
⭐️在这个怀疑的年代,我们依然需要信仰。
个人主页 :YYYing.
⭐️高并发内存池项目专栏:C++项目之高并发内存池
系列上期内存:【C++项目之高并发内存池 (三)】CentralCache与PageCache的初步实现
系列下期内容:暂无
目录
[📖 ThreadCache回收空间](#📖 ThreadCache回收空间)
[📖 CentralCache回收空间](#📖 CentralCache回收空间)
3、CentralCache的ReleaseToSpans接口
[📖 PageCache回收空间](#📖 PageCache回收空间)
[📖 回收空间的测试](#📖 回收空间的测试)

前言:
上一篇博客我们讲了CentralCache与PageCache的初步实现,我们差不多是把总体三层缓存的申请空间流程写完了,那么这一篇我们就讲我们剩下的三层缓存的空间回收的流程。
📖 ThreadCache回收空间
我们回顾下之前在tc中写的空间回收代码
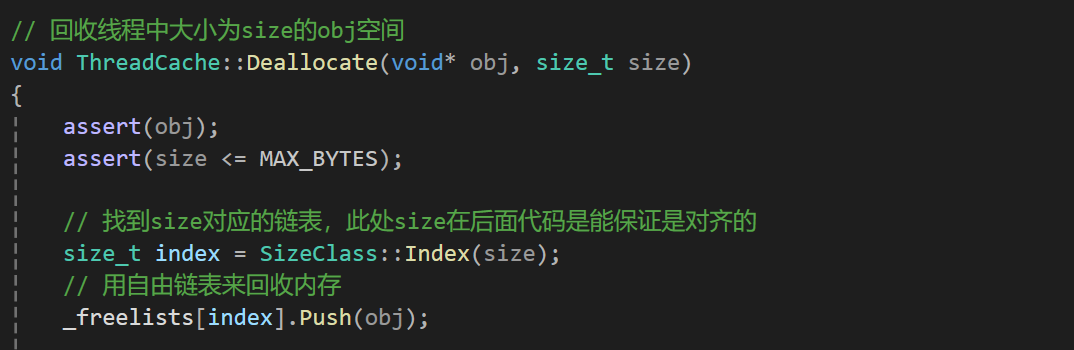
这里本意就是回收线程还回来的空间,这里将规定的size对齐后,挂到tc对应的自由链表上。
那么当tc中单个自由链表中的块数过多的时候就要砍掉一部分,放到cc对应的span中,那么什么时候是过多了呢?
我们不妨回顾一下,当时是不是在FreeList类中定义了一个MaxSize函数,这个函数返回_maxSize参数,意思是单次能申请的最大块数。
那么我们不妨可以规定------tc中某桶中块数超过MaxSize的时候就要还MaxSize个块给cc。
但其实tcmalloc源码中的归还规则可没有这么简单,里面考虑了非常多的因素,比如说整个tc管理的总空间不能超过2M啥的,超过了就要还,还有其他很多规则,这里只是化简了之后的归还规则。
1、FreeList类中的_size变量
由于我们要记录自由链表中挂的块数量,所以我们再在FreeList类中添加一个成员_size,以表达当前链表有多少块内存空间。
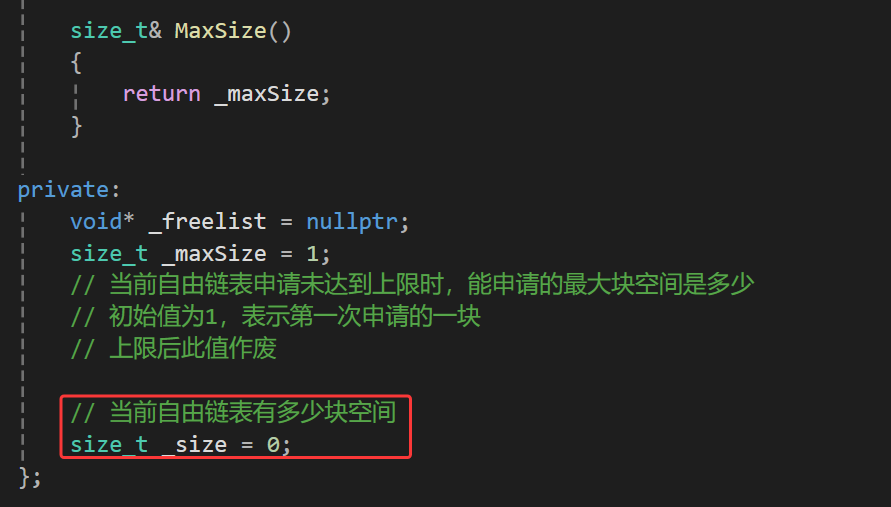
然后我们还需要修改下增删接口
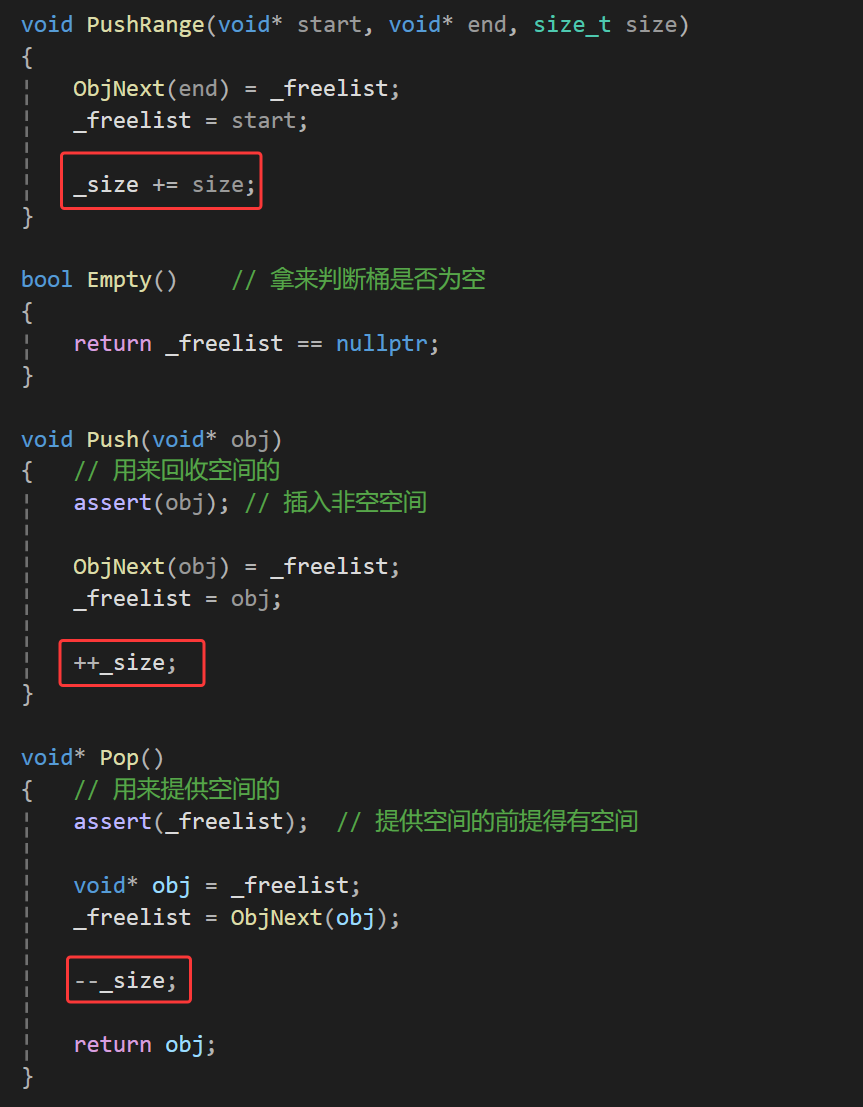
而且我们上一篇还有一个小错误,我忘记改了,就是此处的PushRange的size参数,这个在上一篇是不应该加的,到此处才应该加上,那么现在的FetchFromCentralCache接口中的PushRange调用才是这样的:
最后我们再提供一个接口来返回FreeList的_size参数:

2、ThreadCache的ListTooLong接口
在ThreadCache中写一个ListTooLong的接口,提供一个参数FreeList& list表示的哪个桶中的块数过多了,一个参数size_t size表示该桶下块大小是多少,这个函数用来实现某个桶中块数过多时归还某个桶空间的逻辑:
