本章涵盖以下内容
- 激活函数:神经网络与线性模型之间的关键差异
- 使用 PyTorch 的
nn模块 - 用神经网络求解线性拟合问题
到目前为止,我们已经仔细考察了线性模型是如何学习的,以及如何在 PyTorch 中实现这一过程。我们关注的是一个非常简单的回归问题:使用一个只有单输入、单输出的线性模型。这样一个简单的例子,使我们能够剖析"模型如何学习"的机制,而不会过多被模型本身的实现细节分散注意力。正如我们在图 5.2 的概览图中所看到的那样(此处再次给出为图 6.1),要理解训练模型的高层过程,并不需要关心模型的精确细节。将误差反向传播到参数,再根据损失对参数求梯度并更新参数,这一过程无论底层模型是什么,都是一样的。
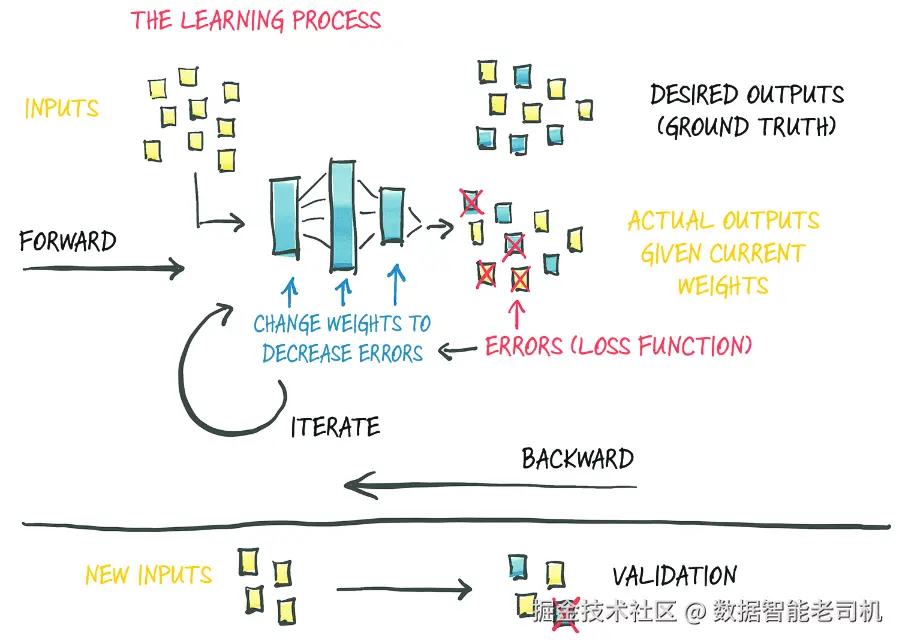
图 6.1 我们对学习过程的心智模型,如第 5 章中所实现的那样
在本章中,我们将对模型架构做一些修改:我们要实现一个完整的人工神经网络,来解决我们的温度转换问题。我们会继续使用上一章中的训练循环,以及按训练集和验证集划分好的华氏温度到摄氏温度样本。我们本来也可以开始使用一个二次模型:把模型改写为其输入的二次函数(例如, y=a∗x∗∗2+b∗x+c)。由于这样的模型也是可微的,PyTorch 会负责计算梯度,而训练循环也会照常工作。不过,这对我们来说并没有太大意思,因为那仍然是在固定函数的形状,而对于更复杂的问题,这种形状往往根本不可能预先知道。
在本章中,我们开始把前面打下的基础,与今后做项目时会日常使用的 PyTorch 功能连接起来。你将会理解 PyTorch API 这层精致外壳之下到底发生了什么,而不只是把它当成一个黑盒。在进入新模型的实现之前,我们先来说明一下,什么是人工神经网络。
6.1 人工神经元
深度学习的核心是神经网络------一种数学实体,它通过将较简单的函数进行组合,来表示复杂函数。"神经网络"这个术语显然会让人联想到人脑的工作方式。虽然最初的模型确实受到神经科学的启发(参见 F. Rosenblatt, "The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain," Psychological Review 65(6), 386--408 (1958)),但现代人工神经网络与大脑中神经元的机制其实只有很轻微的相似性。更可能的情况是,人工神经网络与生理神经网络都采用了某种大致相似的数学策略,来逼近复杂函数,因为这类策略确实非常有效。
