数 (float类型,默认为0)。设置为大于0的值(如 0.9)即可开启物理动量机制,加速收敛并减少震荡。 - 权重衰减 (weight_decay):即 L2 正则化惩罚系数 (float类型,默认为0)。用于防止模型过拟合,它会在每次更新时让权重按比例微微缩小。
核心属性 (Attributes):
实例化 optim.SGD 后,可以通过以下属性查看优化器的内部状态:
.param_groups:一个包含了所有参数组的列表(list)。每个组是一个字典(dict),里面存储了这组参数的张量列表以及对应的学习率、动量等超参数。.state:一个字典,保存了优化器的状态信息。当你开启了momentum时,这里面就隐式地存储了所有参数对应的历史累计动量矩阵(相当于底层自动维护了你的v = torch.zeros_like(dw))。
理论与底层代码的对齐 (极其重要):
在基础理论中,梯度下降的参数更新公式为:
wt+1=wt−η⋅∇L(wt)w_{t+1} = w_t - \eta \cdot \nabla L(w_t)wt+1=wt−η⋅∇L(wt)
如果在 PyTorch 中手动实现,我们会写成 w.data = w.data - lr * w.grad。但在底层,为了避免破坏计算图并最大化内存效率,optim.SGD 会调用张量的原地操作(例如 sub_() 或 add_()),并自动在 torch.no_grad() 的上下文中执行更新,确保参数更新这一步不会被记录到反向传播的历史图(计算图)中。
补充:
虽然它的名字叫"随机"梯度下降(SGD),但在 PyTorch 中,只要你传入的损失
loss是基于一个 Batch 的数据计算出来的,它实际上执行的就是小批量梯度下降(Mini-batch Gradient Descent)。
(2). zero_grad() 与 step() - 实例调用(执行清零与更新)
作用:优化器与网络层不同,它并不通过 __call__ 执行。它最核心的工作流依赖于两个方法相互配合:
zero_grad():在每一轮(epoch/batch)计算新的梯度之前,必须调用此方法清空前一轮残留的梯度。如果不清空,PyTorch 默认会将新计算的梯度与旧梯度累加。step():在调用了loss.backward()产生新的.grad之后,调用此方法执行一次参数更新。
python
# 每次迭代的标准工作流三部曲
optimizer.zero_grad() # 1. 梯度清零
loss.backward() # 2. 反向传播,计算并填充 .grad
optimizer.step() # 3. 根据计算出的 .grad 更新模型参数参数:
- 两者在日常使用中通常不需要传入任何参数。
返回值:
- 两者均无返回值 (None),它们通过直接修改底层参数张量的值(原地修改)来生效。
示例:
python
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 准备假数据和模型
X = torch.tensor([[1., 2.],
[3., 4.]])
y = torch.tensor([[1.], [0.]])
model = nn.Linear(in_features=2, out_features=1)
criterion = nn.MSELoss()
# 2. 实例化优化器,把模型的参数交给它管理,设置学习率和动量
# 相当于替代了你之前手写的 lr=0.1, gama=0.9 逻辑
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
print("更新前的权重:", model.weight.data)
#更新前的权重:tensor([[-0.4281, -0.5816]])
# 3. 标准训练循环的三部曲
# 第一步:清空上一步的残余梯度 (第一步其实是0,但保持习惯很重要)
optimizer.zero_grad()
# 前向传播与损失计算
z_hat = model(X)
loss = criterion(z_hat, y)
# 第二步:反向传播,此时 model.weight.grad和model.bias.grad被填充了值
loss.backward()
# 第三步:优化器执行参数更新
# 底层自动执行: w = w - lr * dw (加上了动量逻辑)
optimizer.step()
print("\n更新后的权重:", model.weight.data)
#更新后的权重: tensor([[0.9275, 1.4009]])(3).单轮迭代的标准范式:
-
执行
net.forward(X)进行正向传播。 -
使用
criterion(zhat, y)计算损失。 -
执行
opt.zero_grad()清空梯度。 -
调用
loss.backward()反向传播求解梯度。 -
通过
opt.step()更新权重。
四.开始迭代:batch_size与epoches
1.小批量随机梯度下降(Mini-batch)
小批量随机梯度下降是深度学习入门级的优化算法(梯度下降是入门级之下的),其求解与迭代流程与传统梯度下降(GD)基本一致,不过二者在迭代权重时使用的数据这一点上存在巨大的不同。传统梯度下降在每次进行权重迭代(即循环)时都使用全部数据,每次迭代所使用的数据也都一致。而mini-batch SGD是每次迭代前都会从整体采样一批固定数目的样本组成批次(batch) BBB,并用 BBB 中的样本进行梯度计算,以减少样本量。如果每次只用一个数据,即batch=1,叫作随机梯度下降(SGD)。
-
为什么会选择mini-batch SGD作为神经网络的入门级优化算法呢?
有两个比较主流的原因:
-
比起传统梯度下降,mini-batch SGD更可能找到全局最小值。
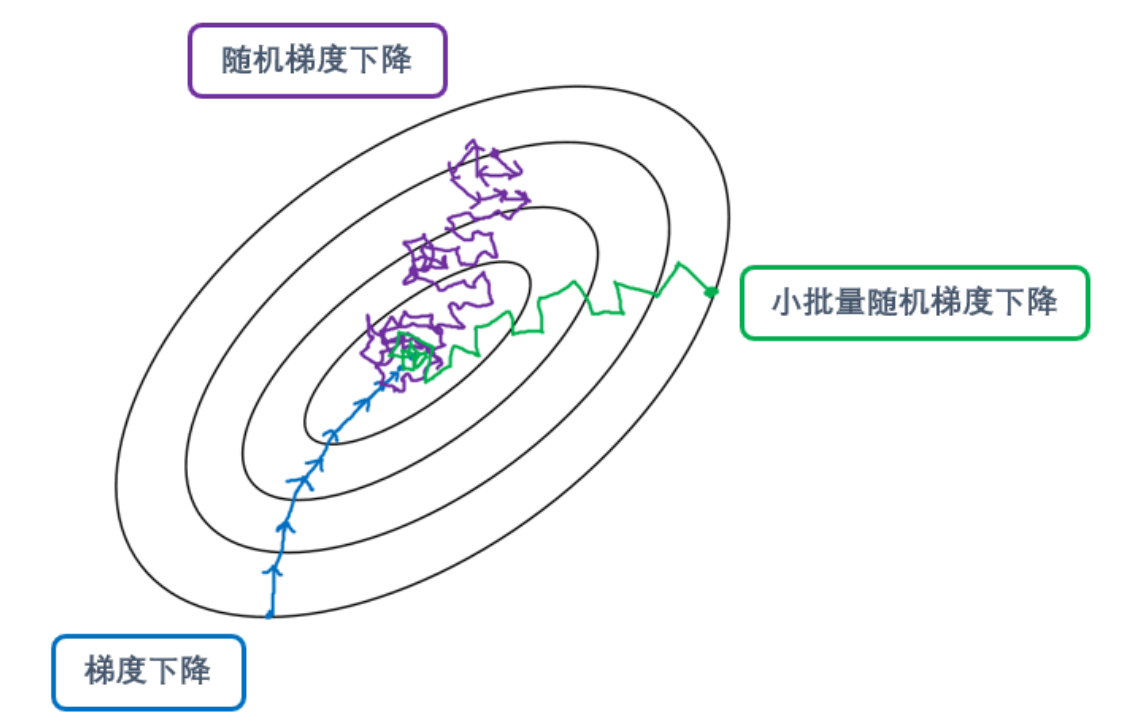
传统梯度下降是每次迭代时都使用全部数据的梯度下降,所以每次使用的数据是一致的,因此梯度向量的方向和大小都只受到权重 的影响,所以梯度方向的变化相对较小,很多时候看起来梯度甚至是指向一个方向(如上图所示)。这样带来的优势是可以使用较大的步长,快速迭代直到找到最小值。但是缺点也很明显,由于梯度方向不容易发生巨大变化,所以一旦在迭代过程中落入局部最优的范围,传统梯度下降就很难跳出局部最优,再去寻找全局最优解了。
而mini-batch SGD在每次迭代前都会随机抽取一批数据,所以每次迭代时带入梯度向量表达式的数据是不同的,梯度的方向同时受到系数 www,bbb 和带入的训练数据的影响,因此每次迭代时梯度向量的方向都会发生较大变化。并且,当抽样的数据量越小,本次迭代中使用的样本数据与上一次迭代中使用的样本数据之间的差异就可能越大,这也导致本次迭代中梯度的方向与上一次迭代中梯度的方向有巨大差异。所以对于mini-batch SGD而言,它的梯度下降路线看起来往往是曲折的折线(如上图所示)。
极端情况下,当我们每次随机选取的批量中只有一个样本时,梯度下降的迭代轨迹就会变得异常不稳定(如上图所示)。我们称这样的梯度下降为随机梯度下降(stochastic gradient descent, SGD)。
mini-batch SGD的优势是算法不会轻易陷入局部最优,由于每次梯度向量的方向都会发生巨大变化,因此一旦有机会,算法就能够跳出局部最优,走向全局最优(当然也有可能是跳出一个局部最优,走向另一个局部最优)。不过缺点是,需要的迭代次数变得不明。如果最开始就在全局最优的范围内,那可能只需要非常少的迭代次数就收敛,但是如果最开始落入了局部最优的范围,或全局最优与局部最优的差异很小,那可能需要花很长的时间、经过很多次迭代才能够收敛,毕竟不断改变的方向会让迭代的路线变得曲折。
从整体来看,为了mini-batch SGD这"不会轻易被局部最优困住"的优点,我们在神经网络中使用它作为优化算法(或优化算法的基础)。
-
当然,还有另一个流传更广、更为认知的理由支持我们使用mini-batch SGD:mini-batch SGD可以提升神经网络的计算效率,让神经网络计算更快。
为了解决计算开销大的问题,我们要使用mini-batch SGD。考虑到可以从全部数据中选出一部分作为全部数据的"近似估计",然后用选出的这一部分数据来进行迭代,每次迭代需要计算的数据量就会更少,计算消耗也会更少,因此神经网络的速度会提升。当然了,这并不是说使用1001个样本进行迭代一定比使用1000个样本进行迭代速度要慢,而是指每次迭代中计算上十万级别的数据,会比迭代中只计算一千个数据慢得多。
-
2. batch_size与epoches
- batch_size: 批量尺寸,指每次迭代抽取的样本数目。
- epoch: 衡量训练数据被使用的次数单位。1个epoch代表优化算法将全部训练数据都完整使用了一次。
- 换算公式: 假设总样本为 mmm,则完成 1 个epoch所需的迭代次数 n=mbatch_sizen = \frac{m}{batch\_size}n=batch_sizem。
3. TensorDataset类 - 张量数据集
TensorDataset类是torch.utils.data.Dataset类的子类(属于torch.utils.data模块)
需要from torch.utils.data import TensorDataset
(1). TensorDataset类类型
作用:
TensorDataset 是 PyTorch 中用于打包数据的最基础工具。它的核心作用是将特征张量(如 XXX)和标签张量(如 yyy)"绑定"在一起,形成一个一一对应的数据集对象。使用这个类,我们不需要再手动去维护特征与标签的索引对齐,它会在底层确保同一个索引 i 能够同时准确地取到第 i 个样本的特征及其对应的真实标签。
python
torch.utils.data.TensorDataset(*tensors)核心参数:
-
*打包张量 (tensors):这里通常传入我们的特征张量 XXX 和标签张量 yyy。要求传入的所有张量在第一维度(通常是样本数,即Batch Size 维度)上的大小必须绝对一致。否则,底层无法将它们按行对齐,会直接抛出形状不匹配的报错。
