本章涵盖以下内容:
- 生成式 AI 在图像合成中的应用概览
- 扩散模型的基础原理
- 从零开始实现一个扩散模型
在继续我们的生成式 AI 之旅时,我们现在将目光转向图像合成。在上一章中,我们探讨了如何使用 Transformer 进行文本生成。本章中,我们将深入研究利用深度学习技术进行图像生成这一领域。
乍看之下,生成图像这项任务似乎与生成文本有着相当大的不同。图像由像素构成,每个像素都由特定的颜色值定义;而文本则由一连串单词或 token 组成。在文本生成中,各元素之间的关系主要是序列性的,并且很大程度上由 token 的顺序决定。相比之下,图像生成涉及空间依赖关系,其中上下文不仅受元素之间距离远近的影响,也受它们在整张图像中的整体排列方式影响。将我们此前学到的"基于前面的 token 以概率方式预测下一个 token"的方法,直觉上似乎并不适合用于生成图像。
然而,生成式 AI 的底层原则并没有改变:建立一个关于数据底层分布的模型,从而生成新的样本。尽管文本生成模型与图像生成模型之间存在差异,但我们的目标是相同的:我们希望学习训练数据集的概率分布,以生成新的、合理的样本,使这些样本看起来像是可信地属于原始数据集。无论是预测一句话中的下一个单词,还是预测图像中某个像素的颜色值,其根本挑战都是捕捉并重现真实世界数据中所观察到的复杂模式。
本章首先会介绍图像生成模型的一些历史背景。我们将看到,变分自编码器(VAE)和生成对抗网络(GAN)是最早在图像生成上取得成功的模型架构。随后我们将深入讨论扩散模型。扩散模型在图像生成任务上已经在很大程度上超越了 VAE 和 GAN,并成为主流模型。我们还将考察扩散模型的基本实现,以理解训练扩散模型和从扩散模型中采样的基础要素,最后再从已有数据集中生成新的图像。
10.1 VAEs 和 GANs 的历史
VAE 于 2013 年末被提出(arxiv.org/abs/1312.61...)。它采用双模型架构,由识别模型(也称为编码器)和生成模型(也称为解码器)组成。编码器的作用是将输入(例如一张图像)压缩为一个较低维度的潜在表示;解码器则尝试根据这个潜在表示重构原始数据。若要使用 VAE 生成新样本,我们只需移除编码器,并向解码器输入一份噪声样本,解码器会将这份噪声解释为一种"图像表示",并将其解码为一张新的图像。
另一种用于图像生成的模型 GAN 于 2014 年提出,并且由于其能够生成更锐利、更逼真的图像(见图 10.1),很快就在流行度上盖过了 VAE。GAN 由两个部分组成:生成器(generator)和判别器(discriminator)。生成器从随机噪声中创建数据,试图欺骗作为二分类器的判别器;判别器则同时评估来自数据集的真实数据和来自生成器的伪造数据,目标是区分二者。在训练过程中,这两个网络通过对抗过程不断彼此挑战、共同提升。训练完成后,我们只需使用生成器生成新数据,就可以得到新的样本。
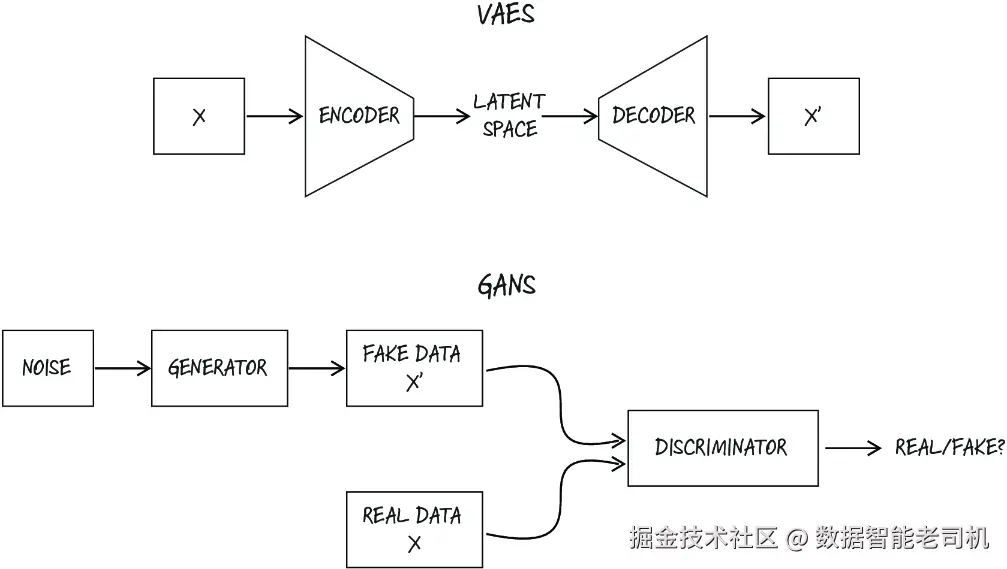
图 10.1 VAE 与 GAN 的架构对比。VAE 利用潜在空间生成新样本,而 GAN 通过生成器/判别器这一对组件来创建新数据。
在随后的几年里,GAN 一直是最前沿图像生成任务中的首选架构。尽管扩散模型在 2015 年就已经被提出,但直到大约 2020 年,它们才开始作为 GAN 的可行替代方案获得广泛关注和认可。正如我们将在下一节中看到的那样,扩散模型采用了另一种训练思路。
10.2 扩散模型的动因
当 OpenAI 发布 DALL-E 模型时,扩散模型迅速进入大众文化视野。DALL-E 展示了扩散模型在商业应用中的实用性。DALL-E 是一种生成模型,能够根据文本描述创建图像。该模型是在一个包含大量图像及其对应说明文字的数据集上训练得到的。随后,诸如 Stable Diffusion 这样的扩散模型开源变体也被发布出来,它们能够生成高分辨率图像。图 10.2 展示了一张由 Stable Diffusion XL 生成的图像示例。

