目录
- [1. mysql登录&退出](#1. mysql登录&退出)
-
- [1.1 mysql登录指令](#1.1 mysql登录指令)
- [1.2 mysql退出指令](#1.2 mysql退出指令)
- [1.3 切换root用户再登录](#1.3 切换root用户再登录)
- [2. mysql理解](#2. mysql理解)
- [3. mysql在Linux中的表现](#3. mysql在Linux中的表现)
- [4. 主流数据库介绍](#4. 主流数据库介绍)
- [5. 服务器,数据库,表之间的关系](#5. 服务器,数据库,表之间的关系)
- [6. MySQL架构](#6. MySQL架构)
- [7. SQL分类](#7. SQL分类)
- [8. 存储引擎](#8. 存储引擎)
-
- [8.1 存储引擎](#8.1 存储引擎)
- [8.2 查看存储引擎](#8.2 查看存储引擎)
- [8.3 存储引擎对比](#8.3 存储引擎对比)
1. mysql登录&退出
1.1 mysql登录指令
bash
sudo mysql -h 127.0.0.1 -P 3306 -u root -p
# -h:指明登录部署了mysql服务的主机
# -P:指明我们要访问的端口号
# -u:指明登录用户
# -p:指明需要输入密码注意:
- 目前免密码,后续再设置密码
- 密码输入不回显
由于已经在配置文件中设置了相关参数,可以直接使用以下指令登录
bash
sudo mysql -u root
# 因为目前免密码登录,所以不需要-p选项1.2 mysql退出指令
输入quit,按下Enter即可退出。
1.3 切换root用户再登录
前期学习先使用root用户,root用户切换指令
bash
sudo su root
再次进入mysql就不需要sudo命令了
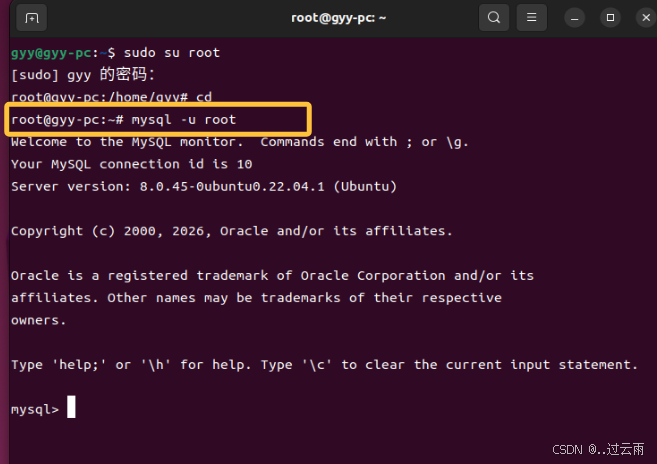
2. mysql理解
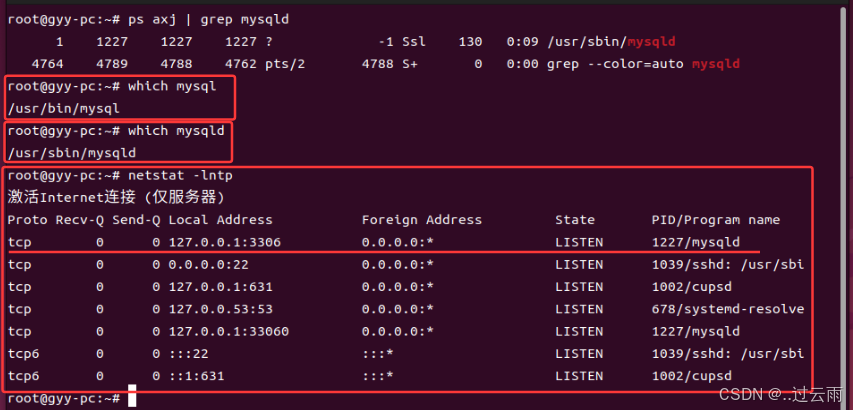
- mysql是它的数据库服务的客户端
- mysqld是它的数据库服务的服务器端
- mysql本质:基于C(mysql) S(mysqld)模式的一种网络服务。
mysql是一套给我提供数据存取的服务的网络程序
数据库:一般指的是,再磁盘或者内存中存储的特定结构组织的数据---将来在磁盘上存储的一套数据库方案
数据库服务:mysqld
问题:为什么不使用文件存储数据?
