2.11-2.24历时两周,一开始一天做几个题都费劲,后来越做越顺了,记录了一些做题时遇到的困难和知识点,继续做中等题
目录
[196.删除重复的电子邮箱 ***](#196.删除重复的电子邮箱 ***)
[197.上升的温度 ***](#197.上升的温度 ***)
[597.好友申请I:总体通过率 ***](#597.好友申请I:总体通过率 ***)
[613.直线上的最近距离 ***](#613.直线上的最近距离 ***)
[1050.合作过至少三次的演员和导演 ***](#1050.合作过至少三次的演员和导演 ***)
[1075.项目员工 I](#1075.项目员工 I)
[1082.销售分析| ***](#1082.销售分析| ***)
[1141.查询近30天活跃用户数 ***](#1141.查询近30天活跃用户数 ***)
[1142.过去30天的用户活动 ***](#1142.过去30天的用户活动 ***)
[1179.重新格式化部门表 ***](#1179.重新格式化部门表 ***)
[1211.查询结果的质量和占比 ***](#1211.查询结果的质量和占比 ***)
[1241.每个帖子的评论数 ***](#1241.每个帖子的评论数 ***)
[1280.学生们参加各科测试的次数 ***](#1280.学生们参加各科测试的次数 ***)
[1294.不同国家的天气类型 ***](#1294.不同国家的天气类型 ***)
[1303.求团队人数 ***](#1303.求团队人数 ***)
[1322.广告效果 ***](#1322.广告效果 ***)
[1327.列出指定时间段内所有的下单产品 ***](#1327.列出指定时间段内所有的下单产品 ***)
[1511.消费者下单频率 ***](#1511.消费者下单频率 ***)
[1517.查找拥有有效邮箱的用户 ***](#1517.查找拥有有效邮箱的用户 ***)
[1543.产品名称格式修复 ***](#1543.产品名称格式修复 ***)
[1667.修复表中的名字 ***](#1667.修复表中的名字 ***)
[1683.无效的推文 ***](#1683.无效的推文 ***)
[1777.每家商店的产品价格 ***编辑](#1777.每家商店的产品价格 ***编辑)
[1795.每个产品在不同商店的价格 ***编辑](#1795.每个产品在不同商店的价格 ***编辑)
[1853.转换日期格式 ***编辑](#1853.转换日期格式 ***编辑)
[1939.主动请求确认消息的用户 ***](#1939.主动请求确认消息的用户 ***)
[1965.丢失信息的雇员 ***](#1965.丢失信息的雇员 ***)
[2026.低质量的问题 ***编辑](#2026.低质量的问题 ***编辑)
[2205.有资格享受折扣的用户数量 ***编辑](#2205.有资格享受折扣的用户数量 ***编辑)
[2230.查找可享受优惠的用户 ***](#2230.查找可享受优惠的用户 ***)
[2837.总旅行距离 ***](#2837.总旅行距离 ***)
[3150.无效的推文Ⅱ ***](#3150.无效的推文Ⅱ ***)
[3172.第二天验证 ***](#3172.第二天验证 ***)
[3246.英超积分榜排名 ***](#3246.英超积分榜排名 ***)
[3415.查找具有三个连续数字的产品 ***](#3415.查找具有三个连续数字的产品 ***)
[3465.查找具有有效序列号的产品 ***](#3465.查找具有有效序列号的产品 ***)
175:组合两个表
181.超过经理收入的员工
182.查找重复的电子邮箱
183.从不订购的客户
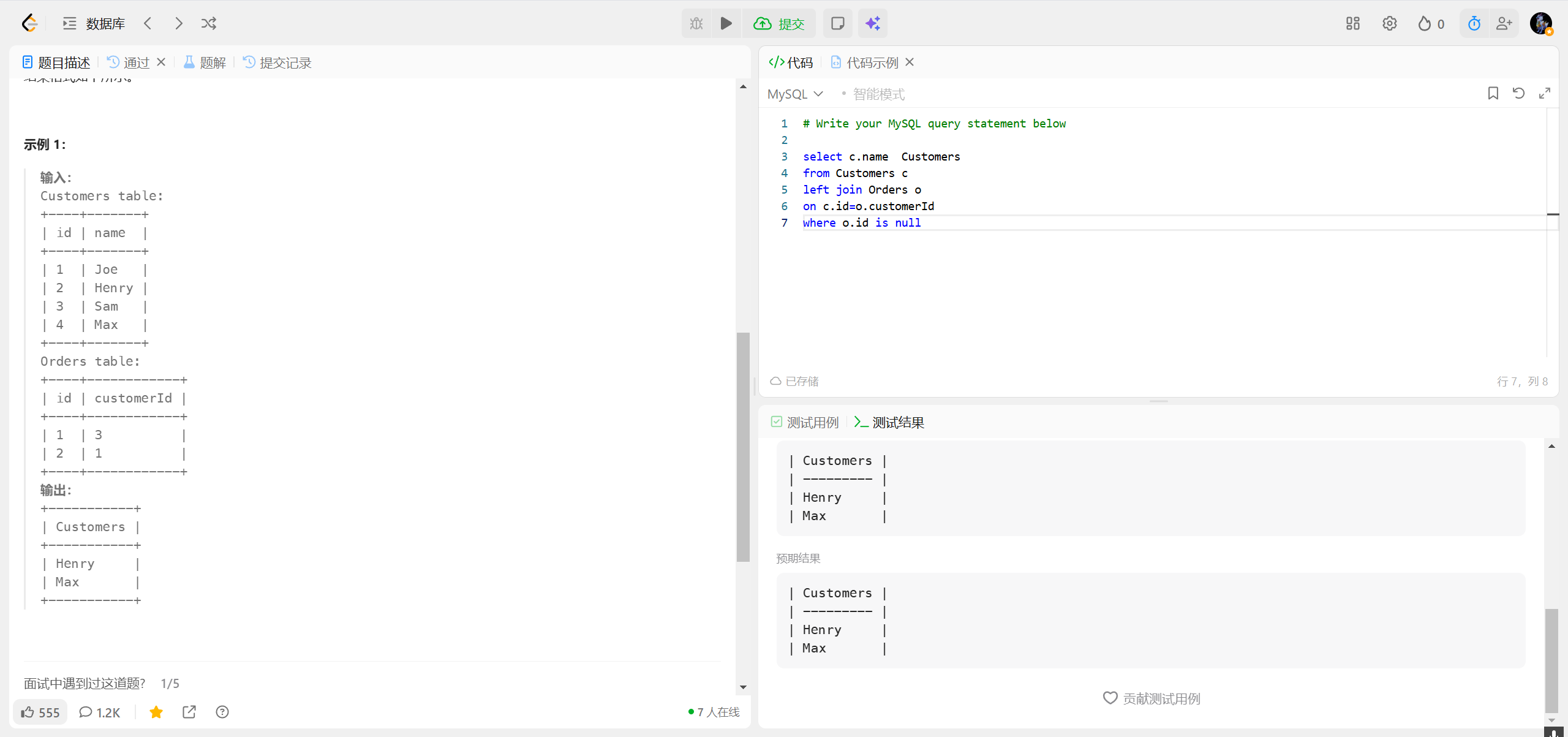
196.删除重复的电子邮箱 ***
在大多数数据库(如 MySQL)中,不能在
DELETE语句的同一个表中直接使用子查询来引用该表 ,这会导致 "You can't specify target table for update in FROM clause" 错误。我们需要通过嵌套子查询的方式,将子查询结果包装成一个临时表,绕开这个限制。
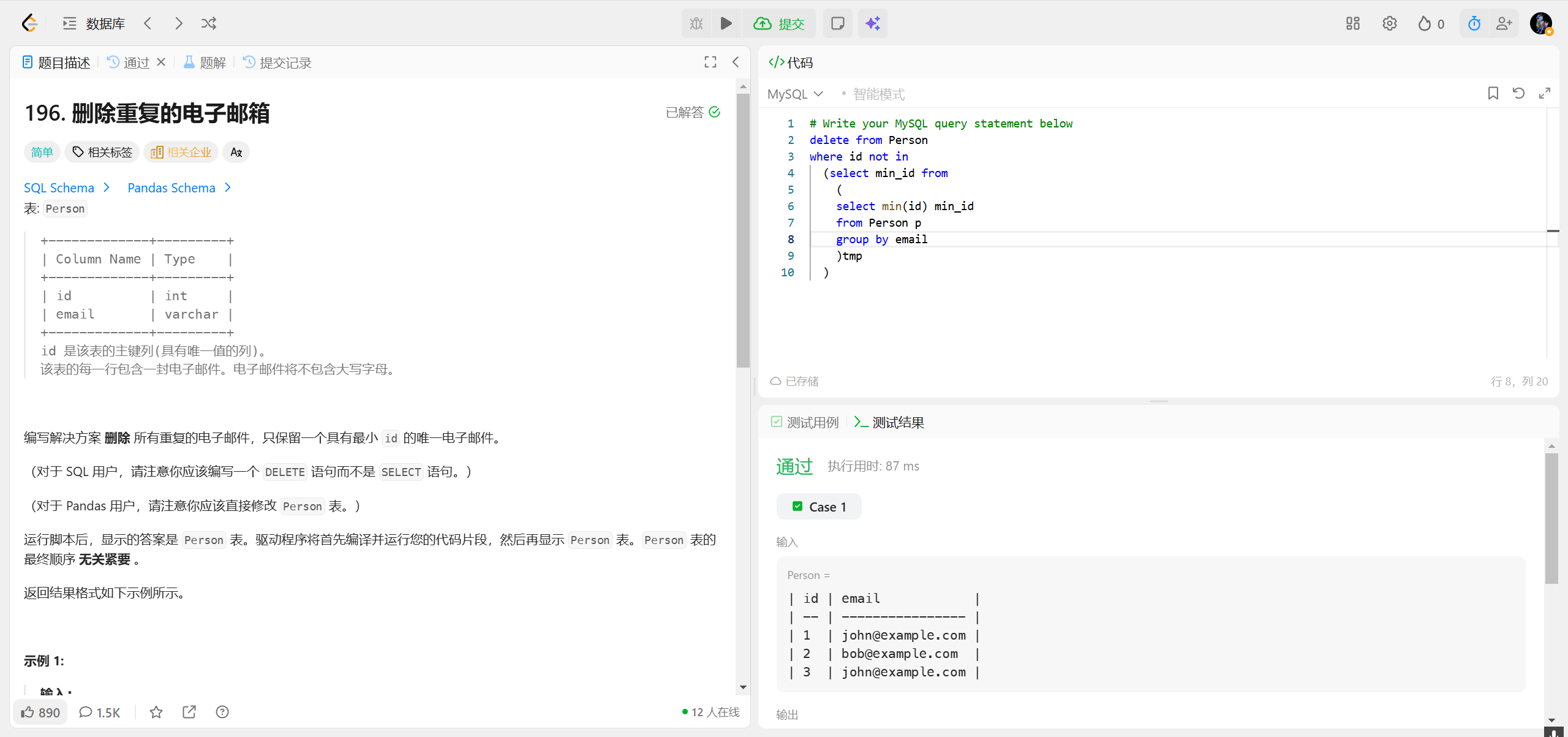
197.上升的温度 ***
- 日期加减(最常用,如 "前一天 / 后两天")
| 函数格式 | 作用 | 示例(基于 2024-01-01) |
结果 |
|---|---|---|---|
DATE_ADD(日期, INTERVAL 数值 单位) |
日期加指定时长 | DATE_ADD('2024-01-01', INTERVAL 1 DAY) |
2024-01-02(加 1 天) |
DATE_ADD(日期, INTERVAL 数值 单位) |
日期加指定时长 | DATE_ADD('2024-01-01', INTERVAL 2 DAY) |
2024-01-03(加 2 天) |
DATE_SUB(日期, INTERVAL 数值 单位) |
日期减指定时长 | DATE_SUB('2024-01-01', INTERVAL 1 MONTH) |
2023-12-01(减 1 月) |
| 简写(仅天数) | 日期加减天数(仅 MySQL 生效) | '2024-01-01' + INTERVAL 3 DAY |
2024-01-04 |
常用单位 :DAY(天)、MONTH(月)、YEAR(年)、HOUR(小时)、MINUTE(分钟)
- 日期差计算(如 "两天相差几天")
| 函数格式 | 作用 | 示例 | 结果 |
|---|---|---|---|
DATEDIFF(日期1, 日期2) |
计算日期 1 - 日期 2 的天数差 | DATEDIFF('2024-01-05', '2024-01-01') |
4(相差 4 天) |
TIMESTAMPDIFF(单位, 日期2, 日期1) |
精准计算任意单位的差值 | TIMESTAMPDIFF(HOUR, '2024-01-01 10:00', '2024-01-02 12:00') |
26(相差 26 小时) |
511.游戏玩法分析|
512.游戏玩法分析Ⅱ
577.员工奖金
584.寻找用户推荐人
586.订单最多的客户
595.大的国家
596.超过5名学生的课
597.好友申请I:总体通过率 ***
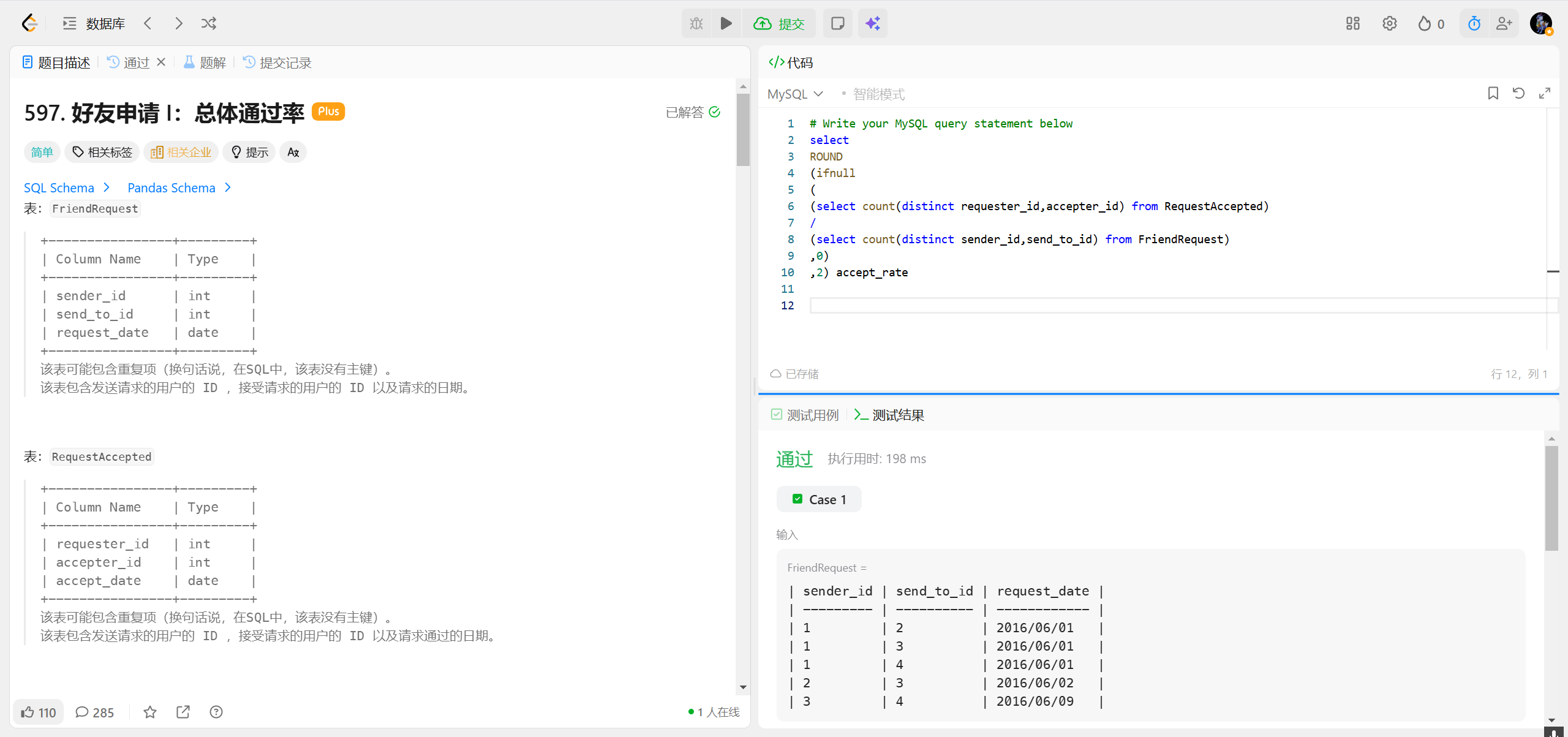
count(distinct requester_id, accepter_id) 是一种多列去重计数的写法,它的作用是:
- 先将
requester_id和accepter_id作为一个组合对(比如 (1,2)、(2,1)、(1,3)); - 对这些组合对去重(只保留唯一的组合);
- 最后统计去重后的组合对的总数。
607.销售员
610.判断三角形
613.直线上的最近距离 ***
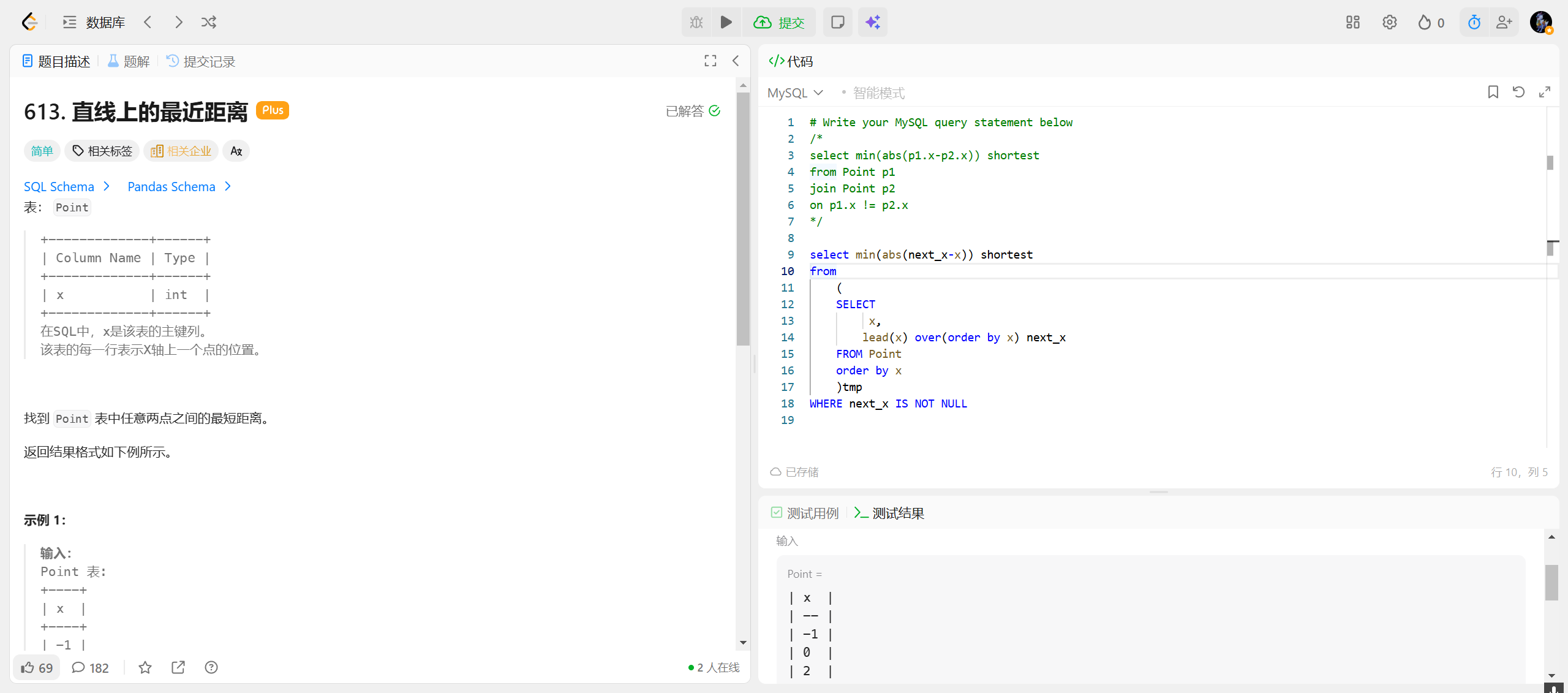
abs:绝对值函数
LEAD(x) OVER(ORDER BY x):
- 这是一个窗口函数。
- 它的作用是:对于当前行,获取排序后下一行 的
x值。- 例如,如果排序后的
x是[1, 3, 5],那么对于x=1的行,next_x就是3;对于x=3的行,next_x就是5。- 结果 :生成一个临时表(别名为
tmp),包含两列:
x: 当前点的值。next_x: 下一个点的值。
扩展:窗口函数
sql
窗口函数名() OVER (
[PARTITION BY 分组列1[, 分组列2...]] -- 可选:按哪些列分组,组内单独计算
[ORDER BY 排序列1 [ASC/DESC][, 排序列2 [ASC/DESC]...]] -- 可选:窗口内的排序规则
不常用
[ROWS/RANGE BETWEEN 窗口起始范围 AND 窗口结束范围] -- 可选:定义窗口的物理/逻辑范围
) AS 别名;| 分类 | 函数名 | 核心作用 | 关键特点 / 使用注意 |
|---|---|---|---|
| 排序编号类 | ROW_NUMBER() | 为每行分配唯一的连续编号 | 即使值重复,编号也不重复;无跳号 |
| 排序编号类 | RANK() | 对数据进行排名 | 值相同则排名相同,后续排名跳号(如 1,2,2,4) |
| 排序编号类 | DENSE_RANK() | 对数据进行密集排名 | 值相同则排名相同,后续排名不跳号(如 1,2,2,3) |
| 偏移取值类 | LEAD() | 获取当前行之后第 N 行的指定列值(默认 N=1) | 无后续行时返回 NULL;可自定义默认值(如 LEAD (score,1,0)) |
| 偏移取值类 | LAG() | 获取当前行之前第 N 行的指定列值(默认 N=1) | 无前置行时返回 NULL;可自定义默认值(如 LAG (score,1,0)) |
| 偏移取值类 | FIRST_VALUE() | 获取窗口内第一行的指定列值 | 常用来查分组内的极值(如班级最高分) |
| 偏移取值类 | LAST_VALUE() | 获取窗口内最后一行的指定列值 | 需显式指定窗口范围(ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING),否则仅计算到当前行 |
| 窗口聚合类 | SUM() | 计算窗口内指定列的累计 / 整体总和 | 保留原表行数,区别于 GROUP BY 的 "合并行聚合";加 ORDER BY 为累计求和,不加为分组整体求和 |
| 窗口聚合类 | AVG() | 计算窗口内指定列的累计 / 整体平均值 | 加 ORDER BY 为累计平均,不加为分组整体平均 |
| 窗口聚合类 | COUNT() | 统计窗口内的行数 / 指定列非空值数量 | COUNT (*) 统计所有行,COUNT (列名) 排除 NULL 值;加 ORDER BY 为累计计数 |
| 窗口聚合类 | MAX() | 计算窗口内指定列的累计 / 整体最大值 | 加 ORDER BY 为 "到当前行的最大值",不加为分组整体最大值 |
| 窗口聚合类 | MIN() | 计算窗口内指定列的累计 / 整体最小值 | 加 ORDER BY 为 "到当前行的最小值",不加为分组整体最小值 |
619.只出现一次的最大数字
620.有趣的电影
627.变更性别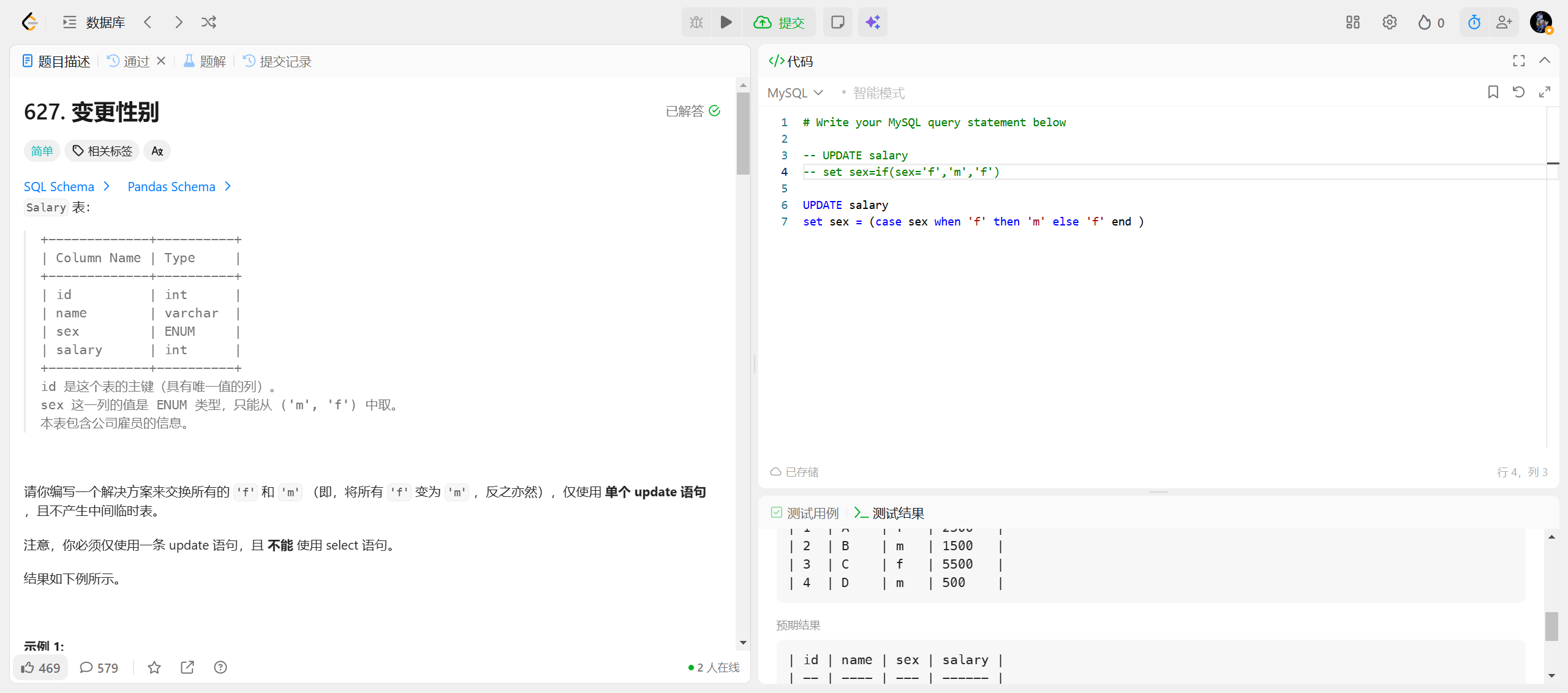
IF(条件, 结果1, 结果2)
sql
CASE 字段名
WHEN 取值1 THEN 结果1
WHEN 取值2 THEN 结果2
...
