
作者:逆境不可逃
技术永无止境
希望我的内容可以帮助到你!!!!!
大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】规划与协调篇 之 Skills:按需加载的领域知识框架》.
Learn-Claude-Code 官方地址 : https://github.com/shareAI-lab/learn-claude-code
Skills 是迭代的第 5 个版本(s05),核心解决 系统提示词臃肿、知识加载效率低 的问题。它用「两层注入 + 按需加载」的方式,让 Agent 只在需要时加载特定领域的知识,既保证了提示词缓存效率,又避免了无关知识的 token 浪费。
学习路线:s01 > s02 > s03 > s04 > s05 > s06 | s07 > s08 > s09 > s10 > s11 > s12
一、问题根源:为什么直接塞系统提示会越用越慢?
当你希望 Agent 遵循特定领域的工作流时(如 Git 约定、测试模式、代码审查清单),传统做法是把所有规则全塞进系统提示词:
- 10 个 Skill,每个 2000 token,直接占用 20,000 token
- 大部分知识跟当前任务毫无关系(比如修复 Python Bug 时,Kubernetes 部署的规则完全没用)
- 每次新增 / 修改 Skill 都会改变系统提示词,导致 Anthropic、OpenAI 的 prompt caching 失效,API 调用成本飙升、响应变慢
二、三大核心设计决策(图片内容详解)
Skills 框架通过三个关键设计,完美解决了上述问题,每个决策都对比了替代方案的缺陷。
1. Skill 通过 tool_result 注入,而非系统提示词
核心设计 :当 Agent 调用 load_skill 工具时,Skill 的完整内容(SKILL.md 正文)会作为 tool_result 在用户消息中返回,而不是直接注入系统提示词。
两大关键优势:
- 保持系统提示词可缓存:系统提示词在各轮对话中保持静态,API 提供商的 prompt caching 可以正常工作,大幅降低成本和延迟
- 按需注入知识:只有 Agent 需要的 Skill 才会被加载到上下文中,无关知识不会占用 token 空间
替代方案的致命缺陷:
把 Skill 直接注入系统提示词实现更简单,也能让模型优先关注这些知识,但会破坏 prompt caching(每次加载新 Skill 都会生成新的系统提示词变体),而且随着 Skill 增多,系统提示词会越来越臃肿。
tool_result方案牺牲了一点点注意力优先级,换来了缓存友好和 token 效率。
2. 按需加载 Skill,而非预加载
核心设计 :Skill 不会在 Agent 启动时加载,初始只在系统提示词中保留 Skill 的名称和简短描述(来自 YAML frontmatter)。当 Agent 判断需要特定 Skill 时,再调用 load_skill 工具加载完整内容。
解决的核心问题:
- 保持初始提示词的精简,避免无关知识浪费上下文窗口
- 让 Agent 「用什么、拿什么」,修复 Python Bug 时不会加载 Kubernetes 部署的 Skill,既省 token 又避免模型被无关指令干扰
替代方案的致命缺陷:
预加载所有 Skill 能保证模型随时获取所有知识,但会在无关技能上浪费大量 token,甚至可能超出上下文限制;推荐系统(模型建议技能、人工审批)会增加延迟。懒加载(按需加载)让模型在需要时自助获取知识,是最务实的方案。
3. SKILL.md 采用 YAML Frontmatter + Markdown 正文
核心设计 :每个 SKILL.md 文件分为两部分:
- YAML frontmatter:存储元数据(名称、描述、标签、适用文件 glob 模式),作为「Skill 注册表」的数据源
- Markdown 正文:存储完整的技能指令、工作流、最佳实践,是按需加载的有效负载
这种分离让你可以列出 100 个 Skill(每个仅需几字节的 frontmatter),而不必一次性加载 100 套完整指令集(每套可能数千 token)。
替代方案的致命缺陷:
用单独的元数据文件(
skill.yaml+skill.md)也能实现,但会让文件数量翻倍;把元数据嵌入 Markdown(作为标题或注释)需要解析整个文件才能提取元数据。Frontmatter 是 Jekyll、Hugo 等静态站点生成器广泛采用的成熟约定,能让元数据和内容共存,同时又能被单独解析。
三、系统整体架构与工作原理
1. 核心架构:两层注入模型
System prompt (Layer 1 -- always present):
+--------------------------------------+
| You are a coding agent. |
| Skills available: |
| - git: Git workflow helpers | ~100 tokens/skill
| - test: Testing best practices |
