从0到1实现LRU缓存:思路拆解+代码落地
在后端开发、算法面试中,LRU缓存是高频考点------它不仅是一种经典的缓存淘汰策略,更能考察开发者对"时间复杂度优化""数据结构组合使用"的理解。很多初学者看到LRU的O(1)性能要求就望而却步,其实只要拆解清楚需求、选对数据结构,就能轻松写出可复用、高性能的LRU实现。
本文不会直接扔代码,而是跟着"需求分析→思路拆解→数据结构选型→逐步实现→易错点总结"的节奏,带你从零构建LRU缓存,最终写出和工业界标准一致的最优版本(双向链表+Map)。
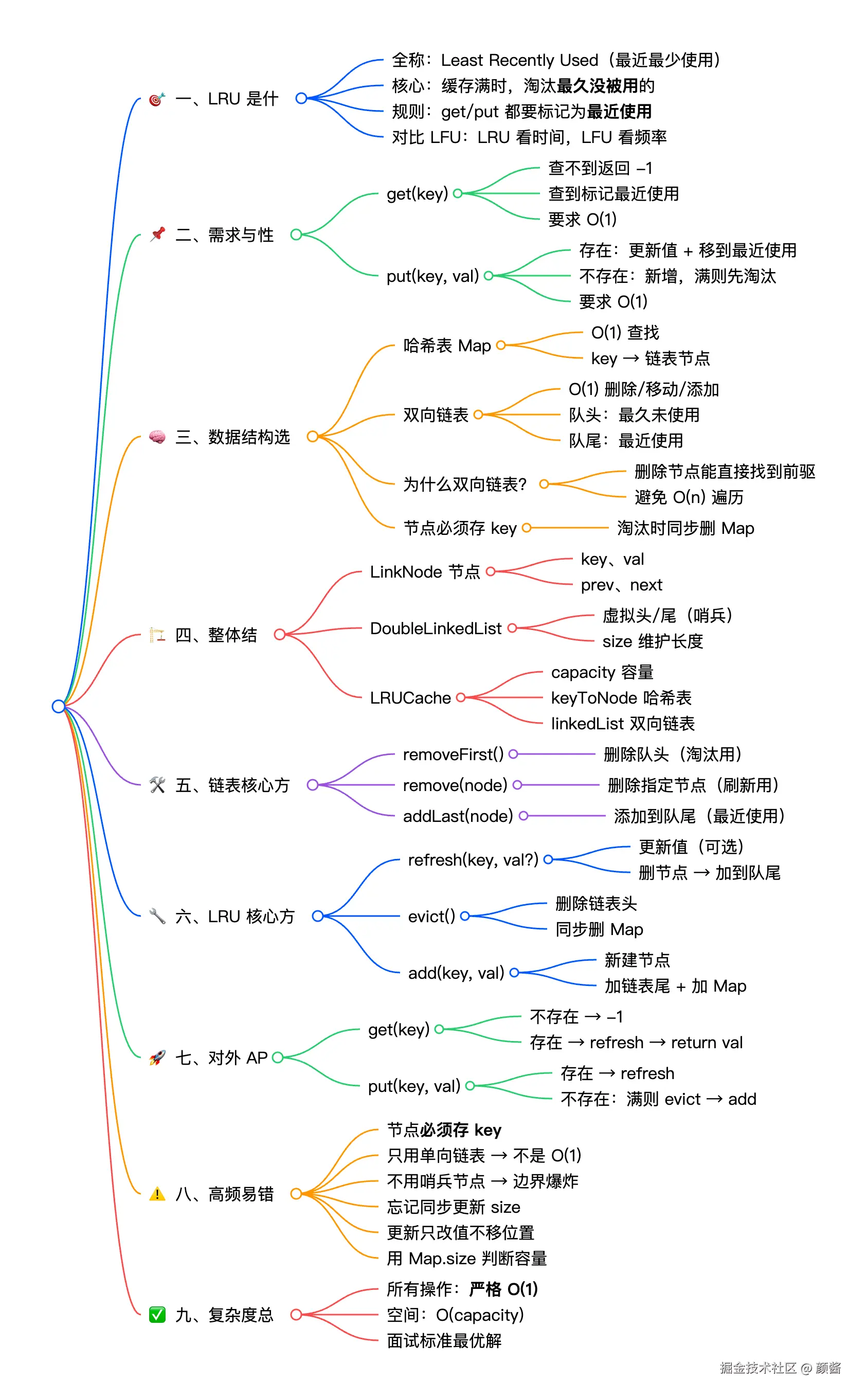
一、先搞懂:LRU到底是什么?