图 10.2 Stable Diffusion XL 根据提示词"Astronaut in a prairie, warm color palette, detailed, 8k"生成的图像
在本章剩余部分,我们将探讨使扩散模型能够生成如此高质量图像的基础原理。
10.3 扩散详解
通常所说的 diffusion(扩散),是指某种东西向更广范围传播的过程;这一概念在不同领域中有其特定含义。例如,在物理学中,扩散描述的是粒子从高浓度区域向低浓度区域移动的现象,就像一滴牛奶逐渐均匀地散开在一杯咖啡中一样。
在深度学习语境下,扩散模型对这一概念作了独特的采用。这类模型是一种特殊的生成模型,它会在图像上逐步引入噪声。在物理学里,扩散是不可逆的,该过程会自然地增加熵或随机性;而在扩散模型中,噪声是被刻意设计为可逆的。模型通过学习反转这种噪声来重构原始图像。扩散模型真正强大的地方,在于它能够学会如何有条不紊地逆转噪声,逐步重建图像。这个过程实际上是对自然扩散现象的反演:把看似随机的像素逐渐转化为有组织的结构,而这种结构能够代表一张真实图像。
这一思想可以浓缩为 2015 年原始论文《Deep Unsupervised Learning Using Nonequilibrium Thermodynamics》中 Sohl-Dickstein 等人的一句话(arxiv.org/pdf/1503.03...):
受非平衡统计物理启发,其核心思想是通过一个迭代的前向扩散过程,系统性且缓慢地破坏数据分布中的结构。然后,我们学习一个反向扩散过程,以恢复数据中的结构,从而得到一个高度灵活且可处理的数据生成模型。
为了进一步拆解这句较为凝练的话,前向扩散过程会缓慢地瓦解数据的结构,就像一座沙堡被海浪一点点侵蚀。每一道海浪(也就是扩散过程中的一次迭代)都会冲刷沙堡,使细节被抹平、轮廓逐渐模糊。在这个类比中,沙堡代表原始数据或图像,而海浪则象征逐步施加的噪声,它会一点点削弱数据的清晰度和结构。
这个前向扩散过程由某种调度机制加以控制和维持,以确保这种退化是缓慢且可预测地发生的。在理解并控制了这一过程之后,我们就可以训练一个神经网络去执行相反的过程,也就是有效地"重建沙堡"。这意味着模型要学会在每一个反向步骤中抵消噪声,恢复数据原本的结构与细节,最终将数据重新生成回其清晰、明确的原始形态。图 10.3 展示了扩散模型的前向与反向过程。
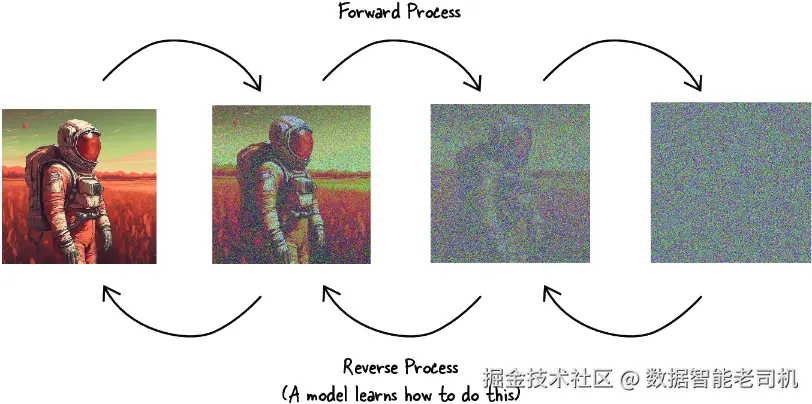
图 10.3 扩散模型在图像上的前向与反向过程
在接下来的几节中,我们将更深入地考察支撑扩散模型的数学理论,并亲手实现一个扩散模型。
10.4 准备数据
扩散模型及其工作机制最适合通过可视化来理解,因此我们将从最基础的一类可视化数据开始:二维点。我们希望演示扩散在具有 x、y 坐标的点集上的作用。
首先,导入实现过程中需要使用的所有库:
javascript
from PIL import Image, ImageFilter
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F我们将定义两个辅助方法:一个用于把图像转换为表示其轮廓的一组二维点,另一个用于绘制一组二维点。第一个方法将用于生成自定义的二维点数据集,第二个方法则帮助我们可视化这些点在扩散过程中的变化。为了简洁起见,书中省略了这两个方法的完整实现,但可在 /code/p2ch10/forward_diffusion.ipynb 中找到:
python
def points_from_img(img_file, min_distance=5):
...
