这篇文中主要提出了一种利用多尺度图像构建约束方程从而直接求解视差的框架,而不是像其他密集匹配算法进行相似性度量下进行赢者通吃匹配。并且这种框架是天然兼容大多数代价计算方式的。代码开源:https://github.com/rookiepig/CrossScaleStereo
摘要
人类通过多个尺度处理立体对应。然而,这种生物启发被用于密集立体对应的最先进的代价聚合方法所忽略。本文提出了一种通用的跨尺度代价聚合框架,允许在代价聚合中进行多尺度交互。我们首先从一个统一的优化角度重新表述代价聚合,并表明不同的代价聚合方法本质上在于相似性核的选择不同。然后,将尺度间正则项引入优化中,求解这个新的优化问题即得到所提出的框架。由于正则化项独立于相似性核,各种代价聚合方法都可以集成到所提出的通用框架中。我们表明,跨尺度框架很重要,因为它有效且高效地扩展了最先进的代价聚合方法,并在 Middlebury、KITTI 和 New Tsukuba 数据集上评估时带来了显著的改进。
1. 引言
两幅图像之间的密集对应是计算机视觉中的一个关键问题 12。加上两幅图像是同一场景的立体对这一约束,密集对应问题就简化为立体匹配问题 23。立体匹配算法通常包含四个步骤:代价计算、代价(支持)聚合、视差计算和视差优化 23。在代价计算中,通过为每个像素在所有可能的视差级别计算匹配代价来生成一个 3D 代价体积(也称为视差空间图像 23)。在代价聚合中,代价在每个像素的支持区域上进行聚合,以强制视差的片段恒定。然后,使用局部或全局优化方法计算每个像素的视差,并在最后两个步骤中分别通过各种后处理方法进行优化。在这些步骤中,代价聚合的质量对立体算法的成功有显著影响。它是最先进的局部算法 36, 21, 33, 16 的关键组成部分,也是某些表现最佳的全局算法 34, 31 的主要构建模块。因此,在本文中,我们主要关注代价聚合。
大多数代价聚合方法可以看作是联合滤波在代价体积上的应用 21。实际上,即使是简单的线性图像滤波器,如盒式滤波器或高斯滤波器,也可以用于代价聚合,但作为各向同性扩散滤波器,它们往往会模糊深度边界 23。因此,许多保边滤波器,如双边滤波器 28 和
引导图像滤波器 7 被引入用于代价聚合。Yoon 和 Kweon 36 在代价聚合中采用了双边滤波器,在 Middlebury 数据集 23 上生成了吸引人的视差图。然而,他们的方法计算量大,因为为了实现高视差精度,通常需要使用大的核尺寸(例如 35×3535 \times 3535×35 )。为了解决双边滤波器的计算限制,Rhemann 等人 21 将引导图像滤波器引入代价聚合,其计算复杂度与核大小无关。最近,Yang 33 提出了一种非局部代价聚合方法,将核大小扩展到整个图像。通过在图像图上计算最小生成树,可以非常快地执行非局部代价聚合。Mei 等人 16 遵循了非局部代价聚合的思想,并表明通过使用分段树而不是 MST 来强制视差一致性,可以获得比 33 更好的视差图。
所有这些最先进的代价聚合方法都为立体视觉做出了巨大贡献。这些方法的一个共同特性是,代价是在输入立体图像的最精细尺度上聚合的。然而,人类通常通过多个尺度处理立体对应 17, 15, 14。根据 14,在人类立体视觉系统的对应搜索中,粗尺度和精细尺度的信息是交互处理的。因此,从这种生物启发来看,代价应该在多个尺度上进行聚合,而不是像传统方法那样只在最精细尺度上进行(图 1),这是合理的。
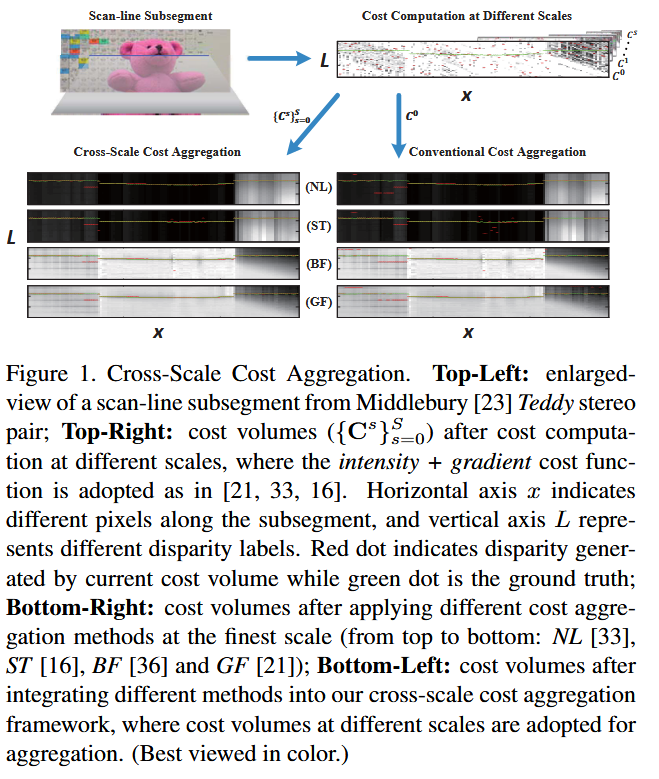
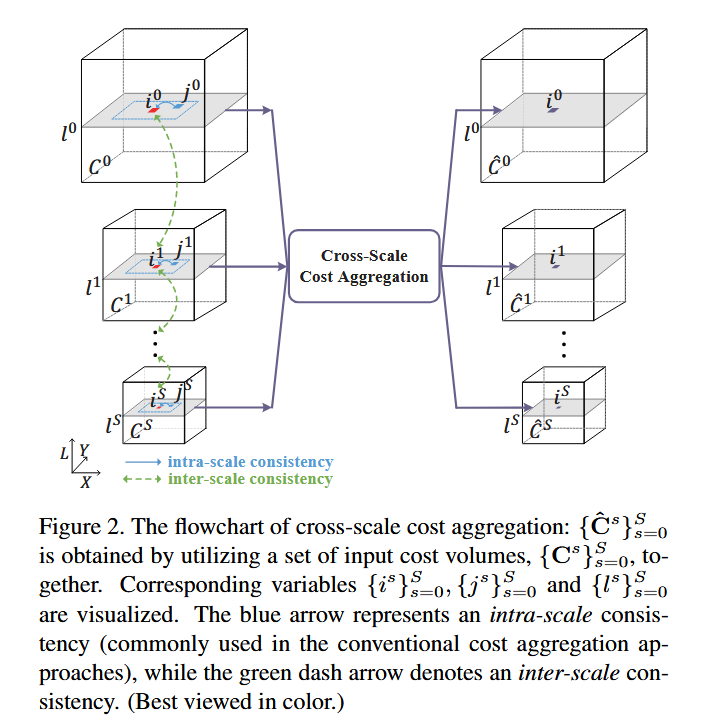
本文提出了一个通用的跨尺度代价聚合框架。首先,受 18 中图像滤波器公式化的启发,我们表明各种代价聚合方法可以统一表述为加权最小二乘优化问题。然后,从这个统一的优化角度出发,通过将广义 Tikhonov 正则化项添加到 WLS 优化目标中,我们强制了代价体积在相邻尺度之间的一致性,即尺度间一致性。带有尺度间正则化的新优化目标是凸的,可以轻松解析求解。由于代价体积的尺度内一致性仍由传统的代价聚合方法保持,因此许多方法都可以集成到我们的框架中,以生成更稳健的代价体积和更好的视差图。图 1 展示了所提框架的效果。四种代表性代价聚合方法的代价体积切片被可视化,包括非局部方法 33 、分段树方法 16 、双边滤波方法 36 和引导滤波方法 21 。我们用红点表示在每个代价体积中通过局部胜者全取优化生成的视差,用绿点表示真实视差。可以发现,通过采用跨尺度代价聚合,产生了更稳健的代价体积和更准确的视差。在 Middlebury 23、KITTI 4 和 New Tsukuba 20 数据集上的大量实验也表明,使用跨尺度代价聚合可以获得更好的视差图。总之,本文的贡献有三个方面:
通过采用跨尺度代价聚合产生的。在 Middlebury 23、KITTI 4 和 New Tsukuba 20 数据集上的大量实验也表明,使用跨尺度代价聚合可以获得更好的视差图。总之,本文的贡献有三个方面:
1.从优化角度对各种代价聚合方法进行统一的 WLS 公式化。
2.一个新颖且有效的跨尺度代价聚合框架。
3.在三个数据集上对代表性代价聚合方法进行定量评估。
本文的其余部分组织如下。第 2 节总结了相关工作。第 3 节给出了代价聚合的 WLS 公式。我们的尺度间正则化在第 4 节中描述。然后我们在第 5 节详细介绍了我们框架的实现。最后,实验结果和分析在第 6 节给出,结论性意见在第 7 节提出。
2. 相关工作
最近的综述 9, 29 对各种代价聚合方法进行了充分的比较和分析。我们建议读者查阅这些综述以了解不同代价聚合方法的概述,我们将重点讨论涉及多尺度信息的立体匹配方法,这些方法与我们的想法非常相关但存在实质性差异。
早期的立体视觉研究者采用由粗到精的策略进行立体匹配 15。首先分配粗分辨率的视差,然后使用较粗的视差来减少计算较精细视差的搜索空间。这种 CTF(分层)策略已广泛应用于全局立体方法中,例如动态规划 30、半全局匹配 25 和置信传播 3, 34,目的是加速收敛并避免意外的局部最小值。不仅全局方法,局部方法也采用 CTF 策略。与全局立体方法不同,在局部立体方法中采用 CTF 策略的主要目的是减少搜索空间 35, 11, 10 或利用多尺度相关的图像表示 26, 27。然而,在局部 CTF 方法中有一个例外。Min 和 Sohn 19 通过各向异性扩散对代价聚合进行建模,并通过多尺度方法高效求解了所提出的变分模型。他们模型的动机是去噪代价体积,这与我们非常相似,但我们的方法通过正则化强制了代价体积的尺度间一致性。
总的来说,大多数 CTF 方法都有一个相似的特性。它们显式或隐式地模拟了尺度空间中的视差演化过程 27,即跨多个尺度的视差一致性。与以前的 CTF 方法不同,我们的方法模拟了代价体积在尺度空间中的演化,即跨多个尺度的代价体积一致性。从优化的角度来看,CTF 方法缩小了解空间,而我们的方法没有改变解空间,而是将尺度间正则化添加到优化目标中。因此,通过正则化融入多尺度先验是我们方法的独创性。另一点值得一提的是,局部 CTF 方法的性能并不优于最先进的代价聚合方法 10, 11,而我们的方法可以显著改进那些代价聚合方法 21, 33, 16。
3. 作为优化的代价聚合