LRU 全称 Least Recently Used(最近最少使用),核心逻辑非常简单:当缓存容量满时,优先淘汰"最近最少被使用"的缓存项;每次访问(get)或新增(put)缓存项,都要将其标记为"最近使用"。
举个贴近生活的例子,帮你快速理解:
你有一个只能放3本书的书架(缓存容量=3):
-
先放《算法》→ 书架:算法(仅1本,未满)
-
再放《Java》→ 书架:算法,Java(2本,未满)
-
再放《Python》→ 书架:算法,Java, Python(3本,已满)
-
访问《算法》→ 标记为最近使用 → 书架:Java, Python, 算法(算法移到最右侧,代表最近使用)
-
新增《JS》→ 容量满,淘汰最少使用的《Java》→ 书架:Python, 算法,JS(JS作为新项,放到最右侧)
这个书架的操作逻辑,就是LRU的核心------始终保留"最近用得多"的,淘汰"最久没用"的。
二、明确需求:LRU需要实现哪些功能?
面试中,LRU缓存的核心需求的固定的,且有明确的性能要求(这是解题关键):
| 操作 | 功能描述 | 性能要求 |
|---|---|---|
| get(key) | 根据key查询缓存值;查不到返回-1;查到则标记为"最近使用" | O(1) |
| put(key, val) | 1. 若key存在:更新缓存值,标记为"最近使用";2. 若key不存在:新增缓存;若容量满,先淘汰最少使用项,再新增 | O(1) |
这里的O(1)性能要求,是我们选择数据结构的核心依据------如果忽略性能,用数组也能实现,但面试中会直接被淘汰。
三、思路拆解:如何满足O(1)性能?
我们逐个分析两个核心操作,拆解需要的技术点:
1. 先看get(key):如何实现O(1)查询+标记最近使用?
get操作的核心是"快速找到key对应的缓存项",能实现O(1)查询的 data structure,最常用的就是哈希表(Map)------Map的get(key)操作天生是O(1),能直接通过key定位到对应的值。
但问题来了:找到缓存项后,如何"标记为最近使用"?
如果只用Map,我们无法记录"使用顺序"------Map只能存储key和value的映射,没法知道哪个key是最近用的、哪个是最久没用的。所以,我们需要一个额外的数据结构,来维护缓存项的"使用顺序"。
2. 再看put(key, val):如何实现O(1)新增/更新+淘汰?
put操作有两个关键场景:
-
场景1:key已存在 → 更新值,标记为最近使用;
-
场景2:key不存在 → 新增值;若容量满,淘汰最久未使用项。
这两个场景,都需要"快速移动/删除缓存项"------比如,更新时要把缓存项移到"最近使用"的位置,淘汰时要删除"最久未使用"的位置。
此时,数组就不合适了:数组删除、移动元素的时间复杂度是O(n)(需要遍历找到目标元素),无法满足O(1)要求。而链表的删除、移动操作可以做到O(1)------前提是我们能直接拿到要操作的节点。
3. 数据结构选型:双向链表 + Map(最优组合)
结合上面的分析,我们需要两种数据结构配合,才能实现所有操作的O(1):
-
哈希表(Map):key → 链表节点,负责O(1)查询节点;
-
双向链表:维护缓存项的使用顺序,队头=最久未使用,队尾=最近使用,负责O(1)移动/删除节点。
补充两个关键细节(新手必踩坑):
-
为什么用双向链表,而不是单向链表?------ 单向链表删除节点时,需要遍历找到前驱节点(O(n));双向链表有prev和next指针,能直接定位前驱和后继,删除/移动节点只需O(1)。
-
链表节点需要存储key吗?------ 必须存!淘汰队头节点时,我们需要通过节点的key,删除Map中对应的映射(否则Map会有冗余数据,导致内存泄漏)。
四、逐步实现:从基础到完整代码
我们分三步实现,先搭建基础结构,再实现核心方法,最后组合成完整的LRUCache类,每一步都标注思路和注意点。
第一步:实现双向链表节点(LinkNode)
节点需要存储key、val,以及prev(前驱)、next(后继)指针,用于链表的连接和操作。
javascript
/**
* 双向链表节点类 - 存储缓存的键值对和前后指针
* @class LinkNode
* @param {any} key - 缓存的键(淘汰时需通过key删除Map映射)
* @param {any} val - 缓存的值
*/
class LinkNode {
constructor(key, val) {
this.key = key; // 必须存储key,淘汰时用
this.val = val; // 缓存值
this.prev = null; // 前驱节点指针
this.next = null; // 后继节点指针
}
}第二步:实现双向链表(DoubleLinkedList)
链表需要维护使用顺序,核心方法包括:删除队头(淘汰最久未使用)、删除指定节点、在队尾添加节点(标记最近使用),同时自维护节点数量(避免和LRUCache类状态不一致)。
这里用虚拟头/尾节点(哨兵节点)------避免处理空链表的边界问题(比如删除队头时,无需判断链表是否为空)。
javascript
