目录
[(1)顺序表的封装(部署就先写在一个文件里,再分文件。 )](#(1)顺序表的封装(部署就先写在一个文件里,再分文件。 ))
9) 清空链表 清空链表)
[2. 栈的封装](#2. 栈的封装)
[1. 算法思想](#1. 算法思想)
[2. 时间复杂度](#2. 时间复杂度)
[3. 时间复杂度](#3. 时间复杂度)
[示例1 直接地址法](#示例1 直接地址法)
[示例2 叠加法](#示例2 叠加法)
[示例3 保留余数法和备用表法](#示例3 保留余数法和备用表法)
一.数据结构基知
是一种存储和组织数据的方式,旨在便于访问和修改。 ------ 《算法导论》
**1.**逻辑结构
是数据之间的关系,和存储方式关系不大。
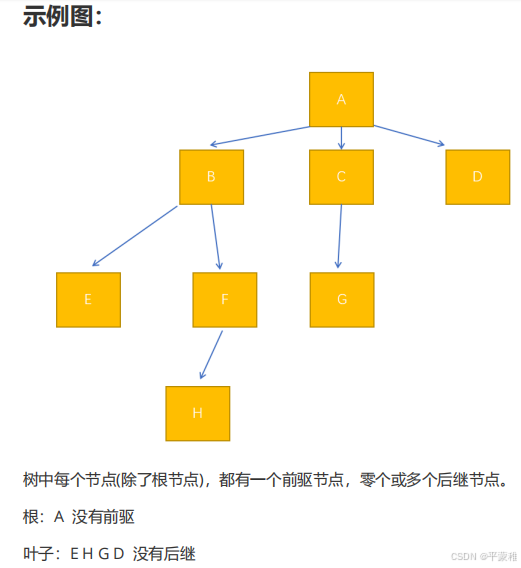
(1)线性结构:
每个节点只有一个前驱和一个后继。
前驱:每个节点前面的节点 首节点没有前驱
后继:每个节点后面的节点 尾节点没有前驱
节点:就是数据结构中的一个数据
第一个节点没有前驱,最后一个节点没有后继。
(2)树形结构:
每个节点只有一个前驱,有多个后继。
根:没有前驱的节点
叶子:没有后继的节点
(3)图形结构:
每个节点可以有多个前驱和多个后继。
图形结构一般不用来存数据,用来写算法
**2.**存储结构
数据的存储结构是指数据的逻辑结构在计算机中的表示。
顺序存储 数据在内存中连续存储 数组就是典型的顺序存储
链式存储 数据在内存中不是连续存储,每个节点都有若干个指针指向其他节点
二.算法复杂度
算法:是任何良定义的计算过程,该过程取某个值或者集合作为输入并产生某个值或值的集合作为输出。 ------ 《算法导论》
1.时间复杂度(运行速度是否快)
重点概念:
时间复杂度是一个效率的概念,不能看具体的执行时间。是数据量和消耗时间的关系。
T(n) 是一个符号,表示 " 时间复杂度 " 这 5 个字
O() 是某一种时间复杂度,时间复杂度分很多种
T(N) = O(xxx) 表示时间复杂度是 xxx
**实例:**分析时间复杂度,不要看代码的行数,要看循环和递归的次数。
时间复杂度要看随着 n 的增加,循环和递归次数的变化规律。
for ( i = 0 ; i < n ; i ++ )
{
for ( j = 0 ; j < n ; j ++ )
{
// 处理 (n * n) // 时间复杂度不在乎具体做什么事
}
}
T ( n ) = O ( n^2 ) // 时间复杂度是 O(n^2) 表示 消耗的时间和 n 是平方关系
for ( i = 0 ; i < n ; i ++ )
{
for ( j = 0 ; j < n ; j ++ )
{
for ( k = 0 ; k < n ; k ++ )
{
// 处理 (n * n)
}
}
}
T ( n ) = O ( n^3 ) // 时间复杂度是 O(n^3) 表示 消耗的时间是 n 的 3 次方关系
for ( i = 0 ; i < n ; i ++ )
{
// 处理 (n * n);
}
for ( j = 0 ; j < n ; j ++ )
{
// 处理 (n * n);
}
T ( n ) = O ( 2 * n ) 量级和 O ( N )
2.空间复杂度
运行程序需要的内存空间
时间复杂度和空间复杂度不能兼顾
三.线性表
线性表:使用顺序存储实现的线性结构。
1.顺序表
顺序表:数据的关系是连续存放的。 类似:a0 a1 a2 a3 a4
我们使用的存储结构: 顺序存储结构(用数组)。(实际上还可以是链式存储)
(1)顺序表的封装(部署就先写在一个文件里,再分文件。 )
对数据结构的封装
1 首先要定义一个结构体,包含数据结构中需要的成员
2 其次,要根据我们要对数据结构进行的操作封装函数
**重点:**数据结构的功能都是围绕 增、删、改、查。
命名法:
单词之间使用下划线分隔;类型名以_t 结尾 type
student_study 是对象名
student_t 是类型名
(2)封装顺序表结构体
需要分头文件和源文件 list.h 宏定义,结构体,函数声明 list.c 函数实现 main.c 写 main 函数
list.h 和 list.c 两个文件中只写和顺序表相关的代码。
(3)创建空顺序表函数
/*
功能:创建一个顺序表类型结构体变量,并将 size 成员赋值为 0
返回值:返回创建的顺序表结构体变量
*/
List_t create_empty_list ();
(4)判断表是否为空
/*
功能:判断顺序表是否满 数据数量达到数组的最大容量
参数:指向顺序表结构体变量的指针
返回值:满返回 1 不满返回 0
*/
int is_full ( const List_t * p );
(5)判断表是否满
/*
功能:判断顺序表是否满 数据数量达到数组的最大容量
参数:指向顺序表结构体变量的指针
返回值:满返回 1 不满返回 0
*/
int is_full ( const List_t * p );
(5)清空顺序表
/*
功能:清空顺序表 size=0 就是清空数组,只要 size 得 0 ,那么数组中所有的数据在逻辑上都是无效的
参数:指向顺序表结构体变量的指针
*/
void clear_list ( List_t * p );
(6)打印表中数据
/*
功能:打印顺序表中的数据
参数:指向顺序表结构体变量的指针
*/
void print_list ( const List_t * p );
(7)求有效元素个数
/*
一般情况下,我们不会直接对数据结构的成员操作,而是将对成员的操作封装在函数中
功能:求顺序表中的元素个数
参数:指向顺序表结构体变量的指针
返回值:顺序表的元素个数
*/
int list_size ( const List_t * p );
(8)在有效指定位置插入元素
/*
功能:在指定位置 pos 插入数据 x
参数 1 :指向顺序表结构体变量的指针
参数 2 :插入数据的位置
参数 3 :插入的数据
返回值:如果顺序表已满,或者 pos 位置超出当前数据范围,或者超出顺序表的最大容量,返回 0 表示失败,否则返回 1 表示成
功
*/
int insert_list ( List_t * p , int pos , int x );
(9)从顺序表中删除指定位置数据
/*
功能:删除指定位置 pos 的元素
参数 1 :指向顺序表结构体变量的指针
参数 2 :删除数据的位置
返回值:如果顺序表为空,或者 pos 位置超出当前的数据范围 0~size-1 , pos<0 ,返回 0 表示失败,否则返回 1 表示成功
*/
int delete_list ( List_t * p , int pos );
(10)综合代码
main.c
#include <stdio.h>
#include "list.h"
int main ()
{
List_t list = create_empty_list ();
insert_list ( & list , 0 , 10 ); // 头插
print_list ( & list ); //10
insert_list ( & list , 0 , 20 ); // 头插
print_list ( & list ); //20 10
insert_list ( & list , 2 , 30 ); // 尾插
print_list ( & list ); //20 10 30
if ( insert_list ( & list , 10 , 100 ) == 0 )
{
printf ( "insert pos 10 error\n" ); //insert pos 10 error
}
print_list ( & list ); //20 10 30
insert_list ( & list , 1 , 40 ); // 中间插
print_list ( & list ); //20 40 10 30
delete_list ( & list , 1 );
print_list ( & list ); //20 10 30
if ( delete_list ( & list , 5 ) == 0 )
{
printf ( "delete pos 5 error\n" ); //delete pos 5 error
}
print_list ( & list ); //20 10 30
return 0 ;
}
list.h
#ifndef LIST_H
#define LIST_H
#define MAX_DATA_SIZE 100
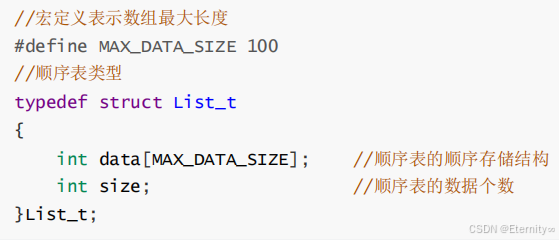
typedef struct List_t
{
int data MAX_DATA_SIZE ;
int size ;
} List_t ;
List_t create_empty_list ();
int is_full ( const List_t * p );
int is_empty ( const List_t * p );
void clear_list ( List_t * p );
void print_list ( const List_t * p );
int list_size ( const List_t * p );
#endif
list.c
#include "list.h"
#include <stdio.h>
List_t create_empty_list ()
{
List_t l = {{ 0 }, 0 };
return l ;
}
int is_full ( const List_t * p )
{
// 返回 == 运算符的运算结果
return p -> size == MAX_DATA_SIZE ;
}
int is_empty ( const List_t * p )
{
return p -> size == 0 ;
}
void clear_list ( List_t * p )
{