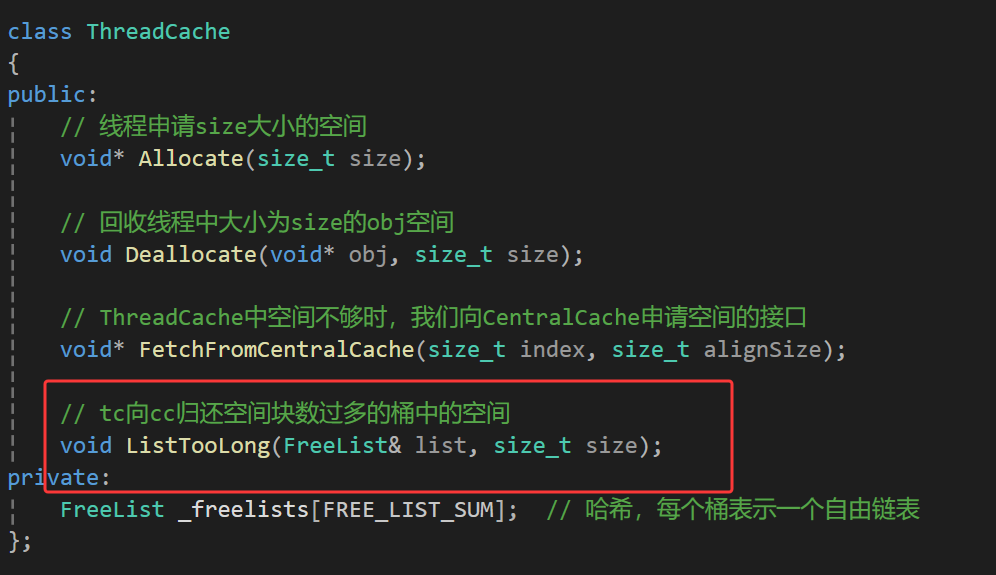
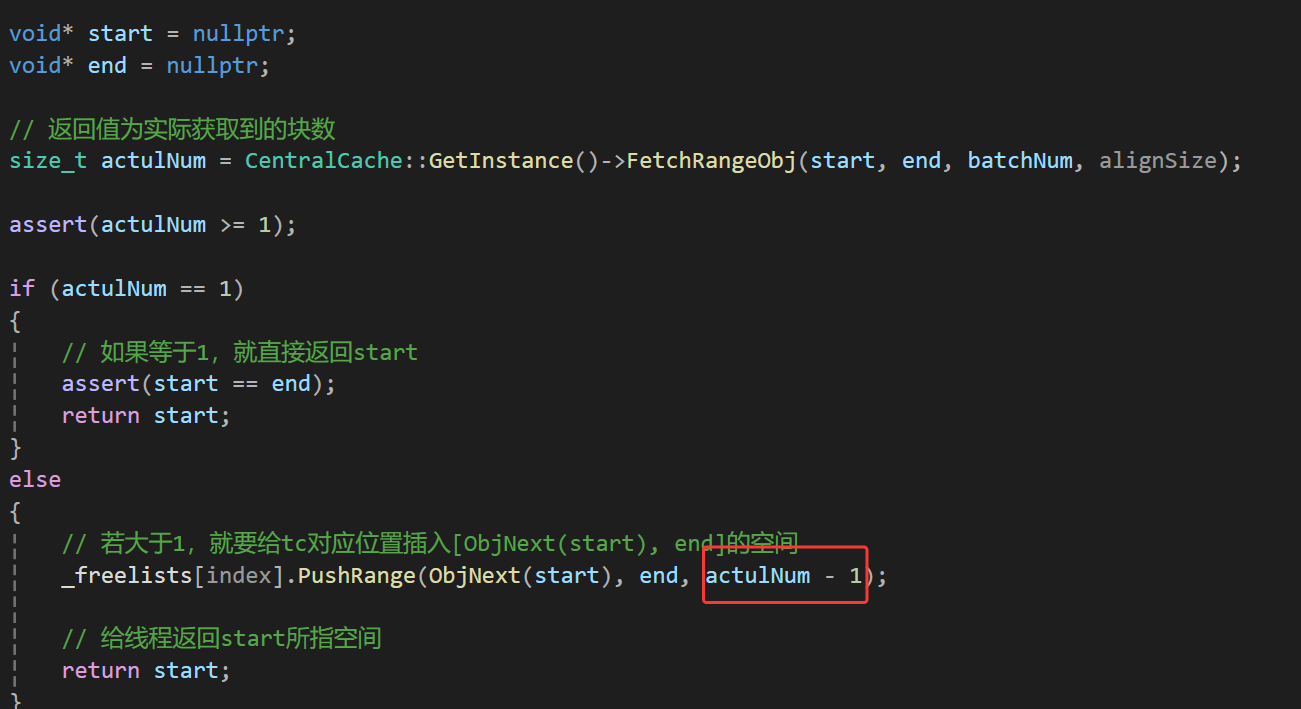
实现这个函数之前,我们先实现下对一段空间的删除逻辑:
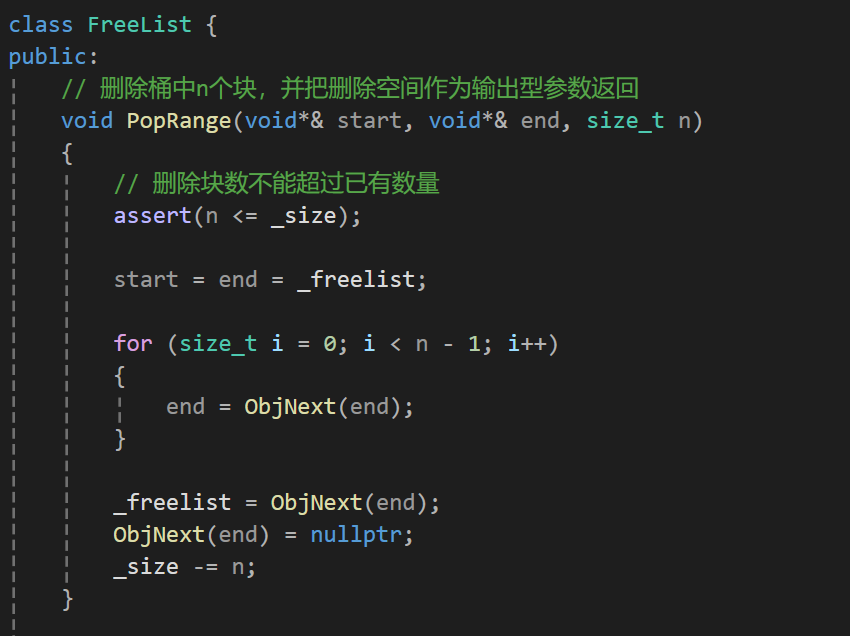
上面代码我相信肯定有疑问,没事,我们看图:
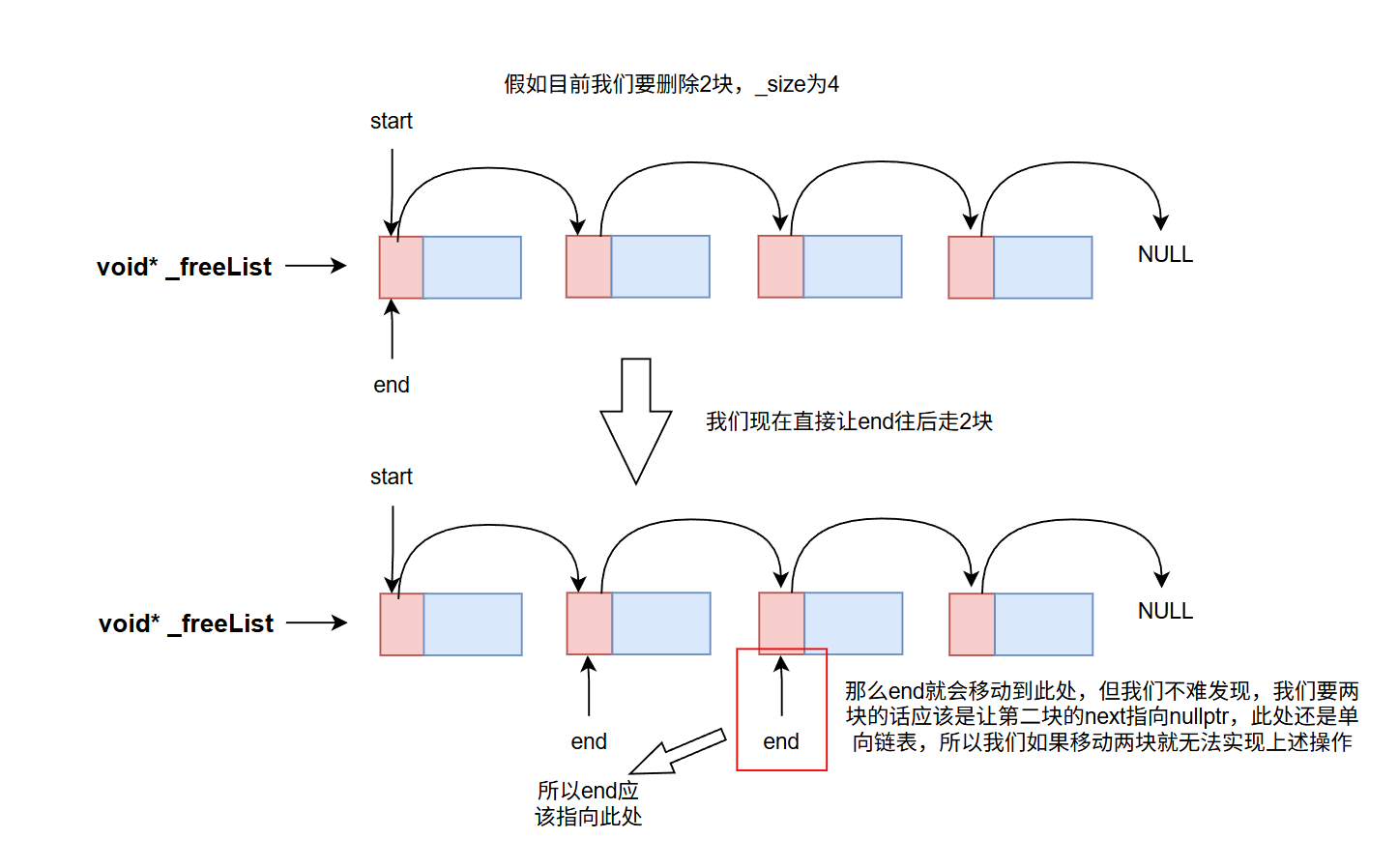
这样获得到的空间范围就是start, end,然后在ListTooLong中调用这个函数就能拿到想要的空间,拿到后将此空间交给cc即可,在cc中定义一个ReleaseListToSpans接口:
cpp
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{
void* start = nullptr;
void* end = nullptr;
list.PopRange(start, end, list.MaxSize());
CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}而且这里不需要传end,因为PopRange保证了end后面就是空,所以只需要判断一下next为不为空就恰巧能判断出是不是end了。
📖 CentralCache回收空间
cc的回收逻辑就在我们刚才写的ReleaseListToSpans中写:

注意是Spans,而不是Span,因为tc传回来的这些块可能不仅仅是一个span中的,且申请走的块空间返回时间是不能确定的,假设有两个span(span1和span2),假设某个线程申请空间的时候拿走了span1后半部分的空间和span2前半部分的空间,归还的块空间返回的时间是不能确定的。
1、空间的地址算页号
但返回给cc的块只能通过块大小size算出来其index对应在cc中哪个哈希桶下挂着,不能确定在对应哈希桶中的哪个span,但是没有关系,块空间是有地址的,我们可以通过(块空间的地址 >> 13)来确定这个块在哪个页中,来看个例子。
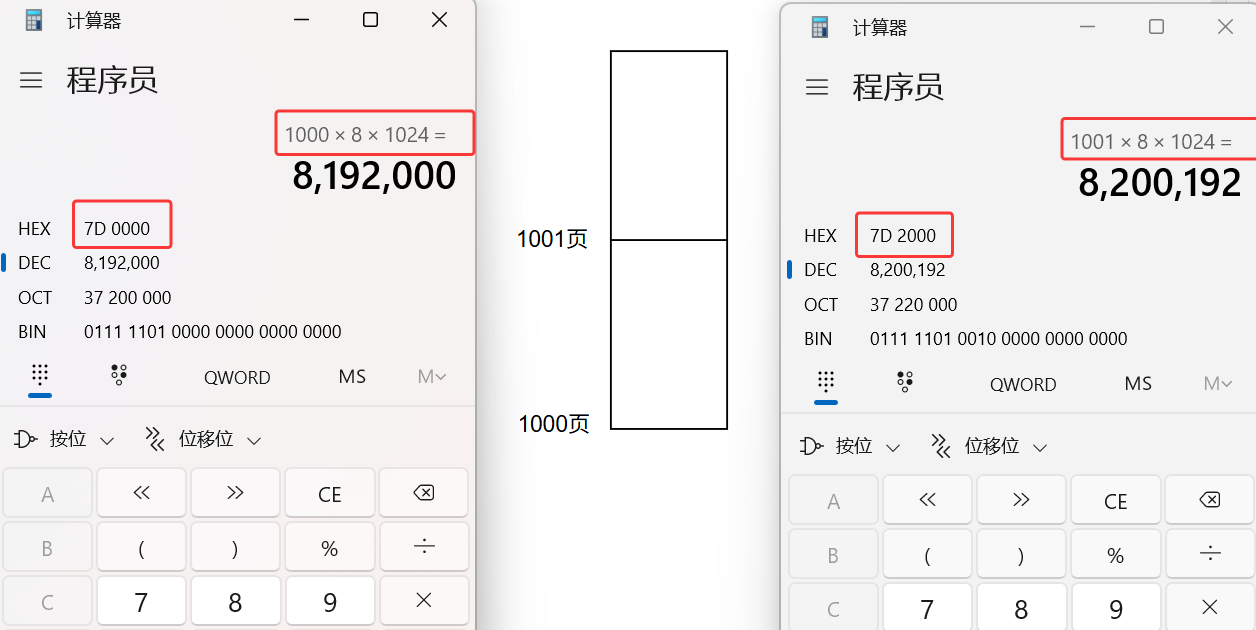
那么,对于1000页中空间的地址,都在[0x007D0000, 0x007D2000)这个范围内。
对于1001页中空间的地址,都在[0x007D2000, 0x007D4000)这个范围内。
其中任意一个地址右移13位,都能映射到对应的页号上,因为只要16进制的最前面的7D不动,那么后面的4位(换算为2进制是16位)数最后右移完后都没了,只剩下了前面的7D,而这个7D就是对应页号,那么就能保证映射到对应的页号上,且页号变了这个右移13位的结果才会变。
