本章涵盖以下内容
- 对文本生成问题的解释
- 对无监督学习的介绍
- 使用注意力机制学习结构
- 从简单概率模型逐步构建到深度学习模型
- Transformer 架构及其变体与应用
尽管前面几章已经展示了深度学习在回归和分类任务中的能力,但这项技术真正具有颠覆性的力量,远远不止于分析已有数据。深度学习如今正在进入创造性领域------生成全新的图像、创作原创文本,甚至生成逼真的视频。这些生成能力,过去一度被认为是人类智能的专属领域,而现在却已经成为当前 AI 革命的核心,推动了近年来我们所见证的大部分 AI 热潮与兴奋情绪。
AI 生成内容的起源可以追溯到 20 世纪 60 年代,那是计算机科学家刚开始探索"机器生成语言"这一想法的时期。由麻省理工学院 Joseph Weizenbaum 开发的计算机程序 ELIZA ,是最早利用自然语言处理(NLP)来模拟对话的程序之一,因此它也被视为最早的聊天机器人之一。ELIZA 最著名的一个配置(DOCTOR)被设计成模仿一位罗杰斯学派心理治疗师,这种治疗方式更关注患者的感受和想法,而不是治疗师本人的意见。ELIZA 通过识别患者回应中的关键词,生成新的问题并维持对话。例如,如果患者说:"我很难过。" ELIZA 就会回答:"你为什么难过?"
这个程序当时非常成功,很多人都被它骗到,以为自己真的在和一个真人交流。然而,ELIZA 实际上并不能理解对话的意义。它不过是一个巧妙的把戏:利用一套固定规则来生成回应。以前面的对话为例:
患者:"我很难过。"
ELIZA:"你为什么难过?"
无论患者之前是否已经解释过自己的感受,ELIZA 都会用这样的问题作出回应。通过模式匹配和一套设计得相当精巧的基于规则的语句系统,ELIZA 在实际上并不理解对话上下文的前提下,制造出了一种"似乎理解了"的幻觉。研究人员还要再花上几十年,才终于设计出一种真正可行的架构,能够准确捕捉对话上下文------而这正是生成逼真文本的关键前提。本章所关注的,就是这种架构。
不过,一个重要问题仍然摆在面前:AI 究竟是如何生成内容的? 对于回归和分类问题,任务定义得更明确------你有数据,也有明确的目标(标签)。但对于生成任务,输出从理论上讲是无限的。文本的重组方式似乎无穷无尽,画笔的落法也变化万千,仿佛只有经过无数排列组合,才能创造出类似莎士比亚或莫奈的作品。事实证明,深度学习模型之所以能够应对这些挑战,靠的是它们发现数据中潜在结构(latent structure) 的惊人能力。"latent" 一词源自拉丁语 lateo,意为"隐藏着",它强调的是这样一种被隐藏的数据结构:人类在从事创造性工作时,其实也会在无意识中依赖它。无论是写作、绘画还是作曲,艺术创作很大一部分都涉及技巧,以及对某些约定俗成规范的遵循。
这就形成了一个有趣的悖论:各种创造性媒介既遵循某些隐含规则,同时又始终保持动态、不断演化。虽然这些底层模式很难通过显式编程来表达,但深度学习模型却非常擅长通过分析现有数据中的模式,捕捉这些隐藏的惯例,并学习如何复现它们。举例来说,在处理音乐时,我们需要理解旋律、节奏与和声的结构;类似地,对于一幅画,我们需要理解色彩、纹理和形体的组织方式。一旦掌握了这些结构,我们就可以利用它们构建一个概率模型,从而生成新的内容。
在本章中,我们将探讨 Transformer 如何驱动文本生成。我们会从一个实际例子开始:逐字符生成人名,并借此介绍处理文本数据的技术。接着,本章会进一步讨论注意力机制------也就是 Transformer 技术的基石------然后深入到完整的 Transformer 架构及其在 NLP 中的应用。本章的重点会放在文本生成上,而下一章我们将把目光转向图像。
9.1 一个激发动机的例子:逐字符生成人名
正如前面几章一样,我们先从一个具体的问题开始,然后看看如何利用 PyTorch 来帮助我们解决它。让我们从"逐字符生成单词"这个问题入手,探索深度学习如何生成符合人类风格的名字。最终,我们会逐步走向生成整段整段的文本,但现在先停留在字符层面,以便更好地理解其中涉及的技术。
假设你被要求设计一个算法,用来生成原创的人名。这些名字需要是英文的、易于发音的,并且符合人们熟悉的命名模式,也就是别人一看就会觉得"像个正常名字"。挑战在于:既要生成听起来自然、真实(就像你日常生活中会遇到的名字)的名字,又不能简单照搬已有名字。面对这样一个问题,我们该如何着手?
这正是一个可以用生成式语言模型 来解决的经典问题。要理解这类模型如何工作,首先必须理解语言领域里的一个概念:词汇表(vocabulary) 。所谓词汇表,指的是模型能够识别并使用的那一组不同元素。每一个元素称为一个 token(词元) ,它是构成模型输入序列和输出序列的基本单位。
在我们这个问题里,词汇表由英语字母表中所有小写字母构成(这里我们忽略名字中的大写字母)。每个字母,也就是每个 token,都会被分配一个唯一的整数表示------例如,"a" 表示为 1,"b" 表示为 2,依此类推。正如图 9.1 所示,这种方法使我们能够把任何一个名字都表示成一个整数序列。例如,名字 "ada" 就可以表示为序列 [1, 4, 1]。
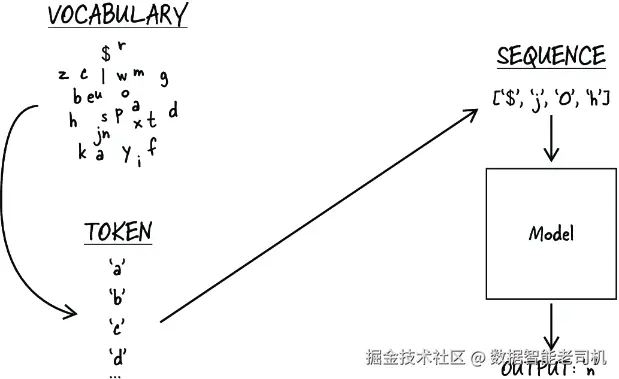
图 9.1 语言模型中的一些通用术语:vocabulary、token 和 sequence。符号 $ 是一个特殊 token,用来表示名字的开始或结束。
我们可以用标准 Python 字典,在字符和整数之间建立双向映射。现在打开 /code/p2ch9/generating_names.ipynb 看看具体怎么做。
代码清单 9.1 设置词汇表和字符映射
ini
# In[]:
vocab = "$abcdefghijklmnopqrstuvwxyz"
vocab_size = len(vocab)
ch_to_i = {char: i for i, char in enumerate(vocab)}
i_to_ch = {i: char for i, char in enumerate(vocab)}你可能已经注意到,我们在词汇表里额外加入了一个字符 $,并把它映射为 0。这个特殊字符用于表示名字的开始或结束。例如,名字 "ada" 会被表示成序列 [0, 1, 4, 1, 0],其中 $ 同时标记了左右两个边界。
作为一个非常粗糙的第一步,我们可以通过随机选择字母并把它们串起来,直接生成名字。我们可以构造一个字母的均匀分布,让每个字母都具有完全相同的概率。这里我们会使用 softmax 函数把原始分数转成概率。回忆一下,softmax 会接收一个数值向量,并输出一个关于这些数值的概率分布:
python
# In[]:
import torch
import torch.nn as nn
import torch.nn.functional as F
equal_probs = F.softmax(torch.ones(vocab_size), dim=0) #1
for i in range(5):
generated = ""
while True:
random_int = torch.multinomial(equal_probs, 1).item() #2
random_char = i_to_ch[random_int]
if random_char == "$":
break
generated += random_char
print(f"name {i}: {generated}")
# Out[]:
name 0: zrcgahwsalcydnvq
name 1: allatytiyxpckqwbwmeyi
name 2: jrwymeibyroivykbrqqhhbowjpm
name 3: ancvvzdtzhzlweiew
name 4: fvydasrmttj
#1 因为传进去的是一个所有值都相同的向量,所以得到的是字符上的均匀分布(1/27)。
#2 要从一个概率分布中采样,可以使用 torch.multinomial。它接收一个概率张量,并返回从该分布中采样得到的一个索引。嗯,这个输出实在不怎么样。这些"名字"既不可读,也谈不上可发音。我大概不会给自己的孩子起名叫 "zrcgahwsalcydnvq"------除非我突然继承了一笔科技巨富的遗产,急需确保后代在寄宿学校里足够与众不同。我们当然可以尝试通过改变字母分布来改进这一点。有些字符,比如 x 或 q,在名字中本来就很少见,因此把所有字母都赋予同等概率,其实并不合理。
除此之外,名字本身也具有内在结构:某些字符更容易跟在另一些字符之后。例如,a 后面跟 n,在很多名字里都很常见,比如 "Hannah""Morgan" 或 "Jordan"。
9.2 自监督学习
大多数 NLP 模型的核心,都建立在统计生成这一思想之上。它利用概率分布来预测并生成文本序列。比如,当我们用统计方式来建模名字时,本质上是在计算某些字母序列按特定顺序出现的概率。以名字 "John" 为例,它的概率由以下因素共同决定:J 作为首字母出现的可能性,接着出现 o 的可能性,再接着是 h,最后是 n,按照这个精确顺序依次相乘得到。
为了学习这种结构,我们可以从查看一份庞大的名字列表开始,并统计每个字母出现在另一个字母之后的次数。换句话说,我们是在学习一个关于字母对 的概率分布。这种模型叫做 bigram model(二元模型) ,其中 "bi" 表示我们观察的是成对的字母。
要构造这样的模型,我们首先需要一大份现有名字的列表。巧的是,美国社会保障局(US Social Security Administration)会汇总所有在美国出生婴儿的姓名,并把这些数据开放下载。
我们可以下载 2022 年最新版的姓名列表,它保存在 ../data/p2ch9/names_2022.txt 中,并利用它来近似估计名字中各个字母出现的概率:
css
# In[]:
names = []
with open('../data/p2ch9/names_2022.txt', 'r') as file:
for line in file:
name, _, _= line.lower().strip().split(',')
names.append("$" + name + "$")
len(names)
# Out[]:
31915这样我们就收集到了一份包含 31,915 个名字的列表。现在来看看每一对字母的分布情况。
要构造字符对的分布,我们需要一个 27 × 27 的矩阵,如图 9.2 所示。这个矩阵中的每一行,都对应于"某个给定字符之后,不同字符出现的可能性"。例如,第一行表示:在 $ 之后,各种可能字符分别出现的概率。矩阵中的某个位置,比如 [2, 3](这里使用从 0 开始的索引),就表示某个字符------在这个例子里是 c(第 4 列)------紧跟在 b(第 3 行)之后出现的概率。
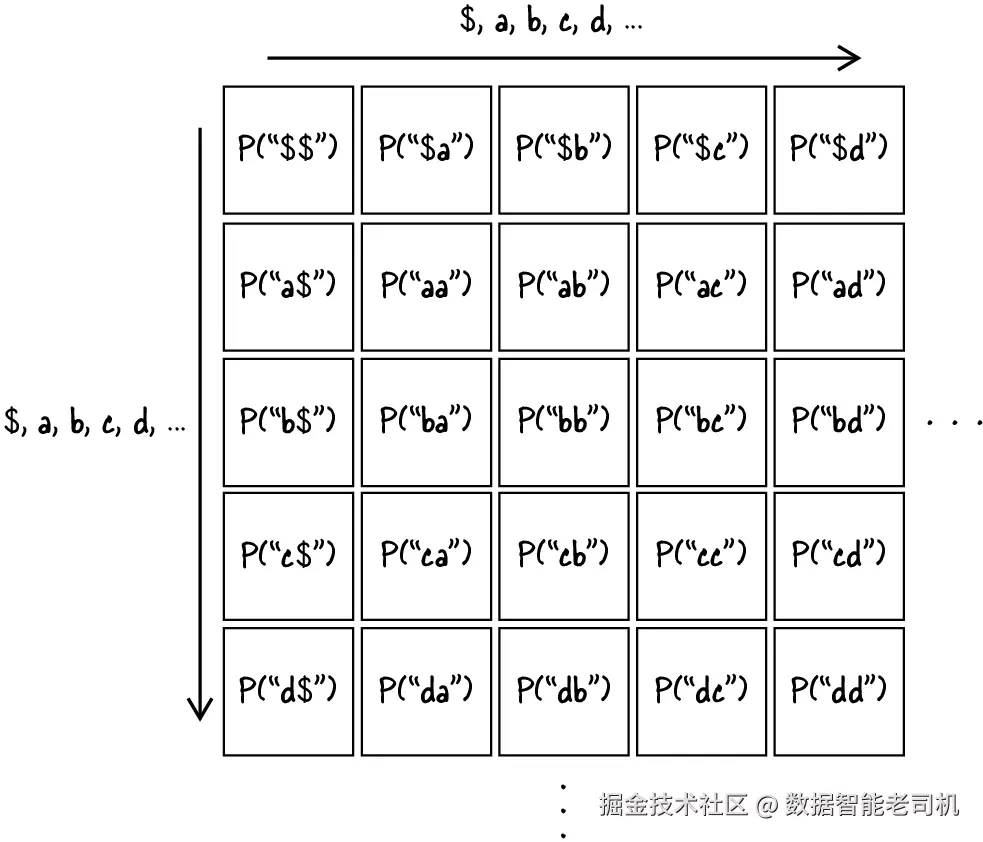
图 9.2 前 5 个字符的 bigram 概率示意,这种结构可以扩展到全部 27 个字符
这个 bigram 模型可以这样构造:
ini
# In[]:
bigram = torch.zeros((vocab_size, vocab_size)) #1
