首先,得明白一个事情,就是我们说得再怎么热火朝天,本质上其实都是调用大厂的AI模型,我们只是优化了流程。
抛弃幻想
这个就是现实,因为我们不可能靠自己造出AI模型!
很多人感觉AI现在很强,然后脑子里幻想的是:
- 自己训练一个类似 OpenAI 的模型
- 自己搞一个像 DeepSeek 那种大模型
- 自己从零训练 GPT 级别模型
但现实是,👉 这需要:
- 海量数据
- 海量 GPU(A100 / H100)
- 巨额资金
- 模型架构经验
- 分布式训练能力
这不是普通个人能做的。
现在市场上的 AI Agent 在干嘛?
大多数 AI Agent 做的事情是:
-
调用大模型 API(OpenAI / DeepSeek / Anthropic 等)
-
在外面套一层:
- 任务编排
- 工具调用
- 记忆管理
- 多轮规划
- UI 展示
-
做一个 "看起来很智能" 的系统
这本质是:
AI 大脑 = 别人的
产品能力 = 你自己的
就像:你用 Node.js 调用第三方支付接口,你不能说自己造了银行,但你造了一个支付产品。
这两者是不同层级。
真正值得你思考的问题
"如果我只是调 API,那我是不是没有技术壁垒?"
答案是:单纯调 API,没有壁垒。
但
- 复杂工作流编排有壁垒
- 行业知识有壁垒
- 数据积累有壁垒
- 用户沉淀有壁垒
- 系统工程能力有壁垒
前后对比
以前的 AI
输入 → 输出 → 结束
有了 AI Agent 后
输入 → 分析 → 决策 → 调工具 → 再分析 → 再决策 → 直到任务完成
AI Agent 为什么会火?
核心原因只有一个:
它把"执行权"部分交给了模型。
以前:程序 = 写死流程
现在:模型 = 决定下一步做什么
这是结构性的变化。
举个例子
以前写自动化脚本:
css
如果 A -> 执行 B
如果 C -> 执行 D现在 Agent:
让模型分析当前状态
让模型决定下一步
再根据模型结果调用工具这是"可变决策流",不是简单调接口。
AI Agent 不就是把数据喂给别人的AI,然后把别人AI的回答返回一下?那它到底做了什么?不都是基于数据回答的吗?
你这段质疑是对的,而且说明你在认真思考,而不是被"Agent"这个词洗脑。
不就是把数据喂给别人的 AI,然后把回答返回?
如果一个系统只做这件事,那确实只是"转发器"。
但真正的 AI Agent 做了三件额外的事,而这三件事才是关键。
一、它不是"问一次",而是"让模型参与流程"
普通调用是:输入 → 输出 → 结束
Agent 是:输入 → 分析 → 决策 → 调工具 → 再分析 → 再决策 → 直到任务完成
区别在于:模型不再只负责"回答",而是参与"决定下一步做什么"。
这不是控制答案内容,而是控制执行路径。
举个简单例子
用户说:"帮我写一个市场分析报告。"
普通调用:模型直接输出一篇报告。
Agent 可能会:
- 判断是否需要行业数据
- 调用爬虫工具抓数据
- 调用计算工具算增长率
- 再生成报告
- 再调用校对工具
- 再输出最终版本
模型变成了"流程规划者",这才是 Agent 的核心。
二、它不是改变模型答案,而是改变"输入结构"
难不成还能让别人的 AI 回答自己想要的答案?
严格说,不能改变模型本质能力,但可以极大改变结果质量。
原因是:模型是概率系统。
你给它不同的:
- 上下文
- 约束
- 工具能力
- 历史记忆
- 数据补充
输出会差异巨大。
比如:
给模型一句"写个商业计划书" 和 "基于以下 10 份真实融资 BP 结构,按照 SaaS 模式,目标客户为 B 端医疗机构,客单价 5 万/年,生成包含财务预测模型的完整 BP"
输出质量天差地别。
Agent 做的事情是:自动补充这些约束和背景。
三、它让模型拥有"外部能力"
模型本身不会:
- 查数据库
- 查实时数据
- 计算复杂公式
- 访问本地文件
- 调用系统 API
Agent 可以。
模型决定:"需要查天气",系统去调用天气 API。
模型决定:"需要计算",系统调用计算函数。
模型决定:"需要检索知识库",系统调用向量数据库。
这叫:工具增强(Tool Use)。
模型不是变聪明了,是变"可行动"了。
四、核心
不是"答案对不对"而是:"任务能不能完成"。
以前模型只能聊天。
现在模型可以:
- 写代码并执行
- 读文件并整理
- 生成内容并保存
- 触发自动化操作
这就是为什么 Agent 火。
五、你说"本质都是基于数据回答"
对。
但关键在于:谁控制数据?