Python 的解包参数:函数定义里的 * 号被称为星号参数。它的作用是将传入的多个参数打包成一个元组(Tuple)。所以*tensors 表示该函数可以接收任意数量的张量参数。
核心属性 (Attributes):
实例化 TensorDataset 后,可以通过以下属性访问底层数据:
.tensors:一个包含了你传入的所有张量的元组 (Tuple)。例如dataset.tensors[0]就是你的特征矩阵 XXX。
理论与底层代码的对齐 (极其重要):
在深度学习中,为了矩阵运算的高效性,XXX 和 yyy 必须保持为纯粹的 Tensor。TensorDataset 巧妙地充当了一个"外壳",它不改变底层数据在显存中的连续物理存储状态,仅仅是提供了一套统一的索引接口。
(2). getitem 与 len - 实例调用(支持索引与长度测量)
作用:TensorDataset 继承自 Dataset,它在底层重写了 Python 的魔法方法 __getitem__ 和 __len__。这意味着实例化后的数据集对象,可以直接像 Python 的列表一样使用 len() 获取总样本数,也可以通过中括号 [] 进行切片或单点索引。
python
# 实例化后,直接像列表一样切片或查询长度
dataset[index] #根据索引index同时提取出对应的特征和标签;返回一个元组(tuple):(feature_tensor, label_tensor)
len(dataset) #返回数据集中样本的总数(3). iter - 实例调用(支持直接迭代)
作用:
得益于 Python 的序列协议(当对象实现了 __getitem__ 且支持从 000 开始的索引时),TensorDataset 实例天然支持被迭代。这意味着你可以直接把它放在 for 循环中进行遍历,它会自动按照索引顺序逐个吐出样本对。
python
# 实例化后,直接作为可迭代对象放在 for 循环中
for feature, label in dataset:
pass返回值:
- 每次循环返回一个元组,包含单个样本的特征张量和标签张量。
与 DataLoader 迭代的本质区别 (极其重要):
在真正的工业界模型训练中,我们极少去直接迭代 Dataset。
- 直接迭代 Dataset: 每次只会死板地按顺序返回一条数据。它没有"批次 (Batch)"维度的概念,也不能打乱数据 (Shuffle)。
- 迭代 DataLoader:
DataLoader才是专门为了迭代而生的。它在底层调用了Dataset的内容,但帮你加上了批量打包、多线程、随机打乱等高级机制。因此,我们总是把Dataset塞进DataLoader里,然后去for循环遍历DataLoader。
示例:
python
import torch
from torch.utils.data import TensorDataset
X = torch.randn(500, 20)
y = torch.randint(0, 3, (500,))
dataset = TensorDataset(X, y)
# 直接迭代 Dataset(不推荐用于训练)
print("直接迭代 Dataset:")
for feature, label in dataset:
print("返回的是单个样本!")
print("特征形状:", feature.shape) # 输出: torch.Size([20]) (注意没有Batch维度)
print("标签形状:", label.shape) # 输出: torch.Size([])
break # 只看第一个就退出4. DataLoader类 - 数据加载器
DataLoader类是一个独立的迭代器构建类 (属于torch.utils.data模块)
需要from torch.utils.data import DataLoader
(1). DataLoader类类型
作用:
DataLoader 是 PyTorch 中实现数据分批次训练的核心引擎。它接收一个 Dataset 对象,并将其包装成一个可迭代对象 (Iterable)。对应了笔记之前提到的"mini-batch SGD"的数据采样过程。它不仅能帮我们自动把庞大的数据集切分成一个个小的批次 (Batch BBB),还自带了打乱数据 (Shuffle) 和多线程加速加载 (Multiprocessing) 的功能。
python
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0, drop_last=False)核心参数:
- 数据集 (dataset):必须是一个
Dataset类的实例(比如我们刚才实例化的TensorDataset)。这是你要从中取数据的数据源。 - 批次大小 (batch_size):即我们在 mini-batch SGD 中定义的批次样本数量 mmm (int)。比如总共有 500 个样本,设为 50,那每次迭代就会吐出 50 个样本。这是极其关键的超参数,直接影响显存占用和梯度下降的轨迹。
- 是否打乱 (shuffle):决定在每一个 Epoch(全量数据遍历一次)开始前,是否重新打乱数据的索引顺序 (bool,默认为 False)。在训练集上强烈建议设为 True,这正是"随机"梯度下降中"随机"二字的来源,能有效防止模型记住数据的输入顺序,帮助跳出局部最优。
- 多线程工作数 (num_workers):决定了用于读取和加载数据的子进程数量 (int,默认为 0)。当设为
0时,代表只在主进程中同步加载数据。在深度学习工程中,由于 CPU 从硬盘读取数据的 I/O 速度往往远慢于 GPU 计算的速度,如果不开启多进程,GPU 常常会"空载"等待数据。适当调大此参数(通常设为 4 或 8,视 CPU 核心数而定),可以让底层并发地预加载下一个批次的数据,极大打破系统 I/O 瓶颈,提升整体训练速度。 - 丢弃尾部 (drop_last):如果数据集大小不能被
batch_size整除,最后会剩下一个较小的 batch。设为True会丢弃这个不完整的尾部批次 (bool)。在某些要求批次大小必须严格一致的底层网络(如 BatchNorm 层)中非常有用。
补充:
深度理解 DataLoader 的"按需加载"与显存管理:
初学者常常疑惑:我都已经把 XXX 和 yyy 放进
TensorDataset了,为什么还要再套一层DataLoader?因为在工业级场景下,你的训练数据可能是几百 GB 的图片或文本,电脑内存和 GPU 显存根本装不下所有的 Tensor。
DataLoader本质上是一个"生成器 (Generator)"。它只有在for循环运行到当前批次时,才会去内存(或硬盘)里把这batch_size个数据提取出来塞进 GPU。这种"流水线"式的数据喂入机制,是保障大型 AI 基础设施稳定运转的基石。
(2). batch_size 属性
作用:
.batch_size(查询批次大小):DataLoader实例化后,内部维护了.batch_size属性。你可以通过它直接获取当前加载器配置的批次大小。这在编写自适应代码时非常方便(例如需要根据批次大小动态调整某些张量形状时)。
python
dataloader.batch_size # 返回设定的 batch_size 大小,例如 50(3). len 与dataset属性
作用与避坑指南:
- **
__len__(支持测量):DataLoader重写了__len__方法,但它返回的不再是样本总数,而是当前配置下的 Batch 总数(即一轮 Epoch 需要迭代的次数)。**例如,500 个样本,batch_size=50,len(dataloader)返回的就是 10。 .dataset属性 (支持穿透访问原始数据):DataLoader对象内部维护了一个.dataset属性,它指向你当初封装好的那个原始数据集。你可以通过它绕过 DataLoader 的批处理机制,直接查询底层特征:dataloader.dataset:展示底层绑定的全部原始数据对象。len(dataloader.dataset):返回底层真实的样本总数量。dataloader.dataset[index]:返回全部数据第 index个单个样本,注不是第 index个Batch,也不是当前Batch的第 index个单个样本。等同于dataset[index]。
__getitem__(不支持!严禁切片): 注意!DataLoader并没有重写__getitem__方法。 绝对不能像操作列表或Dataset那样,使用dataloader[0]去获取第一个批次的数据。因为DataLoader是一个动态流水线(开启打乱后数据更是即时生成的),要想获取 Batch 数据,必须通过迭代。
python
len(dataloader) #一共有多少个batch
dataloader.dataset #展示里面全部的数据
len(dataloader.dataset) #返回样本数量
dataloader.dataset[index] #返回全部数据第index个单个样本,等同dataset[index](4). iter - 实例调用(作为迭代器执行循环)
作用:DataLoader 重写了 __iter__ 魔法方法。在训练时,我们不会直接去调用它,而是将其直接放在 for 循环中。每次循环,它都会自动执行采样、打包,并返回一个包含 (batch_X, batch_y) 的元组。
python
# 将 DataLoader 当作可迭代对象放在 for 循环中
for batch_X, batch_y in dataloader:
pass综合示例 (结合 TensorDataset 与 DataLoader):
python
import torch
from torch.utils.data import TensorDataset, DataLoader
# 1. 准备假数据 (500个样本,20个特征,3分类)
X = torch.rand((500, 20), dtype=torch.float32) * 100