注意 从这里开始,我们将去掉 "artificial(人工)" 这个限定,之后直接把这些结构称为"神经网络"。
这些复杂函数的基本构件是神经元 ,如图 6.2 所示。从本质上说,它不过是对输入做一次线性变换------例如,将输入乘以一个数(权重),再加上一个常数(偏置)------然后再施加一个固定的非线性函数(称为激活函数)。
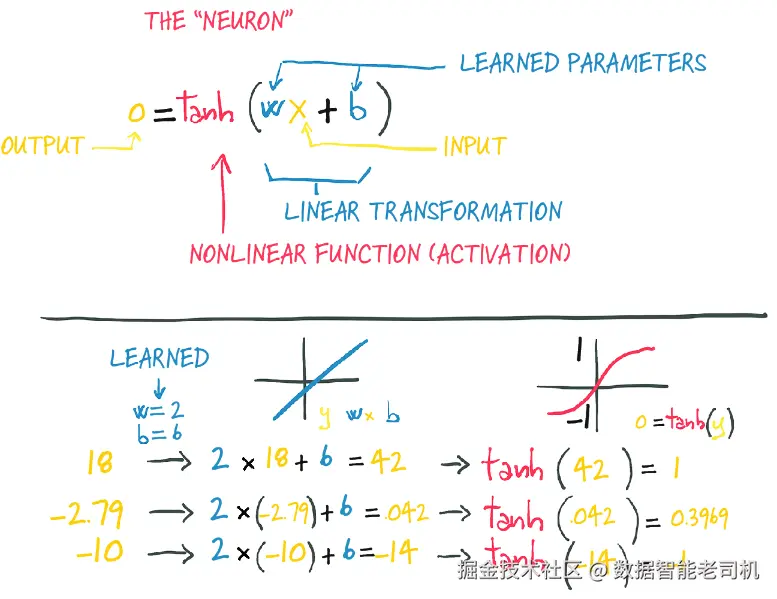
图 6.2 一个人工神经元:包裹在线性变换之外的非线性函数
从数学上,我们可以把它写成:
o=f(w×x+b)
其中,x 是输入,w 是权重或缩放因子,b 是偏置或偏移量。这里的 f 是激活函数,此处设置为双曲正切函数,也就是 tanh。一般来说,x 和 o 可以是简单的标量,也可以是向量值(即包含多个标量值);同样,w 可以是单个标量,也可以是矩阵,而 b 则可以是标量或向量(当然,输入和权重的维度必须匹配)。在后一种情况下,上述表达式就被称为一个神经元层(layer of neurons) ,因为它通过多维的权重和偏置,一次性表示了多个神经元。
6.1.1 组合成多层网络
一个多层神经网络,如图 6.3 所示,是由我们刚才讨论的那类函数组合而成的:
ini
x_1 = f(w_1 * x + b_1) #1
x_2 = f(w_2 * x_1 + b_2) #2
...
o = f(w_h * x_n + b_h) #3#1 第 1 层
#2 第 2 层
#3 第 h 层
也就是说,一层神经元的输出会作为下一层的输入。请记住,在这里,w_1 是一个矩阵,而 x 是一个向量!使用向量后,w_1 就能容纳整整一层神经元,而不只是一个单独的权重。这种矩阵形式使得 w_1 可以承载整层神经元的权重,从而通过线性代数实现并行计算。
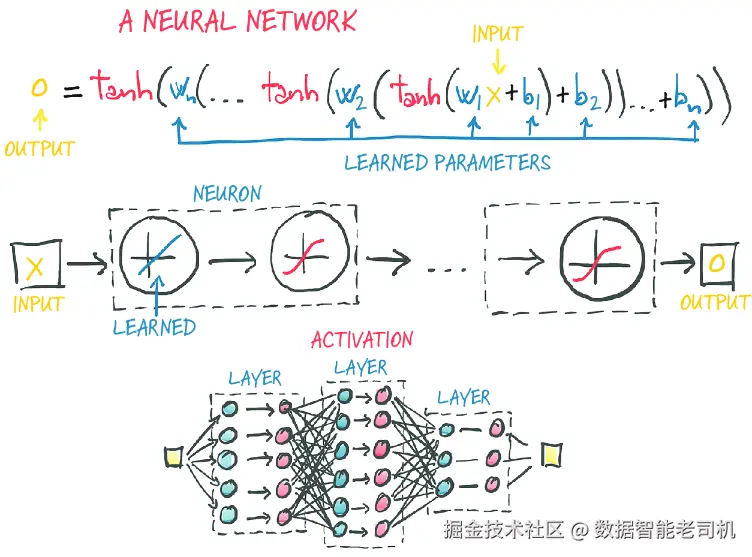
图 6.3 一个包含三层的神经网络
6.1.2 理解误差函数
我们之前的线性模型,与接下来在深度学习中真正会使用的模型之间,一个重要区别就在于误差函数的形状。我们的线性模型配合平方误差损失函数时,得到的是一个凸形误差曲面,具有唯一且明确定义的最小值。如果我们使用其他方法,也可以直接解出最小化误差函数的参数。因此,我们对参数的更新,本质上是在尽可能逼近那个唯一正确答案。