total = 0
for name in names:
for ch1, ch2 in zip(name, name[1:]):
ch1_int = ch_to_i[ch1]
ch2_int = ch_to_i[ch2]
bigram[ch1_int][ch2_int] += 1
total += 1
bigram /= total
#1 我们创建一个 27 × 27 的矩阵,用来存储每种字符对出现的计数。这段代码首先初始化了一个全零矩阵,用于存放 bigram 的计数。然后,它遍历数据集中的所有名字;对每个名字,再遍历其中所有相邻字符对。对于每一对字符,它都会把 bigram 矩阵中对应位置的计数加一,同时把字符对总数也加一。最后,再用总字符对数去归一化 bigram 矩阵,从而得到概率。
接下来,我们就可以从这个分布中采样来生成名字:
ini
# In[]:
for i in range(5):
generated = "$"
while True:
bigram_probs = bigram[char_to_index[generated[-1]]]
sampled_char = index_to_char[
torch.multinomial(bigram_probs, 1).item()
]
if sampled_char == "$":
break
generated += sampled_char
print(f"name {i}: {generated[1:]}")
# Out[]:
name 0: liahuli
name 1: deiannnis
name 2: cl
name 3: de
name 4: neynee这个结果算是稍微好了一点。现在这些名字至少可读了,有的甚至还挺像能发音的。不过,它们仍然不够真实。比如 cl 和 de 这样的输出,看上去显然不像是合格的人名。
在这里,需要特别强调一个根本性的范式转变。对于分类或回归这类以"精确预测"为目标的任务,我们必须把模型的预测与每个输入所对应的"正确答案"或 ground truth 进行比较。通常,这些 ground truth 是通过人工标注训练数据得到的,这个过程就叫做监督学习(supervised learning) ,因为其中有人类介入。而在自监督学习(self-supervised learning) 中,任务会被设计成这样一种形式:即使原始数据没有标签,ground truth 也可以从数据本身推导出来。
换句话说,在前面几章所有例子中,我们都依赖显式的输入 (x) 和目标 (y) 来训练模型。然而,在这个例子里,我们并没有明确给出的目标。我们是在没有任何标签的情况下,直接从数据本身中学习。
自监督学习的强大之处在于:随着数据越来越多,我们就能够构建越来越复杂的模型。这些模型可以学习数据内部的结构,并利用这些潜在信息去生成新的数据。这种方法非常有威力,因为它避免了昂贵而耗时的人工标注过程。
9.2.1 Bigram 模型的局限
我们刚才计算的是:对于每个字符对,给定前一个字符、下一个字符出现的概率,也就是 P(c_n | c_{n-1})。由于我们这里只处理字符,因此这样做是可行的;但即便词汇表只有 27 个字符,可能的字符对数量也已经是 27^2 = 729。也就是说,我们需要计算 729 个不同的概率!
而这个数字会随着词汇表大小呈指数增长。举个例子,如果词汇表大小是 1000,那么可能的字符对数量就是 1000^2 = 1,000,000。而其中大多数概率都会是 0,因为很多字符后面根本从来不会跟着某些其他字符。这种在计算稀有或从未见过的组合时效率极低的问题,就被称为数据稀疏性(data sparsity) 。而如果我们的词汇表不是字符,而是英文中的单词,那么词汇表规模会达到几十万,这种方法显然就更加不可行了。
如果我们还想捕捉更长距离的依赖关系,同样会遇到类似的复杂度问题。比如,如果想建模"给定前两个字符,下一个字符出现的概率",也就是 P(c_n | c_{n-1}, c_{n-2}),那么我们就需要计算 27^3 = 19,683 个概率。而随着你想考虑的上下文长度增加,这个数字也会继续呈指数爆炸。
为了解决这些挑战,神经网络提供了更优的方案。与传统模型不同,神经网络会学习一种稠密的、连续的表示(dense continuous representations) ,从而有效捕捉字符之间的关系。借助这种表示,神经网络不仅可以对未见过的模式进行泛化,也能够更高效地处理数据稀疏问题和长距离依赖问题。更重要的是,它们的参数规模不会随着词汇表大小或依赖长度的增加而指数膨胀,因此在复杂语言任务中才具备现实的计算可行性。
9.3 构造训练数据
在开始用神经网络训练之前,我们需要先把要送入网络的训练数据整理成合适的格式。由于这是一个无监督性质的任务,原始数据中并没有现成给出的"输入---目标"对。因此,我们需要自己通过切分名字序列来构造输入---目标对:输入序列将是名字的前 n 个字符,而目标序列则是第 n+1 个字符。然后,我们就利用这些配对,训练模型去根据前面的字符预测下一个字符:
ini
# In[]:
example_name = "$ada$"
encode = lambda word: torch.tensor([ch_to_i[c] for c in word])
decode = lambda tensor_i: ''.join(i_to_ch[i.item()] for i in tensor_i)
print(encode(example_name))
print(decode(encode(example_name)))
name_indices = [encode(name) for name in names]
target_indices = [name_index[1:] for name_index in name_indices]
# Out[]:
tensor([0, 1, 4, 1, 0])
$ada$首先,我们定义了 encode 和 decode 函数,用来完成字符和整数之间的双向转换。接着,我们用这些函数把所有名字都转成整数序列。然后,再通过把输入序列整体向后平移一个字符,生成对应的目标序列。比如,对于名字 $ada$(记住 $ 是边界字符),输入序列是 [0, 1, 4, 1, 0],而目标序列则是 [1, 4, 1, 0]。
这里的核心思想是:我们的数据将由许多这样的样本组成------输入是"从开头到某个位置为止的连续子序列",对应的目标则是该位置之后的那个字符。对于 $ada$ 来说:
第一条样本:
输入:[0](表示 $)
目标:[1](表示 a)
第二条样本:
输入:[0, 1](表示 $a)
目标:[4](表示 d)
第三条样本:
输入:[0, 1, 4](表示 $ad)
目标:[1](表示 a)
第四条样本:
输入:[0, 1, 4, 1](表示 $ada)
目标:[0](表示 $)
注意,如图 9.3 所示,仅仅从一个名字中,我们就可以构造出多组输入---目标对。
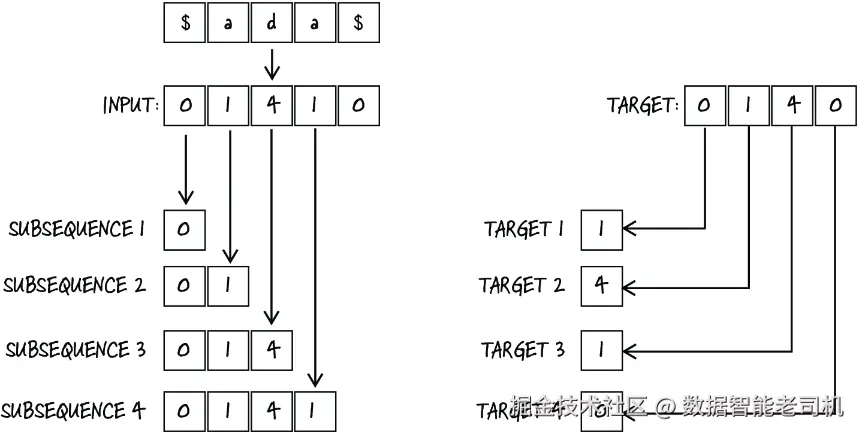
图 9.3 每个输入都可以生成多个子序列,而每个子序列都有一个从数据本身推导出来的对应目标
为了便于模型处理,我们会把输入和目标都填充到相同长度(在这里,就是整个数据集中最长名字的长度)。为了保持长度一致,我们会用 0 来填充输入序列,而用 -1 来填充目标序列。之后在损失函数中,我们会显式指定忽略这些 -1 值,也就是说,这些位置的目标不会被参与计算:
ini
# In[]:
from torch.nn.utils.rnn import pad_sequence
X = pad_sequence(name_indices, batch_first=True, padding_value=0)
max_name_length = max(len(name) for name in names)
target_indices.append(torch.empty((max_name_length),
↪dtype=torch.long)) #1
Y = pad_sequence(target_indices, batch_first=True, padding_value=-1)[:-1]
print(X[0])
print(Y[0])
# Out[]:
tensor([ 0, 15, 12, 9, 22, 9, 1, 0, 0, 0, 0])
tensor([15, 12, 9, 22, 9, 1, 0, -1, -1, -1, -1])
#1 这里用了一个小技巧:往 target_indices 里额外追加一个长度为 11 的张量,这样就能保证 Y 被 pad 到统一长度。现在,我们可以定义一个辅助函数,用来构造输入---目标 batch。这个函数接收一个 batch 大小,并返回相应的输入与标签。之后我们会用它来生成训练数据:
ini
# In[]:
def get_batch(batch_size=64):
random_idx = torch.randint(0, X.size(0), (batch_size,))
inputs = X[random_idx]
labels = Y[random_idx]
return inputs, labels
inputs, labels = get_batch(3)
print(inputs)
print(labels)
# Out[]:
tensor([[ 0, 2, 18, 9, 26, 5, 25, 4, 1, 0, 0],
[ 0, 21, 26, 9, 1, 19, 0, 0, 0, 0, 0],
[ 0, 14, 15, 15, 18, 21, 12, 1, 9, 14, 0]])
tensor([[ 2, 18, 9, 26, 5, 25, 4, 1, 0, -1, -1],
[21, 26, 9, 1, 19, 0, -1, -1, -1, -1, -1],
[14, 15, 15, 18, 21, 12, 1, 9, 14, 0, -1]])到这里,我们的数据终于全部准备好了!接下来,开始真正使用它们吧。
9.4 Embedding 与线性层
在第 4 章中,我们讨论过多种数据表示方式,其中也包括文本数据。我们看到,文本可以表示成文本嵌入(text embeddings) :也就是把单词映射到一个更高维的空间中,以帮助后续学习。在当前这个问题里,我们也可以用 embedding 来表示字符。现在,每个字符只是用一个整数来表示;但我们完全可以把它变成一个数值向量。这样做有助于捕捉字符之间的相似性。比如,元音字母 "a" 和 "e" 在使用方式上会比 "a" 和 "z" 更接近,因此它们的 embedding 也会更相似(后面我们会把这一点可视化出来)。
幸运的是,在 PyTorch 中,已经有现成模块能替我们做这件事。nn.Embedding 模块接收一个索引张量,并返回对应的 embedding 张量。我们需要指定两个参数:字典大小------在这里就是 27 个字符的词汇表大小;以及 embedding 的维度,我们这里把它固定设成 3(设成 3 只是一个任意选择):