def plot_points(all_points, highlight_index=None):
...我们可以让 points_from_img 辅助方法接收任意图像,并提取出一个由长度为 2 的浮点元组组成的列表。在我们的示例中,我们使用一张 PyTorch logo 的 PNG 图片作为输入,输出一个点列表,如图 10.4 所示。然后,我们可以将这个列表转换为张量:
ini
# In[]:
points = points_from_img("../data/p2ch10/pytorch_logo.png")
for x, y in points[:3]:
print(f"({x:.3f}, {y:.3f})")
x0 = torch.tensor(points, dtype=torch.float32)
x0.shape
# Out:
(4.310, -479.528)
(0.310, -475.528)
(4.310, -472.528)
torch.Size([3177, 2])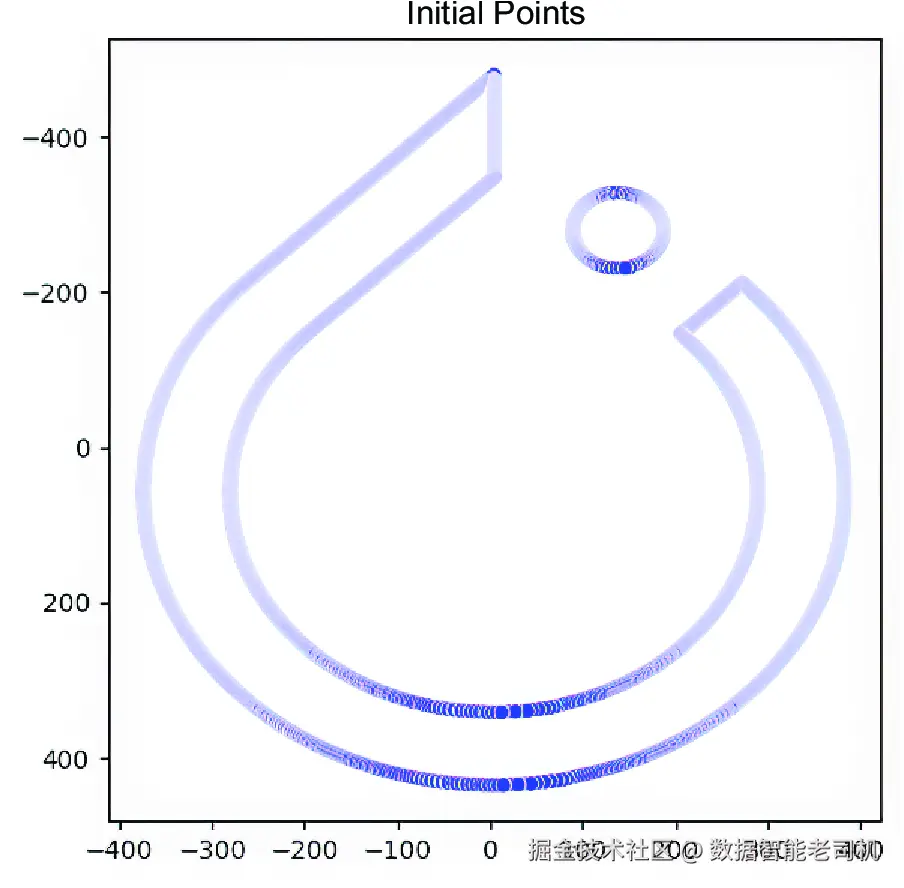
图 10.4 由二维点构成的 PyTorch logo 轮廓
points 列表中的每一项都包含图像轮廓上某个点的 (x, y) 坐标。现在我们可以使用 plot_points 来可视化这个张量(也就是这组点)长什么样:
css
plot_points(x0, ["Initial points"])现在我们已经准备好将这个数据集用于扩散模型了。目标是逐步向这些点中加入噪声,直到它们变成一组随机点。然后,我们就可以训练一个神经网络,去除所添加的噪声并重构原始图像。
10.5 前向过程
扩散模型的前向过程,是在一系列步骤中逐渐摧毁二维点数据集中的全部信息。我们将这些步骤记为 T。初始点集记作 x0,在每一个时间步 t 上都会发生少量变化。因此,时刻 xt 的点集与时刻 xt-1 的点集略有不同。这个过程重复 T 次,到最后,点集将变得完全无法辨认。
单步前向生成可以用图 10.5 所示的数学形式表达。我们引入 bt,它是一个标量,用来控制每一步添加噪声的大小。bt 会随着时间步递增,并遵循某个噪声调度(noise schedule)。随着 bt 的增大,加入系统的总噪声也会随时间不断累积。不过,噪声调度会确保新添加噪声的相对贡献在每一步都变得更小,从而在过程推进时逐渐减弱其整体影响。
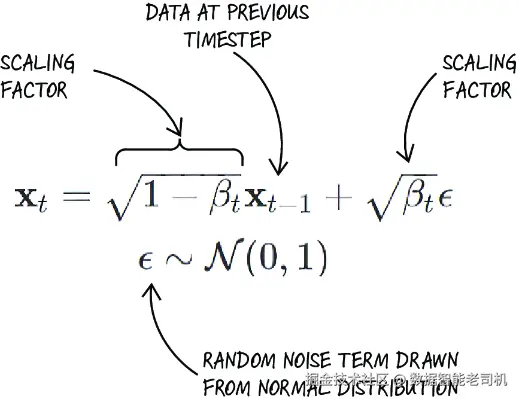
图 10.5 前向扩散过程方程
不同的噪声调度可能对应不同的 bt 值。它是扩散过程中的关键组成部分,并已被证明会影响训练结果。(关于不同调度方式,可参考 Ting Chen 的论文《On the Importance of Noise Scheduling for Diffusion Models》,arxiv.org/pdf/2301.10...)。在我们的示例中,我们使用一个线性调度:从较小的 b0 开始,线性增长到较大的 bT。于是,添加到图像中的噪声会随着时间增加,图像也会逐步变得越来越扭曲:
ini
# In[]:
def linear_beta_schedule(timesteps, start=0.0001, end=0.02):
return torch.linspace(start, end, timesteps)
T = 1000
betas = linear_beta_schedule(T)
print(betas[0], betas[10], betas[T-1])
# Out[]:
tensor(1.0000e-04) tensor(0.0003) tensor(0.0200)现在我们已经得到了要在所有步骤上应用的一组 bt,就可以实现前面给出的前向扩散方程了:
ini
def diffuse_points(points, beta):
new_mean = torch.sqrt(1-beta) * points
noise = torch.randn(points.shape)
perturbation = torch.sqrt(beta) * noise
points = new_mean + perturbation
return points, noise对于每个点,我们先将点乘以 sqrt(1-beta),再加上 sqrt(beta) 倍的噪声。我们来思考一下,这个方程究竟在做什么。sqrt(1-beta) * xt-1 的作用,是缩小上一时刻图像 xt-1 对当前图像 xt 的影响。随着 bt 增大,这一项会减小,因此原始图像的影响会随着时间推移逐渐减弱。第二部分 sqrt(beta) * noise 则是添加到图像中的噪声。随着 bt 增大,这一项也会增大,所以我们是在向图像中加入越来越多的噪声。
