面试官: "双 11 下午 2 点,我们要发一张'满 1000 减 500'的神券。 库存只有 1 万张,但预计会有 500 万人瞬间涌进来抢。
基础题: 怎么设计架构,保证 绝对不超发?
进阶题: 500 万用户的记录存 Redis,怎么防止 BigKey 把集群打爆?
压轴题: 如果 Redis 扣减成功,但 MQ 发送失败(数据库没落库),怎么解决 数据一致性 问题?
地狱题: 1 万库存分了片,怎么解决 '局部缺货'(有的分片卖光了,有的还有货)的问题?"
兄弟答:"数据库乐观锁...Redis Set 存黑名单..." 面试官摇摇头:"500 万 QPS 打到 MySQL?Set 存 500 万 ID?回去等通知吧。"
一、 核心矛盾与架构设计
在 500 万 QPS 面前,任何直接操作数据库的方案都是 "自杀"。
悲观锁: 数据库串行,吞吐量个位数。
乐观锁: CPU 自旋打满,成功率极低。
结论:交易必须在 Redis 内存中完成,数据库只负责"收尸"(异步归档)。
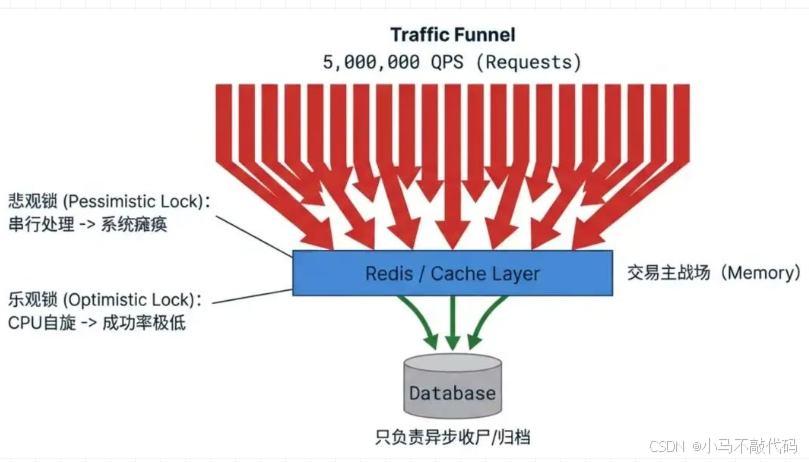
我们必须设计一个 "三级火箭" 架构,像剥洋葱一样把流量一层层拦在外面。
第一级:网关层(无效流量清洗)
库存只有 1 万。如果 Redis 里的全局计数器已经到了 1.5 万,剩下的 498 万请求直接在网关层(Nginx/Gateway)返回"很遗憾,抢光了"。 连 Redis 都不用查,这叫"拦截下沉"。
第二级:应用层(Redis 原子战场)
这是真正的战场。我们需要利用 Redis 的原子性来处理高并发扣减。
第三级:数据层(MQ 异步兜底)
抢到了券的用户,不需要等数据库写入成功。我们发一个 MQ 消息,告诉数据库"慢慢记账",直接给用户返回"领取成功"。
二、 基础防线:Redis + Lua 防止超发
面试官最爱问的坑:
"你用 Redis 的 decr 扣库存?那怎么保证'同一个用户只能领一张'?先 get 判断再 decr,并发这么高,肯定有 Race Condition(竞态条件)!"