而神经网络并不具备凸误差曲面这一性质,即便使用的仍然是同样的平方误差损失函数!对于我们试图逼近的每一个参数,并不存在一个唯一正确答案。相反,我们是在努力让所有参数共同作用时,产生一个有用的输出。既然这个有用的输出本身也只是对真实情况的近似,那么总会存在某种程度的不完美。而这些不完美表现在哪里、以何种方式出现,在一定程度上是任意的;由此可见,那些控制输出、也就是控制这些不完美的参数,也在某种程度上具有任意性。参数本身并不具备单独的可解释性------它们只有作为整体系统的一部分时才有意义。因此,在同一份数据上训练出的两个神经网络,内部参数值可能完全不同,但却能达到相近的性能。
神经网络这种非凸性,在处理真实世界问题时其实反而是一种优势。真实世界很少遵循简单的线性规律,因此需要更复杂的模型来准确表示它。为了捕捉这种复杂性,神经网络需要借助激活函数引入非线性,从而建模现实数据中复杂的关系。
6.1.3 用激活函数引入非线性
正如我们所看到的,(深度)神经网络中最简单的单元,就是一个线性操作(缩放 + 偏移),然后接一个非线性激活函数。我们在最新的模型中其实已经有了线性操作------线性操作就是整个模型本身。激活函数有两个重要作用:
第一,在模型的内部部分,它使输出函数能够在不同取值处具有不同的斜率------而线性函数按定义是做不到这一点的。通过巧妙地组合这些斜率不同的部分,神经网络就能够逼近任意函数,正如我们将在 6.1.6 节中看到的那样。
第二,在网络的最后一层,它负责把前面各层的输出变换为对当前问题有意义的数值,例如,回归问题中的一个数值,或者分类问题中的类别分数。
注意 从直觉上讲,非线性激活使我们能够通过缩放和平移,构造出小的"凸起(bump)"函数。把这些凸起放在不同位置再相加,网络就可以在某个区间上逼近任意连续函数。这正是**通用逼近定理(Universal Approximation Theorem)**的本质。
我们来解释一下第二点是什么意思。假设我们要给图像打一个"乖狗狗"分数。寻回犬和西班牙猎犬的图片应该得高分,而飞机和垃圾车的图片应该得低分。熊的图片也应该得一个偏低的分数,不过总得比垃圾车高一些。
问题在于,我们必须定义什么叫"高分":我们面对的是整个 float32 的取值范围,这意味着分数理论上可以大得离谱。即便我们说"这是一个 10 分制",模型仍然有可能输出一个 11 分(满分 10 分)。别忘了,在底层,它仍然只是 (w*x+b) 的矩阵乘加运算,而这些运算不会天然把输出限制在某个固定范围内。
限制输出范围
我们希望将线性操作的输出严格约束在某个特定范围内,这样消费这个输出的后续模块就不必处理"幼犬 12/10 分、熊 -10 分、垃圾车 -1000 分"这样的数值输入。
