在现实的开发场景中,仅仅开发"正确运行的程序"往往不足以满足用户的需求,你的程序可能会在客户所能提供的硬件上运行的很缓慢;你可能只有一个微处理器,却需要满足巨大的性能开销目标;你可能需要在一个性能有限的设备上需要运行一些高级的渲染效果;这时候,你需要优化你的程序,针对一个已有系统的性能优化,根据我们"动手"的不同方向一般有如下几种情况:
**1.算法层面的优化:**简单到我们需要一个排序算法,不同算法的时间复杂度是不同的,甚至于面对不同的需求,选择不同的算法会得到不同的时间复杂度。
**2.代码使用层面的优化:**比如在函数中使用静态变量,由于在同一函数中动态变量只会初始化一次,我们可以对一些需要读取和加载的方式使用静态变量的方式,既可以满足RAII的方式,在使用的时候再加载,也可以实现只加载一次,避免重复加载。
**3.调用热点层面的优化:**在一些场景中,我们会得到一些性能热点,比如某些语句会被多次调用,某些函数会被放在循环里进行调用,这时优化这些热点语句可以起到事半功倍的效果。一般在一个系统中,这些代码热点往往包括IO,创建分配内存等。
面对不同的情况,我们需要不同的手段,这些都是我们手中一些工具:比如并行思想,把一些可以同时进行的工作拆分成不同的线程,用多线程的方式,比如我们需要读取两套不同的配置,而这两套配置互不相关,这时候可以使用多线程的方式,将两套配置的读取拆分到两个线程上,多线程方法和思维在性能优化中是一个很重要的手段,本套学习笔记后续会有很多篇幅介绍C++的并发编程。另外就是本文介绍的缓存思想。
缓存思想最早来源于硬件,最早的思想萌芽可以追溯到上世纪60年代,来自于CPU计算速度远高于内存读写速度,这样应用热点优化的思想,加入一块缓存区域将常用的数据暂时写到上卖弄,硬件上有了"从动存储器"的概念,如今已经发展出"分布式缓存"和"内容分发网络"等概念。
在软件开发层面,缓存思维是对于一些数据,我们可以采取"空间换时间"的思想,把一些需要IO加载的数据提前批量读到内存当中,当使用时,优先从内存中查找,找不到的情况下再去用IO的方式读取。
使用缓存思想,可以减少数据访问路径,从而达到提升性能的效果。比如一个需要加载字体信息的系统使用fontconfig库来读取,读取字体库的代码逻辑需要占用IO,是代码优化的热点,而单次的加载开销是不可避免的,但是我们可以通过缓存来避免重复加载,对于多次使用的字体,可以一直保存在内存之中,如图所示。
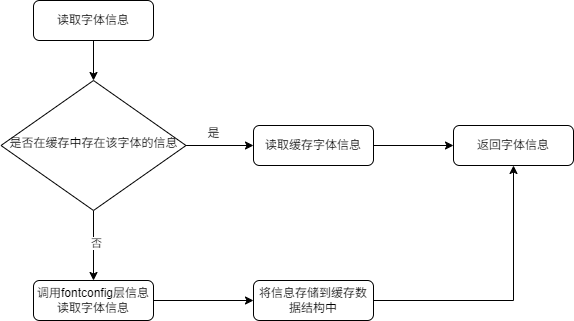
对于读取字体信息的请求,首先在缓存数据结构中获得对应信息,如果存在那么直接返回,如果没有读到,那么继续调用fontconfig的函数来获得字体信息,把字体信息存储到缓存系统中,同时返回这个字体信息。
缓存这个思想,本质上是"时间换空间",然而空间并不能被无限制的使用,因此我们需要更好的缓存策略来有限制的使用内存。所以缓存策略的核心目标,就是利用有限的内存来提升系统的访问效率,这时候就要设计好缓存的淘汰机制,即当内存放不下的时候,需要保留哪些数据,淘汰哪些数据,有一些主流的思路可以参考:
|--------|----------------------------|---------------------|---------------|----------|----------------------|
| 简称 | 描述 | 数据结构 | 时间复杂度 | 空间复杂度 | 适用情况 |
| FIFO | 先进先出,顾名思义,先进入缓存的优先被淘汰 | 队列 | O(1) | 没有额外开销 | 顺序访问,没有数据访问频率优先级 |
| TTL | 有效时间缓存,一旦超过设定的时间,缓存项过期 | 哈希表 时间堆 | O(logn) | 多了对应的哈希表 | 有时效性的访问,比如登录等 |
| Random | 随机选择淘汰数据 | 列表 | O(1) | 没有额外开销 | 没有频率差异的低成本容忍场景 |
| LRU | 淘汰最久未被访问的数据,即链表最末端的数据被最早淘汰 | 哈希表 双向链表 | O(1) | 多了对应的哈希表 | 网络缓存 |
