Pi Coding Agent 编码工具的定制
不谈玄学,只讲落地。
我是一名深耕算法工程化一线的实践者,擅长将 新技术、关键技术、AI/ML 技术从论文和 demo 转化为可规模化部署的生产系统。在这里,你看不到堆砌公式的理论空谈,只有真实项目中踩过的坑、趟过的路,每一篇文章都源自实战经验的提炼。我相信技术的价值在于解决真实问题,而不是制造焦虑。如果你也厌倦了"收藏即学会",渴望掌握让算法真正跑起来的硬核能力,那么这里就是你的技术补给站。
两种哲学的碰撞
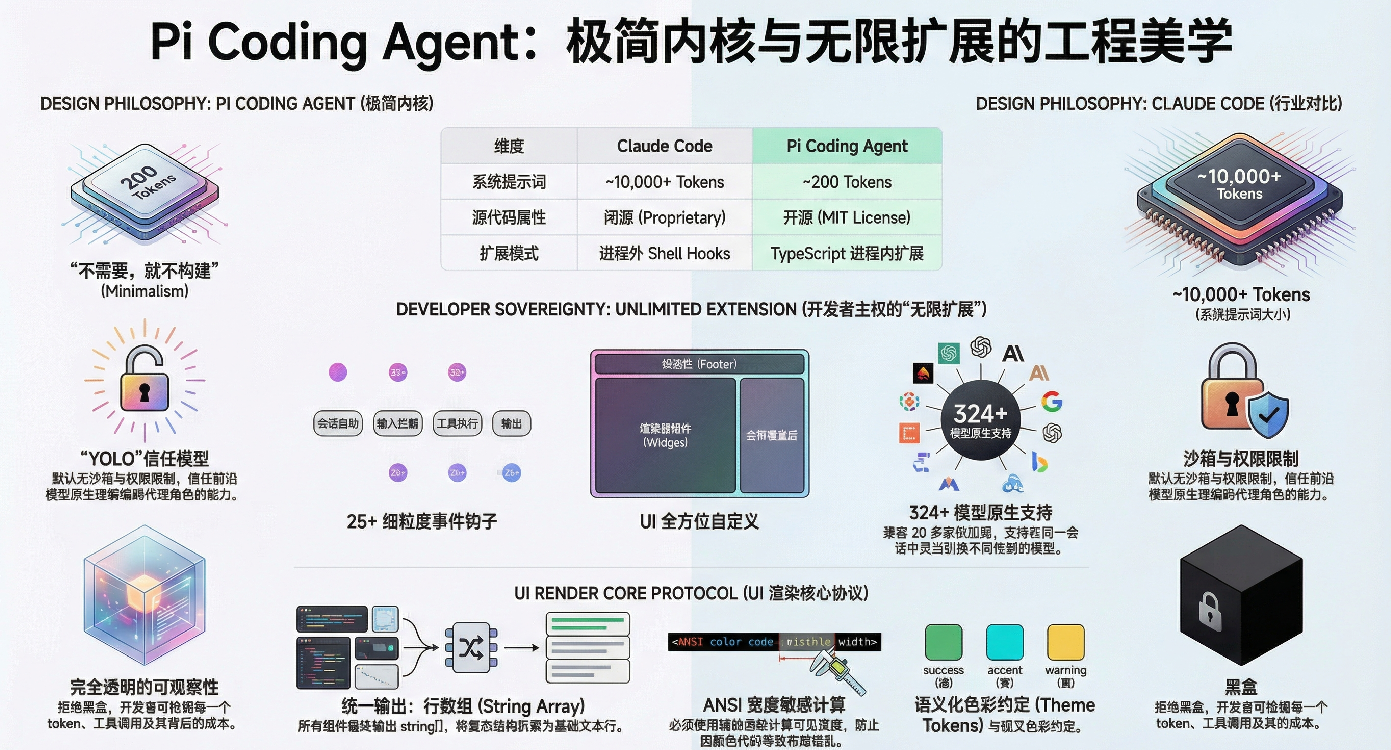
2026 年初,AI 编码代理市场上存在两种截然不同的设计哲学。
Claude Code 选择了"内置一切"------10+ 工具、~10,000 token 的系统提示、5 种权限模式、内建子代理和团队协调。它的理念是把复杂性藏在引擎盖下,让用户不用思考就能上手。
Pi Coding Agent 走向了另一个极端------4 个工具、~200 token 的系统提示、零内置权限。它的创造者 Mario Zechner(libGDX 的作者)有一句口头禅:"前沿模型已经被 RL 训练得够好了,它们天然理解什么是编码代理。"
这两种哲学都有道理。但让我着迷的是 Pi 的做法------它把所有高级功能都推到了扩展层。这意味着,安全审计是扩展,多代理团队是扩展,任务管理是扩展,甚至连状态栏显示什么都是扩展。
我花了几周时间深入研究了 pi-vs-cc 这个项目------16 个 Pi 扩展,从 24 行的纯净模式到 700+ 行的任务纪律系统。在这个过程中,我发现这些扩展不是简单的脚本集合,而是一部浓缩的架构模式教科书。
更重要的是,这些模式与具体的语言和框架无关。它们是通用的。
全景:一个扩展系统的四层架构
在深入每个模式之前,先看全局。Pi 的扩展体系可以分为四层:
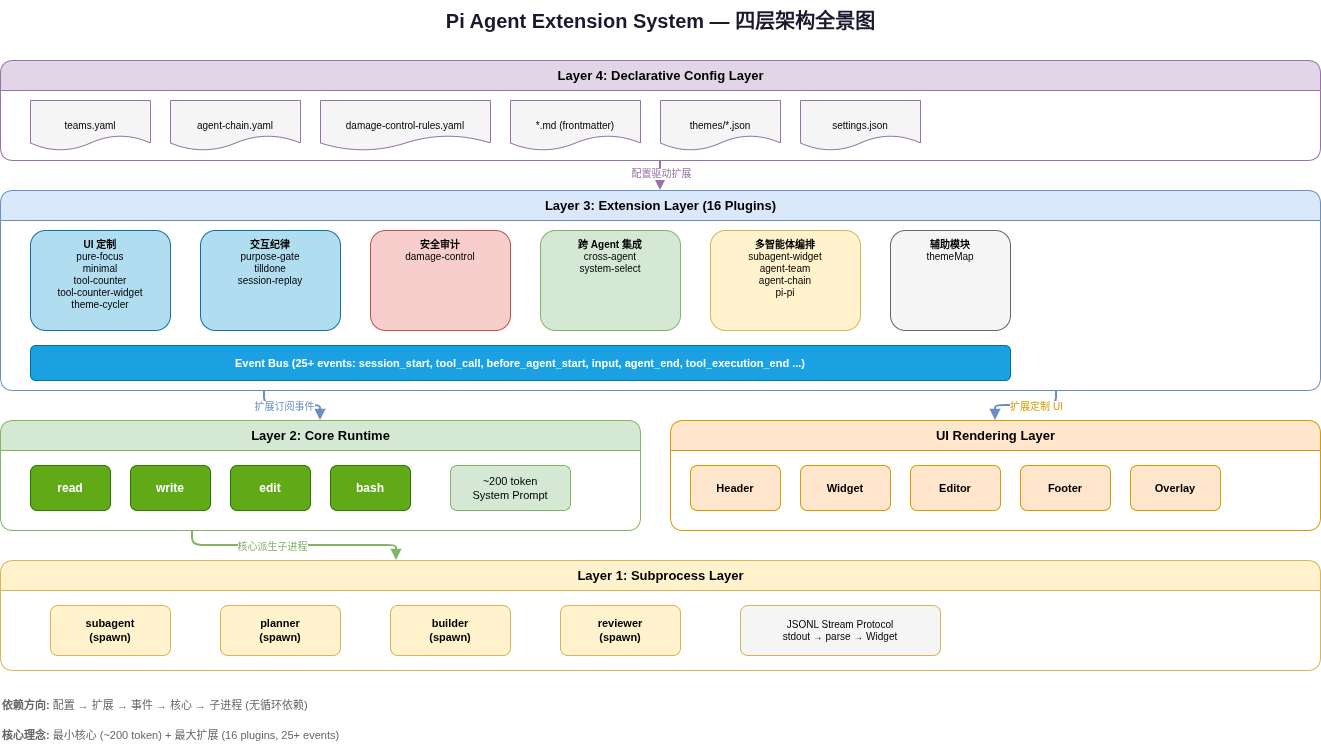
┌─────────────────────────────────────────────────────────────┐
│ Declarative Config Layer │
│ teams.yaml agent-chain.yaml *.md(frontmatter) *.json │
├─────────────────────────────────────────────────────────────┤
│ Extension Layer (16 plugins) │
│ 每个扩展 = 一个函数,接收 API 对象,注册能力 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ UI 定制 │ │ 安全审计 │ │ 任务管理 │ │ 多代理 │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
│ └──────┬─────┴──────┬─────┴──────┬──────┘ │
│ │ Event Bus (25+ events) │ │
├───────────────┴─────────────────────────┴────────────────────┤
│ Core Runtime │
│ 4 tools: read / write / edit / bash │
│ ~200 token system prompt │
├─────────────────────────────────────────────────────────────┤
│ Subprocess Layer │
│ spawn("pi", [...]) → JSONL stream → Widget │