p -> size = 0 ;
}
void print_list ( const List_t * p )
{
int i ;
for ( i = 0 ; i < p -> size ; i ++ )
{
printf ( "%d " , p -> data i );
}
printf ( "\n" );
}
int list_size ( const List_t * p )
{
return p -> size ;
}
int insert_list ( List_t * p , int pos , int x )
{
if ( is_full ( p ) || pos < 0 || pos > p -> size )
{
return 0 ;
}
int i ;
for ( i = p -> size ; i > pos ; i -- )
{
p -> data i = p -> data i - 1 ;
}
p -> data pos = x ;
p -> size ++ ;
return 1 ;
}
int delete_list ( List_t * p , int pos )
{
if ( is_empty ( p ) || pos < 0 || pos > p -> size - 1 )
{
return 0 ;
}
int i ;
for ( i = pos ; i < p -> size - 1 ; i ++ )
{
p -> data i = p -> data i + 1 ;
}
p -> size -- ;
return 1 ;
}
2.链表
1.what
单向链表:每个节点中保存下一个节点的地址
双向链表:每个节点中既保存下一个节点的地址,又保存上一个节点的地址
单向循环链表:最后一个节点保存了第一个节点的地址
双向循环链表:最后一个节点保存了第一个节点的地址,第一个节点还保存最后一个节点的地址
**2.**单向链表的结构体封装
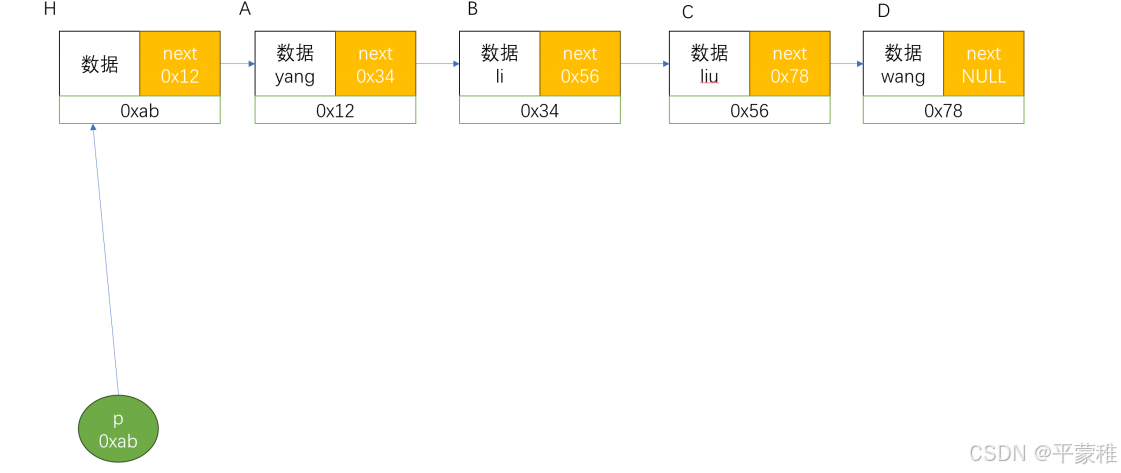
单向链表有两个域,数据域(data)和指针域(next)

**3.**单向链表代码实例
单向链表分为两种类型,一种是带空头结点,一种是不带空头节点。
两种写法原理一模一样,只是代码的实现细节略有不同。
我们将带空头链表,因为带空头的链表代码细节上更简单一些。
实例1:
#include <stdio.h>
typedef struct node_t
{
char name 20 ;
struct node_t * next ;
} Link_node_t ;
int main ()
{
Link_node_t H = { "" , NULL };
Link_node_t A = { "yang" , NULL };
Link_node_t B = { "li" , NULL };
Link_node_t C = { "liu" , NULL };
Link_node_t D = { "wang" , NULL };
H . next = & A ;
A . next = & B ;
B . next = & C ;
C . next = & D ;
Link_node_t * p = & H ;
p = p -> next ; // 空头不参与遍历,因为没有数据,让 p指向第一个数据节点
while ( p != NULL )
{
printf ( "%s\n" , p -> name );
p = p -> next ;
}
return 0 ;
}
实例2:(创建头尾指针和new指针(结构体指针是没存储空间)再创建空间让指针指向空间)在堆空间创建节点,用带头结点的单向链表存储n个学生成绩 ,成绩由键盘输入,输入<=0 时结束
#include <stdio.h>
#include <stdlib.h>
typedef struct node_t
{
int score ;
struct node_t * next ;
} Link_node_t ;
int main ()
{
int s ;
Link_node_t * head = NULL ; // 指向头节点的指针,我们称头指针,关键
Link_node_t * tail = NULL ; // 为了完成构建链表的逻辑,写一个尾指针,之前链表中最后一个节点
Link_node_t * new_node = NULL ; // 指向新创建的节点
// 动态创建一个空头节点
head = ( Link_node_t * ) malloc ( sizeof ( Link_node_t ));
head -> next = NULL ; // 目前链表中只有一个空头,所以它既是头也是尾,尾节点 next 指向 NULL
tail = head ; // 尾指针也指向空头
while ( 1 )
{
scanf ( "%d" , & s );
if ( s <= 0 )
break ;
// 创建新节点
new_node = ( Link_node_t * ) malloc ( sizeof ( Link_node_t ));
new_node -> score = s ; // 数据赋值,我们写链表不关注数据是什么,因为和链表结构没关系
new_node -> next = NULL ; // 新创建的节点 next 默认给 NULL
tail -> next = new_node ; // 将新节点接入链表尾部
tail = new_node ; 等价 // 让 tail 指向新的尾节点
//tail = tail->next;// 和 tail = new_node; 等价
}
Link_node_t * node = head -> next ; // 使用 node 第一个数据节点,然后遍历链表
while ( node != NULL )
{
printf ( "%d\n" , node -> score );
node = node -> next ; // 指向下一个节点
}
return 0 ;
}
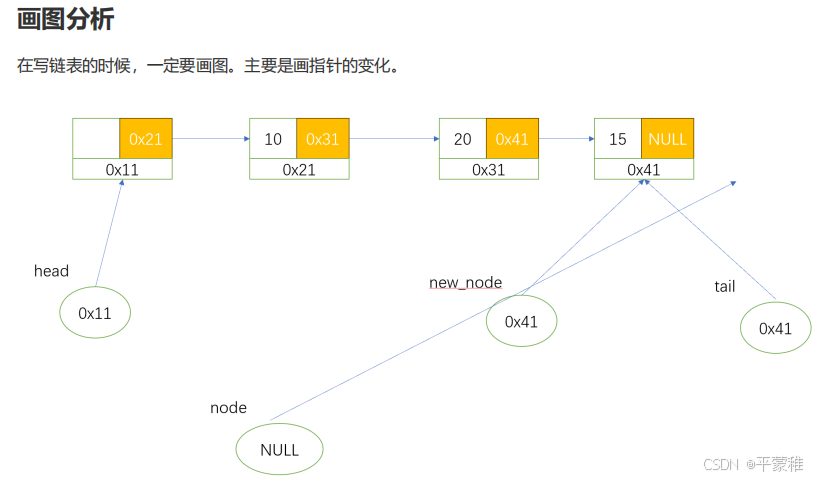
4.链表的封装
1)创建一个带空头节点的空单向链表
// 链表节点的结构体类型
typedef struct node_t
{
int data ;
struct node_t * next ;
} Link_node_t ;
/*
功能:创建一个链表的空头节点(堆空间)
返回值:头结点的地址
*/
Link_node_t * create_link_list ();
int main ()
{
Link_node_t * head = create_link_list ();
return 0 ;
}
// 创建链表就是创建一个空头
Link_node_t * create_link_list ()
{
Link_node_t * p = ( Link_node_t * ) malloc ( sizeof ( Link_node_t ));
p -> next = NULL ;
return p ;
}
2**)判断表是否为空**
/*
功能:判断一个链表是否为空,当链表只有一个空头的时候链表为空
参数:链表头节点指针,我们对链表的操作都是从头节点开始的
返回值:空 1 非空 0
*/
int empty_link_list ( const Link_node_t * p );
int main ()
{
Link_node_t * head = create_link_list ();
if ( empty_link_list ( head ))
{
printf ( " 空 \n" );
}
else
{
printf ( " 非空 \n" );
}
return 0 ;
}
// 没有数据节点就是空的
int empty_link_list ( const Link_node_t * p )
{
return p -> next == NULL ;
}
3**)求出链表有效元素个数**
/*
功能:求链表中除空头节点以外的节点个数
参数:链表头结点指针
返回值:节点个数
*/
int length_link_list ( Link_node_t * p );
int main ()
{
Link_node_t * head = create_link_list ();
Link_node_t * tail = head ;
int i ;
// 以下测试代码
for ( i = 0 ; i < 5 ; i ++ )
{
Link_node_t * new_node = ( Link_node_t * ) malloc ( sizeof ( Link_node_t ));
new_node -> data = i * 10 ;
new_node -> next = NULL ;
tail -> next = new_node ;
tail = new_node ;
}
printf ( "%d\n" , length_link_list ( head ));
// 以上测试代码
return 0 ;
}
int length_link_list ( const Link_node_t * p )
{
// 习惯性的不动头指针
Link_node_t * node = p -> next ;
int count = 0 ;
while ( node != NULL )
{
count ++ ;
node = node -> next ;
}
return count ;
}
4**)获取某个位置元素的值**
/*
功能:获得链表指定位置的数据
参数 1 :链表头结点指针
参数 2 :位置 需要判断位置是否有效 位置从 0 开始, 0 是第一个有效数据节点
参数 3 :找到的值。结构体中的数据域是 int 类型,所以参数定义 int* ,属于输出参数
返回值:表示是否成功成功返回 1 失败返回 0
指针从空头开始移动 pos+1 次,在遍历链表过程中判断时候还有下一个节点,如果没有下一个节点说明查找失败