一种办法是直接截断 输出值:低于 0 的都设为 0,高于 10 的都设为 10。这就是一个简单的激活函数,叫做 torch.nn.Hardtanh(不过要注意,它的默认范围是 -1 到 +1)。
压缩输出范围
另一类效果很好的函数是 torch.nn.Sigmoid 这一家族,其中包括 1 / (1 + e ** -x)、torch.tanh,以及我们稍后会看到的其他函数。这些函数的曲线具有这样的特征:当 x 趋向负无穷时,它们会渐近于 0 或 -1;当 x 增大时,它们会渐近于 1;并且在 x == 0 附近大致具有恒定斜率。从概念上说,这类形状之所以好用,是因为在线性函数输出的中间区域,神经元(再次强调,本质上就是线性函数加激活)会对输入变化较为敏感,而其他区域的值则会被压缩到边界附近。正如图 6.4 所示,我们的垃圾车会得到 -0.97 的分数,而熊、狐狸和狼则会落在 -0.3 到 0.3 之间。
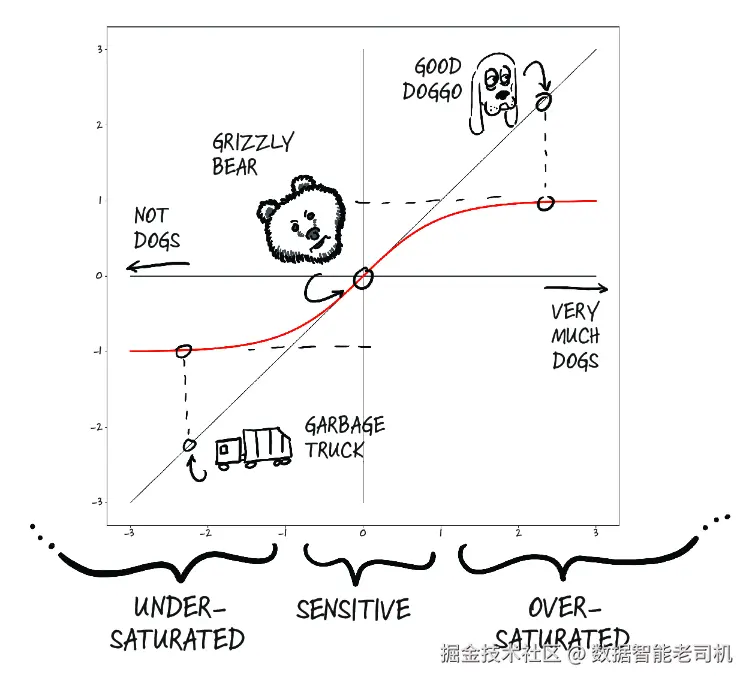
图 6.4 通过 tanh 激活函数,把狗、熊和垃圾车映射为"像狗的程度"
这个过程的结果是:垃圾车会被标记为"不是狗",真正的好狗狗会被映射为"显然是狗",而熊则会落在中间某个位置。用代码来看具体数值如下:
python
>>> import math
>>> math.tanh(-2.2) #1
-0.9757431300314515
>>> math.tanh(0.1) #2
0.09966799462495582
>>> math.tanh(2.5) #3
0.9866142981514303#1 垃圾车
#2 熊
#3 好狗狗
由于熊落在敏感区间内,对熊进行一些小变化,就会导致结果发生明显变化。例如,我们可以把灰熊换成北极熊(它的脸型传统上更接近犬类),于是分值会沿着 Y 轴向上移动,朝着"非常像狗"的方向靠近。相反,如果换成考拉熊,它就会显得更不像狗,激活输出会往下掉。但对于垃圾车来说,不管怎么改,也很难让它变得像狗;即便进行剧烈改动,分数可能也只是从 -0.97 变到 -0.8 左右。
6.1.4 更多激活函数
激活函数有很多种,其中一些如图 6.5 所示。第一列里,我们看到的是平滑函数 Tanh 和 Softplus;第二列则是它们左侧对应的"硬"版本:Hardtanh 和 ReLU。其中,ReLU(rectified linear unit,修正线性单元)尤其值得特别说明,因为它目前被认为是表现最好的通用激活函数之一;许多最先进的结果都使用了它。Sigmoid 激活函数,也称为逻辑函数,在早期深度学习中曾被广泛使用,但后来除了那些我们明确希望把输出限制在 0 到 1 范围的场景------例如输出表示概率时------它已经不再常用。最后,LeakyReLU 对标准 ReLU 做了修改:对于负输入,它不再严格等于 0,而是保留一个很小的正斜率。(通常这个斜率是 0.01,但为了图示清晰,这里画成了 0.1。)