└─────────────────────────────────────────────────────────────┘四层之间有清晰的依赖方向:配置驱动扩展,扩展订阅事件,事件来自核心,核心可派生子进程。没有循环依赖。这种分层本身就是第一个值得学习的架构决策。
下面,我从这 16 个扩展中提炼出 10 个通用模式。每个模式我会讲三件事:它解决什么问题 、它的结构长什么样 、它如何超越具体语言。
模式 1:单入口注册式插件
问题
你的系统需要第三方扩展能力,但你不想让插件继承你的基类(紧耦合),也不想要求插件实现复杂的接口(高门槛)。
结构
Pi 的每个扩展只有一个入口------一个默认导出的函数:
typescript
export default function (pi: ExtensionAPI) {
pi.registerTool({ name: "mytool", ... });
pi.registerCommand("mycommand", { ... });
pi.on("session_start", async (event, ctx) => { ... });
}没有类要继承。没有抽象方法要实现。宿主把自己的 API 对象递给插件,插件调用 register*() 方法声明自己的能力,调用 on() 订阅感兴趣的事件。
项目中最小的扩展 pure-focus.ts 只有 24 行,它做的事情就是用一个空渲染器替换掉默认的 Footer:
typescript
export default function (pi: ExtensionAPI) {
pi.on("session_start", async (_event, ctx) => {
ctx.ui.setFooter(() => ({
render: () => [], // 返回空数组 = 不显示任何内容
invalidate() {},
dispose() {},
}));
});
}24 行。这就是一个完整的、可运行的、有实际用途的扩展。
为什么这很重要
注册优于继承。 当你设计插件系统时,最大的诱惑是定义一个 BasePlugin 类让大家继承。但继承带来三个问题:版本锁定(基类改了签名所有插件都要改)、菱形继承(多插件组合时)、强制结构(你必须实现所有抽象方法,哪怕你只需要其中一个)。
注册式没有这些问题。插件只注册它关心的东西。不注册 = 不参与。一个 24 行的 UI 扩展和一个 700 行的任务管理系统共用同一个入口签名。
跨语言通用性:
python
# Python --- 一个函数就够了
def init(api):
api.register_tool("mytool", handler=my_handler)
api.on("session_start", on_start)
java
// Java --- 一个接口 + 一个方法
public interface Extension {
void init(ExtensionAPI api);
}
go
// Go --- 一个函数签名
func Init(api HostAPI) {
api.RegisterTool(ToolSpec{Name: "mytool", Handler: handle})
}无论什么语言,核心是同一个契约:一个入口函数,一个 API 对象,注册式声明能力。
模式 2:事件总线 + 返回值决策链
问题
多个插件需要对同一个事件做出反应,并且某些插件需要能够拦截 或修改事件的处理流程。
结构
Pi 的事件系统有一个精妙设计:处理器的返回值就是决策。
Event 流经处理链:
tool_call ──▶ purpose-gate ──▶ tilldone ──▶ damage-control ──▶ Execute