一般的文件确实提供了数据的存储功能,但是文件没有提供非常好的数据(内容)管理能力(用户角度)
数据库本质:对数据内容从存储的一套解决方案,你给我字段或者要求,我直接给你结果
3. mysql在Linux中的表现
注意:在mysql中使用指令要加分号 " ; "
**样例:**使用mysql建立一个数据库,建立一张表结构,插入一些数据 -- 对比一下mysql在Linux中是如何表现的
样例指令:
- 创建数据库
sql
create database helloworld;- 使用数据库
sql
use helloworld;- 创建数据库表
sql
create table student(
id int,
name varchar(32),
gender varchar(2)
);- 表中插入数据
sql
insert into student (id, name, gender) values (1, '张三', '男');
insert into student (id, name, gender) values (2, '李四', '女');
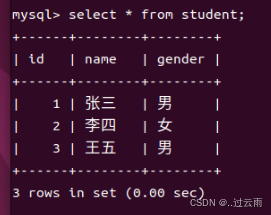
insert into student (id, name, gender) values (3, '王五', '男');- 查询表中的数据
sql
select * from student;样例表现:
- 创建数据库
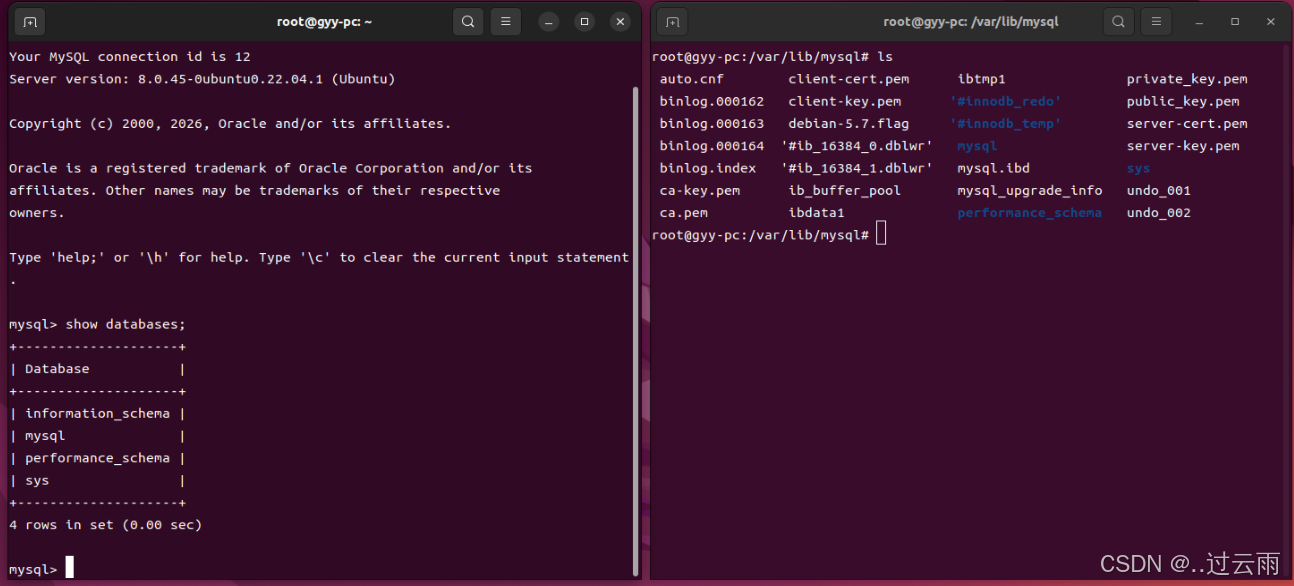
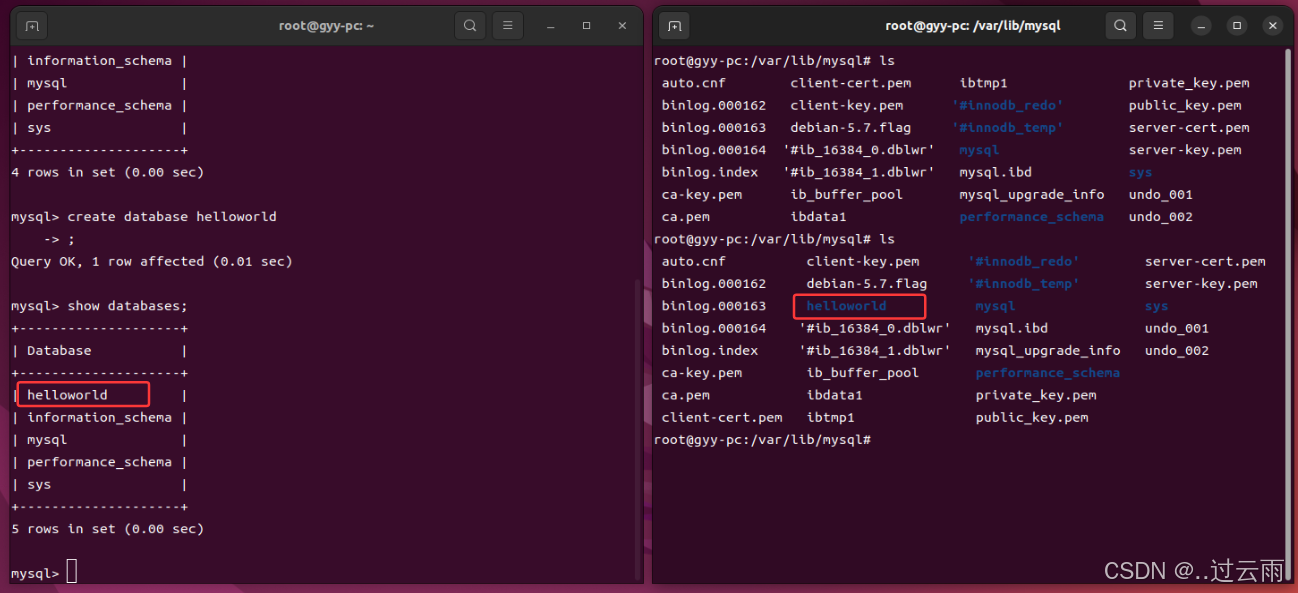
- 在数据库中创建表
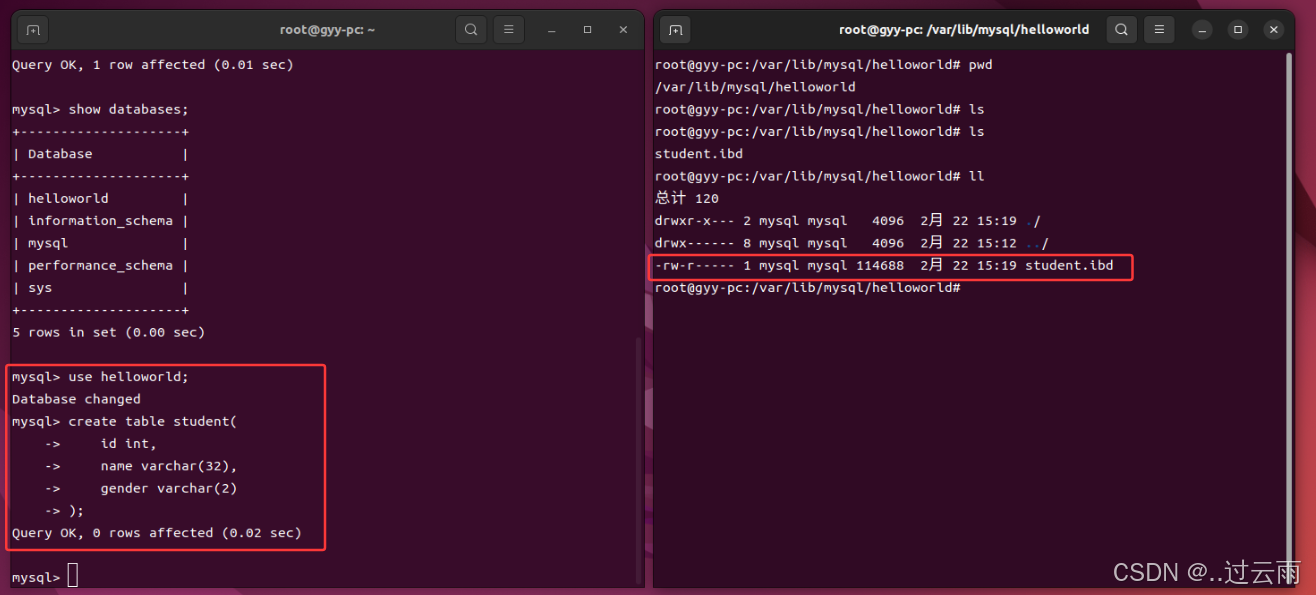
- 数据逻辑存储:行列式结构
结论:
- 建立数据库,本质就是在Linux目录下建立一个目录
- 在数据库内建立表,本质就是在Linux下创建对应的文件
- 数据可本质其实也是文件,只不过这些文件并不是由程序员直接操作,而是由数据库服务(mysqld)帮我们进行操作
4. 主流数据库介绍
SQL Server:微软的产品,是.NET 开发者常用的数据库之一,广泛应用于中大型企业级项目,对 Windows 平台和.NET 生态有极佳的适配性。
Oracle:甲骨文(Oracle)公司的核心产品,适用于超大型企业级项目和复杂的业务场景,在数据一致性、安全性和复杂事务处理上表现优异;在高并发场景下,其原生性能通常不如针对高并发优化的 MySQL,但通过合理的架构设计(如读写分离、分片)可显著提升并发能力。
MySQL:全球使用最广泛的开源关系型数据库之一,目前归属甲骨文公司;高并发处理能力突出,并非 "不适合做复杂的业务",而是在超复杂的分布式事务、极致的复杂查询优化场景下,相比 Oracle 的适配成本更高;主要应用于电商、SNS(社交网络)、论坛等互联网场景,对高频简单 SQL 的处理效率优势明显,也可通过架构扩展支撑复杂业务。
PostgreSQL:由加州大学伯克利分校计算机系研发的开源关系型数据库,支持私用、商用及学术研究场景,可免费使用、修改和分发;在复杂数据类型(如 JSON、地理信息)、自定义函数 / 存储过程、事务一致性等方面表现优异,被称为 "最先进的开源关系型数据库"。
SQLite:一款轻量级嵌入式关系型数据库,完全遵守 ACID(原子性、一致性、隔离性、持久性)原则,核心功能封装在一个小型 C 语言库中;设计目标为嵌入式场景,已广泛应用于各类嵌入式产品、移动端应用(如 Android/iOS 本地存储);占用系统资源极低,在嵌入式设备中仅需几百 KB 内存即可稳定运行。
