开篇介绍:
hello 大家,我们又见面啦,几日不见,甚是想念,那么大家,在前面的博客中,我们将C嘎嘎的模版进阶的知识进行了解析,其实随着那篇博客的完结,我们的C嘎嘎初阶,也算是完成了,在这里大家先给自己一个大大的点赞,非常的牛波一。
那么接下来,我们就要进入C++进阶的学习了,这个就是深入的学习C++了,对应着难度肯定也是有部分的提升,但是,这都不是事,哈哈哈,大家继续加油。
而我们这篇博客便是来讲讲C++三大特性的继承,由于内容较多,所以我会分为两篇博客来进行讲解,OK,话不多说,我们出发喽。
继承的概念:
在面向对象编程中,继承 是一种使代码复用的重要机制,它允许一个类(称为派生类 / 子类 )继承另一个类(称为基类 / 父类)的属性(成员变量)和方法(成员函数)。
通过继承,派生类可以直接使用基类中已有的功能,同时还能在此基础上添加新的成员或重写基类的方法,从而实现对基类的扩展或定制。这就好比现实中 "子类继承父类的特征,同时又有自己独特的特点",例如 "学生类" 继承 "人类" 的姓名、年龄等属性,同时新增 "学号" 等专属成员。
继承主要分为不同的类型,如单继承 (一个派生类只有一个直接基类)、多继承(一个派生类有多个直接基类)等,不同的继承方式在代码结构和内存布局上会有不同表现,同时也涉及到构造函数、析构函数的调用顺序、成员隐藏、访问权限控制等一系列规则。
继承呈现了面向对象程序设计的层次结构,体现了由简单到复杂的认知过程。以前我们接触的函数复用是函数层次的复用,而继承则是类设计层次的复用。
那么在这里,我就直接总结出最精辟的最容易理解的继承的概念:
儿子具有爸爸的所有东西,除了爸爸的隐私(即private),这就是继承
就是这么的简单,大家可以体会体会。
示例:
我们先看一下下面这段代码:
cpp
class Student
{
public:
// 进入校园/图书馆/实验室刷二维码等身份认证
void identity()
{
// ...
}
// 学习
void study()
{
// ...
}
protected:
string _name = "peter"; // 姓名
string _address; // 地址
string _tel; // 电话
int _age = 18; // 年龄
int _stuid; // 学号
};
class Teacher
{
public:
// 进入校园/图书馆/实验室刷二维码等身份认证
void identity()
{
// ...
}
// 授课
void teaching()
{
//...
}
protected:
string _name = "张三"; // 姓名
int _age = 18; // 年龄
string _address; // 地址
string _tel; // 电话
string _title; // 职称
};上面我们看到,在没有使用继承时,我们设计了 Student 和 Teacher 两个类。这两个类中都有姓名、地址、电话、年龄等成员变量,以及 identity 身份认证的成员函数,这些重复的内容在两个类中分别编写,显得十分冗余且麻烦。当然,它们也有各自独有的的成员变量和函数:比如老师独有的职称这个成员变量,学生独有的是学号;学生有学习这个独有的成员函数,老师则有授课这个独有的成员函数。
因此,在 C++ 中,为解决这种冗余问题,便有了继承机制。我们可以将 Student 和 Teacher 两个类中相同的内容封装成一个类,命名为 Person,然后让 Student 和 Teacher 这两个类去继承 Person 类。这样一来,Student 和 Teacher 就能使用 Person 类中除 private 成员外的所有成员变量和成员函数,而它们自身只需要包含各自独有的成员变量和成员函数即可。如此,代码不仅简洁了很多,也更加美观。
你看 Student 和 Teacher 这两个类,就像两个 "人",他们都有姓名、年龄、电话这些 "共同点",也都要做 "刷二维码认证" 这件事。
但之前的写法是,这两个人各说各的,把这些相同的东西都自己写了一遍,多费劲啊!