在本节中,我们表明代价聚合可以表述为一个加权最小二乘优化问题。在此公式下,优化目标中相似性核 18 的不同选择导致了不同的代价聚合方法。
首先,代价计算步骤被表述为一个函数 f :RW×H×3×RW×H×3↦RW×H×Lf\colon \mathbb{R}^{W\times H\times 3}\times \mathbb{R}^{W\times H\times 3}\mapsto \mathbb{R}^{W\times H\times L}f:RW×H×3×RW×H×3↦RW×H×L,其中 WWW、HHH 是输入图像的宽度和高度,3 代表颜色通道,LLL 表示视差级别的数量。因此,对于一个立体彩色对:I,I′∈RW×H×3\mathbf{I},\mathbf{I}^{\prime}\in \mathbb{R}^{W\times H\times 3}I,I′∈RW×H×3,通过应用代价计算:
C=f(I,I′),(1) \mathbf{C} = f(\mathbf{I},\mathbf{I}^{\prime}), \quad (1) C=f(I,I′),(1)
我们可以得到代价体积 C∈RW×H×L\mathbf{C}\in \mathbb{R}^{W\times H\times L}C∈RW×H×L,它表示每个像素在所有可能视差级别上的匹配代价。对于单个像素 i=(xi,yi)i = (x_{i},y_{i})i=(xi,yi),其中 xi,yix_{i},y_{i}xi,yi 是像素位置,其在视差级别 lll 的代价可以表示为一个标量,C(i,l)\mathbf{C}(i,l)C(i,l)。可以使用各种方法来计算代价体积。例如,强度+梯度代价函数 21, 33, 16 可以表述为:
C(i,l)=(1−α)⋅min(∥I(i)−I′(i)∥,τ1)+α⋅min(∥∇xI(i)−∇xI′(i)∥,τ2).(2) \begin{array}{rcl}{\mathbf{C}(i,l)} & = & {(1 - \alpha)\cdot \min (\| \mathbf{I}(i) - \mathbf{I}^{\prime}(i)\| ,\tau_1)}\\ {} & {} & {+\alpha \cdot \min (\| \nabla_x\mathbf{I}(i) - \nabla_x\mathbf{I}^{\prime}(i)\| ,\tau_2).} \end{array} \quad (2) C(i,l)=(1−α)⋅min(∥I(i)−I′(i)∥,τ1)+α⋅min(∥∇xI(i)−∇xI′(i)∥,τ2).(2)
这里 I(i)\mathbf{I}(i)I(i) 表示像素 iii 的颜色向量。∇x\nabla_{x}∇x 是 xxx 方向上的灰度梯度。ili_{l}il 是像素 iii 对应视差 lll 的像素,即 il=(xi−l,yi)i_{l} = (x_{i} - l,y_{i})il=(xi−l,yi)。α\alphaα 平衡了颜色项和梯度项,τ1,τ2\tau_{1},\tau_{2}τ1,τ2 是截断值。
代价体积 C\mathbf{C}C 通常噪声很大(图 1)。受去噪问题 WLS 公式 18 的启发,代价聚合可以用噪声输入 C\mathbf{C}C 表述为:
C~(i,l)=argminz1Zi∑j∈NiK(i,j)∥z−C(j,l)∥2,(3) \tilde{\mathbf{C}} (i,l) = \arg \min_{z}\frac{1}{Z_{i}}\sum_{j\in N_{i}}K(i,j)\| z - \mathbf{C}(j,l)\|^{2}, \quad (3) C~(i,l)=argzminZi1j∈Ni∑K(i,j)∥z−C(j,l)∥2,(3)
其中 NiN_{i}Ni 定义了 iii 的邻域系统。K(i,j)K(i,j)K(i,j) 是相似性核 18,用于衡量像素 iii 和 jjj 之间的相似性,C~\tilde{\mathbf{C}}C~ 是(去噪后的)代价体积。Zi=∑j∈NiK(i,j)Z_{i} = \sum_{j\in N_{i}}K(i,j)Zi=∑j∈NiK(i,j) 是一个归一化常数。这个 WLS 问题的解是:
C~(i,l)=1Zi∑j∈NiK(i,j)C(j,l).(4) \tilde{\mathbf{C}} (i,l) = \frac{1}{Z_i}\sum_{j\in N_i}K(i,j)\mathbf{C}(j,l). \quad (4) C~(i,l)=Zi1j∈Ni∑K(i,j)C(j,l).(4)
因此,就像图像滤波器 18 一样,一种代价聚合方法对应于相似性核的一个特定实例。例如,BFBFBF 方法 36 采用了两个像素之间的空间和光度距离来衡量相似性,这与双边滤波器 28 中使用的核函数相同。Rhemann 等人 21 采用了引导滤波器 7 中定义的核,其计算复杂度与核大小无关。NLNLNL 方法 33 定义了一个基于树结构中两个像素之间测地距离的核。这种方法通过利用颜色分割得到了进一步增强,称为分段树方法 16。基于滤波器 36, 21 和基于树 33, 16 的聚合方法之间的主要区别在于相似性核的作用范围,即公式 (4) 中的 NiN_{i}Ni。在基于滤波器的方法中,NiN_{i}Ni 是一个以 iii 为中心的局部窗口,但在基于树的方法中,NiN_{i}Ni 是整个图像。图 1 可视化了不同作用范围的效果。基于滤波器的方法在代价聚合后保持了一些局部相似性,而基于树的方法往往在代价体积的不同区域之间产生硬边缘。
在展示了代表性代价聚合方法可以在统一框架内进行公式化之后,让我们重新检查图 1 中的代价体积切片。该切片来自 Middlebury 数据集 24 中的 Teddy 立体对,包含三个典型场景:低纹理、高纹理和近无纹理区域(从左到右)。这四种最先进的代价聚合方法在高纹理区域都表现得非常好,但大多数在低纹理或近无纹理区域都失败了。为了在那些低纹理和近无纹理区域产生高度准确的对应,应该在粗尺度上进行对应搜索 17。然而,在公式 (3) 下,代价总是在最精细尺度上聚合,这使得不可能自适应地利用来自多个尺度的信息。因此,我们需要从尺度空间的角度重新表述 WLS 优化目标。
4. 跨尺度代价聚合框架
很容易证明,直接使用公式 (3) 来处理多尺度代价体积等价于在每个尺度上分别执行代价聚合 。首先,我们给 C\mathbf{C}C 加上上标 sss,表示立体对不同尺度的代价体积,记为 Cs\mathbf{C}^sCs,其中 s∈{0,1,...,S}s \in \{0, 1, \ldots , S\}s∈{0,1,...,S} 是尺度参数。C0\mathbf{C}^0C0 表示最精细尺度的代价体积。多尺度代价体积 Cs\mathbf{C}^sCs 是使用下采样因子为 ηs\eta^sηs 的下采样图像计算的。请注意,这种方法也减少了视差的搜索范围。公式 (3) 的多尺度版本可以很容易地表达为:
v~=argmin{zs}s=0S∑s=0S1Ziss∑js∈NisK(is,js)∥zs−Cs(js,ls)∥2.(5) \tilde{\mathbf{v}} = \underset {\{z^s\}{s = 0}^S}{\arg \min}\sum{s = 0}^{S}\frac{1}{Z_{i^s}^s}\sum_{j^s\in N_{i^s}}K(i^s,j^s)\| z^s -{\bf C}^s (j^s,l^s)\| ^2. \quad (5) v~={zs}s=0Sargmins=0∑SZiss1js∈Nis∑K(is,js)∥zs−Cs(js,ls)∥2.(5)
这里,Ziss=∑js∈NisK(is,js)\begin{array}{r}Z_{i^s}^s = \sum_{j^s\in N_{i^s}}K(i^s,j^s) \end{array}Ziss=∑js∈NisK(is,js) 是一个归一化常数。{is}s=0S\{i^s\}{s = 0}^S{is}s=0S 和 {ls}s=0S\{l^s\}{s = 0}^S{ls}s=0S 表示每个尺度上的一系列对应变量(图 2),即 is+1=is/ηi^{s + 1} = i^{s} / \etais+1=is/η 和 ls+1=ls/ηl^{s + 1} = l^{s} / \etals+1=ls/η。NisN_{i^s}Nis 是第 sss 尺度上的一组相邻像素。在我们的工作中,NisN_{i^s}Nis 的大小对所有尺度保持不变,这意味着在更粗的尺度上实施了更大程度的平滑。我们使用向量 v~=C\~0(i0,l0),C\~1(i1,l1),...,C\~S(iS,lS)T\tilde{\mathbf{v}} = \\tilde{\\mathbf{C}}\^0 (i\^0,l\^0),\\tilde{\\mathbf{C}}\^1 (i\^1,l\^1),\\dots ,\\tilde{\\mathbf{C}}\^S (i\^S,l\^S)^Tv~=C\~0(i0,l0),C\~1(i1,l1),...,C\~S(iS,lS)T(具有 S+1S + 1S+1 个分量)来表示每个尺度上的聚合代价。公式 (5) 的解是通过在每个尺度上独立执行代价聚合得到的,如下所示:
∀s,C~s(is,ls)=1Ziss∑js∈NisK(is,js)Cs(js,ls).(6) \forall s,\tilde{\mathbf{C}}^s (i^s,l^s) = \frac{1}{Z_{i^s}^s}\sum_{j^s\in N_{i^s}}K(i^s,j^s)\mathbf{C}^s (j^s,l^s). \quad (6) ∀s,C~s(is,ls)=Ziss1js∈Nis∑K(is,js)Cs(js,ls).(6)
以往的 CTF 方法通常通过使用从更粗尺度的代价体积估计出的视差图来缩小当前尺度的视差搜索空间,这常常导致小视差细节的丢失。或者,我们通过将广义 Tikhonov 正则化项添加到公式 (5) 中,直接在代价体积上强制尺度间一致性,从而得到以下优化目标:
v^=argmin{zs}s=0S(∑s=0S1Ziss∑js∈NisK(is,js)∥zs−Cs(js,ls)∥2+λ∑s=1S∥zs−zs−1∥2),(7) \begin{array}{rl} & {\hat{\mathbf{v}} = \underset {\{z^s\}{s = 0}^S}{\arg \min}\big(\sum{s = 0}^{S}\frac{1}{Z_{i^s}^s}\sum_{j^s\in N_{i^s}}K(i^s,j^s)\| z^s -{\bf C}^s (j^s,l^s)\| ^2}\\ & {\qquad +\lambda \sum_{s = 1}^{S}\| z^s -z^{s - 1}\| ^2),} \end{array} \quad (7) v^={zs}s=0Sargmin(∑s=0SZiss1∑js∈NisK(is,js)∥zs−Cs(js,ls)∥2+λ∑s=1S∥zs−zs−1∥2),(7)
其中 λ\lambdaλ 是一个常数参数,用于控制正则化的强度。此外,与 v~\tilde{\mathbf{v}}v~ 类似,向量 v^=C\^0(i0,l0),C\^1(i1,l1),...,C\^S(iS,lS)T\hat{\mathbf{v}} = \\hat{\\mathbf{C}}\^0 (i\^0,l\^0),\\hat{\\mathbf{C}}\^1 (i\^1,l\^1),\\dots ,\\hat{\\mathbf{C}}\^S (i\^S,l\^S)^Tv^=C\^0(i0,l0),C\^1(i1,l1),...,C\^S(iS,lS)T 也具有 S+1S + 1S+1 个分量来表示每个尺度上的代价。上述优化问题是凸的。因此,我们可以通过找到优化目标的驻点来获得解。设 F({zs}s=0S)F(\{z^s\}_{s = 0}^S)F({zs}s=0S) 表示公式 (7) 中的优化目标。对于 s∈{1,2,...,S−1}s \in \{1, 2, \ldots , S - 1\}s∈{1,2,...,S−1},FFF 对 zsz^szs 的偏导数为:
∂F∂zs=2Ziss∑js∈NisK(is,js)(zs−Cs(js,ls))+2λ(zs−zs−1)−2λ(zs+1−zs)=2(−λzs−1+(1+2λ)zs−λzs+1−C~s(is,ls)).(8) \begin{array}{rcl}\frac{\partial F}{\partial z^s} & = & \frac{2}{Z_{i^s}^s}\sum_{j^s\in N_{i^s}}K(i^s,j^s)(z^s -{\bf C}^s (j^s,l^s))\\ & & +2\lambda (z^s -z^{s - 1}) - 2\lambda (z^{s + 1} - z^s)\\ & = & 2(-\lambda z^{s - 1} + (1 + 2\lambda)z^s -\lambda z^{s + 1} - \tilde{\mathbf{C}}^s (i^s,l^s)). \end{array} \quad (8) ∂zs∂F==Ziss2∑js∈NisK(is,js)(zs−Cs(js,ls))+2λ(zs−zs−1)−2λ(zs+1−zs)2(−λzs−1+(1+2λ)zs−λzs+1−C~s(is,ls)).(8)
令 ∂F∂zs=0\frac{\partial F}{\partial z^s} = 0∂zs∂F=0,我们得到:
−λzs−1+(1+2λ)zs−λzs+1=C~s(is,ls).(9) -\lambda z^{s - 1} + (1 + 2\lambda)z^s -\lambda z^{s + 1} = \tilde{\mathbf{C}}^s (i^s,l^s). \quad (9) −λzs−1+(1+2λ)zs−λzs+1=C~s(is,ls).(9)
很容易得到 s=0s = 0s=0 和 s=Ss = Ss=S 的类似方程。因此,我们总共有 S+1S + 1S+1 个线性方程,可以简洁地表示为:
Av^=v~.(10) A \hat{\mathbf{v}} = \tilde{\mathbf{v}}. \quad (10) Av^=v~.(10)
矩阵 AAA 是一个 (S+1)×(S+1)(S + 1) \times (S + 1)(S+1)×(S+1) 的三对角常数矩阵,可以从公式 (9) 轻松推导出来。由于 AAA 是三对角的,其逆矩阵总是存在。因此,