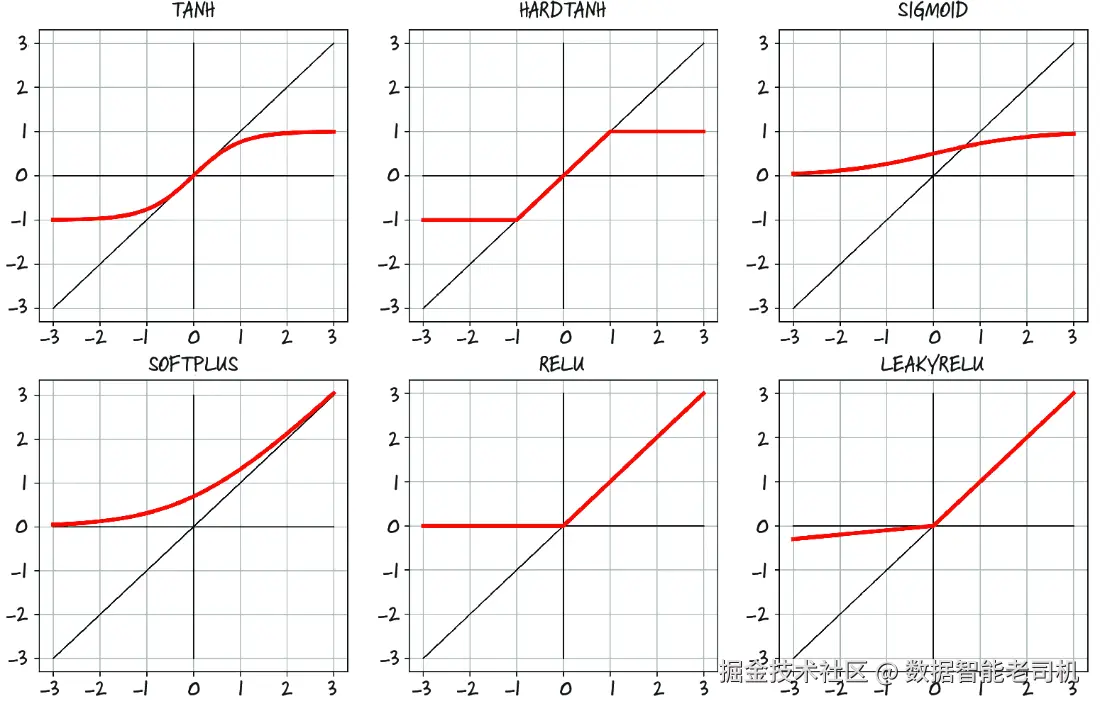
图 6.5 一组常见和不那么常见的激活函数
6.1.5 选择最佳激活函数
激活函数这个话题很有意思,因为已经被证明有效的激活函数种类如此之多(远不止图 6.5 中展示的那些),这说明真正严格的要求可能很少,甚至没有。因此,接下来我们要讨论一些关于激活函数的一般性结论,而这些结论在具体个例中很可能轻易就能被反驳。即便如此,按照定义,激活函数通常具有以下特点:
非线性 ------如果反复应用 (w*x+b) 而没有激活函数,那么最终结果仍然只是同一种形式的函数(仿射线性函数)。非线性使整个网络能够逼近更复杂的函数。
可微 ------这样梯度才能穿过它进行计算。像 Hardtanh 或 ReLU 那样,在某些特定点上导数可能不存在的点状不连续,并没有问题。缺少这些特性,网络要么退化成线性模型,要么就会变得难以训练。
注意 当然,连这些说法也并非总是成立。
对于这些函数而言,通常还成立以下事实:
- 它们至少有一个敏感区间,在这个区间里,输入的有意义变化会对应地引起输出的有意义变化。训练需要这一特性。
- 许多函数还有一个不敏感区间 (或称饱和区间),在这个区间里,输入变化几乎不会引起输出变化。
举例来说,Hardtanh 就可以通过把其敏感区间与不同的输入权重和偏置结合起来,轻松构造出某个函数的分段线性逼近。
通常情况下(虽然远非普遍如此),激活函数往往还至少满足以下之一:
- 当输入趋向负无穷时,存在一个会逐渐逼近(或直接达到)的下界
- 对正无穷方向,也存在一个类似但相反的上界
结合我们对反向传播机制的理解,可以推断:当输入处于响应区间时,误差会更有效地通过激活函数向后传播。反过来,对于那些输入已经饱和的神经元,误差对它们的影响会很小(因为此时梯度由于输出附近区域较平坦,通常接近于 0)。
把这些综合起来,结果就形成了一个非常强大的机制:在由"线性 + 激活"单元构成的网络中,当输入变化时,
(a) 对于同样的输入,不同单元会在不同区间作出响应;
(b) 与这些输入相关的误差,主要会影响那些工作在敏感区间内的神经元,而其他单元则基本不受学习过程影响。