│ │ │
▼ ▼ ▼
{action: {block:true, {block:true,
"handled"} reason:"无 reason:"rm -rf
阻止输入 任务"} 检测到"}看 damage-control 的拦截逻辑------它监听 tool_call 事件,检查是否匹配危险规则,然后返回一个结构化的决策对象:
typescript
pi.on("tool_call", async (event, ctx) => {
if (isToolCallEventType("bash", event)) {
for (const rule of rules.bashToolPatterns) {
if (new RegExp(rule.pattern).test(event.input.command)) {
if (rule.ask) {
const ok = await ctx.ui.confirm("确认执行?", rule.reason);
if (!ok) return { block: true, reason: rule.reason };
} else {
return { block: true, reason: rule.reason };
}
}
}
}
return { block: false };
});这里的关键是 return { block: true, reason: "..." }。处理器不是调用 ctx.block() 这样的副作用方法,而是返回一个不可变的决策对象。这使得整条链可以被日志化、测试和推理。
为什么这很重要
返回值即决策是一个比"调用副作用方法"更优雅的拦截模式。原因有三:
- 可测试 --- 给 handler 一个 mock event,检查返回值,不需要 mock 任何副作用
- 可组合 --- 多个 handler 的返回值可以合并(任意一个 block=true 则整体 block)
- 可追溯 --- 每个决策都有 reason 字段,出了问题可以追溯到具体哪条规则
短路语义 也很重要:任何一个 handler 返回 block: true,后续 handler 不再执行。这与 Unix 管道的 set -e 和 Java Servlet Filter 的 chain.doFilter() 是同一个思想。
这个模式适用于任何需要"多方投票决定是否放行"的场景:API 网关的中间件链、表单验证的规则链、CI/CD 流水线的质量门禁。
模式 3:统一渲染协议
问题
你有多种 UI 组件(Footer、Widget、Overlay),它们的布局和功能各不相同,但你需要一个统一的渲染机制。
结构
Pi 的所有 UI 组件------无论是简单的单行 Footer 还是复杂的可滚动 Overlay------都遵循同一个协议:
interface Renderer {
render(width: number): string[] // 输入宽度,输出行数组
invalidate(): void // 标记数据已变化
dispose(): void // 资源清理
}三个方法,一个核心约定:render() 是纯函数,输入宽度,输出字符串数组。
这个设计让终端 UI 的复杂性降到最低。tool-counter 的 Footer 返回 2 行,tilldone 返回 5-8 行,session-replay 的 Overlay 返回 30+ 行------但对宿主来说,它们都是 string[]。
更聪明的是 invalidate/render 分离 。数据变化时只标记脏(invalidate),真正的计算推迟到下一帧渲染(render)。如果一秒内发生 100 次数据变化但只渲染 30 帧,你省了 70 次无用计算。
