导读:
人与数据的交互方式正在经历一场深刻的重构。云器Lakehouse始终坚信在AI驱动的自动化浪潮下:AI应被赋予更核心的能力。为了顺应这一趋势,继云器Lakehouse v1.3版本奠定AI语义层与存储层全面增强Iceberg生态双向集成能力,今天,云器Lakehouse Studio(v1.9.4) 正式推出MCP-Server------我们将AI可直接操作Lakhehouse的工具库扩充至45个,这意味着,我们进一步赋予AI Agent直接操作数据湖仓的"双手",让"对话式数据工程"从概念真正走向落地。
此外,本次更新还对AI交互的安全性与响应速度进行了深度优化,包括企业级的权限沙箱机制、针对LLM上下文优化的元数据压缩策略,以及对主流AI客户端(如Claude Desktop)的无缝兼容。
本文将逐一解读这些新特性,帮助读者全面了解云器Lakehouse 在"AI + Data"领域的最新技术升级与实践。
什么是 MCP Server?
MCP 协议简介
Model Context Protocol(MCP)是 Anthropic 推出的开放协议,旨在标准化AI模型与外部工具、数据源之间的交互方式。通过 MCP,AI Agent可以:
-
访问外部数据源:数据库、API、文件系统等
-
执行操作:创建任务、运行查询、管理资源
-
获取上下文:理解业务逻辑、表结构、依赖关系
云器 Lakehouse MCP-Server 的定位
云器 Lakehouse MCP-Server 是专为云器 Lakehouse 数据平台设计的 MCP 服务。 接入该服务后,您可以直接在第三方 AI Agent内通过输入自然语言的方式,直接操作产品功能,而无需关注过多的产品操作细节。
目前该服务提供了40+专业工具:覆盖 SQL 查询、任务创建、运维管理、数据质量多个场景。
快速开始:配置你的第一个 MCP Server
环境准备
推荐工具:
-
Claude Desktop:原生支持 MCP
-
Cherry Studio:开源 AI 客户端,支持 MCP 配置
前置要求:
-
云器 Lakehouse 账号及 Personal Access Token( PAT )
-
目标工作空间( Workspace )和项目( Project )的访问权限
-
Node.js 环境(用于运行 mcp-remote )
Claude Desktop 配置详解
步骤 1:定位配置文件
在 Claude Desktop 的 Settings 中找到 Local MCP servers 配置入口,点击 Edit Config 打开 claude_desktop_config.json 文件。
配置文件路径通常为:
-
macOS: ~/Library/Application Support/Claude/claude_desktop_config.json
-
Windows: %APPDATA%\Claude\claude_desktop_config.json
步骤 2:配置测试环境
在产品内,点击左下角个人信息「 Lakehouse MCP 」
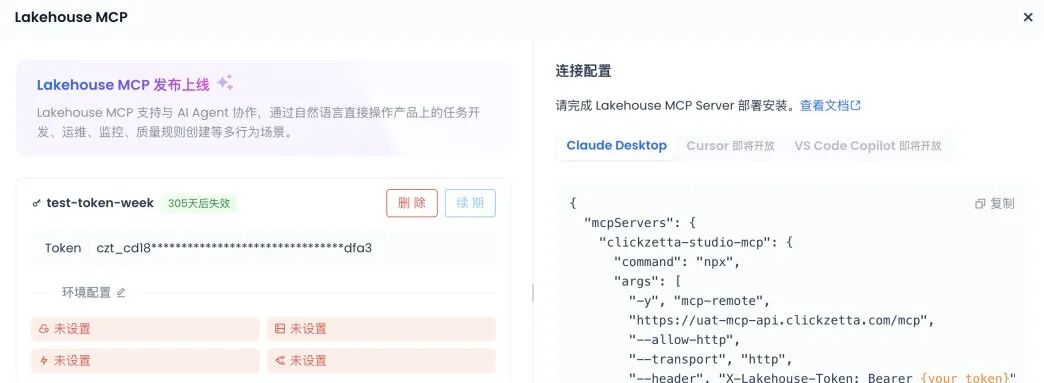
{
"clickzetta-http": {
"command": "npx",
"args": [
"-y", "mcp-remote",
"https://cn-shanghai-alicloud-mcp.clickzetta.com/mcp",
"--allow-http",
"--transport", "http",
"--header", "x-Lakehouse-Token: Bearer <your_pat>"
]
}
}Cherry Studio 配置
如果使用 Cherry Studio:
-
打开设置 → MCP → 点击添加服务器
-
配置如下:
-
名称:Clickzetta MCP
-
类型:可流式传输的 HTTP (streamableHttp)
-
请求头(每行一个):
x-Lakehouse-Token=Bearer <your_pat>
-
验证配置
重启 Claude Desktop 或 Cherry Studio,在对话框中输入:
列出当前工作空间中的所有文件夹如果返回文件夹列表,说明配置成功!