ELSE 默认结果 -- 可选,无匹配时返回 NULL
END1050.合作过至少三次的演员和导演 ***
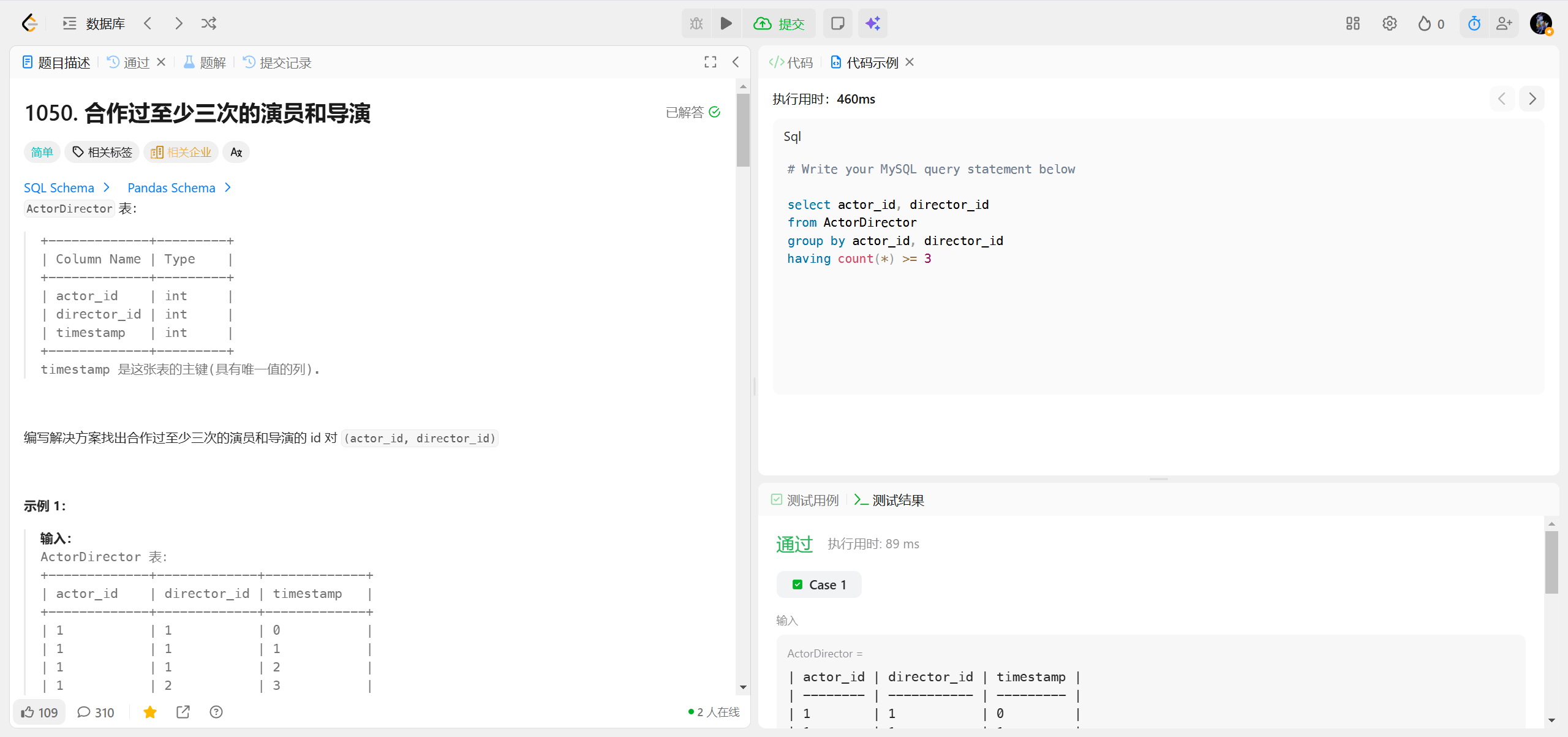
GROUP BY支持同时对多个字段分组,分组逻辑是「字段组合值相同则归为一组」;SELECT中查询的字段,要么是GROUP BY后的分组字段,要么是被聚合函数(如 SUM/COUNT/AVG)包裹的字段;
1068.产品销售分析Ⅰ
1069.产品销售分析Ⅱ
1075.项目员工 I
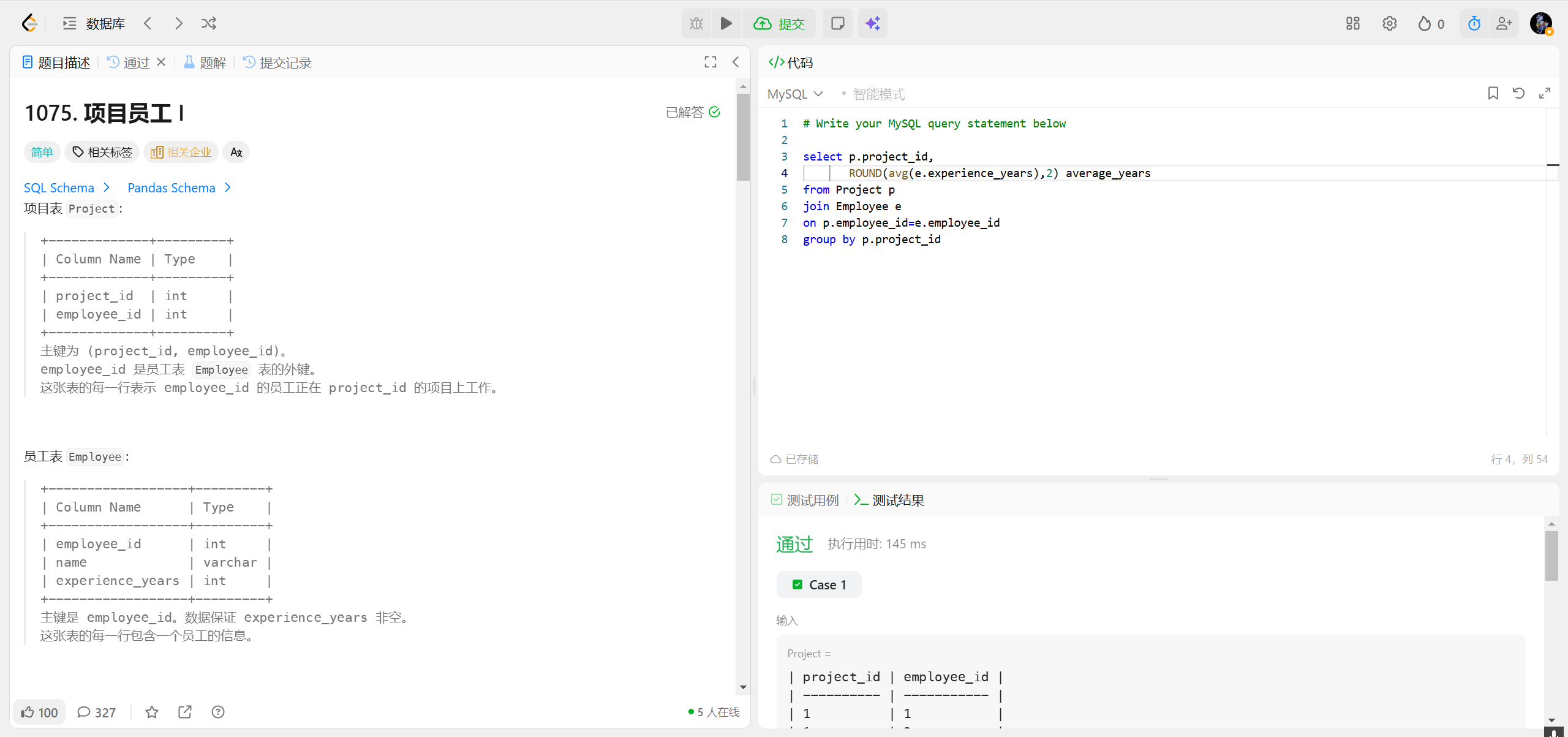
1076.项目员工Ⅱ
1082.销售分析| ***
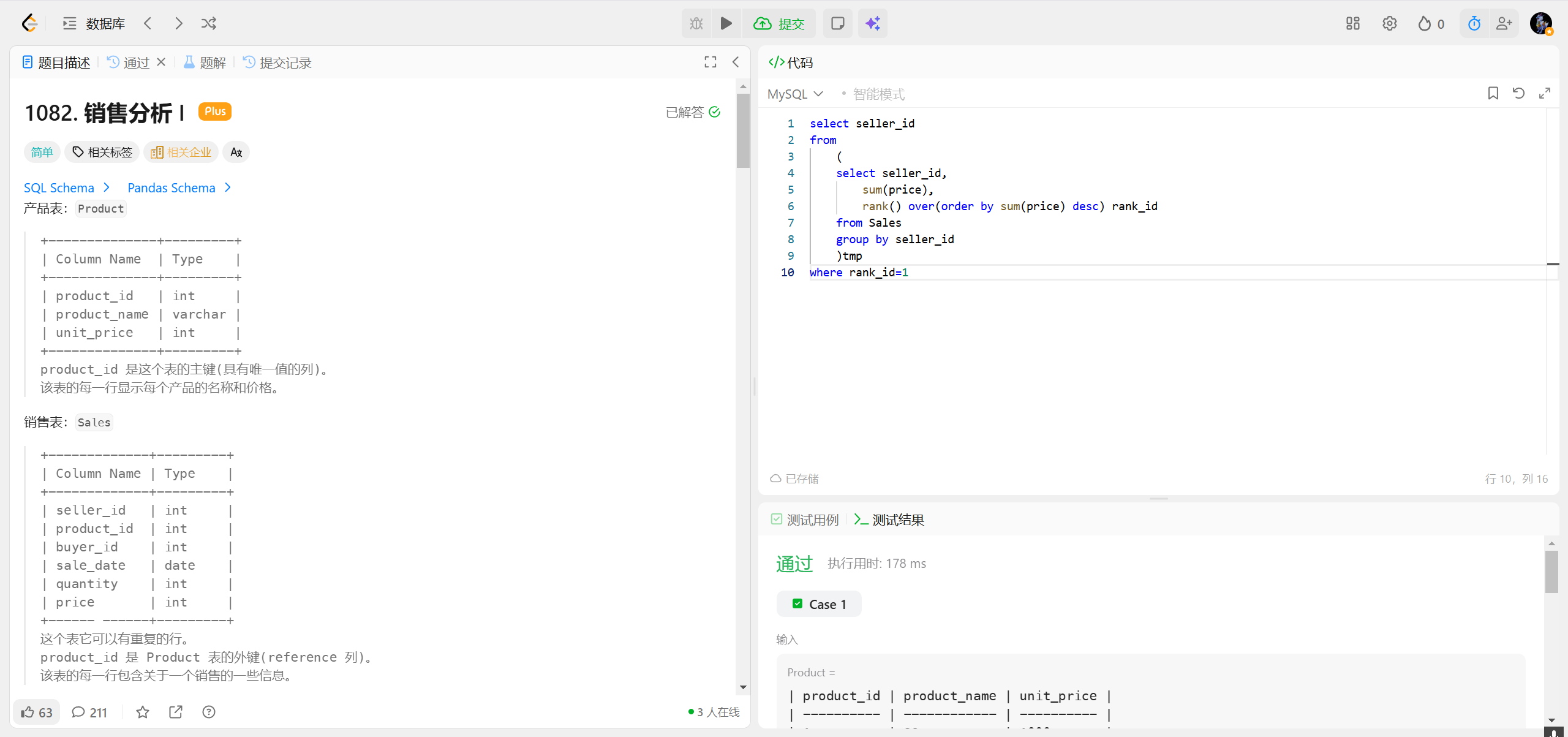
RANK()函数核心定义
RANK() 是窗口排名函数 ,作用是:在指定的窗口(或全局)内,根据ORDER BY的规则为每行数据分配一个排名值,支持并列排名,且并列后会跳过后续排名。
简单说:如果有 2 个第 1 名,下一个就是第 3 名(而非第 2 名)。
| seller_id | total_sales | sales_rank | |
|---|---|---|---|
| 1 | 2800 | 1 | |
| 3 | 2800 | 1 | -- 与 seller_id=1 并列第 1 |
| 2 | 800 | 3 | -- 跳过 2,直接排 3 |
1083.销售分析Ⅱ
1084.销售分析Ⅲ
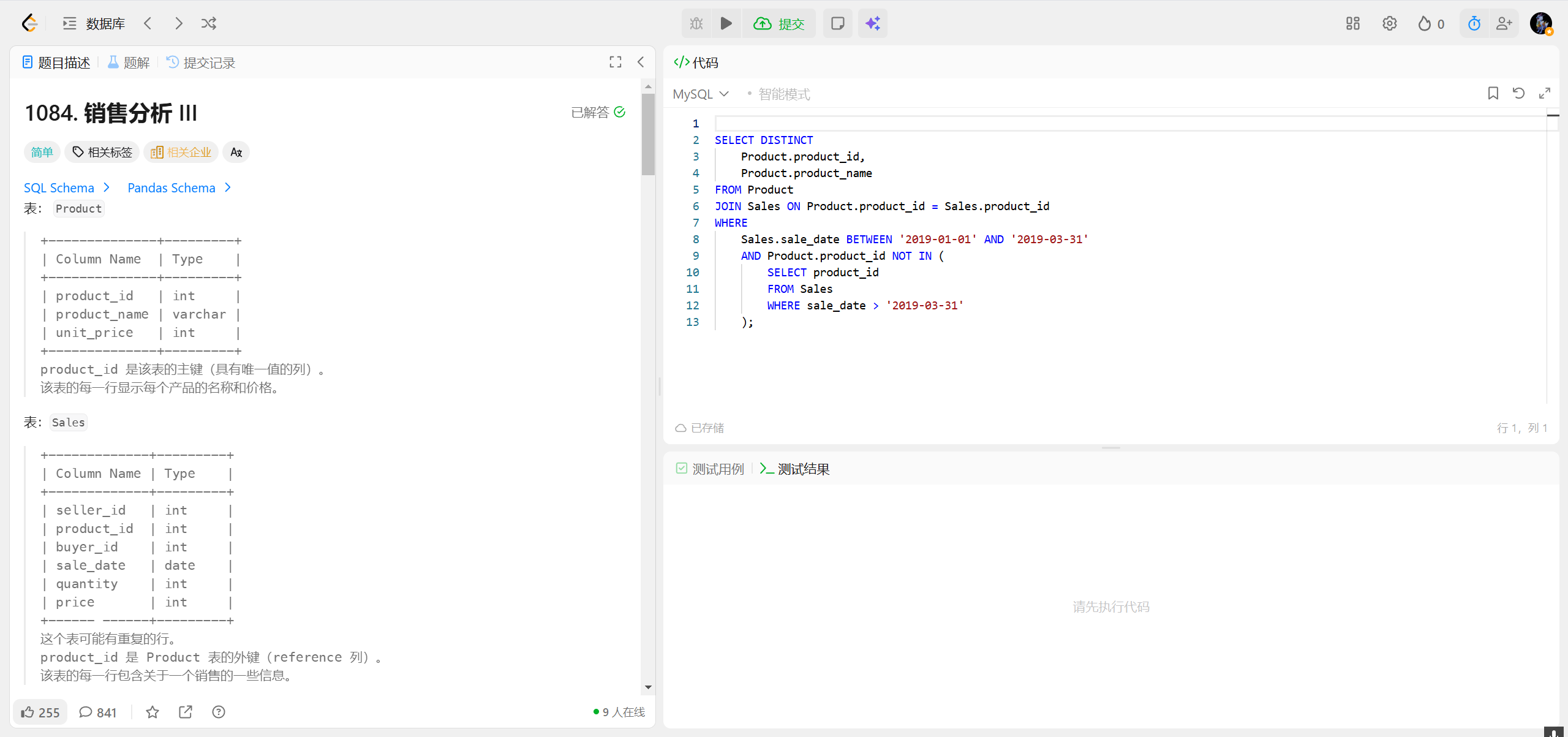
1113.报告的记录
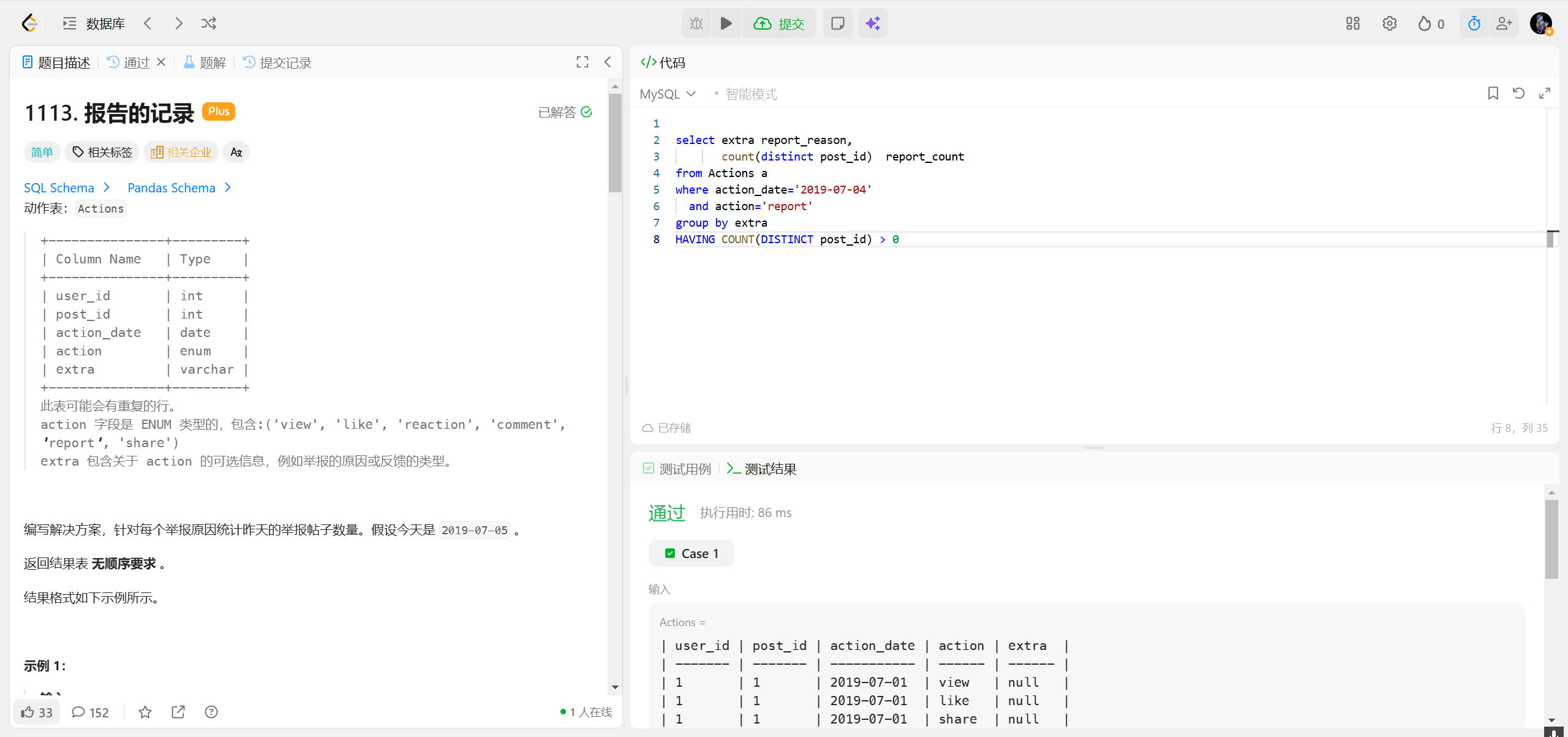
1141.查询近30天活跃用户数 ***
关键逻辑:
DATEDIFF('2019-07-27', activity_date)计算的是「2019-07-27 - activity_date」的天数,2019-08-25 的话,这个值是 负数 (因为 2019-08-25 在 2019-07-27 之后),所以会满足<30,但这些日期本就不在统计范围内。
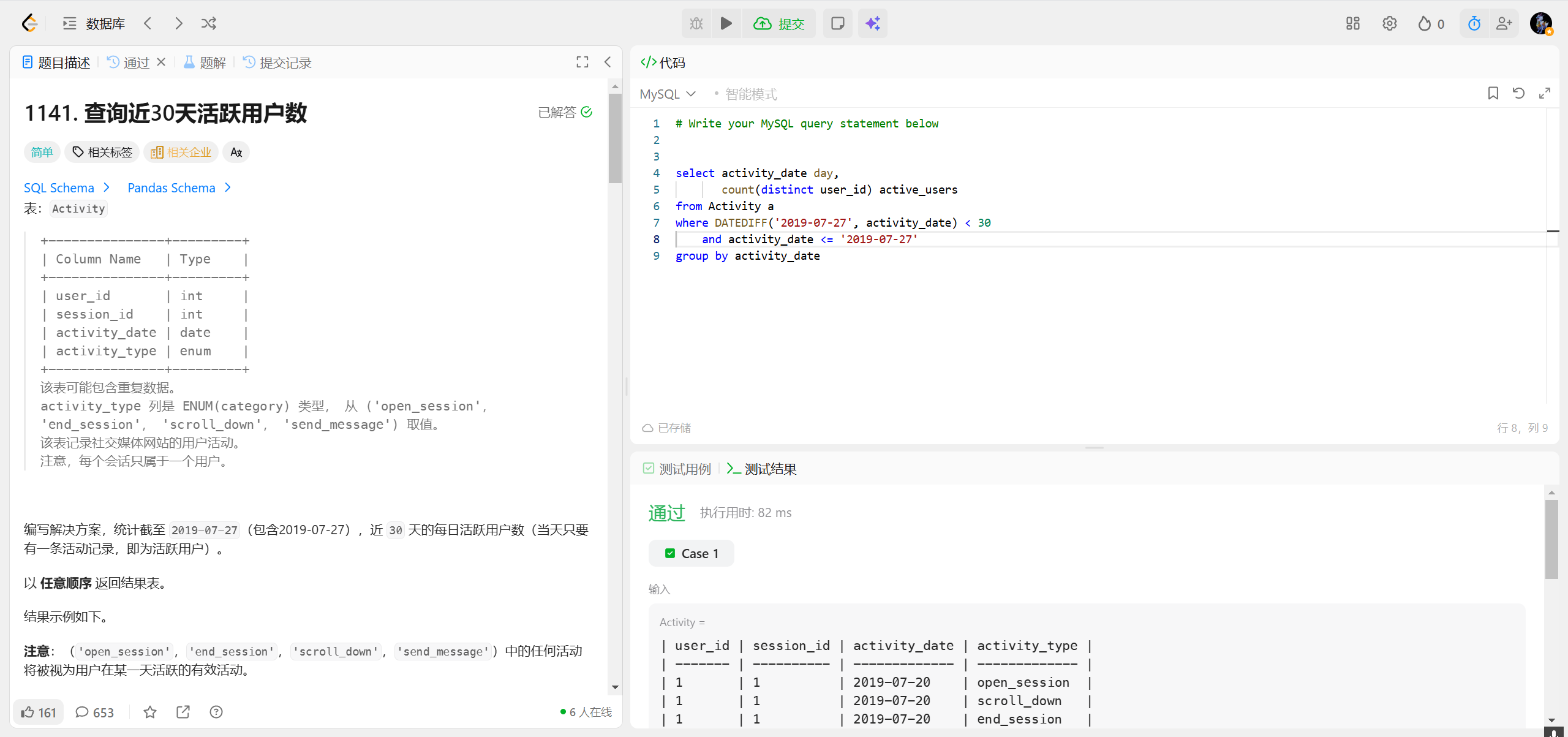
1142.过去30天的用户活动 ***
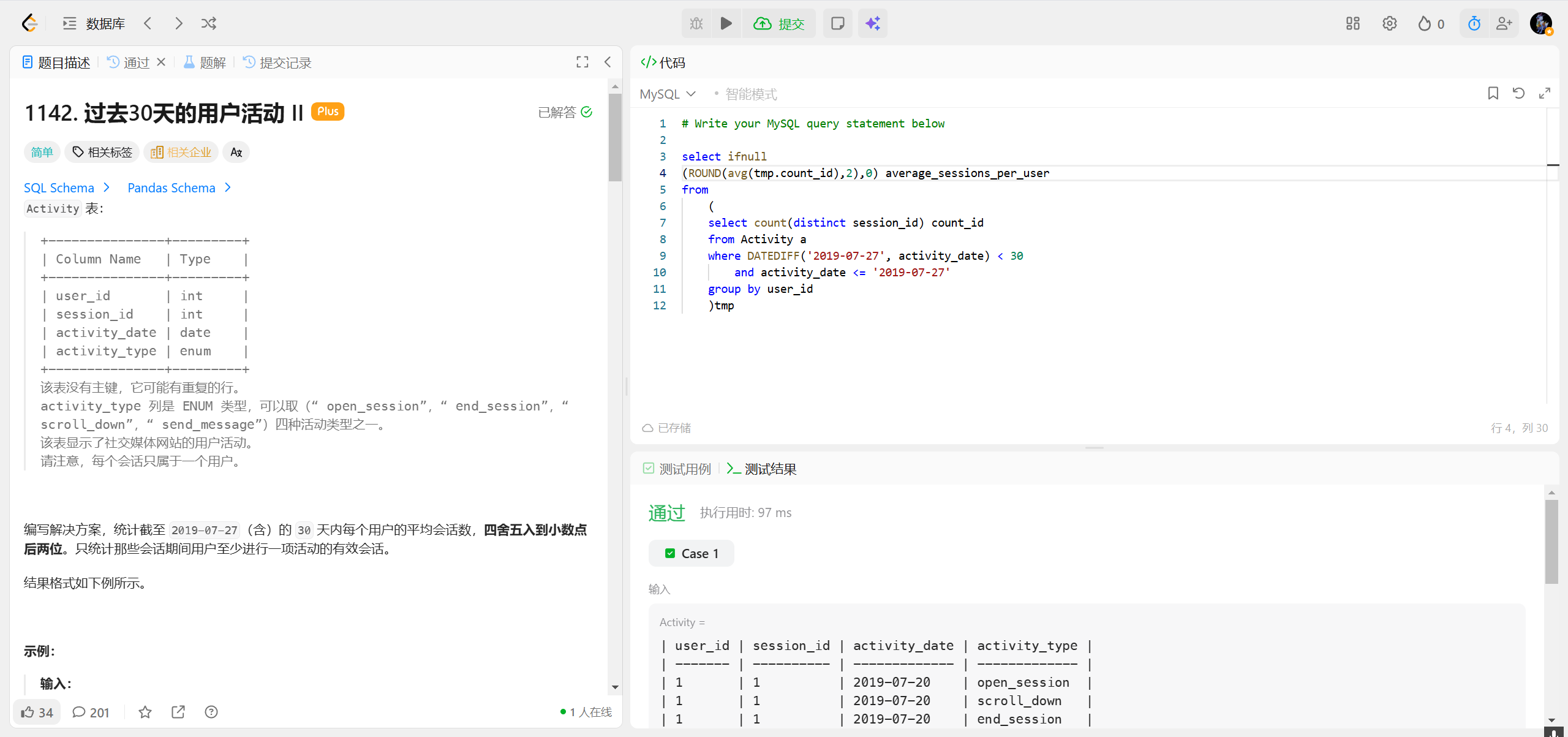
| 函数 | 核心作用 | 语法格式 | 支持数据库 |
|---|---|---|---|
IF |
通用条件判断(类似 if-else) | IF(条件, 真值, 假值) |
MySQL/MariaDB |
IFNULL |
如果表达式为null替换为默认值 | IFNULL(表达式, 默认值) |
MySQL/MariaDB |
COALESCE |
如果前面几个值都为空用最后一个值 | COALESCE(值1, 值2, ..., 值N) |
所有主流数据库 |
1148.文章浏览Ⅰ
1173.即时食物配送|
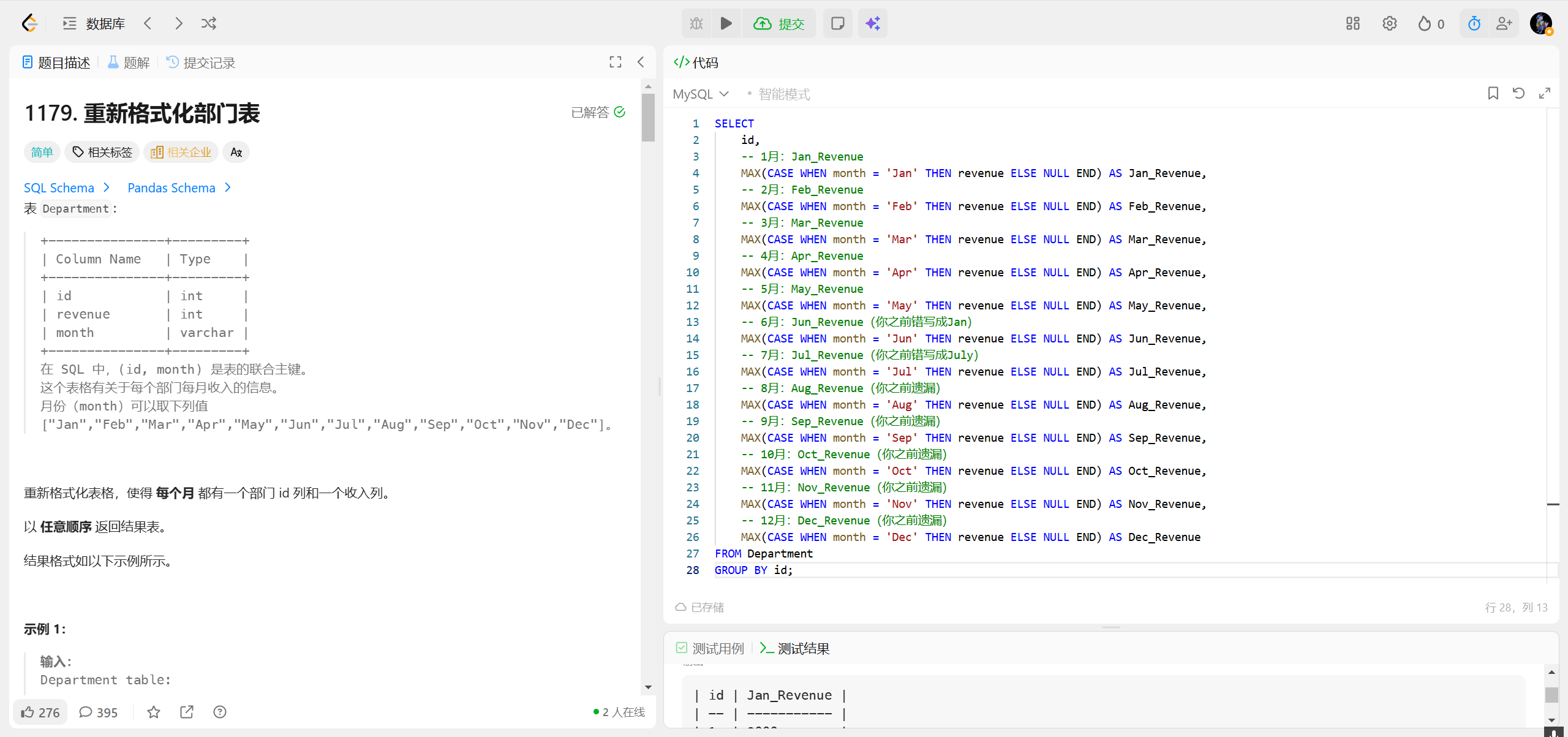
1179.重新格式化部门表 ***
关键代码解释
- GROUP BY id:确保每个部门只保留一行数据(因为一个部门可能有多个月份的记录,分组后会把同一部门的所有行合并为一行);
- MAX () 函数 (CASE WHEN 版本):分组后需要聚合函数收尾,
MAX()会取非 NULL 的 revenue 值(因为同一部门同一月份只有一条记录,MAX/ MIN/ SUM 效果都一样)。