此外,由于激活函数对输入的导数在敏感区间内通常接近 1,因此,对于那些落在这一工作区间内的单元,通过梯度下降估计其线性变换参数,看起来会很像我们此前见过的线性拟合问题。
我们正在逐渐建立起更深的直觉:把许多个线性激活单元并联起来,再一层层堆叠起来,就会形成一个能够逼近复杂函数的数学对象。不同的单元组合会对不同区间的输入作出响应,而这些单元对应的参数又比较容易通过梯度下降优化,因为在输出进入饱和之前,它们的学习行为很像线性函数。
6.1.6 对神经网络而言,"学习"意味着什么
用"线性变换 + 可微激活"的堆叠来构建模型,会得到一类能够逼近高度非线性过程、且其参数又可以通过梯度下降出奇地有效估计出来的模型。即使面对拥有数百万参数的模型,这一点仍然成立。深度神经网络之所以如此有吸引力,原因在于它使我们不必过于担心到底该用什么精确函数来表示数据------到底是二次函数、分段多项式,还是别的形式。许多问题根本无法用手工设计的函数来描述;例如,你要怎样构造一个数学函数,来判断一张图像中是否有狗?而借助深度神经网络,我们拥有了一个通用逼近器,以及一种估计其参数的方法。通过组合简单的基本构件,这个逼近器可以根据我们的需求进行定制,无论是在模型容量上,还是在建模复杂输入/输出关系的能力上。图 6.6 展示了一些例子。
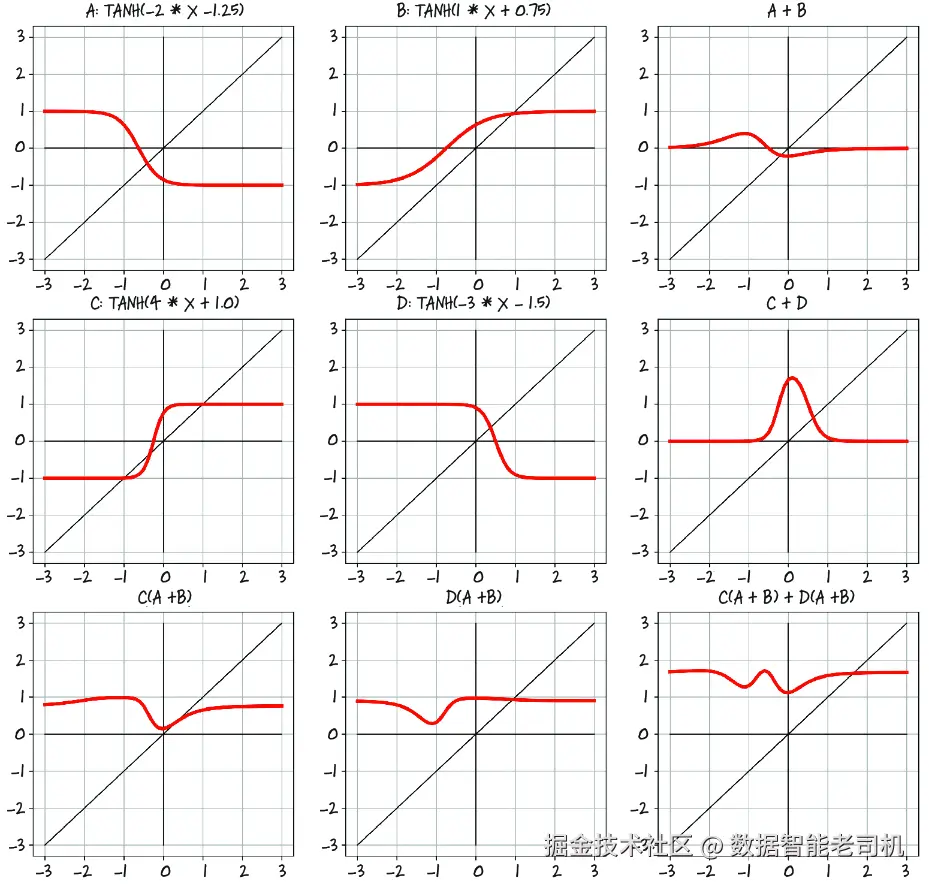
图 6.6 通过组合多个线性单元和 tanh 激活函数来生成非线性输出
图 6.6 左上角的四幅图展示了四个神经元------A、B、C 和 D------每个都有其各自的权重和偏置(这些值是任意选取的)。每个神经元都使用 Tanh 激活函数,其最小值为 -1,最大值为 1。不同的权重和偏置会移动中心点,并改变从最小值到最大值过渡的陡峭程度,但它们显然都具有同样的一般形状。右侧的几列则展示了神经元两两相加的结果(A + B 和 C + D)。在这里,我们开始看到一些类似于单层神经元层的有趣性质。A + B 呈现出轻微的 S 形曲线,两端趋近于 0,但中间同时出现一个正凸起和一个负凸起。相反,C + D 只有一个较大的正凸起,而且峰值甚至高于单个神经元的最大值 1。
在图 6.6 的第三行中,我们开始像双层网络那样组合这些神经元。C(A + B) 和 D(A + B) 都具有与 A + B 相同的正负凸起,但正峰值更微弱一些。而 C(A + B) + D(A + B) 的组合则呈现出一种新的性质:两个明显的负凸起,同时在主要关注区域左侧还可能有一个非常细微的第二个正峰。仅仅用两层中的四个神经元,就能产生这样的效果!
