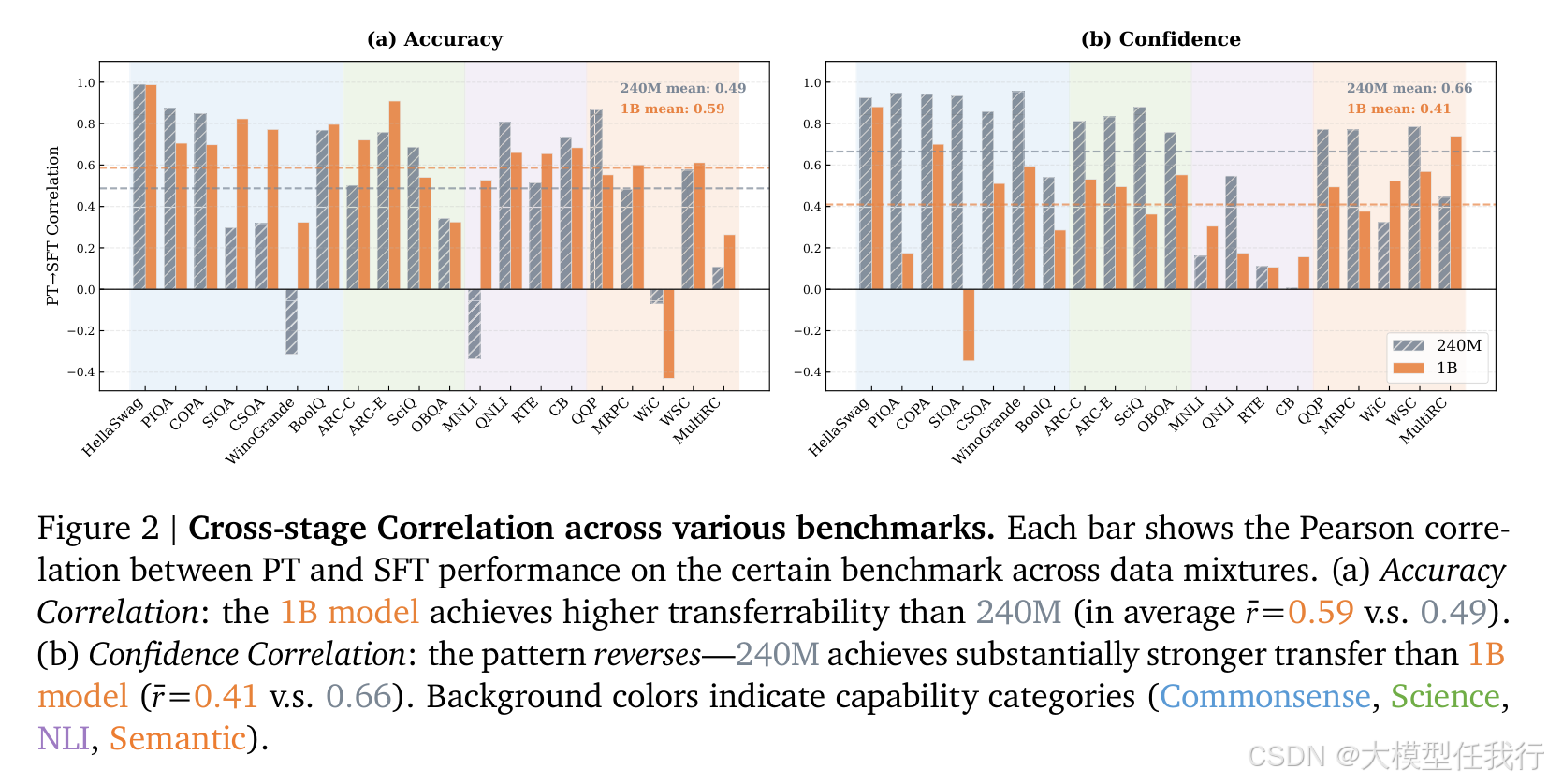
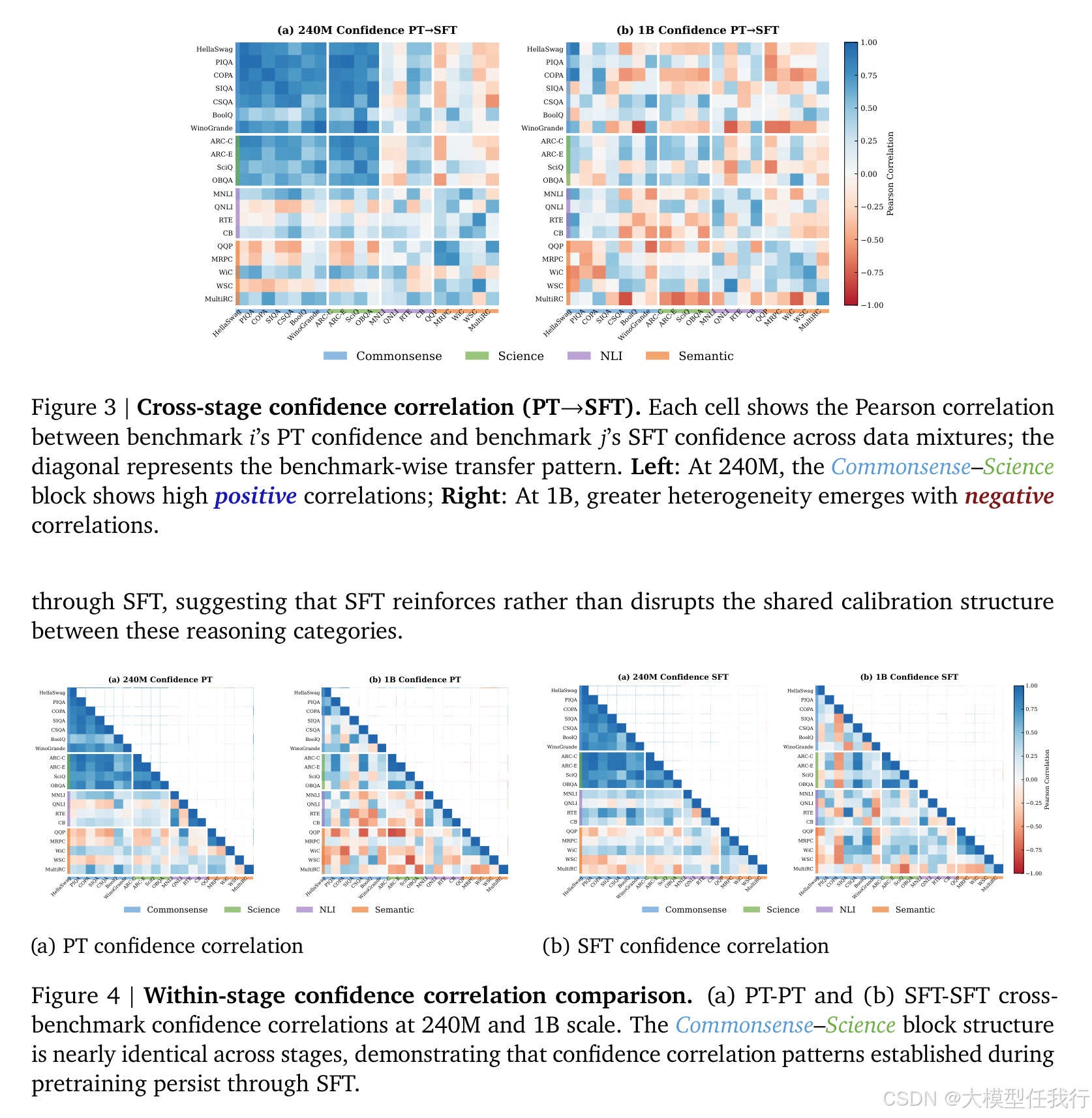
📖标题:The Magic Correlations: Understanding Knowledge Transfer from Pretraining to Supervised Fine-Tuning
🌐来源:arXiv, 2602.11217v1
🌟摘要
了解语言模型能力如何从预训练转移到监督微调(SFT)对于高效的模型开发和数据管理至关重要。在这项工作中,我们研究了四个核心问题:RQ1。在SFT之后,预训练期间建立的准确性和置信度排名在多大程度上持续存在?RQ2。哪些基准作为鲁棒的跨阶段预测器,哪些不可靠?RQ3。转移动态如何随着模型规模而变化?RQuar。作为校准质量的衡量标准,模型置信度与准确性的一致性如何?这种对齐模式是否会在训练阶段转移?我们通过一套应用于不同数据混合物和模型尺度的准确性和置信度指标的相关协议来解决这些问题。我们的实验表明,转移可靠性在能力类别、基准和规模之间差异很大------准确性和置信度表现出不同的、有时是相反的缩放动态。这些发现揭示了预训练决策和下游结果之间复杂的相互作用,为基准选择、数据管理和高效模型开发提供了可操作的指导。
🛎️文章简介
🔸研究问题:预训练阶段获得的能力和置信度模式,在监督微调(SFT)后是否仍能可靠预测下游性能?
🔸主要贡献:论文系统揭示了准确性与置信度在跨阶段迁移中呈现逆向尺度规律,且迁移可靠性高度依赖能力类别、基准任务和模型规模,为基准选择与数据构建提供实证指南。
📝重点思路
