5.1 多目标模型
5.1.1 用户-笔记的交互
点击率=点击次数/曝光次数
点赞率=点赞次数/点击次数
收藏率=收藏次数/点击次数
转发率=转发次数/点击次数
5.1.2 排序的依据
- 排序模型预估点击率、点赞率、收藏率、转发率等多种分数;
- 融合这些预估分数(如加权和),根据融合后的分数做排序、截断。
5.1.3 多目标模型
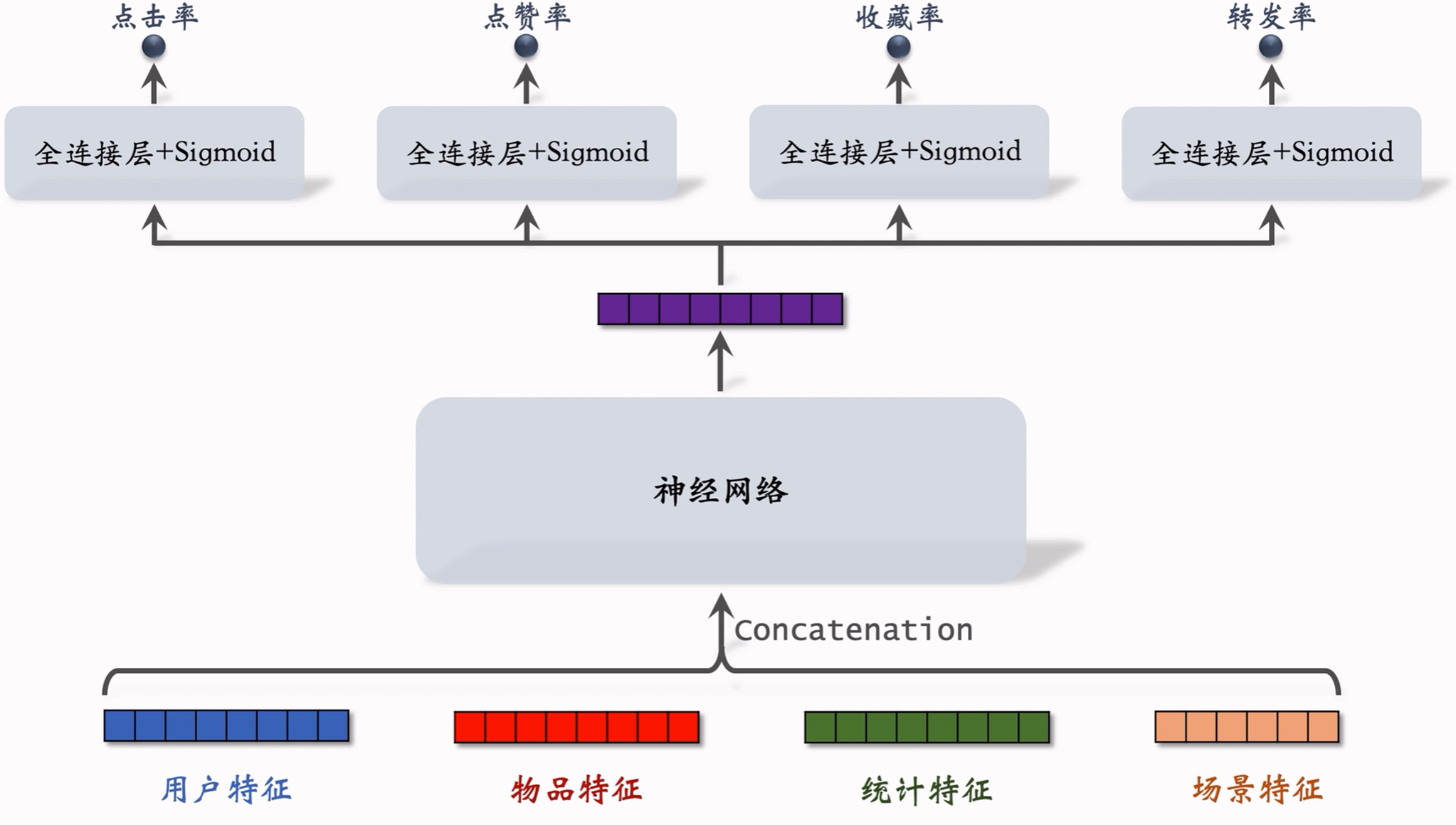
排序模型的输入是多种特征:
- 用户特征:用户ID和用户画像;
- 物品特征:物品ID、物品画像和作者信息;
- 统计特征:用户统计特征(如给用户曝光了多少篇笔记,用户点击了多少篇,点赞了多少篇等)、物品统计特征(获得了多少次曝光机会,获得了多少次点击、点赞等);
- 场景特征:随请求传入,包含用户所在的时间和地点等。

训练时,预估的 p 1 , ⋯ , p 4 p_1,\cdots,p_4 p1,⋯,p4的取值范围为 0 , 1 0,1 0,1;目标的 y 1 , ⋯ , y 4 y_1,\cdots,y_4 y1,⋯,y4的取值范围为0或1(只有两种状态)。采用交叉熵损失进行训练,总损失函数为:
∑ i = 1 4 α i ⋅ CrossEntropy ( y 1 , p i ) \sum_{i=1}^4 \alpha_i\cdot\text{CrossEntropy}(y_1,p_i) i=1∑4αi⋅CrossEntropy(y1,pi)
其中权重 α \alpha α根据经验设置。
5.1.4 负样本过多问题
实际训练过程中,负样本数量很大,需要对负样本进行降采样:
- 保留一小部分负样本;
- 让正负样本数量平衡,节约计算。
5.1.5 预估值校准
由5.1.4节得知,对负样本进行了降采样,负样本变少,预估点击率会大于真实点击率。
- 正样本、负样本数量为 n + n_+ n+和 n − n_- n−;
- 使用 α ⋅ n − \alpha\cdot n_- α⋅n−个负样本, α ∈ ( 0 , 1 ) \alpha\in(0,1) α∈(0,1)是采样率。
真实点击率:
p true = n + n + + n − p_\text{true}=\frac{n_+}{n_++n_-} ptrue=n++n−n+
预估点击率:
p pred = n + n + + α ⋅ n − p_\text{pred}=\frac{n_+}{n_++\alpha\cdot n_-} ppred=n++α⋅n−n+
由上面两个式子推导得到:
p true = α ⋅ p pred ( 1 − p pred ) + α ⋅ p pred p_\text{true}=\frac{\alpha\cdot p_\text{pred}}{(1-p_\text{pred})+\alpha\cdot p_\text{pred}} ptrue=(1−ppred)+α⋅ppredα⋅ppred
5.2 Multi-gate Mixture-of-Experts (MMoE)
5.2.1 模型结构
5.2.1.1 下层结构
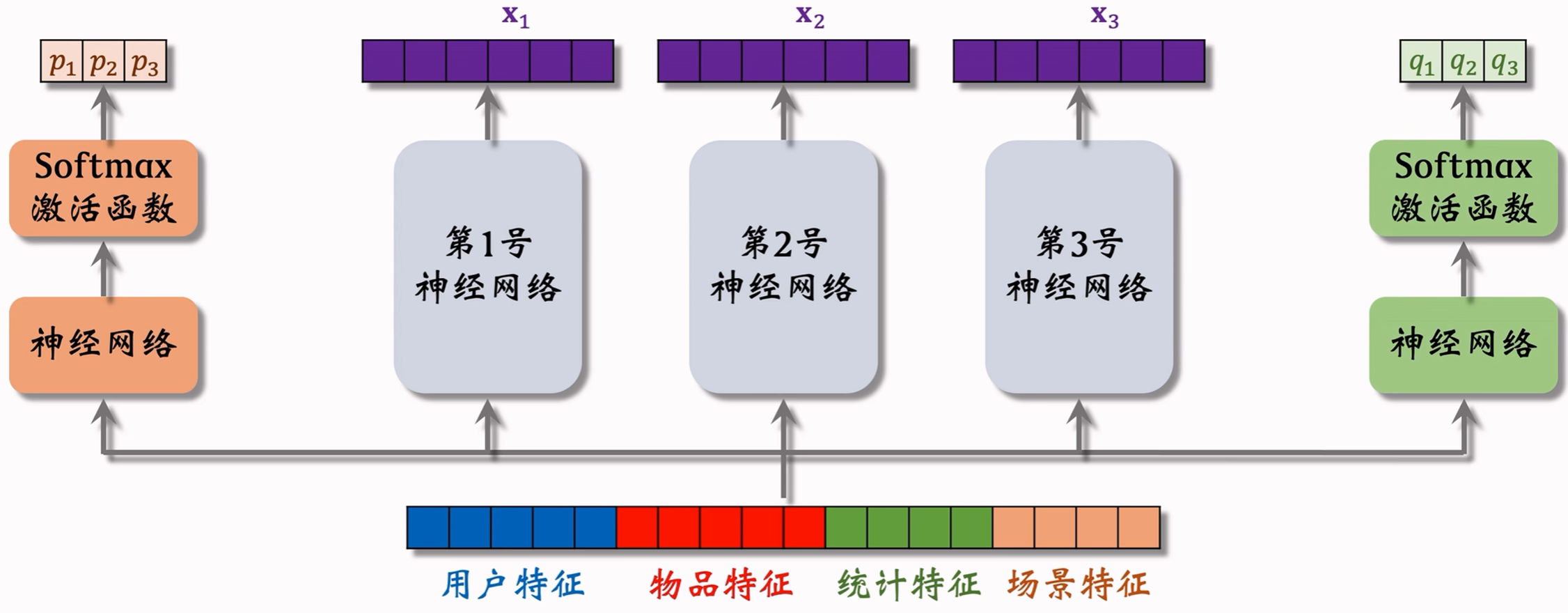
注:图中为了展示方便,放了3个专家神经网络,实践中通常尝试4个或8个。专家神经网络的数量是MMoE的一个超参数。
5.2.1.2 上层结构
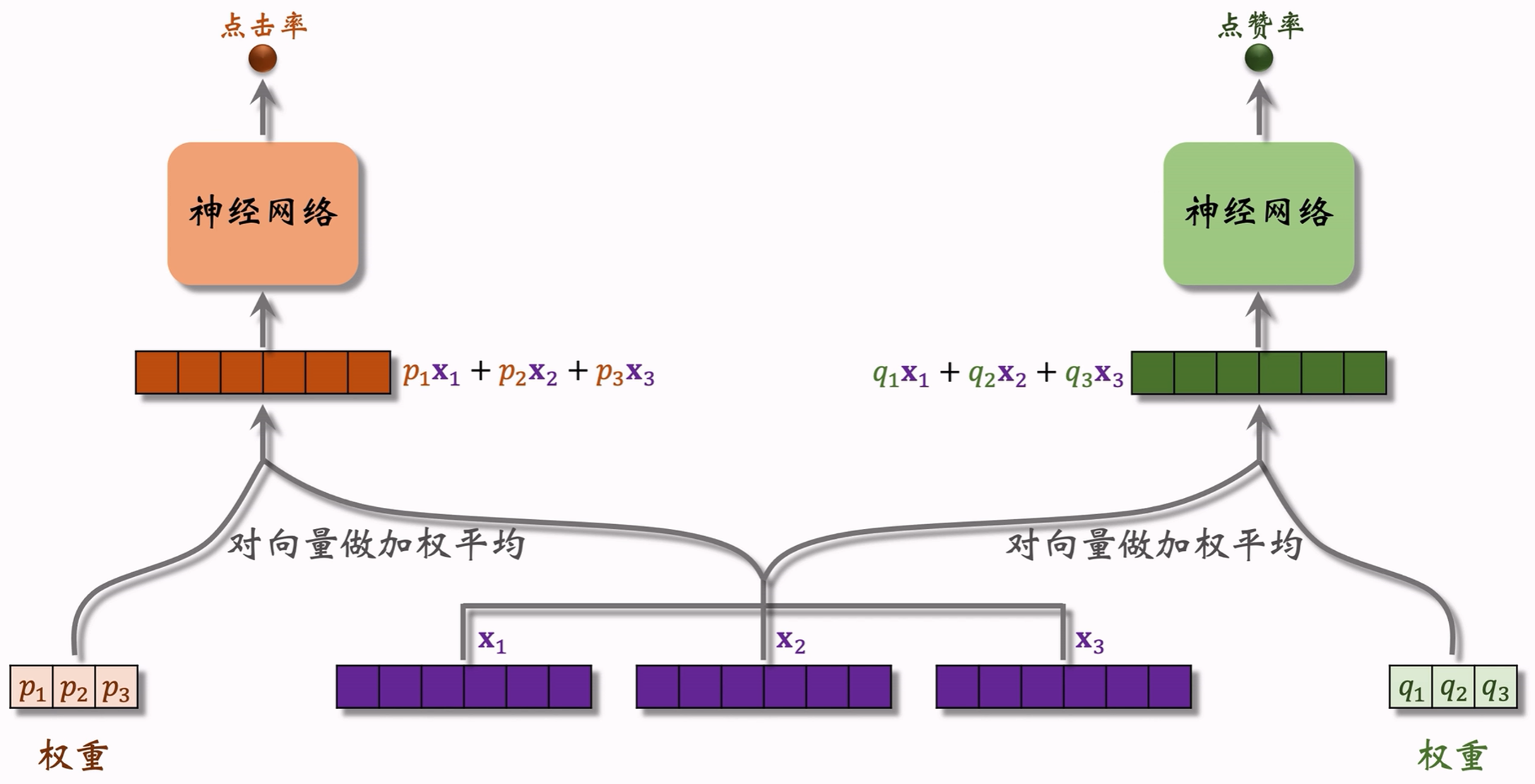
注: p 1 , p 2 , p 3 p_1,p_2,p_3 p1,p2,p3和 q 1 , q 2 , q 3 q_1,q_2,q_3 q1,q2,q3是两组用于对 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3加权平均的权重。加权平均的权重的组数等于多目标模型的目标个数(如点击率、点赞率),详见5.2.1.2节。