那么如何根据页号来找对应span呢?其实相当简单,前面定义span的时候内部就有一个表示span所管理空间的起始页号_pageID,而且还有一个span管理的页数_n,这两个合到一块就可以算出来span算管理空间的页号的范围,也就是[_pageID,_pageID + _n),比如说_pageID为2000,_n为1,那么范围就是[2000, 2001),也就是只有2000这一页。
所以只需要拿(块空间的地址>>13)和span的管理页的页号范围进行比较,在span管理的页范围中的就说明这个块在这个span中,那么直接将这个块插入到span的_freeList里面就行。
2、查找span的效率问题
现在假如说有n个span,tc还回来了m块空间,直接暴力对比的话效率也太低了,每拿一块空间就和n个span对比一下才能找到对应span,时间复杂度就直接变成 了。
那该怎么办呢?诶!我有一计!🤓------可以再专门搞一个映射关系是K-V队的哈希映射,分别就是页号-span地址,这样将cc中的所有span的页号与span的映射全部添加到这个哈希表中,仅通过A>>13就可以再找的时候就以O(1)的时间找到对应span,非常高效。
此处我们暂且就用STL库中的unordered_map了,而且要定义在PageCache中,因为等会PageCache也会用到这个哈希表,但为什么说暂且呢?其实STL在这种场景下的性能还是较为低劣的,我们在最后优化的时候会用基数树来优化,不优化的话甚至连malloc都跑不过,不过现在有个印象就行。
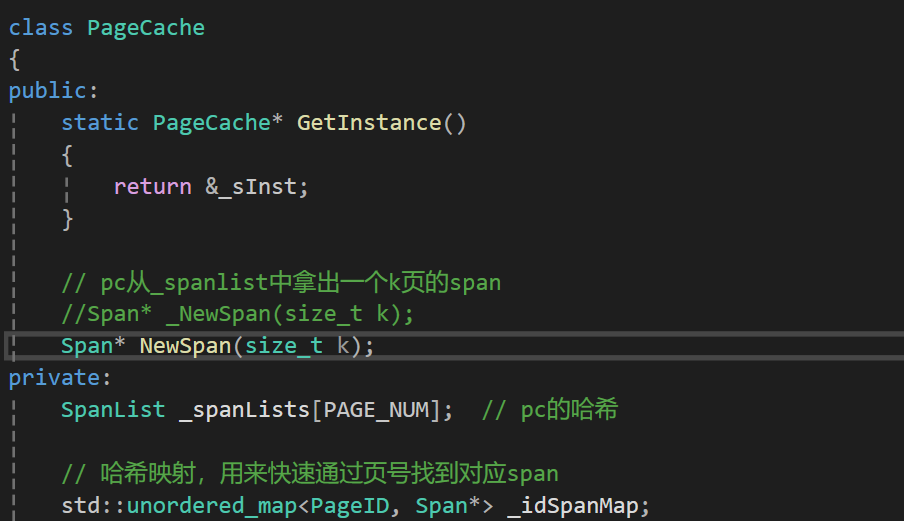
数据结构有了,那么什么时候添加cc中页号与span之间的映射呢?
就在将pc中的span分配给cc的时候记录一下就行也就是这里:
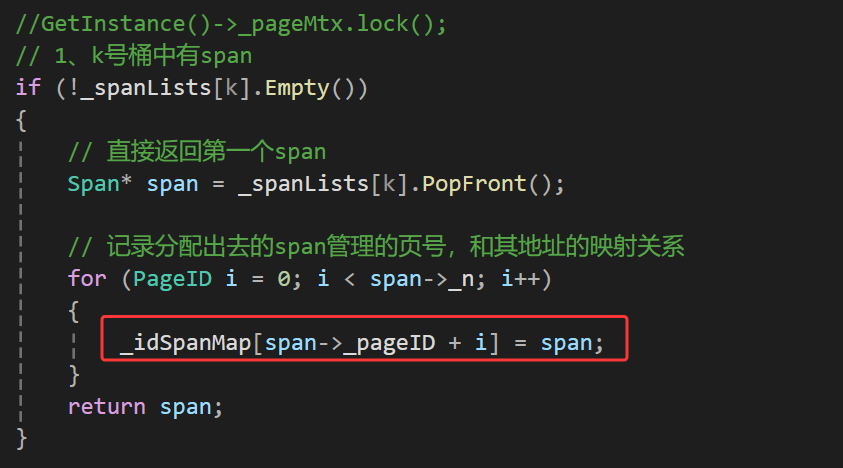
还有这里:
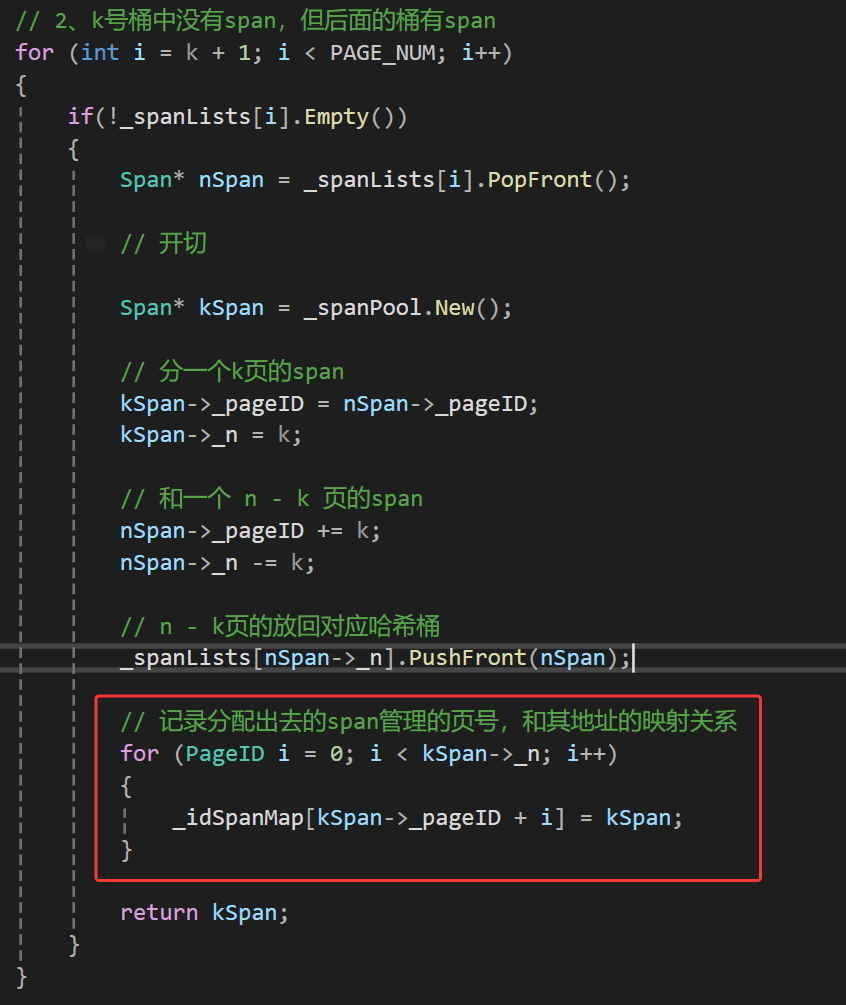
当然对于pc而言的映射关系也需要创建,但不是现在,后面说合并span的时候再讨论pc中span建立映射的逻辑。
那么现在归还小块内存的总体逻辑就是------先让小块内存的地址右移13位,得到小块地址所在页的页号,然后再根据哈希映射得到页号对应的span,再往span中插入这小块内存就OK了。
最后我们还缺少一个接口,就是从页地址找到span的接口:
cpp
// 页地址找span
Span* PageCache::MapObjectToSpan(void* obj)
{
// 通过块地址找到页号
PageID id = (((PageID)obj) >> PAGE_SHIFT);
// 通过哈希找到页号对应span
auto ret = _idSpanMap.find(id);
if (ret != _idSpanMap.end())
{
return ret->second;