y = torch.randint(low=0, high=3, size=(500,), dtype=torch.float32)
# 2. 数据集打包与装载
dataset = TensorDataset(X, y)
# 设定 batch_size=50,意味着一个 Epoch 会有 500/50 = 10 个 Batch
dataloader = DataLoader(dataset, batch_size=50, shuffle=True)
# 3. 设定训练轮数
epochs = 5
print(f"数据准备完毕,总样本数: {len(dataset)},每轮Batch数: {len(dataloader)}")
#数据准备完毕,总样本数: 500,每轮Batch数: 10
# 4. 嵌套循环训练流程
for epoch in range(epochs):
print(f"第{epoch + 1}轮训练") # 第1轮训练
# 在每一个 Epoch 内部,遍历所有的 Batch
for batch_idx, (batch_X, batch_y) in enumerate(dataloader):
# 打印当前 Epoch 下的 Batch 进度
print(f"正在处理第 {batch_idx+1} 个Batch") # 正在处理第1个Batch5.TensorDataset与DataLoader总结
PyTorch 中的 torch.utils.data 模块提供了强大的数据预处理工具。
- 打包数据 (
TensorDataset): 将特征张量 XXX 和真实标签 yyy 进行配对打包。 - 划分批量 (
DataLoader): 接受打包好的数据集,并根据设定的batch_size将其切分为可迭代的小批量数据。
6. 外部真实数据的导入与封装 (Sklearn & Pandas)
作用:
在真实的深度学习工程和比赛中,我们极少使用 torch.rand() 来生成随机假数据。数据通常储存在本地的 .csv 文件、数据库中,或者通过第三方数据科学库(如 scikit-learn 和 pandas)进行读取和清洗。本节展示了如何将这些外部真实数据"无缝接入"到 PyTorch 的数据加载流中。
核心转换流水线 (Pipeline):
无论数据来源于何处,想要最终喂给 PyTorch 神经网络进行 mini-batch 训练,都必须严格遵守以下四步转换公式:
外部格式 (DataFrame/字典) →\rightarrow→ Numpy 数组 →\rightarrow→ PyTorch Tensors (X, y) →\rightarrow→ TensorDataset →\rightarrow→ DataLoader
代码解析与避坑指南:
-
场景一:从
sklearn导入数据 (如乳腺癌数据集)
sklearn.datasets返回的通常是类似字典的对象。我们可以直接提取它的.data(特征矩阵) 和.target(标签向量)。在转化为 Tensor 时,务必显式指定dtype=torch.float32,因为 sklearn 默认生成的往往是 float64 (双精度),这在 PyTorch 默认的 float32 神经网络中会引起类型不匹配的报错。 -
场景二:从
pandas读取本地 CSV 文件
pandas是读取结构化表格的利器。读取后,我们通常使用切片器.iloc进行特征和标签的分离:data.iloc[:, :-1]:提取所有行,以及除了最后一列之外的所有列(作为特征 XXX)。data.iloc[:, -1]:提取所有行,仅保留最后一列(作为标签 yyy)。- 致命避坑: PyTorch 的
torch.tensor()无法直接稳定地接收 Pandas 的DataFrame或Series对象!必须像代码中那样,先用np.array()将其剥离成纯粹的 Numpy 数组,然后再转化为张量。
代码示例:
python
# 场景一:导入 sklearn 中的内置数据
from sklearn.datasets import load_breast_cancer as LBC
import torch
from torch.utils.data import TensorDataset, DataLoader
data = LBC()
# 1. 提取并转为 Tensor,强制使用 float32
X = torch.tensor(data.data, dtype=torch.float32)
y = torch.tensor(data.target, dtype=torch.float32)
# 2. 数据装箱与分批配送
data_sklearn = TensorDataset(X, y)
batchdata_sklearn = DataLoader(data_sklearn, batch_size=5, shuffle=True)
for x, y in batchdata_sklearn:
print("Sklearn Batch X shape:", x.shape)
break
# 场景二:从 pandas 导入本地 CSV 数据
import pandas as pd
import numpy as np
# 1. 读取本地数据
# 注意:这里的路径需要替换为你电脑上的实际路径
data_pd = pd.read_csv(r"C:\creditcard.csv")
# 查看数据概况
print(data_pd.shape)
print(data_pd.head())
# 2. 切片、转 Numpy、再转 Tensor (核心步骤)
# data.iloc[:, :-1] 提取除了最后一列的所有列作为特征
X = torch.tensor(np.array(data_pd.iloc[:, :-1]), dtype=torch.float32)
# data.iloc[:, -1] 提取最后一列作为标签
y = torch.tensor(np.array(data_pd.iloc[:, -1]), dtype=torch.float32)
# 3. 数据装箱与分批配送
data_csv = TensorDataset(X, y)
batchdata_csv = DataLoader(data_csv, batch_size=1000, shuffle=True)
for x, y in batchdata_csv:
print("Pandas CSV Batch X shape:", x.shape)
break五.复习 AutoGrad自动微分
1. autograd.grad - 自动求导与梯度计算
作用:计算并返回输出张量(函数)对输入张量(自变量)的梯度(偏导数)。这是 PyTorch 动态计算图的核心运算。与直接调用 .backward() 会把梯度偷偷累加到张量的 .grad 属性中不同,autograd.grad 会"干净"地将算出的梯度作为一个元组直接返回,不会对原有变量产生副作用。
数学表示:假设目标函数(输出标量)为 yyy,输入变量为 x1,x2x_1, x_2x1,x2,则它计算的是偏导数集合 (∂y∂x1,∂y∂x2)(\frac{\partial y}{\partial x_1}, \frac{\partial y}{\partial x_2})(∂x1∂y,∂x2∂y)。
python
torch.autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False)参数:
- 输出张量 (outputs): 作为目标函数输出的因变量张量(通常是损失值 Loss 或误差 SSE 等标量) (Tensor 或 Tensor 列表)。
- 输入张量 (inputs): 需要求导的自变量张量。避坑提醒:传入的这些张量在创建时,必须显式设置了
requires_grad=True,并且参与了前向计算,否则引擎找不到求导路径会直接报错! (Tensor 或 Tensor 列表)。 - 输出梯度权重 (grad_outputs): 雅可比向量积中的权重向量。如果
outputs是一个普通标量,这个参数完全不用管(底层默认自动填1.0);但如果outputs是个多维张量,你必须传入一个和它形状完全一样的权重矩阵 (Tensor 或 Tensor 列表)。 - 保留计算图 (retain_graph): 决定在算出梯度后,是否保留底层的计算图内存。默认为
None(通常图用完一次就自动释放销毁了)。如果你需要对同一个图进行多次求导,必须设为True(Boolean)。 - 创建高阶计算图 (create_graph): 决定是否为"求导过程本身"也建立计算图。如果设为
True,你可以对算出来的梯度再求一次导,这是大模型中计算二阶导数、海森矩阵(Hessian Matrix)或梯度惩罚项的核心机制 (Boolean,默认为False)。
返回值:
- 成功: 返回一个元组 (Tuple),里面的元素严格按照你传入
inputs的顺序,依次对应每个自变量的梯度张量 (Tensor)。
requires_grad是tensor的一个属性可以查看修改。
python
a = torch.tensor(1.,requires_grad = True)
a.requires_grad # True示例:
python
# 1. 定义自变量并允许自动求导 (requires_grad=True 极其重要)
x = torch.tensor(2.0, requires_grad=True)
w = torch.tensor(3.0, requires_grad=True)
# 2. 构建前向计算图: y = w * x^2
y = w * (x ** 2)
# 3. 求解 y 对 w 和 x 的偏导数
# 理论数学解:
# dy/dw = x^2 = 2^2 = 4
# dy/dx = 2 * w * x = 2 * 3 * 2 = 12
grads = torch.autograd.grad(outputs=y, inputs=[w, x])