1211.查询结果的质量和占比 ***
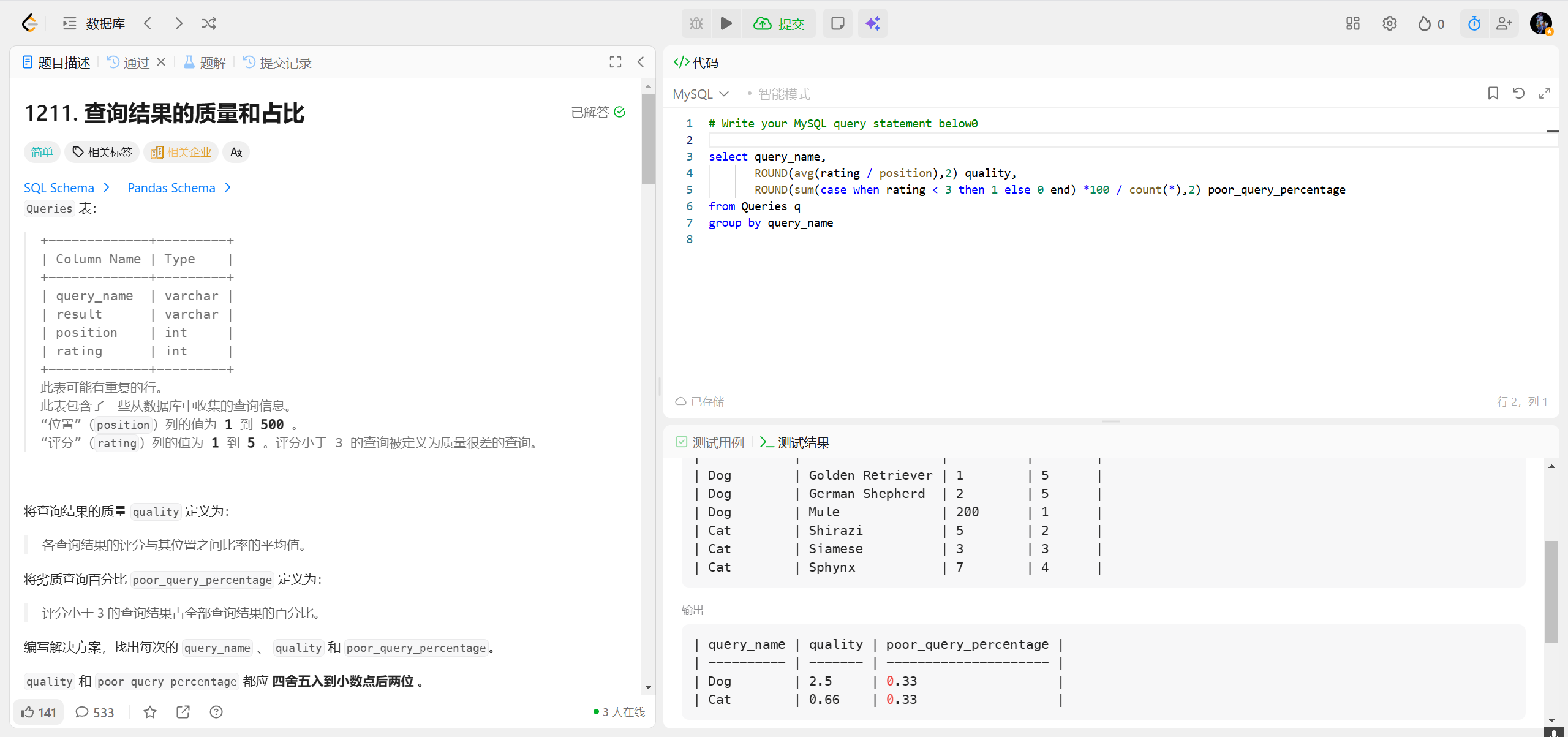
错误:CASE rating when rating < 3 是语法错误 CASE 有两种写法,你混淆了:
• ❌ 错误写法:CASE 字段 WHEN 条件表达式 THEN ...(这种写法只支持「字段 = 值」的等值判断,不支持 </> 这类比较);
• ✅ 正确写法:CASE WHEN 条件表达式 THEN ...(支持所有条件判断,包括 </>/=)。
1241.每个帖子的评论数 ***
COUNT (*):统计所有行(包括 NULL 行)
COUNT (s2.sub_id):只统计 s2.sub_id 非 NULL 的行
1251.平均售价
1280.学生们参加各科测试的次数 ***
多表联查 的核心是通过「关联字段」(主键 / 外键 / 业务唯一字段),把多个表的信息整合到一起,本质就是你之前理解的:两两连接生成临时表,再和下一个表连接(3 表及以上都是 "两步两表联查" 的延伸)。
1294.不同国家的天气类型 ***
LIKE 的核心定义
LIKE 是 SQL 中用于字符串模糊匹配 的运算符,只能用于CHAR/VARCHAR/TEXT等字符类型字段(DATE/DATETIME 类型也可匹配,因为会隐式转换为字符串),语法:
字段名 LIKE '匹配模式'
-- 反向匹配(不满足模式)
字段名 NOT LIKE '匹配模式'| 通配符 | 含义 | 示例 | 匹配结果 |
|---|---|---|---|
% |
匹配任意长度的任意字符(0 个 / 1 个 / 多个) | '2019-11-%' |
2019-11-01、2019-11-30、2019-11-abc |
_ |
匹配单个任意字符 | '2019-11-_ _' |
2019-11-01、2019-11-30(仅两位日期) |
- 通配符只能用单引号包裹的匹配模式里,不能单独用;
- 无通配符时,
LIKE等价于=(精准匹配)
1303.求团队人数 ***
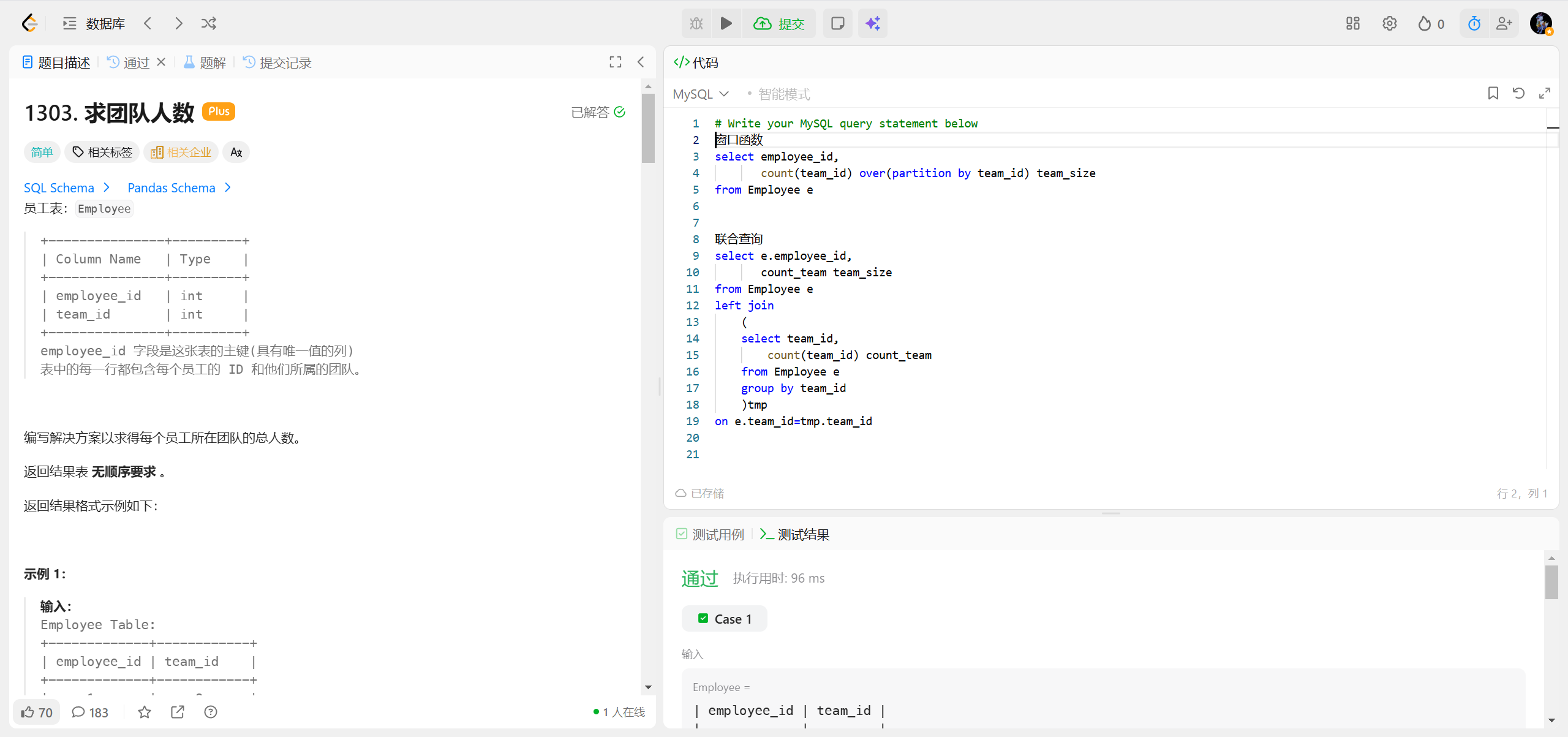
窗口函数 count(team_id) COUNT(*) over(partition by team_id) team_size
OVER (PARTITION BY team_id):这是窗口函数 的核心,作用是 "按team_id分组,但不聚合整行 "------ 也就是说,不会像GROUP BY那样只返回每个分组的一行,而是为每一行(每个员工)都添加上其所属分组的统计结果;ORDER BY重点:核心作用是给每个分组内的行排序,进而改变窗口函数的统计逻辑
1322.广告效果 ***
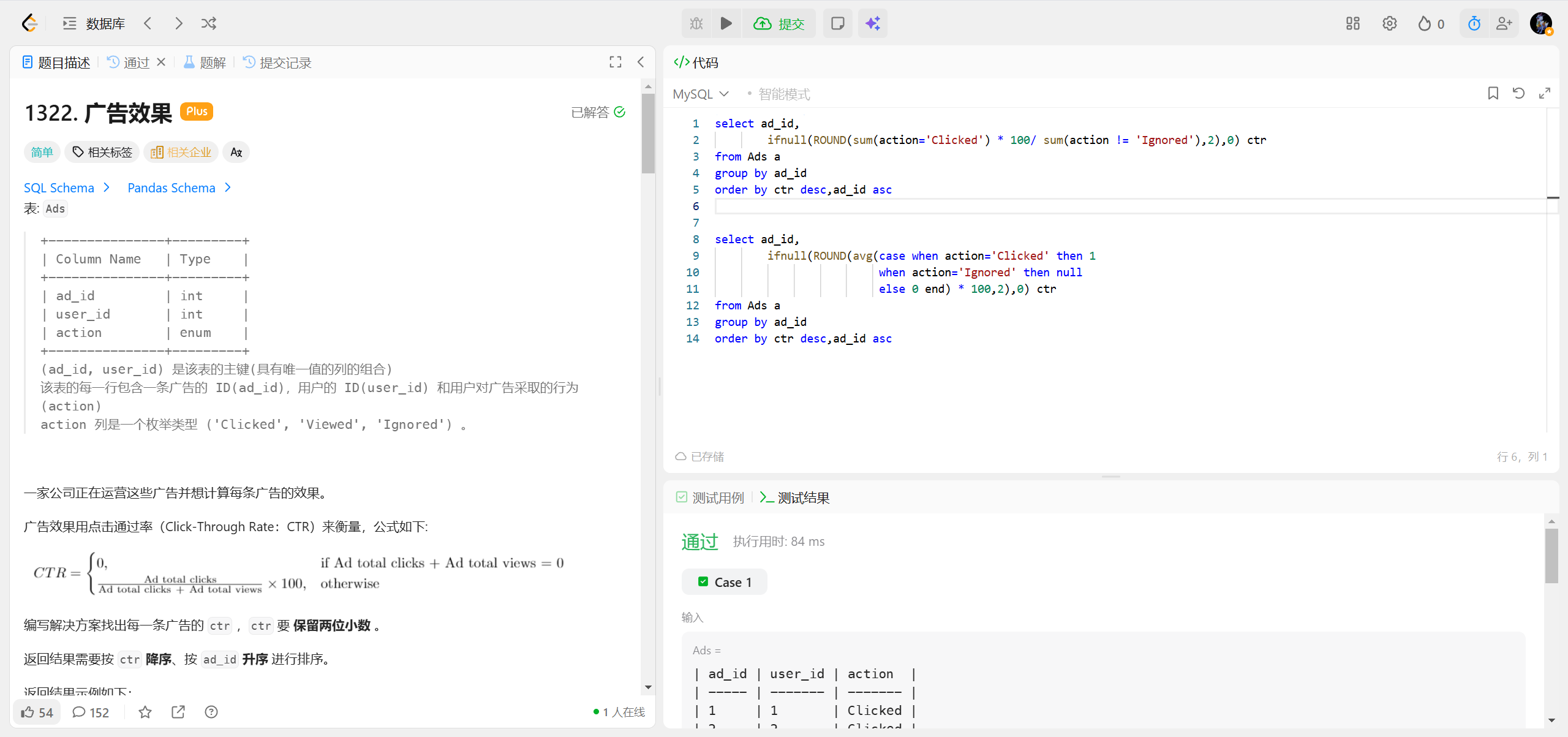
在 SQL 的聚合函数(比如 SUM)里确实可以直接写条件表达式,这是一种非常实用且常见的写法,能帮你省去很多子查询或 CASE WHEN 的冗余代码。
1327.列出指定时间段内所有的下单产品 ***
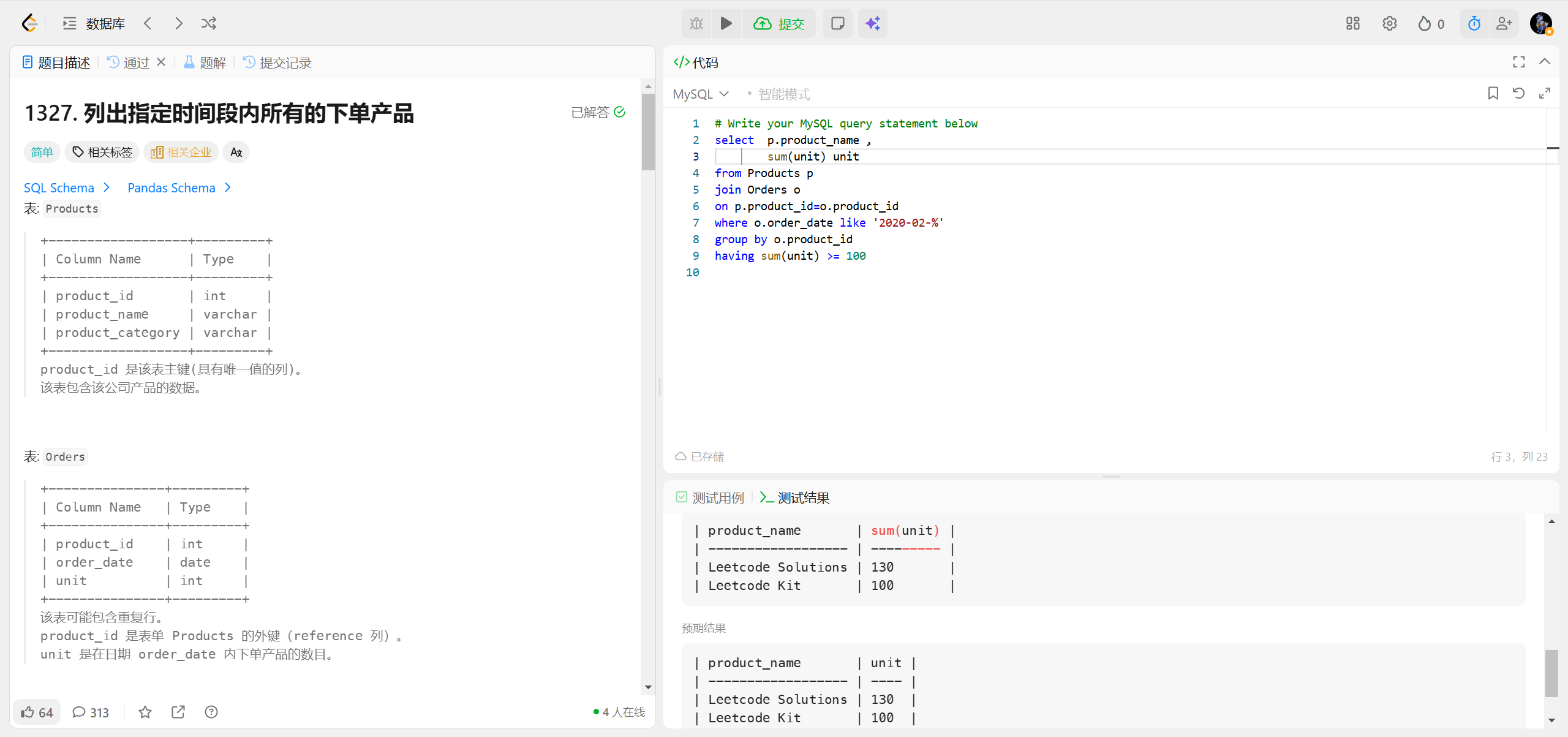

1350.院系无效的学生
1378.使用唯一标识码替换员工ID
1407.排名靠前的旅行者
1421.净现值查询
1435.制作会话柱状图
1484.按日期分组销售产品
STRING_AGG 和 GROUP_CONCAT 核心区别(极简版)