}
else
{
assert(false);
return nullptr;
}
}前置逻辑结束,至此可以开始写ReleaseToSpans了。
3、CentralCache的ReleaseToSpans接口
首先先算出哈希桶下标:
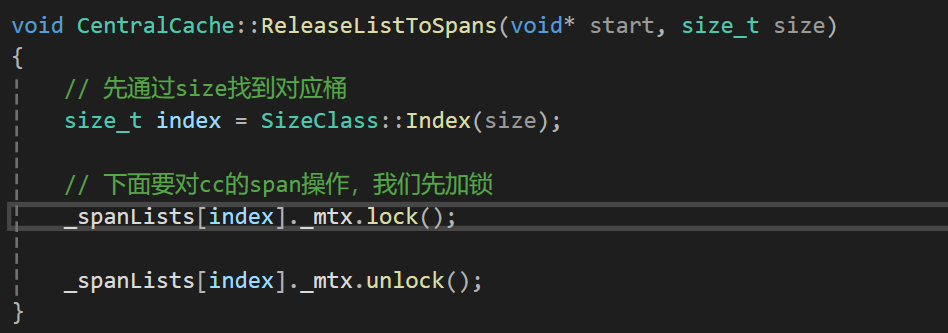
然后我们对其中的桶进行操作,我们要不断遍历start中的各个块,然后不断头插,直到遇到空指针:
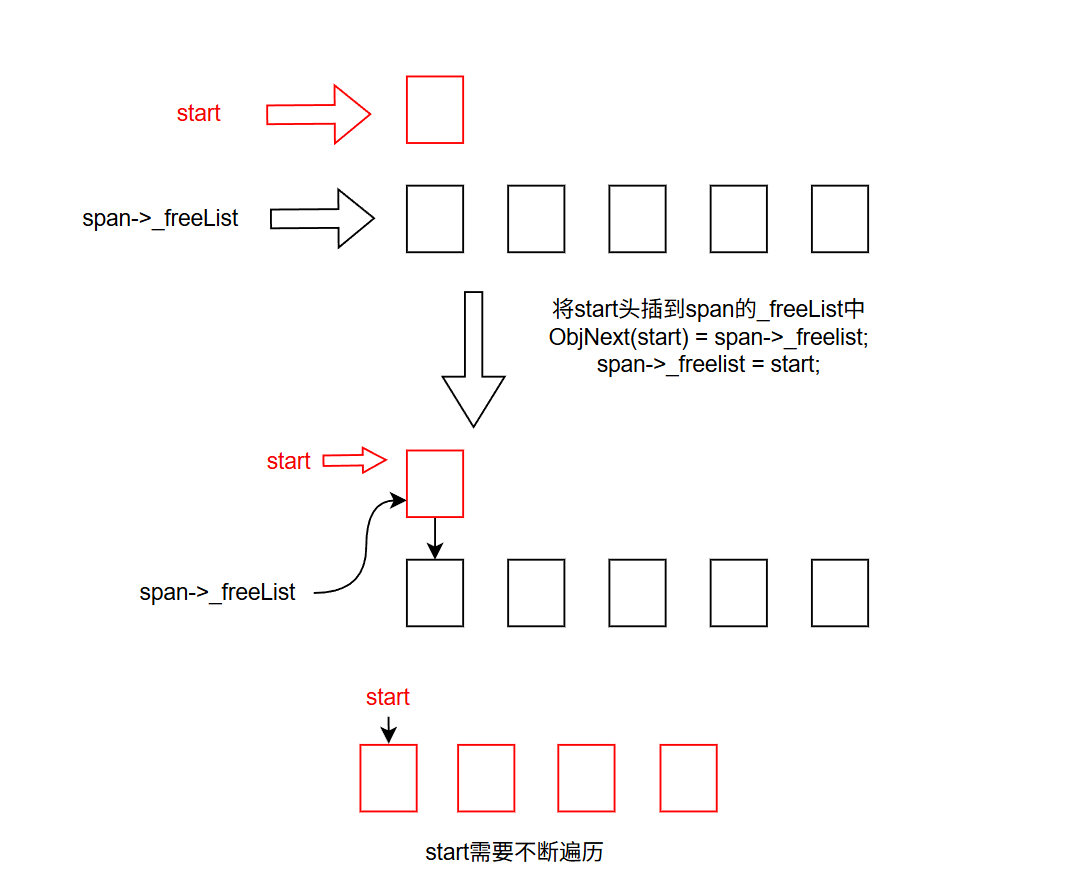
然后前面还讲过一个_useCount,这个是用来统计span中分配出去的块数的,因为这里还回来了很多块,所以要让对应的span的_useCount- -,那么代码就该是这样:
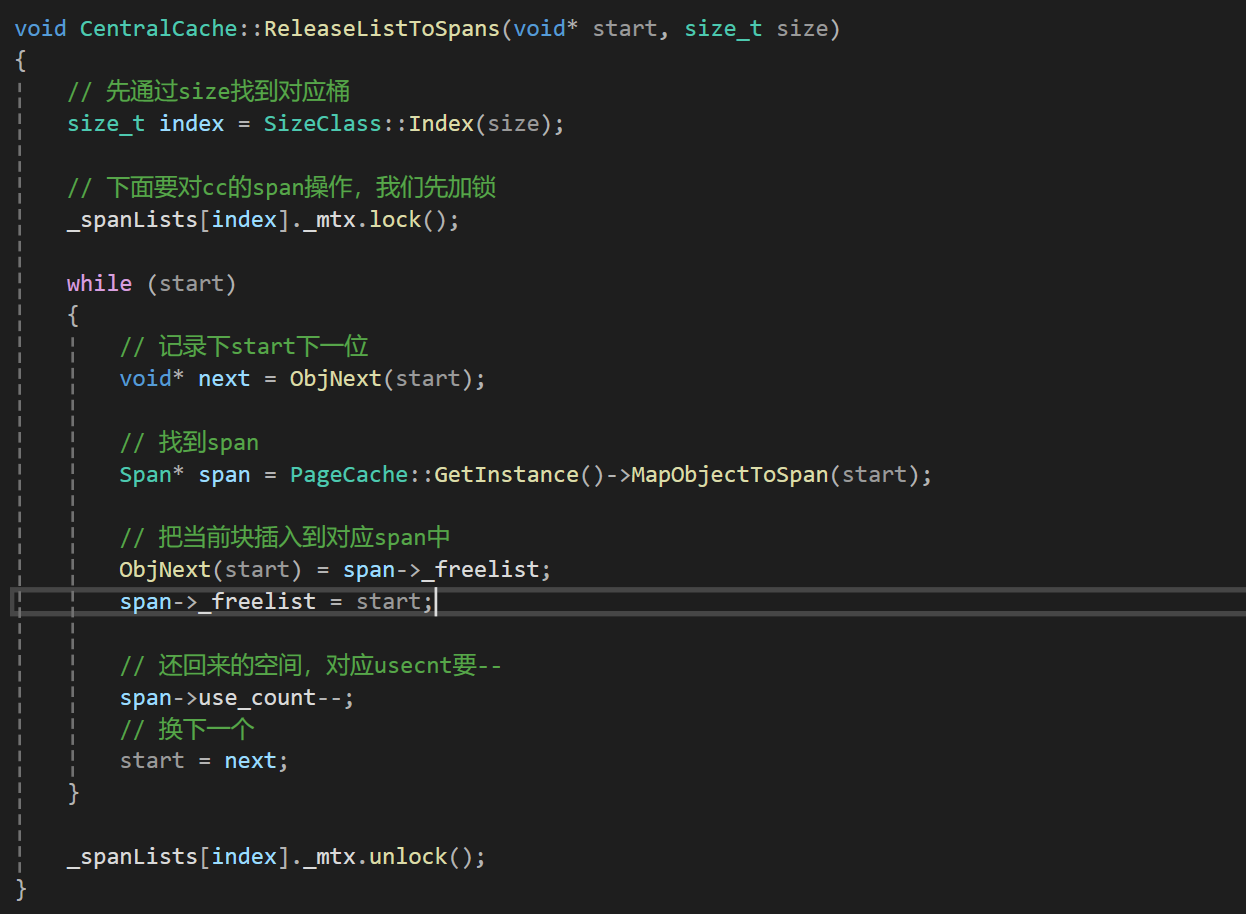
然后我们还需要考虑到useCount减到0的时候就表示当前span中的所有空间都还回来了,所以此时就可以让cc将空间还给pc来管理,我们在pc中定义一个接受这段空间的接口ReleaseSpanToPageCache:
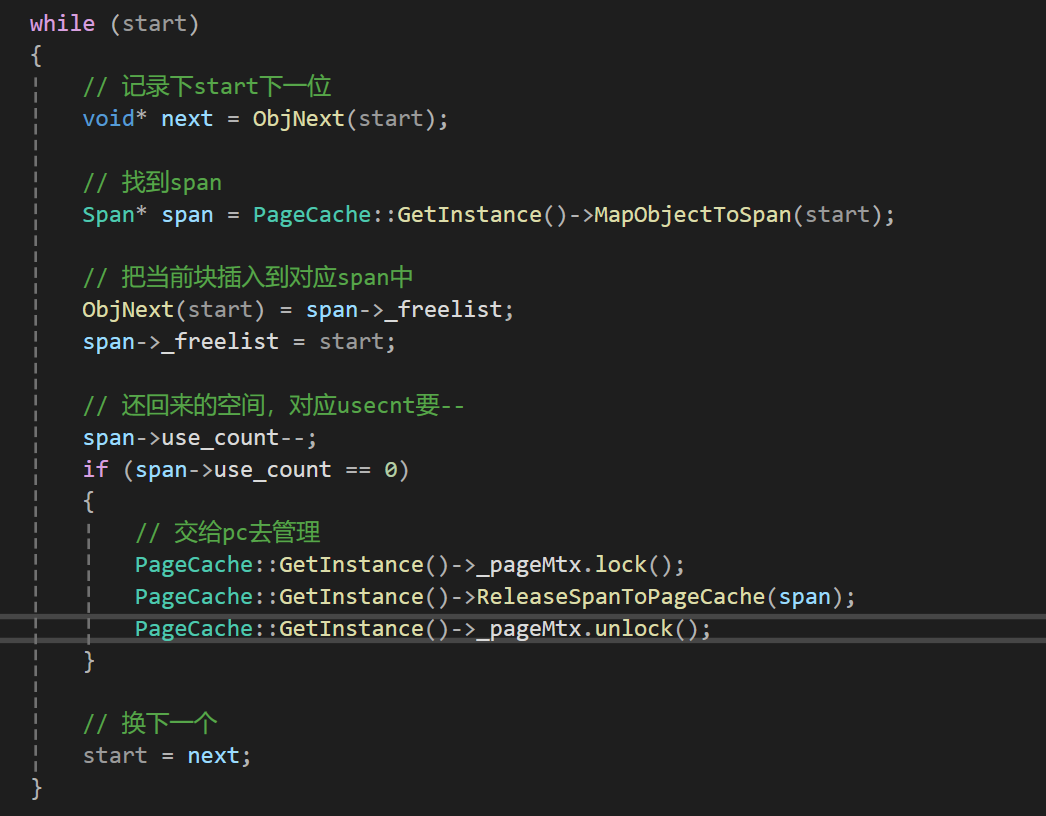
在归还span后,pc会对空间上相邻的span进行合并,和前面的span分裂一样,span的合并也需要加锁,而且加锁的位置也和前面span分裂一样,直接加在调用ReleaseSpanToPageCache的位置两边就行,但就只这样写还有点问题,就是这里span还是在cc里的,所以要从cc中删掉:
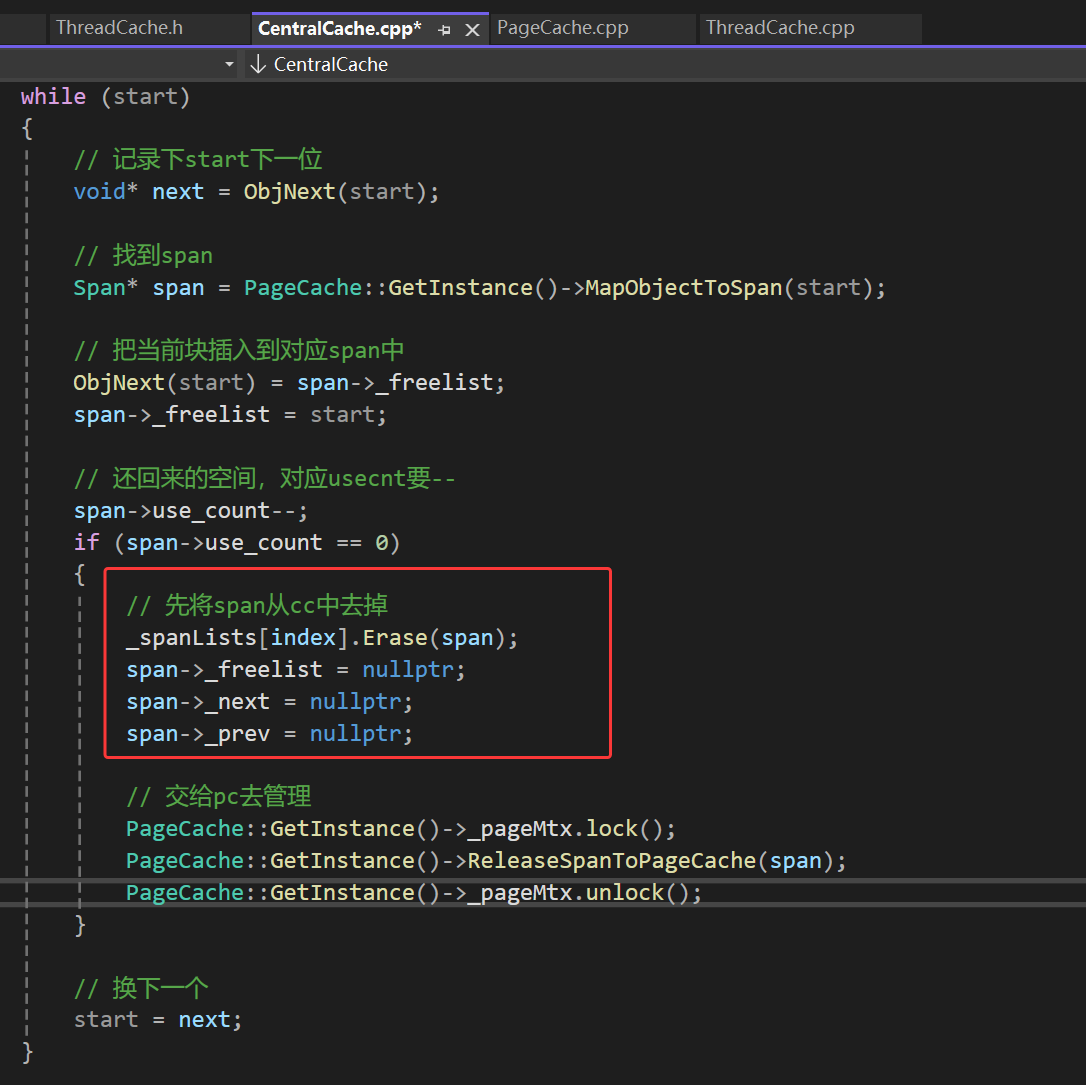
这里span->_freelist给空是为什么呢?首先要确定一点,span中归还回来的_freeList是乱序的,因为刚刚也说了,申请空间是按照_freeList一块一块申请的,但是归还回来的时间无法确定,所以可能现申请出去的空间后还回来,而这里还回来的时候还直接进行了头插,所以原先span中按照顺序排好的空间(所有页的空间在cc获取到的时候是用链表串起来的)返回来之后的所有块的连接顺序大概率是被打乱了的,但整体上还是一个链表,只不过每一块的前void*个字节中的空间大概率不是其原先内存中下一块的空间。
但最后是不会影响到归还的,因为只要是span整个空间回去了就行,pc按照整个span进行回收,就算是同一个span再提供给cc的时候cc会重新对这些空间按照顺序向链表一样串起来。
所以对于此处span->_freelist已经没有用了,所以置空即可。
不过还有一件事,在归还span的时候需要将当期cc中的桶锁解掉,以便其他线程对该桶进行操作时不会阻塞,就和前面申请的那里一样,那么最终版代码就出来了:
cpp
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{