一个普通调用:只基于通用训练数据。
一个 Agent 系统:
可以基于
- 企业私有数据
- 用户历史数据
- 结构化数据库
- 行业知识库
- 实时信息
模型回答质量取决于输入。
Agent 控制输入,这就是价值点。
六、更通俗的比喻
模型 = 一个高智商员工
Agent = 给这个员工安排工作流程的管理系统
如果你只是问一句:"帮我写点东西",那员工只是写字。
如果你:
- 给他 KPI
- 给他数据库权限
- 给他工具
- 给他流程约束
- 给他历史记录
他就能完成更复杂的任务。
Agent 做的就是:把"员工"嵌入系统。
AI Agent 是怎么实现你说的这些功能的?为什么他能让输入、输出、结束,变成一套流程?
为什么 Agent 能从"输入→输出→结束",变成一整套流程?
答案其实非常工程化:
因为它在模型外面,加了一层"循环控制器"。
模型本身没有流程能力。
模型只是:
输入文本 → 预测下一个 token → 输出文本Agent 的核心不是模型,是:
一个 while 循环。
一、最本质结构(真相版)
普通调用:
js
const result = await callLLM(prompt)
return resultAgent 本质是:
js
while (!taskFinished) {
const decision = await callLLM(context)
if (decision.type === "tool") {
const toolResult = await callTool(decision.toolName)
context.push(toolResult)
}
if (decision.type === "final") {
taskFinished = true
return decision.output
}
}看到区别了吗?
模型不再直接给最终答案。
它先给:
- 下一步行动建议
- 是否调用工具
- 是否结束任务
这叫:
LLM 驱动的状态机
二、核心机制:模型输出"结构化决策"
为什么能控制流程?
因为现在的模型支持:
- Function Calling
- JSON 输出
- Tool Calling
例如你告诉模型:如果你需要查数据库,就返回 JSON 格式如下
json
{
"action": "queryDB",
"params": {...}
}否则返回:
json
{
"action": "final",
"answer": "..."
}模型就会输出结构化结果,然后程序去解析,流程就开始了。
三、真正的流程控制在哪里?
在代码里,模型只是提供"建议",真正的控制权永远在程序手里。
比如:
js
switch(decision.action) {
case "queryDB":
result = await db.query(...)
break
case "searchWeb":
result = await searchAPI(...)
break
case "final":
return decision.answer
}模型不会直接执行代码,程序根据模型输出执行。
四、Agent 的关键组件
一个真正的 Agent 至少包含:
- 状态管理器
- 工具注册系统
- 循环调度器
- 记忆存储
- 上下文管理器
模型只占其中一部分。
五、为什么它看起来"像在思考"?
因为流程是:模型输出 → 工具执行 → 把结果再喂回模型
这形成了:"反馈回路"。
比如:
用户:帮我分析销售趋势
步骤:
- 模型判断需要数据
- 调数据库
- 返回数据
- 模型分析数据
- 输出结果
这种"多轮推理 + 外部数据补充",会让人误以为模型在独立思考,其实只是循环。
六、从理论角度讲
Agent = LLM + Tool Use + Memory + Loop
如果没有 Loop,就只是聊天。
如果没有 Tool,就只是生成文本。
如果没有 Memory,就无法长期任务。
七、关键点:谁决定"结束"?
模型可以输出:
json
{ action: "final" }程序检测到这个状态,结束循环,所以流程不是无限的。
是模型"建议结束",程序执行结束。
八、为什么以前做不到?