5.2.2 极化现象
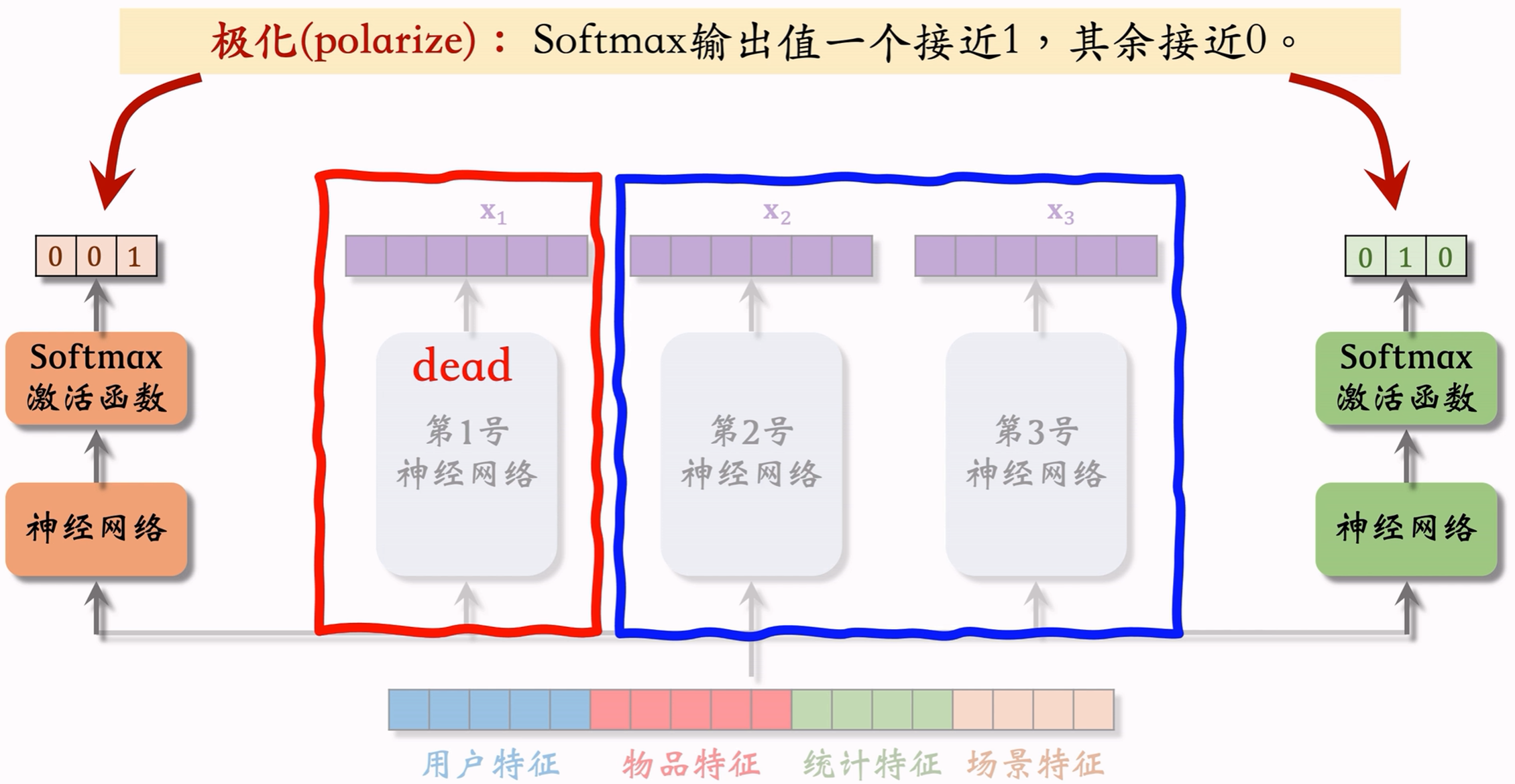
解决方法:
- 如果有 n n n个专家,那么每个softmax的输入和输出都是 n n n维向量;
- 训练时,对softmax的输出使用dropout,softmax输出的 n n n个数值被mask的概率都是10%,即每个专家被随机丢弃的概率都是10%;
- dropout可以避免模型训练时过度依赖某个专家。
5.3 融合预估分数
5.3.1 简单的加权和
p click + w 1 p like + w 2 p collect + ⋯ p_\text{click}+w_1p_\text{like}+w_2p_\text{collect}+\cdots pclick+w1plike+w2pcollect+⋯
5.3.2 点击率乘以其他项的加权和
p click ⋅ ( 1 + w 1 p like + w 2 p collect + ⋯ ) p_\text{click}\cdot (1+w_1p_\text{like}+w_2p_\text{collect}+\cdots) pclick⋅(1+w1plike+w2pcollect+⋯)