归属与兼容性: ◦ STRING_AGG:标准 SQL 函数,支持 PostgreSQL、SQL Server、MySQL 8.0.19+; ◦ GROUP_CONCAT:MySQL/MariaDB 专属,低版本 MySQL(5.7 及以下)唯一选择,其他数据库不支持。
语法与默认值: ◦ STRING_AGG:必须手动指定分隔符(如 ','),否则报错; ◦ GROUP_CONCAT:默认分隔符为逗号,可省略 SEPARATOR 关键字。
长度限制: ◦ STRING_AGG:无内置长度限制,仅受字段类型 / 数据库配置影响; ◦ GROUP_CONCAT:默认限制 1024 字符,需手动调整 group_concat_max_len 避免截断。
1495.上月播放的儿童适宜电影
1511.消费者下单频率 ***
这段代码的核心逻辑可浓缩为 3 个关键点:
-
分月统计:用CASE WHEN + SUM实现「按客户、按月份」的消费金额统计;
-
双重条件:AND确保客户 6 月和 7 月消费都≥100(区别于 "或" 的逻辑);
-
表关联兜底:LEFT JOIN Product避免产品无价格时丢失订单数据。
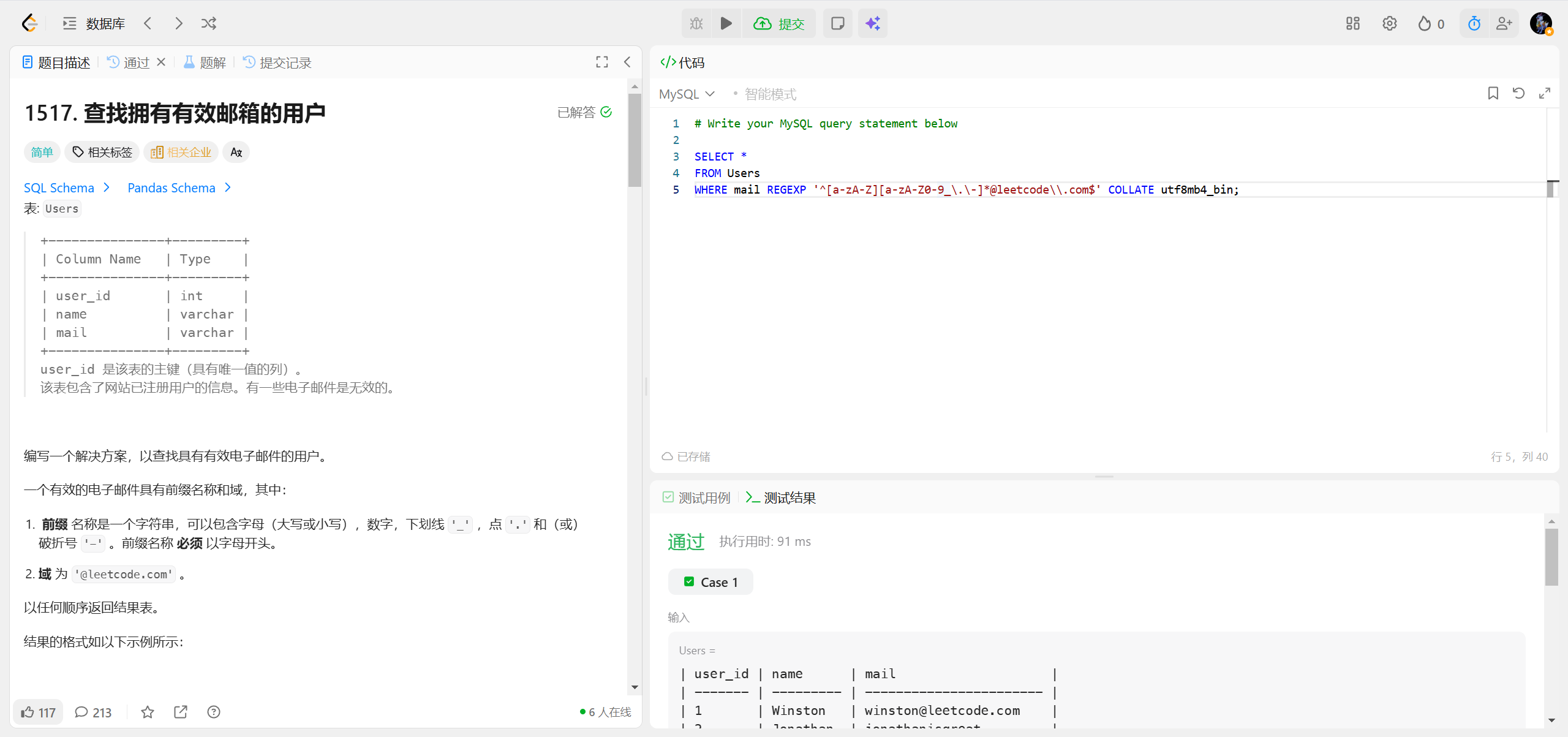
1517.查找拥有有效邮箱的用户 ***

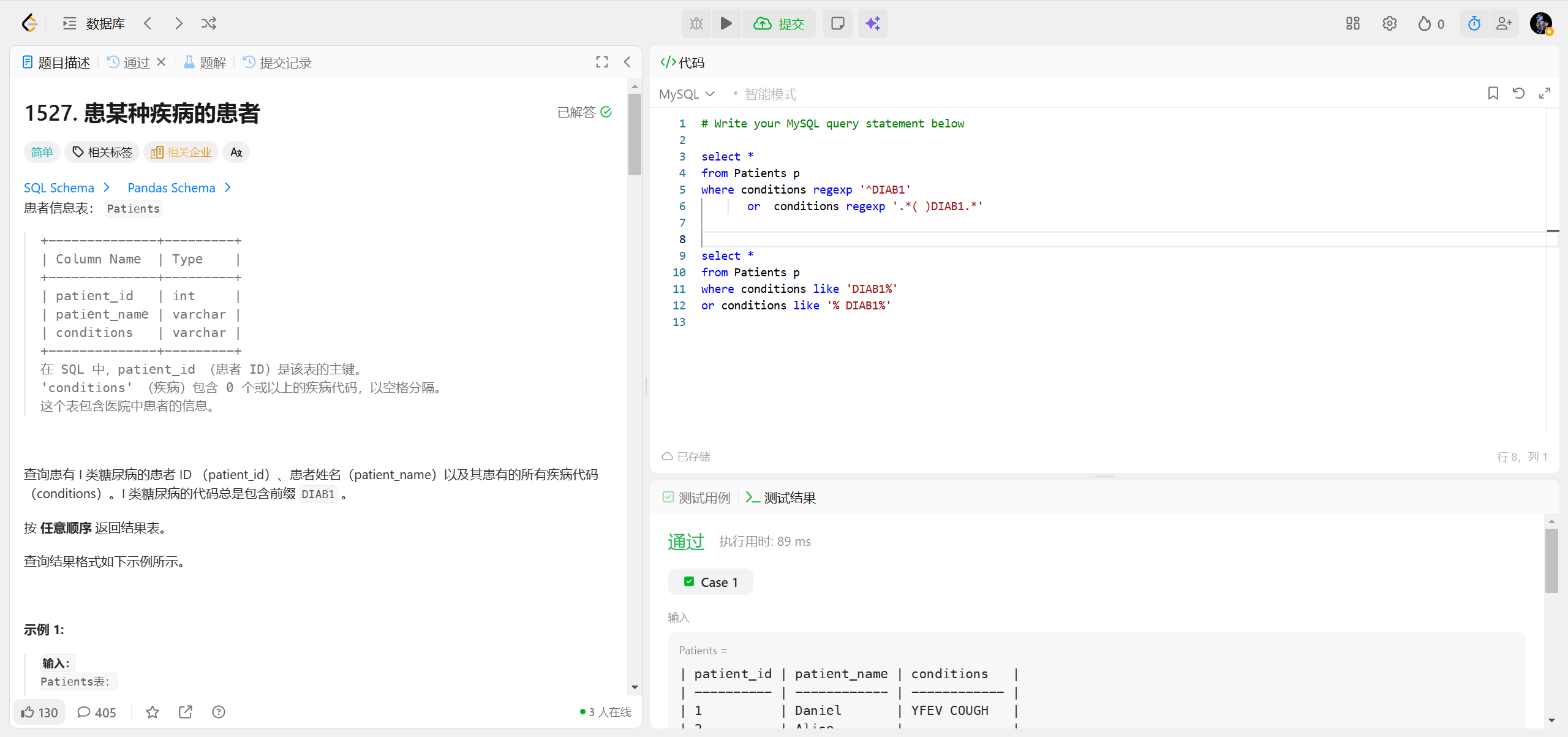
1527.患某种疾病的患者
1543.产品名称格式修复 ***
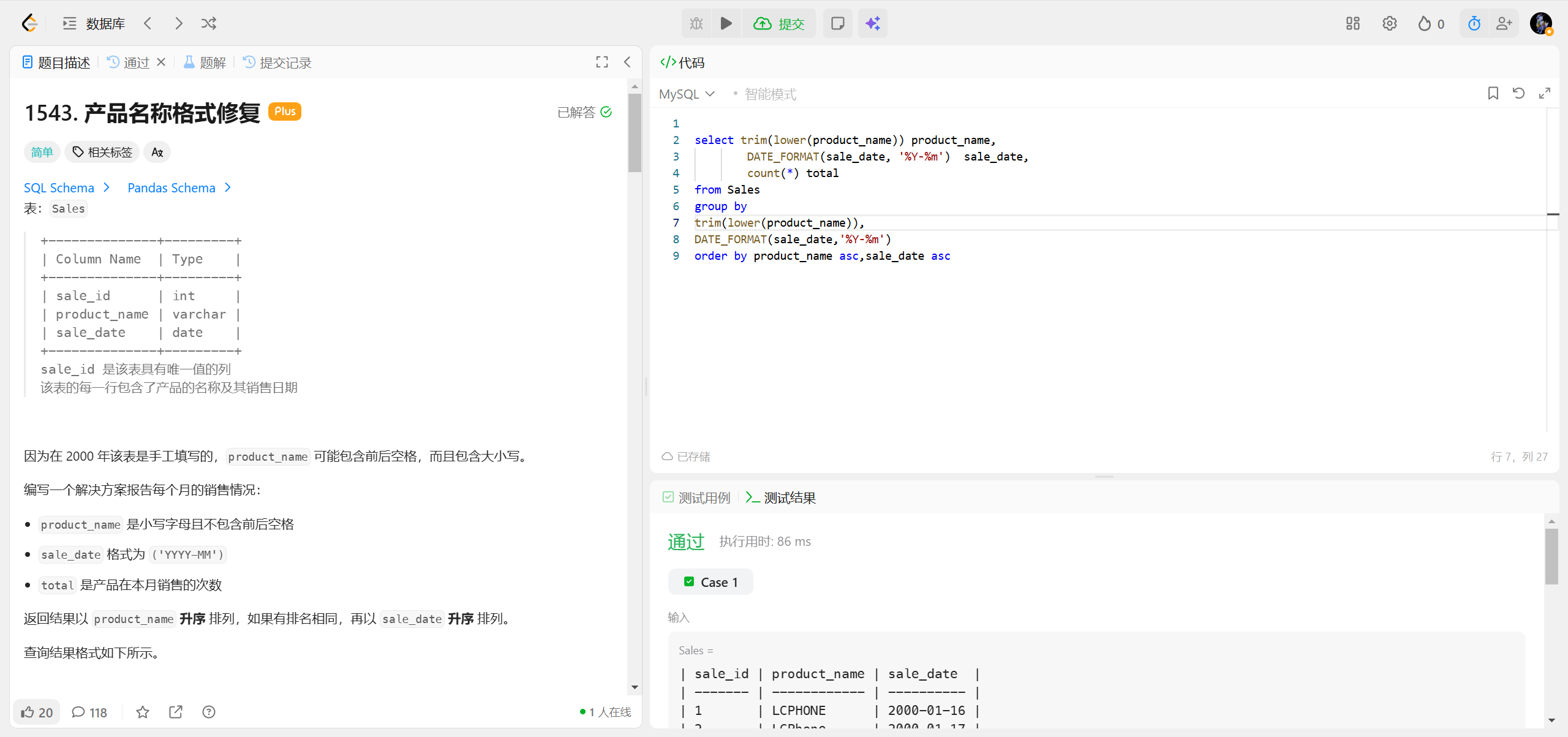
代码关键部分解释
| 函数 / 语法 | 作用 |
|---|---|
TRIM(LOWER(product_name)) |
LOWER() 把产品名转为全小写,TRIM() 去除名称前后的空格(示例中无空格但需兼容) |
DATE_FORMAT(sale_date, '%Y-%m') |
将 YYYY-MM-DD 格式的日期转为 YYYY-MM 格式 |
核心结论:函数在 GROUP BY/ORDER BY 中的使用规则
| 子句 | 是否可以用函数 / 表达式 | 关键说明 |
|---|---|---|
GROUP BY |
✅ 可以 | 分组的本质是 "按计算后的结果分组",函数处理后的字段和普通字段无区别 |
ORDER BY |
✅ 可以 | 排序的依据可以是计算后的结果,甚至可以用 SELECT 里的别名(GROUP BY 通常不建议) |
1565.按月统计订单数与顾客数
1571.仓库经理
1581.进店却未进行过交易的顾客
1587.银行账户概要Ⅱ
1607.没有卖出的卖家
1623.三人国家代表队
1633.各赛事的用户注册率
1661.每台机器的进程平均运行时间
1667.修复表中的名字 ***
| 函数名 | 核心作用 | 基础语法 | 注意事项 |
| CONCAT | 拼接多个字符串 / 字段为一个新字符串 | CONCAT (字符串 1, 字符串 2, ...) | 任意一个参数为 NULL,结果就为 NULL |
| LEFT | 从字符串左侧截取指定长度字符 | LEFT (字符串,截取长度) | 截取长度超过字符串总长度时,返回原字符串 |
| RIGHT | 从字符串右侧截取指定长度字符 | RIGHT (字符串,截取长度) | 同 LEFT,长度超总长度返回原字符串 |
| UPPER | 将字符串全部转为大写字母 | UPPER (字符串) | 仅对字母生效,数字 / 符号保持不变 |