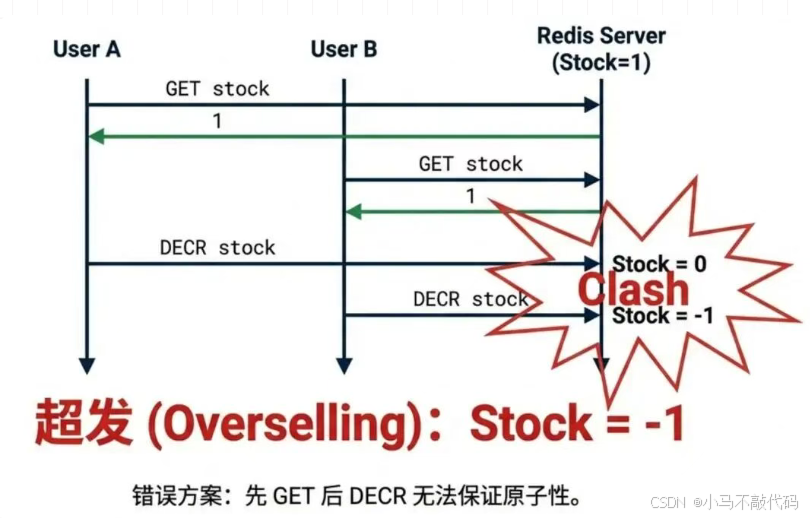
解法:Redis + Lua 脚本
Redis 的命令是原子的,但"业务逻辑"不是。我们必须把 "检查库存"、"检查是否已领"、"扣减库存"、"写入领取记录" 打包进一个 Lua 脚本。 Redis 执行 Lua 脚本是单线程的,同一时刻只能处理一个人的请求,天王老子来了也插不了队。
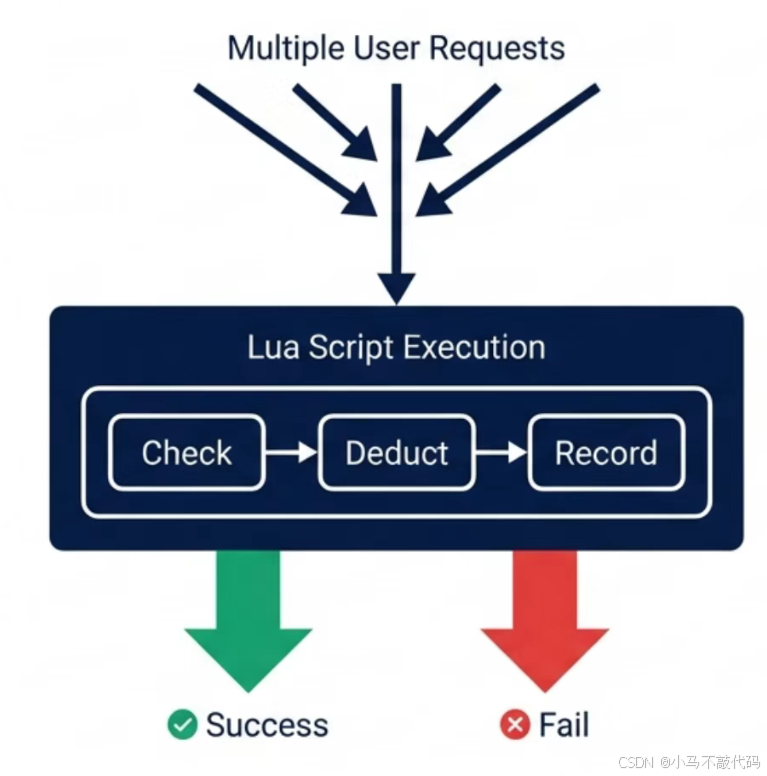
Lua 脚本逻辑(基础版):
java
-- KEYS[1]: 库存Key (e.g., stock_1001)
-- KEYS[2]: 用户已领记录 (e.g., users_1001)
-- ARGV[1]: 用户ID
-- 1. 校验用户是否已领取 (Set结构 - 这是一个坑,后面会优化)
if redis.call('SISMEMBER', KEYS[2], ARGV[1]) == 1then
return-1-- 重复领取
end
-- 2. 校验库存是否充足
local stock = tonumber(redis.call('GET', KEYS[1]))
if stock <= 0then
return-2-- 库存不足
end
-- 3. 核心动作:扣减库存 + 记录用户
redis.call('DECR', KEYS[1])
redis.call('SADD', KEYS[2], ARGV[1]) -- 写入 Set
return1-- 抢券成功写到这里,你给系统埋下了一个 核弹级隐患:BigKey。
三、 深度填坑:BitMap 消灭 BigKey
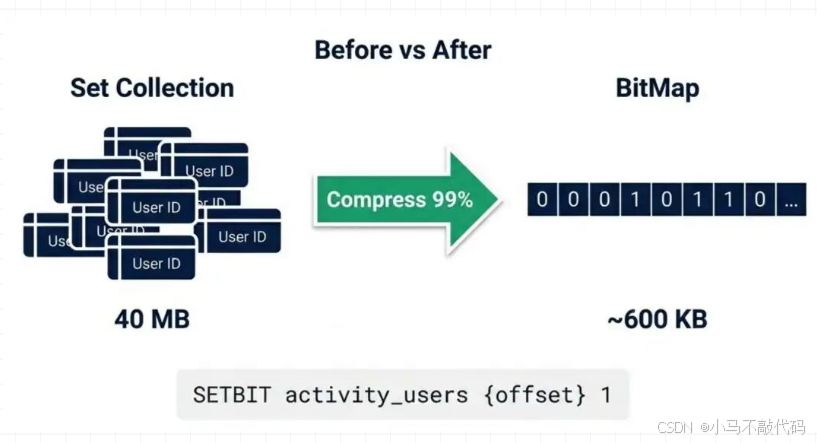
隐患爆发: 上面代码用了 SADD 存用户 ID。 如果有 500 万人领券(或尝试领券),这个 Set 集合里就有 500 万个 ID。