继承就相当于:先找一个 "大长辈"(比如叫 Person 类),把这些 "姓名、年龄、电话、身份认证" 这些大家都有的东西,全放到这个长辈身上。然后 Student 和 Teacher 就 "认 Person 当爹",成为它的 "孩子"。
这样一来:Student 和 Teacher 就不用自己再写那些重复的东西了,因为 "爹有了,孩子自然就有了"(除了爹藏起来不让孩子碰的 private 内容)。孩子只需要管好自己独有的东西:Student 记上学号、写个学习的功能;Teacher 记上职称、写个授课的功能就行。
打个比方:就像你不用自己重新发明 "吃饭、走路" 这些人类共有的能力,因为你继承了人类的这些基础能力,你只需要学会自己的专属技能(比如编程、画画)就行。
编译器在背后会帮你做一件事:把 Person 类里能给孩子的东西,偷偷 "复制" 到 Student 和 Teacher 类里,但这些复制的东西算在 "爹的名下",不会和孩子自己的东西冲突。所以继承的核心就是:少写重复代码,让类之间像家族一样共享基础功能,只专注于自己的特色。
上面所说的,也就是继承,即让某一个类去认另一个类为爸爸,然后那个类就能拥有它爸爸类中除了 private 之外的成员变量和成员函数了。这其实就相当于,爸爸类中除了 private 的成员变量和成员函数都存在于儿子类里面,只不过是处于爸爸类的类域中。
再换句话来说,我们在外面创建的儿子类变量,可以直接通过这个儿子类变量去调用爸爸类中除了 private 的成员变量和成员函数,而且儿子类内部也可以直接使用爸爸类中除了 private 的成员变量和成员函数。
注意点:
那么我在这里再给大家一个初学者对于继承可能容易误解的一个点:
很多人可能会觉得,继承就是相当于父类的成员变量和成员函数都在子类里面加上了,那么其实不是这样的:
子类并不会 "物理性地复制" 父类非 private 成员的代码定义,但其对象会包含父类非 private 成员变量的存储空间,同时拥有对这些成员的访问权限。具体来说:
子类对象的内存布局中,会专门划分一块区域用于存储父类的非 private 成员变量(确保这些数据有地方存放);而子类通过类域的嵌套关系(类似 "子空间包含父空间"),能够找到并访问父类的成员(包括成员变量和成员函数)。不过,父类成员的代码定义(比如成员函数的实现、成员变量的类型声明)只存在唯一一份,被所有子类共享,不会因为继承而重复创建,这避免了代码冗余。
进一步总结:每个子类对象的内存中,都会包含一块独立的空间用于存储父类的非 private 成员变量(注意:成员函数不占用对象的存储空间,它们被统一存放在单独的代码区,供所有对象共享)。这些存储空间是彼此独立的 ------ 即使多个子类对象继承自同一个父类,它们各自包含的 "父类成员变量空间" 也互不相干。例如,学生对象 s 的_name 和老师对象 t 的_name 会存放在不同的内存地址,各自的数据修改不会影响对方。
简言之,父类的成员定义(规则和逻辑)是所有子类共享的,但每个子类对象中用于存储父类成员变量的空间是独立的,成员函数的代码也只存在一份。这种设计既保证了代码复用,又确保了不同对象的数据互不干扰。
这个是一个很重要的点,大家千万不能误会了
怎么样大家,这样子是不是就能对继承的理解更进一步了呢,大家还是要去结合生活中的例子,然后多去思考,就会好理解很多。
继承的定义:
继承的方式:
在正式讲解继承的格式是什么之前,我们得先来了解了解,继承的方式有哪些,毕竟继承那么重要,那么肯定花样也挺多的,所以接下来我们就来看看:
继承的方式有三种,分别是 public 继承、protected 继承和 private 继承。
| 类成员 / 继承方式 | public 继承 | protected 继承 | private 继承 |
|---|---|---|---|
| 父类的 public 成员 | 相当于派生类的 public 成员(外部可通过派生类对象直接访问,如derivedObj.pubFunc()) |
相当于派生类的 protected 成员(仅派生类内部及子类可访问,外部无法直接调用) | 相当于派生类的 private 成员(仅派生类内部可访问,子类无法继承此权限) |
| 父类的 protected 成员 | 相当于派生类的 protected 成员(派生类内部可自由使用,子类也能继承此权限) | 相当于派生类的 protected 成员(与 public 继承的 protected 权限效果一致) | 相当于派生类的 private 成员(派生类内部可使用,但子类无法访问) |
| 父类的 private 成员 | 在派生类中不可见(无论派生类如何操作,均无法直接访问基类 private 成员) | 在派生类中不可见(同 public 继承,基类 private 成员完全隔离) | 在派生类中不可见(所有继承方式下,基类 private 成员对派生类均不可见) |
补充说明:
- 权限等级 :
public > protected > private,继承后的权限取 "基类成员权限" 和 "继承方式" 的较低等级(例如基类 public 成员 + protected 继承 → 派生类中为 protected)。 - 场景选择 :
- 若需保持基类接口的开放性(如 "动物" 的
eat()方法让 "狗""猫" 都能被外部调用),选public 继承。 - 若需隐藏基类接口,仅让派生类内部或子类复用(如基类的工具方法仅给派生类使用),选protected 继承。
- 若需完全隔离基类接口,仅让当前派生类内部复用(极少场景使用,易导致耦合),选private 继承。
- 若需保持基类接口的开放性(如 "动物" 的
- 关键原则 :基类的
private成员在任何继承方式下,对派生类都完全不可见(即使派生类内部也无法直接访问),这是 C++ 封装性的严格保障。
这是一点,下面则是主要的补充