| LOWER | 将字符串全部转为小写字母 | LOWER (字符串) | 仅对字母生效,数字 / 符号保持不变 |
| LENGTH | 获取字符串的字符长度 | LENGTH (字符串) | 中文字符长度:MySQL 占 3 字符,Oracle 占 1 字符 |
|---|
1677.发票中的产品金额
问题分析
- 分组字段错误 :
group by i.product_id会导致「无发票记录的产品」被过滤(因为i.product_id为 NULL),违背LEFT JOIN保留左表所有数据的初衷,应该按左表的p.product_id分组。 - 字段引用不完整 :
sum(paid)实际应为sum(i.paid),虽然部分数据库允许简写,但显式指定表别名更规范,也能避免多表字段重名的问题。
1683.无效的推文 ***
| 函数名 | 核心作用 | 基础语法 | 注意事项 |
|---|---|---|---|
| CONCAT | 拼接多个字符串 / 字段为一个新字符串 | CONCAT (字符串 1, 字符串 2, ...) | 任意一个参数为 NULL,结果就为 NULL |
| LEFT | 从字符串左侧截取指定长度字符 | LEFT (字符串,截取长度) | 截取长度超过字符串总长度时,返回原字符串 |
| RIGHT | 从字符串右侧截取指定长度字符 | RIGHT (字符串,截取长度) | 同 LEFT,长度超总长度返回原字符串 |
| UPPER | 将字符串全部转为大写字母 | UPPER (字符串) | 仅对字母生效,数字 / 符号保持不变 |
| LOWER | 将字符串全部转为小写字母 | LOWER (字符串) | 仅对字母生效,数字 / 符号保持不变 |
| LENGTH | 获取字符串的字符长度 | LENGTH (字符串) | 中文字符长度:MySQL 占 3 字符,Oracle 占 1 字符 |
1693.每天的领导和合伙人
1729.求关注者的数量
1731.每位经理的下属员工数量
1741.查找每个员工花费的总时间
1757.可回收且低脂的产品
1777.每家商店的产品价格 ***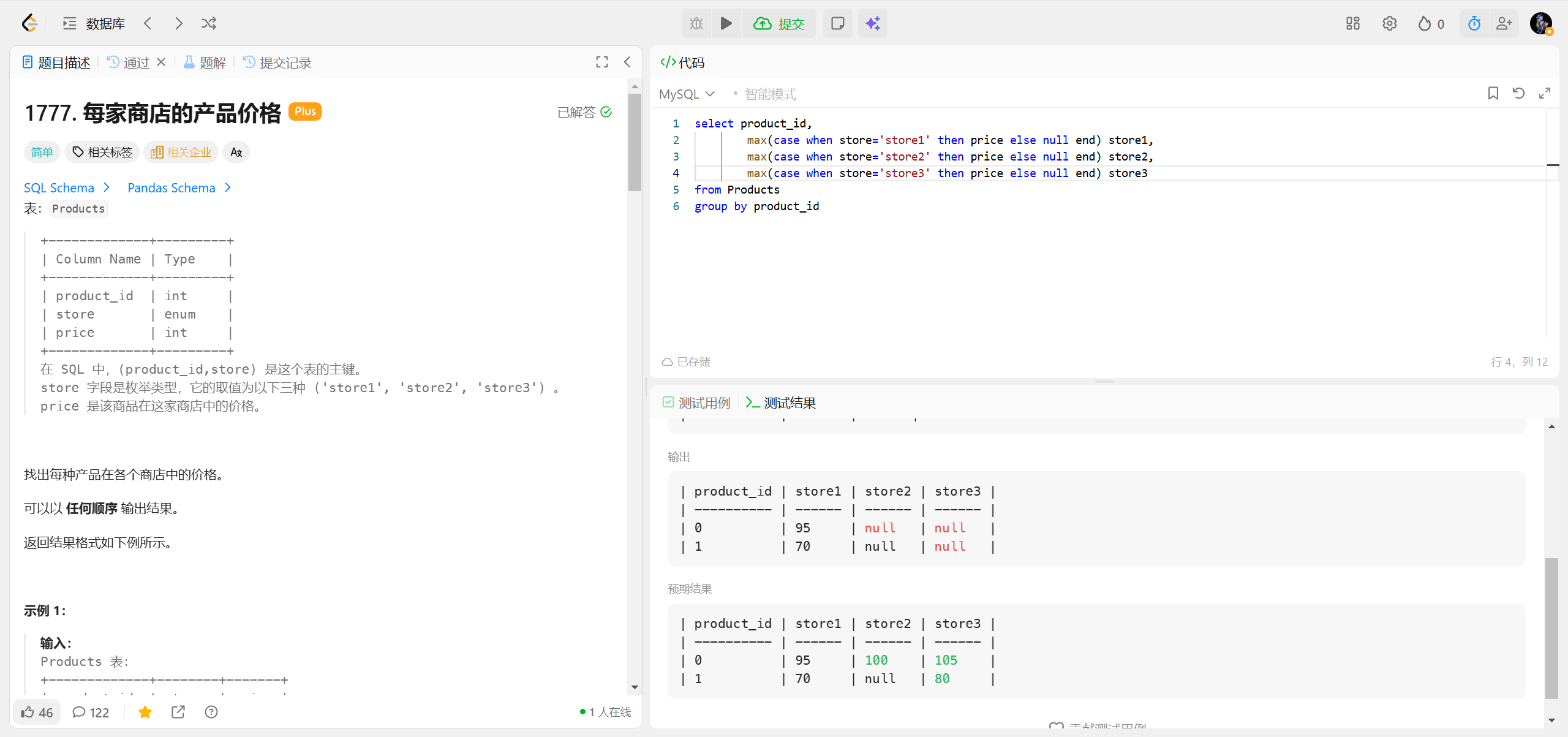
不加 MAX (),查询结果大概率随机且不可控
总结
- 核心结论:不加 MAX () 时,GROUP BY 的查询结果对使用者而言就是随机的,且这个随机结果没有业务价值;
- 关键原因:非分组列缺少聚合规则,数据库只能按底层不可控的规则选值;
- 实践要求:只要用 GROUP BY 做 "数据汇总"(比如你的行转列),就必须搭配 MAX ()/MIN () 等聚合函数,避免随机结果
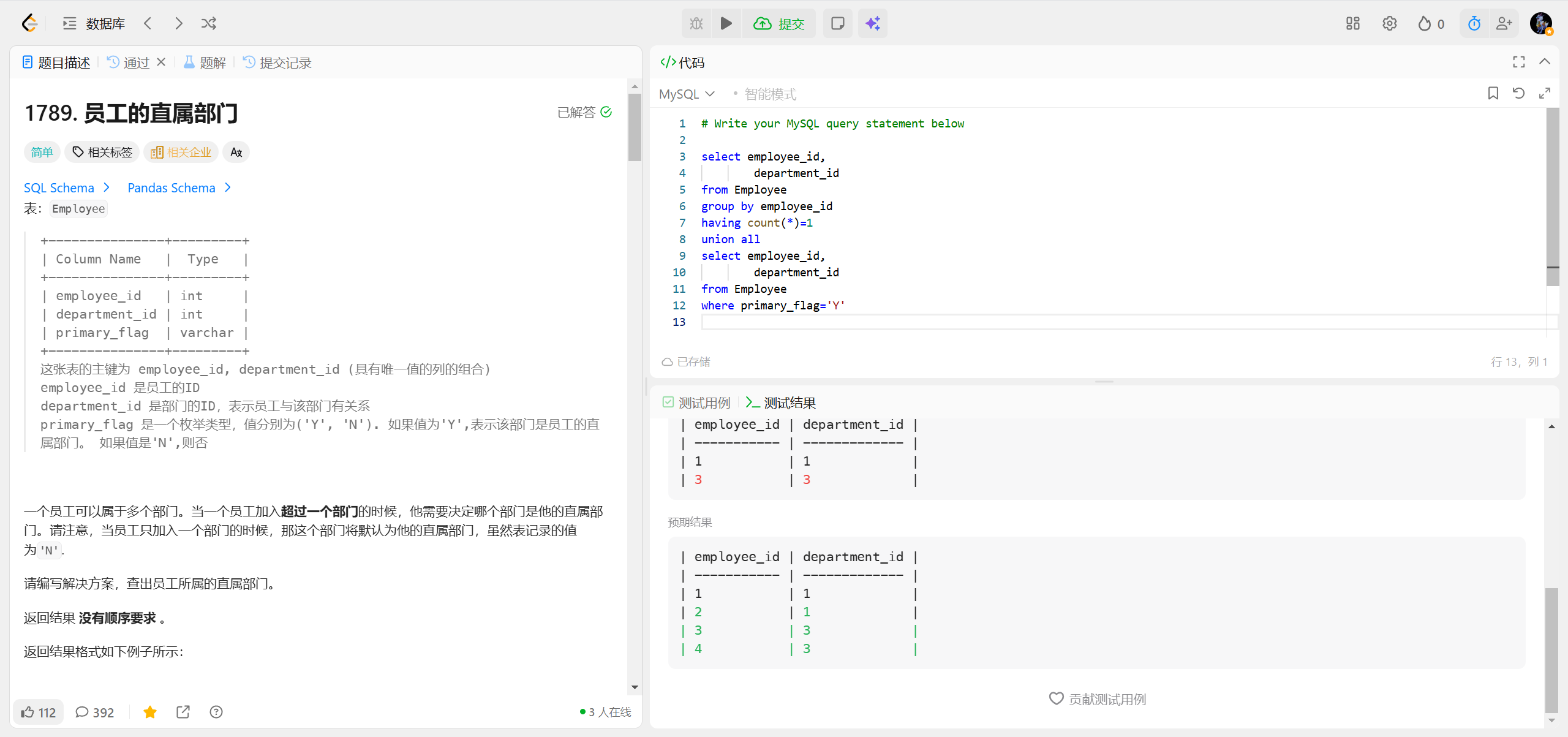
1789.员工的直属部门
1795.每个产品在不同商店的价格 ***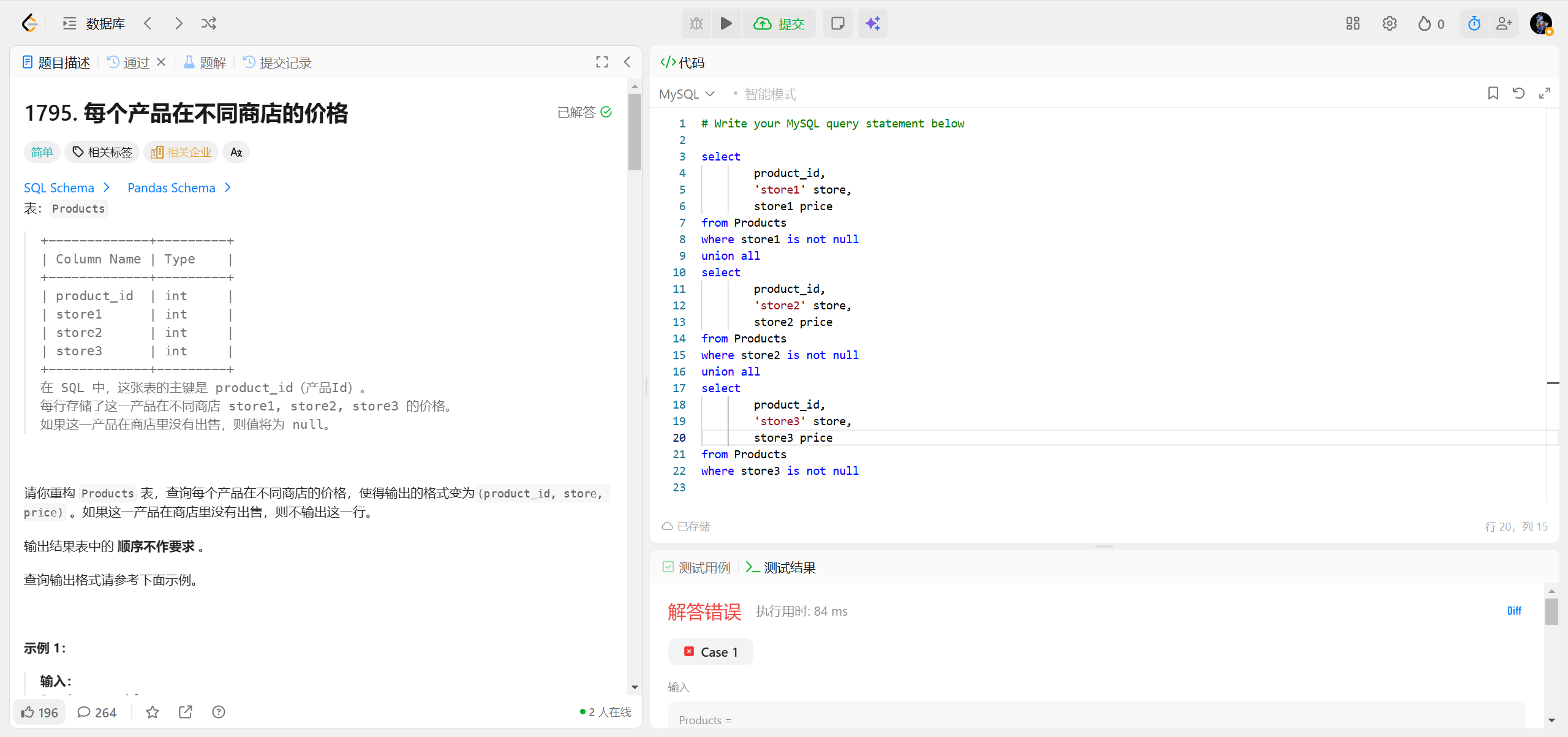
SQL 中 UNION/UNION ALL 要求合并的结果集列名 / 列数 / 列类型必须一致
数据库会以第一个查询的列名作为最终结果的列名
UNION 会对合并后的所有行去重(先排序再去重),而 UNION ALL 只是简单合并所有行(保留重复)
1809.没有广告的剧集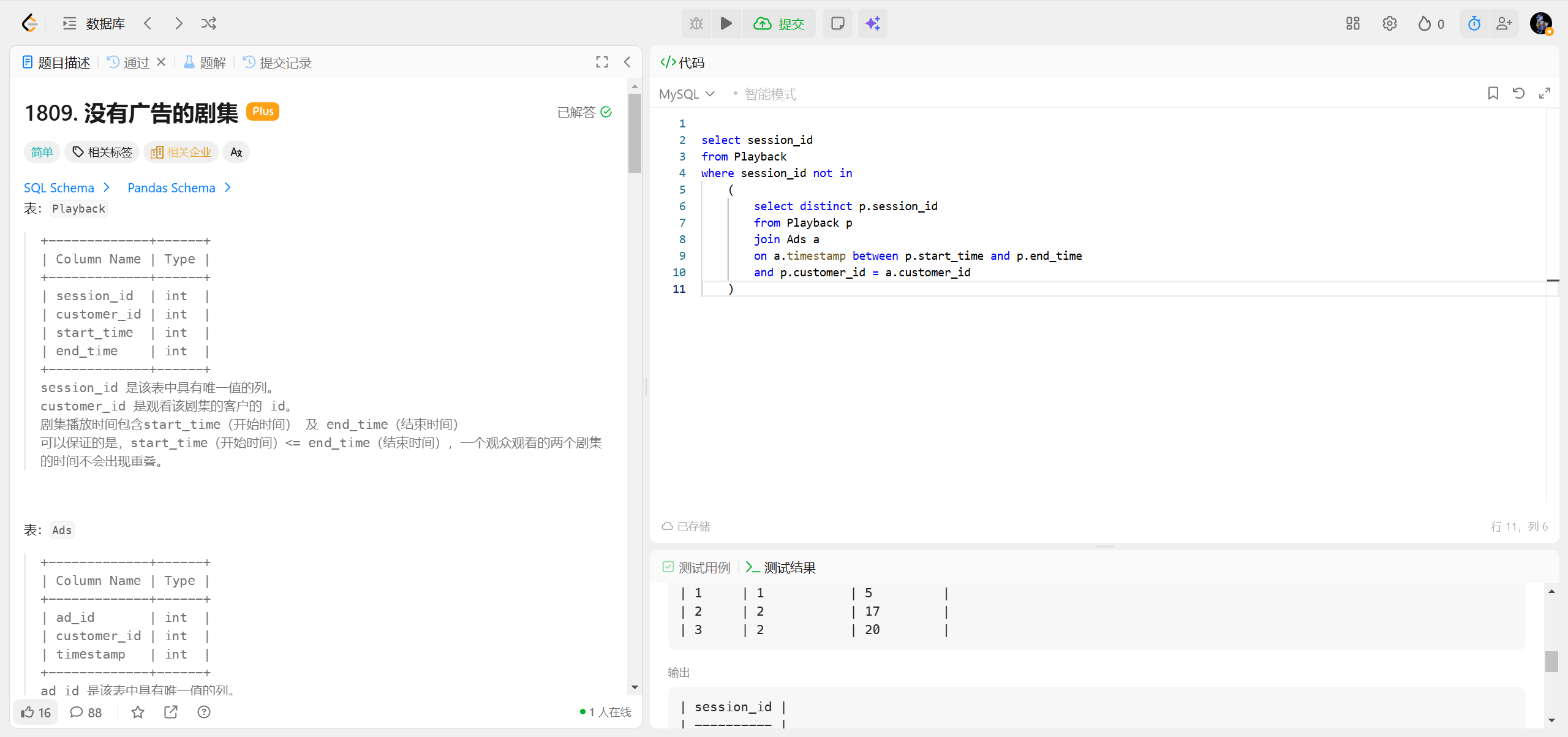
1821.寻找今年具有正收入的客户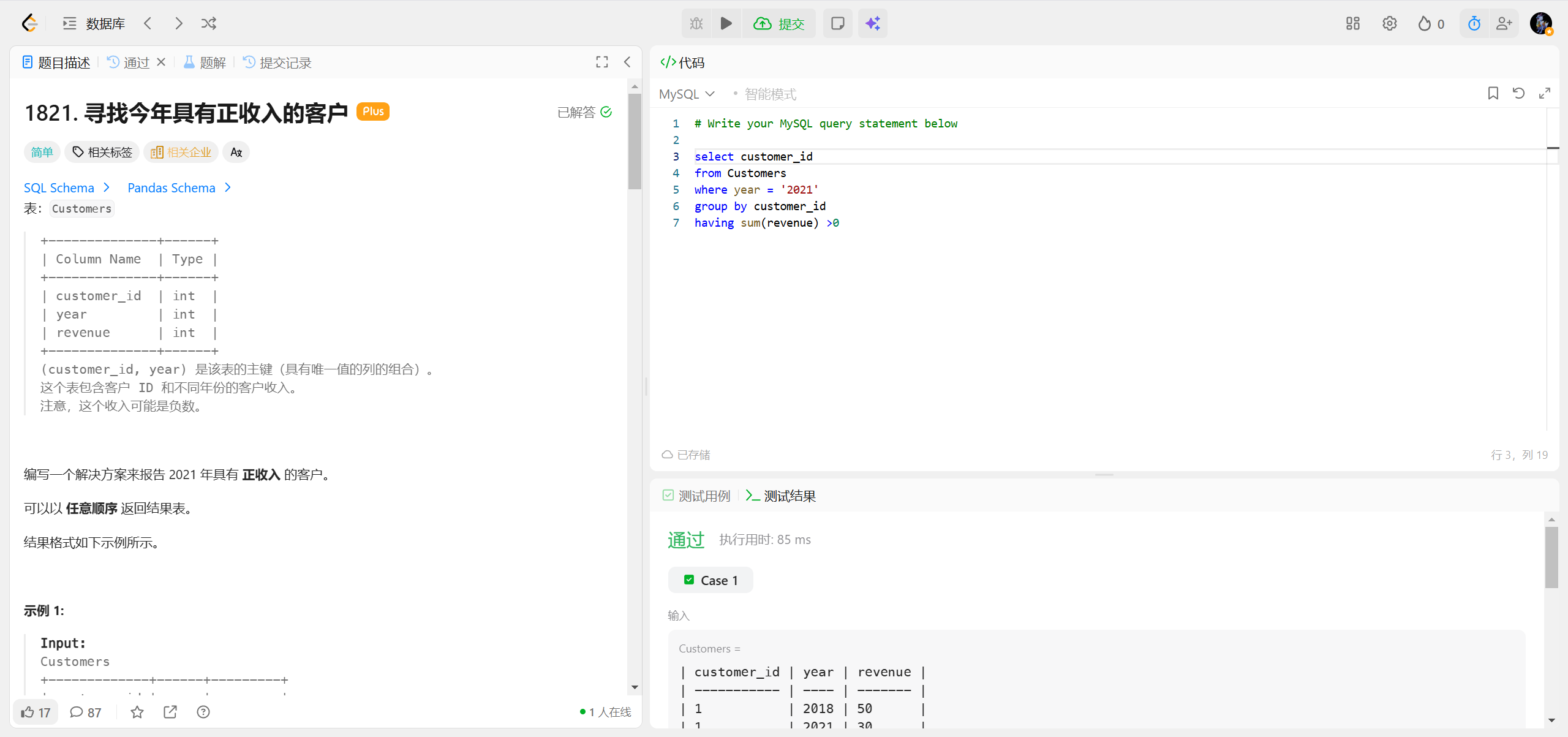