// 先通过size找到对应桶
size_t index = SizeClass::Index(size);
// 下面要对cc的span操作,我们先加锁
_spanLists[index]._mtx.lock();
while (start)
{
// 记录下start下一位
void* next = ObjNext(start);
// 找到span
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
// 把当前块插入到对应span中
ObjNext(start) = span->_freelist;
span->_freelist = start;
// 还回来的空间,对应usecnt要--
span->use_count--;
if (span->use_count == 0)
{
// 先将span从cc中去掉
_spanLists[index].Erase(span);
span->_freelist = nullptr;
span->_next = nullptr;
span->_prev = nullptr;
// 归还span,解掉当前桶锁
_spanLists[index]._mtx.unlock();
// 交给pc去管理
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
// 完毕后加上桶锁
_spanLists[index]._mtx.lock();
}
// 换下一个
start = next;
}
_spanLists[index]._mtx.unlock();
}那么这里cc回收tc中多个内存块的逻辑就完了,下面来说pc回收cc返回的span的逻辑。
📖 PageCache回收空间
我们回顾下pc的存储结构:
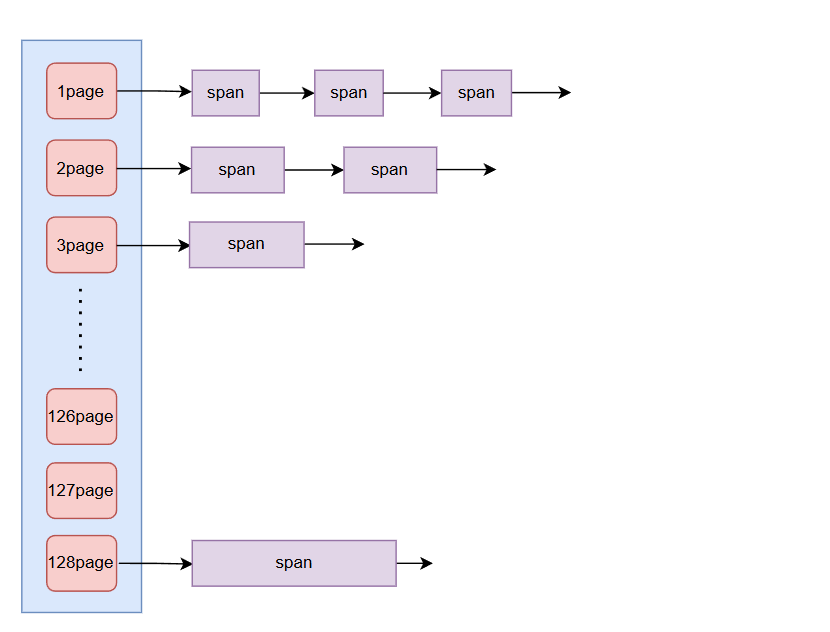
那现在返回了一个1page的span,我们是否应该直接就放在1page的第三个span后,而不进行其他操作?比如合并。
答案是不行,至于为什么,我们不妨想想,如果现在申请出去的全是小于10page的span,返回来的这些span就只是挂在对应桶后,那么我们突然申请一个11page的span,那么前面这些一个都没用岂不是太浪费了点,也就是所谓的外碎片问题。
所以这些小页的span不妨可以尝试着合并一下,管理的页如果相邻就拼到一个span中,就能拼成管理更大页的span,这样就能尽量避免外碎片的问题。
**注意:**内碎片问题在内存池中是无法避免的,只有我们在定义自定义类型的时候注意对齐问题才能解决,不过内碎片不算啥问题,反正提供的空间能回收回来,可以重复利用,但是外碎片不解决就会一直在那。
1、合并span的逻辑
那么为了应对这种外碎片问题,我们pc的span该如何合并呢?