*/
int get_link_list ( Link_node_t * p , int pos , int* data );
int main ()
{
Link_node_t * head = create_link_list ();
int data ;
if ( get_link_list ( head , 10 , & data ) == 1 )
{
printf ( " 查找失败 \n" );
}
return 0 ;
}
int get_link_list ( Link_node_t * p , int pos , int* data )
{
Link_node_t * node = p -> next ;
int i = 0 ;
while ( node != NULL )
{
if ( i ++ == pos )
{
* data = node -> data ; // 返回数据
return 1 ; //查找成功
}
node = node -> next ;
}
return 0 ;
}
5**)插入元素**
/*
功能:在指定位置插入值为 x 的节点
参数 1 :链表头结点指针
参数 2 :位置 需要判断位置是否有效 0 是第一个有数据的节点,空头不是 0
参数 3 :新节点的值
返回值:成功返回 1 失败返回 0
指针从空头开始移动 pos 次,在遍历链表过程中判断时候还有下一个节点,如果没有下一个节点说明查找失败
*/
int insert_link_list ( Link_node_t * p , int pos , int x );
int main ()
{
Link_node_t * head = create_link_list ();
insert_link_list ( head , 0 , 10 ); // 头插 10
insert_link_list ( head , 0 , 20 ); // 头插 20 10
insert_link_list ( head , 1 , 30 ); // 中插 20 30 10
insert_link_list ( head , 3 , 40 ); // 尾插 20 30 10 40
if ( ! insert_link_list ( head , 10 , 50 )) // 越界
{
printf ( "insert 10 error\n" );
}
printf ( "%d \n" , length_link_list ( head ));
int i ;
// 这里遍历的方法非常的不好,因为每次循环都要遍历一次链表计算长度,仅仅是为了测试函数
/*
可以改成
int n = length_link_list(head);
for(i = 0;i < n;i++)
*/
for ( i = 0 ; i < length_link_list ( head ); i ++ )
{
int data ;
get_link_list ( head , i , & data );
printf ( "%d " , data );
}
printf ( "\n" );
return 0 ;
}
int insert_link_list ( Link_node_t * p , int pos , int x )
{
Link_node_t * node = p ;
int i = 0 ;
while ( node != NULL )
{
if ( i ++ == pos )
{
// 为数据创建一个新的节点
Link_node_t * newnode = ( Link_node_t * ) malloc ( sizeof ( Link_node_t ));
newnode -> data = x ;
//newnode->next = NULL;// 这行可以不写
// 插入到链表中
newnode -> next = node -> next ;
node -> next = newnode ;
return 1 ;
}
node = node -> next ;
}
return 0 ;
}
6**)删除元素**
int del_link_list ( Link_node_t * p , int pos )
{
Link_node_t * node = p ;
int i = 0 ;
while ( node != NULL )
{
if ( i ++ == pos && node -> next != NULL )
{
Link_node_t * t = node -> next ;
/*
node->next 计算得到 node 指向的对象中的 next 成员,成员中存放再下一个节点的地址
* */
node -> next = node -> next -> next ;
free ( t );
return 1 ;
}
node = node -> next ;
}
return 0 ;
}
void print_list ( const Link_node_t * p )
{
// 习惯性的不动头指针
Link_node_t * node = p -> next ;
while ( node != NULL )
{
printf ( "%d " , node -> data );
node = node -> next ;
}
printf ( "\n" );
}

7**)遍历打印链表**
void print_list ( const Link_node_t * p )
{
// 习惯性的不动头指针
Link_node_t * node = p -> next ;
while ( node != NULL )
{
printf ( "%d " , node -> data );
node = node -> next ;
}
printf ( "\n" );
}
8**)测试代码**
int main ()
{
Link_node_t * head = create_link_list ();
if ( empty_link_list ( head ))
{
printf ( " 空 \n" );
}
if ( insert_link_list ( head , 1 , 100 ) == - 1 )
{
printf ( " 插入失败 \n" );
}
insert_link_list ( head , 0 , 100 );
insert_link_list ( head , 1 , 1000 );
if ( ! empty_link_list ( head ))
{
printf ( " 不是空 \n" );
}
int data ;
if ( get_link_list ( head , 2 , & data ) == - 1 )
{
printf ( " 查找失败 \n" );
}
get_link_list ( head , 0 , & data );
printf ( "find %d\n" , data );
printf ( "%d\n" , length_link_list ( head ));
print_list ( head );
if ( del_link_list ( head , 2 ) == - 1 )
{
printf ( " 删除失败 \n" );
}
if ( del_link_list ( head , 3 ) == - 1 )
{
printf ( " 删除失败 \n" );
}
del_link_list ( head , 1 );
del_link_list ( head , 0 );
if ( del_link_list ( head , 0 ) == - 1 )
{
printf ( " 删除失败 \n" );
}
printf ( "%d\n" , length_link_list ( head ));
return 0 ;
}
**9)**清空链表
void clear_link ( Link_node_t * p ); // 清空空头以外的节点,链表还可以继续使用
void free_link ( Link_node_t * p ); // 清空包括空头的所有节点,链表不可以使用了
void clear_link ( Link_node_t * p )
{
Link_node_t * node = p -> next ;
p -> next = NULL ; // 空头的 next 成员置空
while ( node != NULL )
{
Link_node_t * t = node ;
node = node -> next ;
free ( t );
}
}
void free_link ( Link_node_t * p )
{
Link_node_t * node = p ;
while ( node != NULL )
{
Link_node_t * t = node ;
node = node -> next ;
free ( t );
}
}
5.链表与顺序表的优缺点
顺序表优势:查找快,首地址通过地址偏移运算可以得到任何元素的地址。
顺序表劣势:中间位置插入删除慢,移动数组元素。
什么时候选择使用顺序表:经常查找,很少在中间位置插入删除
链表优势:插入删除快,只需要改变几个指针的指向。节省内存。
链表劣势:查找慢,找一个元素必须从头开始遍历。
什么时候选择使用链表:经常插入删除,很少随机查找。
线性表的元素访问方式:一般使用位置。
顺序表是使用顺序存储实现的线性结构;
链表使用链式存储实现的线性结构
3.栈
1.what
栈( stack )是只能在一端进行插入和删除操作的线性表,是一种逻辑结构,必须基于某中存储结构才能完成,不支持随机访问。 栈的操作中没有遍历,遍历栈的存储结构这种操作和栈没关系。
栈的操作规则: FILO first in last out 先进后出 LIFO last in first out 后进先出
栈的实现可以依赖于哪种存储结构?