ini
# In[]:
embedding_dim = 3
embedding = nn.Embedding(vocab_size, embedding_dim)
example_input = torch.tensor([1, 1, 0, 2])
input_embd = embedding(example_input)
print(input_embd.shape)
input_embd
# Out[]:
torch.Size([4, 3])
tensor([[-2.0552, -0.5413, -0.2367],
[-2.0552, -0.5413, -0.2367],
[ 0.6718, -0.1038, 2.3367],
[-0.0655, 1.0041, 2.0066]], grad_fn=<EmbeddingBackward0>)nn.Embedding 模块就是专门为整数索引设计的。它本质上是一个可训练的查找表,里面存储了 27 个字符各自的 embedding;对于输入中的每个索引,它都会返回对应行上的数值,如图 9.4 所示。这些 embedding 最开始是随机初始化的,随后会在训练过程中通过反向传播不断更新,让模型学到最适合当前任务的字符表示。

图 9.4 embedding 查找过程。每个索引都会去 embedding 张量中查找对应的一行数值。
这里输入张量长度为 4,因此输出的 embedding 张量形状就是 4 × 3:因为输入里有 4 个索引,而每个索引对应一个长度为 3 的向量,所以一共得到 4 行,每行 3 个值。embedding 张量中的每一行,分别对应输入张量中相同位置字符的 embedding。例如,前两行之所以完全一样,是因为输入张量中的前两个索引本身就是相同的。
现在,我们就可以在之前的 bigram 模型基础上进一步进化,构建一个真正的深度学习模型:利用 embeddings 和线性层。在这个新模型的前向传播过程中,我们会先把每个子序列转换成一串 embedding;然后把这些 embedding 拉平成一个长向量,并送入线性层得到输出;接着,我们就可以利用这个输出来预测下一个字符。图 9.5 展示了这个模型的结构:
ini
# In[]:
class SequenceMLP(nn.Module):
def __init__(self, vocab_size, max_sequence_length,
↪ embedding_dim, hidden_dim=32):
super().__init__()
self.vocab_size = vocab_size
self.max_sequence_length = max_sequence_length
self.embedding_dim = embedding_dim
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.linear = nn.Linear(embedding_dim * max_sequence_length,
↪ hidden_dim)
self.relu = nn.ReLU()
self.out = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
batch_size, seq_len = x.shape
sequence_embeddings = torch.zeros(batch_size, seq_len,
↪ self.max_sequence_length * self.embedding_dim)
for i in range(seq_len): #1
subsequence = torch.zeros(batch_size, self.max_sequence_length,
↪ dtype=torch.int)
prefix = x[:, :i+1]
subsequence[:, :i+1] = prefix
emb = self.embedding(subsequence)
sequence_embeddings[:, i, :] = emb.view(
↪batch_size, -1) #2
x = self.linear(sequence_embeddings) #3
x = self.relu(x)
x = self.out(x)
return x
embedding_dim = 3
max_sequence_length = X.shape[1]
model = SequenceMLP(vocab_size, max_sequence_length, embedding_dim)
#1 我们沿着序列长度进行迭代,并为序列中的每个位置构造一个子序列。
#2 表示这个子序列的 embedding 会被拉平成一个数值列表。
#3 这些拉平后的 embedding 会经过一个隐藏层和一个输出层,从而得到最终输出。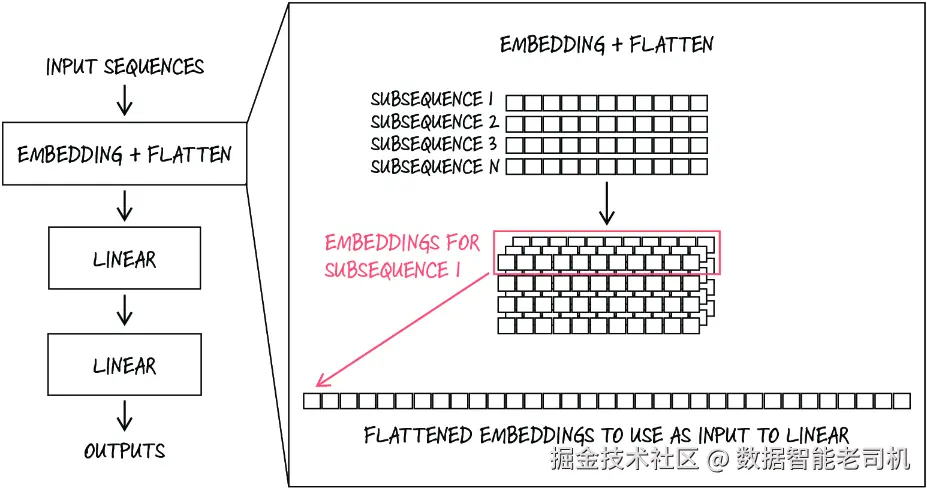
图 9.5 模型结构示意图
训练循环与前几章里看到的相似。这里我们不去特别强调超参数,因为当前的重点是探索不同架构,而不是追求一个最先进模型。我们将使用简单的 SGD 优化器和交叉熵损失函数,并每隔 1,000 步报告一次损失:
ini
# In[]:
import torch.optim as optim
def train(model, optimizer, num_steps=10_001, loss_report_interval=1_000):
losses = []
for i in range(1, num_steps):
inputs, labels = get_batch()
optimizer.zero_grad()
logits = model(inputs)
loss = F.cross_entropy(logits.view(-1, logits.shape[-1]),
↪ labels.view(-1), ignore_index=-1) #1
losses.append(loss.item())
if i % loss_report_interval == 0:
print(f'Average loss at step {i}: {sum(losses[
↪-loss_report_interval:]) / loss_report_interval:.4f}')
loss.backward()
optimizer.step()
optimizer = optim.SGD(model.parameters(), lr=0.1)
#1 我们需要把 logits 拉平成一个二维张量,同时把 labels 拉平成一个一维张量。关于我们的数据组织方式,这里有一个重要说明:每个训练 batch 都包含多个名字,而每个名字又会生成多条训练样本。对于每个名字,我们通过构造越来越长的子序列(作为输入)及其对应的下一个字符(作为目标),从而生成多组输入---目标对。这样做的好处是:能够从有限的名字数据集中尽可能榨取更多学习信号。这和之前见过的情况不同------在此前,batch_size 就是观测到的样本数;而现在,每个样本内部本身又包含多个输入和目标。
因此,在损失函数中,我们会把 logits 展平成一个二维张量,其中第二维对应 27 个可能字符;而目标则展平成一个一维张量,记录正确字符。同时,我们会指定忽略目标中的 -1 值,这样那些无效的填充位置就不会被纳入训练。
最后,我们终于可以开始训练了:
yaml
# In[]:
train(model, optimizer)
# Out[]:
Average loss at step 1000: 2.6099
Average loss at step 2000: 2.5163
Average loss at step 3000: 2.4691
Average loss at step 4000: 2.4229
Average loss at step 5000: 2.3910
Average loss at step 6000: 2.3728
Average loss at step 7000: 2.3593
Average loss at step 8000: 2.3517
Average loss at step 9000: 2.3420
Average loss at step 10000: 2.3352要从这个训练好的模型中采样并生成名字,我们可以使用一种自回归的字符级生成方法(autoregressive character-level generation) 。(所谓 autoregressive,指的是模型每次只生成序列中的一个 token,并把之前生成出来的 token 当作下一步预测的输入。)具体做法是:先把 $ 作为模型的起始字符输入进去。模型由于已经学会根据前文字符预测下一个字符,因此会输出一个预测结果。
这个被预测出来的字符随后会被追加到输入序列后面,再次喂回模型,从而形成一个不断增长的输入序列;每新生成一个字符,序列就长一步。模型会持续进行这样的预测和生成,直到生成出终止字符 $ 为止。正是这一自回归过程,让模型能够以与前文上下文相一致的方式,生成名字或者任何其他字符序列:
ini
# In[]:
def generate_samples(model, num_samples=1, max_len=max_name_length):
sequences = torch.zeros((num_samples, 1)).int()
for _ in range(max_len):
logits = model(sequences)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
sequences = torch.cat((sequences, idx_next), dim=1)
for sequence in sequences:
indices = torch.where(sequence == 0)[0]
end = indices[1] if len(indices) > 1 else max_len
sequence = sequence[1:end]
print(decode(sequence))
generate_samples(model, num_samples=10)
# Out[]:
jatini
tladauh
ceney
aamsse
keisvta
yassi
aenmli
lydude
ikiyo
jayhal这次生成的结果比之前要好得多。从直觉上看,这些输出明显更像"名字",在形式和长度上也更真实。我们可以看到,模型正在学习名字内部的结构,并利用这种潜在信息去生成新的名字。
9.4.1 可视化 embeddings
训练带来的效果同样也体现在 embedding 的取值上。经过训练之后,这些 embedding 已经能够有效捕捉字符的结构性细微差别。每个字符现在都由一个长度为 3 的张量表示,因此我们可以把它们可视化到一个三维空间中。在这个可视化中,张量的第一个、第二个和第三个值,分别对应 x、y、z 坐标。