我们使用便捷的 torch.randn 函数来生成噪声,该函数会从均值为 0、标准差为 1 的正态分布中生成一个随机张量。新的点就是"经过修改后的点"与"噪声"二者之和。
为了建立直观理解,我们先将这个函数作用到单个点上,观察其随时间变化的效果:
ini
temp_x0 = x0.clone()
index = len(temp_x0) - 1
single_point = temp_x0[index]
all_points = []
for i in range(500):
if i % 100 == 0:
temp_x0[index] = single_point
all_points.append(temp_x0.clone())
single_point, _ = diffuse_points(single_point, betas[i])
plot_points(all_points, ["T=0", "T=100", "T=200", "T=300", "T=400"],
↪ highlight_index=index)我们复制原始点集,取出最后一个点,并逐步对它施加扩散过程。修改后的点所形成的图如图 10.6 所示,显示这个点在逐渐移动。

图 10.6 PyTorch logo 中一个点在 500 个步骤中的扩散过程。这只是为了建立直觉而展示的单点示例;在实际中,所有点都会经历这一扩散过程。
我们可以看到,随着扩散过程推进,这个点会一点点远离其原始位置,并朝均值为 0 的方向移动。最终,这个点会与一个随机点无异。当我们把扩散过程应用到数据集中的所有点时,这种转变会更加明显,如图 10.7 所示:
ini
x = torch.zeros(T, *x0.shape)
x[0] = x0
for t in range(1, T):
beta_t = betas[t]
x_t, noise = diffuse_points(x[t - 1], beta_t)
x[t] = x_t
plot_points([x[0], x[250], x[500], x[800], x[999]],
↪["T=0", "T=250", "T=500", "T=800", "T=999"])
图 10.7 PyTorch logo 的所有点在 1,000 个步骤中的扩散过程
随着这些点被整体扩散,它们会变得越来越随机,并围绕均值为 0 呈正态分布。很有意思!
到目前为止,我们一直在反复应用扩散过程,每一步都建立在前一步的数据之上。事实证明,我们不必通过繁琐的方式对所有时间步进行循环、反复应用扩散过程,而是可以用一个闭式公式一次性计算整个前向扩散过程,如图 10.8 所示。
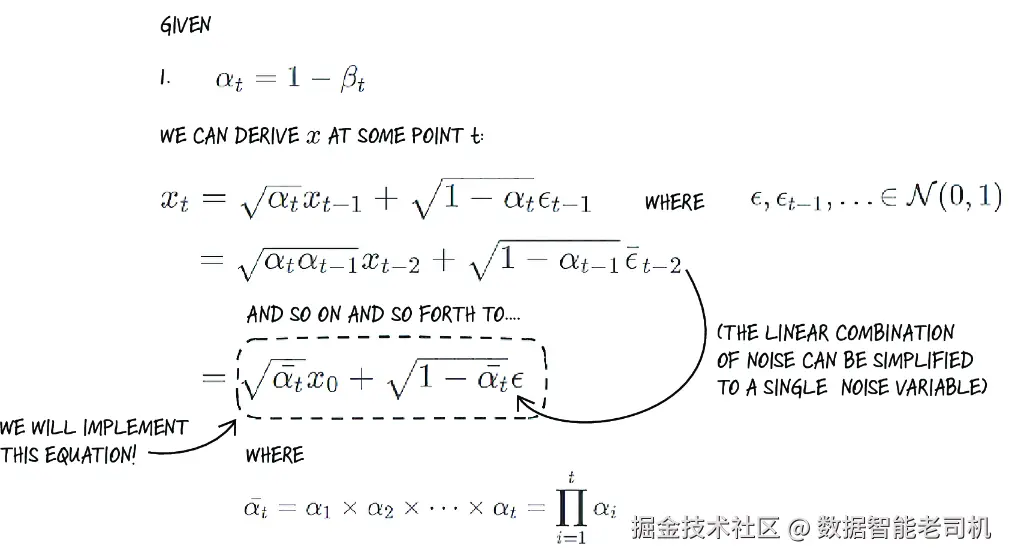
图 10.8 闭式形式的前向扩散方程
最终我们推导出:某个时刻 t 的 xt,可以通过初始点 x0 和一组 alpha 值的连乘积来计算。这样一来,我们就可以一步完成整个前向扩散过程的计算(再也不需要循环了)!在 PyTorch 中可以这样实现:
ini
alphas = 1. - betas #1
alphas_cumprod = torch.cumprod(alphas, dim=0) #2
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)
def reshape_for_x(a, x): #3
ones_to_broadcast = len(x.shape) - 1
# python unpacking performed here
return a.view(-1, *([1] * ones_to_broadcast)).to(x.device)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def forward_diffusion_sample(x, t):
x = x.to(device)
noise = torch.randn_like(x)
sqrt_alphas_cumprod_t = reshape_for_x(sqrt_alphas_cumprod[t], x)
sqrt_one_minus_alphas_cumprod_t = reshape_for_x(
↪sqrt_one_minus_alphas_cumprod[t], x)
return sqrt_alphas_cumprod_t * x + sqrt_one_minus_alphas_cumprod_t *
↪ noise, noise #4
#1 上文中的 αt,由原始 β 值计算得到
#2 上文中的 ᾱt
#3 我们用这个方法把 alpha 值(一个 1D 张量)重塑成与输入张量形状一致。输入通常是图像对应的 N 维张量。这样做是为了将这些值应用到图像中的每个点上。