v^=A−1v~.(11) \hat{\mathbf{v}} = A^{-1}\tilde{\mathbf{v}}. \quad (11) v^=A−1v~.(11)
最终的代价体积是通过对不同尺度上执行的代价聚合结果进行自适应组合获得的。这种自适应组合使得代价聚合在优化背景下能够进行多尺度交互。
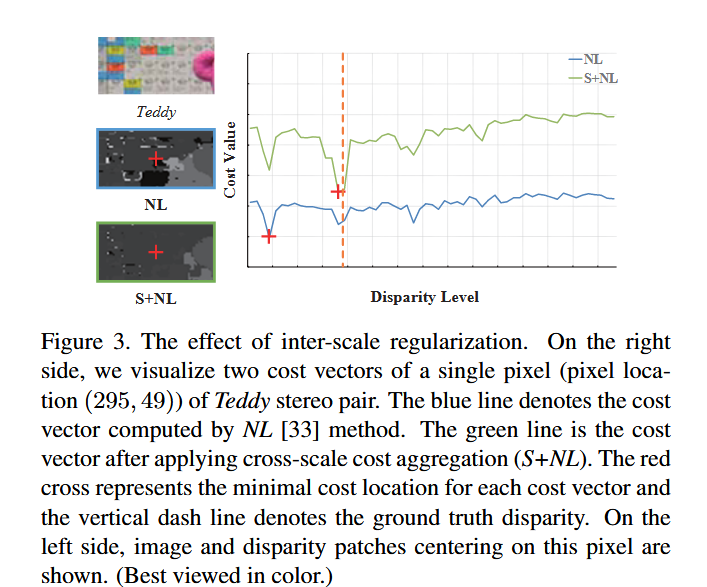
最后,我们用一个例子来展示图 3 中尺度间正则化的效果。在这个例子中,没有跨尺度代价聚合时,代价向量中存在相似的局部最小值,导致错误的视差。最精细尺度的信息不足,但当采用尺度间正则化时,来自粗尺度的有用信息重塑了代价向量,生成更接近真实视差的视差。
5. 实现和复杂度
为了构建不同尺度的代价体积(图 2),我们需要提取不同尺度的立体图像对。在我们的实现中,我们选择了高斯金字塔 2,这是尺度空间理论中的经典表示。高斯金字塔是通过连续平滑和下采样 (η=2)(\eta = 2)(η=2) 获得的。这种表示的一个优点是图像大小随着尺度级别的增加呈指数减小,这使较粗尺度的代价聚合计算成本呈指数降低。
算法 1 跨尺度代价聚合
输入: 立体彩色图像 I\mathbf{I}I, I′\mathbf{I}^\primeI′
- 构建高斯金字塔 Is,Is,s∈{0,1,...,S}\mathbf{I}^s,\mathbf{I}^{s},s\in \{0,1,\ldots ,S\}Is,Is,s∈{0,1,...,S}
- 根据公式 (1) 通过代价计算为每个尺度生成初始代价体积 Cs\mathbf{C}^sCs。
- 根据公式 (6) 在每个尺度上分别聚合代价以获得代价体积 C~s\tilde{\mathbf{C}}^sC~s
- 根据公式 (11) 跨多个尺度聚合代价以获得最终代价体积 C^s\hat{\mathbf{C}}^sC^s
输出: 稳健的代价体积:C^0\hat{\mathbf{C}}^{0}C^0
跨尺度代价聚合的基本工作流程如算法 1 所示,我们可以在步骤 3 中利用任何现有的代价聚合方法。与传统的代价聚合方法相比,我们算法的计算复杂度仅增加了一个小的常数因子。具体来说,让我们将传统代价聚合方法的计算复杂度表示为 O(mWL)O(mWL)O(mWL),其中 mmm 因不同的代价聚合方法而异。在尺度 sss 上的像素数和视差数分别为 ⌊WL4s⌋\left\lfloor \frac{WL}{4^s}\right\rfloor⌊4sWL⌋ 和 ⌊L2s⌋\left\lfloor \frac{L}{2^s}\right\rfloor⌊2sL⌋。因此,与传统代价聚合方法相比,步骤 3 的计算复杂度最多增加 17\frac{1}{7}71,解释如下:
∑s=0S(m⌊WHL8s⌋)≤limS→∞(∑s=0SmWHL8s)=87mWHL.(12) \sum_{s = 0}^{S}\left(m\left\lfloor \frac{WHL}{8^s}\right\rfloor\right)\leq \lim_{S\to \infty}\left(\sum_{s = 0}^{S}\frac{mWHL}{8^s}\right) = \frac{8}{7} mWHL. \quad (12) s=0∑S(m⌊8sWHL⌋)≤S→∞lim(s=0∑S8smWHL)=78mWHL.(12)
步骤 4 涉及大小为 (S+1)×(S+1)(S + 1)\times (S + 1)(S+1)×(S+1) 的矩阵 AAA 的求逆,但 AAA 是一个空间不变矩阵,每行最多包含三个非零元素,因此可以预先计算其逆。此外,在公式 (11) 中,最精细尺度的代价体积 C^0(i0,l0)\hat{\mathbf{C}}^{0}(i^{0},l^{0})C^0(i0,l0) 用于生成最终的视差图,因此我们只需要计算
C^0(i0,l0)=∑s=0SA−1(0,s)C~s(is,ls),(13) \hat{\mathbf{C}}^0 (i^0,l^0) = \sum_{s = 0}^{S}A^{-1}(0,s)\tilde{\mathbf{C}}^s (i^s,l^s), \quad (13) C^0(i0,l0)=s=0∑SA−1(0,s)C~s(is,ls),(13)
而不是 v^=A−1v~\hat{\mathbf{v}} = A^{- 1}\tilde{\mathbf{v}}v^=A−1v~。这种跨多个尺度的代价聚合仅需要少量的额外计算负担。在下一节中,我们将更详细地分析我们方法的运行时效率。
6. 实验结果与分析
在本节中,我们使用 Middlebury 23、KITTI 4 和 New Tsukuba 20 数据集来验证,当将最先进的代价聚合方法(如 BFBFBF 36、GFGFGF 21、NLNLNL 33 和 STSTST 16)集成到我们的框架中时,性能会有显著提升。此外,我们还实现了简单的盒式滤波器聚合方法(命名为 BOXBOXBOX,窗口大小为 7×77\times 77×7)作为基线,当集成到我们的框架中时,它也变得非常强大。对于 NLNLNL 和 STSTST,我们直接使用作者提供的 C++C + +C++ 代码 1,2^{1,2}1,2,因此所有参数设置与其实现中使用的相同。对于 GFGFGF,我们通过参考作者提供的软件(在 MATLAB 中实现 3^{3}3)实现我们自己的 C++C + +C++ 代码,以便高效处理来自 KITTI 和 New Tsukuba 数据集的高分辨率图像。对于 BFBFBF,我们按照 9 的建议实现了非对称版本。采用局部胜者全取策略来生成视差图。为了公平地比较不同的代价聚合方法,除非我们明确声明,否则不使用视差优化技术。SSS 设置为 4,即我们的框架中总共使用五个尺度。对于正则化参数 λ\lambdaλ,考虑到 KITTI 和 New Tsukuba 数据集包含大量无纹理区域,我们在 Middlebury 数据集上将其设置为 0.3,而在 KITTI 和 New Tsukuba 数据集上设置为 1.0 以进行更强的正则化。
6.1. Middlebury 数据集
Middlebury 基准测试 24 是事实上的比较现有立体匹配算法的标准。在基准测试 24 中,使用四个立体对(Tsukuba、Venus、Teddy、Cones)对 100 多个立体匹配算法进行排名。在我们的实验中,我们采用了这四个立体对。此外,我们使用"Middlebury 2005" 22(6 个立体对)和"Middlebury 2006" 8(21 个立体对)数据集,它们涉及更复杂的场景。因此,我们总共有 31 个立体对,记为 M31M31M31。值得一提的是,在我们的实验过程中,所有局部代价聚合方法在来自 Middlebury 2006 数据集的 4 个立体对(即 Middle1、Middle2、Monopoly 和 Plastic)上表现得相当差(非遮挡区域(nonocc)的错误率超过 20%20\%20%)。这四个立体对的一个共同特性是它们都包含大的无纹理区域,使得局部立体方法变得脆弱。为了减轻对这 4 个立体对的偏差,我们将它们从 M31 中排除以生成另一个立体对集合,我们称之为 M27。我们对 M31 和 M27 都进行了统计(表 1)。我们采用了公式 (2) 中的强度+梯度代价函数,这在最先进的代价聚合方法 21, 16, 33 中被广泛使用。