/**
* 双向链表类 - 维护LRU缓存的使用顺序(队头=最少使用,队尾=最近使用)
* @class DoubleLinkedList
*/
class DoubleLinkedList {
constructor() {
// 虚拟头/尾节点(无实际意义,仅简化边界处理)
this.dummyHead = new LinkNode(null, null);
this.dummyTail = new LinkNode(null, null);
// 初始化链表:虚拟头 ↔ 虚拟尾
this.dummyHead.next = this.dummyTail;
this.dummyTail.prev = this.dummyHead;
this.size = 0; // 有效节点数(自维护)
}
// 判断链表是否为空
isEmpty() {
return this.size === 0;
}
// 获取有效节点数
getSize() {
return this.size;
}
// 删除并返回队头节点(最少使用,用于淘汰)
removeFirst() {
if (this.isEmpty()) {
throw new Error('链表为空,无法删除队头');
}
const cur = this.dummyHead.next; // 真正的队头节点
const prev = cur.prev;
const next = cur.next;
// 断开连接
prev.next = next;
next.prev = prev;
cur.prev = null;
cur.next = null;
this.size--;
return cur;
}
// 删除指定节点(用于访问/更新时,移除原位置节点)
remove(node) {
if (this.isEmpty()) {
throw new Error('链表为空,无法删除指定节点');
}
const cur = node;
const prev = cur.prev;
const next = cur.next;
prev.next = next;
next.prev = prev;
cur.prev = null;
cur.next = null;
this.size--;
return cur;
}
// 在队尾添加节点(标记为最近使用)
addLast(node) {
const cur = node;
const prev = this.dummyTail.prev; // 原队尾节点
const next = this.dummyTail;
// 建立连接 prev的指针、next的指针、cur的指针
prev.next = cur;
next.prev = cur;
cur.prev = prev;
cur.next = next;
this.size++;
}
}第三步:实现LRUCache类(核心逻辑)
LRUCache类组合Map和双向链表,封装get、put方法,同时提取语义化方法(refresh、evict、add),让代码更清晰、可维护------这也是工业界常用的封装思路。
javascript
/**
* LRU缓存实现类(最优版)
* @class LRUCache
* @param {number} capacity - 缓存最大容量
*/
class LRUCache {
constructor(capacity) {
if (capacity < 1) {
throw new Error('缓存容量必须大于0');
}
this.capacity = capacity; // 缓存容量
this.keyToNode = new Map(); // key → 链表节点(O(1)查找)
this.linkedList = new DoubleLinkedList(); // 维护使用顺序
}
/**
* 语义化方法:刷新缓存(更新值+标记最近使用)
* @param {any} key - 缓存键
* @param {any} [val] - 可选:更新的值(不传则只更新位置)
*/
refresh(key, val) {
const targetNode = this.keyToNode.get(key);
// 可选更新值
if (val !== undefined) {
targetNode.val = val;
}
// 移到队尾,标记为最近使用
this.linkedList.remove(targetNode);
this.linkedList.addLast(targetNode);
}
/**
* 语义化方法:淘汰最少使用节点(删除队头)
*/
evict() {
const removedNode = this.linkedList.removeFirst();
this.keyToNode.delete(removedNode.key); // 同步删除Map映射
}
/**
* 语义化方法:新增节点并标记为最近使用
* @param {any} key - 缓存键
* @param {any} val - 缓存值
*/
add(key, val) {