假设现在有一个span,那么这个span合并的话,就要找其管理页的相邻页:

那么我们此时合并首先就需要选出一边,也就是先按一个方向进行合并,假设这里就先往左,我们就需要找到_pageID为999的页,但实际找到的不一定只是这个页,怎么理解这句话呢?也就是我们也可能找到的是_pageID为996,因为如果有个span管理页的首地址是996但管理页数为4,也就是_n为4,那么他的管理范围就是[996,1000),此时刚好就连上了,那么就应该是这样:
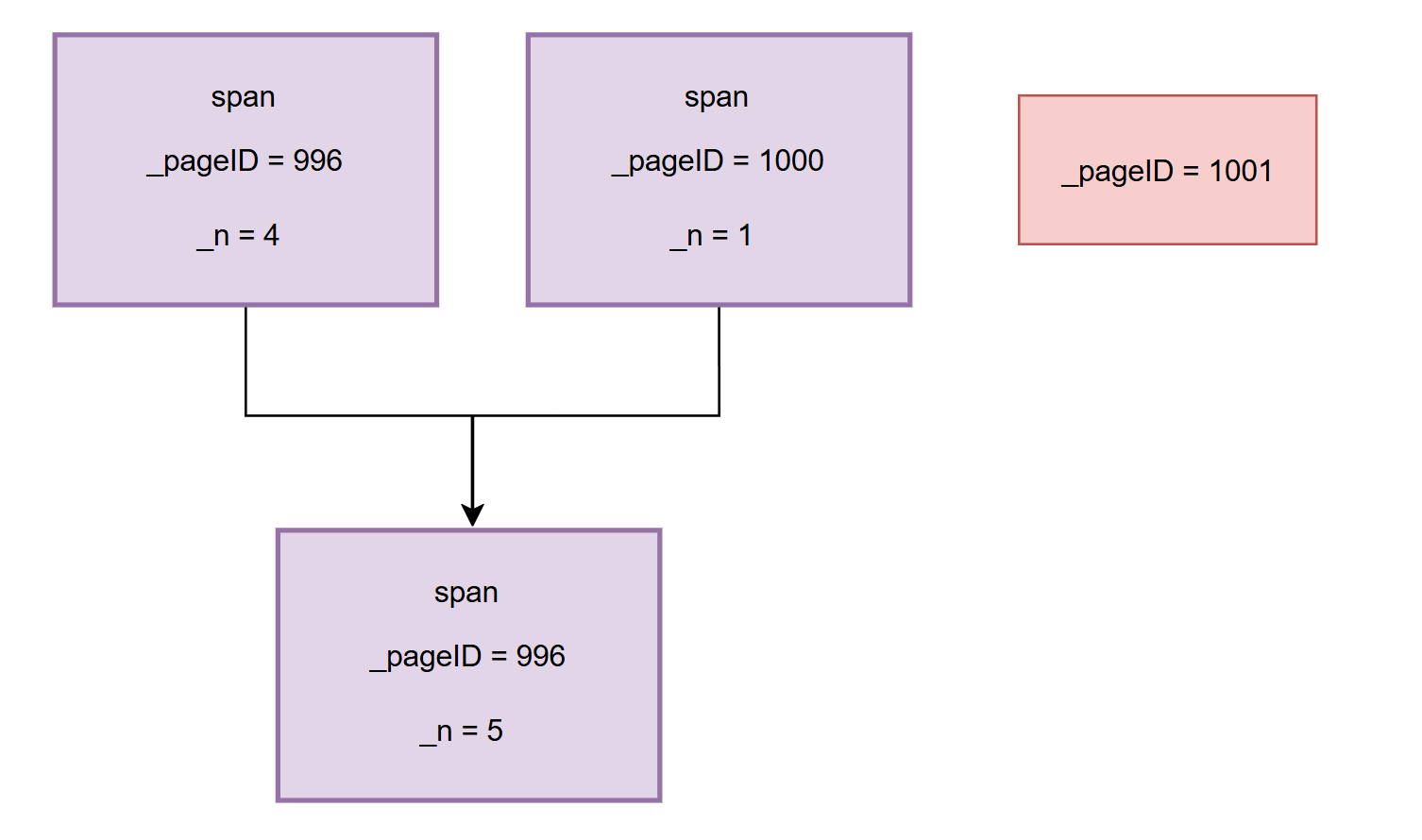
然后假如说又找到了一个可以合并的span:
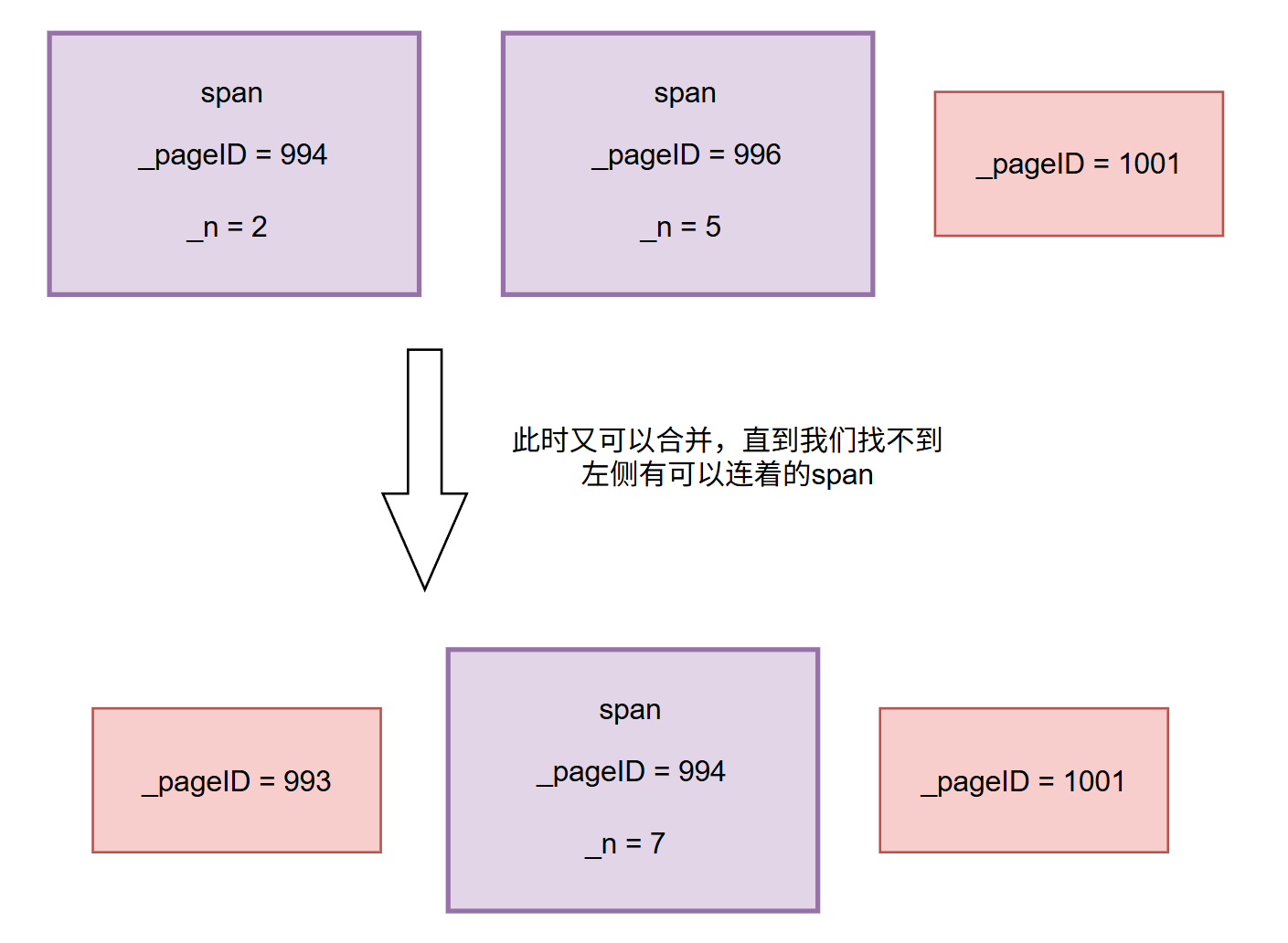
然后右侧开始找,也是同理,此处就不过多赘述了。
2、判断span在cc还是pc
那么如何通过左右两侧的pageId来确定该页所在的span呢?还是用刚刚的哈希,也就是PageCache中的_idSpanMap。
不过还有一个小问题,映射出来的span有已经由cc还给了pc,也有可能还在cc中,但只有挂在pc中的span才能合并,挂在cc中的span是不能进行合并的,因为cc中的span是正在使用的span,那么如何区分cc和pc中的span呢?