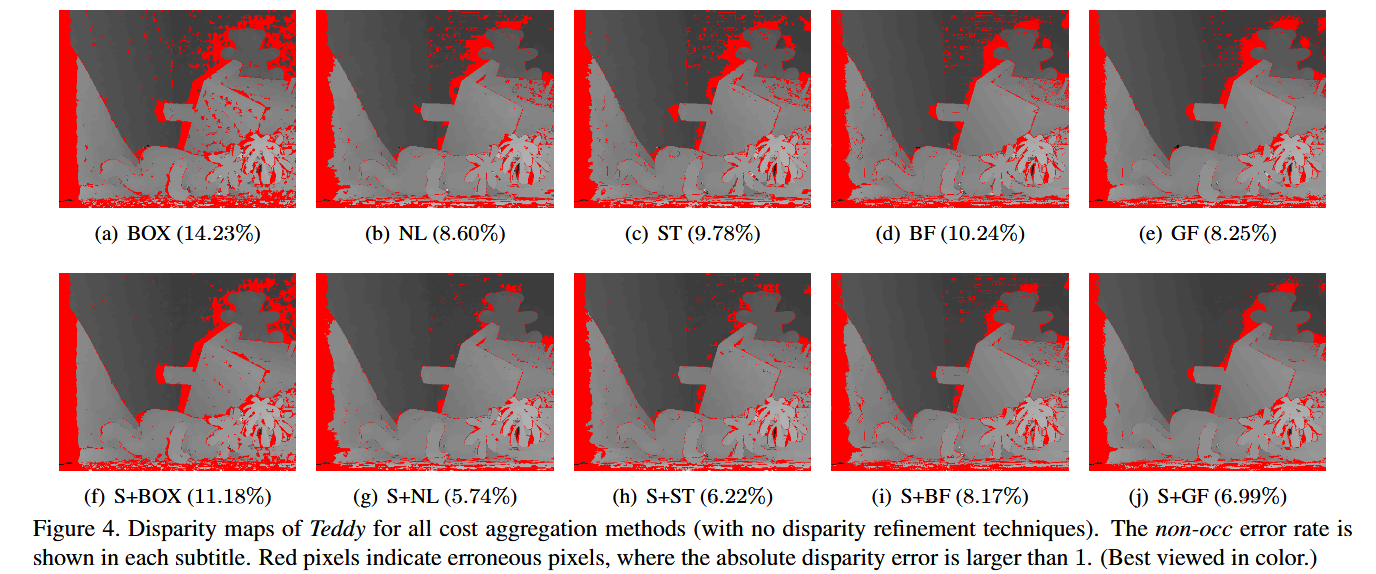
在表 1 中,我们展示了不同代价聚合方法在 M31 和 M27 数据集上非遮挡区域的平均错误率。我们使用前缀 S+Σ∗\mathbf{S} + \mathbf{\Sigma}^*S+Σ∗ 表示将现有代价聚合方法集成到跨尺度代价聚合框架中。Avg Non-occ 是非遮挡区域中匹配错误的像素平均百分比,其中绝对视差误差大于 1。结果令人鼓舞:当使用跨尺度代价聚合时,所有代价聚合方法都有所改进,即使是简单的 BOX 方法在使用跨尺度代价聚合时也变得非常强大(在 M27 上与最先进的方法相当)。图 4 显示了 Teddy 立体对所有方法的视差图,而其他结果因篇幅限制显示在补充材料中。
此外,为了遵循 Middlebury 基准测试 24 的标准评估指标,我们在表 1 中展示了截至 2013 年 10 月每个代价聚合方法在网站上的排名。Avg Rank 和 Avg Err 表示使用 Tsukuba、Venus、Teddy 和 Cones 图像 24 测量的平均排名和错误率。在这里,每种方法都与 33 中最先进的视差优化技术结合(对于 ST 16,我们列出了其在 Middlebury 基准测试 24 中报告的原始排名,因为使用作者的 C++{C} + +C++ 代码未能复现相同的结果)。排名也验证了我们框架的有效性。
表 1. Middlebury 数据集上代价聚合方法的定量评估。前缀S+表示我们的跨尺度代价聚合框架。对于排名部分(第 4 和第 5 列),视差结果使用相同的视差优化技术 33 进行了优化。
| 方法 | Avg Non-occ(%) (M31) | Avg Non-occ(%) (M27) | Avg Rank | Avg Err(%) | 时间 (s) |
|---|---|---|---|---|---|
| BOX | 15.45 | 10.75 | 96 | 6.2 | 0.3 |
| S+BOX | 13.09 | 8.55 | 51 | 1.95 | 0.3 |
| NL33 | 12.22 | 9.44 | 41 | 2.15 | 0.48 |
| S+NL | 11.49 | 8.73 | 39 | 1.95 | 0.52 |
| ST16 | 11.52 | 8.95 | 31 | 1.65 | 0.35 |
| S+ST | 10.51 | 8.07 | 27 | 1.45 | 0.39 |
| BF36 | 12.26 | 8.77 | 48 | 2.05 | 0.89 |
| S+BF | 10.95 | 8.04 | 40 | 1.75 | 0.93 |
| GF21 | 10.5 | 6.84 | 40 | 1.55 | 0.64 |
| S+GF | 9.39 | 6.20 | 37 | 1.35 | 0.66 |
我们还报告了在配备 2.83 GHz CPU 和 8 GB 内存的 PC 上处理 Tsukuba 立体对的运行时间。如前所述,计算开销相对较小。具体来说,它包括 C~s(s∈{0,1,...,S})\tilde{\mathbf{C}}^s (s \in \{0, 1, \dots , S\})C~s(s∈{0,1,...,S}) 的代价聚合和公式 (13) 的计算。
6.2. KITTI 数据集
KITTI 数据集 4 包含 194 个训练图像对和 195 个测试图像对,用于评估立体匹配算法。对于 KITTI 数据集,图像对是在真实世界光照条件下捕获的,几乎所有图像对都包含很大一部分无纹理区域,例如墙壁和道路 4。在我们的实验期间,我们使用全部 194 个带有真实视差图的训练图像对。评估指标与 KITTI 基准测试 5 相同,误差阈值为 3。
表 2. KITTI 数据集上代价聚合方法的定量比较。Out-No:非遮挡区域中错误像素的百分比;Out-All:总错误像素的百分比;Avg-No:非遮挡区域的平均视差误差;Avg-All:总平均视差误差。
| 方法 | Out-No | Out-All | Avg-No (px) | Avg-All (px) |
|---|---|---|---|---|
| BOX | 22.51 % | 24.28 % | 12.18 | 12.95 |
| S+BOX | 12.06 % | 14.07 % | 3.54 | 4.57 |
| NL33 | 24.69 % | 26.38 % | 4.36 | 5.54 |
| S+NL | 25.41 % | 27.08 % | 4.00 | 5.20 |
| ST16 | 24.09 % | 25.81 % | 4.31 | 5.47 |
| S+ST | 24.51 % | 26.22 % | 3.82 | 5.02 |
| GF21 | 12.50 % | 14.51 % | 4.64 | 5.69 |
| S+GF | 9.66 % | 11.73 % | 2.19 | 3.36 |
此外,由于 BFBFBF 对于高分辨率图像来说太慢(处理一个立体对需要超过一小时),我们在评估中省略了 BFBFBF。
考虑到 KITTI 数据集上的光照变化,我们采用了 Census Transform 37,这被证明对于稳健的光流计算非常有效 6。我们在表 2 中展示了不同方法集成到跨尺度代价聚合时的性能。一些有趣的点值得注意。首先,对于 BOXBOXBOX 和 GFGFGF,当使用跨尺度代价聚合时,有显著的改进。同样,与 Middlebury 数据集一样,简单的 BOXBOXBOX 方法通过使用跨尺度代价聚合变得非常强大。然而,对于 S+NLS + NLS+NL 和 S+STS + STS+ST,它们的性能与没有跨尺度代价聚合时几乎相同,甚至比 S+BOXS + BOXS+BOX 还要差。这可能是由于基于树的代价聚合方法的非局部特性。对于无纹理的倾斜平面,例如道路,基于树的方法倾向于过度使用分段常数假设,并可能产生错误的正面平行平面。因此,即使采用了跨尺度代价聚合,无纹理倾斜平面中的错误也没有完全解决。所有方法的视差图都在补充材料中给出,这也验证了我们的分析。
6.3. New Tsukuba 数据集
New Tsukuba 数据集 20 包含 1800 个带有真实视差图的立体对。这些立体对由一分钟的光真实感立体视频组成,通过在计算机生成的 3D 场景中移动立体相机生成。此外,还有 4 种不同的光照条件:日光、荧光灯、灯光和闪光灯。在我们的实验中,我们使用日光场景,它具有挑战性的真实世界光照条件 20。由于相邻帧通常共享相似的场景,我们每秒对 1800 帧进行采样,得到 60 个立体对的子集,这节省了评估时间。我们测试了强度+梯度和 Census Transform 代价函数,强度+梯度代价函数在该数据集中给出了更好的结果。该数据集的视差级别与 KITTI 数据集相同,即 256 个视差级别,使得 BF 36 太慢,因此我们在评估中省略了 BF。
表 3 显示了 New Tsukuba 数据集上不同代价聚合方法的评估结果。我们使用与 KITTI 基准测试 5 相同的评估指标(误差阈值为 3)。同样,当使用跨尺度代价聚合时,所有代价聚合方法都有所改进。