- 一般来说,我们常用的是 public 继承,这种继承方式下,除了父类的 private 成员外,父类的其他成员子类都可以使用,大家可以直接记住这个就足够了
- 需要明确的是,基类的 private 成员在派生类中无论以何种方式继承都是不可见的。这里的 "不可见" 具体指基类的私有成员仍会被继承到派生类对象中,但语法上会加以限制,派生类无论是在类内部还是类外部都无法访问该成员;
- 若基类的某个成员既不想在类外被直接访问,又需要允许派生类内部访问,那么该成员应定义为 protected,由此可见,保护成员限定符是因继承场景的需求才出现的,这也是 protected 和 private 限定访问符的区别。
- 另外,在 C++ 中,当我们用 class 或 struct 定义子类并继承父类时,如果不明确写出继承方式(比如 public),编译器会自动使用默认的继承方式,且 class 和 struct 的默认继承方式恰好相反:使用关键字 class 时默认的继承方式是 private,使用 struct 时默认的继承方式是 public,不过为了代码的清晰性,最好显式地写出继承方式。
所以经过上面的讲解,大家应该就会对继承方式有了个清晰的认知,那么我们接下来就来看看继承的格式是什么。
继承的格式:
继承的格式是:在子类的名字后面加上冒号 ":",后面再跟上继承方式和父类名字即可。拿上面的例子来说就是:
下面我给大家一个示例代码,帮助大家理解:
示例代码:
cpp
class person
{
public:
void identity()
{
cout << "身份识别" << endl;
}
protected:
string mname = "张三"; // 姓名
string maddress; // 地址
string mtel; // 电话
int mage = 18; // 年龄
};
class student:public person //继承
{
public:
// 学习
void study()
{
cout << "学习" << endl;
}
void definestudent()
{
mage = 20;
maddress = "太阳系";
}
void printstudent()
{
cout << mage << " " << maddress << endl;
}
private:
string mstuid;
};
class teacher:public person //继承
{
public:
// 授课
void teaching()
{
cout << "授课" << endl;
}
void defineteavher()
{
mage = 29;
maddress = "地球";
}
void printteacher()
{
cout << mage << " " << maddress << endl;
}
protected:
string title; // 职称
};
int main()
{
student s;
teacher t;
//创建两个子类变量
s.identity();
t.identity();
//可以在外面直接通过子类变量调用父类的public的成员函数
s.definestudent();
t.defineteavher();
//可以在子类中定义父类的成员变量
s.printstudent();
t.printteacher();
//打印出我们可以看出,两个子类所存储的父类是独立的
return 0;
}大家结合着例子进行理解,并不算多难。
继承类模板:
类模板的继承,本质上就是一个类模板以另一个类模板作为基类(即 "认其为父类")的机制。和普通类的继承逻辑一致,当一个子类模板继承自父类模板后,它可以使用父类模板中所有非 private 的成员变量和成员函数,无需重复定义这些共性内容,只需专注于自身特有的功能实现。
这种机制在实际开发中很常见,比如 STL 中 stack(栈)和 queue(队列)的模拟实现就是典型例子:它们通常会继承自一个底层容器类模板(如 deque 或 vector 的类模板),直接复用底层容器的存储和基础操作(如元素的插入、删除、访问等非 private 成员),再在其上封装栈的 "先进后出" 或队列的 "先进先出" 等特有逻辑,既保证了代码复用,又简化了实现过程。
示例代码:
cpp
namespace win
{
template <typename T1>
class stack :public vector<T1>
{
public:
void push(const T1& val = T1())
{
//push_back(val);
//注意,不能就像上面那么使用,
//因为虽然认了vector为爸爸,但是编译器没那么智能
//直到你用的push_back函数就是vector里面的
//所以我们要指定类域
//即指定是vector里面的push_back函数才行
vector<T1>::push_back(val);
//因为stack<int>实例化时,也实例化vector<int>了
//但是模版是按需实例化,push_back等成员函数未实例化,所以找不到
}
void pop()
{
vector<T1>::pop_back();
}
T1& top()
{
return vector<T1>::back();
}
size_t size() const
{
return vector<T1>::size();
}
bool empty() const
{
return vector<T1>::size() == 0;
}
private:
//就不用设置容器作为成员变量了
//因为已经认vector为爸爸了,所以就不需要了
//在上面的成员函数可以直接使用父类模版vector的成员函数了
};
}那么其实大家要注意一下,对于类模版继承,我们写子类模版的成员函数时,如果想要去调用父类模版的成员函数的时候,是不能就直接写父类模版里的函数名就行了,而是要去指定类域,即类域::成员函数,这样子,那么之所以要这个样子的原因是:
按需实例化:
- 类模板的 "按需实例化" 特性
C++ 的类模板是 **"蓝图" 式的存在 **,只有当我们用具体类型(如int、double)去实例化它时,编译器才会真正生成对应的类代码。例如:
- 定义
template<class T> class Vector { ... };时,编译器不会生成任何实际代码。 - 当我们写
Vector<int> v;时,编译器才会生成Vector<int>这个具体类的代码(包括它的成员变量、成员函数,如push_back(int))。
这种 "用到才生成" 的机制称为按需实例化,即我们有实质性调用了,编译器才会去仔细检查我们所调用的,不难编译器是只会随便检查一下就完事了,容易忽略一些错误,目的是避免生成冗余代码。
- 类模板继承时的 "成员函数可见性" 问题
当一个子类模板(如Stack<T>)继承自父类模板(如Vector<T>)时,会出现一个关键问题:
- 父类模板的成员函数(如
push_back)只有在被实例化后,才能被编译器识别为 "可调用的函数"。 - 但子类模板在编译阶段,若直接写
push_back(val),编译器会因为 "父类模板的push_back还未实例化" 而无法确认这个函数的存在,从而报错。
- 类域指定(
Vector<T1>::push_back(val))的作用
为了明确告诉编译器:"我要调用的是父类模板Vector<T1>中的push_back函数",我们需要显式指定类域 ,格式为父类模板名<模板参数>::成员函数名(参数)。
以代码中的stack和vector为例:
Stack<T>继承自Vector<T>,当我们在Stack的成员函数中要调用vector的push_back时,必须写成Vector<T>::push_back(val)。- 这样编译器就能明确:"这个
push_back属于父类模板Vector<T>,需要等Vector<T>实例化后(如Stack<int>实例化时,Vector<int>也会被实例化),才能调用其push_back(int)函数"。
总结
在类模板继承场景中,由于按需实例化 的机制,父类模板的成员函数在编译阶段是 "不可见" 的。为了让编译器明确找到要调用的父类成员函数,必须显式指定类域 (如Vector<T1>::push_back(val)),告诉编译器 "该函数属于哪个父类模板",从而保证编译和实例化的正确性。
这个是一个比较关键的点,希望大家注意。
那么还有就是,除了我们可以指定类域,还可以用this指针:
this指针法:
在类模板的继承中,除了通过显式指定类域(如父类模板名<参数>::成员函数)来使用父类模板的成员函数,还可以通过this指针来访问。这背后的逻辑与子类对象的内存结构和this指针的指向特性直接相关。
我们知道,this指针的本质是指向当前对象自身的指针。对于子类模板(比如Stack<T>)来说,this指针指向的是Stack<T>的对象实例。而根据继承的特性,子类对象的存储空间中会包含父类模板(比如Vector<T>)的成员变量(以及对父类成员函数的访问权)------ 就像子类对象 "包含" 了父类的部分一样。
正因为子类对象中 "包含" 父类的成员(非private部分),this指针在指向子类对象时,自然也能 "触及" 到这些继承自父类的成员函数。也就是说,当我们在子类模板中用this->父类成员函数()时,this指针会先定位到当前子类对象,再通过对象内部包含的父类部分,找到对应的父类成员函数并调用。
这种方式无需显式写类域,是因为this指针已经隐含了当前对象的完整信息(包括继承自父类的部分),this->的作用是触发 "延迟查找",让编译器在实例化(即外部调用了)时才执行 "子类->父类" 的查找流程,编译器能通过this指针的指向,明确要访问的成员函数来自父类模板,从而正确关联到对应的实现。
下面是示例代码:
cpp
namespace win
{
template <typename T1>
class stack : public vector<T1>
{
public:
void push(const T1& val = T1())
{
// push_back(val);
// 注意,不能像上面那样直接使用,
// 因为虽然继承了vector作为父类,但编译器无法自动识别
// 该push_back函数是来自vector的成员
// 因此需要通过this指针明确访问父类成员
this->push_back(val);
// 原因:stack<int>实例化时会同时实例化vector<int>,
// 但模板采用按需实例化机制,未显式调用的成员函数(如push_back)不会提前实例化,
// 导致编译器无法直接找到该函数
}
void pop()
{
this->pop_back();
}
T1& top()
{
return this->back();
}
size_t size() const
{
return this->size();
}
bool empty() const
{
return this->size() == 0;
}
private:
// 无需再定义容器作为成员变量,
// 因为已继承自vector父类,可直接使用其成员函数
};
}
int main()
{
win::stack<int> st;
st.push(1);
st.push(2);
st.push(3);
while (!st.empty())
{
cout << st.top() << " ";
st.pop();
}
return 0;
}OK,对于继承类模版的解析,就到这里,大家要记住一些注意点哦。
基类和派生类间的转换:
那么这就又是一个比较重要的知识点了,我们且看下文