内存占用: 假设 ID 是 Long 类型,500 万 * 8 字节 ≈ 40MB,加上 Redis 指针开销,轻松过百兆。
后果: 这是一个标准的 BigKey。在集群迁移、RDB 落盘时,会直接 阻塞 Redis 主线程,导致全站故障。
解法:BitMap + ID Mapping
我们不存 UserID,我们存 Bit(位)。500 万用户只需要 500 万个 bit,大约 600 KB。内存节省了 99%。
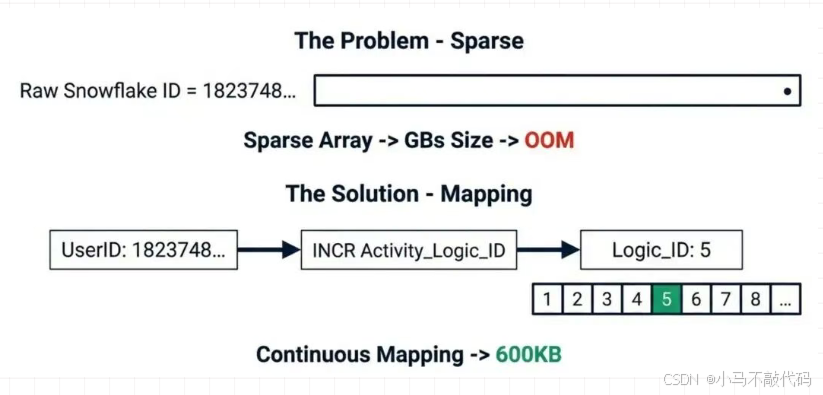
但这里有一个巨大的坑:稀疏 ID 问题。 现在的 UserID 通常是 19 位的雪花算法 ID(如 1823748...)。 如果你直接 SETBIT key 1823748... 1,Redis 会申请 几百 MB 甚至 GB 的连续内存来补齐前面的 0。系统直接 OOM(内存溢出)!
终极方案:自增 ID 映射 (ID Mapping)
我们需要把 离散的大整数 ID 映射为 连续的小整数 Offset。
分配 Slot: 当用户第一次请求活动时,利用 Redis 的 INCR 命令,给该用户分配一个 Activity_Logic_ID(从 1 开始自增)。
存储映射: 将 UserID -> Logic_ID 存入本地缓存或辅助 Redis Hash(有效期仅限活动期间)。
落位: 使用这个 Logic_ID 去 SETBIT。
这样,500 万人,Offset 就是 1~5000000。BitMap 大小被严格控制在 600KB 以内,极致紧凑。
四、 抗压进阶:库存分片与"贫富不均"之痛
面试官追问:
"你的 Redis 只有一个 Key (stock_1001) 存库存。500 万人同时 DECR 这个 Key,Redis 单个分片的 CPU 肯定被打满到 100%,其他业务全阻塞。你怎么解决这个热点?"