为什么这很重要
统一输出协议 是构建可组合 UI 系统的基石。React 的组件返回 Virtual DOM,Flutter 的 Widget 返回 Element Tree,终端 UI 返回 string[]------抽象层级不同,思想相同:所有组件都输出同一种中间表示。
这个模式在任何 UI 系统中都适用。如果你在做仪表盘、报表系统、或者任何有多种可视化组件的产品,定义一个统一的输出协议是第一步。
模式 4:声明式配置驱动行为
问题
你需要让非开发者(或者不想每次都写代码的开发者)能够定义系统行为。
结构
Pi 的扩展系统用了三种声明式配置格式,覆盖三种不同的需求:
Markdown + Frontmatter → 定义 Agent 角色:
markdown
---
name: planner
description: Architecture and implementation planning
tools: read,grep,find,ls
---
You are a planner agent. Analyze requirements and produce
clear, actionable implementation plans. Do NOT modify files.6 行配置,就定义了一个只读分析专家。元数据(name、tools)用 YAML,行为描述用自然语言。创建一个新角色的成本接近零。
YAML → 定义团队和管道:
yaml
# teams.yaml --- 定义谁和谁一起工作
plan-build:
- planner
- builder
# agent-chain.yaml --- 定义谁先做谁后做
plan-build-review:
steps:
- agent: planner
prompt: "分析并制定计划: $INPUT"
- agent: builder
prompt: "根据计划实现: $INPUT"
- agent: reviewer
prompt: "审查代码: $INPUT"YAML → 定义安全规则:
yaml
bashToolPatterns:
- pattern: "rm\\s+(-[^\\s]*)?\\s*-[^\\s]*r"
reason: "递归删除检测"
ask: false
zeroAccessPaths:
- ".env"
- "~/.ssh/"为什么这很重要
这三种配置格式背后是同一个原则:用声明描述"是什么",用引擎决定"怎么做"。
添加一个新 Agent 不需要写 TypeScript------写一个 .md 文件。
组建一个新团队不需要改代码------编辑 teams.yaml。
添加一条安全规则不需要碰扩展源码------编辑 damage-control-rules.yaml。
这是 配置即代码的平民替代品。不是每个配置变更都值得一次代码审查和部署。有些行为的变更频率远高于代码,它们应该活在配置文件里。
Kubernetes 的 YAML manifests、Terraform 的 HCL、GitHub Actions 的 workflow YAML------它们都是这个模式的工业级实践。
模式 5:分层规则引擎
问题
你需要一个灵活的安全/校验系统,规则会频繁变化,而且不同规则有不同的严格程度。
结构
damage-control 的规则引擎不是一个扁平的规则列表,而是四层金字塔:
严格程度
▲
│ Layer 1: zeroAccessPaths → 完全禁止 (.env, ~/.ssh)
│ Layer 2: bashToolPatterns → 命令拦截 (rm -rf, DROP TABLE)
│ Layer 3: readOnlyPaths → 只读保护 (node_modules, /etc)