有人可能会说_useCount这个参数为0时,表示是pc的,如果不是0就表示是cc中的,这样乍一看没啥问题,但经不起我们推敲:
我们cc进行切分的时候是在GetOneSpan中进行的:
但我们_useCount的修改却是在FetchRangeObj中完成的:
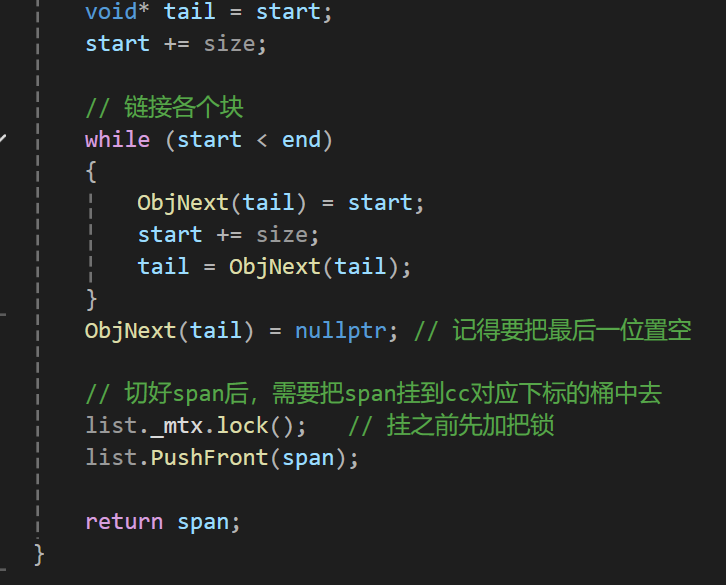
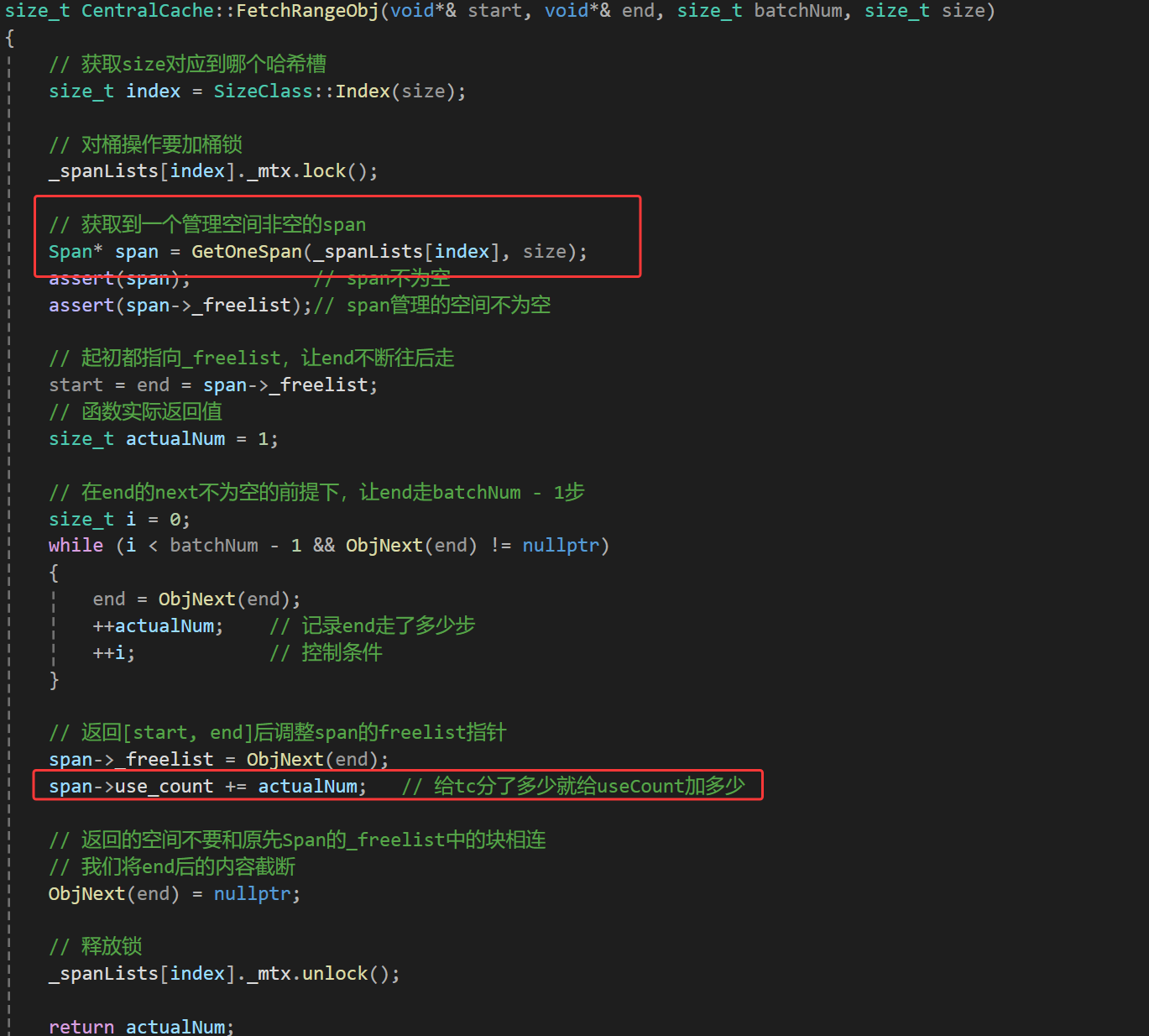
我相信看到这多少会有点感觉了,那么实际也就是会说,cc正在切分从pc中获取到的span时_useCount还为0,这个时候如果pc合并的时候一看这个span的_useCount为0,就直接拿去合并了,很明显这个时候就出问题了。实际这个span是cc准备分好拿去给tc用的,给tc后我们_useCount才会进行修改,但此时却被pc拿去合并了,那么就会出现这个span既在pc中又在cc中的情况,而且其管理的一部分空间还给了tc,所以这里用useCount来判断是有问题的。
所以我们如果想要解决这个问题就需要再添加一个变量,位置就在我们的Span类中:
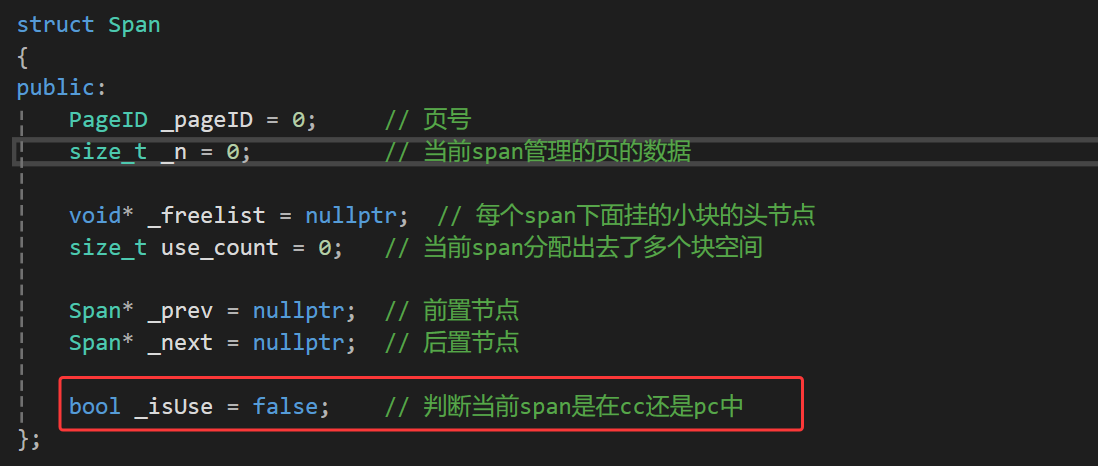
这个值为false就表示这个span当前没有被使用,也就是在pc中,true就是被使用了,那么就在cc中。默认值给成false,所有的span初始情况下都是在pc中的,所以给成false。
至于这个值在什么时候修改,我们在GetOneSpan中cc获取到新Span后就改一下。
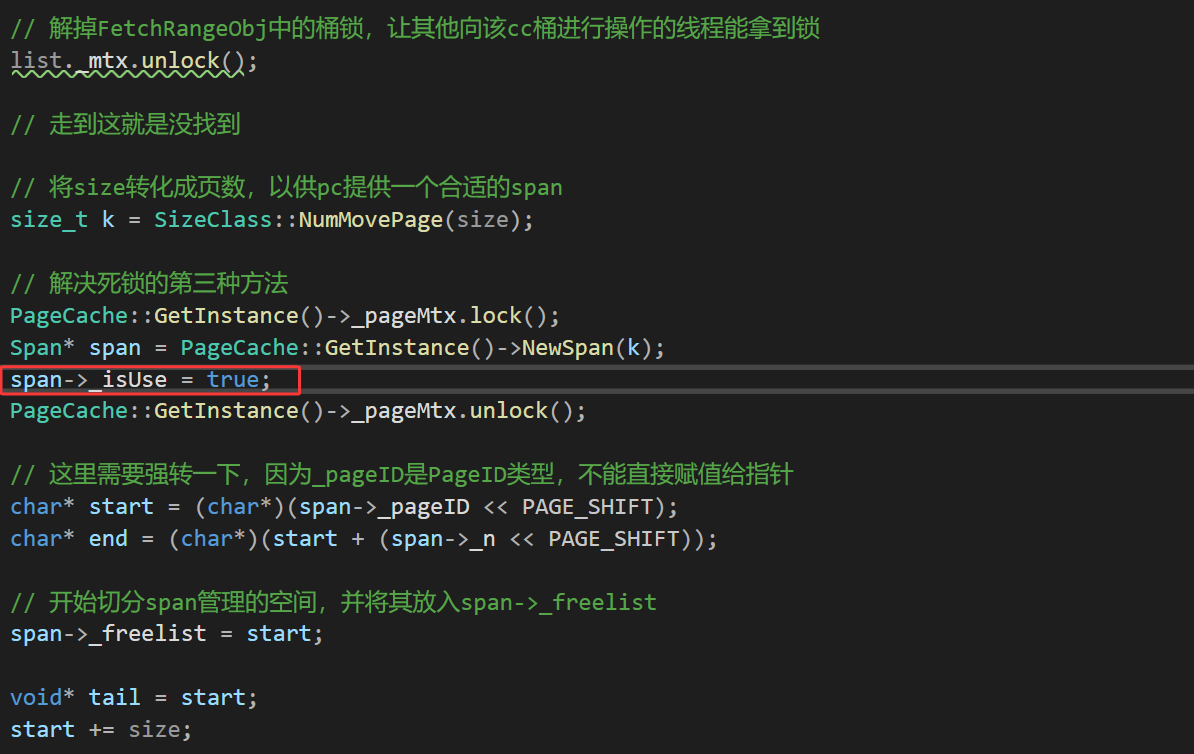
向pc申请和回收空间的时候都用的是pc中的那把锁,所以是不会存在同时向pc申请span和向pc归还span的,那么pc锁内修改_isUse就没有问题。整个流程就只有这里需要把_isUse改为true,也就是span由pc到cc之后。
3、合并span的代码实现
此处span的合并是不看span的属性的,也就是不看这个span是从cc中还回来的,还是本来就在pc中的。
前面也讲了pc中的span也是要映射进入_idSpanMap的,但是映射的时候不需要将pc中的span所有的页都映射成span地址,因为pc中的span是不会用到其中管理的空间的,只需要将pc中的span管理的首页与末尾页映射进去即可。
这主要是因为,我们span向左右扩张时只会找这个span所管理空间的左右两页,那么这样两边的页只会是某一个span的边缘页,意思就是只会是某个span的pageID或pageID + _n - 1,也就是这样:
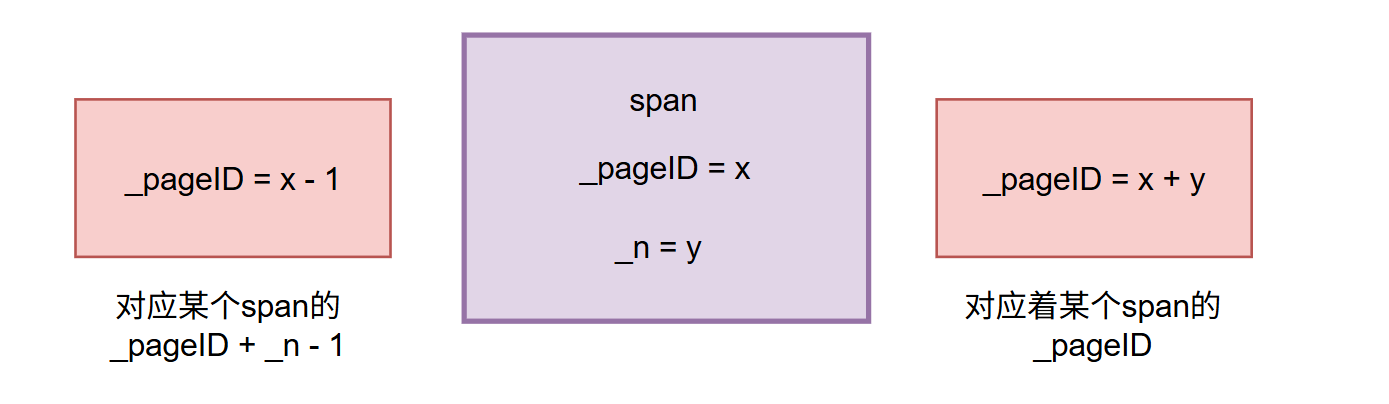
也就是我们pc的span内部的页是用不到的,所以不用浪费时间与空间去存储。
那么在NewSpan内加上:

现在就可以正式开始合并了,先来说说合并会遇到的几种情况:
- 某一边相邻页没有映射出对应的span后就停止这一边的合并。
- 相邻页所在span正在被cc使用时就不能合并。
- 相邻页所在span与当前页所在span合并起来后页数超过128页就不能合并,因为该项目中设定的span所管理的最大页数为128页。
- 没有以上问题的就合并,而且合并要不断迭代进行。当前span与相邻span合并后要修改当前span的_n和_pageID,并将相邻span从pc原桶中删掉,然后delete掉相邻span对象的空间。
首先是向左合并的四种情况:
cpp
// 向左合并
while (1)
{
PageID leftID = span->_pageID - 1;
auto ret = _idSpanMap.find(leftID);
// 没有相邻span,停止合并
if (ret == _idSpanMap.end())
{
break;
}
Span* leftSpan = ret->second; // 相邻span
// 相邻span在cc中,停止合并
if (leftSpan->_isUse == true)
{
break;
}
// 相邻span与当期span合并后超过128页,停止合并
if (leftSpan->_n + span->_n > PAGE_NUM - 1)
{
break;
}
// 当前span与相邻span进行合并
span->_pageID = leftSpan->_pageID;
span->_n += leftSpan->_n;
_spanLists[leftSpan->_n].Erase(leftSpan);
delete leftSpan;
}其次是向右合并,大体逻辑一模一样
cpp
// 向右合并
while (1)
{
PageID rightID = span->_pageID + span->_n;
auto ret = _idSpanMap.find(rightID);
// 没有相邻span,停止合并
if (ret == _idSpanMap.end())
{
break;