思路:由于 p click p_\text{click} pclick=点击/曝光, p like p_\text{like} plike=点赞/点击,......
通过把点击率乘在外面,使得其他项的点击被消除,剩下了点赞/曝光。
5.4 视频播放建模
5.4.1 图文vs视频
图文笔记排序的主要依据:点击、点赞、收藏、转发、评论......
视频排序的依据还有播放时长 和完播 。
直接回归拟合播放时长效果不好。
5.4.2 视频播放时长建模
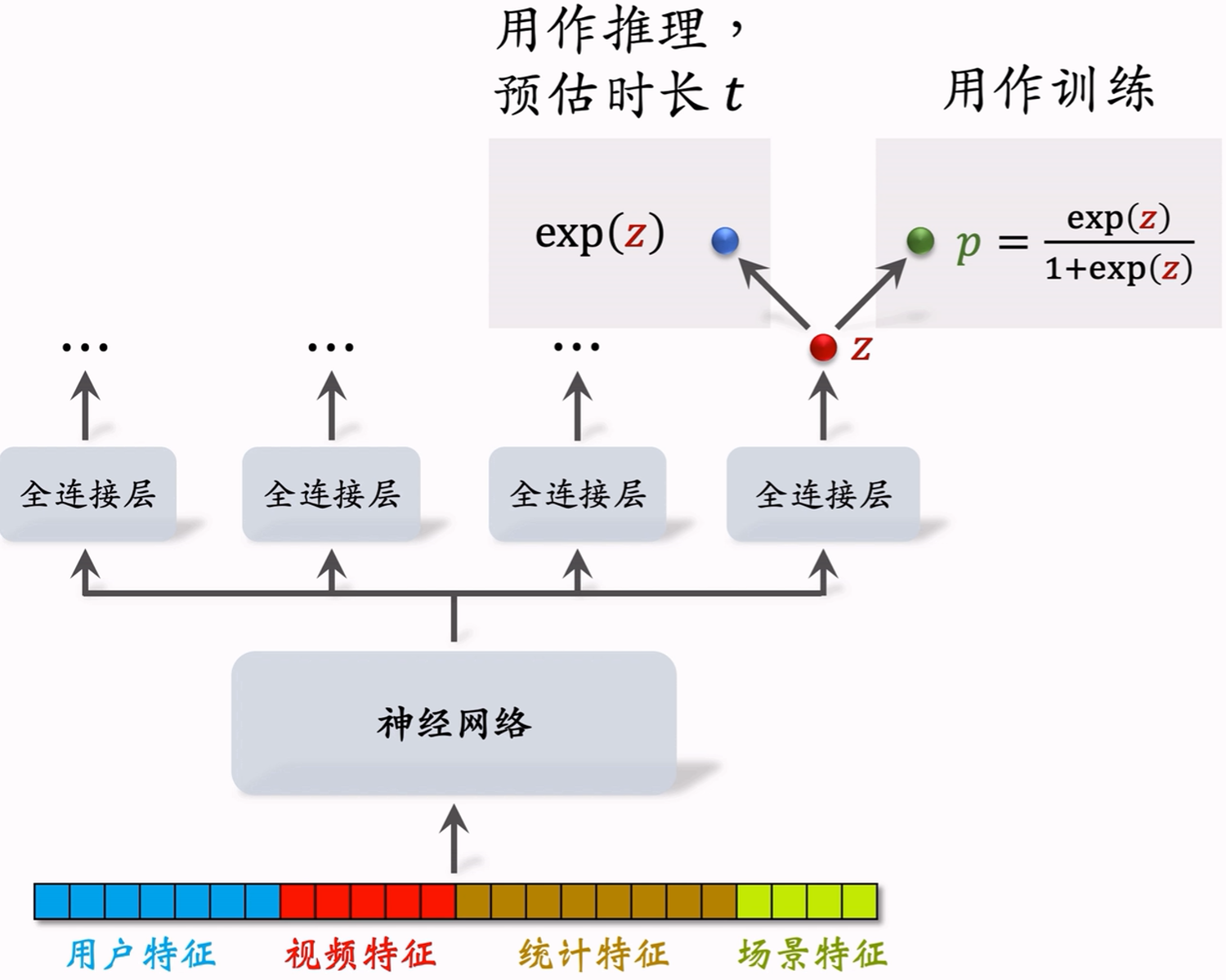
把最后一个全连接层的输出记作 z z z,设 p = sigmoid ( z ) p=\text{sigmoid}(z) p=sigmoid(z)。
实际观测的播放时长记作 t t t,如果用户没有点击视频,则 t = 0 t=0 t=0。
训练时,目标值为 y = t 1 + t y=\frac{t}{1+t} y=1+tt,输出值 z z z做sigmoid后为 p = exp ( z ) 1 + exp ( z ) p=\frac{\exp(z)}{1+\exp(z)} p=1+exp(z)exp(z),目标是让 p p p拟合 y y y,用交叉熵损失:
CE ( y , p ) = y ⋅ log p + ( 1 − y ) ⋅ log ( 1 − p ) \text{CE}(y,p)=y\cdot\log p+(1-y)\cdot\log(1-p) CE(y,p)=y⋅logp+(1−y)⋅log(1−p)
由于我们尝试用 p p p拟合 y y y,因此 exp ( z ) \exp(z) exp(z)就是拟合的播放时长 t t t,将 exp ( z ) \exp(z) exp(z)作为融合预估分数中的一项,从而影响视频的排序。
5.5 视频完播
5.5.1 回归方法
例:视频长度10分钟,实际播放4分钟,则实际播放率为 y = 0.4 y=0.4 y=0.4。
令预估播放率 p p p拟合 y y y,损失函数为:
L = y ⋅ log p + ( 1 − y ) ⋅ log ( 1 − p ) L=y\cdot \log p+(1-y)\cdot \log (1-p) L=y⋅logp+(1−y)⋅log(1−p)
线上预估完播率,模型输出 p = 0.73 p=0.73 p=0.73时,意思是预计完播73%。
5.5.2 二元分类方法
定义完播指标,比如完播80%,那么播放>80%的作为正样本,播放<80%的作为负样本,然后做二元分类模型。
线上预估完播率,模型输出 p = 0.73 p=0.73 p=0.73,意思是
P ( 播放>80% ) = 0.73 P(\text{播放>80\%})=0.73 P(播放>80%)=0.73
5.5.3 融合预估分数中的完播率
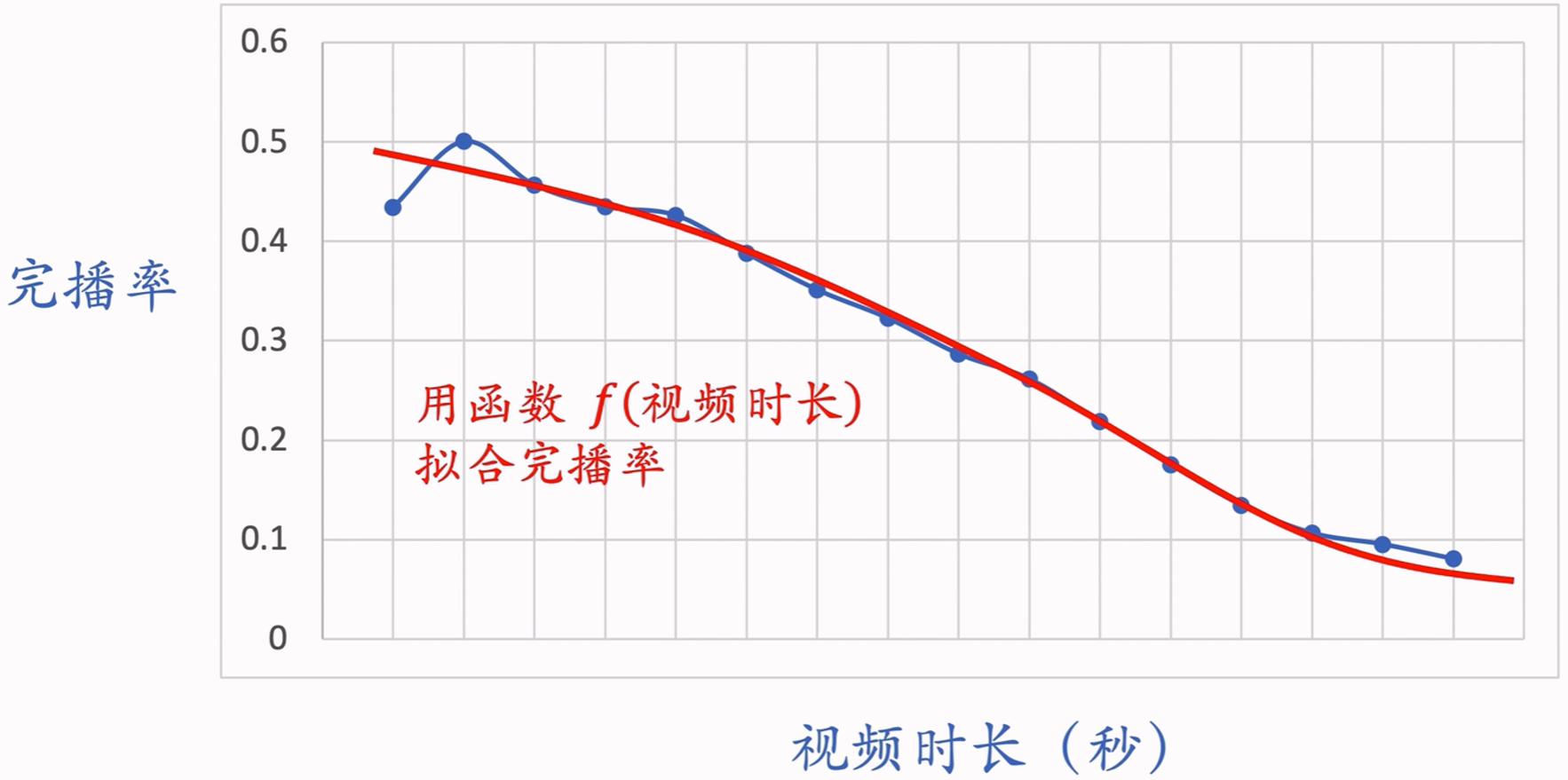
如图所示,视频越长完播率越低,因此不能直接把预估的完播率用到融分公式。
线上预估完播率后,做调整:
p finish = 预估完播率 f ( 视频长度 ) p_\text{finish}=\frac{\text{预估完播率}}{f(\text{视频长度})} pfinish=f(视频长度)预估完播率
预估完播率是通过用户、物品等很多信息预测出的一个完播率的估计值,而 f ( 视频长度 ) f(\text{视频长度}) f(视频长度)是一个只与视频长度有关的拟合函数。
p finish p_\text{finish} pfinish可以作为融分公式中的一项。