H2:由 Java 语言开发的嵌入式关系型数据库,以 Jar 包形式提供(仅需引入单个类库),可直接嵌入 Java 应用程序中运行;支持内存模式(数据仅存于内存)和文件模式(数据持久化到文件),常用于开发、测试环境,也可作为小型应用的生产数据库。
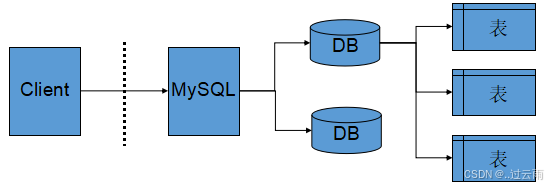
5. 服务器,数据库,表之间的关系
安装数据库服务器,本质是在服务器(物理机 / 虚拟机)上部署了一套数据库管理系统(DBMS) 程序(如 MySQL、Oracle、SQL Server 等)。该管理系统具备多数据库管理能力,在实际开发中,开发人员通常会为每个独立的应用系统创建一个专属数据库,实现不同应用数据的隔离管理。
为存储应用系统中各类业务实体(如用户、商品、订单)的数据,开发人员会在对应数据库中创建多张数据表。每张表对应一类业务实体,用于结构化存储该实体的所有属性数据(如 "用户表" 存储用户名、密码、手机号等用户信息)。
数据库服务器、数据库和数据表的层级关系可总结为:
- 数据库服务器(DBMS 程序)是顶层管理载体,可管理多个独立数据库;
- 数据库是数据隔离单元,为单个应用系统服务,包含多张数据表;
- 数据表是数据存储的最小单元,对应具体业务实体,承载实际业务数据。
6. MySQL架构
MySQL 是一款高度可移植的开源关系型数据库管理系统,几乎能运行在当前主流的所有操作系统之上,包括 Unix/Linux 系列(如 CentOS、Ubuntu)、Windows、macOS 以及 Solaris 等。尽管不同操作系统在底层内核、文件系统、进程管理等实现层面存在显著差异,但 MySQL 通过统一的抽象层设计,基本能保证在各平台上逻辑架构与核心功能的一致性,物理存储结构也保持高度兼容。
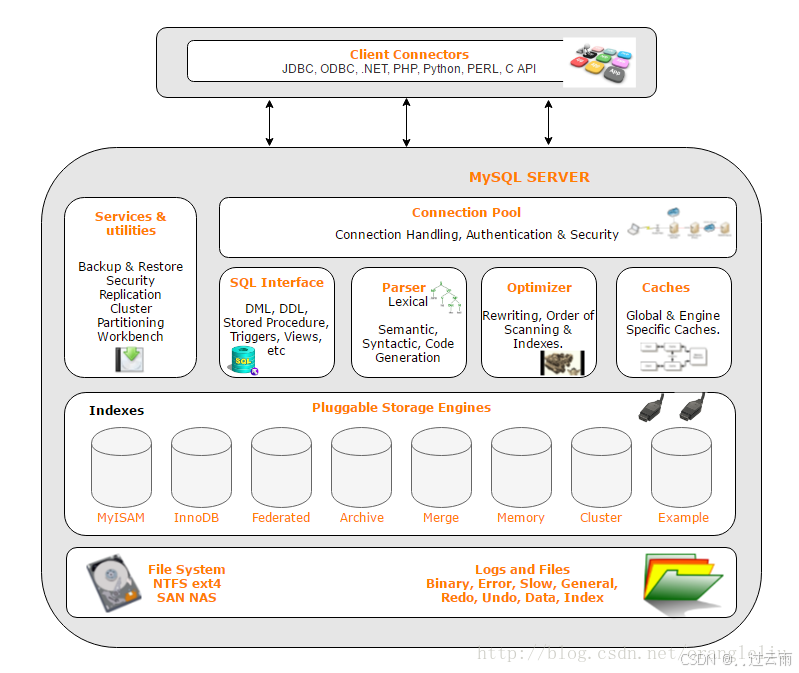