顺序存储 优势随机访问快,但是栈不需要随机访问,劣势在中间插入删除慢,但是栈不需要在中间插入删除。
链式存储 优势在中间位置插入删除快,但是栈不需要在中间插入删除栈不,劣势随机访问慢,但是栈不需要随机访问
所以顺序存储和链式存储都可以实现栈
**2.**栈的封装
1)类型结构体
2**)创建空的顺序栈**
3**)清空顺序栈**
4**)判断是否栈空**
5**)判断是否栈满**
6**)入栈(将数放到栈里面)**
7**)出栈(将数从栈中移出)**
8**)获得栈顶元素**
9**)测试**
aa
**3.**栈的应用举例
后缀表达式
1 操作数 (数字或字母)
直接输出到后缀表达式结果中。
2 左括号 (
直接压入运算符栈。
3 右括号 )
依次弹出栈顶运算符并输出 ( 入后缀表达式栈 ) ,直到弹出左括号 ( (括号不输出)。
4 运算符 ( + , - , * , / )
若栈为空或栈顶为 ( ,直接入栈。
否则, 比较与栈顶运算符的优先级 :若优先级比栈顶运算符高,则入栈;否则,弹出栈顶运算符并输出 ( 入后缀表达式
栈 ) ,然后重新执行步骤 4 进行比较。
5 表达式扫描完毕
将运算符栈中所有剩余的运算符依次弹出并输出 ( 入后缀表达式栈 )
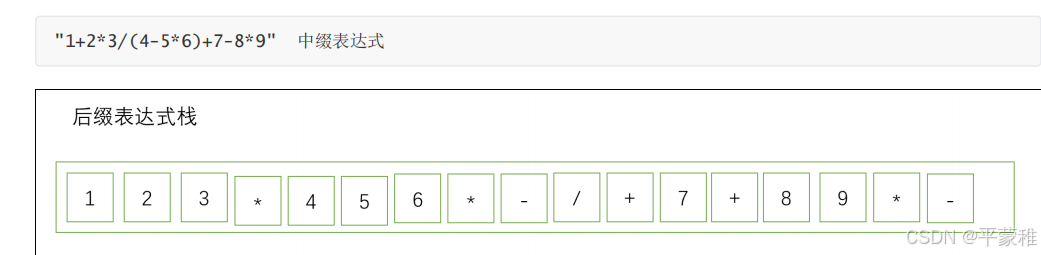
解析后缀表达式:
出栈元素,如果是符号,那么下一次出栈就是符号的右值,递归,直到遇到数字归回,当归回到符号位置是,再出栈
就是符号的左值,当左值也遇到数字时符号可以运算,将运算结果继续归回。 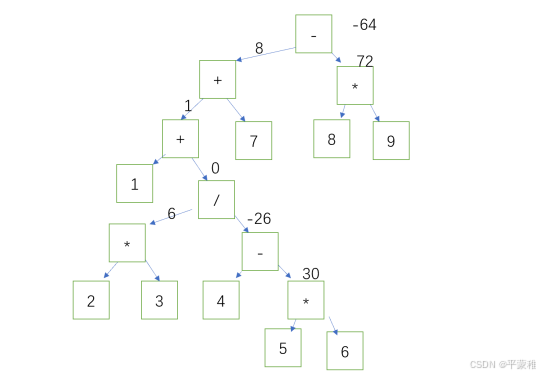
4.队列
1.what
队列 (queue) 允许在一端进行插入和另一端进行删除操作的线性表,是逻辑结构的一种,不支持随机访问。
FIFO first in first out 先进先出
队列的实现可以依赖于哪种存储结构?
顺序存储 优势随机访问快,但是栈不需要随机访问,劣势在中间插入删除慢,但是栈不需要在中间插入删除。
链式存储 优势在中间位置插入删除快,但是栈不需要在中间插入删除栈不,劣势随机访问慢,但是栈不需要随机访问
所以顺序存储和链式存储都可以实现栈。
**2.**队列的封装
1**)类型结构体**
typedef struct
{
int* data ; // 指针指向动态数组
int max_len ; // 动态数组的长度
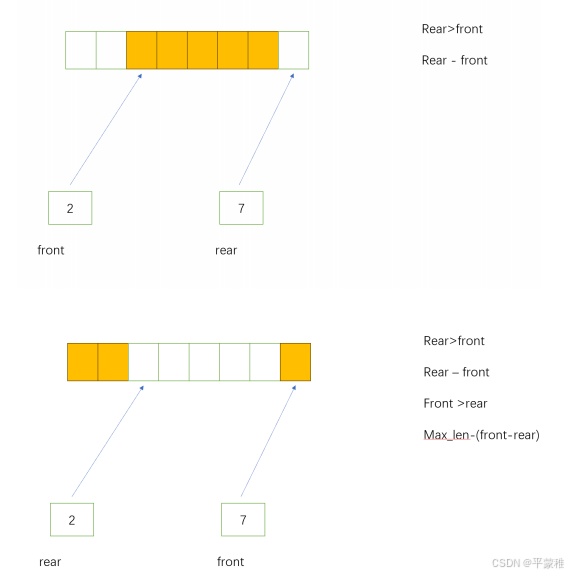
int front ; // 出队 队首元素
int rear ; // 入队 如果入队需要插入 rear 位置,然后 rear++ , rear 位置总是空的
} Queue_t ;
2**)创建空队列**
/*
功能:在堆空间创建队列结构体, front 和 rear 成员赋值 0
返回值:结构体地址
*/
Queue_t * create_empty_queue ( int len );
3**)判断队列是否为空**
/*
功能:判断队列为空 front 和 rear 相等既空
参数:队列结构体指针
返回值:空 1 非空 0
*/
int empty_qeue ( Queue_t * p );
4**)判断队列是否满**
/*
为了区分满和空的条件,存储结构会牺牲一个元素, % 数组长度的目的是为了让 rear 或者 front+1 越界之后将它们的值置成 0
功能:判断队列满
参数:队列结构体指针
返回值:满 1 不满 0
*/
int full_queue ( Queue_t * p );
5**)入队**
/*
功能:在队列 rear 位置插入一个数据 然后移动 rear 到下一个角标位置
参数 1 :队列结构体指针
参数 2 :插入的数据
队列满失败,打印入队失败信息
*/
void push_queue ( Queue_t * p , int x );
6**)出队**
/*
功能:移动 front 到下一个角标位置
参数:队列结构体指针
*/
void pop_queue ( Queue_t * p );
7**)获得队头元素**
/*
功能:获得将要出队的元素
*/
int top_queue ( const Queue_t * p );
8**)求队列长度**
/*
求队列中数据的个数
rear>front
rear<front
统一两种情况
(rear-front+m)%m
*/
int size_queue ( Queue_t * p );
9**)测试**
int main ()
{
Queue_t * queue = create_empty_queue ( 5 );
push_queue ( queue , 10 );
push_queue ( queue , 20 );
push_queue ( queue , 30 );
push_queue ( queue , 40 ); // 此时已经满了
if ( ! full_queue ( queue ))
push_queue ( queue , 50 );
if ( ! full_queue ( queue ))
printf ( "%d\n" , top_queue ( queue )); //10 20 30 4
push_queue ( queue , 60 );
printf ( "size:%d\n" , size_queue ( queue )); //4
while ( ! empty_queue ( queue ))
{
0
pop_queue ( queue );
}
return 0 ;
}
queue.h
#ifndef QUEUE_H
#define QUEUE_H
typedef struct
{
int* data ;
int max_len ;
int front ;
int rear ;
} Queue_t ;
Queue_t * create_empty_queue ( int len );
int empty_queue ( const Queue_t * p );
int full_queue ( const Queue_t * p );
void push_queue ( Queue_t * p , int x );
void pop_queue ( Queue_t * p );
int top_queue ( const Queue_t * p );
int size_queue ( const Queue_t * p );
#endif
queue.c
#include <stdio.h>
#include <stdlib.h>
#include "queue.h"
Queue_t * create_empty_queue ( int len )
{
Queue_t * queue = ( Queue_t * ) malloc ( sizeof ( Queue_t ));
queue -> data = ( int* ) malloc ( sizeof ( int ) * len );
queue -> max_len = len ;
queue -> front = 0 ;
queue -> rear = 0 ;
return queue ;
}
int empty_queue ( const Queue_t * p )
{
return p -> front == p -> rear ;
}
int full_queue ( const Queue_t * p )
{
return ( p -> rear + 1 ) % p -> max_len == p -> front ;
}
void push_queue ( Queue_t * p , int x )
{
if ( full_queue ( p )) // 满了不能加
return ;
p -> data p -\> rear = x ; // 插入数据
p -> rear = ( p -> rear + 1 ) % p -> max_len ;