+--------------------------------------+
When model calls load_skill("git"):
+--------------------------------------+
| tool_result (Layer 2 -- on demand): |
| <skill name="git"> |
| Full git workflow instructions... | ~2000 tokens
| Step 1: ... |
| </skill> |
+--------------------------------------+- 第一层(低成本):系统提示词中只放 Skill 的名称和简短描述,每个仅需约 100 token,让模型知道「有什么可用」
- 第二层(按需加载) :当模型需要时,通过
load_skill工具在tool_result中注入完整的 Skill 内容,仅在需要时占用 token
2. 关键组件与工作流程
(1) SkillLoader:技能加载与解析器
class SkillLoader:
def __init__(self, skills_dir: Path):
self.skills_dir = skills_dir
self.skills = {}
self._load_all()
def _load_all(self):
"""递归扫描所有 SKILL.md 文件,解析 frontmatter 和正文"""
if not self.skills_dir.exists():
return
for f in sorted(self.skills_dir.rglob("SKILL.md")):
text = f.read_text()
meta, body = self._parse_frontmatter(text)
name = meta.get("name", f.parent.name)
self.skills[name] = {"meta": meta, "body": body, "path": str(f)}
def _parse_frontmatter(self, text: str) -> tuple:
"""解析 YAML frontmatter(--- 之间的部分)"""
match = re.match(r"^---\n(.*?)\n---\n(.*)", text, re.DOTALL)
if not match:
return {}, text
try:
meta = yaml.safe_load(match.group(1)) or {}
except yaml.YAMLError:
meta = {}
return meta, match.group(2).strip()
def get_descriptions(self) -> str:
"""第一层:生成系统提示词中的技能列表(仅元数据)"""
if not self.skills:
return "(no skills available)"
lines = []
for name, skill in self.skills.items():
desc = skill["meta"].get("description", "No description")
tags = skill["meta"].get("tags", "")
line = f" - {name}: {desc}"
if tags:
line += f" [{tags}]"
lines.append(line)
return "\n".join(lines)
def get_content(self, name: str) -> str:
"""第二层:返回完整的技能正文,用于 tool_result"""
skill = self.skills.get(name)
if not skill:
return f"Error: Unknown skill '{name}'. Available: {', '.join(self.skills.keys())}"
return f"<skill name=\"{name}\">\n{skill['body']}\n</skill>"(2) 系统提示词初始化
# 第一层:技能元数据注入系统提示词
SYSTEM = f"""You are a coding agent at {WORKDIR}.
Use load_skill to access specialized knowledge before tackling unfamiliar topics.
Skills available:
{SKILL_LOADER.get_descriptions()}"""(3) 工具注册:load_skill 工具
TOOL_HANDLERS = {
# 基础工具(bash、read_file 等)
"bash": lambda **kw: run_bash(kw["command"]),
"read_file": lambda **kw: run_read(kw["path"], kw.get("limit")),