在图 9.6 中,我们可以看到:元音字母的 embedding 更靠近彼此,辅音字母的 embedding 也更靠近彼此,而特殊字符 $ 则明显与其他字符分离开来。这是模型从英语及我们这份名字数据集中学习到字符结构之后产生的结果。
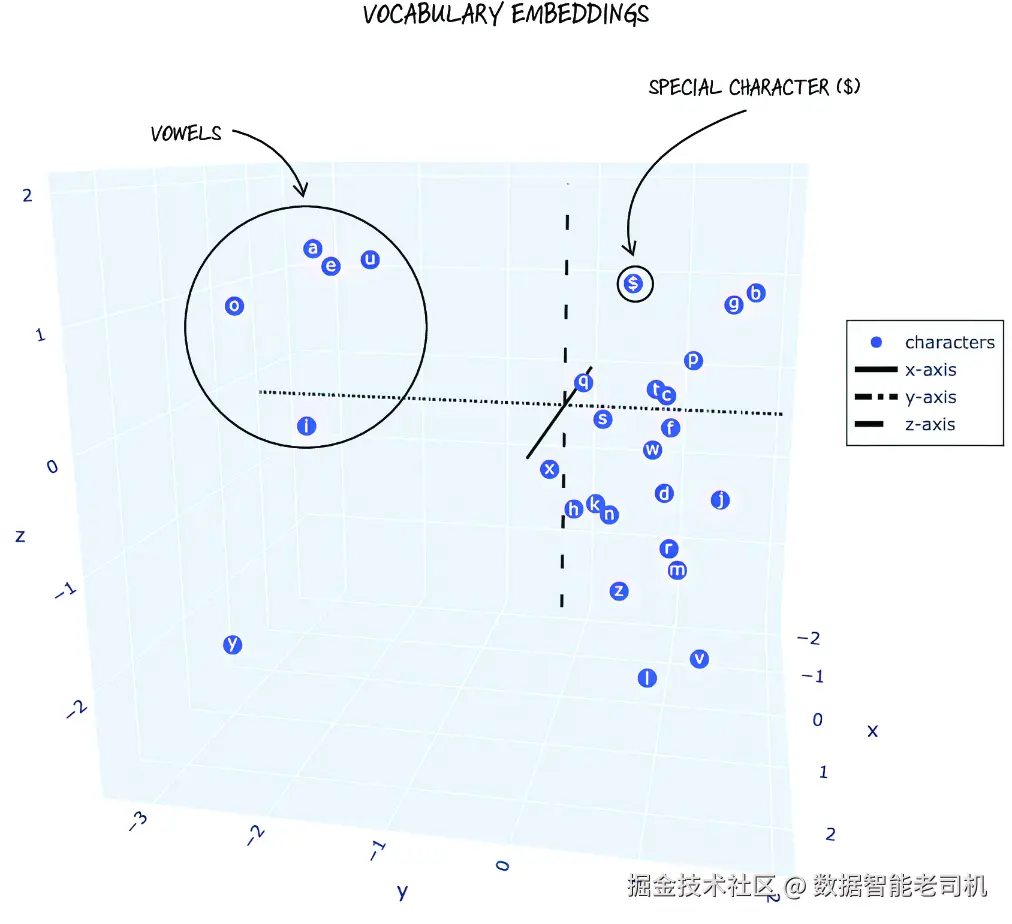
图 9.6 在三维空间中可视化后的 embeddings
embedding 空间的目标,是尽可能多地编码与字符相关的信息,包括它本身的含义、它在名字中的角色,以及它与其他字符之间的关系。虽然在这个例子中我们只用了 3 个维度,主要是为了便于可视化,但在真实应用中,embedding 的维度通常会达到上千,用来表示语言中复杂的语义与句法关系。
我们已经走到了很远的地方,但其实还可以做得更好。接下来,我们将关注一种更复杂的模型:它能够动态地捕捉数据结构,以及字符序列内部的关系。这也正是**注意力(attention)**登场的地方。
9.5 注意力(Attention)
Embedding 确实能够捕捉字符之间的语义和句法关系,但它对每个字符来说仍然是静态的 。同一个字符,不管出现在什么上下文中,它对应的 embedding 都是一样的。在我们前面的模型里,字符 a 无论出现在 car 中(发音更像 far 里的 a),还是出现在 care 中(发音完全不同),其 embedding 都会一模一样。尽管它还是那个字母,但它在不同单词中的作用差异巨大,而静态 embedding 无法表达这种差异。
相比之下,注意力机制会根据每个字符所在的上下文动态地调整模型对输入序列不同部分的关注程度。这使得模型可以依据周围上下文,为每个字符赋予不同的重要性权重,从而更好地生成在上下文中恰当的名字。
一个很形象的现实类比,是舞台演出中的追光师。你可以把整个舞台看成整条序列,把名字中的每个字符看成舞台上的演员。如果没有注意力机制,聚光灯就会平均地照在所有演员身上,不管当前是谁在说台词、谁在这一场戏里最关键------这就像传统 embedding 一样,不管上下文如何,每个字符都被同等对待。而有了注意力机制,追光师(也就是模型)就会动态地调整灯光的焦点和强度,把注意力集中到当前正在说话、或者在此刻最符合场景上下文的演员身上。
在实际计算中,注意力是通过三个组成部分实现这种"聚焦"的:query、key 和 value。这些术语和信息检索系统中的说法是一致的。比如你在 Google 上搜索时,搜索引擎会把你的查询(query,也就是搜索文本)与一组键(key,也就是被索引的网页)进行匹配,然后返回最相关的值(value,也就是搜索结果)。
更具体地说:
- Query(查询) ------ 表示在序列的某个位置上,我们此刻"想找什么"。
- Key(键) ------ 表示序列中每个位置都"包含了什么信息",看它是否和我们正在寻找的内容匹配。
- Value(值) ------ 表示一旦 query 和 key 匹配上之后,真正会被取出来并参与后续计算的内容。
正是这三者共同作用,让注意力机制能够判断:对于序列中的某个位置来说,输入序列中的哪些部分最相关。当某个位置上的 query 与另一个位置上的 key 匹配得很好时,模型就会给对应的 value 更高的权重,从而把注意力集中在最有价值的信息上,以帮助生成序列中的下一个字符。
我们接下来要讨论的,是一种特殊类型的注意力机制,叫做 self-attention(自注意力) 。所谓自注意力,指的是一个序列对它自己施加注意力(与之相对的是 cross-attention,它涉及两个不同序列之间的注意力)。现在,让我们更详细地看看 self-attention 是如何工作的。
9.5.1 点积自注意力(Dot Product Self-Attention)
自注意力是帮助我们捕捉序列中不同位置之间关系的核心机制。它的工作方式如下:
-
输入(Inputs)
一个自注意力块接收 N 个输入
(x1, ..., xn),其中每个输入的维度都是 D。在我们的字符级模型里,每一个输入对应一个字符的 embedding。 -
构造 value(Creating values)
对于序列中的每个位置 m,我们会通过一个可学习的线性变换,把该位置的 embedding 转成一个 "value" 向量:
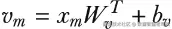
这本质上就是对每个位置应用一个 nn.Linear 层,从而生成 N 个 D 维 value 向量。
-
注意力权重(Attention weights)
对于序列中的每个位置 n,我们会计算一组注意力权重,用来决定它应该把注意力分配给序列中哪些位置 m。这些权重会被归一化,使其总和为 1。
-
加权组合(Weighted Combination)
位置 n 的输出,是所有 value 向量的加权和:
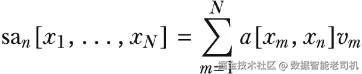
其中,权重 a_n[x_m, x_n] 反映了:位置 m 对位置 n 有多重要。此刻,我们先暂时假设这些权重已经给定------下一小节中我们再来详细讨论它们到底是怎么计算出来的。
这个机制使模型在处理序列中某个位置时,能够动态聚焦到输入中真正相关的部分。例如,在预测名字中的下一个字符时,模型可能会对那些包含"经常会影响后续字符"的位置赋予更高权重(见图 9.7)。
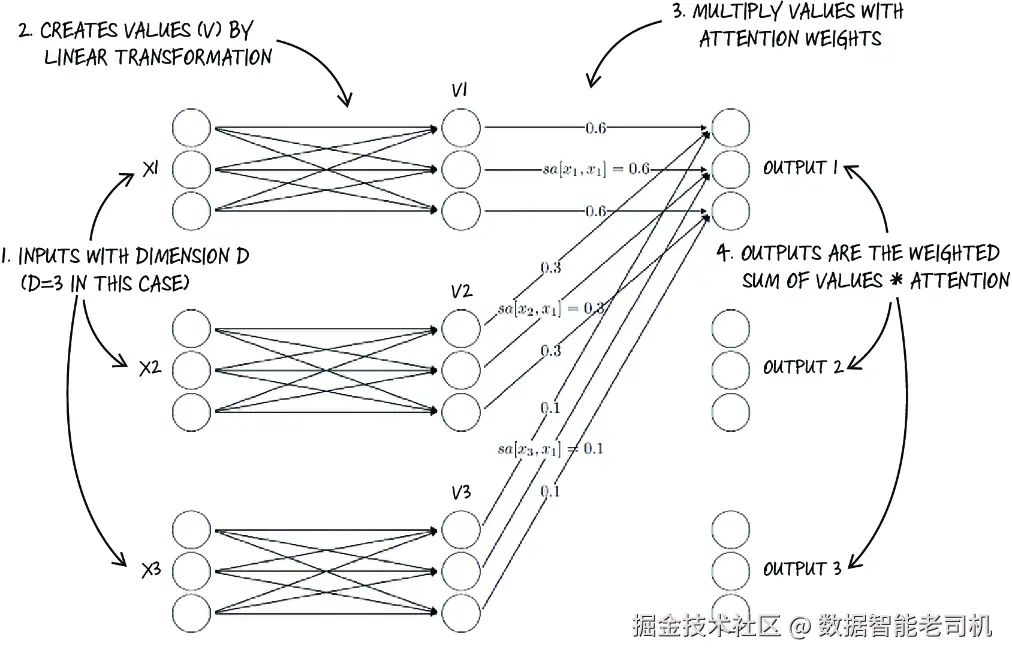
图 9.7 自注意力的逐步过程:从输入到输出
换一个角度理解,注意力也可以被看作是一种信息路由(routing information) 机制。它决定了:在每一步计算中,输入数据的哪些部分应该被重点关注。比如,在处理名字的某一部分时,注意力机制也许会把更多注意力分配给关键字符,而对没那么重要的字符则关注较少。
计算注意力权重
不过,问题还没完全解决:我们刚才一直在使用那些"神奇"的注意力权重 a_n[x_m, x_n],可它们到底是怎么来的?
要计算注意力权重,我们首先需要分别计算一组 query 向量 和 key 向量。其方式与刚才计算 value 时类似,只不过使用的是另一组不同的权重和偏置:
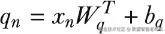
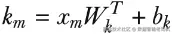
接着,我们通过对 query 和 key 向量做点积,再把结果送入 softmax 函数,来得到注意力权重:
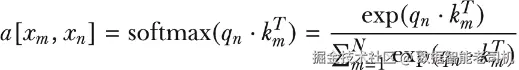
这就得到了某一对 (m, n) 对应的注意力权重。softmax 保证:对于固定的 n,当 m 从 1,...,N 枚举时,这些权重加起来会等于 1;这一点非常重要,因为这样加权和才是一个规范意义上的"平均"。
用代码实现点积自注意力
为了让这一过程更具体,我们来看完整的点积自注意力代码实现(code/p2ch9/attention.ipynb)。在这个例子中,我们的输入 x 形状是 [2, 3];因此 query、key 和 value 矩阵的形状也都是 [2, 3],表示两个位置,每个位置有三个 embedding 维度。
代码清单 9.2 attention.ipynb
ini
# In[]:
torch.manual_seed(0)
x = torch.rand(2, 3)
query = F.linear(x, weight=torch.rand(3, 3),
↪bias=torch.rand(3)) #1
key = F.linear(x, weight=torch.rand(3, 3), bias=torch.rand(3))
value = F.linear(x, weight=torch.rand(3, 3), bias=torch.rand(3))
def dot_product_attention_single(q, k, v):
attn_weights = q @ k.T #2
attn_weights = F.softmax(attn_weights, dim=-1) #3
output = attn_weights @ v #4
return output
dot_product_attention_single(query, key, value)
# Out[]:
tensor([[1.3667, 0.6913, 1.0614],
[1.3718, 0.6930, 1.0627]])
#1 用 F.linear 对输入 x 做线性变换,得到 query、key 和 value 向量
#2 针对 N 个输入的全部点积,可以写成一次矩阵乘法(@),其中 .T 用于矩阵转置,以便正确对齐维度。
#3 对这些点积结果应用 softmax,得到注意力权重。这里沿着 -1 维应用,因为我们希望每一行上的值形成一个平均分布。
#4 用这些注意力权重对 value 做加权求和这个实现通过矩阵乘法,一次性高效地计算出 query 向量和 key 向量之间的所有点积。然后,再用 softmax 把这些分数变成规范化的注意力权重。最后,再用这些权重去乘 value 向量,得到一个加权和,其中越相关的信息,对输出的贡献也越大。
9.5.2 缩放点积因果自注意力(Scaled Dot Product Causal Self-Attention)
现在,我们已经得到了一种新的输入表示方式:它在生成表示时,会考虑序列中其他所有元素之间的关系,如图 9.8 所示。实际使用中,这种点积注意力通常还要加上三个扩展:
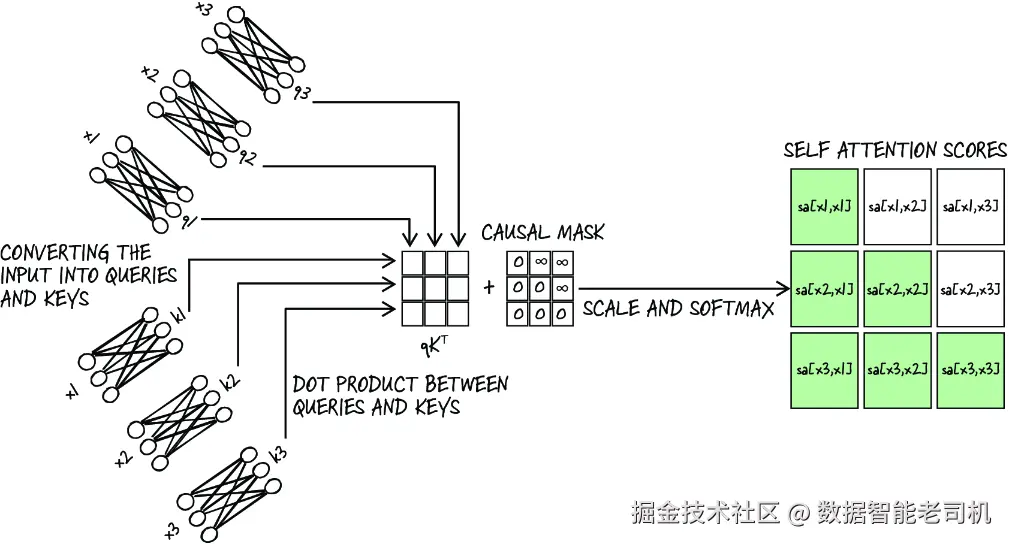
图 9.8 完整的因果自注意力机制
- Batching(批处理) ------ 我们希望支持一批输入同时进入模型,因此需要保证对 batch 中每一个输入都正确计算注意力权重。
- Causal masking(因果掩码) ------ 在某些情况下,我们必须确保注意力机制不会"偷看"序列中未来的位置。这对于自回归模型尤为重要,因为我们希望模型在当前时刻只能看到之前的元素。
- Scaling(缩放) ------ 我们希望对注意力分数进行适当缩放,以防止梯度消失或爆炸。
因此,我们前面的实现可以改写为:
ini
# In[]:
torch.manual_seed(0)
x = torch.rand(1, 2, 3) #1
query = F.linear(x, weight=torch.rand(3, 3), bias=torch.rand(3))
key = F.linear(x, weight=torch.rand(3, 3), bias=torch.rand(3))
value = F.linear(x, weight=torch.rand(3, 3), bias=torch.rand(3))
def scaled_dot_product_causal_attention(q, k, v):
attn_weights = q @ k.transpose(1, 2) #2
mask = torch.tril(torch.ones(attn_weights.