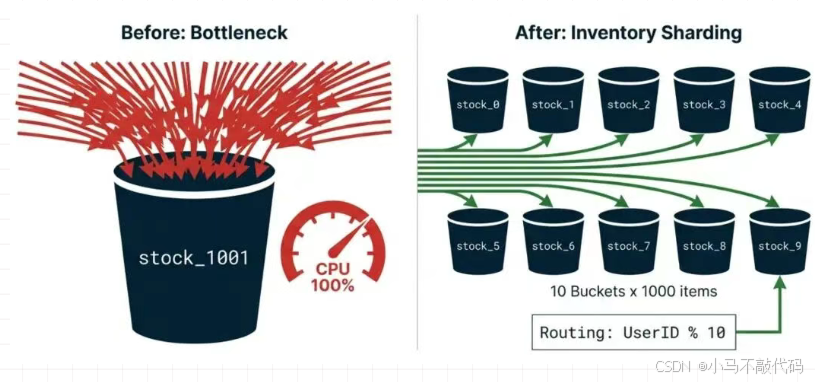
普通解法:库存分片(Sharding)
不要把鸡蛋放在一个篮子里。
拆分: 将 1 万库存拆分为 10 个 Key:stock_1001_0 到 stock_1001_9,每个放 1000 个库存。
路由: 用户请求进来,UserId % 10,路由到对应的分片 Key 上去扣减。
效果: 将单点压力分散到了 10 个 Redis 实例上,吞吐量线性提升 10 倍。
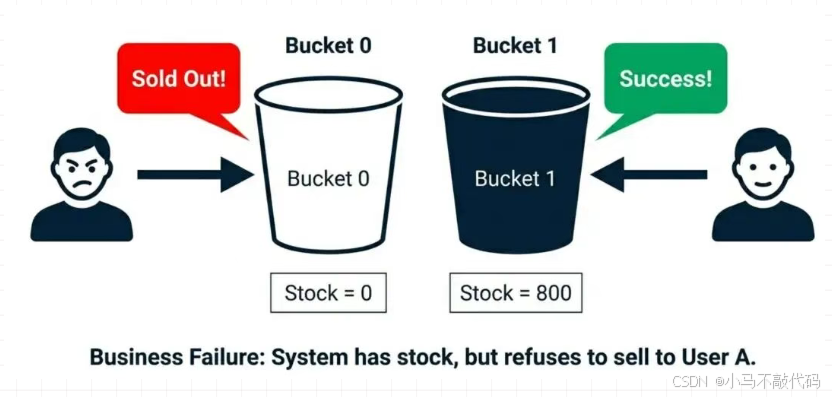
深坑:局部缺货(Hotspot Skew)
面试官:"如果 UserId % 10 路由,万一 stock_0 对应的用户特别热情,1 秒钟把分片 0 抢光了;而 stock_1 的用户比较佛系,还剩 800 个。
后果: 路由到分片 0 的新用户收到'抢光了',但他明明看到朋友(路由到分片 1)还能抢。这叫'局部缺货',是严重的业务事故。"
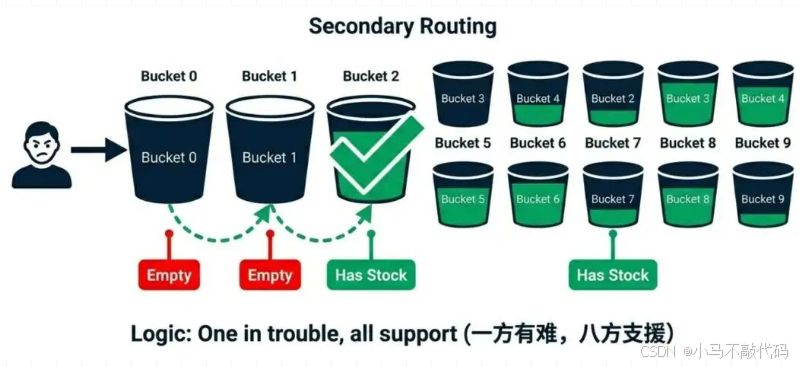
终极方案:Lua 轮询 + 惰性释放
我们不能死板地绑定 UserID 和分片。我们要实现 "一方有难,八方支援"。
Lua 脚本逻辑升级(带权重的二次路由):
第一次尝试: 根据 UserId % 10 计算初始分片 Index。
扣减尝试: 去 stock_{Index} 扣减。
如果 > 0:扣减成功,返回。
如果 <= 0(该分片空了):不要立刻返回失败!