│ Layer 4: noDeletePaths → 禁止删除 (.git, README.md)
▼
宽松程度评估顺序从最严格到最宽松。一旦在任意层匹配到违规,立即终止评估------不需要检查后面的层。
每层内部,规则也不是简单的 true/false。bashToolPatterns 有一个 ask 字段:
ask: false→ 直接阻止,不给商量ask: true→ 暂停,弹出确认对话框,让用户决定
这比全部禁止或全部放行都要好。rm -rf / 应该被无条件阻止,但 git push --force 可能在某些场景下是合理的------让用户来判断。
为什么这很重要
分层 + 渐进式响应是规则引擎的最佳实践。扁平规则列表的问题是无法表达"A 比 B 更严格"。分层后,语义清晰:第 1 层的规则永远优先于第 4 层。
ask 机制 是一个值得推广的设计。在安全系统中,最常见的错误是把应该 ask 的规则设成了 block,导致用户抱怨;或者把应该 block 的规则设成了 ask,导致安全事故。显式区分这两种策略,让规则编写者做出有意识的选择。
模式 6:能力剥夺式调度
问题
你想让一个 AI Agent 协调多个专家代理,但你不想让它"既当裁判又下场踢球"------即自己做调度的同时也直接处理任务。
结构
agent-team 的设计做了一个大胆决定:主 Agent 被剥夺了所有代码工具。
Before: Agent tools = [read, write, edit, bash, grep, find, ls]
│
setActiveTools(["dispatch_agent"])
│
After: Agent tools = [dispatch_agent] ← 只剩一个工具主 Agent 的系统提示被改写为:
"你是一个调度员。你没有任何代码工具。你唯一的工具是 dispatch_agent。所有工作都必须委派给你的团队成员。"
这不是"建议"它去委派,而是在架构层面让它不可能直接执行代码。它被迫思考"谁最适合做这件事",而不是"我自己怎么做这件事"。
专家之间的差异也通过工具集体现:
planner: [read, grep, find, ls] ← 只读
builder: [read, write, edit, bash, ...] ← 读写
reviewer: [read, bash, grep, find, ls] ← 只读 + 可运行测试Planner 想写文件?做不到,它的工具集里没有 write。架构约束比口头嘱咐强一万倍。
为什么这很重要
能力剥夺 > 能力添加。 这是我从这个项目中学到的最反直觉的架构原则。
传统做法是给调度员"添加"调度能力。但问题是,一个既能调度又能直接执行的 Agent 往往会走捷径------"这个小任务我自己做算了"。结果就是调度员变成了全栈,专家形同虚设。
Pi 的做法是反过来:先给你所有工具,然后把不该有的全部拿走。这就像给 CEO 一个没有代码编辑器的电脑------你想写代码?先找你的工程师。
这个原则适用于任何需要角色分离的系统:微服务之间的权限隔离、数据库用户的最小权限原则、Kubernetes 的 RBAC。不是"你可以做什么",而是"你只能做什么"。
模式 7:$INPUT 管道
问题
你需要多个 Agent(或处理步骤)按顺序执行,每一步的输出喂给下一步。
结构
agent-chain 用了可能是世界上最简单的管道实现------字符串替换:
yaml
plan-build-review:
steps:
- agent: planner
prompt: "分析需求并制定计划: $INPUT"
- agent: builder
prompt: "根据计划实现: $INPUT"
- agent: reviewer