表 3. New Tsukuba 数据集上代价聚合方法的定量比较。
| 方法 | Out-No | Out-All | Avg-No (px) | Avg-All (px) |
|---|---|---|---|---|
| BOX | 31.08 % | 37.70 % | 7.37 | 10.72 |
| S+BOX | 18.82 % | 26.50 % | 3.92 | 7.44 |
| NL33 | 21.88 % | 26.72 % | 4.12 | 6.40 |
| S+NL | 19.84 % | 24.50 % | 3.65 | 5.73 |
| ST16 | 21.68 % | 27.07 % | 4.33 | 7.02 |
| S+ST | 18.99 % | 24.16 % | 3.60 | 5.96 |
| GF21 | 23.42 % | 30.34 % | 6.35 | 9.86 |
| S+GF | 14.40 % | 21.78 % | 3.10 | 6.38 |
6.4. 正则化参数研究
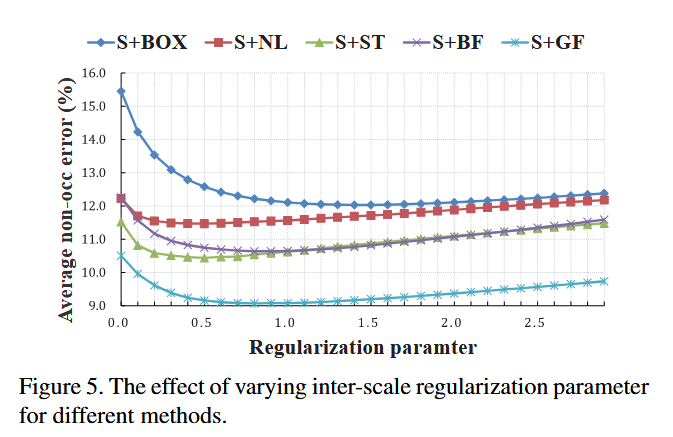
公式 (7) 中的关键参数是正则化参数 λ\lambdaλ。通过调整此参数,我们可以控制尺度间正则化的强度,如图 5 所示。错误率在 M31M31M31 上评估。当 λ\lambdaλ 设置为 0 时,禁止了尺度间正则化,这相当于在最精细尺度上执行代价聚合。当引入正则化时,所有方法都有改进。随着 λ\lambdaλ 变大,正则化项主导了优化,导致每个尺度的代价体积变得完全相同。结果,视差图的精细细节丢失,错误率增加。有人可能会注意到,通过为不同的代价聚合方法选择不同的 λ\lambdaλ 会产生更好的结果,尽管我们对所有方法使用一致的 λ\lambdaλ。
7. 结论与未来工作
在本文中,我们提出了一个用于立体匹配的跨尺度代价聚合框架。本文的目的不是提出一个完全新的、能产生高精度视差图的代价聚合方法。相反,我们研究了各种代价聚合方法在尺度空间中的行为。在三个数据集上的大量实验验证了跨尺度代价聚合的效果。几乎所有方法都得到了改进,即使是简单的盒式滤波方法与我们的框架结合也取得了非常好的性能。最近,立体视觉的一个新趋势是在连续平面参数空间中解决对应问题,而不是在离散视差标签空间中 1, 13, 32。这些方法可以很好地处理倾斜平面,一个可能的未来方向是研究这些方法在尺度空间中的行为。
附录
A公式证明
根据论文中的公式(7)和上下文,我们可以详细推导出公式(8)。公式(7)是带尺度间正则化的优化目标:
F({zs}s=0S)=∑s=0S1Ziss∑js∈NisK(is,js)∥zs−Cs(js,ls)∥2+λ∑s=1S∥zs−zs−1∥2 F(\{z^s\}{s=0}^S) = \sum{s=0}^{S} \frac{1}{Z_{i^s}^s} \sum_{j^s \in N_{i^s}} K(i^s, j^s) \| z^s - \mathbf{C}^s(j^s, l^s) \|^2 + \lambda \sum_{s=1}^{S} \| z^s - z^{s-1} \|^2 F({zs}s=0S)=s=0∑SZiss1js∈Nis∑K(is,js)∥zs−Cs(js,ls)∥2+λs=1∑S∥zs−zs−1∥2
我们需要对 FFF 关于 zsz^szs(其中 s∈{1,2,...,S−1}s \in \{1, 2, \ldots, S-1\}s∈{1,2,...,S−1})求偏导。
步骤 1:分解目标函数
目标函数 FFF 由两部分组成:
- 第一项:尺度内代价聚合项
Gs(zs)=1Ziss∑js∈NisK(is,js)∥zs−Cs(js,ls)∥2 G_s(z^s) = \frac{1}{Z_{i^s}^s} \sum_{j^s \in N_{i^s}} K(i^s, j^s) \| z^s - \mathbf{C}^s(j^s, l^s) \|^2 Gs(zs)=Ziss1js∈Nis∑K(is,js)∥zs−Cs(js,ls)∥2
注意,zsz^szs 只出现在 GsG_sGs 中(对于固定的 sss),其他 s′≠ss' \neq ss′=s 的 Gs′G_{s'}Gs′ 与 zsz^szs 无关。 - 第二项:尺度间正则项
R=λ∑t=1S∥zt−zt−1∥2 R = \lambda \sum_{t=1}^{S} \| z^t - z^{t-1} \|^2 R=λt=1∑S∥zt−zt−1∥2
当 t=st = st=s 时,项为 λ∥zs−zs−1∥2\lambda \| z^s - z^{s-1} \|^2λ∥zs−zs−1∥2。
当 t=s+1t = s+1t=s+1 时,项为 λ∥zs+1−zs∥2\lambda \| z^{s+1} - z^s \|^2λ∥zs+1−zs∥2。
正则项中只有这两项包含 zsz^szs。
因此,FFF 中与 zsz^szs 相关的部分可以写为:
Frelated=Gs(zs)+λ∥zs−zs−1∥2+λ∥zs+1−zs∥2 F_{related} = G_s(z^s) + \lambda \| z^s - z^{s-1} \|^2 + \lambda \| z^{s+1} - z^s \|^2 Frelated=Gs(zs)+λ∥zs−zs−1∥2+λ∥zs+1−zs∥2
其他与 zsz^szs 无关的项在求偏导时为0。
步骤 2:对 Gs(zs)G_s(z^s)Gs(zs) 求偏导
∂Gs∂zs=∂∂zs1Ziss∑jsK(is,js)(zs−Cs(js,ls))2 \frac{\partial G_s}{\partial z^s} = \frac{\partial}{\partial z^s} \left \\frac{1}{Z_{i\^s}\^s} \\sum_{j\^s} K(i\^s, j\^s) (z\^s - \\mathbf{C}\^s(j\^s, l\^s))\^2 \\right ∂zs∂Gs=∂zs∂Ziss1js∑K(is,js)(zs−Cs(js,ls))2
由于求和符号内各项都是标量,且 zsz^szs 是标量,我们可以逐项求导。使用链式法则:
∂∂zs(zs−Cs(js,ls))2=2(zs−Cs(js,ls)) \frac{\partial}{\partial z^s} (z^s - \mathbf{C}^s(j^s, l^s))^2 = 2(z^s - \mathbf{C}^s(j^s, l^s)) ∂zs∂(zs−Cs(js,ls))2=2(zs−Cs(js,ls))
因此,
∂Gs∂zs=1Ziss∑jsK(is,js)⋅2(zs−Cs(js,ls))=2Ziss∑jsK(is,js)(zs−Cs(js,ls)) \frac{\partial G_s}{\partial z^s} = \frac{1}{Z_{i^s}^s} \sum_{j^s} K(i^s, j^s) \cdot 2(z^s - \mathbf{C}^s(j^s, l^s)) = \frac{2}{Z_{i^s}^s} \sum_{j^s} K(i^s, j^s)(z^s - \mathbf{C}^s(j^s, l^s)) ∂zs∂Gs=Ziss1js∑K(is,js)⋅2(zs−Cs(js,ls))=Ziss2js∑K(is,js)(zs−Cs(js,ls))