1853.转换日期格式 ***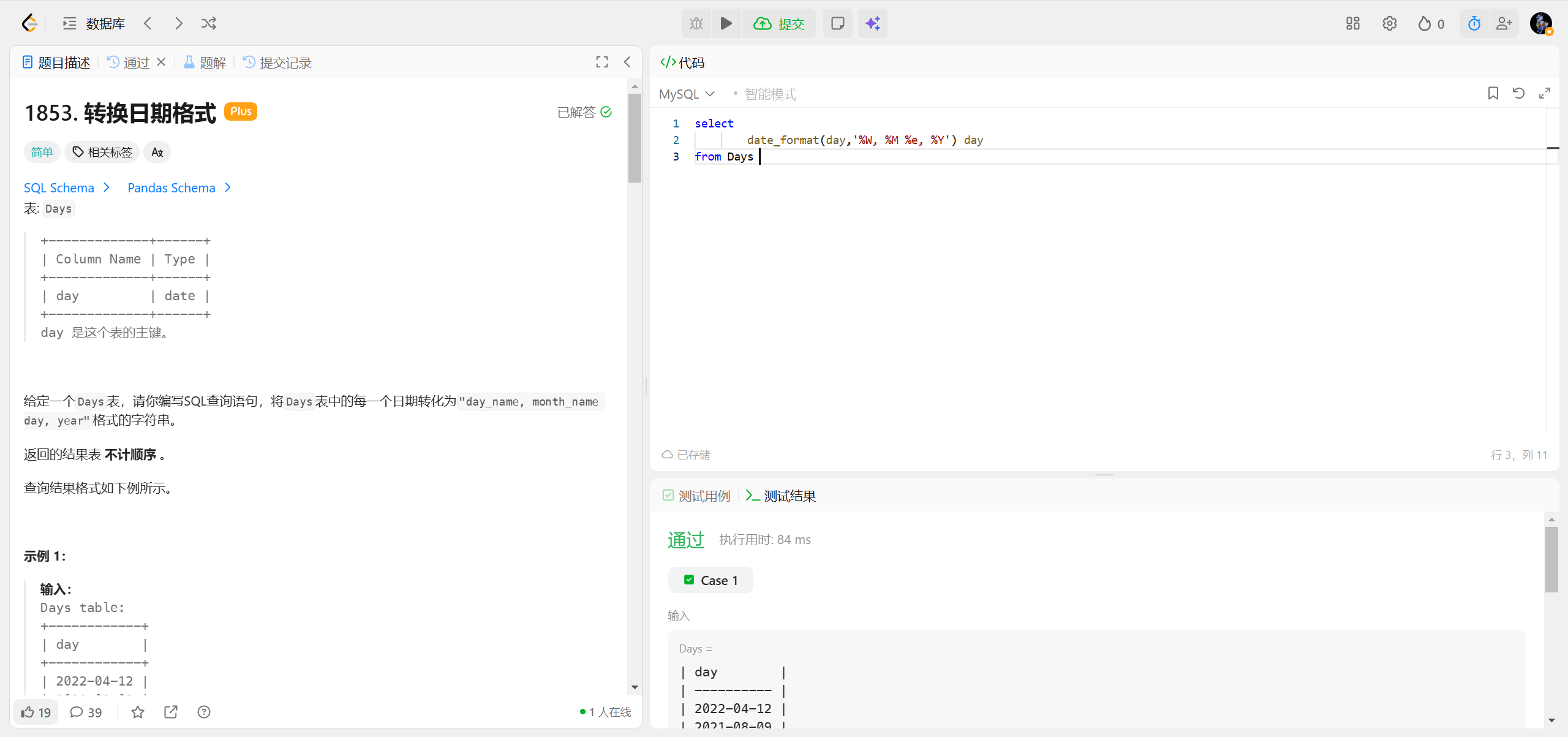
date_format() 函数的完整语法
DATE_FORMAT(date, format)
date:要格式化的日期 / 时间字段(或日期字符串,如 '2026-02-21');format:格式化模板,由占位符 + 自定义字符(比如逗号、空格、横杠)组成,这就是你说的 "参数" 核心。
参数
| 类别 | 占位符 | 含义 | 示例结果 |
|---|---|---|---|
| 年份 | %Y | 4 位完整年份 | 2026 |
| %y | 2 位年份(后两位) | 26 | |
| 月份 | %M | 月份全称(英文) | February |
| %m | 月份(数字,前导 0) | 02 | |
| %b | 月份缩写(英文) | Feb | |
| %c | 月份(数字,无前导 0) | 2 | |
| 日期 | %d | 日期(数字,前导 0) | 21 |
| %e | 日期(数字,无前导 0) | 21 | |
| %D | 日期(带后缀) | 21st | |
| 星期 | %W | 星期全称(英文) | Saturday |
| %w | 星期(数字,0 = 周日) | 6 | |
| %a | 星期缩写(英文) | Sat | |
| 小时 | %H | 24 小时制(前导 0) | 14 |
| %h | 12 小时制(前导 0) | 02 | |
| %k | 24 小时制(无前导 0) | 14 | |
| %l | 12 小时制(无前导 0) | 2 | |
| 分钟 | %i | 分钟(前导 0) | 05 |
| 秒 | %s/%S | 秒(前导 0) | 08 |
| 上午 / 下午 | %p | AM/PM(配合 12 小时制) | PM |
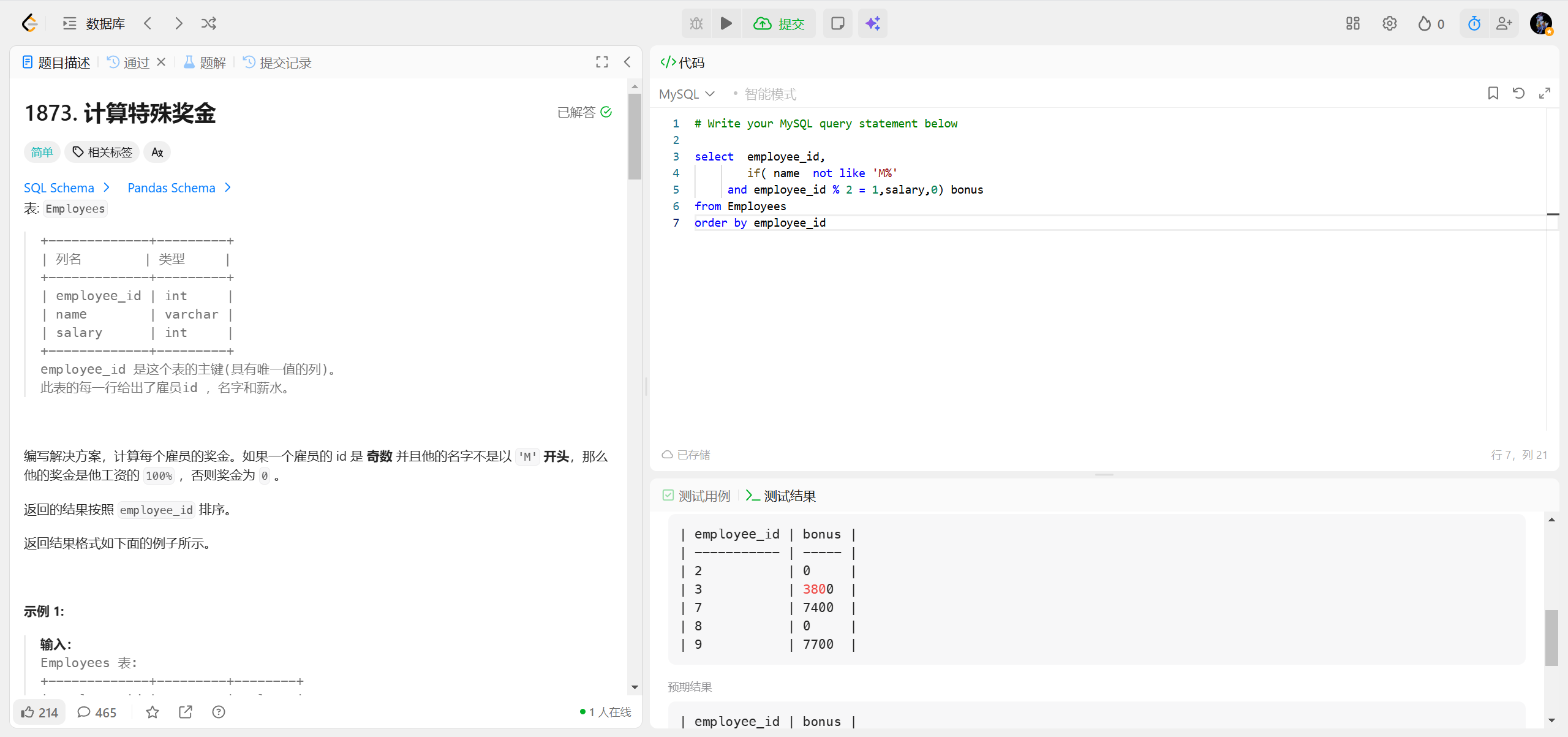
1873.计算特殊奖金
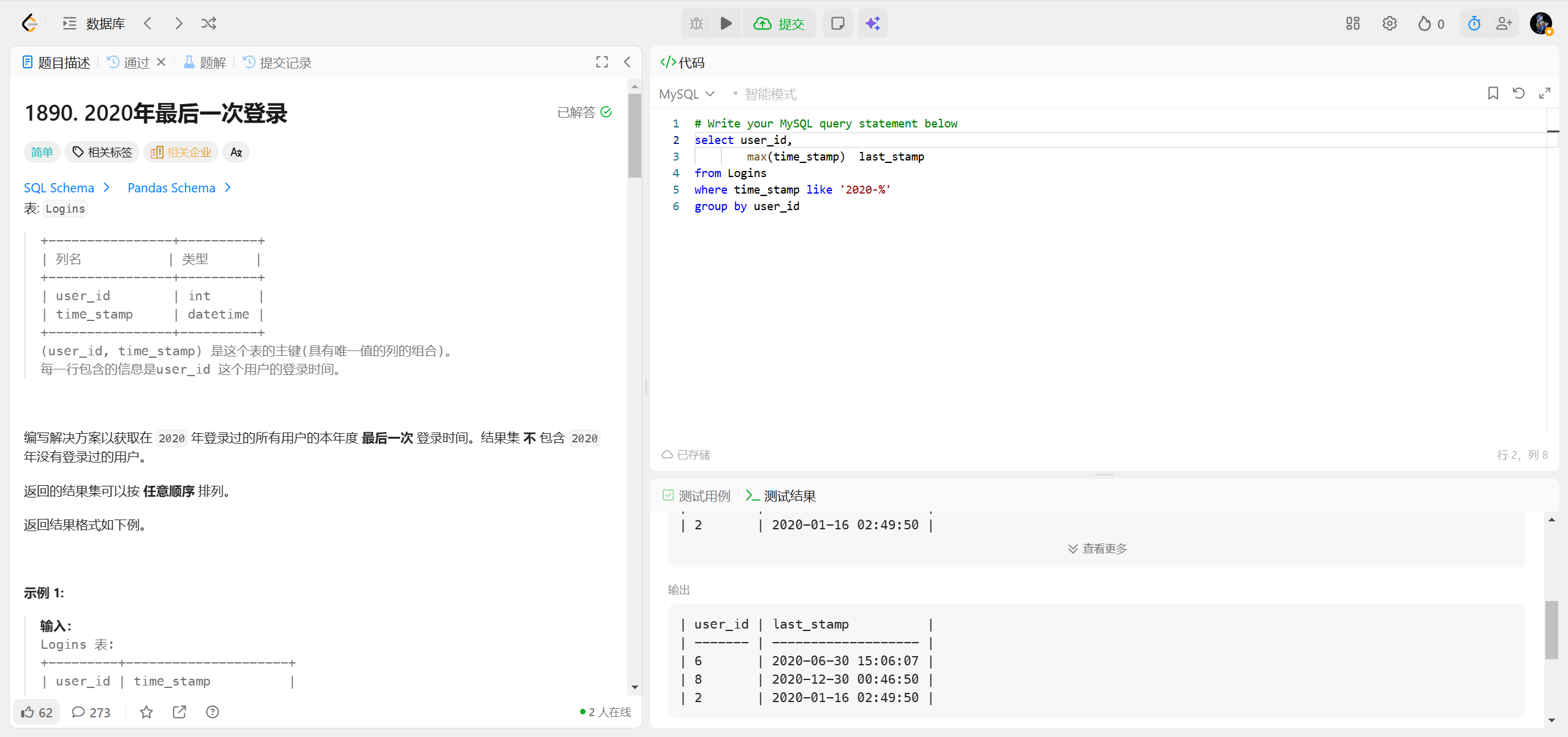
1890.2020年最后一次登录
1939.主动请求确认消息的用户 ***
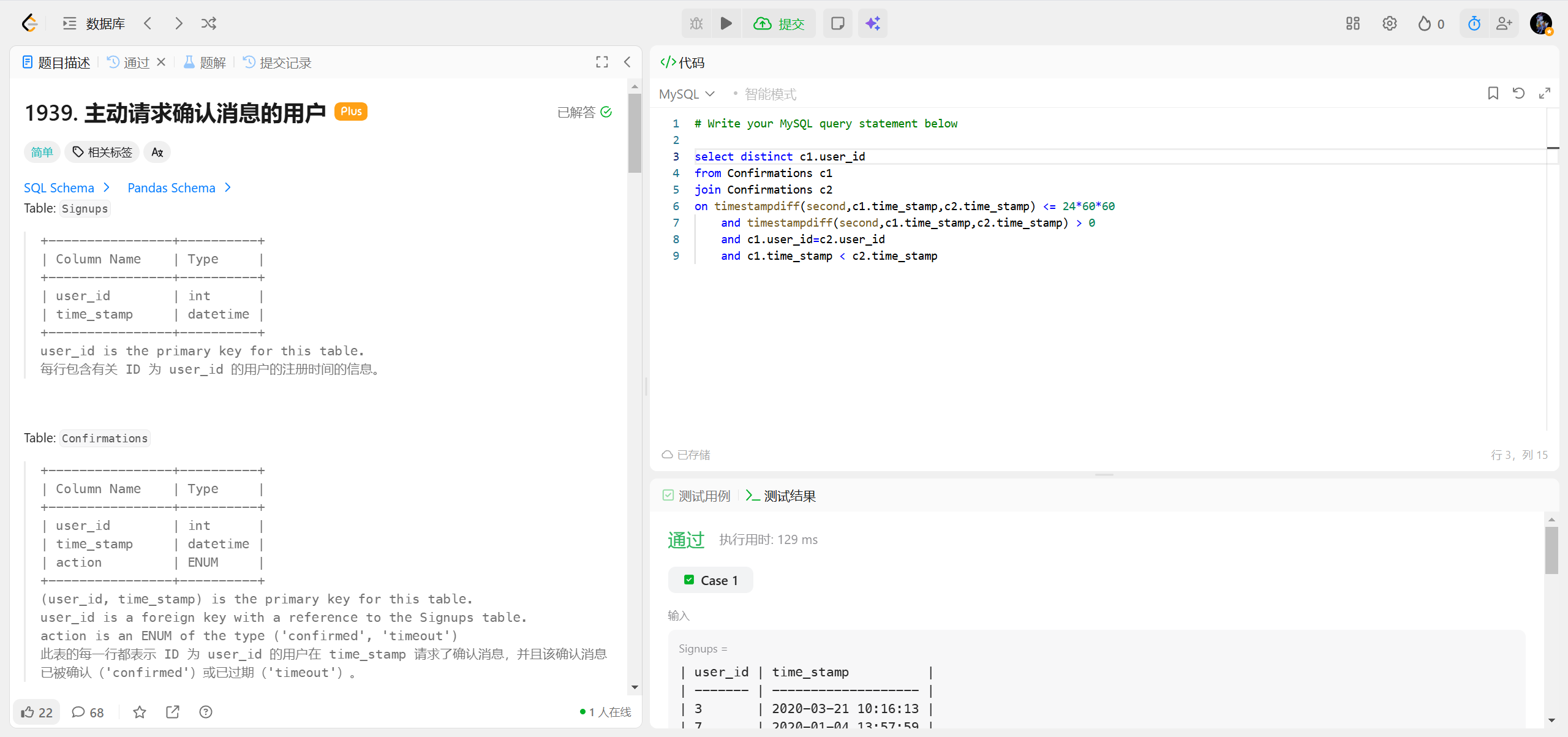
- 日期 / 时间差:最常用的 TIMESTAMPDIFF()/DATEDIFF() 这是日常开发中最常被误称 "diff" 的函数,用于计算两个日期 / 时间的差值。
(1)TIMESTAMPDIFF(单位, 开始时间, 结束时间)
• 功能:按指定单位计算两个时间的差值(灵活,支持年 / 月 / 日 / 时 / 分 / 秒);
• 单位参数:YEAR/MONTH/DAY/HOUR/MINUTE/SECOND;
• 示例:
-- 计算两个日期的天数差(2026-02-21 减 2026-02-15)
SELECT TIMESTAMPDIFF(DAY, '2026-02-15', '2026-02-21'); -- 结果:6
-- 计算两个时间的小时差
SELECT TIMESTAMPDIFF(HOUR, '2026-02-21 10:00:00', '2026-02-21 18:30:00'); -- 结果:8
(2)DATEDIFF(结束日期, 开始日期) • 功能:仅计算两个日期的天数差(简化版,只认日期,忽略时间);
• 示例:
SELECT DATEDIFF('2026-02-21', '2026-02-15'); -- 结果:6