极速轮询(Loop):
在 Lua 脚本内,利用 Redis 内存操作极快的特点,遍历 Index + 1 到 Index + 9 的其他分片。
一旦发现某个分片 stock > 0,立刻扣减并返回。
Lua 代码核心片段:
java
-- ARGV[1]: UserId, ARGV[2]: ShardCount (10)
-- 1. 计算初始分片
local index = ARGV[1] % ARGV[2]
local stockKey = "stock_" .. index
-- 2. 尝试扣减首选分片
if redis.call("DECR", stockKey) >= 0then
return1-- 成功
end
-- 失败回补 (DECR 减成了 -1,必须加回去,否则库存变成负数)
redis.call("INCR", stockKey)
-- 3. 兜底轮询 (核心优化:一方有难八方支援)
-- 遍历其他分片,找到一个有库存的
for i = 1, ARGV[2] - 1do
local nextIndex = (index + i) % ARGV[2]
stockKey = "stock_" .. nextIndex
local stock = tonumber(redis.call("GET", stockKey))
if stock > 0then
-- 发现有货!尝试扣减
if redis.call("DECR", stockKey) >= 0then
return1-- 救活了!
else
redis.call("INCR", stockKey) -- 并发下也被抢光了,继续找下一个
end
end
end
return-1-- 真的全抢光了效果: 用户无感知,只要总量有库存,就一定能抢到。同时保留了分片带来的性能提升。
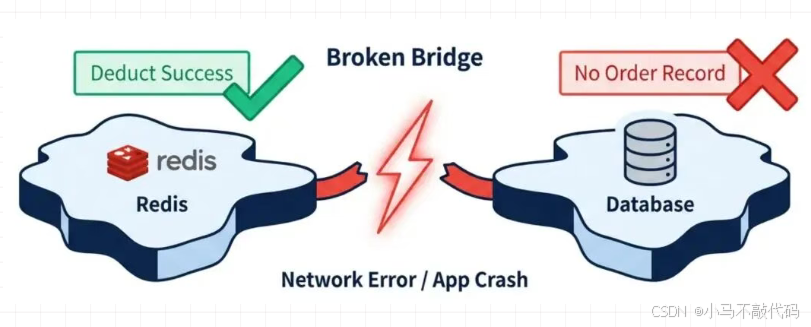
五、 一致性死局:Redis 成功,MQ 挂了怎么办?
面试官:"Lua 脚本执行成功了(库存扣了,BitMap 也是 1),但发 MQ 消息给数据库时网络断了。 结果: Redis 里库存少了,但数据库里没订单。用户显示'抢购成功',去列表里却找不到券。怎么解?"
错误解法:
"在 Lua 前先发 MQ?" -> 不行,万一 Redis 抢失败了,MQ 撤不回,数据库多记了。
"重试?" -> 进程如果挂了(OOM),内存里的重试任务就丢了。
解法:RocketMQ 事务消息(Two-Phase Commit)
普通的 MQ 无法解决这个问题,必须用 事务消息。我们将领券流程倒置,利用 MQ 的 "半消息" 机制来实现类似分布式事务的效果。
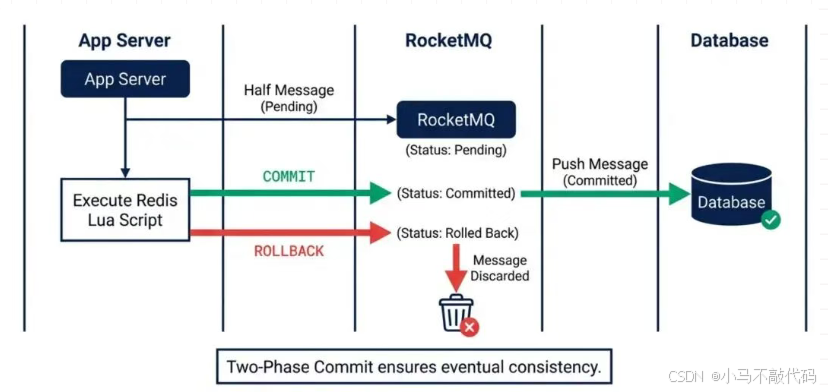
第一阶段:发送半消息 (Prepare)
用户请求到达,先发一条 "Half Message" 给 MQ。
内容: 包含 UserId 和 Logic_Id。
状态: MQ 收到后,暂时不投递给消费者(数据库),只返回"接收成功"。用户对此无感知。
第二阶段:执行本地事务 (Execute)
发送半消息成功后,执行我们的 Redis Lua 抢券脚本。
第三阶段:提交或回滚 (Commit/Rollback)
如果 Redis 抢到了: 告诉 MQ "Commit",MQ 才会把消息推给数据库落库。
如果 Redis 没抢到/报错: 告诉 MQ "Rollback",消息直接丢弃,不落库。
这就完了吗?没有!最坑的地方来了。
六、 回查死局:MQ 来问你时,你查谁?