prompt: "审查代码,原始需求: $ORIGINAL\n代码: $INPUT"两个变量,两条规则:
$INPUT= 上一步的输出(第一步时 = 用户原始输入)$ORIGINAL= 始终是用户的初始提示
引擎的实现极其简洁:
currentInput = userPrompt
for step in pipeline.steps:
prompt = step.prompt
.replace("$INPUT", currentInput)
.replace("$ORIGINAL", userPrompt)
currentInput = execute(step.agent, prompt)
return currentInput没有消息队列、没有序列化协议、没有 Schema 验证。只有字符串替换。
为什么这很重要
管道的威力在于简单。 Unix 哲学是 cat file | grep pattern | sort | uniq -c------每个程序只做一件事,用 | 组合。Pi 的 agent-chain 是同一个思想:每个 Agent 只有一个职责,用 $INPUT 串联。
复杂的管道框架(Airflow、Prefect、Temporal)有它们的价值,但对于 AI Agent 编排来说,$INPUT 字符串替换就够了。原因是 LLM 的输入输出都是文本------不需要 protobuf 或 JSON Schema 来定义接口契约,自然语言本身就是最灵活的接口。
模式 8:Fire-and-Forget + 流式回调
问题
你需要异步启动子任务,不阻塞主流程,但需要实时看到子任务的进度。
结构
subagent-widget 的做法是启动子进程、立即返回、流式读取进度、完成后回调:
Main Agent Subagent Process
┌──────────┐ ┌──────────────────┐
│ │ spawn("pi",[...]) │ pi --mode json │
│ │─────────────────────▶│ -p "task" │
│ 立即返回 │ │ │
│ "已启动" │ stdout (JSONL) │ {"type": │
│ │◀─────────────────────│ "message_update"│
│ 更新 │ (持续流入) │ "delta":"..."} │
│ Widget │ │ │
│ │ on("close") │ exit(0) │
│ sendMsg │◀─────────────────────│ │
│ (result) │ └──────────────────┘
└──────────┘关键技术细节是 JSONL 流缓冲区管理:
typescript
let buffer = "";
proc.stdout.on("data", (chunk) => {
buffer += chunk;
const lines = buffer.split("\n");
buffer = lines.pop() || ""; // 最后一行可能不完整
for (const line of lines) {
if (line.trim()) processEvent(JSON.parse(line));
}
});TCP 数据是字节流,不保证按行到达。一个 JSON 对象可能跨两个 chunk。buffer + split + pop 是处理这种情况的标准技法。
为什么这很重要
Fire-and-Forget + Callback 是异步编排的轻量级替代品。 你不需要 Redis Queue、不需要 Celery、不需要 gRPC streaming。一个子进程、一个 stdout 管道、一个 JSONL 协议------足以实现实时进度追踪。