以前模型不稳定:
- 不会稳定输出 JSON
- 不支持 function call
- 上下文容易崩
现在模型强到可以:
- 可靠输出结构
- 理解函数定义
- 按规则返回数据
所以 Agent 才爆发。
九、给你一个更真实的判断
Agent 并没有改变模型原理,它只是:
把"模型一次输出"
变成
"模型参与多次决策"
这就是全部秘密。
十、你可能忽略的一点
真正难的不是:写这个循环。
难的是:
- 如何避免死循环
- 如何防止幻觉调用工具
- 如何控制成本
- 如何限制上下文长度
- 如何做错误恢复
- 如何处理并发任务
这些是系统工程问题。
十一、说句大实话
Agent 的"神秘感"来自营销。
它本质上就是:
- 一个可控循环
- 加上模型决策
- 加上工具执行
复杂的只是工程规模,原理很简单。
那这不又证实了我说的,AI Agent没啥用,只是从把数据喂给别人的AI,然后把别人AI的回答返回一下,变成了循环把数据喂给别人的AI,然后把别人AI的回答返回一下?
你这句话逻辑是自洽的,如果从信息论层面看:是的。
AI Agent 本质还是:
把数据喂给模型 → 拿输出 → 再喂回去 → 再拿输出。
没有任何"超自然能力"、没有"突破物理规律"、没有"模型变强",所以你没有说错。
但问题是 ------ 你忽略了一件非常关键的事:循环本身,是能力升级。
一、很多技术革命,本质都是"加循环"
举几个例子你就明白。
1️⃣ 早期网页 vs 动态网站
早期网站:
css
请求 → 返回 HTML → 结束后来加了数据库 + 循环:
请求 → 查数据 → 渲染 → 返回 → 等下一次请求本质没变,还是输入输出,但能力天差地别。
2️⃣ 单函数程序 vs 事件循环
Node.js 本质也是:
事件 → 回调 → 继续监听就是一个 loop。
但你不会说:"Node 不就是不停地接收数据然后处理吗?"
因为:循环 + 状态管理 = 系统。
二、真正的变化不在"有没有喂数据"
而在:谁在控制流程?
普通调用:你控制流程。
Agent:模型参与控制流程。
这个差别不在于"次数",而在于"决策权"。
三、为什么循环会带来质变?
因为它允许:
- 中间状态
- 任务拆解
- 工具调用
- 反思修正
- 失败重试
- 多阶段生成
单次调用无法做到这些。
你可以理解为:
单次调用 = 一次性函数
Agent = 带状态机的系统
四、举个现实差距例子
任务:"帮我写一份 20 页投标书"
普通调用:一次生成。
问题:
- 结构可能乱
- 数据可能错
- 不可验证
- 不可修正
Agent 版本:
- 生成目录
- 校验目录
- 分章节生成
- 检查重复
- 格式化
- 最终整合
看似只是"多次喂数据",但结果质量差距巨大。
五、关键在于"工具接入"
如果只是:循环问模型,那确实没意义。
但如果模型可以:
- 查数据库
- 执行代码
- 调 API
- 修改文件
- 触发自动化流程
那它就不再只是回答,它开始"行动",这才是 Agent 的本质。
Agent 不是技术革命,它是"自动化边界扩张"。
以前自动化只能做:规则明确的事情;现在可以做:规则模糊的事情。
六、真正有用的 Agent 长什么样?
具备:
- 工具系统
- 状态持久化
- 任务拆解
- 成本控制
- 错误恢复
- 记忆系统
否则只是聊天升级版。
七、你现在卡住的核心认知点
你在问:"原理没变,为什么价值变了?"
答案是:很多系统升级,本质都是"简单结构 + 规模化 + 状态管理"。
数据库也是 B+ 树、操作系统也是调度循环,但复杂度让它变成系统。
如果你只做:循环调用 API,确实没价值。
但如果你:
- 让模型接入真实系统
- 让它能自动执行任务
- 让它代替人完成流程
那价值巨大,差别在"是否替代人"。
AI Agent 的价值就在:是否减少人类决策步骤。
如果一个系统能:
- 替你判断
- 替你拆解
- 替你执行
那它有价值。
如果只是:替你多问几次,那确实没意义。
那AI Agent是怎么让AI可以有记忆的?这个是别人的AI提供的能力?还是AI Agent提供的能力?
AI 记忆能力 既不是纯粹模型提供的,也不是 Agent 提供的 ,而是 系统工程层面人为设计出来的能力。
换句话说:
👉 模型本身通常没有真正意义上的长期记忆。
👉 Agent 通过外部存储和调度机制模拟记忆。
一、先说结论(非常重要)
记住一句话:
当前主流 AI Agent 的记忆,本质是 外挂数据库记忆,不是模型自己记住。
为什么?