# (tensor(4.), tensor(12.))
print("返回类型:", type(grads))
# 返回类型: <class 'tuple'>
print("偏导数计算结果:", grads)
# 偏导数计算结果: (tensor(4.), tensor(12.)) <-- 分别对应 w 和 x 的梯度
# 验证副作用:x 和 w 的 .grad 属性依然是 None,证明 autograd.grad 很"干净"
print("x 自身的 .grad 属性:", x.grad) # None2. backward - 误差反向传播与梯度计算
作用:计算当前张量(通常是代表整体误差的标量 Loss)对计算图中所有叶子节点(即 requires_grad=True 的模型参数)的梯度。这是深度学习训练网络时最核心的动作!与 autograd.grad 直接返回结果不同,.backward() 是一个原地(In-place)操作,它没有返回值,而是会沿着计算图一路往回算,并把算出的梯度偷偷塞进各个参数自己的 .grad 属性中。
数学表示:执行反向传播算法,利用链式法则自动计算 ∂Loss∂wi\frac{\partial Loss}{\partial w_i}∂wi∂Loss 和 ∂Loss∂bi\frac{\partial Loss}{\partial b_i}∂bi∂Loss。
python
tensor.backward(gradient=None, retain_graph=None, create_graph=False)参数:
- 梯度权重 (gradient): 雅可比向量积的初始梯度。避坑提醒:如果你对一个"标量"(比如求和/求均值后的 Loss)调用
.backward(),这个参数完全不用填(底层默认传入 1.0);但如果你对一个"多维张量"直接调用.backward(),就必须传入一个与它形状完全相同的张量作为权重! (Tensor 或 None)。 - 保留计算图 (retain_graph): PyTorch 为了节省极宝贵的显存,默认在一次
.backward()执行完毕后,就会把中间的计算图直接销毁(释放内存)。如果你的代码需要在同一个前向传播的结果上调用两次.backward(),必须在此参数传入True(Boolean,默认为False)。 - 创建高阶计算图 (create_graph): 用于二阶导数或梯度惩罚(如 WGAN-GP 或大模型的某些特殊正则化)。设为
True时,反向传播的过程本身也会被记录进计算图 (Boolean,默认为False)。
返回值:
- 无返回值 (
None)。计算出的梯度会自动累加到对应自变量张量的.grad属性中。
注:一次性消耗:默认情况下,一次反向传播结束后,计算图会被销毁。若需多次求导,需设置 backward(retain_graph=True)。
示例:
python
x = torch.tensor(1.,requires_grad=True)
y = x**2
z = y + 1
y.backward() #默认:同计算图上执行.backward两次,会报错
z.backward() #报错
x = torch.tensor(1.,requires_grad=True)
y = x**2
z = y + 1
y.backward(retain_graph=True)
z.backward() #不报错示例与重大避坑警告:
python
# 1. 定义模型参数 (大模型中的权重 w 和 b)
w = torch.tensor([2.0, 3.0], requires_grad=True)
x = torch.tensor([1.0, 2.0]) # 输入数据不用求导
# 2. 模拟第一次前向传播与计算 Loss
loss1 = torch.sum((w * x) ** 2)
# Loss = (2*1)^2 + (3*2)^2 = 4 + 36 = 40
# 3. 第一次反向传播
loss1.backward()
print("第一次 backward 后的 w.grad:", w.grad)
# tensor([ 4., 24.]) (算法: 2*w*x^2)
# 史诗级避坑:梯度累加 (Gradient Accumulation)
# 假设我们进行第二个 Batch 的训练...
loss2 = torch.sum((w * x) ** 2)
# 4. 第二次反向传播前,如果不清空梯度:
loss2.backward()
print("第二次 backward 后的 w.grad:", w.grad)
# tensor([ 8., 48.]) <-- 致命错误!它把两次的梯度加起来了!
# 正确做法:每次反向传播前/后,必须清零梯度!
# 在实际大模型训练中,这对应着 optimizer.zero_grad() 这一关键步骤。
w.grad.zero_() 3. 完整神经网络的学习代码示例
假设我们有500条数据,20个特征,标签为3分类。我们现在要实现一个三层神经网络,这个神经网络的架构如下:第一层有13个神经元,第二层有8个神经元,第三层是输出层。其中,第一层的激活函数是relu,第二层是sigmoid。
python
#一共需要定义6个内容:
#定义超参数
#定义伸进网络的架构类Model
#定义损失函数
#定义优化算法
#定义dataset
#定义dataloader
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import TensorDataset,DataLoader
class Model(nn.Module):
def __init__(self,in_features=10, out_features=2):
"""
in_features: 输入该神经网络的特征数目(输入层上的神经元的数目)
out_features:神经网络的输出的数目(输出层上的神经元的数目)
"""
# 1. 重点:必须继承父类的初始化方法!
super().__init__()
# 2. 定义网络的各个层 (此时并不执行计算,只是声明有这些组件)
self.linear1 = nn.Linear(in_features,13,bias=False)
self.linear2 = nn.Linear(13,8,bias=False)
self.output = nn.Linear(8,out_features,bias=True)
def forward(self,x): #神经网络的向前传播
# 3. 定义数据x的流向和激活过程
sigma1 = torch.relu(self.linear1(x))
sigma2 = torch.sigmoid(self.linear2(sigma1))
zhat = self.output(sigma2)
return zhat
# 假设我们有500条数据,20个特征,标签为3分类。
X = torch.rand((500,20),dtype=torch.float32)*100 #防止X经过sigmod后数值太小,乘不乘100都行
y = torch.randint(low = 0,high=3,size=(500,),dtype=torch.float32)
input_ = X.shape[1] #输入层神经元个数,即特征数量
output_ = len(y.unique()) #对y中内容去重,得到标签一共有几类
torch.random.manual_seed(420)
# 实例化模型
model = Model(in_features=input_,out_features=output_)
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 确定超参数
lr = 0.1 # 学习率
gama = 0.9 # 动量参数
epochs = 1000 #训练轮次
batch_size = 120 #batch大小
# 定义优化器
opt = optim.SGD(model.parameters(),lr=lr,momentum=gama) #学习率为0.1,动量参数为0.9
# 定义dataset
dataset = TensorDataset(X,y)
# 定义dataloader
dataloader = DataLoader(dataset,batch_size=batch_size,shuffle=True,drop_last=True)
for epoch in range(epochs):
epoch_loss =0.0
for batch_idx,(batch_X,batch_y) in enumerate(dataloader):
# 神经网络的学习步骤
# 1.正向传播
zhat = model(batch_X)
# 2.计算损失
loss = criterion(zhat,batch_y.long())
# 3.清空梯度
opt.zero_grad()
# 4.反向传播求解梯度
loss.backward()
# 5.更新权重
opt.step()
epoch_loss += loss.item()
# 计算本轮epoch的loss平均值
loss_avg = epoch_loss/len(dataloader)
print(f"第{epoch}轮的loss是{loss_avg}")
# 第0轮的loss是1.1431220471858978
# 第1轮的loss是1.1105788946151733
# 第2轮的loss是1.10615673661232
# ...
# 第998轮的loss是1.0990446507930756
# 第999轮的loss是1.100236713886261 4. requires_grad设置
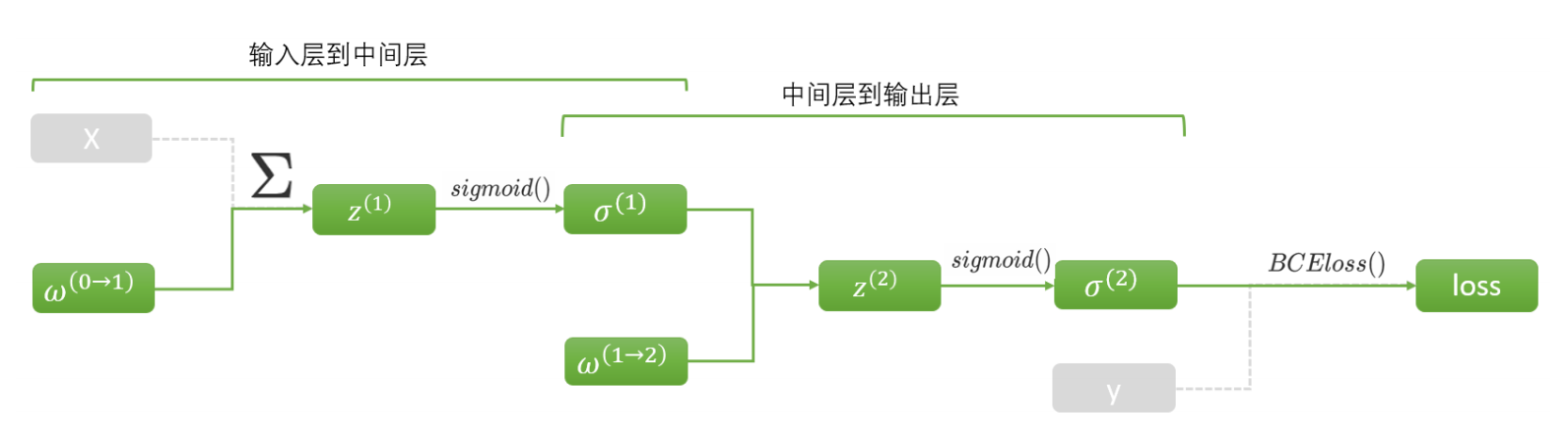
不难发现,我们的特征张量 XXX 与真实标签 yyy 都不在反向传播的过程当中,但是 XXX 与 yyy 其实都是损失函数计算需要用的值,在计算图上,这些值都位于叶子节点上,我们在定义损失函数时,并没有告诉损失函数哪些值是自变量,哪些是常数,那backward函数是怎么判断具体求解哪个对象的梯度的呢?