}
void pop_queue ( Queue_t * p )
{
if ( empty_queue ( p ))
return ;
p -> front = ( p -> front + 1 ) % p -> max_len ; // 无论 front rear 只要有 +1 的操作,必须 % 数组长度
}
int top_queue ( const Queue_t * p )
{
return p -> data p -\> front ; // front就是队首元素
}
int size_queue ( const Queue_t * p )
{
/*
if(p->rear > p->front)
return p->rear - p->front;
else
return p->max_len-(p->front - p->rear);
*/
return ( p -> max_len + p -> rear - p -> front ) % p -> max_len ;
}
**3.**队列应用举例
扫雷的开图算法
使用队列实现广度优先遍历
挺难,不要求必须掌握
四.查找算法
1.顺序查找
**1.**算法思想
遍历数组,一个一个比较
**2.**时间复杂度
T(N) = O(N)
不依赖与数据的规律,当数据完全没有规律的时候,只能顺序查找。
最慢的查找算法。
2.二分查找
1.算法思想
链表不能使用二分法查找。
数组有序(一般是升序)。先比较中间位置的元素是不是要找的元素,如果不是,根据大小关系决定向左或者向右继续查找。
中间位置: ( left+right ) / 2 left 是查找范围左边的下标, right 是查找范围右边的下标
2.实例
/*
参数1:数组
参数2:数组长度
参数3:要找的数
返回值: -1 没找到 返回x在数组中的角标
* */
int find_half ( int* p , int n , int x )
{
int left = 0 ; // 左边位置
int right = n - 1 ; // 右边位置
while ( left <= right ) // 循环过程中 left 会增大, right 会减小,如果 left 大于了 right 说明查找失败
{
int mid = ( left + right ) / 2 ; // 计算中间位置
if ( p mid == x )
{
return mid ; // 如果找到直接返回下标
}
else if ( x < p mid )
{
right = mid - 1 ; // 向左找,减小 right
}
else
{
left = mid + 1 ; // 向右找,增加 left
}
}
return - 1 ; // 查找失败返回 -1
}
/*
二分法查找的递归写法
参数1:指向数组的指针
参数2:数组分段的起始角标
参数3:数组分段的结束角标
参数4:要找的数
返回值:找到的位置 -1 没找到
* */
int find_half_req ( int* p , int left , int right , int x )
{
if ( left > right )
return - 1 ; // 超出范围查找失败,返回 -1
int mid = ( left + right ) / 2 ;
if ( x == p mid )
{
return mid ; // 找到返回下标
}
else if ( x < p mid )
{
right = mid - 1 ; // 向左找 缩小 right
}
else
{
left = mid + 1 ; // 向右找 增加 left
}
return find_half_req ( p , left , right , x );
}
int main ()
{
int a 10 = { 10 , 15 , 18 , 20 , 25 , 30 , 31 , 38 , 40 , 45 };
int x ;
scanf ( "%d" , & x );
int ret = find_half ( a , 10 , x );
//int ret = find_half_req(a, 0, 9, x);
if ( ret == - 1 )
printf ( "not find\n" );
else
printf ( "find it at %d\n" , ret );
return 0 ;
}
**3.**时间复杂度
T(N) = O(logN)
3.分块查找
**1.**算法思想
要求数据分块,块间有序(前一个块中的所有值都小于下一个块中的最小值),块内无序。
先确定数据可能在哪个块中(块间的查找可以使用顺序或者二分法),再到块内顺序查找。
**2.**算法示例
typedef struct
{
int max ; // 块中的最大值
int start_pos ; // 块中的起始下标
int end_pos // 块中的结束下标
} index_t ;
/*
参数 1 :指向数据数组的指针
参数 2 :指向索引表数组的指针
参数 3 :索引表数组的元素个数
参数 4 :要找的数据
*/
int find_index ( int* data , index_t * index , int index_len , int x )
{
int i ;
// 顺序查找分块信息表,确定数据可能在哪个块中
for ( i = 0 ; i < index_len ; i ++ )
{
if ( x <= index i . max ) // 由于我是顺序查找,所以查找的数小于哪个块的最大值就可能在哪个块中
{
break ;
}
}
// 如果 i == index_len 说明 x 大于所有块中的最大值,不在数组范围内
if ( i == index_len )
{
return - 1 ;
}
int j ;
// 在一个块中顺序查找 indexi.start_pos 块的起始位置, indexi.end_pos 是块的结束位置
for ( j = index i . start_pos ; j <= index i . end_pos ; j ++ )
{
if ( data j == x )
{
return j ;
}
}
return - 1 ;
}
int main ()
{
// 数组 a 是一个分好块的数组
int a 19 = { 18 , 10 , 9 , 8 , 16 , 20 , 38 , 42 , 19 , 50 , 84 , 72 , 56 , 55 , 76 , 100 , 90 , 88 ,
108 };
// 数组 b 描述的数组 a 的分块信息
index_t b 4 = {{ 18 , 0 , 4 }, { 50 , 5 , 9 }, { 84 , 10 , 14 }, { 108 , 15 , 18 }};
int num ;
scanf ( "%d" , & num );
printf ( "%d\n" , find_index ( a , b , 4 , num ));
return 0 ;
**3.**时间复杂度
T(N)=O(√N)
4.哈希查找
1.算法思想
哈希查找一定基于数组,按照一定的规则将任意类型的一个数据放到数组的某个位置上。
选择数组的原因是因为数组支持随机访问,我们只需要根据一个规则将要存的数据算出一个数组中的角标,就可以到数组中存取数据。
时间 复杂度O(1)
1**)哈希函数**
哈希函数封装将任意类型转换成数组中角标的算法。
2**)解决冲突**
两个不同的数据可能计算出相同的角标,此时我们称为冲突。
我们需要根据数据的规律定制哈希算法,尽量降低冲突的可能性**。**
链地址法
数组的每个元素都是一个链表,将发生冲突的数据追加到链表的尾部。在查找的时候顺序遍历链表。
链表不可能很长,如果链表过程说明哈希算法不适合当前的数据特性。
再哈希法
准备若干哈希算法,一个算法冲突了换下一个算法,如果所有算法都冲突那么插入失败。