在 C++ 的 public 继承关系中,派生类对象(子类对象)有一个非常关键的特性:它可以直接赋值给基类(父类)指针或基类引用,这个过程有个形象的名字叫 "切片"(也叫 "切割")。
要理解 "切片",得先回到派生类对象的内存布局 ------ 之前我们提到过,子类对象的内存里会完整包含父类的所有成员(数据成员存于对象内存中,继承的成员函数虽在代码区,但子类拥有访问权),相当于子类对象的内存空间里,"嵌套" 了一块专属的 "父类成员区域",再加上子类自己新增的成员变量(比如 Student 类继承 Person 类后,内存里既有 Person 的 "姓名、年龄",又有自己的 "学号")。
当把子类对象赋值给父类指针或引用时,编译器不会把整个子类对象都 "搬过去",而是只 "切取" 其中 "父类成员区域" 的内容:如果是赋值给父类引用,引用会直接绑定到子类对象里的 "父类成员区域",相当于 "只盯着对象里属于父类的部分";如果是赋值给父类指针,指针会指向子类对象中 "父类成员区域" 的起始地址。正因为只 "切取" 了父类部分,所以后续通过这个父类指针或引用访问时,只能拿到父类定义的成员(比如用指向 Student 对象的 Person 指针,只能访问 "姓名",没法访问 "学号"),子类新增的专属成员是访问不到的。
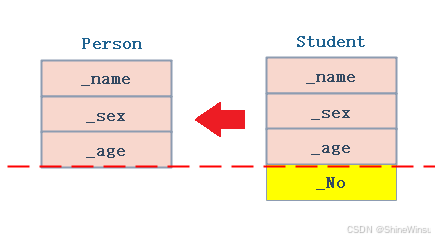
这里必须注意,"切片" 的赋值关系是单向的 ------ 绝对不能把父类对象赋值给子类对象。原因很简单:父类对象的内存里根本没有子类新增的成员,强行赋值的话,子类那些专属成员就找不到对应的初始化数据,会变成随机值;更重要的是,这违背了继承的设计逻辑 ------ 父类是子类的通用模板(比如 Person 是 Student 的通用模板),子类是父类的特殊化扩展(Student 是有 "学号" 的特殊 Person),通用模板自然无法包含特殊扩展的内容,反过来赋值也就不成立。
说白了就是,子类对象里本来就存着父类的成员变量,只是多了些父类没有的专属成员;所以把子类对象赋值给父类指针或引用时,编译器会自动 "过滤" 掉子类独有的成员,只让父类指针或引用关联到子类里 "属于父类的那部分成员变量",这样既符合继承的内存结构,又保证了访问的合理性。
这个还是比较重要的,我们在接下来的学习中就会用到这个知识,希望大家注意,下面给出示例代码:
示例代码:
cpp
class person
{
public:
void identity()
{
cout << "身份识别" << endl;
}
protected:
string mname = "张三"; // 姓名
string maddress; // 地址
string mtel; // 电话
int mage = 18; // 年龄
};
class student : public person
{
public:
// 学习
void study()
{
cout << "学习" << endl;
}
void definestudent()
{
mage = 20;
maddress = "太阳系";
}
void printstudent()
{
cout << mage << " " << maddress << endl;
}
private:
string mstuid; // 学生学号
};
class teacher : public person
{
public:
// 授课
void teaching()
{
cout << "授课" << endl;
}
// 修正拼写错误:defineteavher → defineteacher
void defineteacher()
{
mage = 29;
maddress = "地球";
}
void printteacher()
{
cout << mage << " " << maddress << endl;
}
protected:
string title; // 教师职称
};
int main()
{
// 子类对象实例化
student s;
teacher t;
// 子类对象赋值给基类指针
person* p1 = &s;
person* p3 = &t;
// 子类对象赋值给基类引用
person& p2 = s;
person& p4 = t;
// 子类对象赋值给基类对象(通过基类拷贝构造完成,后续讲解)
student sobj;
person pobj = sobj;
// 2. 基类对象不能赋值给派生类对象,以下代码编译会报错
person p;
// s = p; // 错误:没有与这些操作数匹配的 "=" 运算符
return 0;
}大家依旧是结合着代码和文字进行理解哦。
继承中的作用域:
隐藏规则:
在继承体系中,基类和派生类从始至终保持着各自独立的类域,并不会因为存在继承关系,就将两者的成员名称自动合并到同一个作用域里。这种独立的类域设计,是理解 "成员隐藏" 现象的关键前提。
当派生类(子类)中定义了与基类(父类)同名的成员时 ------ 不管这个成员是数据成员(比如父类有int age,子类也定义int age),还是成员函数(比如父类有void show(),子类也定义void show()),就会触发 "隐藏" 机制。简单来说,派生类的同名成员会像一层 "遮挡",屏蔽掉对基类同名成员的直接访问:在派生类内部编写代码时,直接使用这个同名成员,编译器会默认匹配派生类自己的成员;通过派生类对象访问这个成员时,同样只会找到派生类的版本,基类的同名成员则被 "藏" 了起来,无法直接调用。
如果确实需要在派生类中访问被隐藏的基类成员,就必须通过显式指定类域 的方式实现,也就是用 "基类名::基类成员名" 的格式(比如父类是Person,要访问其age成员,就写Person::age)。这样能明确告诉编译器,要找的是基类作用域下的成员,从而绕开隐藏,精准定位到基类的成员。
