4.1 Deep Retrieval
经典双塔模型把用户、物品表示为向量,线上做最近邻查找。
Deep Retrieval把物品表征为路径(path),线上查找用户最匹配的路径。
4.1.1 物品表征为路径
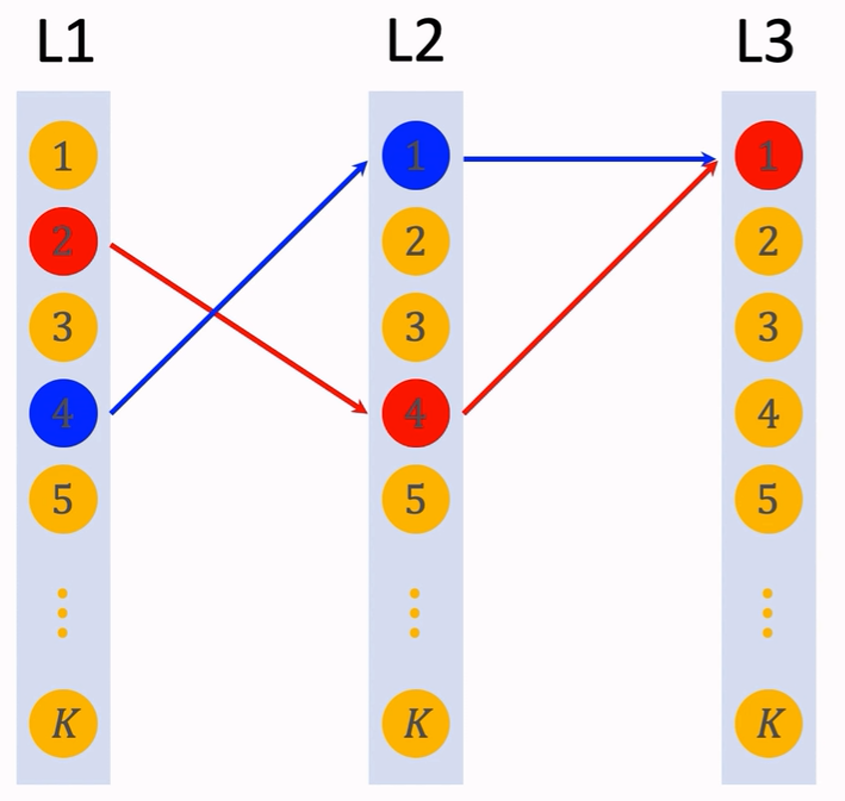
Deep Retrieval中,有depth层节点,每一层有K个节点。从每一层中选出一个节点,共选出depth个节点,形成一条路径。(图示中depth=3)
图中2,4,1和4,1,1分别为一条路径。
一个物品表示为一个路径,也可以表示为多个路径。
4.1.2 物品到路径的索引
索引:item→Listpath
一个物品对应多条路径。通常用depth个节点表示一条路径,当depth=3时,一个path可以表示为a,b,c。
4.1.3 路径到物品的索引
索引:path→Listitem
一条路径对应多个物品。
4.1.4 预估模型
下面内容均以depth=3为例。
通过预估模型预估用户对路径的兴趣。
- 用3个节点表示一条路径:path=a,b,c;
- 给定用户特征 x x x,预估用户对节点 a a a的兴趣 p 1 ( a ∣ x ) p_1(a|x) p1(a∣x);
- 给定 x , a x,a x,a,预估用户对节点 b b b的兴趣 p 2 ( b ∣ a ; x ) p_2(b|a;x) p2(b∣a;x);
- 给定 x , a , b x,a,b x,a,b,预估用户对节点 c c c的兴趣 p 3 ( c ∣ a , b ; x ) p_3(c|a,b;x) p3(c∣a,b;x)。