备用表法
将所有发生冲突的数据放在一个顺序表中
任何哈希算法都不能保证没有冲突,只能尽量的降低冲突概率。
3**)装填因子**
实际存放的数据的数量 / 数组长度 = 装填因子
装填因子一定小于 1 ,数越小冲突概率越小,但是越废内存
2.实例几种典型的哈希算法
使用哈希算法计算出来的角标 叫 哈希值( hash code )
用于计算哈希值的数据称为 key (键)
要存入哈希表的数据叫 value ( 值 )
示例1直接地址法
通过这个例子要理解哈希的使用原理。
直接地址法只能用于 key 是整数,而且 key 天然的就能作为数组的角标
完成人口统计哈希表练习
1 3000 人
2 2500 人
3 2700 人
4 2200 人
....
录入 : 根据年龄 存人数 (1 3000 2 2500 25 20000 ....)
取出 : 根据年龄 取人数
示例2叠加法
把关键字从左向右分成位数相等的几部分,每一部分的位数和散列表地址(数组)位数相同,把这些部分叠加起来。
叠加法和平方取中法有些类似。
平方取中法
取关键字的平方,然后根据可使用空间的大小,选取平方数是中间几位为哈希表的地址。
比如:关键字: 1234 ,关键字的平方: 1522756 ,哈希函数值: 227
示例3保留余数法和备用表法
保留余数法是哈希算法
备用表法解决冲突
定义一个较大的数组,数据模除数组长度得到哈希值。
23 , 34 , 14 , 38 , 46 , 16 , 68 , 15 , 7 , 31 , 26
结合备用表法解决冲突的示例
五.树
(一)树形结构**------**二叉树
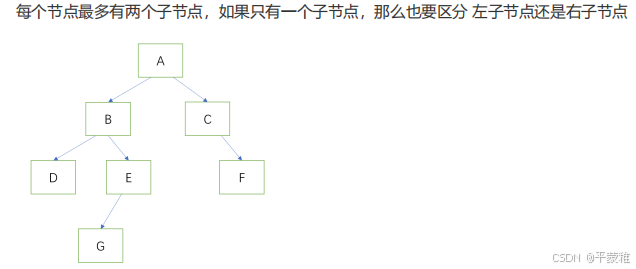
1.二叉树性质

2**.满二叉树和完全二叉树**
满二叉树 :深度为 k ( k ≥ 1 )时有 2 的 k 次幂- 1 个节点的二叉树
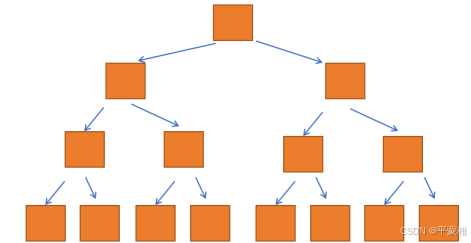
完全二叉树 :只有最下面两层有度数小于 2 的节点,且最下面一层的叶节点集中在最左边的若干位置上
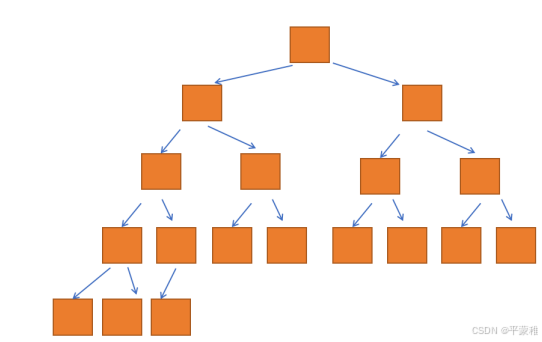
满二叉树是一种特殊的完全二叉树。
3.二叉树的深度遍历
也叫深度优先遍历。
递归
遍历 :沿某条搜索路径周游二叉树,对树中的每一个节点访问一次且仅访问一次
先序遍历 ( 前序遍历 ) 根 --> 左 --> 右
中序遍历 左 --> 根 --> 右
后序遍历 左 --> 右 --> 根
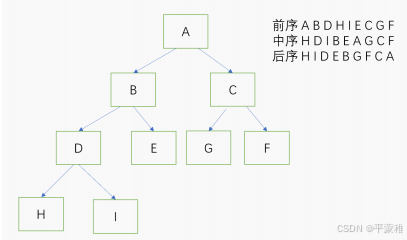
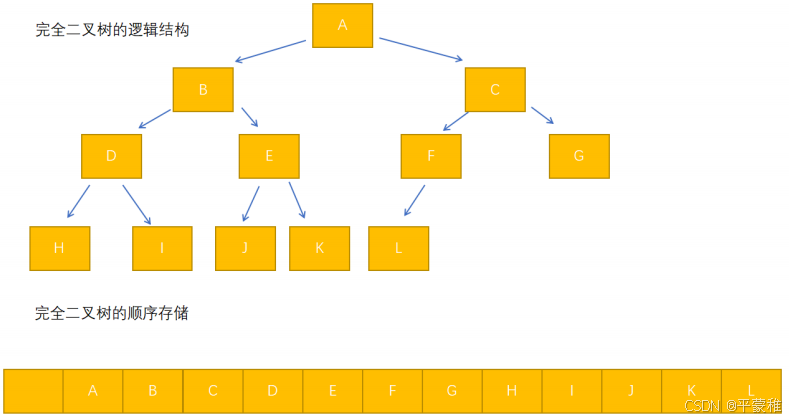
**4.**完全二叉树的数组储存方式
树形结构是逻辑结构,树形结构一般使用链接存储,但是如果是完全二叉树,使用顺序存储也是极好的。
数组中 i(i>=1) 元素的左孩子在 2*i 位置,右孩子在 2*i+1 位置。
由子节点找父节点 i/2
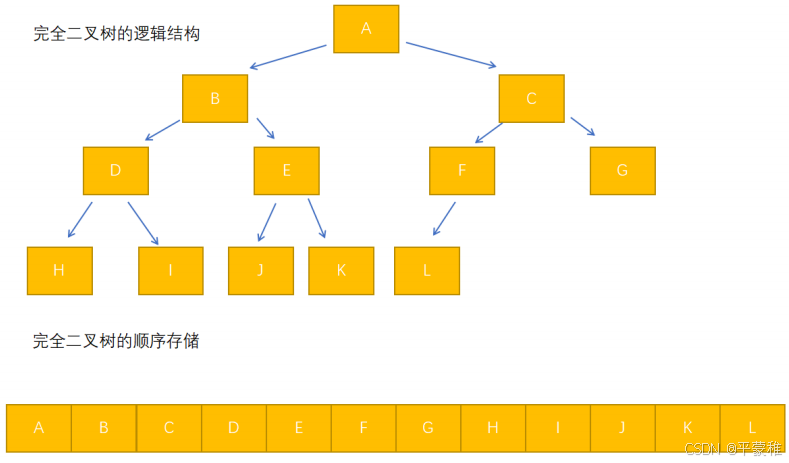
i>=0,会是怎样的关系? 左孩子 2*i+1 右孩子 2*i+2 父节点 (i-1)/2
**5.**深度(优先)遍历二叉树的代码实例
链式结构
#include <stdio.h>
// 链式存储二叉树节点的结构体
typedef struct node_t
{
char data ;
struct node_t * lchild ; // 指向左孩子的指针
struct node_t * rchild ; // 指向右孩子的指针
} bitree_t ;
void firstList ( bitree_t * r );
void middleList ( bitree_t * r );
void lastList ( bitree_t * r );
int main ()
{
// 为了测试,随便写一个二叉树
bitree_t A = { 'A' , NULL , NULL };
bitree_t B = { 'B' , NULL , NULL };
bitree_t C = { 'C' , NULL , NULL };
bitree_t D = { 'D' , NULL , NULL };
bitree_t E = { 'E' , NULL , NULL };
bitree_t F = { 'F' , NULL , NULL };
A . lchild = & B ;
A . rchild = & C ;
B . lchild = & D ;
B . rchild = & E ;
C . lchild = & F ;
firstList ( & A );
printf ( "\n" );
middleList ( & A );
printf ( "\n" );
lastList ( & A );
printf ( "\n" );
return 0 ;
}
void firstList ( bitree_t * t )
{
if ( t == NULL ) // 传入空指针归回
{
return ;
}
printf ( "%c " , t -> data ); // 根
firstList ( t -> lchild ); // 左
firstList ( t -> rchild ); // 右
}
void middleList ( bitree_t * t )
{
if ( t == NULL )
{
return ;
}
middleList ( t -> lchild ); // 左
printf ( "%c " , t -> data ); // 根
middleList ( t -> rchild ); // 右
}
void lastList ( bitree_t * t )
{
if ( t == NULL )
{
return ;
}
lastList ( t -> lchild ); // 左
lastList ( t -> rchild ); // 右
printf ( "%c " , t -> data ); // 根
}
6.广度(优先)遍历二叉树的代码实例层序遍历
#include <stdio.h>
// 二叉树的节点
typedef struct node_t
{
char data ;
struct node_t * lchild ;
struct node_t * rchild ;
} bitree_t ;
int main ()
{
// 随便构建一颗二叉树
bitree_t A = { 'A' , NULL , NULL };
bitree_t B = { 'B' , NULL , NULL };
bitree_t C = { 'C' , NULL , NULL };
bitree_t D = { 'D' , NULL , NULL };
bitree_t E = { 'E' , NULL , NULL };
bitree_t F = { 'F' , NULL , NULL };
A . lchild = & B ;
A . rchild = & C ;
B . lchild = & D ;
B . rchild = & E ;
C . lchild = & F ;
bfs ( & A );
return 0 ;
}
void bfs ( bitree_t * t )
{
bitree_t data 10 ; // 创建队列,不是循环队列
int front = 0 , rear = 0 ;
data rear ++ = * t ; // 根先入队
// 只要队列不为空,就一直循环遍历
while ( front != rear )
{
bitree_t bt = data front ++ ; // 获得队首元素,并出队
printf ( "%c " , bt . data ); // 打印数据
// 如果有左孩子,左孩子入队
if ( bt . lchild != NULL )