1.客户端连接层(Client Connectors)
这是应用与 MySQL 交互的入口,提供了多种编程语言的驱动和连接方式:
- 支持的协议 / 语言:JDBC(Java)、ODBC、.NET、PHP、Python、Perl、C API 等。
- 作用:让不同技术栈的应用程序能通过标准接口连接到 MySQL 服务器,发送 SQL 请求并接收结果。
2.MySQL 服务层(MySQL SERVER)
这是 MySQL 的核心大脑,负责处理所有 SQL 请求,主要分为以下子模块:
2.1 连接池(Connection Pool)
- 职责:管理客户端连接、处理身份验证、权限检查和安全控制。
- 作用:避免频繁创建 / 销毁连接,提升性能,同时保障访问安全。
2.2 SQL 接口(SQL Interface)
- 职责:接收并解析 DML(数据操作)、DDL(数据定义)语句,以及存储过程、触发器、视图等高级对象的调用。
- 作用:提供统一的 SQL 交互入口。
2.3 解析器(Parser)
- 职责:对 SQL 语句进行词法分析(Lexical)、语义分析(Semantic)和语法检查(Syntactic),生成语法树和可执行代码。
- 作用:确保 SQL 语句的合法性,并为后续优化做准备。
2.4 优化器(Optimizer)
- 职责:重写查询语句、决定扫描顺序、选择最优索引,生成执行计划。
- 作用:通过各种策略最大化查询性能。
2.5 缓存(Caches)
- 职责:维护全局和引擎特定的缓存,如查询缓存(已废弃)、表缓存、键缓存等。
- 作用:缓存热点数据和元数据,减少磁盘 I/O,提升响应速度。
2.6 服务与工具(Services & utilities)
- 职责:提供备份恢复、安全管理、复制、分区、集群和 Workbench 等管理工具。