SELECT DATEDIFF('2026-02-21 18:00:00', '2026-02-15 10:00:00'); -- 结果仍为6(忽略时间)
1965.丢失信息的雇员 ***
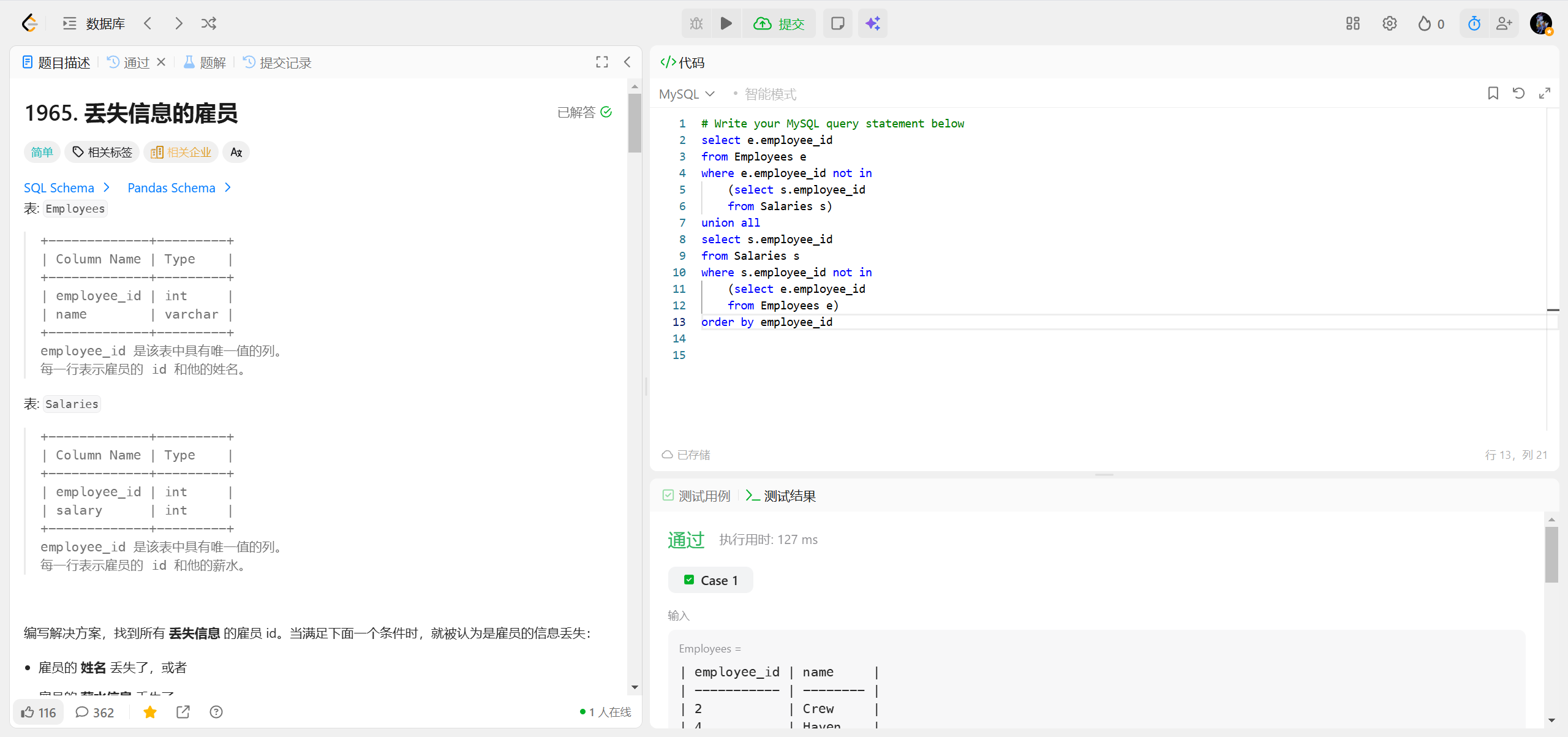
在你提供的这段查询中,order by employee_id 是按最终合并结果集中的 employee_id 字段进行排序的。
为什么能直接用 employee_id 排序?因为你在两个子查询中都只查询了 employee_id 字段,union all 合并后的结果集只有这一个字段,所以 order by employee_id 就是对这个唯一的字段排序。
1978.上级经理已离职的公司员工
2026.低质量的问题 ***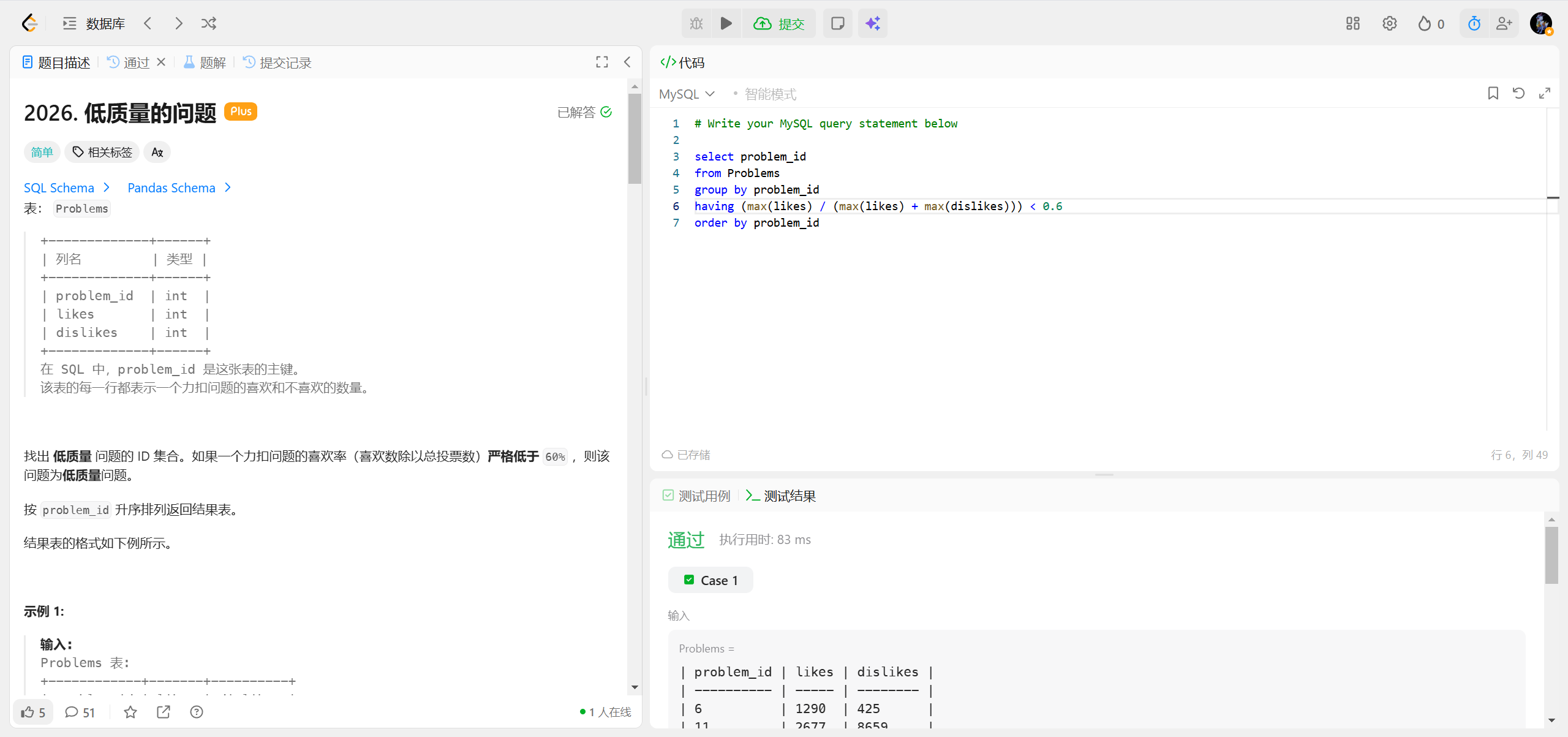
你遇到的 Unknown column 'likes' in 'having clause' 错误,是因为在 MySQL 中使用 HAVING 子句时,引用了未正确暴露的字段,我会帮你分析原因并给出可直接运行的修复方案。
错误原因解析
HAVING 子句的作用是过滤分组后的聚合结果,它只能引用:
-
GROUP BY 子句中声明的分组字段;
-
聚合函数(如 SUM()、COUNT())的计算结果;
-
给聚合计算结果起的别名。 你的原代码中直接写 HAVING (likes / (likes + dislikes)) < 0.6,但 likes 既不是分组字段的聚合形式,也没有别名,MySQL 无法识别这个字段,因此报错。
where和having区别
| 特性 | WHERE 子句 | GROUP BY 子句 |
|---|---|---|
| 作用阶段 | 分组之前筛选原始数据 | 对筛选后的原始数据进行分组 |
| 筛选对象 | 单条的原始记录(行) | 多条相关记录(行)聚合为一个组 |
| 能否用聚合函数 | ❌ 不能(比如 WHERE SUM(likes) > 10 报错) |
✅ 可以(分组的依据,比如 GROUP BY problem_id) |
| 核心目的 | 过滤 "不合格" 的原始行,减少后续处理量 | 将数据按指定字段归类,为聚合计算做准备 |
2072.赢得比赛的大学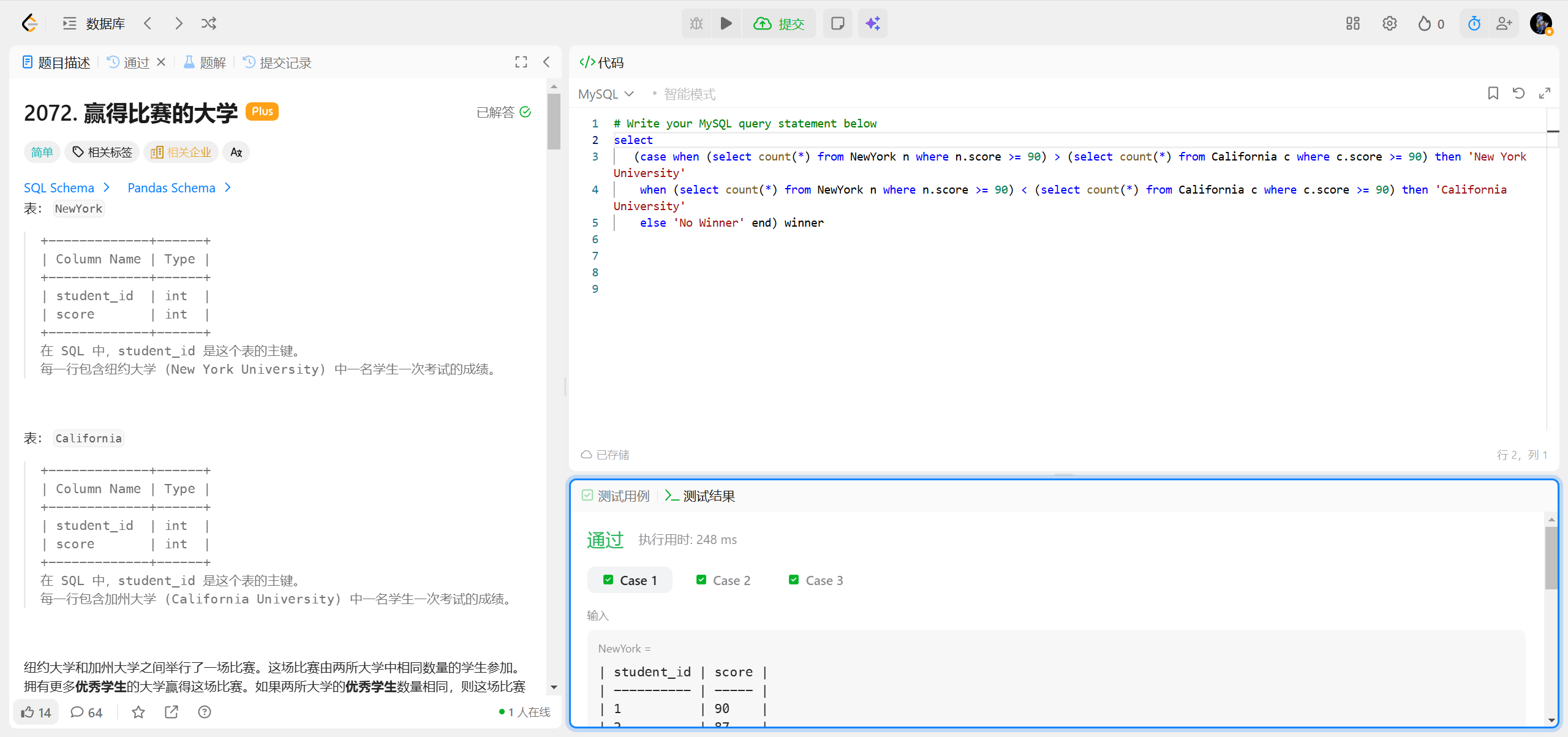
2082.富有客户的数量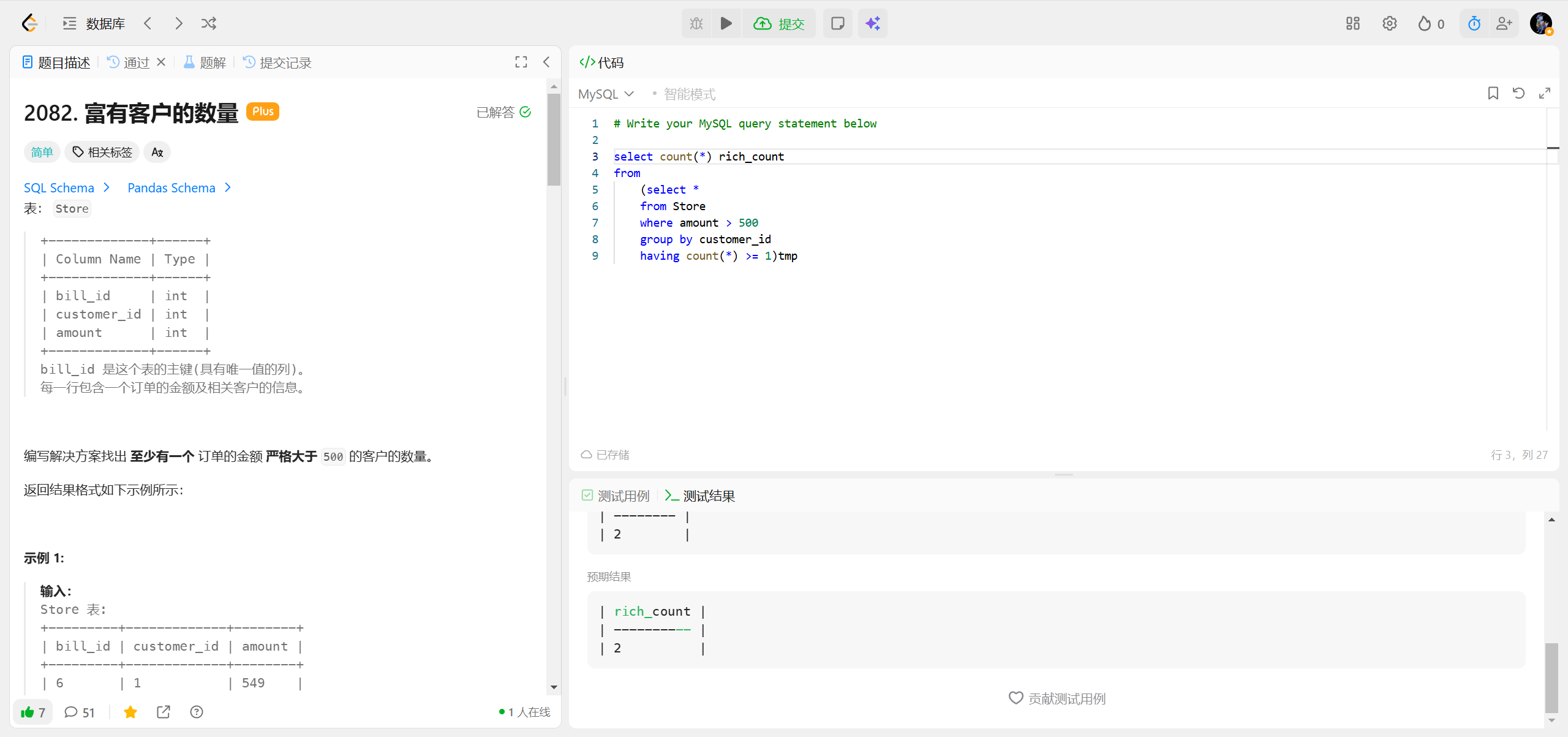
2205.有资格享受折扣的用户数量 ***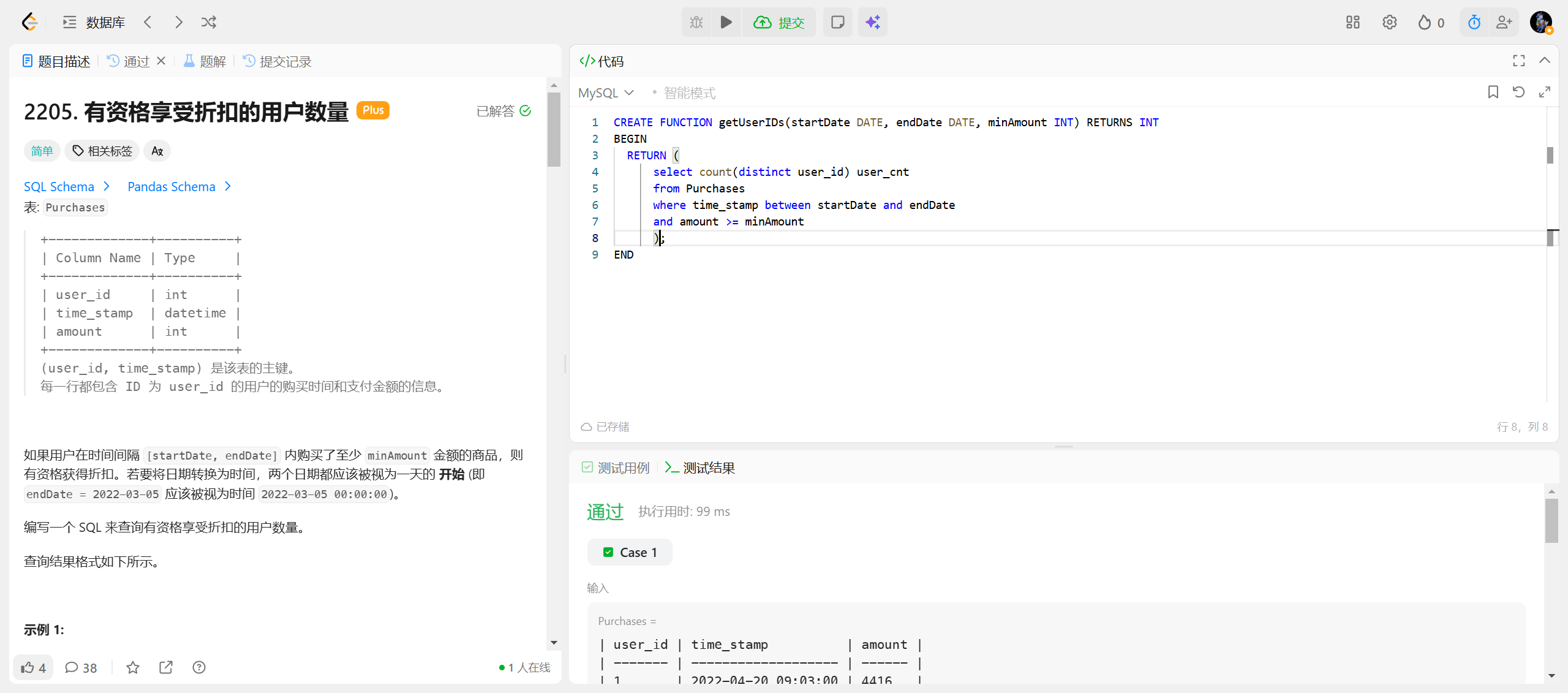
MySQL 函数核心语法(极简版)
DELIMITER //
CREATE FUNCTION 函数名(参数 类型)
RETURNS 返回类型
BEGIN
RETURN 结果;
END //
DELIMITER ;核心 3 句话
- 必写
RETURNS声明返回类型; - 函数体
BEGIN...END内必须RETURN一个值; - 先改结束符
DELIMITER //,最后恢复;。
2230.查找可享受优惠的用户 ***
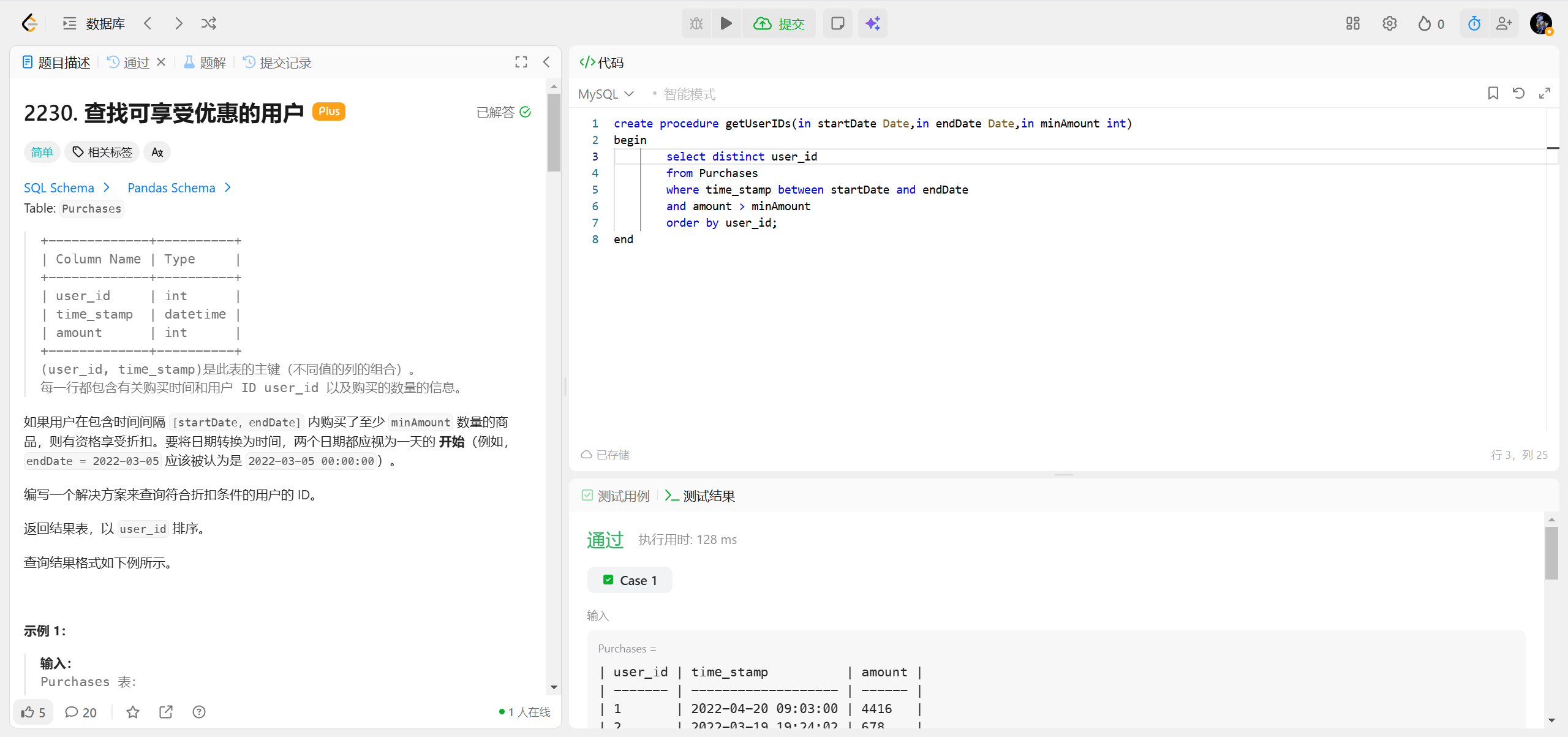
MySQL 存储过程极简核心语法
DELIMITER //
CREATE PROCEDURE 过程名([IN/OUT/INOUT] 参数名 类型[, ...])