==其实就是靠requires_grad。首先backward会识别叶子节点,不在叶子上的变量是不会被backward考虑的。对于全部叶子节点来说,只有属性requires_grad=True的节点,才会被计算。==在设置 XXX 与 yyy 时,我们都没有写requires_grad参数,也就是默认"允许求解梯度"这个选项为False,所以backward在计算的时候就只会计算关于 www 的部分。
当然,我们也可以将 XXX 和 yyy 或者任何除了权重以及截距的量的requires_grad打开,一旦我们设置为True,backward就会在帮助我们计算 www 的导数的同时,也帮我们计算以 XXX 或 yyy 为自变量的导数。在正常的梯度下降和反向传播过程中,我们是不需要这些导数的,因此我们一律不去管requires_grad的设置,就让它默认为False,以节约计算资源。当然,如果你的 www 是自己设置的,千万记得一定要设置requires_grad=True。
六. 优化网络训练技巧:Batch Normalization与Dropout
随着神经网络越来越深,模型在学习过程中极易遇到"过拟合(死记硬背数据)"以及"梯度消失/爆炸(无法有效更新)"的问题。在 PyTorch 中,我们通常会引入两个极其经典的层来解决这些问题:Dropout 与 Batch Normalization。
1. nn.Dropout类 - 随机失活层
nn.Dropout类是nn.Module类的子类
(1). nn.Dropout类类型
作用:
nn.Dropout 是深度学习中极其经典的反过拟合(Regularization)层。它的核心作用是在训练过程中,按照设定的概率随机将输入张量中的部分元素"归零"(失活)。这相当于强迫网络在每次前向传播时使用一个"残缺"的子网络进行学习,从而打破神经元之间复杂的相互依赖(共适应现象),让每个神经元都能独立地学到更鲁棒的特征。
python
torch.nn.Dropout(p=0.5, inplace=False)核心参数:
- 失活概率 §:每个元素被归零的概率。默认为
0.5。例如设为 0.3,代表每次前向传播时,会有大约 30% 的神经元输出被强制置 0 (float)。 - 原地操作 (inplace):如果设为
True,PyTorch 会直接在原有内存上修改输入张量,能够稍微节省一点显存,但可能会导致原张量在后续计算中不可用。默认为False(bool)。
核心属性 (Attributes):
与 nn.Linear 不同,Dropout 没有任何可学习的权重矩阵。实例化后,它的属性极其简单:
.p:可以直接查看或修改当前层设定的失活概率。- 注意:Dropout 层绝对没有
.weight和.bias属性!
理论与底层代码的对齐 (极其重要):
问:如果在训练时随机丢弃了 p∗100p*100p∗100%的神经元,那测试(评估)时火力全开,信号的总强度不就突然翻倍了吗,模型怎么适应?
-
在传统的理论教学中,测试阶段会把所有权重乘以 (1−p)(1 - p)(1−p) 来保持期望一致。
-
但在 PyTorch 底层,为了让预测(推理)阶段速度最快,官方采用的是"Inverted Dropout(反向失活)"算法:
PyTorch 不会在测试时做任何缩放,而是在训练时,直接把所有存活下来的元素数值乘以 11−p\frac{1}{1-p}1−p1 进行放大!
ytrain=x∗mask1−py_{train} = \frac{x * mask}{1 - p}ytrain=1−px∗mask
这样,无论丢弃多少元素,训练阶段输出的期望值与测试阶段完全一致,测试阶段可以直接通过,不需要任何额外计算。
补充:致命的 train() 与 eval() 模式坑
nn.Dropout在训练(Train)和测试(Eval)时的行为是完全相反的!
- 在
model.train()模式下: Dropout 疯狂工作,随机归零元素,并按比例放大存活元素。- 在
model.eval()模式下: Dropout 彻底罢工(失效)。它会像玻璃一样完全透明,原封不动地把输入透传给下一层。
(2). call - 实例调用(执行前向传播)
作用:将输入数据喂给该层执行随机失活。
python
# 实例化后,直接像调用函数一样调用该对象
dropout_layer(input)参数:
- 输入张量 (input): 任意形状的特征张量 (Tensor)。
返回值:
- 成功: 返回经过失活处理后的张量,形状与输入绝对一致。
示例:
python
# 1. 准备假数据 (全 1 张量)
X = torch.ones(2, 5)
# 2. 实例化Dropout层(设置 50% 概率失活)
model = nn.Dropout(p=0.5)
# 3. 训练模式下的前向传播
model.train() # 默认就是train模式,这里显式声明
output_train = model(X)
print(output_train)
# tensor([[0., 0., 0., 2., 2.],
# [2., 0., 2., 0., 2.]])
# 大约一半的1.变成了0.且存活下来的1.变成了2.(因为底层乘了1/(1-0.5))
# 4. 测试模式下的前向传播
model.eval()
output_eval = dropout_layer(X)
print(output_eval)
# tensor([[1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1.]])
# Dropout彻底罢工,原封不动输出了全1的张量。2. nn.BatchNorm1d 与 nn.BatchNorm2d - 批标准化层
nn.BatchNorm系列均是nn.Module类的子类
(1). nn.BatchNorm类类型
作用:
批标准化(Batch Normalization,简称 BN 层)是深层神经网络中加速收敛、防止梯度消失的终极杀器。它的核心作用是在每一层网络将数据喂给激活函数之前,强行把当前 mini-batch 内的数据拉回到均值为 0、方差为 1 的正态分布,从而解决"内部协变量偏移 (Internal Covariate Shift)"问题。
nn.BatchNorm1d:处理 2D 或 3D 张量(通常用于普通全连接层之后,或一维时序卷积之后)。nn.BatchNorm2d:处理 4D 张量(专门用于处理图像的二维卷积层nn.Conv2d之后)。
python
# 1D与2D的参数签名几乎一模一样
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)核心参数:
-
特征通道数 (num_features):必须填入上一层输出的特征数 / 通道数。如果是接在
Linear(out_features=128)后面,这里就填 128。这是唯一必填的参数 (int)。 -
极小值 (eps):为了防止分母出现除以 0 的崩溃情况,加在方差里的极小常数。默认
1e-05,一般永远不去动它 (float)。 -
动量 (momentum):用于计算全局运行均值和方差的平滑衰减系数。注意:这里的动量和优化器
optim.SGD里的动量完全是两个东西! BN的动量计算公式是x_new = (1-m)*x_old + m*x_batch。默认为0.1(float)。m(momentum):设置的动量参数。x_old:更新前的历史全局统计量(即旧的running_mean或running_var)。x_batch:当前这批数据刚刚算出来的新均值(或无偏方差)。x_new:更新后的全局统计量(准备留给下一个 Batch 当作x_old用,或者在测试阶段拿来做标准化的那个最终值)。
补充:BN 层底层方差计算的史诗级避坑点
在 BN 层的底层运算中,关于方差的计算隐藏着一个极其严谨的统计学细节。对于同一个 Batch 的数据,它在内部同时计算了两种不同的方差:
-
在执行前向传播标准化时(生成 zhatz_{hat}zhat):
BN 层使用的是有偏方差 (Biased Variance) 。即计算方差时的分母是 NNN (当前 Batch 的样本数)。
原因:此时它的任务仅仅是处理眼前的这批数据,把当前已知的数据强行拉回均值 0、方差 1,因此直接除以总数 NNN 即可。
-
在利用动量公式更新全局方差时(更新
running_var):代入动量公式
x_new = (1-m)*x_old + m*x_batch中的x_batch(当前批次的新方差),使用的是无偏方差 (Unbiased Variance) !即计算方差时的分母是 N−1N-1N−1 (统计学中的贝塞尔校正)。原因:
running_var的终极使命是利用一个个局部的抽样 Batch,去估计整个训练集总体的真实方差。根据统计学原理,使用样本估计总体方差时,必须除以 N−1N-1N−1 才能得到无偏估计。
在 BN 层的底层运算中,关于均值的计算,前向传播标准化和利用动量公式更新全局均值时分母都是N.
-
是否进行仿射变换 (affine):如果设为
True,该层将额外学习两个参数 γ\gammaγ(缩放)和 β\betaβ(平移)。默认为True(bool)。 -
追踪全局统计量 (track_running_stats):如果为
True,模型会记录整个训练过程的均值和方差,用于测试阶段。 (bool)。
核心属性 (Attributes):
实例化 BN 层后,除了参数,它还默默维护了极其重要的统计状态:
.weight和.bias:这就是公式中的 γ\gammaγ 和 β\betaβ!它们是张量,形状为(num_features,),并且requires_grad=True(会通过反向传播被优化)。.running_mean和.running_var:全局运行均值和方差。这是整个网络中最特殊的存在!它们随着前向传播更新,但不属于模型权重,不参与反向传播计算梯度!
理论与底层代码的对齐 (极其重要):
BN 底层的数学操作分为死板的两步:
- 标准化: 取当前 Batch 内的特征计算均值 μB\mu_BμB 和方差 σB2\sigma^2_BσB2,将数据拉回标准分布。
- 仿射变换(恢复表达能力): 标准正态分布可能会破坏之前层学到的特征,所以利用可学习的 γ\gammaγ 和 β\betaβ 把分布进行适当拉伸和平移。
y=x−μBσB2+ϵ∗γ+βy = \frac{x - \mu_B}{\sqrt{\sigma^2_B + \epsilon}} * \gamma + \betay=σB2+ϵ x−μB∗γ+β
补充:1D 与 2D 的维度对齐方式
- **BatchNorm1d:**接收形状
(N, C)。这里的特征数就是 CCC。它是在NNN(Batch 维度) 上求均值。每个特征列得到均值为0,方差为1。- **BatchNorm2d:**接收形状
(N, C, H, W)(图像:批次、通道数、高、宽)。这里的num_features是通道数 CCC。它是怎么算均值的?它会在 N,H,WN, H, WN,H,W 三个维度上同时拉平求均值! 即:不管这批图片有多大,红、绿、蓝的3个均值为0和3个方差为1。这在计算机视觉中被称为 Spatial Batch Normalization。
(2). call - 实例调用(执行前向传播)
作用:对输入数据执行批标准化。与 Dropout 一样,严禁漏掉 train() 和 eval() 的模式切换!
python
# 实例化后,直接作为函数调用
bn_layer(input)参数:
- 输入张量 (input):
BatchNorm1d接收 2D 或 3D 张量,BatchNorm2d接收 4D 张量。
返回值:
- 成功: 返回标准化且仿射变换后的结果,形状与输入绝对一致。
示例:
python
# 1. 准备假数据:5 个样本,每个样本 3 个特征
X = torch.tensor([[100., 1., 0.],
[ 50., 2., 0.],
[200., 3., 0.],
[150., 4., 0.],
[ 80., 5., 0.]])