步骤 3:对正则项求偏导
正则项包含两个与 zsz^szs 相关的项:
R1=λ(zs−zs−1)2,R2=λ(zs+1−zs)2 R_1 = \lambda (z^s - z^{s-1})^2, \quad R_2 = \lambda (z^{s+1} - z^s)^2 R1=λ(zs−zs−1)2,R2=λ(zs+1−zs)2
分别求偏导:
∂R1∂zs=2λ(zs−zs−1) \frac{\partial R_1}{\partial z^s} = 2\lambda (z^s - z^{s-1}) ∂zs∂R1=2λ(zs−zs−1)
对于 R2R_2R2,注意它是 (zs+1−zs)2(z^{s+1} - z^s)^2(zs+1−zs)2 关于 zsz^szs 的导数,因为 zs+1z^{s+1}zs+1 被视为常数,所以:
∂R2∂zs=2λ(zs+1−zs)⋅(−1)=−2λ(zs+1−zs) \frac{\partial R_2}{\partial z^s} = 2\lambda (z^{s+1} - z^s) \cdot (-1) = -2\lambda (z^{s+1} - z^s) ∂zs∂R2=2λ(zs+1−zs)⋅(−1)=−2λ(zs+1−zs)
因此,正则项的总偏导为:
∂(R1+R2)∂zs=2λ(zs−zs−1)−2λ(zs+1−zs) \frac{\partial (R_1 + R_2)}{\partial z^s} = 2\lambda (z^s - z^{s-1}) - 2\lambda (z^{s+1} - z^s) ∂zs∂(R1+R2)=2λ(zs−zs−1)−2λ(zs+1−zs)
步骤 4:组合偏导数
目标函数 FFF 关于 zsz^szs 的偏导数是这两部分之和:
∂F∂zs=2Ziss∑jsK(is,js)(zs−Cs(js,ls))+2λ(zs−zs−1)−2λ(zs+1−zs) \frac{\partial F}{\partial z^s} = \frac{2}{Z_{i^s}^s} \sum_{j^s} K(i^s, j^s)(z^s - \mathbf{C}^s(j^s, l^s)) + 2\lambda (z^s - z^{s-1}) - 2\lambda (z^{s+1} - z^s) ∂zs∂F=Ziss2js∑K(is,js)(zs−Cs(js,ls))+2λ(zs−zs−1)−2λ(zs+1−zs)
这对应于公式(8)中的前两行。
步骤 5:化简为论文中的最终形式
将上述表达式展开并整理。首先,将 2λ(zs−zs−1)−2λ(zs+1−zs)2\lambda (z^s - z^{s-1}) - 2\lambda (z^{s+1} - z^s)2λ(zs−zs−1)−2λ(zs+1−zs) 合并:
2λ(zs−zs−1)−2λ(zs+1−zs)=2λ(2zs−zs−1−zs+1) 2\lambda (z^s - z^{s-1}) - 2\lambda (z^{s+1} - z^s) = 2\lambda (2z^s - z^{s-1} - z^{s+1}) 2λ(zs−zs−1)−2λ(zs+1−zs)=2λ(2zs−zs−1−zs+1)
其次,处理第一项。根据公式(6),我们知道:
C~s(is,ls)=1Ziss∑jsK(is,js)Cs(js,ls) \tilde{\mathbf{C}}^s(i^s, l^s) = \frac{1}{Z_{i^s}^s} \sum_{j^s} K(i^s, j^s) \mathbf{C}^s(j^s, l^s) C~s(is,ls)=Ziss1js∑K(is,js)Cs(js,ls)
并且,由于 zsz^szs 与求和指标 jsj^sjs 无关,且 ∑jsK(is,js)=Ziss\sum_{j^s} K(i^s, j^s) = Z_{i^s}^s∑jsK(is,js)=Ziss,所以:
2Ziss∑jsK(is,js)zs=2zs \frac{2}{Z_{i^s}^s} \sum_{j^s} K(i^s, j^s) z^s = 2z^s Ziss2js∑K(is,js)zs=2zs
因此,第一项可以重写为:
2Ziss∑jsK(is,js)(zs−Cs(js,ls))=2zs−2C~s(is,ls) \frac{2}{Z_{i^s}^s} \sum_{j^s} K(i^s, j^s)(z^s - \mathbf{C}^s(j^s, l^s)) = 2z^s - 2\tilde{\mathbf{C}}^s(i^s, l^s) Ziss2js∑K(is,js)(zs−Cs(js,ls))=2zs−2C~s(is,ls)
现在,将两部分合并:
∂F∂zs=2zs−2C~s(is,ls)+2λ(2zs−zs−1−zs+1)=2zs+4λzs−2λzs−1−2λzs+1−2C~s(is,ls)=2(1+2λ)zs−λzs−1−λzs+1−C\~s(is,ls) \begin{aligned} \frac{\partial F}{\partial z^s} &= 2z^s - 2\tilde{\mathbf{C}}^s(i^s, l^s) + 2\lambda (2z^s - z^{s-1} - z^{s+1}) \\ &= 2z^s + 4\lambda z^s - 2\lambda z^{s-1} - 2\lambda z^{s+1} - 2\tilde{\mathbf{C}}^s(i^s, l^s) \\ &= 2\left (1+2\\lambda)z\^s - \\lambda z\^{s-1} - \\lambda z\^{s+1} - \\tilde{\\mathbf{C}}\^s(i\^s, l\^s) \\right \end{aligned} ∂zs∂F=2zs−2C~s(is,ls)+2λ(2zs−zs−1−zs+1)=2zs+4λzs−2λzs−1−2λzs+1−2C~s(is,ls)=2(1+2λ)zs−λzs−1−λzs+1−C\~s(is,ls)
这等价于:
∂F∂zs=2−λzs−1+(1+2λ)zs−λzs+1−C\~s(is,ls) \frac{\partial F}{\partial z^s} = 2\left -\\lambda z\^{s-1} + (1+2\\lambda)z\^s - \\lambda z\^{s+1} - \\tilde{\\mathbf{C}}\^s(i\^s, l\^s) \\right ∂zs∂F=2−λzs−1+(1+2λ)zs−λzs+1−C\~s(is,ls)
这正是论文中公式(8)的最终形式。
总结推导步骤:
- 识别目标函数中与 zsz^szs 相关的项。
- 分别对尺度内聚合项和尺度间正则项求偏导。
- 利用定义 C~s\tilde{\mathbf{C}}^sC~s 和归一化条件 ∑K=Z\sum K = Z∑K=Z 化简第一项。
- 合并同类项,得到最终简洁的表达式。
B核心思想说明
这是一个非常好的问题,触及了跨尺度代价聚合方法的核心。让我详细解释这个优化问题的结构。
一、为什么可以求解方程?