| LFU | 淘汰访问频率最低的数据,淘汰频率最低的项目 | 哈希表(键值对) 哈希表(频率键值对) | O(1)- O(logn) | 多了频率键值对 | 高频访问数据场景(比如微博热搜) |
| ARC | 自适应替换缓存 | 两个双向列表 两个哈希表 | O(1)- O(logn) | 多了一组额外数据 | 结合LRU和LFU优点,缺点是额外空间多 |
其中ARC结合了LRU和LFU优势,在高负载或者不同访问模式下提升内存中缓存项的命中率。通过动态自适应不同场景,比传统的LRU或LFU算法更有效。
ARC的核心就是两套列链表和哈希表数据结构,第一套是LRU结构,首先添加到缓存中的新数据先进入这个链表,第二次访问后进入第二套数据结构,当数据数量超过预定的容量后,选择淘汰机制,通过检查LRU和LFU列表中的数量,来判断这个缓存使用的是数据集较大还是访问频率比较高,如果是数据集较大,则按LRU的规则删除数据最末尾的项目,反之则按照LFU删除访问频率最低的项目,其核心代码为:
cpp
void ARCCache::put(int key, const Data &value) {
Data ignored;
// 更新数据
if (get(key, ignored)) {
mapT2[key].value = value;
return;
}
// 是否已经在LRU列表中
if (mapB1.find(key) != mapB1.end()) {
std::size_t b1 = mapB1.size();
std::size_t b2 = mapB2.size();
std::size_t delta = 1;
if (b1 == 0) delta = (b2 == 0 ? 1 : b2);
else delta = std::max<std::size_t>(b2 / b1, 1);
p = std::min(capacity, p + delta);
replace(key);
B1.erase(mapB1[key]);
mapB1.erase(key);
T2.push_front(key);
mapT2[key] = {value, T2.begin()};
return;
}
// 是否已经在LFU列表中
if (mapB2.find(key) != mapB2.end()) {
std::size_t b1 = mapB1.size();
std::size_t b2 = mapB2.size();
std::size_t delta = 1;
if (b2 == 0) delta = (b1 == 0 ? 1 : b1);
else delta = std::max<std::size_t>(b1 / b2, 1);
p = (p >= delta) ? p - delta : 0;
replace(key);
B2.erase(mapB2[key]);
mapB2.erase(key);
T2.push_front(key);
mapT2[key] = {value, T2.begin()};
return;
}
// 淘汰机制
if (T1.size() + B1.size() == capacity) {
if (T1.size() < capacity) {
int old = B1.back();
B1.pop_back();
mapB1.erase(old);
replace(key);
} else {
int old = T1.back();
T1.pop_back();
mapT1.erase(old);
}
} else {
std::size_t total = T1.size() + T2.size() + B1.size() + B2.size();
if (total >= capacity) {
if (total == 2 * capacity) {
int old = B2.back();
B2.pop_back();
mapB2.erase(old);
}
replace(key);
}
}
T1.push_front(key);
mapT1[key] = {value, T1.begin()};
}这段缓存机制已经被集成到我的Crisp项目中,后续打算参照开源项目将更多缓存策略集成进来,可供开发者缓存使用。