BEGIN
-- 业务逻辑(SELECT/INSERT/UPDATE/DELETE等)
END //
DELIMITER ;最简核心规则(仅语法)
- 必写
CREATE PROCEDURE 过程名(参数)声明过程; - 必用
BEGIN...END包裹过程体; - 必须先执行
DELIMITER //改结束符,最后恢复DELIMITER ;; - 参数可选,类型分
IN(默认)、OUT、INOUT。
2329.产品销售分析V
2339.联赛的所有比赛
2356.每位教师所教授的科目种类的数量
2377.整理奥运表
2480.形成化学键
2504.把名字和职业联系起来 ***
| 函数 | 核心作用 | 基本语法 | 关键特点 |
|---|---|---|---|
LEFT() |
从字符串左侧截取指定长度的字符 | LEFT(字符串/字段, 截取长度) |
仅截取,不补位;长度超原字符串则返回全部 |
LPAD() |
左侧填充字符至目标长度(截取 + 补位二合一) | LPAD(字符串/字段, 目标长度, 填充字符) |
不足补位,超长截取;填充字符仅 1 个时生效 |
CONCAT() |
拼接多个字符串 / 字段为一个字符串 | CONCAT(字符串1, 字符串2[, ...]) |
任意数量参数;遇 NULL 则整体返回 NULL |
2668.查询员工当前薪水
2669、统计Spotify排行榜上艺术家出现次数
2687.自行车的最后使用时间
2837.总旅行距离 ***
字段名带空格要用反引号` `引起来
2853.最高薪水差异
2985.计算订单平均商品数量
2987.寻找房价最贵的城市
2990.贷款类型
3051.寻找数据科学家职位的候选人
3053.根据长度分类三角形
3059.找到所有不同的邮件域名
3150.无效的推文Ⅱ ***
REPLACE 函数的基础定义 REPLACE 是 SQL 内置的字符串函数,作用是将字符串中指定的子串替换为新的子串,返回替换后的新字符串。

- 原字符串:可以是字段名(如
content)、固定字符串(如'abc@123'); - 要替换的子串:需要被替换的字符 / 字符串(如
'@'、'#'); - 替换后的新子串:替换成的内容(若设为空字符串
'',则相当于删除原字符串中的指定子串)。
| 函数调用 | 执行结果 | 说明 |
|---|---|---|
REPLACE('abc@123', '@', '-') |
abc-123 |
将 @ 替换为 - |
REPLACE('a#b#c', '#', '') |
abc |
将 # 替换为空(删除所有 #) |
REPLACE('hello', 'll', 'xx') |
hexxo |
替换多字符子串 |
REPLACE(NULL, '@', '') |
NULL |
原字符串为 NULL 时,结果也为 NULL |
3172.第二天验证 ***
DATEDIFF 用于计算两个日期之间的差值,返回一个整数,表示两个日期在指定时间单位(天 / 月 / 年等)上的间隔数。

3198.查找每个州的城市
GROUP_CONCAT 核心定义
GROUP_CONCAT 是 MySQL 专属的聚合函数,作用是将同一个分组内的指定字段值,拼接成一个字符串 (默认逗号分隔),常配合 GROUP BY 使用。

3246.英超积分榜排名 ***
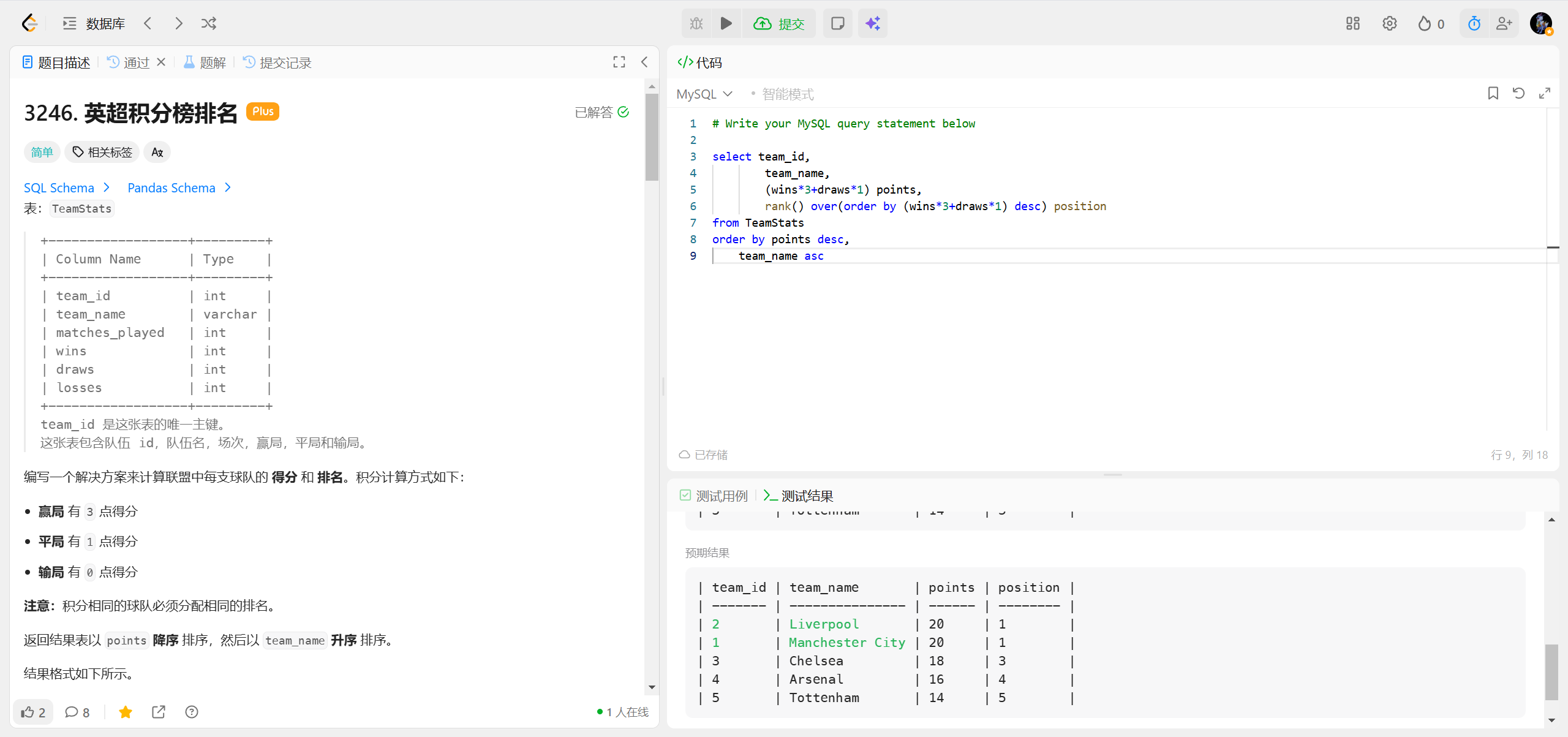
RANK() 函数核心概念 RANK() 属于窗口函数(Window Function),作用是在指定的分组(PARTITION BY)内,按指定排序规则(ORDER BY)为每行计算排名。
• 特点:如果有并列的行,会跳过后续排名(比如并列第 1 名后,下一个是第 3 名)。

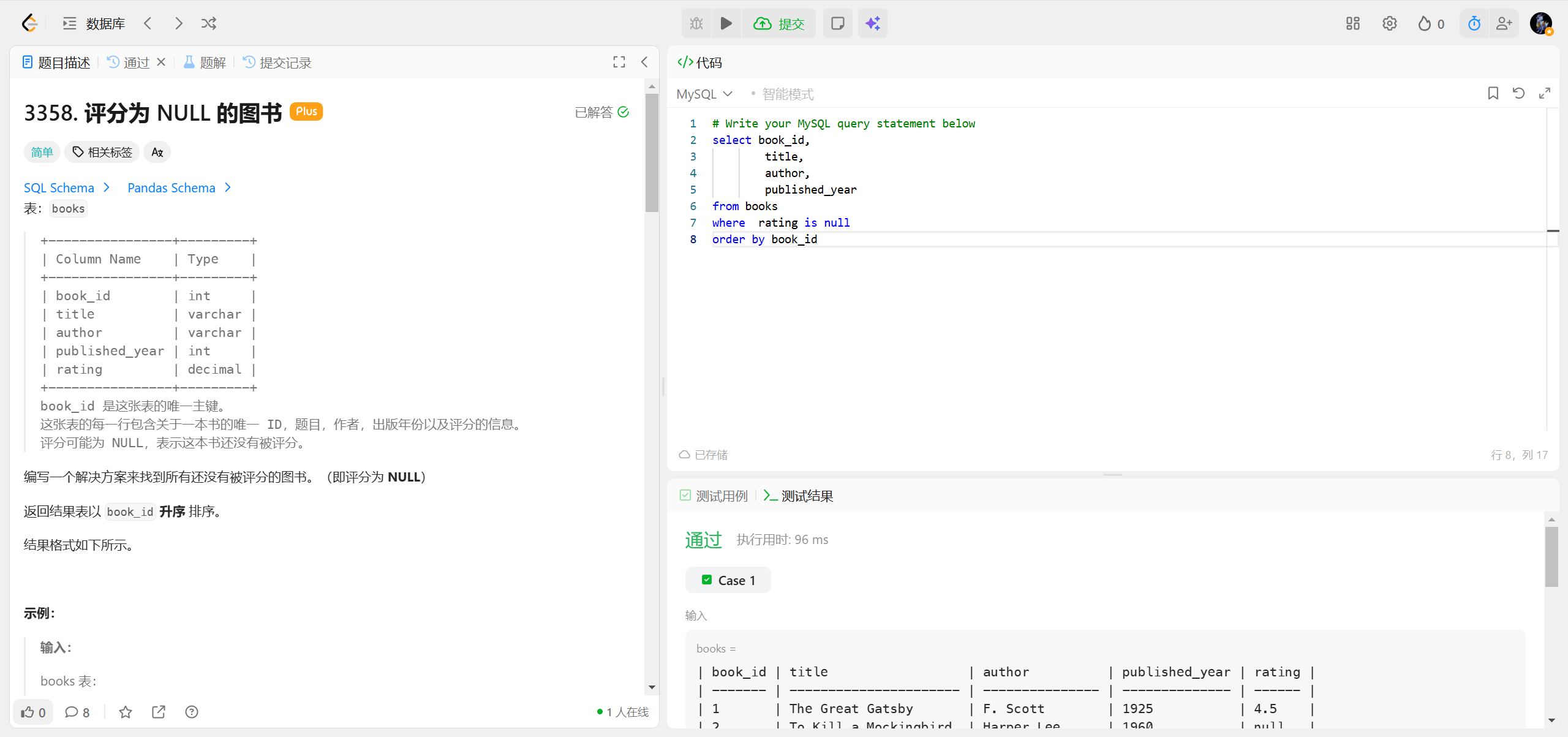
3358.评分为NULL的图书
3415.查找具有三个连续数字的产品 ***
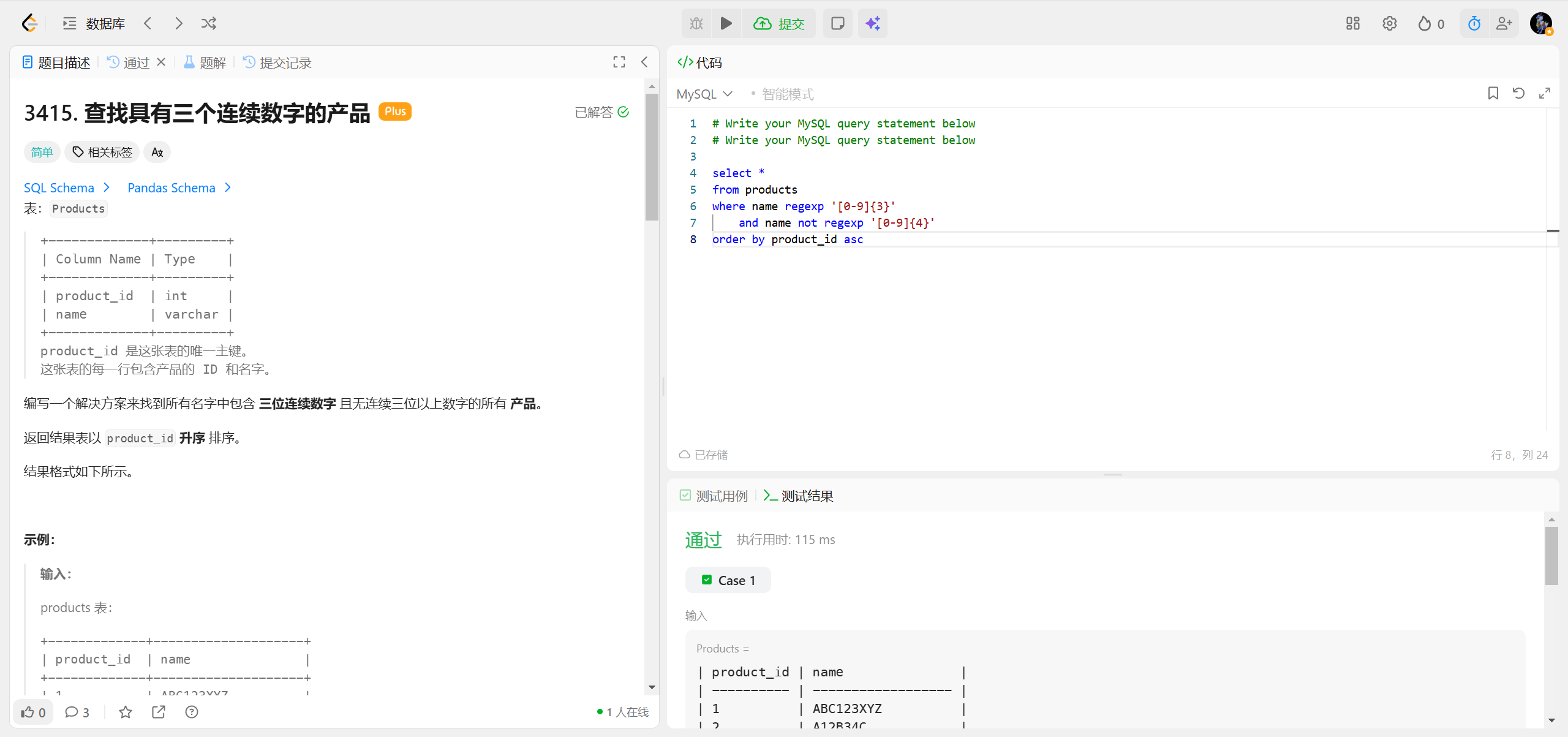
REGEXP '[0-9]{3}' 本质上是 "匹配至少包含一组连续 3 个数字"
| 量词 | 含义 | 例子 |
|---|---|---|
{n} |
恰好 n 次 | [0-9]{2} → 连续 2 个数字 |
{n,} |
至少 n 次 | [0-9]{4,} → 连续 4 个及以上数字 |
{n,m} |
至少 n 次,最多 m 次 | [0-9]{2,4} → 连续 2-4 个数字 |
+ |
至少 1 次(等价 {1,}) |
[0-9]+ → 连续 1 个及以上数字 |
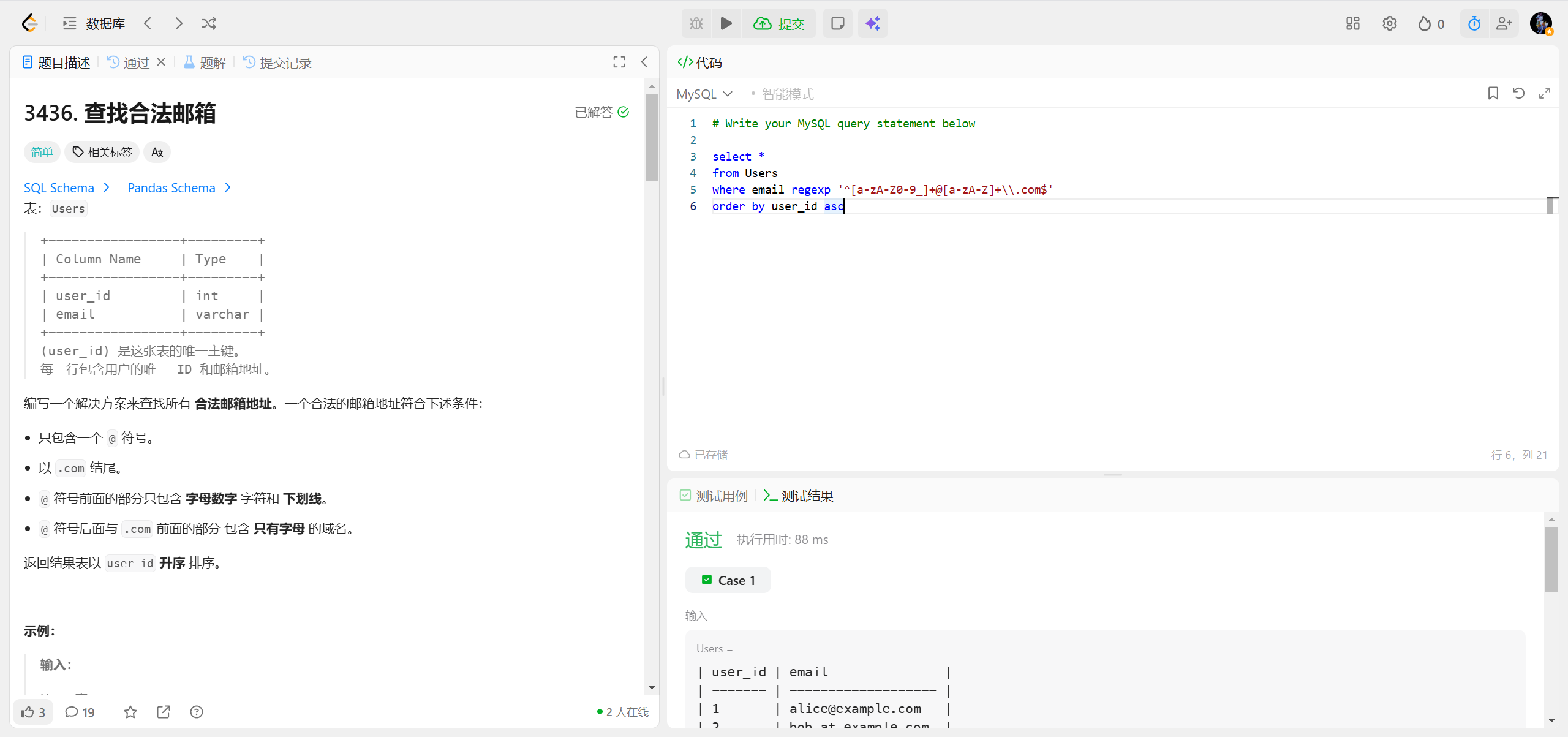
3436.查找合法邮箱
3465.查找具有有效序列号的产品 ***
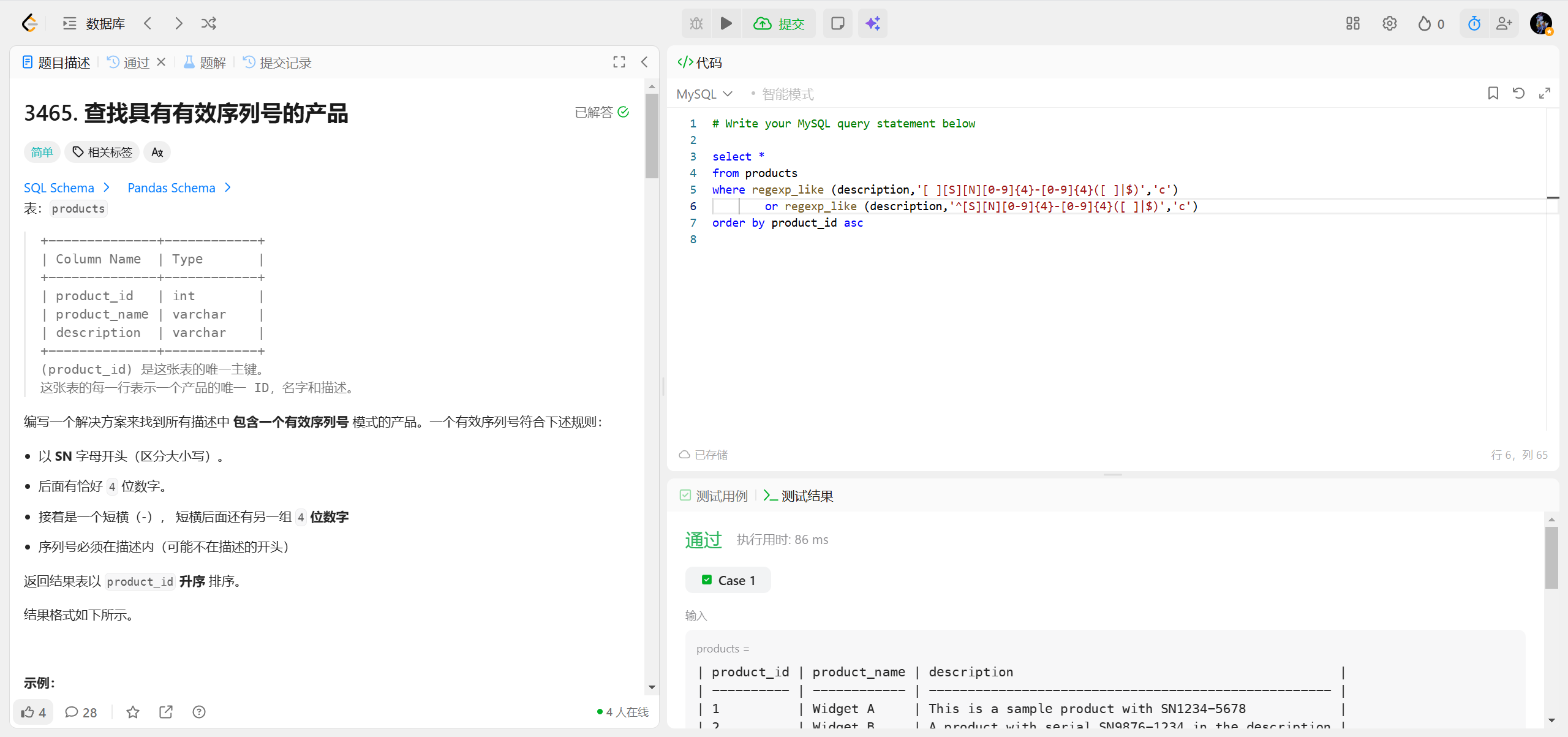

| 修饰符 | 含义 | 适用场景 |
|---|---|---|
c |
Case-sensitive(区分大小写) | 匹配固定大小写(如你需要的大写 SN) |
i |
Case-insensitive(不区分大小写) | 模糊匹配(如同时匹配 SN/sn/Sn) |
m |
Multiline(多行模式) | 匹配多行文本(^/$ 匹配每行开头 / 结尾) |
n |
允许 . 匹配换行符 |
跨行匹配时使用 |
3570.查找无可用副本的书籍
3793.查找高tokens使用量的用户