JSONL(每行一个 JSON) 是进程间通信的最佳文本协议。比 XML 简单、比裸 JSON 流易解析(用换行符分割)、比 protobuf 易调试(人可读)。Docker、Kubernetes、Elasticsearch 都用 JSONL 做日志格式,不是偶然。
模式 9:状态持久性光谱
问题
不同的数据有不同的生命周期需求------工具调用计数重启后丢了无所谓,但任务列表丢了就是灾难。你不想为每种状态都搭建一套持久化方案。
结构
这 16 个扩展展示了四种状态管理策略,形成一个从易失到持久的光谱:
易失 ◀─────────────────────────────────────────────────────▶ 持久
闭包变量 details 字段 appendEntry 文件系统
(tool-counter) (tilldone) (damage-control) (subagent-widget)
│ │ │ │
会话内有效 随工具结果自动 写入会话 JSONL 独立文件
重启即丢失 保存到会话 JSONL 可后续查询 跨会话存在
零成本 几乎零成本 几乎零成本 有 I/O 成本最精妙的是 tilldone 的 details 持久化 + 重建 模式。它不维护自己的数据库,而是把每次操作的快照塞进工具结果的 details 字段:
typescript
// 工具执行后,把当前完整状态放进 details
return {
content: [{ type: "text", text: "Added task #1" }],
details: { tasks: [...allTasks], nextId: 2, listTitle: "Auth" },
};
// 重启后,遍历会话历史,取最后一个快照恢复状态
for (const entry of session.getBranch()) {
if (entry.toolName === "tilldone") {
state = entry.details; // 最后一个 = 最新状态
}
}不需要额外存储。会话 JSONL 本身就是数据库。
为什么这很重要
选择最弱的持久性 是这个光谱的核心原则。不是所有数据都值得写磁盘。闭包变量零成本、零复杂度,如果数据可以丢失(如调用计数),用闭包变量就够了。
利用已有存储 是 tilldone 教给我的。它没有引入 SQLite、没有写 JSON 文件、甚至没有调用 fs.writeFile()。它利用了一个已经存在的事实------工具结果会自动写入会话 JSONL------把自己的状态"搭便车"存进去。
这个思维方式在数据库设计中叫做 Event Sourcing :不存当前状态,存每一步操作。当前状态可以从操作历史中重建。tilldone 的 details 就是一个轻量级的 Event Sourcing。
模式 10:零耦合组合
问题
你希望多个插件能自由组合,但它们之间不能有依赖关系------因为用户可能只安装其中几个。
结构
Pi 的扩展可以堆叠:
bash
pi -e extensions/minimal.ts -e extensions/cross-agent.ts -e extensions/theme-cycler.ts三个扩展同时运行,但它们互不知道对方的存在。组合后的效果是各自能力的叠加:
Footer Widget Commands Shortcuts Events
minimal ✓ ✓
cross-agent ✓ ✓ ✓
theme-cycler ✓ ✓ ✓ ✓
─────────────────────────────────────────────────────────────