}
Span* rightSpan = ret->second;
// 相邻span在cc中,停止合并
if (rightSpan->_isUse == true)
{
break;
}
// 相邻span与当期span合并后超过128页,停止合并
if (rightSpan->_n + span->_n > PAGE_NUM - 1)
{
break;
}
// 当前span与相邻span进行合并
span->_n += rightSpan->_n; // 往右就不用该span->pageID了
// 因为右边会和span拼在一起
// 把桶内的span删了
_spanLists[rightSpan->_n].Erase(rightSpan);
delete rightSpan;
}合并完后我们将span挂到对应桶上,并且还要映射一次边缘页
cpp
// 合并完后,挂到对应桶中
_spanLists[span->_n].PushFront(span);
span->_isUse = false;
// 映射当前span边缘页,后续还可以对这个span合并
_idSpanMap[span->_pageID] = span;
_idSpanMap[span->_pageID + span->_n - 1] = span;至此,回收逻辑大体完毕。
📖 回收空间的测试
首先第一个测试就是申请的时候那5个,直接释放:
cpp
void ConcurrentAllocTest1()
{
void* ptr1 = ConcurrentAlloc(5);
void* ptr2 = ConcurrentAlloc(8);
void* ptr3 = ConcurrentAlloc(4);
void* ptr4 = ConcurrentAlloc(6);
void* ptr5 = ConcurrentAlloc(3);
cout << ptr1 << endl;
cout << ptr2 << endl;
cout << ptr3 << endl;
cout << ptr4 << endl;
cout << ptr5 << endl;
ConcurrentFree(ptr1, 5);
ConcurrentFree(ptr2, 8);
ConcurrentFree(ptr3, 4);
ConcurrentFree(ptr4, 6);
ConcurrentFree(ptr5, 3);
}此时将这个块空间push到了tc对应的桶中之后,那个桶的_size和MaxSize相等了,就会将桶里面的四个块交给cc,cc接收到之后span的useCount是2,因为还有ptr4和ptr5没有归还,所以不会走到向pc归还span的那一步。
但是再往后回收ptr4和ptr5两块空间之后,只会向tc归还一下,并不会向cc归还,因为还给tc之后FreeList的size是2,不等于MaxSize(4),所以这里的调试流程没有走到cc向pc归还的那一步。
所以我们还需要两个才能凑齐归还条件:
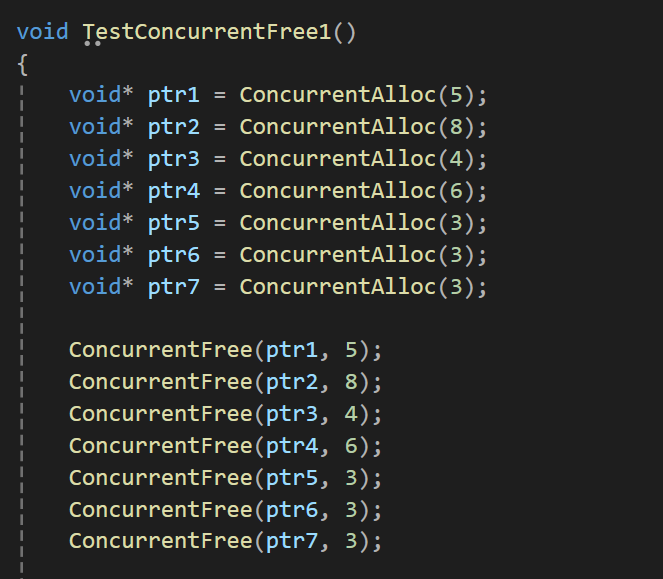
最终会合并出来一个128页的span
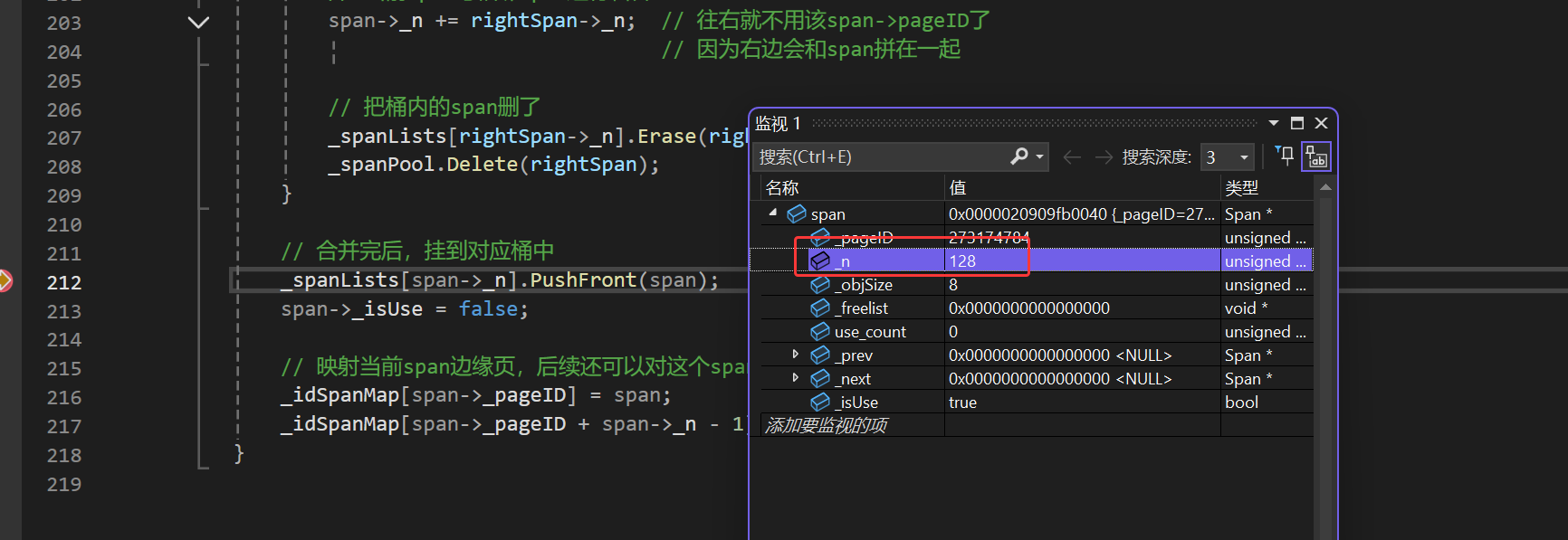
此处再给一个多线程下的测试接口,如果这个最后回收完后也能凑出128页的span那就没什么问题了。
cpp
void MultiThreadAlloc1()
{
std::vector<void*> v;
for (size_t i = 0; i < 7; ++i) // 申请7次,正好单个线程能走到pc回收cc中span的那一步
{
void* ptr = ConcurrentAlloc(6); // 申请的都是8B的块空间
v.push_back(ptr);
}
for (auto e : v)
{
ConcurrentFree(e, 6);
}
}
void MultiThreadAlloc2()
{
std::vector<void*> v;
for (size_t i = 0; i < 7; ++i)
{
void* ptr = ConcurrentAlloc(16); // 申请的都是16B的块空间
v.push_back(ptr);
}
for (int i = 0; i < 7; ++i)
{
ConcurrentFree(v[i], 16);
}
}
void TestMultiThread()
{
std::thread t1(MultiThreadAlloc1);
t1.join();
std::thread t2(MultiThreadAlloc2);
t2.join();
}结语
至此此项目基本所有重要的内容都讲完了,只剩下一些要改动的细节与性能优化了,不优化的性能还是很差的,那么我们就下期再见了。
我是YYYing,后面还有更精彩的内容,希望各位能多多关注支持一下主包。
无限进步,我们下次再见!
---⭐️ 封面自取 ⭐️---