↪shape[1:]), diagonal=0) #3
attn_weights = attn_weights.masked_fill(mask == 0, value=float('-inf'))
attn_weights = attn_weights / torch.sqrt(torch.tensor(
↪k.shape[-1]).float()) #4
attn_weights = F.softmax(attn_weights, dim=-1)
output = attn_weights @ v
return output, attn_weights
output, attn_weights = scaled_dot_product_causal_attention(query, key, value)
output
# Out[]:
tensor([[[1.6253, 0.7788, 1.1252],
[1.3849, 0.6974, 1.0659]]])
#1 在这个例子里,我们使用 batch size 为 1,因此输入现在是一个 1 × 2 × 3 的三维张量。
#2 这里我们用 transpose 把 key 张量最后两个维度交换,以便进行点积。第一维保持为 batch 维度。
#3 我们构造一个掩码,阻止模型去关注未来的 token。这里用 tril 创建一个下三角全 1 矩阵,再把上三角部分填成负无穷。这样一来,未来 token 对应的位置在 softmax 后权重就会变成 0。
#4 我们把注意力分数除以 key 向量维度的平方根来做缩放。这是一个常见技巧,用来避免梯度消失或爆炸。恭喜你!到这里,你已经亲手实现了一个缩放点积因果注意力机制 。这正是很多最先进模型背后的核心运算。当然,不出所料,PyTorch 也已经提供了现成实现可供直接调用;不过,在真正理解底层机制之后,你完全值得给自己点个赞。我们可以验证:自己的实现与 PyTorch 内置函数 F.scaled_dot_product_attention 是等价的:
ini
# In[]:
expected_output = F.scaled_dot_product_attention(
↪query, key, value, is_causal=True)
print(torch.allclose(output, expected_output)) #1
# Out[]:
True
#1 这里用 torch.allclose 来检查两个张量是否足够接近,从而可视为相等。注意 PyTorch 中 F.scaled_dot_product_attention 的实现,在结果上与我们自己写的版本是等价的;但它在内部使用了高度优化过的 kernel,效率非常高。因此,在生产环境中,我们通常应当优先使用 PyTorch 官方实现。
现在既然我们已经有了自己的注意力实现,就可以把它真正用到一个新模型里了。和之前一样,我们还是会先用 embedding 层把输入序列转换成一组 embedding;不过,这一次,我们不再把这些 embedding 全部展平然后拼接起来,而是让注意力机制去捕捉这些 embedding 之间的关系。最后,和前一个模型一样,我们仍然会用若干线性层把注意力输出进一步变换成最终输出:
ini
# In[]:
class AttentionMLP(nn.Module):
def __init__(self, n_embd, vocab_size, block_size, n_hidden=64):
super().__init__()
self.tok_embd = nn.Embedding(vocab_size, n_embd)
self.attn_weights = None
self.query_proj = nn.Linear(n_embd, n_embd)
self.key_proj = nn.Linear(n_embd, n_embd)
self.value_proj = nn.Linear(n_embd, n_embd)
self.register_buffer("mask", torch.tril(torch.ones(
↪(block_size, block_size)), diagonal=0))
self.mlp = nn.Sequential(
nn.Linear(n_embd, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_embd)
)
self.output_proj = nn.Linear(n_embd, vocab_size)
def forward(self, x):
x = self.tok_embd(x)
batch_size, seq_len, embd_dim = x.shape
q = self.query_proj(x)
k = self.key_proj(x)
v = self.value_proj(x)
attn_weights = q @ k.transpose(1, 2)
attn_weights = attn_weights.masked_fill(self.mask[
↪:seq_len, :seq_len] == 0, value=float('-inf'))
attn_weights = attn_weights / torch.sqrt(torch.tensor(
↪k.shape[-1]).float())
self.attn_weights = F.softmax(attn_weights, dim=-1)
x = self.attn_weights @ v
x = self.mlp(x)
x = self.output_proj(x)
return x
model = AttentionMLP(32, vocab_size, max_name_length)
optimizer = optim.SGD(model.parameters(), lr=0.01)
train(model, optimizer, num_steps=10_001, loss_report_interval=1_000)
# Out[]:
Average loss at step 1000: 2.9688
Average loss at step 2000: 2.6580
Average loss at step 3000: 2.5903
Average loss at step 4000: 2.5739
Average loss at step 5000: 2.5555
Average loss at step 6000: 2.5278
Average loss at step 7000: 2.4915
Average loss at step 8000: 2.4602
Average loss at step 9000: 2.4377
Average loss at step 10000: 2.4284这里的 train() 和 generate() 函数都和之前是一样的,所以我们可以直接拿来训练这个新模型并生成样本。现在来看看它的效果:
bash
# In[]:
generate_samples(model, 10)
# Out[]:
venen
cckaeelr
karori
resedl
wlynhoe
jom
amylas
ryinya
kaihun
ernii我们得到的效果和前一个模型差不多,但这一次,我们不需要再显式地通过遍历每个子序列、再把 embedding 拉平展开的方式来处理输入了。这是因为注意力机制本身就能够捕捉字符序列内部的关系,并利用这些信息来预测下一个字符。
另外,在我们的实现中还有一个额外的好处:我们把注意力权重也一并返回出来了,因此可以把注意力分数可视化,看看模型在生成下一个字符时究竟把注意力集中到了哪些字符上。图 9.9 展示了一个以名字 "john" 为例的可视化结果。
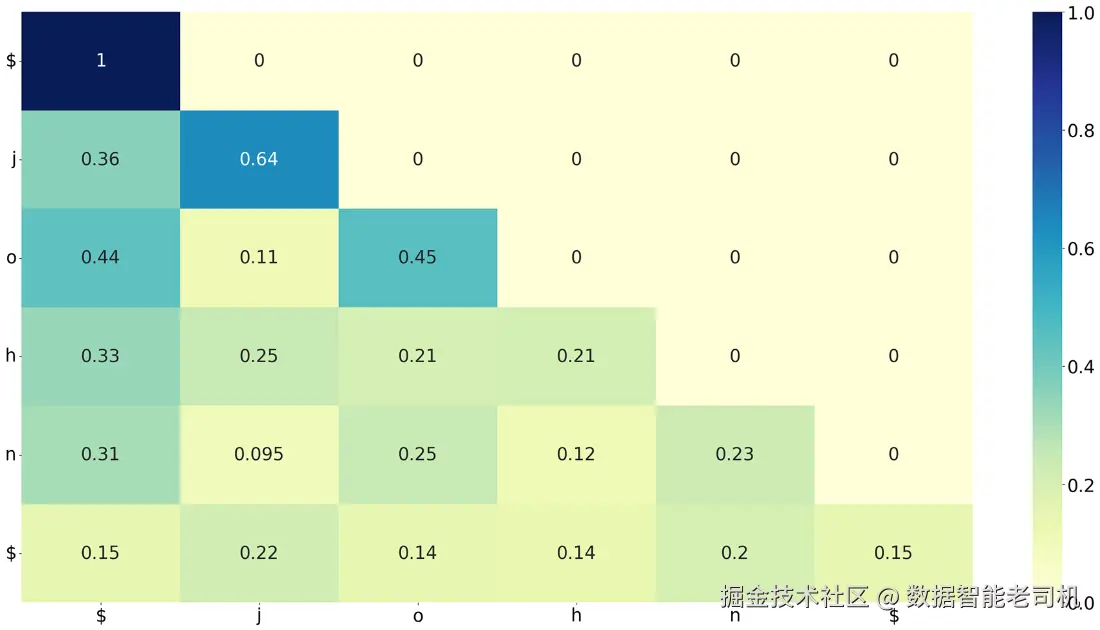
图 9.9 名字 "john" 的注意力权重可视化。图中的每一行加起来都等于 1。颜色越深,表示注意力权重越高。
在图 9.9 中,每一行表示:x 轴上的某个字符在当前这一时刻,对 y 轴上各字符分配了多少注意力。例如,在第 3 行,也就是字符 o 所在的这一行里,它对自己本身赋予了最高权重,其次是 $,然后是 j。这意味着:当模型在处理 "john" 里的 o 时,它最主要关注的是 o 自身,其次会考虑起始符号以及开头的 j。这表明,模型已经在某种程度上学会了:这个位置上的 o,既受它自身身份的影响,也受名字起点以及前文字符的影响。
很酷,对吧?这个可视化清楚展示了:我们的模型正在显式关注序列中字符之间的关联。就好像模型在说:"嘿,我不仅要看现在发生了什么,还要考虑前面发生过什么!" 通过观察这些关系,它就能发现那些有助于预测下一个字符的模式。现在,既然我们已经掌握了注意力的基础,就让我们进一步进入完整的 Transformer 架构,看看它真正能做到什么。
9.6 Transformer
Transformer 架构在 2017 年由 Vaswani 等人在那篇具有里程碑意义的论文 "Attention Is All You Need" 中正式推广开来。正如论文标题所暗示的那样,Transformer 架构的核心正是我们在上一节刚刚实现过的注意力机制。自那以后,Transformer 已经成为 NLP 以及其他诸多领域中大量最先进模型的基础。
在 Vaswani 等人的原始论文中,Transformer 被用于机器翻译 ,也就是把一句话从一种语言翻译成另一种语言。原始的 Transformer 架构由两个主要组件构成:编码器(encoder) 和 解码器(decoder) 。编码器负责接收输入序列,并把它转换成一组表示,这些表示能够捕捉序列中各元素之间的关系。随后,解码器再利用这些表示去生成输出序列。
不过,我们这里不会从完整的 encoder-decoder 架构讲起,而是先从 decoder 组件 开始。原因在于,近年来 decoder-only Transformer 已经获得了压倒性的流行,几乎支撑着所有领先的大语言模型,例如 GPT、Claude 和 Llama。以 decoder 为切入点,也更符合当前行业的重心------在生成式 AI 应用中,最主流的做法正是利用 decoder 架构来发挥其卓越的文本生成能力。
9.6.1 解码器(Decoder)