#4 x_t 的最终推导公式,它依赖于 x_0 和 α_t 的连乘积。现在,forward_diffusion_sample 函数接收原始数据 x0 和一个时间点 t,并利用该公式在一次计算中返回扩散后的数据以及所添加的噪声。若将它作用于原始点集,我们会看到与之前相同的扩散模式:
scss
example_x0 = x0.clone()
example_timesteps = [0, 250, 500, 800, 999]
sample_points = []
for t in example_timesteps:
t = torch.tensor(t).expand(example_x0.shape[0])
new_points, _ = forward_diffusion_sample(example_x0, t)
sample_points.append(new_points)
plot_points(sample_points, ["T=0", "T=250", "T=500", "T=800", "T=999"])得到的图与图 10.3 中所示的扩散效果相似,只不过这次完全是通过我们刚刚推导出的公式实现的,如图 10.9 所示。

图 10.9 使用闭式公式对 PyTorch logo 的所有点执行 1,000 步扩散
我们已经成功实现了前向扩散过程,并且可以在任意给定时间步生成噪声。下一节中,我们将学习如何训练一个神经网络来反转这一过程,并从噪声中生成新的图像。
10.6 训练
现在我们已经有了向数据中添加噪声的方法,就可以训练一个神经网络,通过预测所添加的噪声来反转这个过程。神经网络的主要目标,是学习一个函数:给定带噪声(即扩散后)的数据以及一个具体的时间步,估计该步所引入的噪声的精确大小。
虽然这项任务看起来与生成新图像这一最终目标并不直接相关,但它实际上至关重要。通过学习逐步预测并去除噪声,模型本质上就是在学习如何反转"加噪"的过程。你可以把它想象成把一张揉皱的纸一点点展开------从一个混乱的状态逐渐恢复到原本的形状。当我们需要进行采样时,就输入噪声(那张揉皱的纸),让模型在每一个步骤上预测被加入的噪声,并逐步将其净化,从而重建原始数据。
在模型选择上,我们将使用一个简单的前馈神经网络。与上一章中的输入变换类似,这里我们会使用 embedding 来编码点坐标和时间。Transformer 模型中常用的一种 embedding 函数是正弦位置嵌入(sinusoidal positional embedding),它最早因原始 Transformer 论文《Attention Is All You Need》而广为人知。在 Transformer 中,这类嵌入通常用于注入关于序列中 token 相对位置或绝对位置的信息。在这里,我们将用它来把关于时间步以及二维点坐标的信息注入神经网络。与之前相同,通过把这些输入变换为更高维的嵌入表示,我们能更好地捕捉数据点与噪声之间的复杂交互。
首先,我们定义 SinusoidalEmbedding 类。其实现为了简洁起见在这里省略,但可以在 /code/p2ch10/training.ipynb 中找到:
kotlin
class SinusoidalEmbedding(nn.Module):
...然后我们定义模型。和上一章的 Transformer 模型类似,我们先对输入做 embedding,再将其送入若干层带有 ReLU 激活的线性层。最后一层输出预测的噪声,如图 10.10 所示。该模型的实现如下(见 training.ipynb):
ini
class DenoisingModel(nn.Module):
def __init__(self):
super(DenoisingModel, self).__init__()
self.time_mlp = SinusoidalEmbedding(128) #1
self.pos1_mlp = SinusoidalEmbedding(128)
self.pos2_mlp = SinusoidalEmbedding(128)
concat_size = len(self.time_mlp) + \
len(self.pos1_mlp) + len(self.pos2_mlp)
hidden_size = 128
num_layers = 3
layers = [nn.Linear(concat_size, hidden_size), nn.ReLU()]
for _ in range(num_layers):
layers.extend([nn.Linear(hidden_size, hidden_size), nn.ReLU()])
layers.append(nn.Linear(hidden_size, 2)) #2
