目录
[1. 暴力法不可行](#1. 暴力法不可行)
[2. 动态规划的引入](#2. 动态规划的引入)
[1. 状态表示](#1. 状态表示)
[3. 边界与数据类型](#3. 边界与数据类型)
题目链接:mari和shiny
一、题目引入
mari 每天都非常 shiny,她的目标是把正能量传达到世界的每个角落!有一天,她得到了一个仅由小写字母组成的字符串。她想知道,这个字符串有多少个 "shy" 的子序列?
子序列 :不要求连续,但顺序必须与原串一致。例如,字符串 "shy" 本身有一个子序列 "shy";字符串 "shhsyy" 中,'s'、'h'、'y' 各自出现两次,可以组成多少个 "shy" 呢?稍加枚举就能发现,答案是 4(每个 's' 可以和它后面的任意 'h' 和 'y' 组合,但要注意顺序)。
输入描述
-
第一行一个正整数 n(1 ≤ n ≤ 300000),代表字符串长度。
-
第二行一个长度为 n 的仅由小写字母组成的字符串。
输出描述
- 一个正整数,代表子序列
"shy"的数量。
二、思路分析
1. 暴力法不可行
最直接的想法是枚举所有三元组 (i, j, k) 满足 i < j < k 且 s[i]=='s'、s[j]=='h'、s[k]=='y'。三重循环显然不可行(n 最大 30 万),即使优化到 O(n²) 也会超时。我们需要一种 O(n) 甚至 O(1) 空间的算法。
2. 动态规划的引入
仔细观察,我们要统计的是形如 's' → 'h' → 'y' 的三元组个数,且顺序与原串一致。这是一个多状态的线性dp:我们依次读取字符,每读到一个字符,就考虑它能如何延续已有的部分子序列。
一种经典的动态规划思路是:用dp表记录当前已经形成的不同前缀子序列的个数。
1. 状态表示
si 表示:字符串 str 中 0, i 区间内,有多少个"s"
hi 表示:字符串 str 中 0, i 区间内,有多少个 "sh"
yi 表示:字符串 str 中 0,i 区间内,有多少个 "shy"
2.状态转移方程
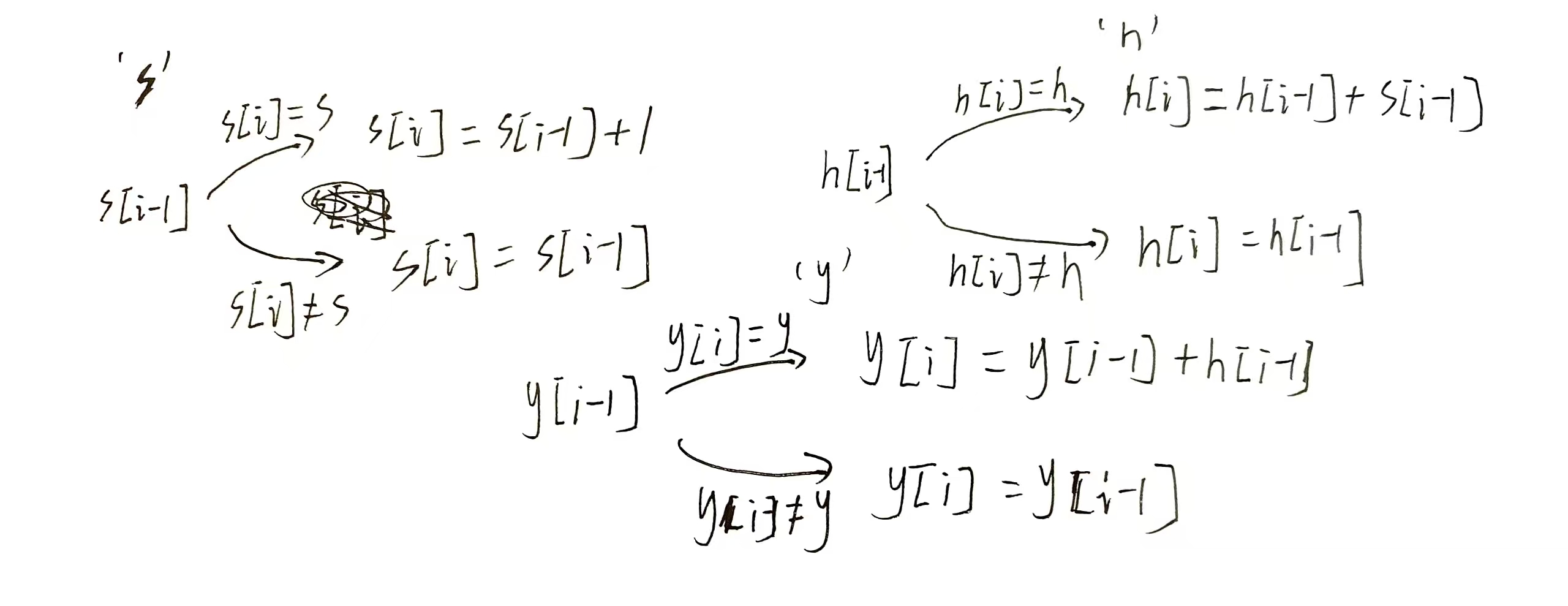
3.空间优化
直接用有限的变量来进行状态表示
-
设
cnt_s表示到目前为止,以当前字符结尾的's'子序列的个数(其实就是字符's'出现的次数)。 -
设
cnt_sh表示到目前为止,以当前字符结尾的"sh"子序列的个数。 -
设
cnt_shy表示到目前为止,以当前字符结尾的"shy"子序列的个数。
当我们遍历到新字符 c 时:
-
如果
c == 's':这个's'可以作为一个新的's'子序列的开始,所以cnt_s += 1。 -
如果
c == 'h':这个'h'可以和之前所有的's'组成新的"sh"子序列,所以cnt_sh += cnt_s。 -
如果
c == 'y':这个'y'可以和之前所有的"sh"组成新的"shy"子序列,所以cnt_shy += cnt_sh。
遍历结束后,cnt_shy 就是答案。
3. 边界与数据类型
-
初始值全部为 0。
-
答案可能很大:最坏情况字符串全是
's'、'h'、'y'中的一种?实际上如果字符串由这三个字母组成,且顺序允许,最大子序列数可能达到组合数级别,比如's'*100000 + 'h'*100000 + 'y'*100000,那么's'有 10^5 个,'h'也有 10^5,每个'y'可以和前面所有的"sh"组合,数量级约为 10^15,会超过 32 位 int 范围,因此必须使用 64 位整数(如 C++ 的long long)。
三、代码实现
cpp
#include <iostream>
#include <string>
using namespace std;
int n;
string str;
int main() {
cin >> n >> str;
long long s = 0, h = 0, y = 0;
for (int i = 0; i < n; i++)
{
char ch = str[i];
if (ch == 's') s++;
else if (ch == 'h') h += s;
else if (ch == 'y') y += h;
}
cout << y << endl;
return 0;
}四、复杂度分析
-
时间复杂度:O(n),仅需一次遍历字符串。
-
空间复杂度:O(1),只用了几个辅助变量。
那么本期的内容就到这里了,觉得有收获的同学们可以给个点赞、评论、关注、收藏哦,谢谢大家。