这里需要特别注意成员函数的隐藏规则,它和我们熟悉的 "函数重载" 完全不同:函数重载要求多个函数在同一作用域 内,且参数列表(个数、类型、顺序)不同 ;而成员函数的隐藏,只要派生类的函数与基类的某一函数名字相同 ,哪怕两者的参数列表、返回值类型完全不一样,都会构成隐藏。比如基类有void func(int),派生类定义void func(double),此时派生类的func(double)会隐藏基类的func(int)------ 如果通过派生类对象直接调用func(10)(传入 int 类型参数),编译器会报错,因为它只会在派生类中找func,却找不到匹配 int 参数的版本,必须显式写Person::func(10)才能正确调用基类的函数。
基于这些特性,在实际开发的继承体系中,我们应尽量避免在派生类中定义与基类同名的成员。因为隐藏很容易导致代码逻辑模糊(比如开发者误以为调用的是基类成员,实际却执行了派生类成员),还可能引发访问歧义或逻辑错误,不利于代码的可读性和后续维护。当然,也存在一些无法避免的场景,比如运算符重载函数(不同类可能都需要重载operator+),这种情况下,若要使用基类的同名运算符重载函数,就必须严格通过 "基类名::运算符函数" 的方式指定类域,确保代码逻辑正确。
示例代码:
下面给大家一个示例代码帮助大家理解:
cpp
//Student的_num和Person的_num构成隐藏关系,
class Person
{
protected:
string _name = "小李子"; // 姓名
int _num = 111; // 身份证号
};
class Student : public Person
{
public:
void Print()
{
cout << " 姓名:" << _name << endl;
cout << " 身份证号:" << Person::_num << endl;//指定是父类person里面的_num
cout << " 学号:" << _num << endl;
}
protected:
int _num = 999; // 学号
};
int main()
{
Student s1;
s1.Print();
return 0;
};
//可以看出这样代码虽然能跑,但是非常容易混淆OK大家,接下来我们来两道选择题考考大家。
考察继承作用域相关选择题:
我们先看代码:
cpp
#include <iostream>
using namespace std;
class A
{
public:
void fun()
{
cout << "func()" << endl;
}
};
class B : public A
{
public:
void fun(int i)
{
cout << "func(int i): " << i << endl;
}
};
int main()
{
B b;
b.fun(10);
b.fun();
return 0;
}1 A 和 B 类中的两个 func 构成什么关系()A. 重载B. 隐藏C. 没关系
2 上面程序的编译运行结果是什么()A. 编译报错B. 运行报错C. 正常运行
我觉得还是很简单的,下面我就给出答案啦:
答案:
1 答案:B(隐藏)
- 重载要求同一作用域 且参数列表不同,但 A 和 B 是不同类(不同作用域);
- 隐藏的规则是:派生类(B)与基类(A)成员函数名字相同 (不管参数 / 返回值是否一致),就会构成隐藏。因此 A 和 B 的
func是隐藏关系。
2 答案:A(编译报错)
- 因为 B 类的
fun(int i)隐藏了 A 类的fun(),直接调用b.fun()时,编译器会在 B 类中查找fun(),但 B 类只有fun(int i),参数不匹配,导致编译报错 。(若要调用 A 类的fun(),需显式指定类域:b.A::fun())
还是很简单滴。
OK大家,接下来按道理我们应该讲讲继承中子类和父类的默认构造函数,但是由于那一部分内容偏多,所以我就放在下一篇博客进行讲解,我们接下来来讲讲继承与友元、继承与静态成员、实现一个不能被继承的类。
实现一个不能被继承的类:
OK大家,那么大家肯定有点疑问,万一我就想让一个类不能被继承呢,那么有没有什么方法呢?诶,有的有的,肯定有的。而且有两个方法。
方法一:
将基类的构造函数设为私有。由于派生类在初始化自身时,必须调用基类的构造函数才能完成初始化,而基类构造函数私有化后,派生类无法访问并调用它,因此派生类无法实例化出对象。
下面是示例代码:
cpp
class Base
{
public:
void func5() { cout << "Base::func5" << endl; }
protected:
int a = 1;
private:
//C++98的方法
Base()
{}
};
class Derive :public Base//编译报错
{
void func4() { cout << "Derive::func4" << endl; }
protected:
int b = 2;
};方法二:
利用 C++11 新增的 final 关键字。用 final 修饰基类后,派生类将不能继承该基类,具体使用方式是将 final 加在父类的名字后面,即 "class 父类名字 final"。
下面是示例代码:
cpp
// C++11的方法
class Base final
{
public:
void func5() { cout << "Base::func5" << endl; }
protected:
int a = 1;
private:
// C++98的方法
/*Base()
{}*/
};
class Derive :public Base//不能将"final"类类型用作基类
{
void func4() { cout << "Derive::func4" << endl; }
protected:
int b = 2;
};这个还是很好理解的,我比较推荐大家使用C++11的方法,即final就行,比较方便,也比较直观。