Transformer 解码器常用于语言生成等任务,因为它能够基于输入序列生成一串 token 序列。最著名的 decoder 模型,就是 GPT 系列 ,其全称为 Generative Pre-Trained Transformer 。这些模型是 OpenAI 的 ChatGPT 的核心,也是在近几年迅速走红、推动生成式 AI 热潮的重要基础。它们在海量文本数据上进行训练,因此能够生成既符合上下文、又连贯自然的文本。在第 2 章中,我们已经见过如何调用 GPT-2 这样的基于 Transformer 的语言模型来生成文本。GPT 风格的模型之所以被称为 decoder-only transformer,就是因为它们只有 decoder 这一部分;而负责生成输出序列的,正是 decoder 架构本身。
现在,让我们在 PyTorch 中自己实现一个 GPT 风格的 decoder,如图 9.10 所示。我们可以在之前工作的基础上继续推进,因为 decoder 的 transformer block,看起来和我们前面实现的 attention MLP block 很相似,只是多了几个额外扩展。
为了把前面的 attention MLP block 升级成一个完整的 transformer decoder block,我们还需要再加入几个组件,包括:
- 残差连接(Residual connections) ------ 也就是 skip connections,它们有助于缓解深层网络中常见的梯度消失问题。随着梯度在网络中逐层反向传播,它们会越来越小;而残差连接允许梯度绕过中间层,直接在网络中流动。
- 多头注意力(Multiheaded attention) ------ 不再只用单个注意力机制,而是把输入同时送进多个并行的注意力"头(heads)"中。每个 head 都拥有自己独立学习的投影参数(分别用于 query、key 和 value),因此每个 head 可以专注于输入的不同方面。举例来说,如果有两个 attention heads,其中一个 head 可能学会关注句法关系,而另一个则可能更偏向语义关联。所有 heads 的输出随后会被拼接起来,再经过一个线性层,形成最终表示。正是这种并行处理,使模型能够同时捕捉序列中的多种不同关系。
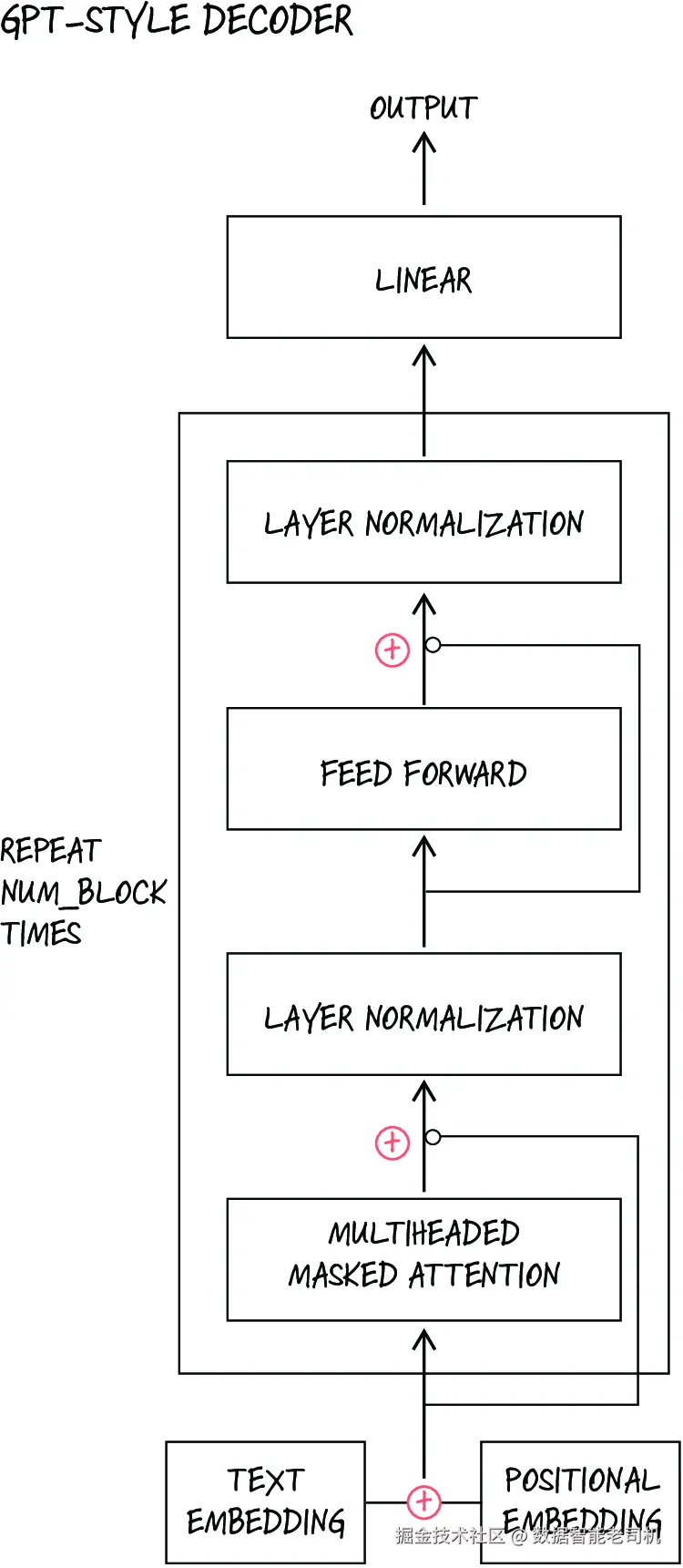
图 9.10 GPT 风格的 decoder。图中的加号表示残差连接,即把输出相加。
- 位置嵌入(Positional embeddings) ------ 由于 Transformer 是对所有 token 并行处理,而不是按顺序逐个处理,因此它本身并不天然理解 token 的先后顺序。位置嵌入通过给每个 token embedding 加入与位置相关的信息来弥补这一点。这些位置表示既可以是可学习参数,也可以是固定的正弦函数。它们使模型能够理解 token 在序列中的相对位置或绝对位置。没有位置嵌入的话,Transformer 会把输入序列仅仅当成一个无序 token 集合,从而丢失大量依赖词序的句法和语义信息。
- 层归一化(Layer normalization) ------ 它与我们在第 8 章见过的 batch normalization 类似,但不同之处在于:layer normalization 不是沿 batch 维度对输入做归一化,而是沿特征维度做归一化。这有助于稳定模型训练。图 9.11 展示了 layer normalization 与 batch normalization 之间的区别。
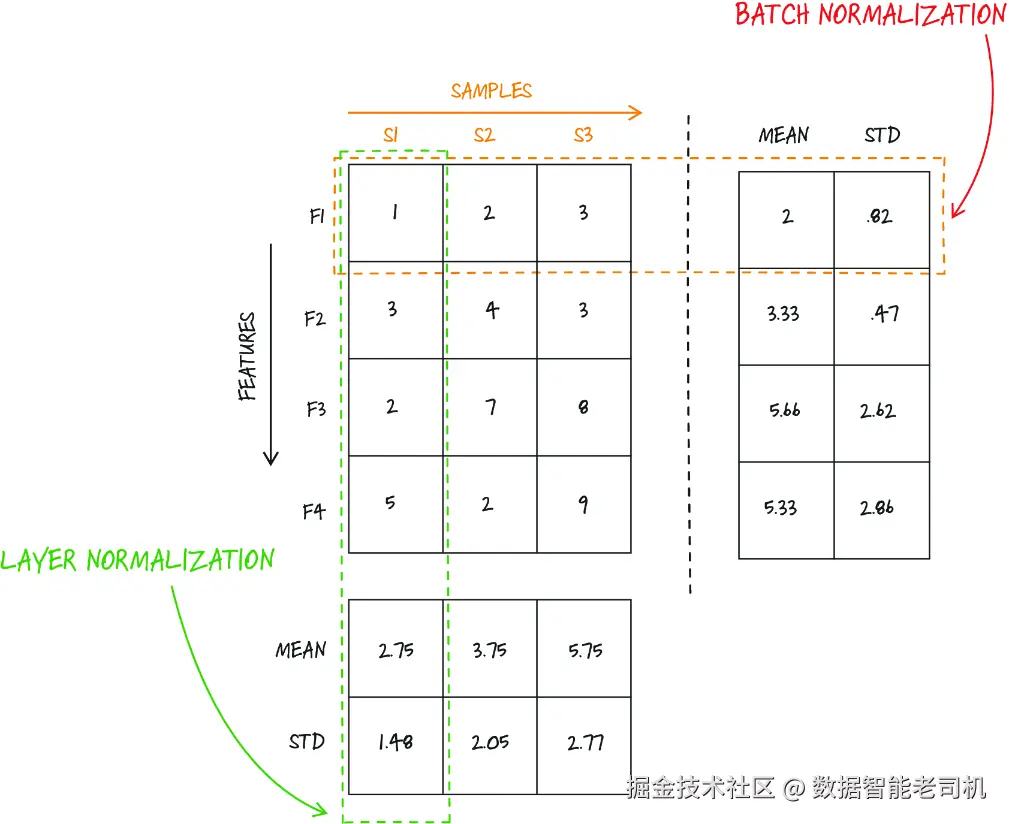
图 9.11 Layer normalization 与 batch normalization 的对比
我们可以把 decoder block 实现成一个 PyTorch 模块。为了简化代码,这里不再使用我们前面手写的 scaled dot product causal attention,而是直接使用等价的 PyTorch 官方实现 F.scaled_dot_product_attention:
ini
class TransformerBlock(nn.Module):
def __init__(self, n_embd, num_heads=4, n_hidden=64):
super().__init__()
assert n_embd % num_heads == 0, "Embedding dimension must be
↪ divisible by the number of heads"
self.num_heads = num_heads
self.head_dim = n_embd // num_heads
self.query_proj = nn.Linear(n_embd, n_embd)
self.key_proj = nn.Linear(n_embd, n_embd)
self.value_proj = nn.Linear(n_embd, n_embd)
self.mlp = nn.Sequential(
nn.Linear(n_embd, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_embd)
)
# Layernorms
self.norm_1 = nn.LayerNorm(n_embd)
self.norm_2 = nn.LayerNorm(n_embd)
def forward(self, x):
batch_size, sequence_length, _ = x.shape
q = self.query_proj(x)
k = self.key_proj(x)
v = self.value_proj(x)
# multiheaded attention
q = q.view(batch_size, sequence_length, self.num_heads,
↪ self.head_dim).transpose(1, 2)
k = k.view(batch_size, sequence_length, self.num_heads,
↪ self.head_dim).transpose(1, 2)
v = v.view(batch_size, sequence_length, self.num_heads,
↪ self.head_dim).transpose(1, 2)
# attention
attn_weights = F.scaled_dot_product_attention(
↪q, k, v, is_causal=True)
# multiple heads concatenation
attn_weights = attn_weights.transpose(1, 2).contiguous().view(
↪batch_size, sequence_length, -1)
# norm and residual connections here
x = self.norm_1(x + attn_weights)
x = self.norm_2(x + self.mlp(x))
return x最后,我们就可以利用这个 transformer block 来构建 decoder。Decoder 会先接收输入 embeddings,并把它们与 positional encoding 相加。所谓 positional encoding,就是一组 embeddings,用来编码序列中每个位置的信息。这一步非常重要,因为 Transformer 本身并不具备对序列位置的天然感知。接着,输入会依次经过多层 transformer block,最后再经过一个线性层得到输出。我们仍然可以沿用前面相同的训练代码来训练这个新模型,并生成样本:
ini
# In[]:
class Transformer(nn.Module):
def __init__(self, n_embd, vocab_size, block_size, num_blocks=6):
super().__init__()
self.char_embedding = nn.Embedding(vocab_size, n_embd)
self.positional_embedding = nn.Embedding(block_size, n_embd)
self.transformer_blocks = nn.Sequential(
*[TransformerBlock(n_embd) for _ in range(num_blocks)]
)
self.output_proj = nn.Linear(n_embd, vocab_size)
def forward(self, x):
_, seq_len = x.shape
pos_embd = self.positional_embedding(torch.arange(seq_len))
char_embd = self.char_embedding(x)
x = char_embd + pos_embd
x = self.transformer_blocks(x)
x = self.output_proj(x)
return x
n_embd = 64
model = Transformer(n_embd, vocab_size, block_size=max_name_length)
optimizer = optim.SGD(model.parameters(), lr=0.1)
train(model, optimizer, num_steps=10_001, loss_report_interval=1_000)
# Out[]:
Average loss at step 1000: 2.2924
Average loss at step 2000: 2.1520
Average loss at step 3000: 2.0999
Average loss at step 4000: 2.0626
Average loss at step 5000: 2.0346
Average loss at step 6000: 2.0107
Average loss at step 7000: 1.9852
Average loss at step 8000: 1.9629
Average loss at step 9000: 1.9477