再次说明,这些神经元的参数只是为了在视觉上产生有趣结果而选取的。所谓训练,就是去寻找一组可接受的权重和偏置,使得由此形成的网络能够正确执行某项任务,例如根据地理坐标和一年中的时间来预测可能的温度。所谓"成功完成任务",是指:对来自与训练数据相同数据生成过程、但训练时未见过的数据,仍然能够得到正确的输出。一个训练成功的网络,会通过其权重和偏置的取值,以有意义的数值表示形式捕获数据的内在结构,并且这些表示能在此前未见过的数据上正常工作。
让我们再向对学习机制的理解迈进一步:深度神经网络使我们能够在没有显式模型的情况下,逼近高度非线性的现象。我们不是先写出一个具体的函数模型,而是从一个通用的、尚未训练的模型出发,通过提供一组输入、输出以及一个可用于反向传播的损失函数,将它专门化为某项任务。用样本把一个通用模型专门化到某项任务上,这就是我们所说的"学习",因为这个模型在构建时并没有为那项特定任务预先编码相应规则。
在我们的温度计例子中,我们假设两个温度计测量温度的方式都是线性的。这个假设本身,就是我们对任务规则的一种隐式编码:我们把输入/输出函数的形状硬编码进了模型中,因此它只能逼近那些分布在线附近的数据点。随着问题维度变高(也就是从多输入到多输出),而且输入/输出关系变得更复杂,对输入/输出函数预设某种形状通常是行不通的。物理学家或应用数学家的工作,往往就是从第一性原理出发,为某种现象建立函数描述,从而根据测量值估计未知参数,并得到一个准确的世界模型。
而深度神经网络则不同,它是一族函数,能够在不要求我们为某个现象先建立解释性模型的前提下,逼近各种各样的输入/输出关系。从某种意义上说,我们是放弃了解释性,以换取处理越来越复杂问题的可能性。从另一个角度看,有时我们根本没有能力、信息或计算资源去构建一个显式模型,因此,数据驱动的方法就成了我们唯一可行的道路。
6.2 PyTorch 的 nn 模块
前面讲了这么多关于神经网络的内容,你大概已经非常想知道,怎样用 PyTorch 从零开始搭一个神经网络了。我们的第一步,是把原先的线性模型替换成一个神经网络单元。从"是否正确解决问题"的角度看,这一步其实有点像是在做一次没什么必要的倒退,因为我们已经验证过,温度校准这个问题只需要一个线性函数就够了。不过,这一步仍然非常重要,因为它能帮助我们从一个足够简单的问题起步,之后再逐步扩展到更复杂的场景。
PyTorch 有一个专门用于神经网络的完整子模块,叫作 torch.nn。它包含了构建各种神经网络架构所需的基本构件。在 PyTorch 的术语里,这些构件被称为 module(模块) (而在其他框架中,这类构件通常被称为 layer(层) )。一个 PyTorch 模块,本质上是一个继承自 nn.Module 基类的 Python 类。一个模块可以包含一个或多个 nn.Parameter 实例作为属性,它们是一些张量,其值会在训练过程中被优化(可以把它们理解成我们在线性模型中的 w 和 b)。一个模块也可以包含一个或多个子模块(即 nn.Module 的子类)作为属性,并且它也能够追踪这些子模块中的参数。
注意 这些子模块必须是模块对象的顶层属性 ,不能藏在 list 或 dict 实例内部!否则,优化器将无法定位这些子模块(也就无法定位它们的参数)。对于模型确实需要用列表或字典来管理子模块的场景,PyTorch 提供了 nn.ModuleList 和 nn.ModuleDict。
不出意外,我们可以在 nn.Module 的子类中找到一个叫作 nn.Linear 的类。它会对输入施加一个仿射变换(通过其参数属性 weight 和 bias),其作用与我们在前面温度计实验中自己实现的线性模型是等价的。现在,我们就从上次停下的地方继续,把之前的代码改写成使用 nn 的形式。
6.2.1 把 nn.Module 当作可调用对象来使用
PyTorch 的 nn.Module 被设计成一种可调用对象(callable object) ,也就是说,它内部定义了自己的 __call__ 方法。因此,我们可以实例化一个 nn.Linear,然后像调用函数一样去调用它(code/p1ch6/1_neural_networks.ipynb):
ini
# In[5]:
import torch.nn as nn
linear_model = nn.Linear(1, 1) #1
linear_model(t_un_val)
# Out[5]:
tensor([[0.6018],
[0.2877]], grad_fn=<AddmmBackward>)
#1 我们马上就会来看构造函数参数的含义。当我们用一组参数去调用一个 nn.Module 实例时,最终会调用一个名为 forward 的方法,并把同样的参数传进去。forward 方法负责执行前向计算 ,而 __call__ 则会在调用 forward 之前和之后完成一些其他相当重要的工作。因此,从技术上讲,直接调用 forward 也确实会得到与 __call__ 相同的输出,但用户代码不应该这么做:
ini
y = model(x) #1
y = model.forward(x) #2
#1 正确!