self.joint_mlp = nn.Sequential(*layers)
def forward(self, x, t):
x1_emb = self.pos1_mlp(x[:, 0])
x2_emb = self.pos2_mlp(x[:, 1])
t_emb = self.time_mlp(t)
x = torch.cat((x1_emb, x2_emb, t_emb), dim=-1)
x = self.joint_mlp(x) #3
return x
#1 我们分别为时间,以及点的 x 坐标(pos1_mlp)和 y 坐标(pos2_mlp)定义嵌入。
#2 模型最后一层输出两个值,表示每个点的预测噪声。
#3 我们将这些嵌入拼接起来,并送入一系列线性层和非线性激活中,以预测噪声。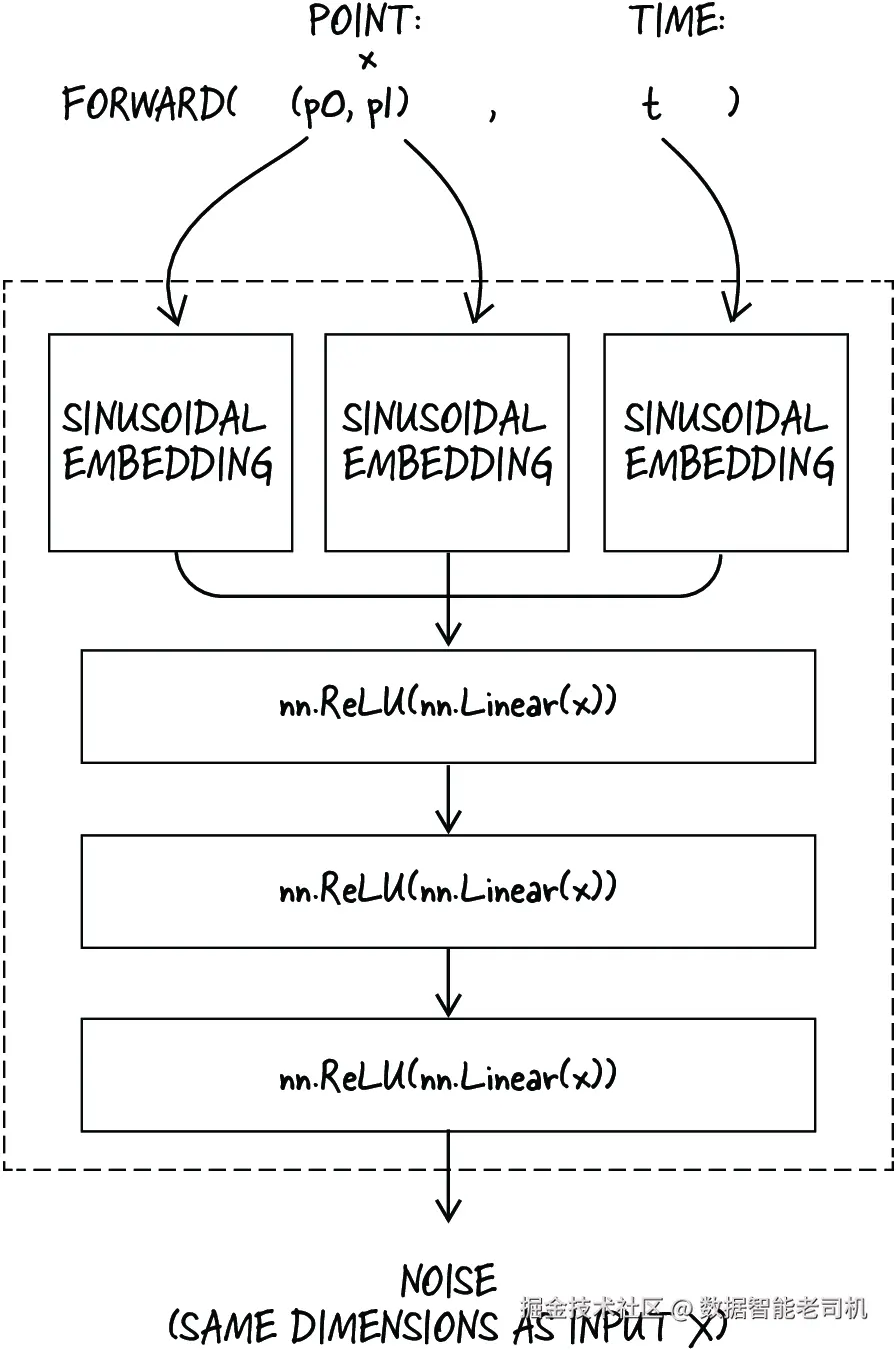
图 10.10 去噪模型架构。模型接收时间以及点的 x、y 坐标,将其嵌入后送入一系列线性层,以预测噪声。
10.6.1 损失函数
现在模型已经定义好了,我们需要训练它去预测之前加到数据中的噪声。该任务的损失函数,是预测噪声(θ)与真实噪声()之间的均方误差(mean squared error, MSE):
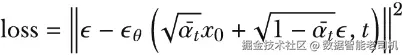
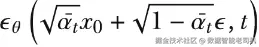
其中的这一部分应该看起来很熟悉,因为它正是我们之前推导出的前向扩散过程方程。损失是通过对预测噪声与真实噪声求均方误差得到的。这个损失函数衡量的是:模型对原始图像在扩散过程中所加入噪声的预测有多准确。在反向过程(即生成过程)中,模型将从纯噪声开始,并逐步将噪声去除。如果模型能够在每一步都准确预测噪声(这正是低损失所对应的目标),它就能有效地对图像去噪,从而生成高质量图像。
整个损失公式可以实现为:
ini
def get_loss(model, x, t):
x_noisy, noise = forward_diffusion_sample(x, t) #1
noise_pred = model(x_noisy, t) #2
return F.mse_loss(noise, noise_pred) #3
#1 我们先对数据执行前向扩散过程,得到带噪数据以及所加的噪声。
#2 然后将带噪数据和时间步输入模型,得到模型预测的"在该时间步加入的噪声"。
#3 最后使用 PyTorch 的 mse_loss 计算预测噪声与真实噪声之间的均方误差,与上面的公式一致。基于这个方法,我们可以像前面章节那样构建一个简单的训练循环,用来计算损失、反向传播并更新模型参数:
css
# In[]:
device = "cuda" if torch.cuda.is_available() else "cpu"
model = DenoisingModel().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
x0 = x0.to(device)
def train(model, optimizer, num_epochs):
model.train()
for epoch in range(num_epochs):
t = torch.randint(0, T, (
↪x0.shape[0],)).to(device) #1
optimizer.zero_grad()
loss = get_loss(model, x0, t) #2
loss.backward()
optimizer.step()
print(f"Finished epoch {epoch + 1}/{num_epochs},
↪loss: {loss.item():.4f}")
train(model, optimizer, 1)
# Out[]:
Finished epoch 1/1, loss: 0.9687#1 我们一次会测试多个时间步,因此会为数据集中的每个点随机生成一个时间步。
#2 我们根据前面的公式计算损失,并利用该损失进行反向传播和参数更新。
我们定义了一个 train 方法,它接收模型、优化器以及训练轮数。模型是前面定义的 DenoisingModel 类的一个实例,我们使用 Adam 优化器来更新参数。在单个 epoch 中,我们随机选择时间步,通过比较预测噪声与真实噪声来计算损失。随后,我们对这个损失执行反向传播,并用优化器更新模型参数。如果机器支持 CUDA,我们也可以利用它来加速训练过程。重复这一过程足够多次之后,就能训练出一个能够预测数据中所加入噪声的模型:
yaml
# In[]:
train(model, optimizer, 20000)
# Out[]:
Finished epoch 1/1, loss: 1.0119
...