# 2. 实例化 BatchNorm1d,特征数为 3
bn = nn.BatchNorm1d(num_features=3)
# 观察初始化的可学习参数和全局统计量
print("初始gamma(weight):", bn.weight.data) # 全 1
# 初始gamma(weight): tensor([1., 1., 1.])
print("初始beta(bias):", bn.bias.data) # 全 0
# 初始beta(bias): tensor([0., 0., 0.])
print("初始全局均值(running_mean):", bn.running_mean) # 全 0
# 初始全局均值(running_mean): tensor([0., 0., 0.])
print("初始全局方差(running_var):", bn.running_var) # 全 1
# 初始全局方差(running_var): tensor([1., 1., 1.])
# 3. 训练模式:前向传播
bn.train()
z_hat = bn(X)
# 第一列 (100,50,200,150,80) 数值非常大经过 BN 后,被强行拉回到了 0 附近!
print("经过 BN 处理后的输出 z_hat:", z_hat)
print("第一列(特征0)的均值变成了:", z_hat[:, 0].mean().item()) # 趋近于 0
print("第一列(特征0)的方差变成了:", z_hat[:, 0].var(unbiased=False).item()) # 趋近于 1
print("初始gamma(weight):", bn.weight.data)
print("初始beta(bias):", bn.bias.data)
print("更新后的全局均值 (running_mean):", bn.running_mean) # 全局均值被隐式更新了
print("更新后的全局方差 (running_var):", bn.running_var) # 全局方差被隐式更新了
# 经过 BN 处理后的输出 z_hat:
# tensor([[-0.3011, -1.4142, 0.0000],
# [-1.2420, -0.7071, 0.0000],
# [ 1.5807, 0.0000, 0.0000],
# [ 0.6398, 0.7071, 0.0000],
# [-0.6774, 1.4142, 0.0000]], grad_fn=<NativeBatchNormBackward0>)
# 第一列(特征0)的均值变成了: -4.7683716530855236e-08
# 第一列(特征0)的方差变成了: 1.0000001192092896
# 初始gamma(weight): tensor([1., 1., 1.])
# 初始beta(bias): tensor([0., 0., 0.])
# 更新后的全局均值 (running_mean): tensor([11.6000, 0.3000, 0.0000])
# 更新后的全局方差 (running_var): tensor([353.9000, 1.1500, 0.9000])
# 4. 测试模式
bn.eval()
test_X = torch.tensor([[100., 1., 0.]])
# 在Eval模式下,BN 不会去算这单独1个样本的均值(否则会除以0报错或结果无意义),
# 而是直接拿刚才训练累积的running_mean和running_var 进行处理。
test_out = bn(test_X)
print(test_out)
# tensor([[4.6991, 0.6528, 0.0000]], grad_fn=<NativeBatchNormBackward0>)3. train() 与 eval() 模式
这是无数深度学习初学者必然会踩的惊天大坑!BN 层和 Dropout 层在"训练"和"预测(测试)"时的行为是完全不同的!
- 在训练时 (Training):
- Dropout 会疯狂丢弃神经元。
- BN 层会不断计算当前批次的均值和方差,并更新全局统计量。
- 在预测/测试时 (Evaluation):
- Dropout 必须被完全关闭(保留所有神经元火力全开去预测)。
- BN 层不能再去计算当前少量测试数据的均值(否则预测结果会随着批次大小剧烈波动),而是必须使用训练时累积下来的"全局均值和方差"。
PyTorch 的终极解决方案:状态切换开关
你不需要手动去改参数,PyTorch 提供了两个一键切换模型状态的开关。一旦你的模型中包含了BN或Dropout,在编写循环代码时必须严格遵守以下规范:
model.train():在进入训练的for epoch循环前调用。告诉模型:"开启训练模式,Dropout 给我丢弃,BN 开始统计!"model.eval():在验证、测试或输出最终结果前调用。告诉模型:"开启预测模式,Dropout 给我关掉,BN 冻结统计量!"
4. Batch Normalization和Dropout顺序
结论:永远不要把Dropout放在BN紧挨着的前面!
- Dropout 的行为像地震: 在训练时,Dropout 会随机把一部分神经元归零,并把剩下的神经元数值放大。这意味着每一批数据(Batch)经过 Dropout 后,它的数据分布、均值、尤其是方差,都在发生极其剧烈的震荡。
- BN 层的行为像测绘员: BN 层需要计算当前数据的均值和方差,并缓慢累积到
running_mean和running_var中留给测试阶段用。 - 悲剧发生: 如果你让 BN 去测量刚经过 Dropout 的数据,BN 测到的全是充满了随机噪音的"假方差"。等到了测试阶段(
model.eval()),Dropout 被关闭了,数据突然变得极其稳定,但 BN 层还在用之前记录的"假方差"去处理真实的稳定数据,导致预测结果彻底崩溃!
七. GPU加速
在真实的深度学习工程中,模型和数据往往极其庞大,我们必定会使用 GPU 来加速训练。理解 CPU 与 GPU 之间的底层通讯流程,不仅是排查 device mismatch (设备不匹配) 报错的根本,更是优化显存和训练速度的 AI Infra 核心素养。
1. 核心概念:Host与Device
在硬件编程与深度学习的底层语境下,有两个专有名词必须区分清楚:
- **Host (主机):指CPU和内存 (RAM)。**它是总指挥,负责控制整体代码逻辑、读取硬盘上的数据集、发号施令。
- Device (设备):指GPU和显存 (VRAM)。它是干活的苦力,拥有成千上万个计算核心,只负责极其纯粹的、无脑的大规模矩阵运算。
2. device - 设备对象实例化
作用:创建一个代表底层计算设备的对象。在 PyTorch 中,所有的张量(Tensor)和模型网络(Module)都需要明确分配到特定的物理设备上(如 CPU 或特定的 GPU 显卡)才能进行运算。torch.device 就是用来精确指定这个数据"落脚点"的核心基类。
python
torch.device(device, index=None)
# 工业界更常用的单字符串简写形式:
# torch.device('cuda:0')参数:
- 设备名称 (device): 指明目标设备的类型。可以是带有编号的完整设备字符串(如
'cpu','cuda:0', 苹果M系芯片的'mps'),也可以是纯设备类型(如'cuda') (String)。 - 设备索引 (index): 指定多卡环境下的物理显卡编号。如果第一个参数
device只填了类型(如'cuda'),可以通过这个可选参数指定第几张显卡(如0代表第一张,1代表第二张)。如果device字符串里已经带了序号(如'cuda:0'),则此项留空 (Int 或 None)。
返回值:
- 成功: 返回一个封装好的设备对象 (
torch.device实例)。该对象可以直接作为参数传递给张量创建函数(如torch.zeros(..., device=dev))或.to()方法。
示例:
python
# 实例化写法的对比
dev1 = torch.device('cuda:0') # 写法 1:单字符串形式 (最直观常用)
dev2 = torch.device('cuda', 0) # 写法 2:类型 + 索引形式
dev3 = torch.device('cpu') # 写法 3:指定使用 CPU
# 工业界最经典的设备自适应 (Device Agnostic) 范式
# 如果系统有N卡GPU则使用第一张,否则降级使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("当前配置的设备对象:", device)
# 输出: device(type='cuda') 或 device(type='cpu')
# 实际应用:将张量分配到该设备上
t = torch.tensor([1.0, 2.0, 3.0])
t_device = t.to(device)3. is_available - 检查CUDA可用性
作用:查询当前系统底层是否检测到了受支持的 NVIDIA GPU 硬件,并且当前安装的 PyTorch 版本能够成功调用CUDA计算引擎。在工业界,它被广泛用于编写不挑硬件的"设备自适应 (Device Agnostic)"代码。
python
torch.cuda.is_available()参数:
- 该函数为探测型函数,不需要传入任何参数。
返回值:
- 成功: 返回标识当前环境是否支持 GPU 加速的布尔值。支持为
True,不支持则为False(bool)。
示例:
python
import torch
# 工业界标准写法:动态分配设备
# 如果GPU可用,就使用cuda,否则优雅地降级使用cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"当前系统已自动挂载至: {device}")
# 后续将数据和模型挂载到该设备上
# X = X.to(device)
# model = model.to(device)4. synchronize - 强制CPU阻塞等待GPU同步
作用:在 PyTorch 默认的"异步并发"执行机制下,强制在当前代码行阻断 CPU 的继续执行,直到目标GPU上所有已经排队的计算任务(核函数)全部执行完毕为止。这是进行极其精准的 GPU 计算测速,或排查分布式底层时序报错的核心函数。
python
torch.cuda.synchronize(device=None)参数:
- 目标设备 (device): 指定需要被同步(等待)的 GPU 设备。可以传入设备的整数索引(如
0代表cuda:0)或者torch.device对象。如果传入None,则默认同步当前处于激活状态的CUDA 设备 (Int/Device 或 None)。
返回值:
- 成功: 无返回值 (
None)。该函数仅产生底层硬件执行流的阻塞等待行为。
示例:
python
import torch
import time
# 数据准备
a = torch.randn(10000, 10000).cuda()
b = torch.randn(10000, 10000).cuda()
# GPU测速范式
start = time.time()
c = a @ b # 异步下达指令,CPU瞬间跳过本行
# 核心:强迫CPU在这里停下,死等GPU计算完庞大的矩阵乘法
torch.cuda.synchronize()