- 作用:支撑数据库的日常运维、高可用和扩展需求。
3.可插拔存储引擎层(Pluggable Storage Engines)
这是 MySQL 架构最独特的设计之一:
- 特点:存储引擎是可插拔的,不同引擎负责数据的实际存储和检索,上层服务层与底层存储逻辑解耦。
- 常见引擎:
- InnoDB:默认引擎,支持事务、外键、崩溃恢复,适合绝大多数生产场景。
- MyISAM:不支持事务,查询速度快,适合读多写少的场景。
- Memory:数据存储在内存中,速度极快,但重启后数据丢失。
- 其他:Federated、Archive、Merge、Cluster、Example 等,各有其特定适用场景。
4.文件系统与日志层(File System & Logs)
- 文件系统:数据最终存储在磁盘上,支持 NTFS、ext4、SAN、NAS 等多种文件系统。
- 日志与文件 :
- 二进制日志(Binary):记录数据变更,用于主从复制和时间点恢复。
- 错误日志(Error):记录服务器启动、运行和关闭时的错误信息。
- 慢查询日志(Slow):记录执行时间超过阈值的 SQL,用于性能优化。
- Redo/Undo 日志:保障事务的原子性和持久性(InnoDB 核心)。
- 数据文件、索引文件:实际存储表数据和索引。
总结
这张图清晰地展示了 MySQL 从客户端连接 到服务层处理 ,再到存储引擎落地 ,最后到文件系统持久化的完整流程。这种分层架构让 MySQL 既灵活(可插拔引擎)又高效(连接池、查询优化),是其成为最流行开源数据库的重要原因。
7. SQL分类
-
DDL(Data Definition Language)------ 数据定义语言
核心作用:用于定义、修改、删除数据库对象的结构(而非数据本身),维护存储数据的底层结构。