继承与友元:
在 C++ 中,友元关系的 "不可继承性" 是一个需要明确的核心特性,我们可以从 "权限范围" 和 "继承传递" 两个维度深入理解:
首先,友元的本质是单向的权限授予。当类 A 将函数 f(或类 B)声明为友元时,相当于 A 主动开放了自己的 "私有领地"(private 成员)和 "受保护区域"(protected 成员),允许 f 或 B 的成员直接访问。但这个权限有严格的范围限制 ------ 仅针对 A 自身的成员,与 A 的派生类无关。
举个例子:假设基类Parent有一个友元函数print,print可以自由访问Parent的私有成员(如m_data)。当Child类公有继承Parent后,Child会继承Parent的m_data(假设为 protected 成员),同时可能新增自己的私有成员m_extra。此时,print作为Parent的友元,只能直接访问Parent对象的m_data,但有两个关键限制:
- 无法通过
Child对象访问继承自Parent的m_data------ 因为Child是独立的类,print没有获得Child的授权,哪怕m_data来自父类,在Child对象中也属于Child的内存布局一部分,受Child的访问控制约束; - 完全无法访问
Child新增的m_extra------ 这是Child独有的私有成员,与Parent无关,自然不在print的权限范围内。
这背后的逻辑是:友元关系是两个实体之间的直接约定 (如Parent与print),这种约定不会随继承关系 "传递" 给派生类。派生类作为独立的类,其私有 / 保护成员的访问权限,只能由它自己主动声明的友元来获得。
因此,若想让print既能访问Parent的成员,又能访问Child的成员,必须分别在Parent和Child中都将print声明为友元 ------ 二者缺一不可,因为Parent的友元声明无法 "替Child做主" 开放权限。
总结来说,友元关系的不可继承性,本质是对类封装边界的严格保护:每个类只负责管理自己的访问权限,不会因为继承关系就将父类的友元 "自动纳入" 自己的信任列表,这也避免了友元权限通过继承被无限制扩散,保障了代码的封装性和安全性。
下面给出示例代码:
cpp
class Student;
class Person
{
public:
friend void Display(const Person& p, const Student& s);
protected:
string _name; // 姓名
};
class Student : public Person
{
protected:
int _stuNum; // 学号
};
void Display(const Person& p, const Student& s)
{
cout << p._name << endl;
cout << s._stuNum << endl;
}
int main()
{
Person p;
Student s;
// 编译报错:error C2248: "Student::_stuNum": 无法访问 protected 成员
// 解决方案:Display也变成Student 的友元即可
Display(p, s);
return 0;
}这个也是比较简单的,我们就直接过了就行。
继承与静态成员:
详解 C++ 继承体系中静态成员的 "全局唯一性" 特性
在 C++ 继承体系里,基类定义的static静态成员(包括静态成员变量和静态成员函数)有一个核心特性 ------全局唯一实例,这个特性贯穿整个继承体系,不会因派生类的创建或对象实例化而改变。
一、静态成员 "全局唯一" 的本质:不依赖对象,属于类本身
首先要明确static成员的基础特性:它不属于某个具体的对象,而是属于整个类,存储在全局数据区(而非对象的内存空间)。无论创建多少个类对象,静态成员都只有一份副本,所有对象共享这一个实例。
当基类定义了静态成员后,这个 "属于类、全局唯一" 的属性会直接延续到继承体系中:整个继承体系(包括基类自己、所有直接派生的子类、子类再派生的孙类等)里,只会存在这一个静态成员实例,不会因为类的继承关系而产生新的副本。
二、具体表现:子类与基类共享同一静态成员
假设基类Parent定义了静态成员变量count和静态成员函数getCount(),子类Child公有继承Parent,此时会有以下关键表现:
- 子类不生成新副本 :
Child不会因为继承Parent,就额外创建一个属于自己的count副本,它和Parent共享同一个count实例。 - 访问方式不影响唯一性 :无论是通过基类访问(
Parent::count、Parent::getCount()),还是通过子类访问(Child::count、Child::getCount()),本质都是操作同一个静态成员实例。 - 对象数量不影响唯一性 :哪怕创建 10 个
Parent对象、20 个Child对象,这些对象访问的count依然是同一个,修改其中一个对象关联的count,所有对象访问到的count值都会同步变化。
三、核心逻辑:静态成员的归属与继承无关
静态成员的 "全局唯一" 特性,根源在于它的归属权只属于定义它的基类 ,继承关系不会改变它的归属。子类虽然能访问基类的静态成员(取决于访问权限,如public或protected),但这种访问是 "共享式访问",而非 "拥有式继承"------ 子类没有自己的静态成员副本,只是获得了访问基类静态成员的权限。
例如:
cpp
class Parent {
public:
static int count; // 基类定义静态成员变量
};
int Parent::count = 0; // 静态成员必须在类外初始化
class Child : public Parent {}; // 子类继承基类
int main() {