{
data rear ++ = * bt . lchild ;
}
// 如果有右孩子,右孩子入队
if ( bt . rchild != NULL )
{
data rear ++ = * bt . rchild ;
}
}
printf ( "\n" );
}
(二)二叉树的应用
**1.**查找二叉树
每个节点的左子树中所有的值都小于该节点,右子树中所有的值都大于该节点。
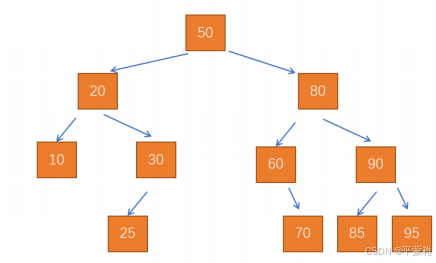
期望查找效率是 T(N) = O(logN)
缺点:按照查找二叉树的定义,那么在构建一颗树的时候,极端情况下可能是一个链表。就算不是链表,也很可能一端很深,一端很浅。
**2.**平衡查找二叉树
目的是为了尽可能的降低二叉树的深度。深度越低查找效率越高。
在查找二叉树的基础上,保证任意节点的左右两个子树的深度差不大于 1 。
当插入数据后,如果不平衡了,需要对二叉树进行调整,这种调整称为 " 旋转 " 。
单旋转
左子树的左孩子打破平衡或者右子树的右孩子打破平衡
双旋转
左子树的右孩子打破平衡或者右子树的左孩子打破平衡
平衡查找二叉树的旋转 ( 了解 )
圆形是需要改变父子关系的节点,三角是固定子树,小三角表示一层节点,大三角表示两层节点。
谁深就提谁,提完之后大小关系不能乱。
**3.**红黑树
性质:
1 )每个节点或是红色,或是黑色。 红黑只代表节点的两种状态,并没有实际属性。节点是可以变色的。
2 )根节点是黑色
3 )每个叶子节点 (NIL) 是黑色
4 )红色节点的子节点必须是黑色
5 )对于每个节点,从该节点到它所有后代的叶子节点的简单路径上,黑色节点数目必须相同
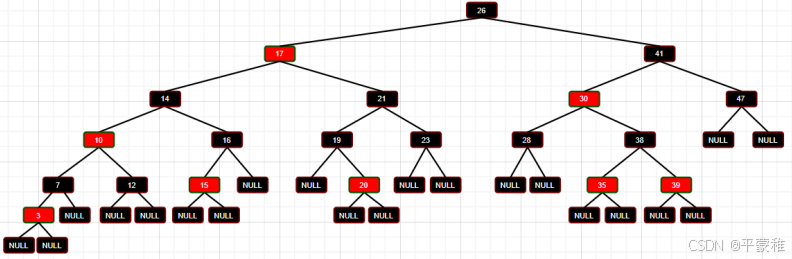
总结:红黑树是一个以黑色节点为平衡的平衡查找二叉树。以牺牲一定的平衡性为代码,综合了插入和查找的效率。
查找的时间复杂度: O(logN)
(三)赫夫曼树
**1.**什么是赫夫曼树
赫夫曼 (Huffman) 树,又称最优树,是求最短带权路径长度的树
- 每次取出权值最小的两个数,小的放左边
- 刚才的两个小的值相加,求出和,然再剩下的 ( 包括刚才的和 ) 中再取出两个小的,
- 依次类推
**2.**赫夫曼树示例:
3,8,6,4 画出赫夫曼树。
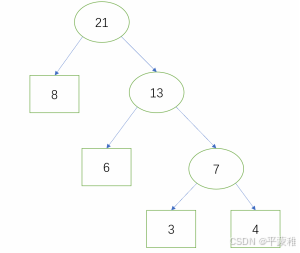
**3.**赫夫曼编码
赫夫曼编码可以有效的压缩数据,通常可以节省 20%~90% 的空间,具体压缩率依赖于数据的特性。
假设要压缩一个 10 万字符的数据文件,文件中只出现了 6 个不同的字符。

如果使用二进制位表示字符,那么每个字符只需要 3 个二进制位。
该文件使用定长编码需要 300000 位长度,使用变长编码需要 224000 位长度。
定长压缩:( 45000+13000+12000+16000+9000+5000 ) *3 37500 字节
变长编码压缩: (1*45+3*13+3*12+3*16+4*9+4*5)*1000 28000 字节
赫夫曼编码就是每个节点在赫夫曼树中的路径。
从根到每个叶子的路径,向左为 0 ,向右为 1 。
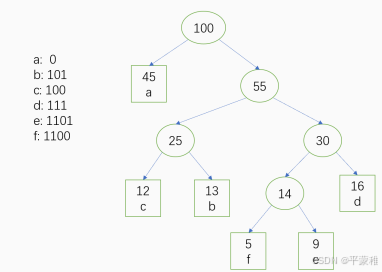
带权路径长度:就是按照赫夫曼编码压缩后的数据长度。
1*45 + 13*3 + 12*3 + 16*3 + 9*4 + 5*4 = 带权路径长度
六.排序算法
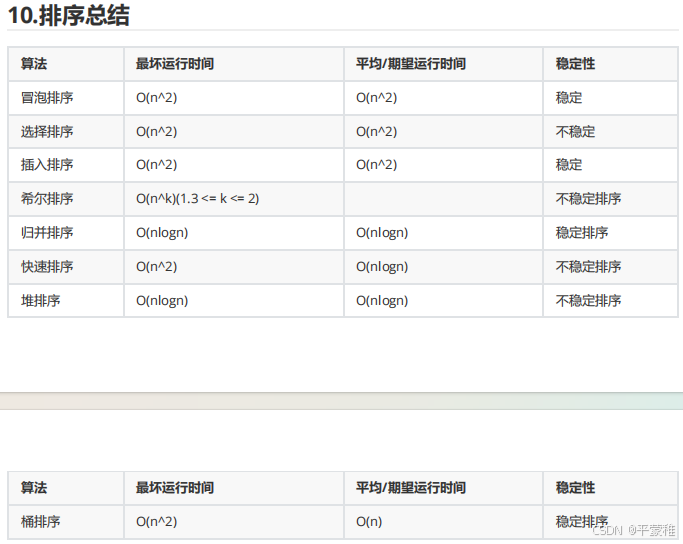
**1.**排序的稳定性
稳定排序或者非稳定排序都不是衡量排序算法优劣的标准,只是排序算法的一个性质。
假设要对成绩排序,小明和小红都是 91 分,在排序之前小明排在小红前面,如果排序之后小明一定还在小红前面就叫稳定排序,否则就是非稳定排序。
稳定排序
如果 a 原本在 b 前面,而 a=b ,排序之后 a 仍然在 b 的前面36(1) 36(2) 42 50 62 65 72 95
非稳定排序
如果 a 原本在 b 的前面,而 a=b ,排序之后 a 可能会出现在 b 的后面。36(2) 36(1) 42 50 62 65 72 95
下面所有排序算法都以升序为例
**2.**冒泡排序
稳定排序 时间复杂度:T(N) = O(N^2)
for(i = 0;i <n-1;i++)
{
int flag = 0;
for(j = 0;j < n-1-i;j++)
{
if(aj > aj+1)
{
int t = aj;
aj = aj+1;
aj+1 = t;
flag = 1;
}
}
if(flag == 0)
{
break;
}
}
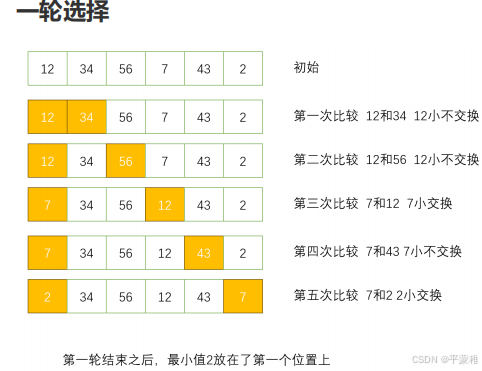
**3.**选择排序
思想:每轮从头到尾 扫描,选出最小的,放在前面。
不稳定排序
时间复杂度: T(N) = O(N^2)
int a6 = {12,34,56,7,43,2};
下图是每一轮找到一个最小值,只交换一次。
如果写代码的话,建议找到一个更小的值就交换。
#include <stdio.h>
void sort ( int* p , int n );
void printArr ( int* p , int n );
int main ()
{
int a 10 = { 23 , 345 , 56 , 87 , 45 , 3 , 2 , 7 , 23 , 87 };
sort ( a , 10 );
printArr ( a , 10 );
return 0 ;
}
void sort ( int* p , int n )
{
int i , j ;
for ( i = 0 ; i < n - 1 ; i ++ )
{
// 假设 p0 是最小值 , 如果 pj 小于 p0 交换
for ( j = i + 1 ; j < n ; j ++ )
{
if ( p i > p j )
{
int t = p i ;
p i = p j ;
p j = t ;
}
}
}
}
void printArr ( int* p , int n )
{
int i ;
for ( i = 0 ; i < n ; i ++ )
{
printf ( "%d " , p i );
}
printf ( "\n" );
}
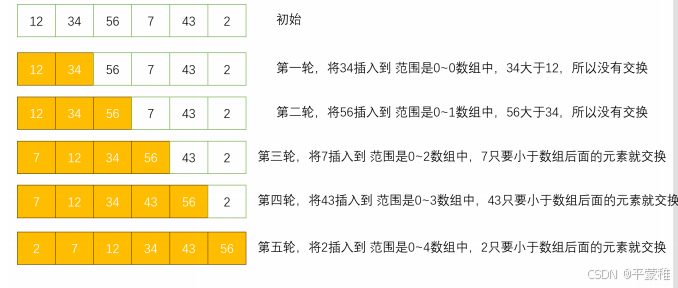
**4.**插入排序
思想:它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
稳定排序
时间复杂度: T(N) = O(N^2)
int a6 = {12,34,56,7,43,2};
插入排序代码示例:
#include <stdio.h>
int main ()
{
int a 10 = { 34 , 45 , 78 , 98 , 45 , 2 , 5 , 8 , 4 , 213 };
int i , j ;
for ( i = 1 ; i < 10 ; i ++ )
{
// 将 ai 插入到 0~i-1 范围的数组中
for ( j = i ; j > 0 ; j -- )
{
if ( a j >= a j - 1 ) // 将要插入的元素和前面的元素进行比较
break ; //break 很重要,只要找到一个不需要交换的数,那么就完成插入
//aj < aj-1 时才进行交换
int t = a j ;
a j = a j - 1 ;
a j - 1 = t ;
}
}
for ( i = 0 ; i < 10 ; i ++ )
{
printf ( "%d " , a i );
}
printf ( "\n" );
return 0 ;
}
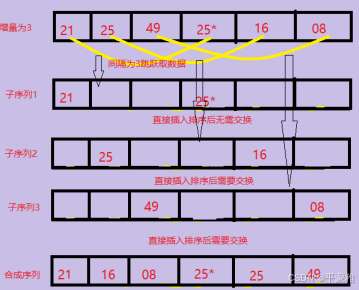
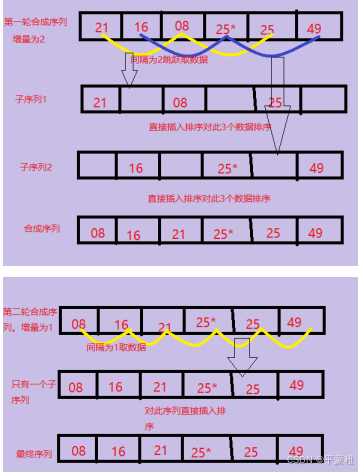