"write_file": lambda **kw: run_write(kw["path"], kw["content"]),
"edit_file": lambda **kw: run_edit(kw["path"], kw["old_text"], kw["new_text"]),
# 新增的技能加载工具
"load_skill": lambda **kw: SKILL_LOADER.get_content(kw["name"]),
}
TOOLS = [
# 其他工具(略)
{"name": "load_skill", "description": "Load specialized knowledge by name.",
"input_schema": {"type": "object", "properties": {"name": {"type": "string", "description": "Skill name to load"}}, "required": ["name"]}},
](4) Agent 主循环:处理工具调用
def agent_loop(messages: list):
while True:
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,
)
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return
results = []
for block in response.content:
if block.type == "tool_use":
handler = TOOL_HANDLERS.get(block.name)
try:
output = handler(**block.input) if handler else f"Unknown tool: {block.name}"
except Exception as e:
output = f"Error: {e}"
print(f"> {block.name}:")
print(str(output)[:200])
results.append({"type": "tool_result", "tool_use_id": block.id, "content": str(output)})
messages.append({"role": "user", "content": results})(5) 执行流程
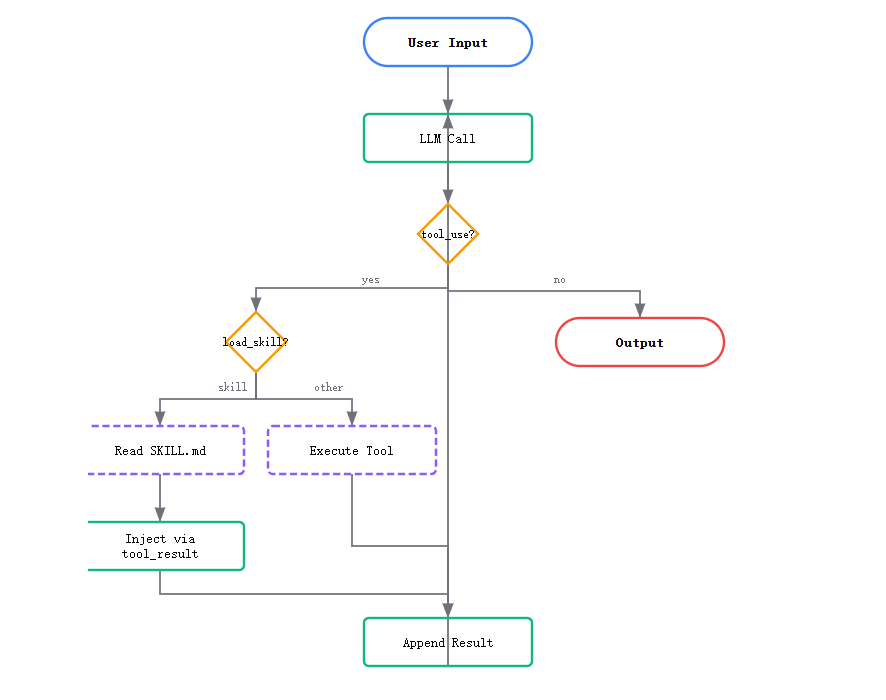
四、与 Subagent(s04)的关键变更对比
| 组件 | 之前(s04 Subagent) | 之后(s05 Skills) |
|---|---|---|
| 工具集 | 5 个工具(基础 + task) |
5 个工具(基础 + load_skill) |
| 系统提示词 | 静态字符串 | 新增 Skill 描述列表(元数据) |
| 知识库 | 无 | skills/*/SKILL.md 文件集合 |
| 知识注入方式 | 无 | 两层模型:系统提示词(元数据)+ tool_result(正文) |
| 核心优化 | 上下文隔离 | 按需知识加载、提示词缓存友好 |
五、核心优势与创新点
- 极致的 token 效率:初始提示词仅加载元数据,完整知识只在需要时注入,大幅降低平均 token 消耗
- 缓存友好的系统提示词:系统提示词保持静态,充分利用 API 提供商的 prompt caching,降低成本和延迟
- 可扩展的知识管理 :新增 / 修改 Skill 只需添加 / 编辑
skills/目录下的文件,无需修改代码,也不会破坏缓存 - 结构清晰的技能定义:YAML frontmatter + Markdown 正文的模式,兼顾了元数据的可解析性和内容的可读性
- 模型自主性与可控性平衡:模型根据任务需求自主决定加载哪些 Skill,系统不强制注入无关知识,同时避免了预加载的臃肿问题
六、运行示例
假设用户输入:"提交本次修改到 Git,遵循项目的提交规范",Agent 的典型执行流程:
- 模型查看系统提示词中的技能列表,看到有
git技能(描述为「Git workflow helpers」) - 模型判断需要加载
git技能,调用load_skill("git")工具 SkillLoader返回git/SKILL.md的完整内容(包含提交规范、Git 命令模板等),作为tool_result加入上下文- 模型根据加载的 Git 技能内容,执行
git add、git commit等命令,输出符合规范的提交信息 - 后续对话中,
git技能的内容会保留在上下文中,无需重复加载(直到对话重置)
七、可扩展方向
- 技能依赖管理 :在 frontmatter 中添加
depends_on字段,实现技能之间的依赖加载(如部署技能依赖于 Git 技能) - 技能版本控制:为每个 Skill 添加版本号,Agent 可指定加载特定版本的技能
- 技能过滤 :根据当前任务类型(如
bugfix/feature)自动推荐相关技能,减少模型选择成本 - 技能缓存:将常用技能的正文缓存到内存,避免重复读取文件