end = time.time()
print(f"GPU计算耗时:{end-start:.6f}秒")5. GPU 计算通用五步流程
无论使用何种框架,GPU 参与计算的生命周期永远遵循极其严密的"五步走"流程:
(1).第一步:在 GPU 分配显存
- 动作: GPU 不能直接读写CPU的内存,它只能操作自己卡上的显存。因此,CPU 第一步要做的,就是提前在 GPU 的显存里圈地,划分好足够存放输入特征 XXX、标签 yyy 以及模型权重的空白空间。
- 注:在PyTorch中,第一步的显存分配被底层引擎隐藏了。当调用
x.to('cuda')时,PyTorch 会在底层自动先圈好显存,再进行搬运。但如果使用torch.zeros(..., device='cuda'),这就是一种直接在 GPU 上分配显存而不经过主机搬运的操作。
(2).第二步:主机到设备的数据搬运
- 动作: CPU 将存放在普通内存中的数据,通过主板上的 PCIe 总线复制到刚才在 GPU 上分配好的显存里。
- PyTorch 实现:
x = x.to('cuda')或model.to('cuda') - 避坑指南: PCIe 总线的带宽是非常有限的。这是整个流程中最容易拖慢速度的一步!顶级工程师会尽量避免在
for循环里极其频繁地把零碎小数据在 CPU 和 GPU 之间传来传去。
(3).第三步:异步计算执行 (指令下达与并行计算)
- 动作:这一步在PyTorch中仅靠一行前向传播
output = model(x)或反向传播loss.backward()即可触发,但底层实际发生了两件跨硬件的物理事件:
- CPU端:指令下达;CPU向GPU发送核函数执行指令,CPU下达指令后立刻掉头去执行下一行Python代码,绝不死等GPU(异步机制)。
- GPU端:海量计算;GPU收到指令后,瞬间唤醒成千上万个计算核心,在显存内部极速完成极其庞大的矩阵运算。
- 测速陷阱: 因为CPU指令下达后就跑了,如果想测GPU计算花了多长时间,不能直接用Python的
time.time()测算。
- PyTorch 实现: 前向传播
output = model(x)或反向传播loss.backward()。
(5).第四步:设备到主机的结果取回
- 动作: GPU 算完了,但预测结果或 Loss 值依然躺在显存里。CPU 为了把这个结果打印到屏幕上,或者保存为日志,必须再次通过 PCIe总线,把显存里的数据拷贝回内存。
- PyTorch 实现:
output.cpu()或提取单个标量loss.item()或转为 Numpyoutput.numpy()。 - 阻塞等待: 由于 CPU 之前是异步去干别的事了,当代码执行到
loss.item()时,CPU 发现自己必须拿到这个结果才能往下走,此时它就会被强制阻塞,直到 GPU 把数据传回来为止。
补充:模型和数据必须在同一设备上
如遇到RuntimeError: Expected all tensors to be on the same device报错,这是因为没有将数据和模型放在同一个设备上。
-
为什么数据要上 GPU?
前向传播计算需要输入数据 (XXX) 和真实标签 (yyy) 参与高速的并行矩阵运算。
-
为什么模型也要上 GPU?
模型不只是代码逻辑,其实在PyTorch中,模型(
nn.Module)包裹着的权重张量 (Weight) 和偏置张量 (Bias)。当执行
output = model(X)时,底层实际上是让模型里的权重矩阵与输入张量 XXX 进行乘法。如果你的 XXX 已经搬到了显存里,而你的模型权重还留在 CPU 的内存里,GPU 在计算时伸手一摸显存,找不到相乘的另一半,当场就会崩溃。 -
正确方法:
不仅要写
X = X.to('cuda'),在训练循环开始前,必须先写model = model.to('cuda'),把模型内部成百上千万个参数统统搬运到显存中。
6. 完整代码流程
python
import torch
import torch.nn as nn
import torch.optim as optim
# 第一步:动态分配设备
# 自动检测当前机器是否有可用的 GPU,没有则平滑降级使用 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"当前正在使用的训练设备是: {device}")
# 第二步:准备数据与实例化模型 (伪代码)
# 1. 导入与封装数据
dataloader = ... # 你的 DataLoader 实例
# 2. 实例化模型、损失函数与优化器
model = ... # 你的神经网络实例 (如 model = MyRNN())
criterion = ... # 损失函数 (如 nn.CrossEntropyLoss())
opt = ... # 优化器 (如 optim.SGD(model.parameters(), lr=0.01))
# 第三步:模型上岛
# 将模型内部的所有权重和偏置搬运至GPU显存!【关键】
# 必须在传入优化器或进行任何计算之前完成!
model = model.to(device)
# 第四步:核心训练循环
epochs = 100
for epoch in range(epochs):
model.train() # 开启训练模式 (启用BN和Dropout)
for batch_idx, (batch_X, batch_y) in enumerate(dataloader):
# 1. 数据上岛(Host to Device)
# 将当前批次的特征和标签搬运到与模型相同的GPU显存中【关键】
batch_X = batch_X.to(device)
batch_y = batch_y.to(device)
# 2. 异步计算执行(指令下达与并行计算)
# 此时CPU飞速越过这几行代码,GPU 在后台开始疯狂计算矩阵和偏导数
zhat = model(batch_X) # 正向传播
loss = criterion(zhat, batch_y) # 计算损失
opt.zero_grad() # 清空残余梯度
loss.backward() # 反向传播
opt.step() # 权重迭代
# 3. 结果取回(Device to Host和阻塞等待)
# 调用.item()会阻塞CPU,等待GPU把标量Loss传回内存打印
if (batch_idx + 1) % 100 == 0:
print(f"Epoch: {epoch+1}, Loss: {loss.item():.4f}")八.在MINST-FASHION上实现神经网络的学习流程
完整的神经网络训练全流程代码架构可归纳为以下核心步骤:
1. 完整的训练流程
-
设置步长 lrlrlr , 动量值 gammagammagamma , 迭代次数 epochsepochsepochs ,
batch_size等信息,(如果需要)设置初始权重 w0w_0w0 , -
导入数据,将数据切分成batches
-
定义神经网络架构
-
定义损失函数 L(w)L(\mathbf{w})L(w) ,如果需要的话,将损失函数调整成凸函数,以便求解最小值
-
定义所使用的优化算法
-
开始在epoches和batch上循环,执行优化算法:
6.1. 调整数据结构,确定数据能够在神经网络、损失函数和优化算法中顺利运行
6.2. 完成向前传播,计算初始损失
6.3. 利用反向传播,在损失函数 L(w)L(\mathbf{w})L(w) 上对每一个 www 求偏导数
6.4. 迭代当前权重
6.5. 清空本轮梯度
6.6. 完成模型进度与效果监控
-
输出结果
2. 导入数据
作用:
在 PyTorch 中,我们可以借助 torchvision 库极其方便地下载和导入经典的计算机视觉数据集。Fashion-MNIST 是一个包含 10 种不同类别衣物(如 T恤、裤子、运动鞋等)的灰度图像数据集,常被用作验证算法的基准测试。每张图像的大小为 28×2828 \times 2828×28 像素。本步的核心目标是将原始图像转化为神经网络可计算的张量 (Tensor),并按照设定的 batch_size 封装成数据迭代器。
核心代码实现:
python
import torchvision #包含数据的模块
import torchvision.transforms as transforms #处理数据的模块
# dataLoader & TensorDataset - 对数据的结构、归纳方式进行变换
# torchvision.transforms - 对数据集的数字本身进行修改
from pathlib import Path
root = Path.cwd()
#实例化数据
mnist = torchvision.datasets.FashionMNIST(
root=root, #计算机上某个目录的地址
download=False, #如果指定的root目录下没有数据,自动从网上下载
train=True, #提取训练集
transform=transforms.ToTensor() #顺手把数据转成Tensor
)
print(mnist) #对于数据的一个说明
# Dataset FashionMNIST
# Number of datapoints: 60000
# Root location: D:\Code\llm\2.pytorch
# Split: Train
# StandardTransform
# Transform: ToTensor()
print(len(mnist)) #数据集样本数量
#60000
print(mnist.data) #查看内部数据长相
# 输出示例 (经过排版精简):
# tensor([[[ 0, 0, 0, ..., 0, 0, 0],
# ...,
# [ 0, 0, 0, ..., 0, 0, 0]],
# ... (中间省略,共包含 60000 个这样的 28x28 矩阵) ...
# [[ 0, 0, 0, ..., 0, 0, 0],
# ...,
# [ 0, 0, 0, ..., 0, 0, 0]]], dtype=torch.uint8)
# 数据解析:
# 1. 最外层包含了 60000 个元素(图片)。
# 2. 内部是 28x28 的二维数组(像素矩阵)。
# 3. 这里的 0 代表纯黑背景,如果有图案的地方,数值会在 1~255 之间。
# 4. dtype=torch.uint8 表示这是 8位无符号整型,是图像的原始像素格式。
print(mnist.data.shape) #查看内部数据形状
#torch.Size([60000, 28, 28]) - 由torch.Size([60000, 1, 28, 28])简化了一下
#(sample_size, C-color, H-height, W-width)
print(mnist.targets) #查看标签
#tensor([9, 0, 0, ..., 3, 0, 5])
print(mnist.targets.unique()) #查看有几个类别
#tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
print(mnist.classes) #查看每个类别编码对应的真正类别
#['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
print(mnist[0])