因为这是一个凸优化问题:
- 目标函数是凸函数:代价聚合项是二次项(平方损失),尺度间正则化项也是二次项,两者都是凸函数。
- 线性约束(无约束):这是一个无约束优化问题。
- 可解析求解:二次函数的导数是一次函数,所以令导数为零得到的是线性方程组。
关键点 :对于每个像素-视差对 (i0,l0)(i^0, l^0)(i0,l0),这个问题是独立的,可以单独求解。
二、方程和未知量是什么?
未知量:
对于固定 的像素 i0i^0i0 和视差 l0l^0l0,我们有:
- z0z^0z0:最精细尺度下的聚合代价
- z1z^1z1:第1个粗尺度下的聚合代价
- z2z^2z2:第2个粗尺度下的聚合代价
- ...
- zSz^SzS:最粗尺度下的聚合代价
所以每个像素-视差对 有 S+1S+1S+1 个未知量。
方程:
对于每个中间尺度 s∈{1,2,...,S−1}s \in \{1, 2, \ldots, S-1\}s∈{1,2,...,S−1},我们有公式(9):
−λzs−1+(1+2λ)zs−λzs+1=C~s(is,ls) -\lambda z^{s-1} + (1 + 2\lambda)z^s - \lambda z^{s+1} = \tilde{\mathbf{C}}^s(i^s,l^s) −λzs−1+(1+2λ)zs−λzs+1=C~s(is,ls)
对于边界情况:
- s=0s=0s=0:z0z^0z0 对应的方程(只与 z1z^1z1 耦合)
- s=Ss=Ss=S:zSz^SzS 对应的方程(只与 zS−1z^{S-1}zS−1 耦合)
所以每个像素-视差对 也有 S+1S+1S+1 个方程。
三、完整的方程数量分析
1. 单个体素(体素 = 像素×视差)
设尺度数为 S+1S+1S+1(从0到S):
- 未知数数量 :S+1S+1S+1 个(z0,z1,...,zSz^0, z^1, ..., z^Sz0,z1,...,zS)
- 方程数量 :S+1S+1S+1 个
- 系数矩阵A :(S+1)×(S+1)(S+1) \times (S+1)(S+1)×(S+1) 的三对角矩阵
这是一个适定线性系统:方程数 = 未知数数,且矩阵A是可逆的。
2. 扩展到完整图像和视差范围
设图像尺寸为 W×HW \times HW×H,视差范围为 0,D0, D0,D(包含 D+1D+1D+1 个离散视差值)。
对于每个像素 iii 和每个视差 lll,我们有一个独立的方程组:
- 像素 iii 在最精细尺度对应 i0i^0i0
- 视差 lll 在最精细尺度对应 l0l^0l0
- 通过尺度映射关系 is+1=is/ηi^{s+1} = i^s / \etais+1=is/η, ls+1=ls/ηl^{s+1} = l^s / \etals+1=ls/η 得到其他尺度的对应
总未知量数量 :
总未知量=(W×H×(D+1))×(S+1) \text{总未知量} = (W \times H \times (D+1)) \times (S+1) 总未知量=(W×H×(D+1))×(S+1)
但关键洞察 :这些方程组是完全解耦 的!每个 (i,l)(i, l)(i,l) 对的求解是独立的。
四、实际计算规模示例
假设:
- 图像尺寸:640×480640 \times 480640×480
- 视差范围:D=128D = 128D=128(129个视差值)
- 尺度数:S+1=5S+1 = 5S+1=5(5个尺度)
计算规模:
- 像素数 :640×480=307,200640 \times 480 = 307,200640×480=307,200
- 视差数 :129129129
- 体素数 :307,200×129≈39.6×106307,200 \times 129 \approx 39.6 \times 10^6307,200×129≈39.6×106
每个体素对应一个 5×55 \times 55×5 的线性系统。
但为什么能高效计算?
-
所有体素共享同一个系数矩阵A:矩阵A只与正则化参数λ和尺度数S有关,与像素、视差无关。
-
只需要计算最终尺度的结果 :如公式(13)所示,我们只需要:
C^0(i0,l0)=∑s=0SA−1(0,s)C~s(is,ls) \hat{\mathbf{C}}^0(i^0,l^0) = \sum_{s=0}^{S} A^{-1}(0,s) \tilde{\mathbf{C}}^s(i^s,l^s) C^0(i0,l0)=s=0∑SA−1(0,s)C~s(is,ls)其中 A−1(0,s)A^{-1}(0,s)A−1(0,s) 是A逆矩阵的第0行元素,可以预先计算。
-
计算复杂度:
- 预计算:求 A−1A^{-1}A−1 的一次性成本(O(S3)O(S^3)O(S3),但S很小,通常S≤4)
- 每个体素:S+1S+1S+1 次乘法和加法(加权平均)
五、与CTF方法的区别
传统的由粗到精(CTF)方法:
- 顺序求解:先解粗尺度,用粗尺度结果约束细尺度
- 信息单向流动:从粗到细
- 可能丢失细节:粗尺度的错误会传播到细尺度
本文的跨尺度方法:
- 联合求解:所有尺度同时求解
- 信息双向流动:通过正则化实现尺度间相互约束
- 保留细节:细尺度的信息可以影响粗尺度的解
六、总结
| 方面 | 传统单尺度方法 | 跨尺度方法 |
|---|---|---|
| 求解单位 | 每个像素-视差对独立 | 每个像素-视差对的多尺度联合 |
| 未知量/方程数 | 1个未知量,1个方程 | S+1个未知量,S+1个方程 |
| 耦合性 | 无尺度间耦合 | 通过正则化耦合相邻尺度 |
| 计算关键 | 直接加权平均 | 求解三对角线性系统 |
| 效率 | 高 | 略低,但通过预计算和并行化仍高效 |
核心思想:虽然每个像素-视差对需要解一个小型线性系统,但由于:
- 系统规模小(S通常≤4)
- 系数矩阵相同可预计算
- 不同体素间完全独立可并行
因此整个算法可以高效实现,同时获得多尺度一致性的好处。