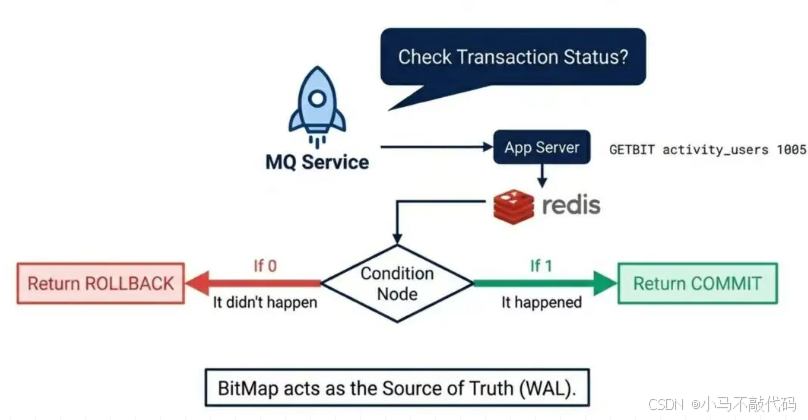
场景复现: 如果 Redis 抢完了(成功),正准备给 MQ 发 Commit 指令时,应用服务器断电了。 MQ 没收到 Commit/Rollback,过了一会会发起 checkLocalTransaction(事务回查)。
MQ 问: "刚才那条半消息,你们到底抢没抢到啊?我该发还是该删?"
你的代码: "呃...我现在查数据库?肯定没数据(还没发)。查 Redis?万一 Redis 刚好也抖动超时呢?"
闭环解法:以"BitMap"为信源
还记得我们在第一部分设计的 BitMap 吗?它不仅仅是防超发,它就是事实上的 "预写日志(WAL)"!
回查逻辑闭环:
MQ 带着 Logic_Id 来回查。
代码去 Redis 查 BitMap:GETBIT key logic_id。
判断:
结果为 1: 说明 Redis 之前肯定执行 Lua 成功了(因为 Lua 是原子的,置 1 和扣库存是一起的)。-> 返回 COMMIT。
结果为 0: 说明 Redis 没执行,或者执行失败了。-> 返回 ROLLBACK。
Redis 报错:****返回 UNKNOWN(等下次再查,不要急着回滚)。
至此,我们形成了一个完美的逻辑闭环:
Redis 挂了: 熔断降级。
MQ 挂了: 事务消息回查 + BitMap 兜底。
应用挂了: 重启后 MQ 依然会来回查,数据绝不丢失。
七、 最后的防线:Redis 挂了,如何"降级求生"?
面试官:
"你的架构强依赖 Redis。万一 Redis 主从切换失败,或者整个机房网络抖动,Redis 连不上了。 这时候 500 万流量直接打过来,你的代码会抛异常,还是会把数据库打死?"
错误解法:
"catch 异常,去查数据库?" -> 找死。数据库瞬间雪崩,甚至导致订单、用户服务连锁瘫痪。
"直接返回失败?" -> 用户体验极差,活动相当于事故。
解法:本地缓存(Guava)有损降级
我们必须在应用服务器(JVM)内部,保留最后的"火种"。
策略:本地分片兜底
在活动开始前,我们预先将极少量的库存(比如总量的 1%,即 100 张),预热到每台应用服务器的本地缓存(Guava / Caffeine)中。
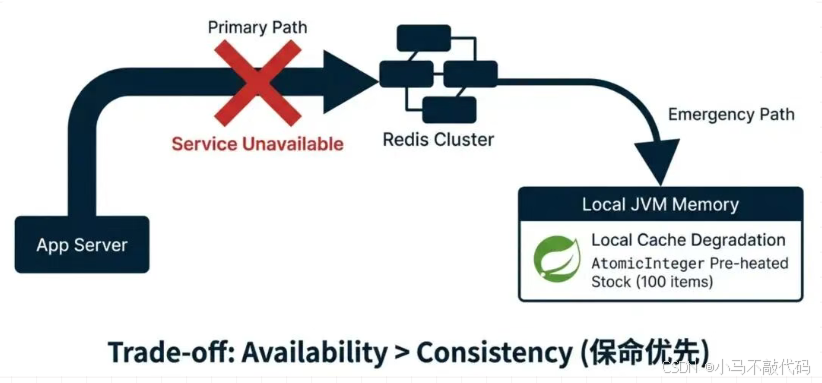
执行流程:
正常模式: 请求走 Redis Lua 抢券。
故障感知: 当系统检测到 Redis 连续超时或报错(Hystrix/Sentinel 熔断触发)。