# (tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
# 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
# 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
# 0.0000, 0.0000, 0.0000, 0.0000],
# ...
# [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
# 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
# 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
# 0.0000, 0.0000, 0.0000, 0.0000]]]), 9)
# 返回值解析: 返回的是一个元组 Tuple(特征张量 X, 真实标签 y)
# 【第一部分:特征张量 X】
# 1. 核心变化:数值不再是 0~255 的整数!因为我们传入了 transform=transforms.ToTensor(),
# 它自动将像素值除以 255,归一化到了 [0.0, 1.0] 之间的 float32 类型小数,这有利于梯度下降。
# 2. 形状变化:它自动在最前面补全了通道维度 C,现在的形状是标准的 [1, 28, 28] (即 [C, H, W])。
# 【第二部分:真实标签 y】
# 1. 这里的数字 9 就是这个样本对应的类别索引。
# 2. 对照上面打印出的 mnist.classes,索引 9 代表 'Ankle boot' (短靴)。
import matplotlib.pyplot as plt
# 打印图片
plt.imshow(mnist[0][0].reshape(28,28)) #现在matplotlib.pyplot支持tensor类型了
3. 分割小批量
MINST-FASHION数据集已经将特征和标签组合好了,就不需要手动定义dataset了
4. 完整代码
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
from pathlib import Path
# 1.确实数据,确定超参数
lr = 0.15
gamma = 0
epochs = 10
batch_size = 128
root = Path.cwd()
mnist = torchvision.datasets.FashionMNIST(
root=root,
download=False,
train=True,
transform=transforms.ToTensor()
)
dataloader = DataLoader(mnist,batch_size=batch_size,shuffle=True,drop_last=False)
input_ = mnist.data[0].numel() #计算输入层神经元个数,即特征数量
output_ = len(mnist.targets.unique()) #计算输出层神经元个数,即种类数量
# 2.定义神经网络架构
class Model(nn.Module):
def __init__(self,in_features=10,out_features=2):
super().__init__()
self.linear1 = nn.Linear(in_features=in_features,out_features=128,bias=False)
self.bn1 = nn.BatchNorm1d(num_features=128)
self.dropout = nn.Dropout(p=0.3)
self.output = nn.Linear(in_features=128,out_features=out_features,bias=False)
def forward(self,x):
x = x.reshape(-1,28*28)
sigma1 = self.linear1(x) # 1. 先做线性变换
sigma1 = self.bn1(sigma1) # 2. 紧接着拉回标准分布 (BN)
sigma1 = F.relu(sigma1) # 3. 再过激活函数
sigma1 = self.dropout(sigma1) # 4. 最后随机失活一部分神经元
sigma2 = F.log_softmax(self.output(sigma1),dim=1)
return sigma2
# 3.定义损失函数、优化算法和梯度下降流程->定义一个训练函数(一般叫train或fit)
def fit(model,dataloader,device,lr=0.01,gamma=0.9,epochs=5,):
criterion = nn.NLLLoss()
opt = optim.SGD(model.parameters(),lr=lr,momentum=gamma)
samples = 0 #记录看过的样本个数,循环开始之前,模型一个样本都没有见过
correct = 0 #记录预测正确的样本个数,循环开始之前,模型一个样本都没有预测
model.train()
for epoch in range(epochs):
epoch_loss = 0.0
for batch_idx,(batch_X,batch_y) in enumerate(dataloader):
batch_y = batch_y.reshape(len(batch_X)) #整理batch_y结构
# 数据搬到GPU
batch_X = batch_X.to(device)
batch_y = batch_y.to(device)
sigma = model(batch_X) #前向传播
loss = criterion(sigma,batch_y) #计算loss
loss.backward() #反向传播
opt.step() #梯度更新
opt.zero_grad() #梯度清零
#求解准确率:全部判断正确的样本数量/已经看过的总样本量
yhat = torch.argmax(sigma,dim=1) #获取最大值对应索引的张量
correct += (yhat==batch_y).sum().item()
samples += len(batch_X) #更新看过的样本个数
epoch_loss += loss.item() #更新每轮epoch的总loss
#每125个batch我就打印一次
if (batch_idx+1)%125 == 0 or batch_idx == len(dataloader)-1:
total_samples = epochs*len(dataloader.dataset) #所有轮次样本量总和
progress_pct = 100 * samples/total_samples #进度百分比
acc_pct = 100 * correct/samples
print(f"Epoch{epoch+1}: [{samples}/{total_samples} ({progress_pct:.0f}%)], "
f"Loss: {loss.item():.6f}, "
f"Accuracy: {acc_pct:.3f}")
#分子代表:已经查看过的数据有多少
#分母代表:在现有的epochs设置,模型一共需要查看多少数据
loss_avg = epoch_loss/len(dataloader)
print(f"{epoch+1}轮loss:{loss_avg}")
# 4.训练与评估
torch.random.manual_seed(420)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"device:{device}")
model = Model(in_features=input_,out_features=output_)
model = model.to(device)
fit(model,dataloader,device,lr=lr,gamma=gamma,epochs=epochs)结果:
shell
# device:cuda
# Epoch1: [16000/600000 (3%)], Loss: 0.469969, Accuracy: 77.438
# Epoch1: [32000/600000 (5%)], Loss: 0.523475, Accuracy: 79.753
# Epoch1: [48000/600000 (8%)], Loss: 0.462733, Accuracy: 80.883
# Epoch1: [60000/600000 (10%)], Loss: 0.404814, Accuracy: 81.493
# 1轮loss:0.5276521389037053
# Epoch2: [76000/600000 (13%)], Loss: 0.500347, Accuracy: 82.126
# Epoch2: [92000/600000 (15%)], Loss: 0.522467, Accuracy: 82.764
# Epoch2: [108000/600000 (18%)], Loss: 0.311655, Accuracy: 83.144
# Epoch2: [120000/600000 (20%)], Loss: 0.355782, Accuracy: 83.378
# 2轮loss:0.4139585699925799
# Epoch3: [136000/600000 (23%)], Loss: 0.341515, Accuracy: 83.723
# Epoch3: [152000/600000 (25%)], Loss: 0.429800, Accuracy: 84.012
# Epoch3: [168000/600000 (28%)], Loss: 0.452742, Accuracy: 84.220
# Epoch3: [180000/600000 (30%)], Loss: 0.285456, Accuracy: 84.384
# 3轮loss:0.38145666253337984
# Epoch4: [196000/600000 (33%)], Loss: 0.362003, Accuracy: 84.576
# Epoch4: [212000/600000 (35%)], Loss: 0.404659, Accuracy: 84.783
# Epoch4: [228000/600000 (38%)], Loss: 0.504485, Accuracy: 84.934
# Epoch4: [240000/600000 (40%)], Loss: 0.361547, Accuracy: 85.028
# 4轮loss:0.3614860218979402
# Epoch5: [256000/600000 (43%)], Loss: 0.430173, Accuracy: 85.192
# Epoch5: [272000/600000 (45%)], Loss: 0.427670, Accuracy: 85.324
# Epoch5: [288000/600000 (48%)], Loss: 0.492034, Accuracy: 85.445
# Epoch5: [300000/600000 (50%)], Loss: 0.483341, Accuracy: 85.512
# 5轮loss:0.34879785537846814
# Epoch6: [316000/600000 (53%)], Loss: 0.403696, Accuracy: 85.642
# Epoch6: [332000/600000 (55%)], Loss: 0.338794, Accuracy: 85.755
# Epoch6: [348000/600000 (58%)], Loss: 0.261797, Accuracy: 85.866
# Epoch6: [360000/600000 (60%)], Loss: 0.388965, Accuracy: 85.928
# 6轮loss:0.3327252206199967
# Epoch7: [376000/600000 (63%)], Loss: 0.328161, Accuracy: 86.047
# Epoch7: [392000/600000 (65%)], Loss: 0.323900, Accuracy: 86.125
# Epoch7: [408000/600000 (68%)], Loss: 0.178122, Accuracy: 86.216
# Epoch7: [420000/600000 (70%)], Loss: 0.168413, Accuracy: 86.281
# 7轮loss:0.32073533690687434
# Epoch8: [436000/600000 (73%)], Loss: 0.378456, Accuracy: 86.367
# Epoch8: [452000/600000 (75%)], Loss: 0.415633, Accuracy: 86.440
# Epoch8: [468000/600000 (78%)], Loss: 0.257854, Accuracy: 86.524
# Epoch8: [480000/600000 (80%)], Loss: 0.290295, Accuracy: 86.575
# 8轮loss:0.31478920839488633
# Epoch9: [496000/600000 (83%)], Loss: 0.271015, Accuracy: 86.655
# Epoch9: [512000/600000 (85%)], Loss: 0.185691, Accuracy: 86.715
# Epoch9: [528000/600000 (88%)], Loss: 0.309847, Accuracy: 86.775
# Epoch9: [540000/600000 (90%)], Loss: 0.265732, Accuracy: 86.827
# 9轮loss:0.30563776913100976
# Epoch10: [556000/600000 (93%)], Loss: 0.305607, Accuracy: 86.911
# Epoch10: [572000/600000 (95%)], Loss: 0.279825, Accuracy: 86.958
# Epoch10: [588000/600000 (98%)], Loss: 0.295040, Accuracy: 87.018
# Epoch10: [600000/600000 (100%)], Loss: 0.387007, Accuracy: 87.048
# 10轮loss:0.2976640771383416