Finished epoch 19997/20000, loss: 0.6959
Finished epoch 19998/20000, loss: 0.7143
Finished epoch 19999/20000, loss: 0.7026
Finished epoch 20000/20000, loss: 0.717810.7 反转扩散(如何采样)
我们的模型已经训练好了。现在终于可以把它用于最初的目标:将一组随机点变成 PyTorch logo!通过执行反向扩散过程,我们可以"预测"在加入噪声之前,那些点原本是什么样子。
这个过程是迭代式的,因为它要求我们在每个时间步都从模型中采样,并逐步重建原始数据。与前向扩散过程不同,这个反向过程并没有闭式解。每一步都需要将上一步的数据和当前时间步输入模型,以预测在该时间步所加入的噪声。正因为如此,扩散模型的采样速度通常较慢。这也就是为什么像 SDXL-Lightning 这样的现代模型会着重减少去噪步数,以便更快生成图像。由于每一步都需要一份新的数据,我们必须在多个时间步上反复从模型中采样,才能完成重建。这个过程与 Transformer 以自回归方式生成文本有相似之处:每个 token 都是基于之前已经生成的 token 以迭代方式预测出来的。
用于采样前一个时间步期望数据的方程为:
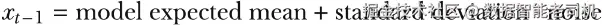
或写成数学形式为:
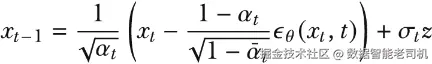
其中
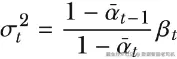
且当
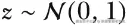
如果
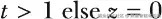
请回忆一下,我们的目标是从带噪数据中重构原始数据,因此我们是在已知 xt 和当前时间步 t 的条件下,求解 xt-1。方程左侧表示前一个时间步的期望数据,其中还会以受控方式重新引入一点噪声。我们训练得到的去噪模型 θ 用于预测当前时间步加入的噪声,然后利用该预测把这部分噪声从 xt 中减去。与此同时,在减去估计噪声的同时,我们还会以可控方式重新加入一小部分噪声,以帮助模型探索可能重构结果的多样性,更好地刻画数据分布的复杂性质。
注意 :这个公式的推导超出了本书讨论范围,但其数学推导可以在 Ho 等人的论文《Denoising Diffusion Probabilistic Models》中找到(arxiv.org/pdf/2006.11...)。
我们可以在 PyTorch 中这样实现这个方程:
ini
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)
posterior_variance = betas * (1. - alphas_cumprod_prev) / \
(1. - alphas_cumprod) #1
@torch.no_grad() #2
def sample_timestep(model, x, t):
betas_t = reshape_for_x(betas[t], x)
sqrt_one_minus_alphas_cumprod_t = reshape_for_x(
↪sqrt_one_minus_alphas_cumprod[t], x)
sqrt_recip_alphas_t = reshape_for_x(sqrt_recip_alphas[t], x)
# Call model (current image - noise prediction)
model_mean = sqrt_recip_alphas_t * (
x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t
) #3
posterior_variance_t = reshape_for_x(posterior_variance[t], x)
if t[0] == 0:
return model_mean
else:
noise = torch.randn_like(x)
return model_mean + torch.sqrt(
↪posterior_variance_t) * noise #4
#1 上一个公式中的 σ_t^2
#2 禁用梯度计算,作用类似于 torch.no_grad(),但这里是通过装饰器修饰一个函数。
#3 模型均值,即求和中的第一部分
#4 标准差 × 噪声,即求和中的第二部分有了这个函数之后,我们就可以从最后一个时间步开始,一步一步回到原始数据。做法是:从一组随机点出发,逐渐重建原始图像:
ini
eval_batch_size = 1000
sample = torch.randn(eval_batch_size, 2, device=device)
example_times = [999, 800, 500, 400, 0]