Average loss at step 10000: 1.9299模型现在变得更复杂了,因此训练时间相比前面几个模型也明显增加。不过,好消息是:损失已经显著低于我们先前的模型。现在来看看这个正式版 Transformer decoder 的生成效果:
ini
# In[]:
generate_samples(model, num_samples=10)
# Out[]:
journe
green
huxson
chanie
antura
robinna
bryce
jazleah
daryza
bailanie这些名字质量相当不错,而且很有独特性!模型生成出来的名字,与我们数据集中的风格已经非常接近。这足以证明 Transformer 架构的强大威力。我们现在已经实现了最初的目标:在不借助任何人工编写规则或模板的前提下,生成人类风格的名字。我们训练出了一个模型,它能够生成既贴合数据集风格、又足够真实自然的名字。
9.7 其他 Transformer 架构
本章剩下的部分,将讨论 Transformer 的其他变体,以及如果我们想把当前这种 decoder 模型扩展到"单词级以上的生成"时,应该如何调整。
9.7.1 编码器(Encoder)
Transformer 编码器如图 9.12 所示,它与 decoder 非常相似,只不过不使用因果掩码(causal masking) 。与 decoder 不同,encoder 不需要阻止模型去看未来 token;相反,它可以自由利用句子中所有单词的信息。Encoder 接收一串 token 序列,并输出这整个序列的一组新的固定大小向量表示。
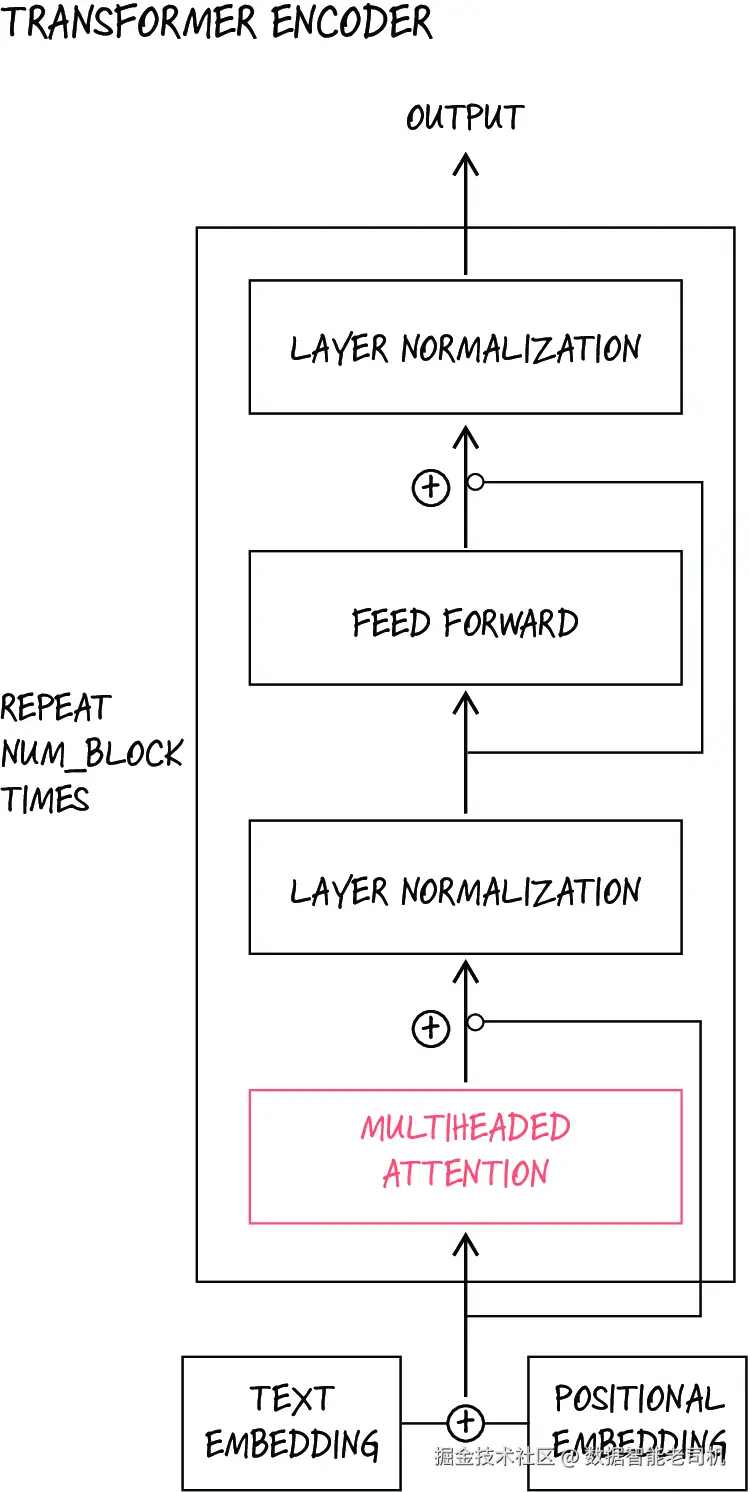
图 9.12 Transformer encoder 的示意图。与前面的 GPT 风格 decoder 相比,唯一变化是:多头注意力中去掉了 masking,并且输出前的线性层也不再一样。
这种输出对于文本分类等任务非常有用,因为这类任务的目标是把输入序列归入某个类别。典型应用包括情感分析、垃圾邮件检测和主题分类。最著名的 encoder 模型之一是 Google 于 2018 年提出的 BERT ,全称为 Bidirectional Encoder Representations from Transformers。BERT 会先在大规模文本语料上进行预训练,然后再针对大量不同任务做微调。
9.7.2 编码器---解码器(Encoder-Decoder)
把 encoder 和 decoder 组合起来,就得到了完整的 Transformer 架构。这一思想最早正是在 "Attention Is All You Need" 一文中提出的,如图 9.13 所示。Encoder 接收输入序列,并把它转换成一组能够捕捉序列内部关系的表示;随后 decoder 再利用这些表示生成输出序列。
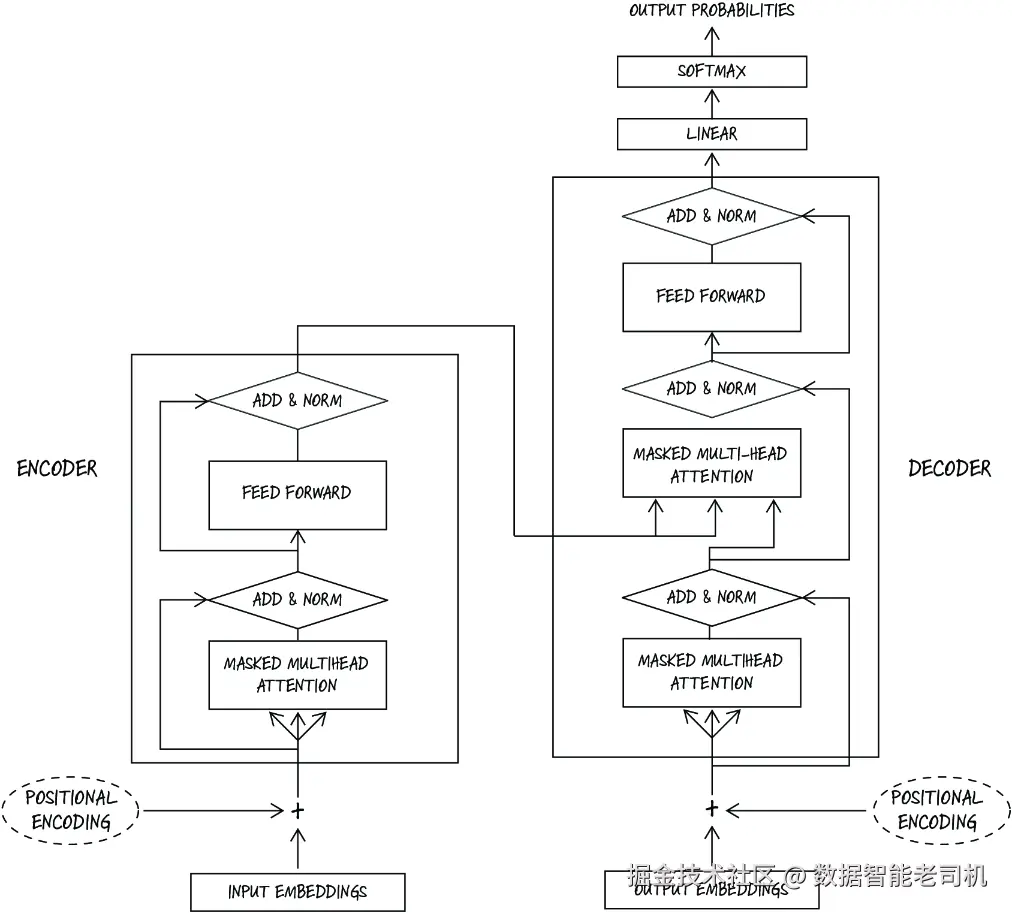
图 9.13 原始论文 "Attention Is All You Need" 中的 Transformer 架构图。左边是 encoder,右边是 decoder。Encoder 的输出会作为 multi-head attention 中的 key 和 value 送入 decoder。
到现在为止,图 9.13 中 Transformer 结构图里的核心运算,对你来说应该已经不陌生了。我们已经实现过前馈网络、layer norm、残差连接,以及最关键的 multiheaded attention 机制。
在 encoder-decoder Transformer 中,有一点特别值得注意:encoder 的输出会被用作 decoder-encoder attention 中的 key 和 value。这使得 decoder 可以显式地去关注 encoder 的输出,并利用其中的信息来生成目标序列。这一机制对于机器翻译尤其有用------例如,把一句话从一种语言翻译到另一种语言。因为不同语言的词序和语法结构可能差异很大,所以 encoder 的作用是先充分捕捉输入句子中各词之间的关系;而 decoder 则利用这些信息,在目标语言中生成合适的输出句子。
9.8 Tokenization
在前面激发动机的例子里,我们使用的 token 是字符 。但在实际应用中,我们更常使用单词 或子词(subwords) 作为 token,因为单词通常比字符更有语义意义。比如,"dog" 这个词有明确含义,而单个字符 "d" 则没有。这对于英语尤其重要,因为词义往往严重依赖字符的排列顺序,例如 "dog" 和 "god" 的含义就完全不同。
Tokenizer(分词器) 的职责,是把原始文本整理成模型可以接收的输入。它的目标是:把原始文本转换成数字,因为模型只能接收数字作为输入。它通过先把文本切分成 token,再把这些 token 映射成数字来实现这一点。
我们之前那版 tokenizer 其实已经做了这件事,但它非常原始,因为我们只把小写字符当作 token。实际上,把文本切分成更小单元远比看上去复杂得多,而且方法也很多。Hugging Face 的 tokenizers 库就是一个专门处理这类任务的开源库。借助 tokenizer,我们就可以进一步扩展到基于单词级 token 的训练。
首先,我们需要 pip install tokenizer,然后导入几个类,以便在一个新数据集上训练 tokenizer。这里我们要使用的文本,是《奥德赛》(The Odyssey ),也就是荷马那部经典史诗。使用 tokenizers 库时,输入文本会经历这样一个流水线:normalization(规范化)→ pretokenization(预切分)→ model → postprocessing(后处理) :
ini
# In[]:
from tokenizers import Tokenizer
from tokenizers.models import WordLevel
from tokenizers.pre_tokenizers import Whitespace
from tokenizers.trainers import WordLevelTrainer
tokenizer = Tokenizer(WordLevel(unk_token="[UNK]")) #1
tokenizer.pre_tokenizer = Whitespace() #2
trainer = WordLevelTrainer(special_tokens=["[UNK]"]) #3
tokenizer.train(["../data/p2ch9/odyssey.txt"], trainer=trainer)
vocab_size = tokenizer.get_vocab_size()
decode = tokenizer.decode
encode = tokenizer.encode
#1 这里使用 tokenizers 库中的 WordLevel 模型。这个模型用于基于单词级词汇表训练 tokenizer。我们还指定了一个特殊 token [UNK],用于表示未知 token。
#2 这一步设置 tokenizer 在正式 tokenization 之前,先按空白字符对文本进行切分。
#3 这里必须指定实际执行 tokenization 的核心算法。在这个例子中,WordLevelTrainer 并没有做特别复杂的事,但也可以选择其他方案,比如 Byte-Pair Encoding、WordPiece 等。现在 tokenizer 已经遍历过文本,我们就可以得到 vocab_size,并定义相应的 encode 和 decode 函数。和之前一样,我们可以通过遍历文本,取出连续子序列及其对应目标,构造训练模型所需的数据集:
ini
# In[]:
with open('../data/p2ch9/odyssey.txt', 'r', encoding='utf-8') as f:
text = f.read()
encoding = tokenizer.encode(text)
sequence_length = 100
X, Y = [], []
for i in range(0, len(encoding.ids) - sequence_length, sequence_length):
X.append(encoding.ids[i:i+sequence_length])
Y.append(encoding.ids[i+1:i+sequence_length+1])
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
X = torch.tensor(X).to(device)
Y = torch.tensor(Y).to(device)9.8.1 生成句子
我们可以继续使用本章 decoder 一节中搭建的同一套模型架构,在这个新数据集上进行训练。由于我们写代码时做得足够抽象,模型只关心"token",而不关心这些 token 到底是字符还是单词,所以对模型来说,它们本质上没有区别------这正是它非常灵活的原因:
ini
# In[]:
n_embd = 64
model = Transformer(n_embd, vocab_size, block_size=sequence_length)
model.to(device)
optimizer = optim.SGD(model.parameters(), lr=0.1)
train(model, optimizer, num_steps=501, loss_report_interval=100)不过,我们需要稍微修改一下 generate_samples 方法,好让输出格式更自然一些。因为 tokenizer 输出的是 token 列表,而我们希望标点前后的空格能处理得更合理。因此,我们可以加一个新的 format_sequence 函数,对输出结果做一点整理,让它在打印前更像可读文本:
ini
# In[]:
def generate_samples(model, num_samples=1, max_len=sequence_length):
sequences = torch.zeros((num_samples, 1)).int().to(device)
for _ in range(max_len):