预估用户对path=a,b,c兴趣:
p ( a , b , c ∣ x ) = p 1 ( a ∣ x ) p 2 ( b ∣ a ; x ) p 3 ( c ∣ a , b ; x ) p(a,b,c|x)=p_1(a|x)p_2(b|a;x)p_3(c|a,b;x) p(a,b,c∣x)=p1(a∣x)p2(b∣a;x)p3(c∣a,b;x)
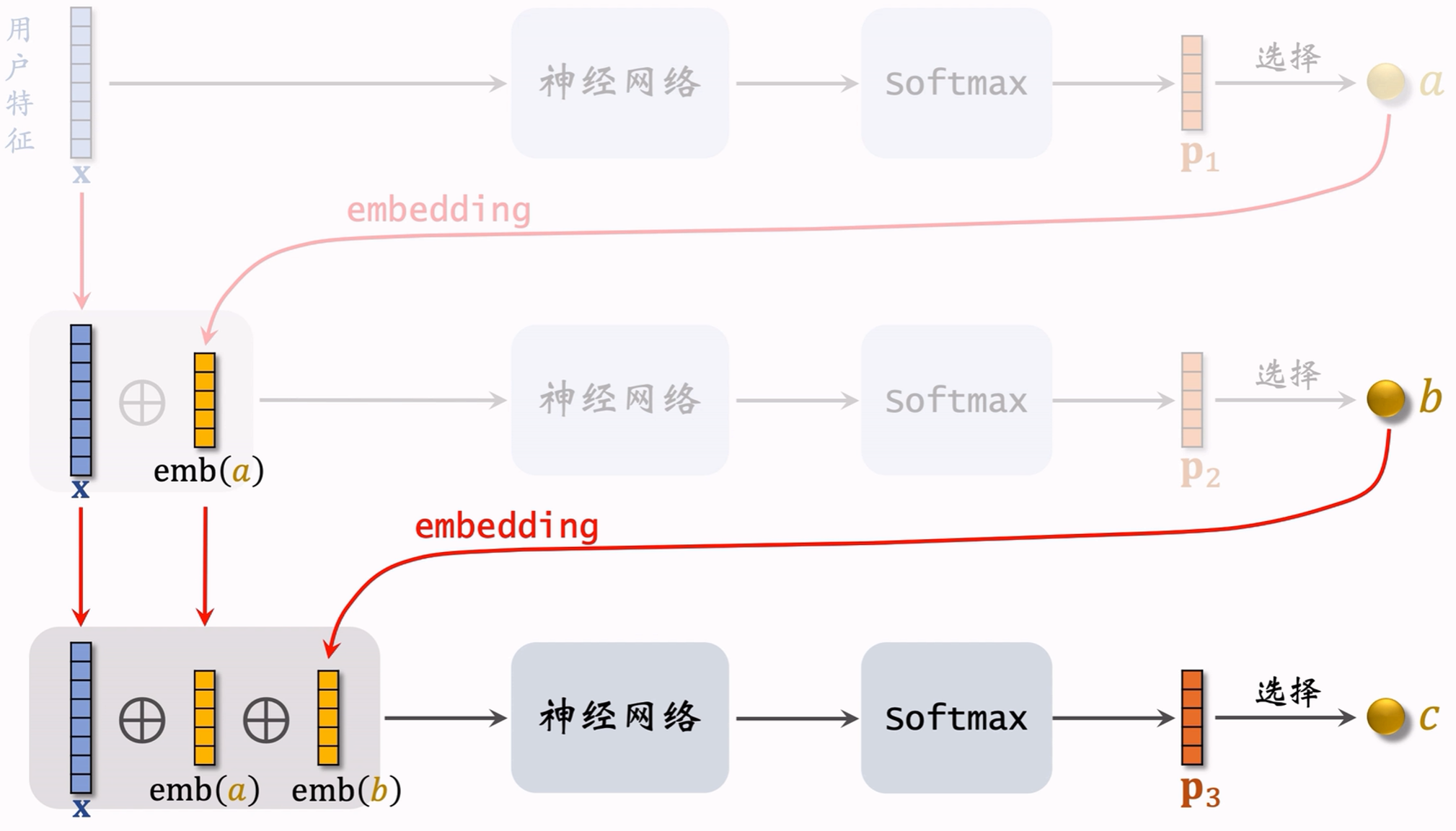
注:图中3个神经网络不共用参数,是3个不同的网络,分别负责预测第1,2,3层的p值。
4.1.5 线上召回
召回流程:
- 给定用户特征,用beam search召回一批路径;
- 利用索引"path→Listitem"召回一批物品;
- 对物品做打分和排序,选出一个子集。
4.1.6 Beam Search
3层,每层 K K K个节点时,一共有 K 3 K^3 K3条路径,此时用神经网络给 K 3 K^3 K3条路经打分,计算开销很大。
做法:采用Beam Search贪心地减小计算量。
Beam Search简述:预测完每一层的路径分数后,选取beam size条分数最大的路径,用于下一层的路径计算。
因此,beam size越大,计算量越大,但是回归越准确。
beam size取值为1时
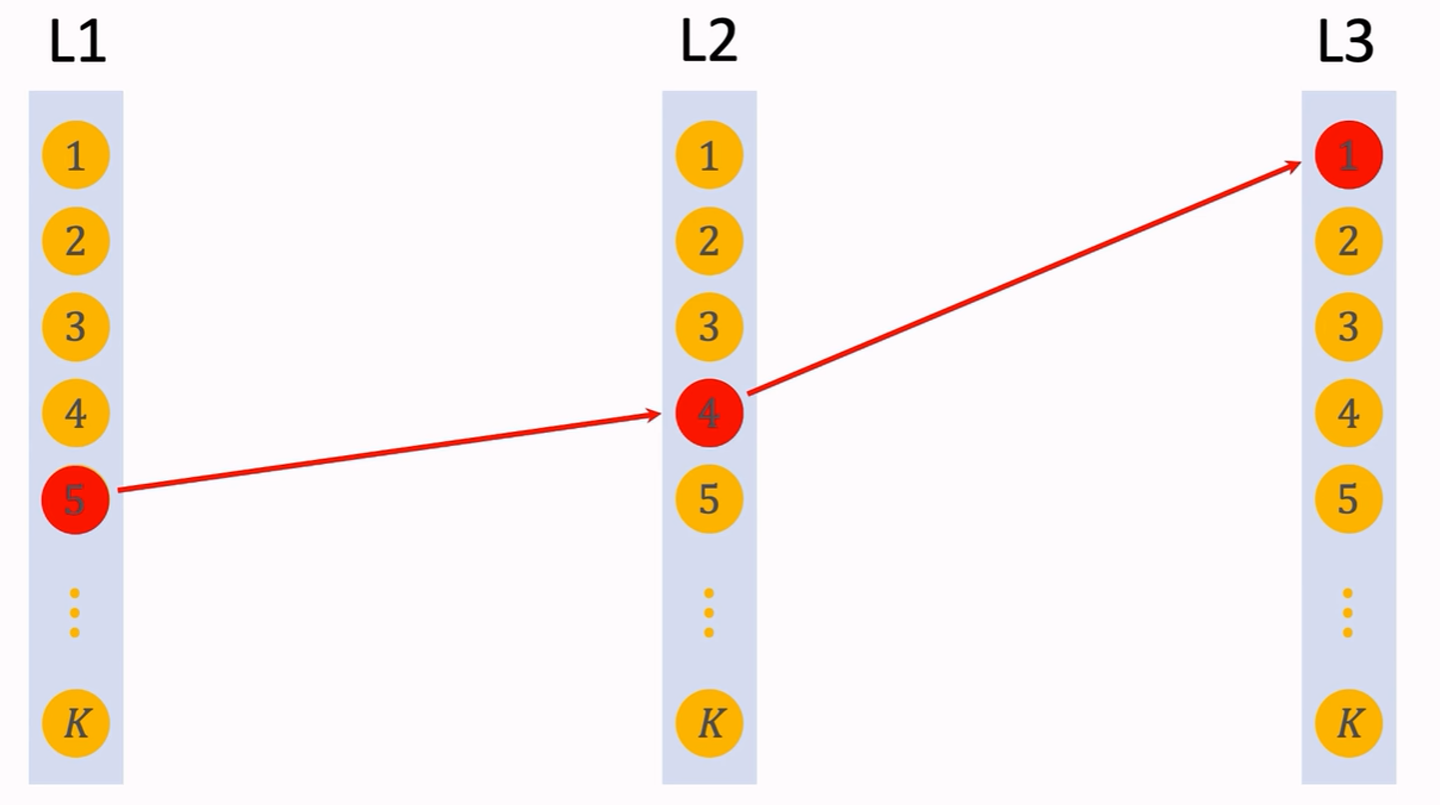
用户对path=a,b,c兴趣:
p ( a , b , c ∣ x ) = p 1 ( a ∣ x ) p 2 ( b ∣ a ; x ) p 3 ( c ∣ a , b ; x ) p(a,b,c|x)=p_1(a|x)p_2(b|a;x)p_3(c|a,b;x) p(a,b,c∣x)=p1(a∣x)p2(b∣a;x)p3(c∣a,b;x)