example_points = []
for i in range(T-1, -1, -1):
t = torch.full((eval_batch_size,), i, dtype=torch.long, device=device)
sample = sample_timestep(sample, t)
if i in example_times:
example_points.append(sample.clone())
plot_points(sample, ["Generated Logo"])在这个示例中,我们为 sample 创建了 1,000 个随机二维点,也就是一个 1000x2 的张量。随后,我们按时间步的逆序遍历,并应用刚才定义的 sample_timestep 函数。我们将 t+1 时刻的图像和当前时间步一起传入,以获得 t 时刻的图像。最后,我们将最终图像画出来,以观察重建出来的 PyTorch logo,如图 10.11 所示。我们还可以看到图像在时间倒流过程中的渐进变化,如图 10.12 所示。
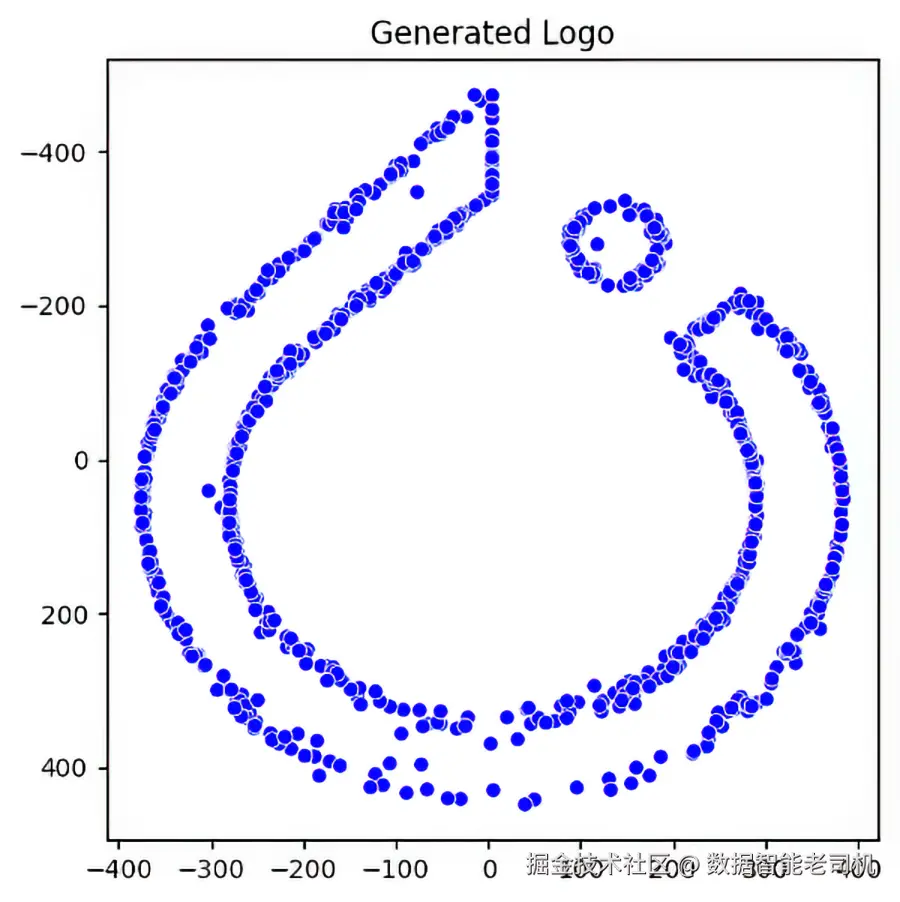
图 10.11 由随机点生成的 PyTorch logo

图 10.12 在不同时间步下,由随机点生成的 PyTorch logo
我们从混沌中创造出了某种东西。我们从一组随机点出发,利用扩散模型逐步重建出原始形状。这正是扩散模型在图像生成中的力量所在。虽然这只是一个简单示例,但同样的原理可以应用到更复杂的图像数据集上。我们用于修改点的那些方程,也可以用于修改图像的 RGB 值。这正是 DALL-E 和 Stable Diffusion 这类当前最前沿图像生成模型所依赖的底层原理。
10.8 结论
自生成模型诞生以来,图像生成领域已经发生了巨大演进。最初,VAE 和 GAN 作为开创性技术铺平了道路。这些模型试图生成照片级逼真的图像,并学习数据的底层分布,以创建多样化的合成图像。尽管 GAN 在生成高质量图像方面取得了成功,但它们在多样性方面存在不足。随后,扩散模型出现了,并凭借其既能实现出色的照片真实感、又能生成种类丰富图像的能力,彻底改变了这一领域。如今,扩散模型已被公认为图像生成任务中的领先方法。
在本章中,我们探索了如何构建自己的扩散模型来进行图像生成。我们学习了扩散模型如何通过添加噪声来逐步破坏数据结构,并进一步学习它如何反转这一过程,以重建原始数据。作为一个贯穿全章的示例,我们从一个由二维点表示图像轮廓的数据集开始。我们使用了 PyTorch logo,并对其施加前向扩散过程,逐步摧毁该 logo 的形状,直到它变成一组随机点。
为了反转扩散过程,我们训练了一个神经网络,用来预测加入到数据中的噪声。我们使用了一个简单的前馈神经网络来预测噪声,并通过将预测噪声与实际施加的噪声进行比较,使用均方误差损失来训练它。模型训练完成后,我们就可以从扩散模型中进行采样,生成新的图像。采样方程来自扩散模型原始研究论文中的推导。
通过在多个时间步上重复地从模型中采样,我们能够将一组随机点逐渐重建为原始形状。同样的原理也可以应用到更复杂的图像数据集上,例如 CIFAR-10 数据集,以生成新的图像。扩散模型似乎代表着图像生成的未来,甚至也可能代表着视频生成的未来(毕竟视频本质上只是一系列图像)。当前许多最先进的图像生成模型都建立在扩散模型之上,并且它们仍在不断推动生成式 AI 的能力边界。
10.9 练习
- 在图像生成中,VAE、GAN 和扩散模型的主要区别是什么?
- 给二维点加噪声,与给图像加噪声相比,有什么异同?
- 我们固定了一些不同的参数,例如噪声水平和扩散步数。改变这些参数会如何影响扩散模型的输出?
- 噪声水平还可以采用哪些不同的调度方式?
- 采样方程是如何从提出扩散模型的研究论文中推导出来的?
- 查看 Hugging Face 的 diffusers 库(huggingface.co/docs/diffus...),了解其中不同的扩散模型。尝试使用 Stable Diffusion 来生成图像。
小结
- 在图像生成中,和文本生成一样,我们关心的是学习数据的底层分布,从而生成新的样本。
- 变分自编码器(VAE)和生成对抗网络(GAN)是最早在图像生成中取得成功的模型架构。
- 扩散模型是一类特殊的生成模型,它会在图像中逐步引入噪声,然后学习如何反转这些噪声以重构图像。
- 前向扩散过程会缓慢地破坏数据的结构。
- 我们使用一个调度机制来控制前向扩散过程中每一步加入的噪声量,即 beta 值。
- 我们可以利用初始数据以及 beta 值的累积乘积,以闭式形式计算整个前向扩散过程。
- 正弦嵌入是一种常用的嵌入函数,因为它有助于保留空间信息并捕捉数据点之间的复杂交互。
- 我们可以训练一个神经网络去预测在前向扩散过程中加入到数据中的噪声。
- 扩散模型以类似自回归的方式进行采样:将上一步数据和当前时间步输入模型,以预测需要被减去的噪声。
- 这种扩散过程正是 DALL-E、Stable Diffusion 等最前沿图像生成模型背后的基本原理。