组合结果 ✓ ✓✓ ✓✓ ✓ ✓✓✓当多个扩展试图设置主题时,冲突通过主扩展优先级 解决------命令行中第一个 -e 后面的扩展是"主扩展",它的主题生效,其他扩展的主题设置被静默跳过。
typescript
function primaryExtensionName(): string | null {
for (let i = 0; i < process.argv.length - 1; i++) {
if (process.argv[i] === "-e") {
return basename(process.argv[i + 1]); // 第一个 = 主扩展
}
}
return null;
}为什么这很重要
零耦合组合 的关键是确定性的冲突解决策略。当两个插件都想设置主题时,不是随机的(取决于加载顺序的隐式行为),而是显式的规则(第一个 -e = 主扩展)。
这个模式的适用范围很广:VS Code 的扩展、Chrome 的 content scripts、WordPress 的插件、Vim 的 plugin。凡是支持多插件并行的系统,都需要回答三个问题:
- 谁先? --- 加载/执行顺序
- 冲突怎么办? --- 同一资源被多人设置
- 彼此不知道对方存在是否可行? --- 零依赖 vs 可选依赖
Pi 的答案简洁有力:命令行顺序决定优先级,同名命令先注册者生效,事件所有订阅者都收到。
写在最后:三个带走的原则
从这 16 个扩展、10 个模式中,如果只能带走三条原则,我会选:
1. 注册优于继承。 给插件一个 API 对象,让它调用 register*(),而不是逼它继承你的 BasePlugin。前者是邀请,后者是强制。
2. 能力剥夺 > 能力添加。 当你需要角色分离时,不是给调度员"添加"调度能力,而是把它不该有的能力全部拿走。架构约束比口头约定可靠一万倍。
3. 选择最弱的持久性。 不是所有数据都值得写数据库。闭包变量、搭便车存储(details)、日志条目(appendEntry)、独立文件------从左到右,成本递增,按需选择最便宜的那个。
这些原则不属于 TypeScript,不属于 Pi,不属于 AI Agent。它们属于软件架构本身。
附录:10 个模式速查表
| # | 模式 | 一句话总结 | 典型场景 |
|---|---|---|---|
| 1 | 单入口注册式插件 | 一个函数 + 一个 API + register*() |
任何插件系统 |
| 2 | 事件总线 + 返回值决策链 | 返回 {block:true} 而非调用 ctx.block() |
中间件、拦截器 |
| 3 | 统一渲染协议 | 所有 UI 组件都输出 string[] |
终端 UI、仪表盘 |
| 4 | 声明式配置驱动 | Frontmatter + YAML → 零代码定义行为 | Agent 定义、流水线 |
| 5 | 分层规则引擎 | 四层金字塔 + ask/block 渐进响应 | 安全审计、权限控制 |
| 6 | 能力剥夺式调度 | 拿走所有工具,只留 dispatch_agent |
多 Agent 编排 |
| 7 | $INPUT 管道 | 字符串替换实现步骤串联 | 顺序流水线 |
| 8 | Fire-and-Forget + 流式回调 | spawn → JSONL stream → sendMessage | 异步子任务 |
| 9 | 状态持久性光谱 | 闭包 → details → appendEntry → 文件 | 任何有状态的系统 |
| 10 | 零耦合组合 | 多插件叠加,互不知道对方存在 | 插件市场 |
本文基于 pi-vs-cc 项目的源码分析。项目包含 16 个 Pi Coding Agent 扩展,从 24 行到 700+ 行,覆盖 UI 定制、安全审计、任务管理和多智能体编排。