const newNode = new LinkNode(key, val);
this.linkedList.addLast(newNode);
this.keyToNode.set(key, newNode);
}
/**
* 对外暴露方法:根据key获取缓存值
* @param {any} key - 缓存键
* @returns {any} 存在返回值,否则返回-1
*/
get(key) {
if (!this.keyToNode.has(key)) {
return -1;
}
// 刷新位置,标记为最近使用
this.refresh(key);
return this.keyToNode.get(key).val;
}
/**
* 对外暴露方法:新增/更新缓存
* @param {any} key - 缓存键
* @param {any} value - 缓存值
*/
put(key, value) {
// 情况1:key已存在 → 更新值+标记最近使用
if (this.keyToNode.has(key)) {
this.refresh(key, value);
return;
}
// 情况2:key不存在 → 新增
// 容量满,先淘汰
if (this.linkedList.getSize() === this.capacity) {
this.evict();
}
// 新增节点
this.add(key, value);
}
// 辅助方法:判断缓存是否已满
isFull() {
return this.linkedList.getSize() === this.capacity;
}
// 辅助方法:判断缓存是否为空
isEmpty() {
return this.linkedList.getSize() === 0;
}
}五、测试验证:确保代码能正常运行
写好代码后,一定要通过测试用例验证核心逻辑,避免边界bug。以下测试用例覆盖了LRU的所有核心场景:
javascript
// 测试用例
function testLRU() {
const lru = new LRUCache(3);
// 1. 新增3个节点
lru.put('算法', 1);
lru.put('Java', 2);
lru.put('Python', 3);
console.log('缓存当前容量:', lru.linkedList.getSize()); // 输出:3
// 2. 访问「算法」→ 标记为最近使用
console.log('访问算法:', lru.get('算法')); // 输出:1
// 3. 新增「JS」→ 容量满,淘汰「Java」
lru.put('JS', 4);
console.log('访问Java:', lru.get('Java')); // 输出:-1(已淘汰)
console.log('访问JS:', lru.get('JS')); // 输出:4
// 4. 更新「Python」的值
lru.put('Python', 33);
console.log('访问Python:', lru.get('Python')); // 输出:33(更新成功)
}
// 执行测试
testLRU();运行后,输出结果符合预期,说明代码逻辑正确。
六、新手高频易错点(面试避坑)
结合我自己的实现经验,以及新手常踩的坑,总结6个关键易错点,面试时一定要注意:
-
节点未存储key:淘汰队头节点时,无法删除Map中的映射,导致Map冗余、内存泄漏;
-
用单向链表替代双向链表:删除节点时需要遍历找前驱,时间复杂度变成O(n),不符合要求;
-
未使用虚拟头/尾节点:处理空链表、删除队头/队尾时,需要额外判断边界,容易出错;
-
忘记更新链表size:新增/删除节点后,未同步更新linkedList.size,导致容量判断错误;
-
更新节点时,只更新值未移动位置:违背LRU"访问即标记最近使用"的核心逻辑;
-
容量判断错误:用Map.size判断容量,而非链表的size(Map和链表的size必须保持一致)。
七、LRU vs LFU:别搞混两种缓存策略
很多初学者会把LRU和LFU搞混,这里简单区分,避免面试时答错题:
-
LRU(最近最少使用):淘汰"最久未被使用"的项,核心看「使用时间」;
-
LFU(最少使用):淘汰"使用次数最少"的项,核心看「使用频率」。
举个例子:一个缓存项使用频率很高,但最近一次使用是很久之前(比如一个常用工具,最近一周没用到),LRU会淘汰它,而LFU不会。
八、总结
LRU缓存的核心,是"用Map实现O(1)查询,用双向链表实现O(1)移动/删除",两者结合就能满足所有性能要求。整个实现过程,最关键的不是代码本身,而是"从需求出发,拆解问题、选择合适数据结构"的思路。
本文的代码是工业界/面试中的最优版本,语义化封装清晰、边界处理完善、性能拉满。建议你自己动手敲一遍代码,结合测试用例调试,重点理解"双向链表和Map的配合逻辑",这样面试时无论遇到什么变体,都能轻松应对。
最后,记住:LRU的核心不是"双向链表",而是"最近最少使用"的淘汰逻辑------只要能满足O(1)性能,数据结构的选择可以灵活调整,但双向链表+Map是最常规、最高效的实现方式。