Parent p1;
Child c1;
p1.count++; // 基类对象修改:count变为1
c1.count++; // 子类对象修改:count变为2
cout << Parent::count; // 输出2(所有访问共享同一实例)
cout << Child::count; // 输出2(与基类共享同一实例)
return 0;
}上述代码中,Parent和Child的所有操作,最终都作用于同一个count实例,充分体现了静态成员在继承中的 "全局唯一性"。
还有比如下面这一段代码:
cpp
class Person
{
public:
string _name;
static int _count;
};
int Person::_count = 0;
class Student : public Person
{
protected:
int _stuNum;
};
int main()
{
Person p;
Student s;
// 这里的运行结果可以看到非静态成员_name的地址是不一样的
// 说明派生类继承下来了,父派生类对象各有一份
cout << &p._name << endl;
cout << &s._name << endl;
// 这里的运行结果可以看到静态成员_count的地址是一样的
// 说明派生类和基类共用同一份静态成员
cout << &p._count << endl;
cout << &s._count << endl;
// 公有的情况下,父派生类指定类域都可以访问静态成员
cout << Person::_count << endl;
cout << Student::_count << endl;
return 0;
}总结
基类的static静态成员在继承体系中是 "全局唯一" 的:整个体系内只有一份实例,子类不生成新副本,所有类(基类、子类)和对象都共享这一份。这种特性的本质是静态成员 "属于类、不依赖对象" 的基础属性,继承关系只会传递其访问权限,不会改变其 "唯一实例" 的核心特性。
结语:
亲爱的小伙伴们,当你读到这里时,我们关于 C++ 继承的第一篇博客已经接近尾声了。或许此刻你眼前还浮现着类与类之间的 "父子关系",脑海里回荡着 "切片""隐藏""静态成员共享" 这些陌生又熟悉的概念 ------ 别急,这正是我们一步步走进 C++ 进阶世界的印记。
回顾这篇博客的旅程,我们从 "代码复用" 的初心出发,揭开了继承的神秘面纱。你看,当 Student 和 Teacher 类不再重复书写姓名、年龄这些共性成员,而是优雅地继承自 Person 类时,我们第一次感受到了继承的魅力:它像一把精巧的剪刀,裁掉了冗余的代码,留下了简洁与高效。就像现实中,我们不必重新学习 "呼吸""行走" 这些人类共有的能力,而是直接继承它们,专注于培养属于自己的独特技能 ------ 编程、绘画、思考,这或许就是继承最生动的隐喻。
我们聊到了继承的三种方式,public、protected、private,它们像三道不同的门:public 继承让基类的接口坦然向世界开放,就像父母教会我们 "善良" 与 "真诚",让我们能在社会中自然展现;protected 继承则像家族内部的秘密技艺,只传子孙,不泄外人;而 private 继承更像尘封的日记,仅当前类可翻阅。这些访问控制的规则,看似繁琐,实则是 C++ 对 "封装性" 的坚守 ------ 既让代码复用成为可能,又严格守护着每个类的边界。
还记得 "切片" 现象吗?子类对象能被基类指针或引用指向,却不能反过来,这像极了生活中的 "局部与整体":我们可以说 "学生是一个人",却不能说 "人是一个学生"。这种单向的转换规则,不仅符合逻辑,更藏着 C++ 对类型安全的深思。而当我们看到子类对象的内存中 "嵌套" 着父类成员时,是不是突然明白:原来继承不是简单的 "复制粘贴",而是一种巧妙的 "包含与共享"------ 父类的定义是公共的模板,每个子类对象却拥有独立的父类成员存储空间,就像每个孩子都继承了父母的基因,却长成了独一无二的自己。
类模板的继承或许让你有些头疼:为什么调用父类成员函数时非要加类域或 this 指针?"按需实例化" 的机制告诉我们,编译器其实是个 "懒家伙",不到万不得已不会生成代码 ------ 这也提醒我们,写代码时要像给编译器 "指路" 一样清晰,才能避免不必要的错误。而成员的 "隐藏" 规则更像一记警钟:子类与父类的同名成员看似巧合,实则可能埋下逻辑陷阱,就像两个同名的文件放在不同文件夹,稍不注意就会拿错。
实现一个不能被继承的类、友元关系的不可继承性、静态成员的全局唯一性...... 这些知识点像一颗颗散落的珍珠,被 "继承" 这条线串在一起,渐渐勾勒出 C++ 面向对象设计的轮廓。你会发现,继承从来不是孤立的技术,它与封装、作用域、访问控制紧密相连,共同构建着代码的秩序与美感。
或许现在的你,对某些概念还似懂非懂,看到代码时仍会犹豫 ------ 这太正常了。学习就像爬山,每向上一步,都会看到新的风景,也会遇到新的挑战。继承作为 C++ 的三大特性之一,其深度与广度需要我们在实践中慢慢品味:多写几行代码验证 "隐藏" 与 "重载" 的区别,多调试几次观察 "切片" 时的内存变化,多思考为什么静态成员要在类外初始化...... 这些细碎的探索,终将让你对继承的理解从 "知道" 变为 "懂得"。
下一篇博客中,我们将深入继承体系中构造函数与析构函数的调用规则,看看当子类诞生与消亡时,父类会扮演怎样的角色。那会是另一段充满发现的旅程,既有规则的严谨,也有设计的智慧。
最后,想对每一个坚持学习的你说:编程的路上没有捷径,但每一步都算数。当你能熟练运用继承搭建出清晰的类层次结构,当你能在代码中既享受复用的便捷,又坚守封装的边界,你会发现,那些曾经让你困惑的概念,早已变成你手中灵活的工具。
休息一下,整理好心情,我们下一篇博客再见。记住,你此刻的每一分努力,都在为未来的自己铺路。加油,勇敢的代码探索者!