**5.**希尔排序
希尔排序( shell sort )这个排序方法又称为缩小增量排序。
思想:本质是插入排序,先使用较小的代价,让数据具备一定的顺序,然后再进行插入排序。先选取增量,根据增量把数组分成若干段,对每一段进行插入排序,使得数组有一定的顺序,然后再缩小增量,重复上述过程。最后以增量为1进行插入排序,确保数组是有序的。
不稳定排序
时间复杂度: O(n^k)(1.3 <= k <= 2) k 值取决于数据特性和增量的选取
希尔排序代码示例:
#include <stdio.h>
int main ()
{
int a 10 = { 34 , 45 , 78 , 98 , 45 , 2 , 5 , 8 , 4 , 213 };
int i , j ;
int cap ;
for ( cap = 3 ; cap >= 1 ; cap -- ) // 增量去 3 2 1 增量的变化没有固定的方法,但是最后一次增量必须是 1
{
// 里面的双重 for 循环是插入排序 将普通插入排序的 1 换成 cap ,因为普通的插入排序就是增量为 1 的排序
for ( i = cap ; i < 10 ; i ++ )
{
for ( j = i ; j >= cap ; j -= cap )
{
if ( a j >= a j - cap )
break ;
int t = a j ;
a j = a j - cap ;
a j - cap = t ;
}
}
}
for ( i = 0 ; i < 10 ; i ++ )
{
printf ( "%d " , a i );
}
printf ( "\n" );
return 0 ;
}
**6.**归并排序
思想:分治算法
- 分解:分解待排序的 n 个元素的序列成格局 n/2 个元素的两个子序列。
- 解决:使用归并排序递归的排序两个子序列。
- 合并:合并两个已排序的子序列以产生已排序的答案。
缺点:每次分解,都要创建新的存放分解后的数组。
在归的过程中排序,将两个有序数组合并成一个有序数组,时间复杂度是 O(N)
稳定排序
时间复杂度: T(N) = O(N*logN)
{34,45,78,98,45,2,5,8,4,213}

当划分到数组中只有一个元素的时候,开始 " 归 " ;在 " 归 " 的过程中将两个有序的数组合并成一个有序的数组
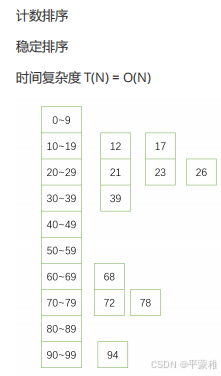
**7.**桶排序
思想:桶排序适用于比较均匀的数据。将数据区间划分成若干个相同大小的子区间,或称为桶。然后将 n 个数分别放入
各个桶中。对每个桶中的数据进行排序。排序过程中需要一个数组来存放链表(即桶)。
A = { 78 , 17 , 39 , 26 , 72 , 94 , 21 , 12 , 23 , 68 }
**8.**堆排序
1**)堆(优先队列)**
heap priority-queue
堆是一个完全二叉树,要求每个节点的值小于(或大于)它的所有子节点的值。
每个节点的值都小于它的子节点,叫小值堆。
每个节点的值都大于它的子节点,叫大值堆。
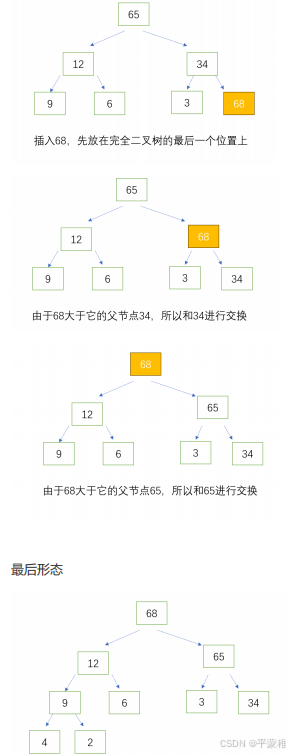
大值堆演示
{12,34,65,9,6,3,68,4,2}
上滤:
入队,插入一个数据先放在完全二叉树的最后一个位置上,如果插入的节点大于父节点就和父节点交换,重复这个过程。
下滤:
出队,根出队,然后把完全二叉树的最后一个位置的元素补的根的位置,然后跟较大的子节点比较,小于较大的子节
点就交换,重复这个过程。 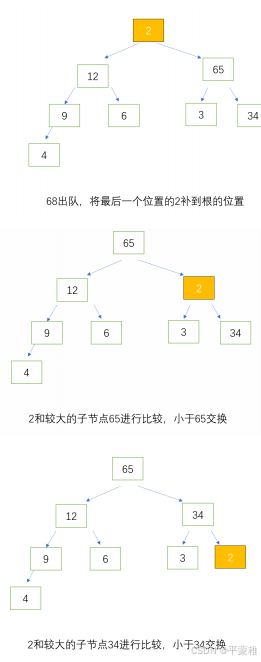
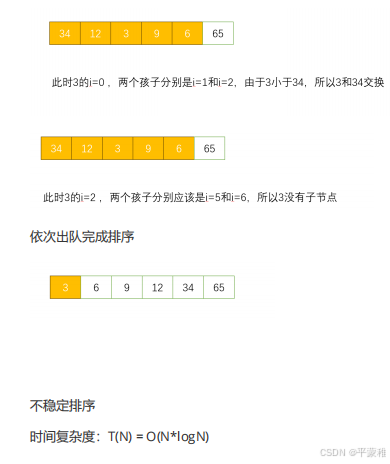
2**)堆排序**
先在数组内构建一个优先队列,以第一个元素作为原始的优先队列。然后逐一出队。
使用数组表示完全二叉树, i >= 0
i 的左孩子 2*i+1
i 的右孩子 2*i+2
i 的父节点 (i-1)/2
{12,34,65,9,6,3}

9.快速排序(必须会写)
不稳定排序 时间复杂度 O(N*logN)
- 分解:数组 Ap..r 被划分为两个(可能为空)子数组 Ap..q-1 和 Aq+1,,r ,使得 Ap..q-1 中的每个元素都小于 Aq ,
Aq+1,,r 中的每个元素都大于等于 Aq ,其中计算下标 q 也是划分过程的一部分。 - 解决:通过递归调用快速排序,对子数组 Ap..q-1 和 Aq+1,,r 进行排序。
- 合并:因为子数组都是原址排序的,所以不需要合并操作。
快速排序的最关键一步就是选取基准值,既 q 位置的值。
中值法选取基准值,选取最左,最右和中间三个值,取值在三个数字之间的数字作为基准。
基准值必须在数组中选取,无论如何选取基准值,要把基准值放在 0 位置。
{12,34,67,3,2,45,23,87,3,6}
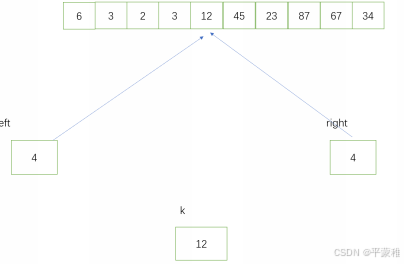
算法示例:
#include <stdio.h>
void quickSort ( int* arr , int left , int right );
int main ()
{
int a 10 = { 12 , 34 , 67 , 3 , 2 , 45 , 23 , 87 , 3 , 6 };
quickSort ( a , 0 , 9 );
int i ;
for ( i = 0 ; i < 10 ; i ++ )
{
printf ( "%d " , a i );
}
printf ( "\n" );
return 0 ;
}
void quickSort ( int* arr , int left , int right )
{
//left=right 说明范围内只有一个元素,不需要排序 left>right 是无效范围
if ( left >= right )
{
return ;
}
// 使用 localLeft 和 localRight 保存初始的范围,用来在递归的时候计算新的范围
int localLeft = left ;
int localRight = right ;
int k = arr left ; // 使用最简单的方式取基准值,使用最左边的首元素作为基准值
// 划分左右范围,将基准值放在中值位置,所以当 left=right 时就是中值的位置
while ( left < right )
{
// 先从右边找,循环内部要 right-- ,所以在这个循环中有可能出现 left=right
while ( left < right && arr right >= k )
{
right -- ;
}
// 上面循环结束有两种可能,要么 left=right ,这种情况就应该结束外层循环了
// 当 left < right 说明在右边遇到了小于基准值的值,那么这个值就应该放在左边位置上
if ( left < right )
{
arr left ++ = arr right ;
}
// 再从左边查找,循环内部要 left++ ,所以在这个循环中有可能出现 left=right
while ( left < right && arr left < k )
{
left ++ ;
}
// 上面循环结束有两种可能,要么 left=right ,这种情况就应该结束外层循环了
// 当 left < right 说明在左边遇到了大于等于基准值的值,那么这个值就应该放在右边位置上
if ( left < right )
{
arr right -- = arr left ;
}
}
// 循环结束的时候, left=right ,就是基准值应该在的位置
arr left = k ;
quickSort ( arr , localLeft , left - 1 ); // 向左边继续排序
quickSort ( arr , left + 1 , localRight ); // 向右边继续排序
}