选择最优的路径:
a ∗ , b ∗ , c ∗ = arg max a , b , c p ( a , b , c ∣ x ) a\^\*,b\^\*,c\^\*=\argmax_{a,b,c} p(a,b,c|x) a∗,b∗,c∗=a,b,cargmaxp(a,b,c∣x)
贪心算法(beam size=1)选中的路径a,b,c未必是最优解。
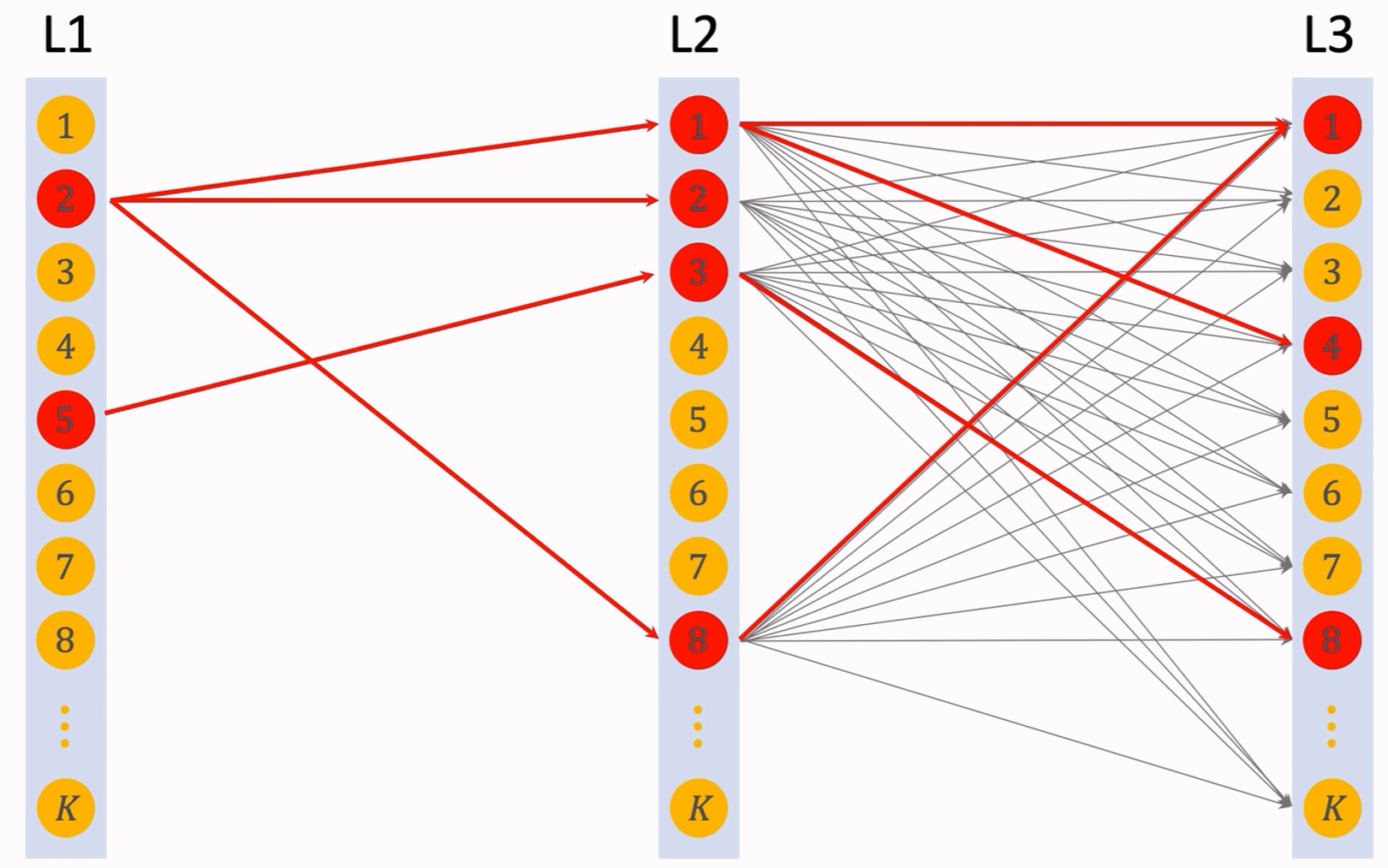
beam size取值为4时
4.1.7 离线训练
训练时,同时学习神经网络参数和物品特征
4.1.7.1 预估用户对路径的兴趣
- 神经网络 p ( a , b , c ∣ x ) p(a,b,c|x) p(a,b,c∣x)预估用户对路径a,b,c的兴趣;
- 把一个物品表征为多条路径{a,b,c},建立索引:item→Listpath和path→Listitem;
- 只使用用户点击的物品作为正样本来训练(user, item):click(user, item)=1。
学习神经网络参数时,假设物品表征为 J J J条路径: a 1 , b 1 , c 1 , ⋯ , a J , b J , c J a_1,b_1,c_1, \cdots, a_J,b_J,c_J a1,b1,c1,⋯,aJ,bJ,cJ;
如果用户对路径 a , b , c a,b,c a,b,c感兴趣,则有