logits = model(sequences)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
sequences = torch.cat((sequences, idx_next), dim=1)
for sequence in sequences:
indices = torch.where(sequence == 0)[0]
end = indices[1] if len(indices) > 1 else max_len
sequence = sequence[1:end]
decoded_sequence = decode(sequence.tolist())
print(format_sequence(decoded_sequence))
def format_sequence(sequence):
formatted_sequence = ""
for i, char in enumerate(sequence):
if char in ",.;:!?":
formatted_sequence = formatted_sequence.rstrip() + char + " "
else:
formatted_sequence += char
return formatted_sequence.strip()
# Out[]:
day horses and as she were dream to do. twittering spake Ulysses laid fain. He fear. Man for their choice, for t he councils and one Hebe angrily πύματον treating which? 61 140 they went - offering in the son of all before the island, and saw mother ', would have a set it did a sweet that we could already, see the Cnossus mortal - rejoinder ahead into your country to quantity of it, till Ulysses to Troy, nor just in us who was as he heard his eyelids这段生成文本也许还远达不到新史诗的水平,但其中《奥德赛》的风格影响已经相当明显了。像 Ulysses、Troy,以及其他英雄人物的影子,都散落在这段样本之中。考虑到只训练了短短几分钟,这已经相当不错了。
9.9 Vision Transformer
最后,如果不提一下 Vision Transformer(ViT) ,那对读者来说就未免有些失职了。ViT 是一种全新的模型,它把 Transformer 架构应用到了图像数据上。在这里,token 不再是字符或单词,而是输入图像的一个个 patch(图像块) 。ViT 会以类似 NLP 中处理文本 token 的方式来处理这些 patch,因此能够学习图像中的视觉模式和关系。
我们在第 2 章中其实已经用过 ViT,当时我们调用了 torchvision 中的一个预训练模型,在 ImageNet 上做图像分类。ViT 之所以能做到这一点,靠的是 self-attention 和 multiheaded attention 去捕捉图像 patch 之间的关系。当一张图像被送入 ViT 时,它会先被切分成规则网格中的若干小 patch,每个 patch 都被当作一个 token。接着,这些 token 会被映射到高维空间中,就像 NLP 中的词嵌入一样。图 9.14 展示了这个过程。
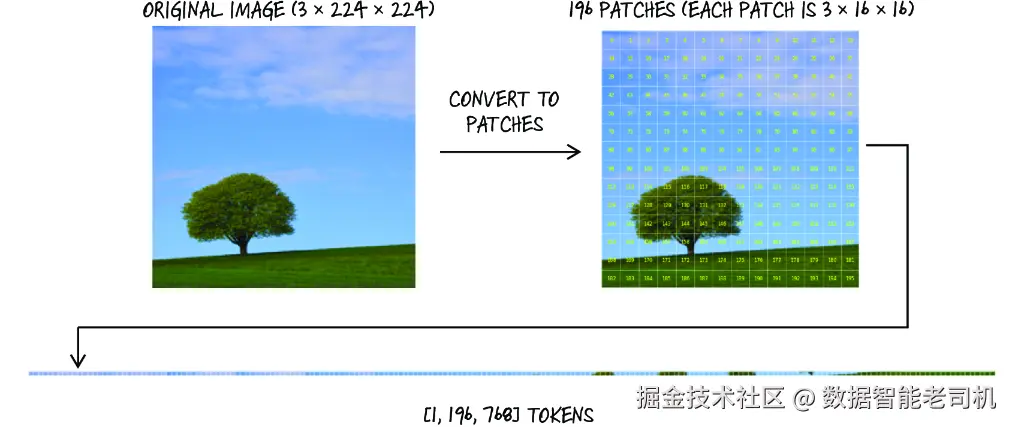
图 9.14 图像被切分成若干图像 patch,这些 patch 会被拉平后送入模型
在获得这些 token 之后,ViT 会在序列前面额外拼接一个可学习的 [CLS] token,并给每个 token 加上可学习的位置嵌入,用来编码 patch 的位置信息。于是,整个序列就形成了一个 [B, N+1, D] 的张量(分别表示 batch size、token 数量加上一个 [CLS] token,以及 embedding 维度),然后它会依次流经一堆 transformer encoder blocks。整个过程如图 9.15 所示。
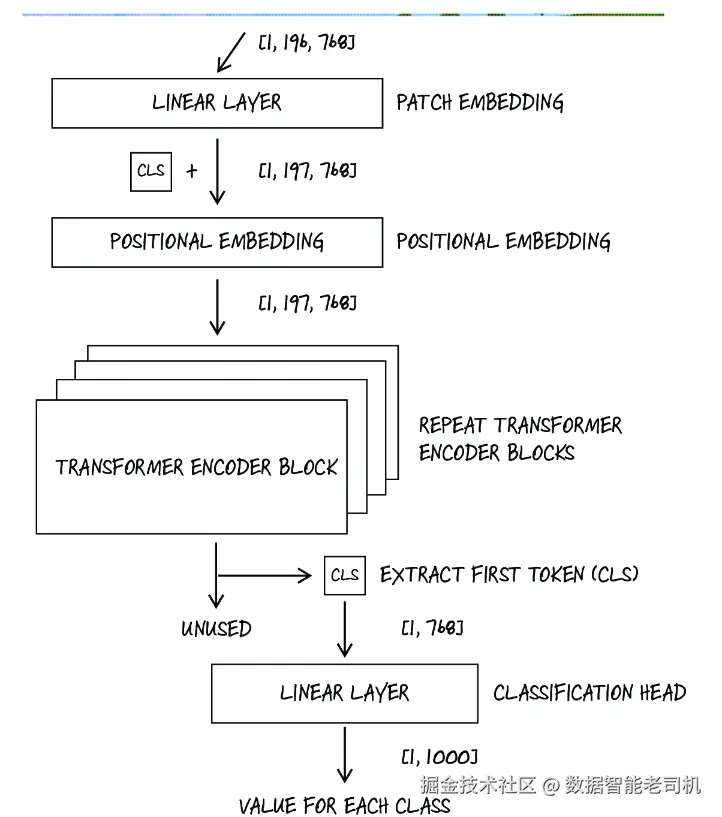
图 9.15 Vision Transformer 架构。图像 token 先经过 patch embedding 层,再加入位置信息,然后送入 transformer encoder blocks。最终只取单个 [CLS] token 的输出,用于分类头。
在图 9.15 中,我们还在每个箭头旁标注了对应张量的尺寸。一个很有意思的细节是:我们前面专门加上的那个可学习 class token,最终竟然是唯一一个真正用于分类的输出 。其他 token 的输出都被丢弃了,因为 [CLS] token 的设计目的,就是去聚合序列中其他所有 token 的信息。自注意力机制允许 [CLS] token 去关注序列中的全部其他 token,因此它能够捕捉整张图像的全局信息。
尽管 ViT 的原始论文主要聚焦于图像分类,但这种架构后来已经被扩展到许多其他计算机视觉任务中,包括目标检测和图像分割。在这些任务里,我们往往不只使用 [CLS] token,而是会利用 transformer encoder blocks 的全部输出。甚至连我们下一章将要看到的 diffusion models,也开始采用 Transformer 架构来提升其高质量图像生成能力。这里最重要的 takeaway 是:Transformer 架构并不局限于文本数据;凡是能够表示成 token 序列的数据,都可以应用 Transformer。无论处理的数据类型是什么,注意力与自注意力背后的基本思想始终都是相同的。
9.10 结论
在本章中,我们取得了相当大的进展:从生成简单的字符序列,逐步走到了生成整段文本,甚至进一步理解图像。机器生成类人文本的能力,长期以来一直是人工智能领域梦寐以求的目标,也曾一度被视为科幻作品中的设定;而如今,通过 Transformer 架构,这已经变成了触手可及的现实。这些模型至今仍处于最前沿研究的核心,围绕它们的性能、效率与能力增强,仍有大量工作在持续推进。随着 Transformer 越来越多地被用于自然语言生成与内容理解,我们已经不难想象这样一个未来:我们能够与看起来仿佛能够自主思考------或者至少非常逼真地表现得像在自主思考------的系统展开有意义的对话。这样的前景既令人兴奋,也令人警惕;而对于任何有能力的 AI 从业者来说,真正理解这些技术背后的运行机制都是至关重要的。
9.11 练习
- 你会如何把
names_2022.txt文件中不同名字的相对频率纳入考虑? - 这会对 bigram 模型产生什么影响?
- 那对 transformer 模型又会有什么影响?
试着修改你的 self-attention 实现,使它支持 cross-attention。
阅读论文 "Attention Is All You Need" :
- 尝试实现论文中描述的 encoder-decoder Transformer。
- Encoder 的输出是怎样送入 decoder 的?
- 原始论文中的架构与 GPT 风格的 decoder 有哪些不同?
- 你能看出基于单词级 tokenization 可能会带来哪些问题吗?
- 去查一下 Byte Pair Encoding(BPE) 。
- 不同的方法是如何应对单词级 tokenization 中这些问题的?
阅读 Vision Transformer(ViT) 论文:
- 从 Torchvision 中加载一个预训练 ViT,并在一个小数据集上(例如 CIFAR-10)进行微调。报告 top-1 accuracy 和训练时间。
- 修改 patch size 和/或 embedding 维度,观察它们对准确率、速度和显存的影响。
总结
- 在语言模型中,词汇表由模型能识别的所有不同元素组成。每个元素称为一个 token,它是构成输入序列和输出序列的基本单位。
- 大多数自然语言处理(NLP)模型背后的关键思想,是一种统计生成模型:利用从大规模数据集中学习到的词或字符序列的概率分布,来预测并生成文本。
- 我们用一个 bigram 模型,对"给定前一个字符,下一个字符出现的概率"做了一个非常粗糙的估计。
- 借助深度学习,并从简单的 embedding 与线性层开始,我们可以逐步构建更复杂的模型,让它们学习数据中的结构,并生成更真实的序列。
- 注意力机制通过 query、key 和 value 这三者,使模型能够更灵敏地响应输入上下文:query 用来确定关注什么,key 用来评估相关性,value 则负责整合相关信息。
- 缩放点积注意力通过对 query 和 key 做点积、按 key 的维度进行缩放、再应用 softmax 来得到 value 的权重,并最终组合出输出。在 PyTorch 中,它由
torch.nn.functional.scaled_dot_product_attention提供。 - Transformer 架构最早由论文 "Attention Is All You Need" 提出,它利用注意力机制来捕捉序列中元素之间的关系,从而使模型能够生成与上下文相关的文本。
- Transformer 的整体架构由两个主要部分组成:encoder 负责把输入序列转换成捕捉元素关系的表示,decoder 则根据这些表示来生成输出序列。
- 近年来爆发式流行的 decoder-only Transformer(例如 GPT 模型),主要用于文本生成任务。它们在大规模文本语料上训练,因此能够生成连贯且与上下文相关的文本。
- Tokenizer 用于把原始文本转换成模型可接收的数值输入;其中 Hugging Face 的 tokenizer 库,为在自定义数据集上训练 tokenizer 提供了非常强大的工具。
- Vision Transformer(ViT)把图像看作一系列 patch 组成的序列,并利用带有可学习
[CLS]token 的 transformer encoder 来完成分类。