代表指令:CREATE(创建)、DROP(删除)、ALTER(修改)、TRUNCATE(清空表结构 + 数据)、RENAME(重命名)等。
适用对象:数据库(Database)、表(Table)、索引(Index)、视图(View)、存储过程(Procedure)等。
-
DML(Data Manipulation Language)------ 数据操纵语言
核心作用:用于对数据库表中的实际数据进行增、删、改操作(不含查询)。
代表指令:INSERT(插入数据)、DELETE(删除数据)、UPDATE(修改数据)。
-
DQL(Data Query Language)------ 数据查询语言
核心作用:专门用于从数据库中查询、检索数据,是日常使用频率最高的 SQL 类型(行业中常将其从 DML 中独立划分)。
代表指令:SELECT(查询),常配合 WHERE、JOIN、GROUP BY、ORDER BY 等子句使用。
-
DCL(Data Control Language)------ 数据控制语言
核心作用:负责数据库的权限管理、事务控制,保障数据访问的安全性和一致性。
代表指令:
- 权限管理:GRANT(授予权限)、REVOKE(回收权限);
- 事务控制:COMMIT(提交事务)、ROLLBACK(回滚事务)、SAVEPOINT(设置事务保存点)。
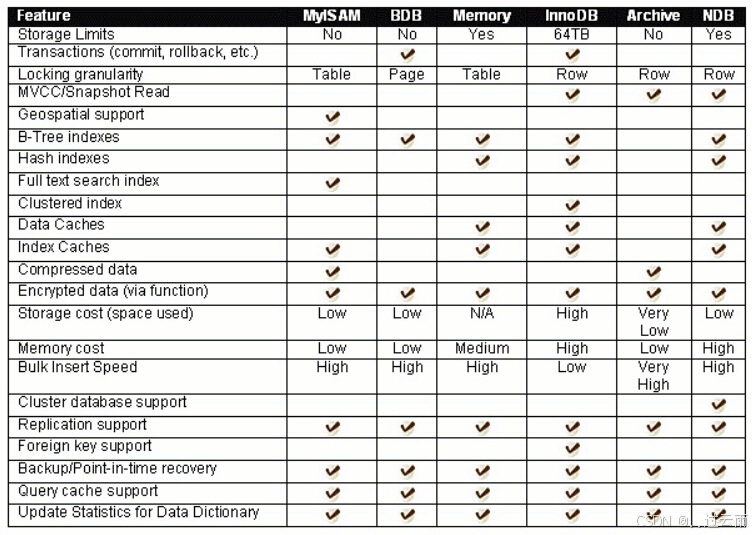
8. 存储引擎
8.1 存储引擎
存储引擎是:数据库管理系统如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术
的实现方法。
MySQL的核心就是插件式存储引擎,支持多种存储引擎。
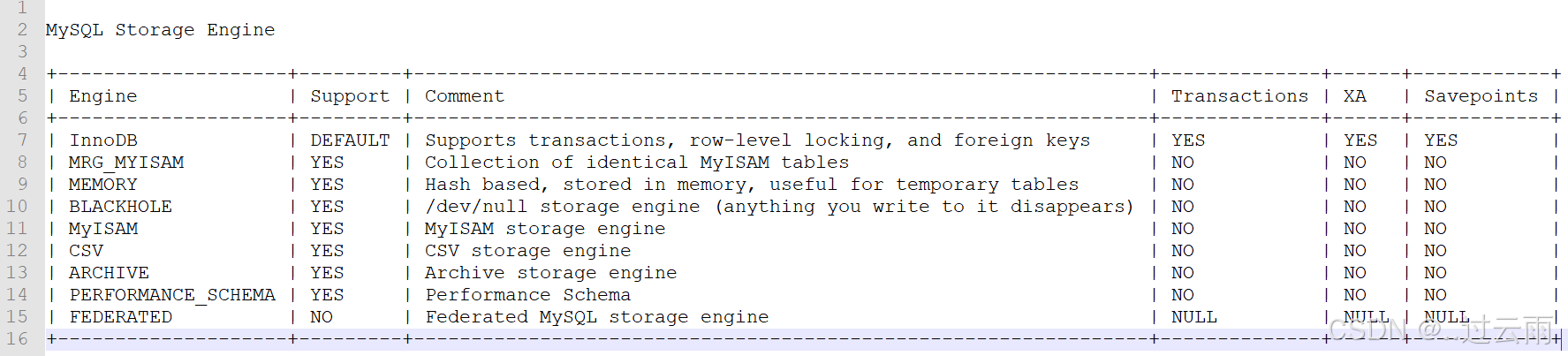
8.2 查看存储引擎
sql
show engines;