p ( a , b , c ∣ x ) = p 1 ( a ∣ x ) p 2 ( b ∣ a ; x ) p 3 ( c ∣ a , b ; x ) p(a,b,c|x)=p_1(a|x)p_2(b|a;x)p_3(c|a,b;x) p(a,b,c∣x)=p1(a∣x)p2(b∣a;x)p3(c∣a,b;x)
如果用户点击过物品,说明用户对 J J J条路经感兴趣,则应当让 ∑ j = 1 J p ( a j , b j , c j ∣ x ) \sum_{j=1}^J p(a_j,b_j,c_j|x) ∑j=1Jp(aj,bj,cj∣x)变大。
损失函数设计:
L = − l o g ( ∑ j = 1 J p ( a j , b j , c j ∣ x ) ) L=-log(\sum_{j=1}^J p(a_j,b_j,c_j|x)) L=−log(j=1∑Jp(aj,bj,cj∣x))
4.1.7.2 学习物品表征
用户对路径path=a,b,c的兴趣记作:
p ( path ∣ user ) = p ( a , b , c ∣ x ) p(\text{path}|\text{user})=p(a,b,c|x) p(path∣user)=p(a,b,c∣x)
物品item对路径path的相关性:
score ( item ∣ path ) = ∑ user p ( path ∣ user ) ⏟ 用户对路径的兴趣 × click ( user , item ) ⏟ 是否点击(0或1) \text{score}(\text{item}|\text{path})=\sum_{\text{user}} \underbrace{p(\text{path}|\text{user})}{\text{用户对路径的兴趣}} \times \underbrace{\text{click}(\text{user},\text{item})}{\text{是否点击(0或1)}} score(item∣path)=user∑用户对路径的兴趣 p(path∣user)×是否点击(0或1) click(user,item)
根据 score ( item ∣ path ) \text{score}(\text{item}|\text{path}) score(item∣path)选出 J J J条路径作为item的表征。
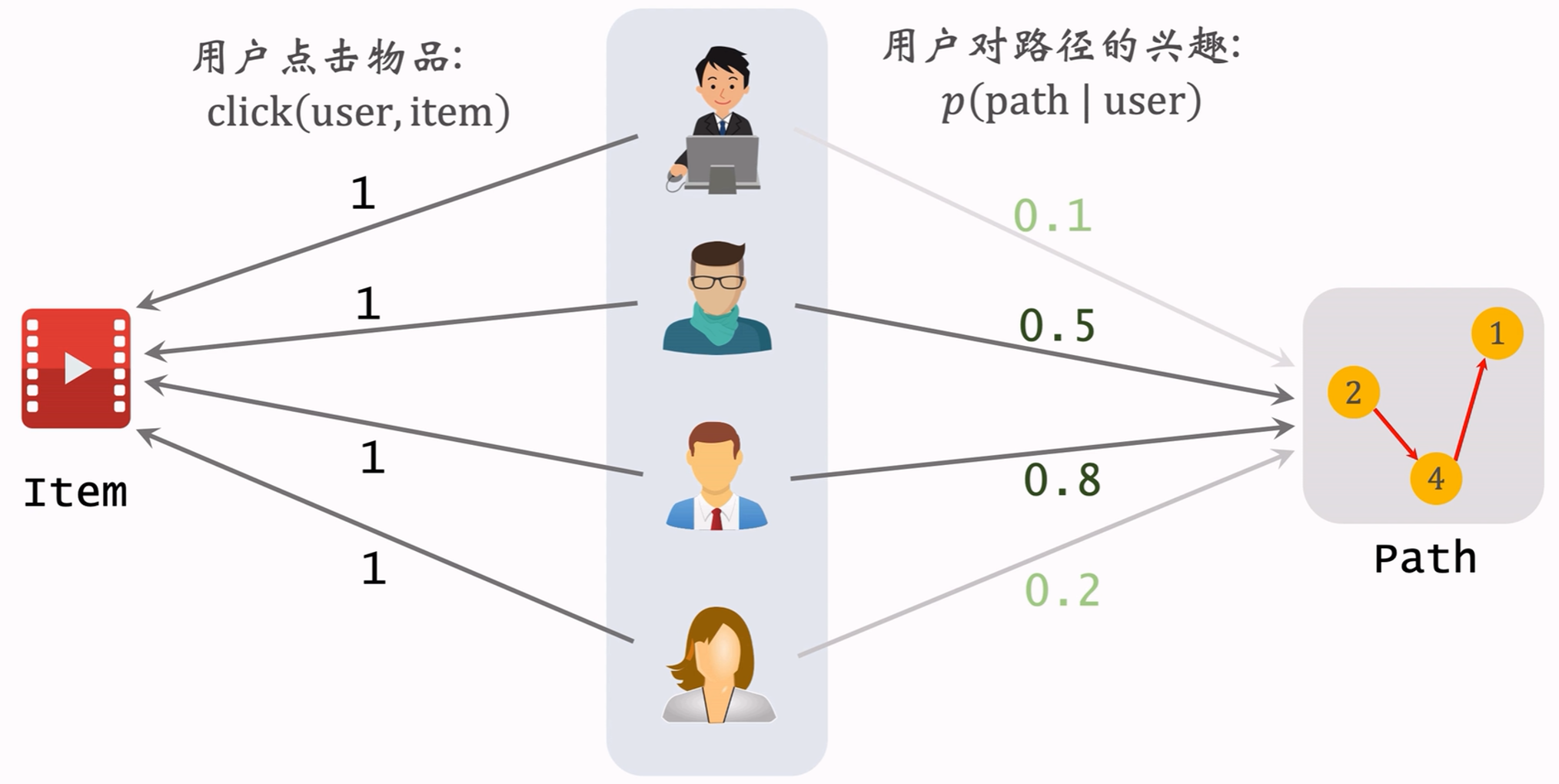
训练时,选出 J J J条路径 Π = { path 1 , ⋯ , path J } \Pi=\{\text{path}_1,\cdots,\text{path}J\} Π={path1,⋯,pathJ}作为物品表征,设计损失函数:
L ( item , Π ) = − log ( ∑ j = 1 J score ( item , path j ) ) L(\text{item},\Pi)=-\log(\sum{j=1}^J \text{score}(\text{item},\text{path}_j)) L(item,Π)=−log(j=1∑Jscore(item,pathj))
有时会有很多物品集中在一条路径上,为了避免这种情况,在损失中加入一个正则项来惩罚这种情况:
reg ( path j ) = ( number of items on path j ) 4 \text{reg}(\text{path}_j)=(\text{number of items on path}_j)^4 reg(pathj)=(number of items on pathj)4
用贪心算法更新路径
假设已经把物品表征为 J J J条路经 Π = { path 1 , ⋯ , path J } \Pi=\{\text{path}_1,\cdots,\text{path}J\} Π={path1,⋯,pathJ},每次固定 { p a t h i } i ≠ l \{path_i\}{i\neq l} {pathi}i=l,并从未选中的路径中选出一条作为新的 path l \text{path}_l pathl:
path l ← arg min path l L ( item , Π ) + α ⋅ reg ( path l ) \text{path}l\leftarrow \argmin{\text{path}_l} L(\text{item},\Pi)+\alpha\cdot\text{reg}(\text{path}_l) pathl←pathlargminL(item,Π)+α⋅reg(pathl)
4.2 其他召回通道
4.2.1 地理位置召回
- 用户可能对附近发生的事感兴趣;
- GeoHash:对经纬度的编码,地图上一个长方形区域;
- 索引:GeoHash→优质笔记列表(按时间倒排);
- 这条召回通道没有个性化。
召回时,根据用户定位的GeoHash,取回该地点最新的 k k k篇优质笔记。
4.2.2 同城召回
- 用户可能对同城发生的事感兴趣;
- 索引:城市→优质笔记列表(按时间倒排);