自动切换: 流量不再请求 Redis,而是直接请求 本地内存里的 AtomicInteger。
localStock.decrementAndGet()
异步记账: 本地抢到后,直接发 MQ(MQ 如果也挂了,就写本地磁盘日志)。
代价(Trade-off):
无法精确控制总量: 比如 100 台机器,每台放 10 张,总量是 1000 张。可能会比 Redis 里的少,或者稍微不可控。
无法防刷: 本地缓存没法做全局去重(BitMap 失效了)。
但是:服务活下来了! 用户能抢到券(虽然少了点),页面没有报错,数据库没有崩盘。在灾难面前,可用性 > 一致性。
八、 面试回答模板
完整的高并发领券架构
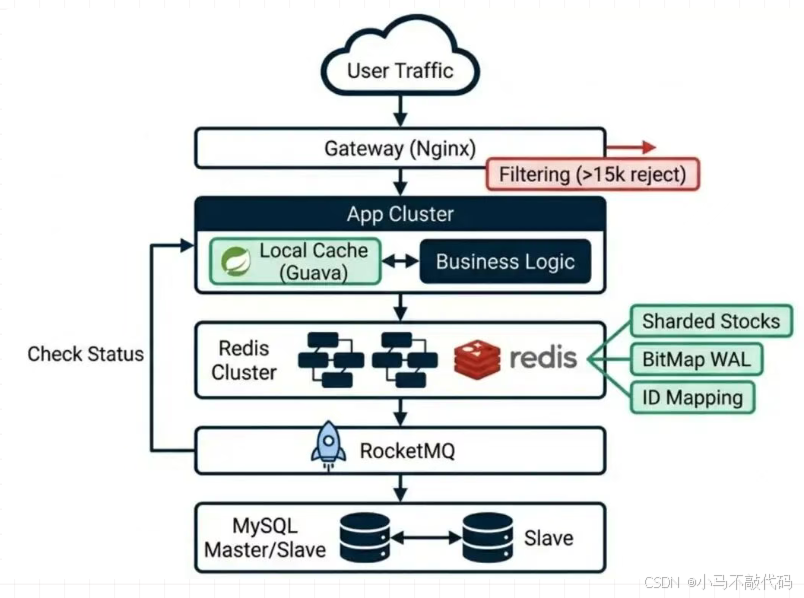
融合了抗压、一致性、存储优化、容灾四个维度:
面试官,这个场景表面看是并发问题,本质上是资源竞争与系统兜底的博弈。我的完整架构方案如下:
1、架构分层(流量漏斗): 我设计了 '网关层静态拦截 -> 应用层 Redis 抗压 -> 数据层 MQ 异步落库' 的三级架构。在网关层利用 Redis 全局计数器拦截 99% 的超量请求,确保到达后端的流量是可控的。
2、极致内存优化(解决 BigKey): 针对 UserID 可能导致的 BigKey 问题,我放弃了 Set,采用了 'ID Mapping + BitMap' 方案。
引入"活动逻辑 ID",将离散的 19 位雪花 ID 映射为连续的整数 Offset。
将 500 万用户的去重记录从几百 MB 压缩到 600KB,彻底消灭了 BigKey 导致的集群阻塞隐患。
3、热点抗压(解决局部缺货): 针对单 Key 热点,采用 '库存分片 + Lua 轮询' 策略。
将库存拆分到 10 个 Redis 实例。
Lua 脚本内部实现 '二次路由':当主分片售罄时,自动轮询其他分片扣减。既解决了单点瓶颈,又避免了Hash路由导致的"局部有货卖不出"的业务 Bug。
4、分布式一致性闭环(解决丢单): 引入 RocketMQ 事务消息。
利用 BitMap 作为回查凭证。
当 Redis 扣减成功但 MQ 发送失败时,MQ 的回查机制会校验 BitMap 状态,从而自动补偿提交,保证了缓存与数据库的最终一致性。
5、容灾兜底(解决 Redis 宕机): 引入 Guava 本地库存降级。当 Redis 集群完全不可用时,自动切换到本地内存扣减极少量库存,优先保证核心服务不宕机,保护底层数据库。