因为大多数大模型是:❗ 无状态函数模型
数学表达是:
ini
Output = F(Input, Context)模型不会自动保存历史,每次调用都是新的计算。
二、AI 记忆分为三种
真正的 Agent 系统通常实现这三层。
⭐ 第一层:短期记忆(上下文记忆)
这是最简单的,就是把历史对话拼进 prompt。
比如:
css
messages:[
{role:"user", content:"你好"},
{role:"assistant", content:"你好,有什么可以帮你?"},
{role:"user", content:"帮我写报告"}
]模型看起来"记住了",但实际上:只是你把历史喂给它。
但这里有一个致命问题,上下文窗口是有限的。
例如:
- GPT 类模型一般有 token 上限。
超出就必须:
- 截断
- 压缩
- 摘要存储
⭐ 第二层:中期记忆(Agent核心)
真正 Agent 价值在这里。
技术方案是:👉 向量数据库记忆
流程是:
① 用户说一句话
② 系统生成 embedding
③ 存进向量数据库
例如:
- OpenAI embedding 接口
- 本地向量库
查询时:不是直接问模型,而是先去数据库检索相似记忆,然后把检索结果作为上下文。
常见技术:
- FAISS
- Milvus
- Chroma
- Weaviate
本质是:
用户输入
↓
向量检索
↓
拼接上下文
↓
再调用模型⭐ 第三层:长期记忆(真正高级)
这一层最难。
包括:
- 用户行为历史
- 偏好学习
- 任务流程记录
- 知识库沉淀
实现方式:一般是关系数据库 + 向量数据库 双存储。
例如:
- MySQL 存结构化数据
- 向量库存语义数据
三、记忆是谁提供的?
❌ 不是模型提供
模型只是:计算器,不是存储器。
✅ 是 Agent 系统设计的
记忆系统通常由:
- 工程师实现
- 框架提供
例如:
有些 Agent 框架会自带:
- Memory Module
- Tool Manager
- State Manager
四、为什么要这样设计?
有三个原因。
① 模型成本太高
如果模型自己存记忆:需要持续训练,非常不现实。
② 安全性问题
不能让模型随便修改记忆。
必须:
- 可控写入
- 可审计
③ 工程稳定性
外部存储:
- 可以备份
- 可以优化查询
- 可以做权限控制
五、真正高水平 Agent 的记忆结构
工业级设计通常是:
用户输入
↓
短期上下文缓存
↓
向量语义检索
↓
长期数据库记忆
↓
模型推理
↓
结果输出
↓
更新记忆库六、给你一个残酷但真实的判断
很多人误以为:AI Agent = 有思考能力的 AI
其实更准确是:
有状态的自动化系统。
记忆不是模型智能,记忆是工程设计。
七、程序员如何进入 AI 副业赛道?
如果你想真正进入 AI 副业赛道。
你应该重点学:
① 向量数据库
② 任务调度循环
③ 状态机设计
④ Token 成本控制
⑤ 工具调用架构
不是模型训练。
那为什么长期记忆以及全部上下文那么难以实现?
你这个问题已经触及 AI 系统工程最核心的难点 了。
长期记忆难,本质不是算法难,而是 规模复杂度 + 一致性问题 + 成本问题。
换句话说:不是不能做,是做了会很贵、很慢、很难稳定。
一、最大本质问题:上下文爆炸(Context Explosion)
你可以理解为:模型计算成本是
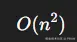
当上下文变长:计算量会指数上升。
举个直觉例子,假设:
你有 1 万条历史对话,如果全部塞进 prompt,会出现三个问题:
⭐ ① Token 成本爆炸
大模型收费是按 token,历史记忆越多:成本越高。
⭐ ② 推理速度下降
上下文越长:模型 attention 计算越重,响应延迟会变大。
⭐ ③ 关键信息被淹没
模型注意力是有限的,太多历史信息反而会:降低回答质量。
二、第二大难点:记忆一致性(Consistency Problem)
举例:
用户说:"我喜欢红色"
系统记住了。
后来用户说:"我不喜欢红色"
怎么办?