- 这条召回通道没有个性化。
4.2.3 作者召回
- 用户对关注的作者发布的笔记感兴趣;
- 索引:用户→关注的作者,作者→发布的笔记;
- 召回:用户→关注的作者→最新的笔记。
4.2.4 有交互的作者召回
- 如果用户对某笔记感兴趣(点赞、收藏、转发),那么用户可能对该作者的其他笔记感兴趣;
- 索引:用户→有交互的作者;
- 召回:用户→有交互的作者→最新的笔记。
4.2.5 相似作者召回
- 如果用户喜欢某作者,那么用户喜欢相似的作者;
- 索引:作者→相似作者;
- 召回:用户→感兴趣的作者→相似作者→最新的笔记。
4.2.6 缓存召回
想法:复用前 n n n次推荐精排的结果。
背景:
- 精排输出几百篇笔记,送入重排;
- 重排做多样性抽样,选出几十篇;
- 精排结果有一大半没有曝光,被浪费。
做法:精排前50,但是没有曝光的,缓存起来,作为一条召回通道。
问题:缓存大小固定,需要退场机制。
- 一旦笔记成功曝光,就从缓存退场;
- 如果超出缓存大小,就移除最先进入缓存的笔记;
- 笔记有召回次数上限;
- 笔记有存储时间上限。
4.3 曝光过滤
4.3.1 问题
- 如果用户看过某个物品,则不再把该物品曝光给该用户;
- 对于每个用户,记录已经曝光给他的物品;
- 对于每个召回的物品,判断是否已经给该用户曝光过,排除掉曾经曝光过的物品;
- 一位用户看过 n n n个物品,本次召回 r r r个物品,如果暴力对比,需要 O ( n r ) O(nr) O(nr)的时间。
4.3.2 Bloom Filter
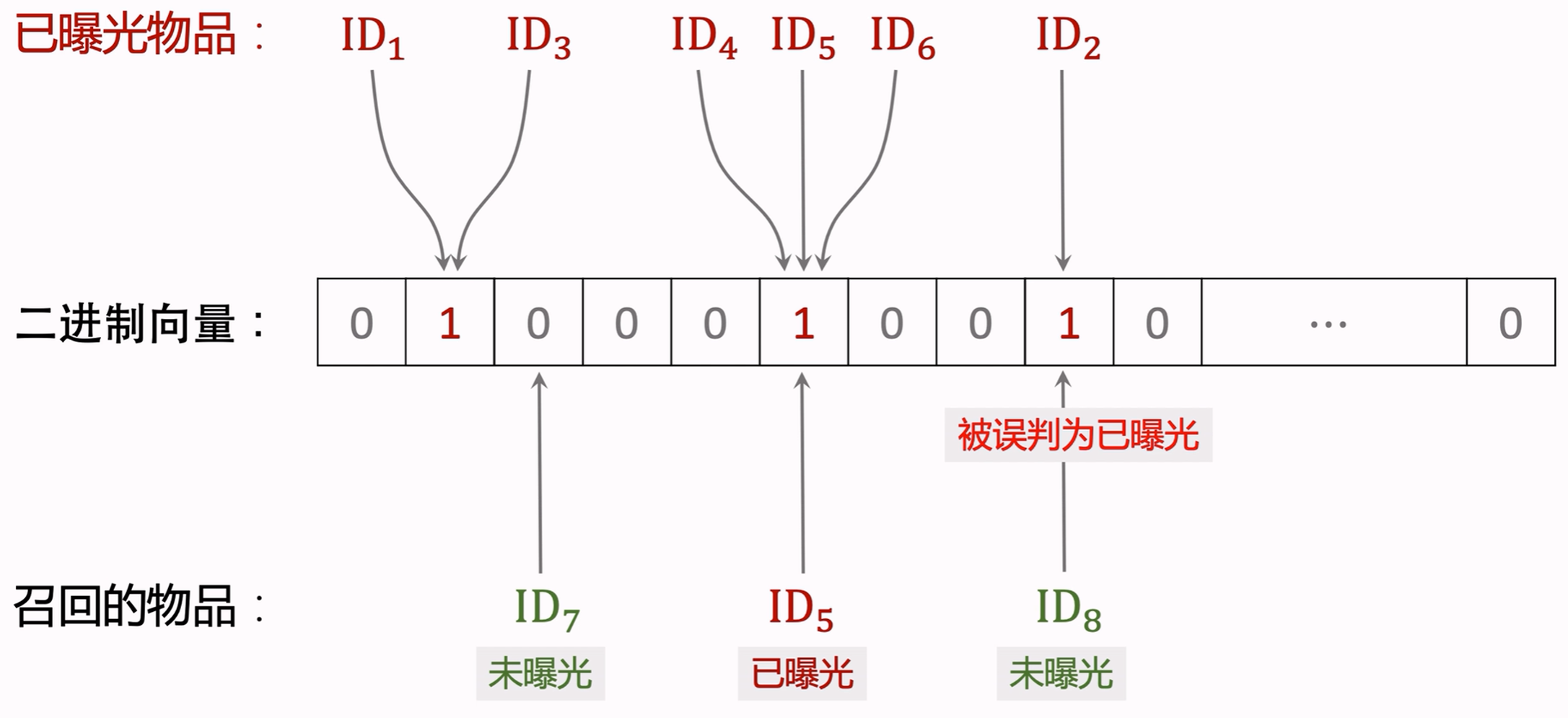