核心能力深度解析
场景一:AI驱动的Data Engineering
传统数据开发的"全链路困境"
在企业级数据仓库建设中,一个典型的"MySQL抽取 → ODS加工 → DWD建模"流程,往往让数据工程师陷入重复性劳动:
-
**手动配置数据集成:**在UI中逐个映射100+字段,处理BIGINT UNSIGNED等类型转换
-
**反复调试SQL逻辑:**编写几百行JOIN/聚合代码,在IDE中试运行验证
-
**复杂的调度编排:**梳理10+任务依赖关系,配置Cron表达式和参数宏
核心痛点:70%的时间消耗在"操作界面"和"重复配置",真正的业务逻辑思考只占30%。
云器 Lakehouse MCP Server 将这一流程简化为通过自然语言对话的方式实现:
案例1: 用户指令:
我要做一个离线同步的任务,目的是:"将 MySQL类型数据源下的 Taxi_data中tc_demo 库下的yellow_taxi_00 表同步到 LakeHouse 的 taxi_trip_analysis空间下的public.dwd_yellow_taxi 表中",同步方式为每天早上8点同步一次。
案例2: 用户指令:
将dwd_yellow_taxi表中支付类型 payment_type字段的值转化为文字(1-信用卡, 2-现金, 3-无收费, 4-争议),并在每天早上8点执行一次。"
场景二:智能运维与数据治理
传统运维的"救火困局"
在企业级数据平台中,运维团队每天面对数百个任务的运行状态,却常常陷入被动应对的循环:凌晨3点收到任务失败告警,需要在日志海洋中人工排查根因;修改一个核心任务的逻辑后,担心影响下游几十个依赖任务却无法快速评估影响范围;数据质量问题总是在下游任务失败或业务方投诉后才被发现;历史数据回填需要手动梳理时间范围和依赖任务,一旦遗漏就会引发连锁问题。
**核心痛点:**运维从"主动治理"退化为"被动救火",80%的时间消耗在问题定位和影响评估上。
云器 Lakehouse MCP Server提供AI驱动的主动式运维:
案例1:任务失败智能诊断
用户指令(运维工程师):
"任务75058685失败了,帮我诊断原因,同时告诉我影响了多少个下游任务。"
案例2:数据质量主动监控
用户指令:
"你是一个数据治理专家,现在要为 dwd_yellow_taxi 表建立质量监控规则,用以保障业务数据报表每天的产出的数值是正确无误的
场景三:交互式数据分析
传统分析的"翻译损耗":传统交互式分析往往要先围绕库表做一套语义层建设:口径对齐、维度建模、指标沉淀、权限配置与持续维护,人力成本很高、且迭代慢。云器 Lakehouse 通过自动构建语义层(Semantic View),把"从数据到可分析"的繁琐工程前置自动化,大幅缩短交付周期,让分析更敏捷、更可控。
核心能力:
-
构建语义层方式1:DataGPT
-
也可以通过 MCP Server,用自然语言构建语义视图。如请基于代理人维度表 dim_agent_info 和保单事实表 fact_policies 创建一个语义视图,用来回答保单相关的问题?同时可以基于 Snowflake 兼容的 YAML 格式文件创建 Semantic View,如 用这个yaml创建一个新的semantic view,改名叫tpch_sv_003
工具全景图(部分展示,持续更新中)
数据查询与探索
- execute_read_query:执行只读SQL查询(SELECT、DESCRIBE、SHOW、EXPLAIN等)
- execute_write_query:执行写操作SQL(INSERT/UPDATE/DELETE/CREATE/DROP等)
- list_data_sources:列出项目中所有可用数据源
- list_namespaces:列出数据源中的命名空间(schema/database)
- list_metadata_objects:列出命名空间中的数据对象(表/视图/集合)
- get_metadata_detail:获取数据对象的详细元数据(列名、类型、约束等)
任务管理
- create_task:创建新数据任务(SQL、Python、Shell、数据集成等)
- create_folder:创建文件夹用于组织任务
- list_folders:列出项目文件夹(支持过滤和分页)
- list_tasks:列出文件夹中的所有任务(包括草稿任务)
- get_task_detail:获取任务详细信息并返回Studio IDE链接
任务内容编辑
-
save_non_integration_task_content:保存SQL/Shell/Python等任务内容
-
save_integration_task_content:保存数据集成任务配置(源到目标同步)
-
recommend_integration_config:为50+种数据源生成完整集成配置
任务调度配置
-
save_task_configuration:保存调度配置(依赖、重试、超时、调度信息等)
-
submit_task:提交任务到调度系统(需用户确认)
任务执行与监控
-
execute_task:异步执行数据任务并自动轮询状态
-
get_task_instance_detail:获取任务实例执行状态和详情
-
list_schedule_task_instance:列出任务实例(支持过滤和分页)
-
list_execution_records:列出任务实例的执行记录
-
get_execution_log_content:获取执行日志内容
任务依赖分析
-
get_schedule_task_relation:获取调度任务的上下游依赖关系树
-
get_task_instance_relation:获取任务实例的上下游依赖关系树
补数任务管理
-
list_backfill_tasks:列出补数(backfill)任务
-
list_backfill_instances:列出补数任务关联的实例
-
get_backfill_task_detail:获取补数任务详细信息
数据质量检查
- create_dqc_rule:创建DQC规则(支持手动/定时/任务关联触发)
语义视图
-
create_semantic_view:从YAML定义创建语义视图
-
desc_semantic_view:以YAML格式返回语义视图定义
-
query_semantic_view:使用指标、维度、过滤条件查询语义视图
-
answer_question_with_semantic_view:根据自然语言问题查询语义视图
-
generate_and_execute_semantic_view_query:执行语义视图查询(接收JSON参数)
-
add_dimensions_to_semantic_view:向语义视图添加新维度
-
remove_dimensions_from_semantic_view:从语义视图删除维度
-
add_tables_to_semantic_view:向语义视图添加新表
-
index_semantic_view_meta:为语义视图元数据创建向量索引
-
index_semantic_view_sample_values:为示例值创建倒排索引
-
check_semantic_view_status:检查语义视图及索引状态
-
drop_semantic_view_index:删除语义视图索引
访问云器官网,可直接试用体验![]() http://https://www.yunqi.tech/?hmsr=CSDN&hmpl=&hmcu=&hmkw=&hmci=更多内容,欢迎关注「云器科技」官网!
http://https://www.yunqi.tech/?hmsr=CSDN&hmpl=&hmcu=&hmkw=&hmci=更多内容,欢迎关注「云器科技」官网!
云器科技-多云及一体化数据平台提供