🔸提出五类相关性分析协议:跨阶段准确率/置信度相关性、类别内一致性、跨基准迁移一致性、性能-置信对齐度,从多维度量化能力迁移稳定性。
🔸在240M和1B两种规模模型上,遍历9种预训练数据混合(覆盖不同网络来源、教育过滤强度与代码比例),统一采用Tulu-v2-mix进行SFT。
🔸评估20个基准任务,按常识推理、科学推理、自然语言推理、语义理解四类能力分组,分别计算准确率、置信度及二者对齐度(r_align)。
🔸引入"置信结构相似性"分析------比较预训练与SFT阶段各基准间置信度相关性矩阵的皮尔逊相关性,检验校准模式的整体保留程度。
🔎分析总结
🔸准确性迁移随模型增大而增强(1B平均r=0.59 > 240M的0.49),但置信度迁移却显著减弱(240M r=0.66 > 1B的0.41),证实二者反映不同迁移机制。
🔸常识与科学类任务跨阶段迁移稳健(r>0.7),而NLI与语义类任务迁移弱甚至为负(如WiC、MNLI在240M时r<−0.3),不宜作为早期代理指标。
🔸小模型存在"类别内竞争"(如优化HellaSwag会损害WinoGrande),大模型则转向"类别内协同",尤其科学类PT→SFT一致性从0.24升至0.50。
🔸科学任务始终高对齐(r_align≈0.8),常识与语义任务普遍负对齐(r≈−0.1~−0.4),表明其置信度反映表层模式而非真实理解。
🔸教育过滤(FineWeb-Edu)效果随规模反转:在240M提升NLI准确率但严重损害校准(Δr=−0.80),在1B则准确率下降而校准略有改善。
💡个人观点
论文摒弃单一性能指标,转而用多维相关性谱系刻画知识迁移的特征,揭示准确率与置信度迁移的尺度解耦现象,强调能力类别特异性与数据-规模交互效应。
🧩附录