- Bloom Filter判断一个物品ID是否在已曝光的物品集合中;
- 如果判断为no,一定不在集合中;
- 如果判断为yes,可能在集合中;
- Bloom Filter把物品集合表征为一个 m m m维二进制向量,每个用户都有一个曝光物品的集合,表征为一个向量,需要 m m m bit的存储;
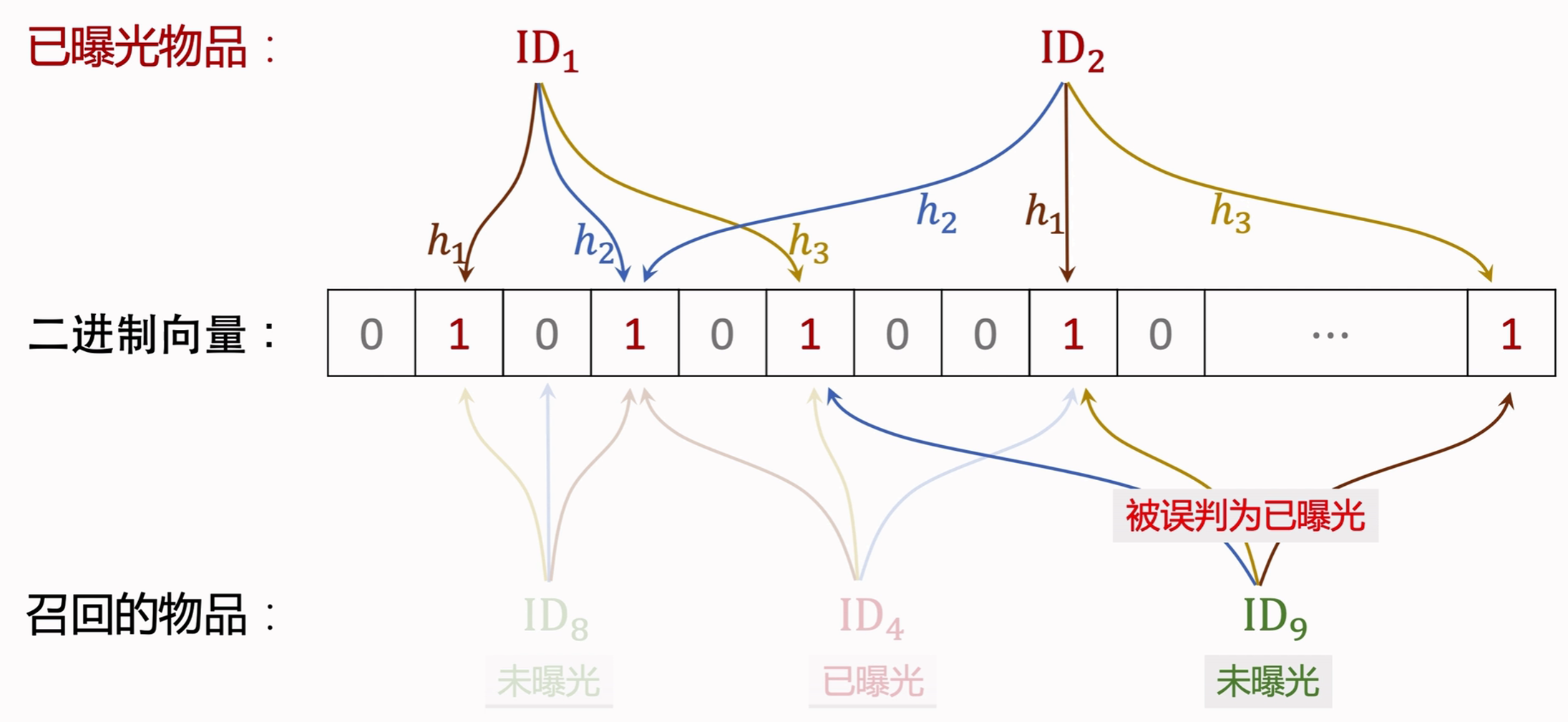
- Bloom Filter有 k k k个哈希函数,每个哈希函数把物品ID映射成介于 0 0 0和 m − 1 m-1 m−1之间的整数。
k = 1 k=1 k=1时:
k = 3 k=3 k=3时:
曝光物品集合大小为 n n n,二进制向量维度为 m m m,使用 k k k个哈希函数。Bloom Filter误伤的概率为:
δ ≈ ( 1 − exp ( − k n m ) ) k \delta\approx (1-\exp(-\frac{kn}{m}))^k δ≈(1−exp(−mkn))k
设定可容忍的误伤概率为 δ \delta δ,那么最优参数为 k = 1.44 ⋅ ln ( 1 δ ) k=1.44\cdot \ln(\frac{1}{\delta}) k=1.44⋅ln(δ1), m = 2 n ⋅ ln ( 1 δ ) m=2n\cdot \ln(\frac{1}{\delta}) m=2n⋅ln(δ1)。
4.3.3 曝光过滤的链路
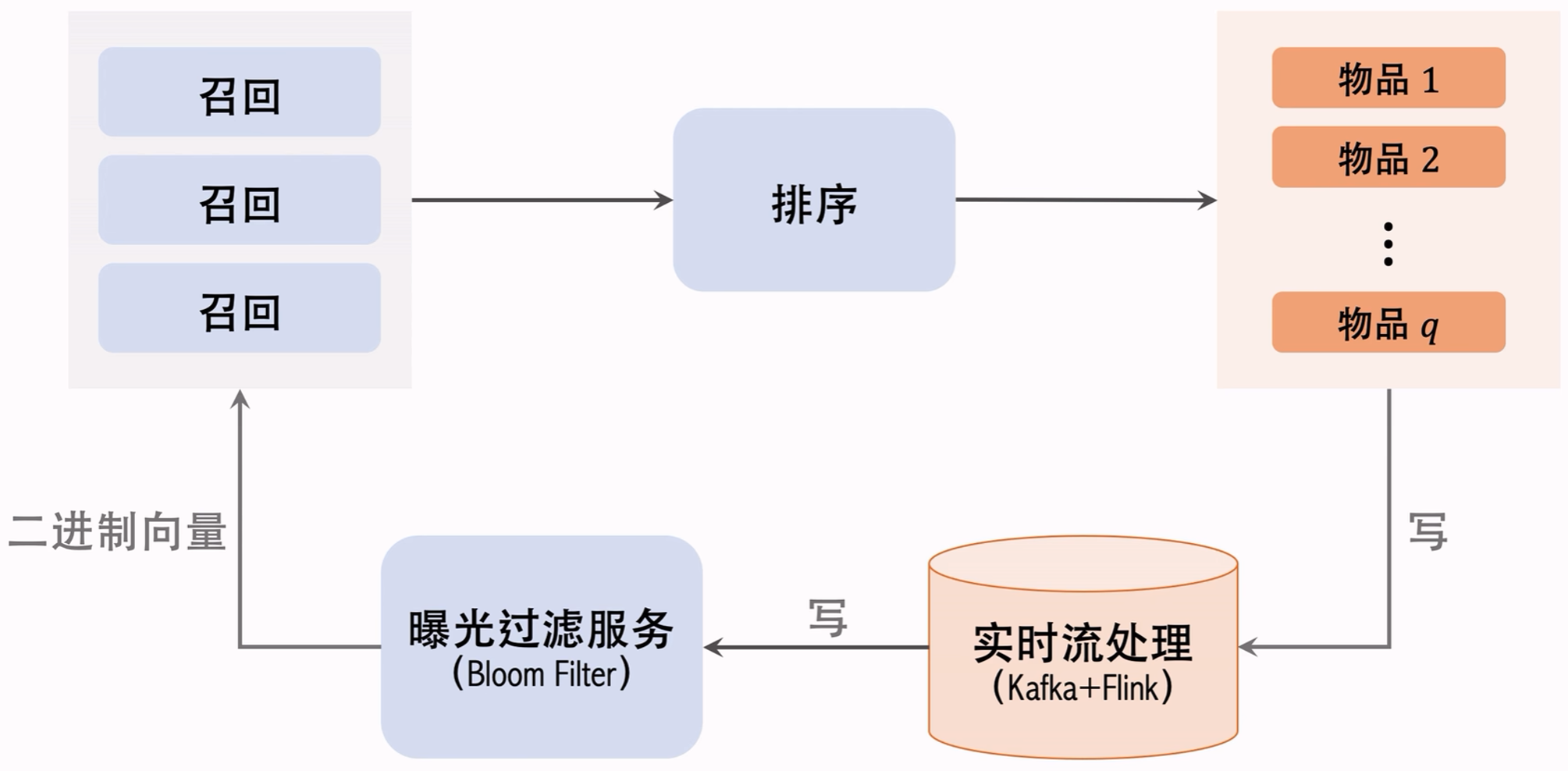
4.3.4 Bloom Filter的缺点
- 只支持添加物品,不支持删除物品。