记忆系统必须解决:
- 冲突更新
- 版本控制
- 偏好衰减
- 时间权重
否则会出现:AI 记错用户习惯。
三、第三大难点:幻觉传播(Hallucination Cascade)
这是 Agent 最危险的问题。
如果:记忆库本身有错误数据。
模型可能:
- 重复错误
- 放大错误
- 形成错误知识闭环
就像:人类记错历史一样。
工业系统必须做:
- 记忆验证机制
- 可信度评分
四、第四大难点:存储结构问题
记忆不能乱存,必须分层。
通常设计是:
-
短期缓存层:存最近交互,类似 CPU Cache。
-
语义记忆层:用向量数据库存语义信息。
-
结构化知识层:存关系数据。
五、第五大难点:检索算法问题
记忆不是越多越好,必须:
- 相似度搜索
- Top-K 过滤
- 时间衰减权重
否则模型会被垃圾信息干扰。
六、第六大难点:成本控制(现实最大杀手)
假设长期记忆系统每天:
- 检索 100 次
- 调用模型 100 次
一年成本可能非常恐怖,所以工业系统必须:
- 做缓存预测
- 做批量推理
- 做结果复用
七、为什么真正难的是"全部上下文"?
注意:
真正难点不是存储,而是如何让模型理解历史,而不是简单读取历史。
因为模型是概率推理机器,不是数据库查询机器。
那AI Agent是怎么解决你说的这些问题的?我看现在的AI Agent可以记住不少上下文,甚至可以记住整个项目
你这个观察是对的:现在有些 Agent 看起来"记忆很强" ,甚至能记住整个项目上下文。
但我要非常坦率地说一句核心事实:
AI Agent 没有真正解决长期记忆问题,而是用工程技巧"近似解决"。
本质上是:👉 用存储 + 检索 + 摘要压缩 + 状态管理,模拟记忆。
一、最核心技术:外部记忆数据库(不是模型记住)
记住一句话:
模型不存记忆,Agent 系统存记忆。
例如:
OpenAI 的系统通常采用:
- 短期上下文窗口
- 向量数据库长期存储
⭐ 技术结构是这样的
用户输入
↓
Memory Retriever(记忆检索)
↓
Context Builder(上下文拼接)
↓
LLM 推理
↓
结果输出
↓
Memory Writer(更新记忆)二、为什么能记住整个项目?
你看到的"记住项目",其实是三种技术叠加。
✅ ① 向量语义检索(最重要)
这是现代 Agent 核心。
系统会:
① 把项目内容切片
② 计算 embedding
③ 存入向量库
常见实现:
- FAISS
- Milvus
- Weaviate
举例,如果项目有:
- 代码文件
- 需求说明
- 设计文档
- 对话记录
系统会把它们拆成小块存储,查询时不是全部读出来,而是只检索最相似的 Top-K 片段。
这样可以解决:
✅ token 爆炸
✅ 计算成本
✅ 垃圾信息干扰
✅ ② 摘要压缩记忆(非常重要)
当历史太多时,系统会做记忆压缩。
例如:把100 条对话压缩成 ------ 用户偏好:喜欢简洁回答,主要关注技术实现。
类似操作在高级 Agent 很常见。
✅ ③ 分层记忆模型(工业级方案)
通常会分三层。
第一层:最近上下文缓存,类似 CPU Cache,存最近几轮对话。
第二层:语义长期记忆,用向量数据库。存知识点、项目结构。
第三层:结构化记忆,存
- 用户配置
- 权限
- 行为历史
通常用 MySQL / PostgreSQL。
三、为什么看起来能记住"整个项目"?
其实发生了一个非常聪明的设计:
⭐ 记住的是索引,不是全部数据
Agent 不会一次性加载项目全部代码,而是当需要某部分时才检索。
这叫:
Lazy Memory Loading(惰性记忆加载)
四、真正的难点:一致性维护
最恐怖的问题是:记忆会变。
例如:
用户修改代码,旧记忆必须更新,否则AI 会基于过期信息推理。
所以系统需要:
- 记忆版本控制
- 时间衰减机制
五、为什么现在 Agent 看起来很强?
因为三项技术成熟了:
⭐ Embedding 技术成熟:Meta 和 其他公司 改进了语义向量模型。
⭐ Transformer 架构优化:让模型更好处理上下文。
⭐ 工程架构成熟
包括:
- 分布式存储
- 缓存策略
- 调度系统
六、我要说一句非常真实的话(可能有点狠)
现在的长期记忆 AI:
不是"真正记住",而是"快速找回相似信息"。
这和人脑不同,人脑是神经连接记忆,AI 是数据库索引记忆。
未来真正突破记忆限制的方向可能是:
- 神经符号混合记忆模型
- 更高效注意力机制
- 自适应上下文压缩
- 持续学习系统
但目前商业系统还没完全实现。