#2 静默错误。不要这样做!在某些情况下,PyTorch 模块会附加 hook(钩子) 。钩子本质上是一些函数,可以被指定在前向传播或反向传播的特定时机执行。这些钩子既可以由用户定义,也可以在一些高级使用场景中由 PyTorch 库自身使用,例如实现某种分布式训练策略。如果你直接调用 forward,这些钩子就不会被执行,从而可能导致程序出错。
6.2.2 回到线性模型
现在回到我们的线性模型。nn.Linear 的构造函数接受三个参数:输入特征数、输出特征数,以及该线性模型是否包含偏置项(默认值为 True,这里也是如此):
ini
# In[5]:
import torch.nn as nn
linear_model = nn.Linear(1, 1) #1
linear_model(t_un_val)
# Out[5]:
tensor([[0.6018],
[0.2877]], grad_fn=<AddmmBackward>)
#1 参数分别是输入大小、输出大小,以及 bias(默认为 True)。在我们的例子中,所谓特征数,指的只是这个模块输入张量和输出张量的大小,因此就是 1 和 1。比如说,如果我们把温度和气压同时作为输入,那么输入就会有两个特征,而输出仍然可能只有一个特征。正如我们后面会看到的,在包含多个中间模块的更复杂模型中,特征数还会与模型的容量相关。
现在我们有了一个输入特征数为 1、输出特征数也为 1 的 nn.Linear 实例。这样一个模型只需要一个权重和一个偏置:
ini
# In[6]:
linear_model.weight
# Out[6]:
Parameter containing:
tensor([[-0.0674]], requires_grad=True)
# In[7]:
linear_model.bias
# Out[7]:
Parameter containing:
tensor([0.7488], requires_grad=True)我们可以用一些输入来调用这个模块:
ini
# In[8]:
x = torch.ones(1)
linear_model(x)
# Out[8]:
tensor([0.6814], grad_fn=<AddBackward0>)虽然 PyTorch 允许我们这么做,但实际上我们提供的输入维度并不真正符合要求。我们这里有一个接收单输入并产生单输出的模型,但 PyTorch 的 nn.Module 及其子类在设计上,是为了同时处理多个样本的。为了支持多个样本,模块会假定输入的第 0 维表示批次中的样本数。我们在第 4 章中已经接触过这个概念,当时我们学习了如何把真实世界的数据组织成张量。
对输入进行批处理
nn 中的任何模块,都是为了能一次性对一个批次中的多个输入同时产生输出而编写的。因此,假设我们要让 nn.Linear 处理 10 个样本,就可以创建一个大小为 B × N_in 的输入张量,其中 B 是批大小,N_in 是输入特征数,然后一次性送进模型。例如:
ini
# In[9]:
x = torch.ones(10, 1)
linear_model(x)
# Out[9]:
tensor([[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814],
[0.6814]], grad_fn=<AddmmBackward>)让我们深入看一下这里到底发生了什么。图 6.7 展示了一个类似的场景,不过那里的输入是按批组织的图像数据。输入张量的形状是 B × C × H × W,其中批大小为 3(比如,三张图片分别是一只狗、一只鸟和一辆车),通道维度为 3(红、绿、蓝),高和宽则对应图像像素的尺寸。正如图中所示,输出是一个大小为 B × N_out 的张量,其中 N_out 是输出特征数(在这张图里,这 4 个输出特征值表示不同类别的分类分数,例如"交通工具""动物""鸟类"和"哺乳动物")。
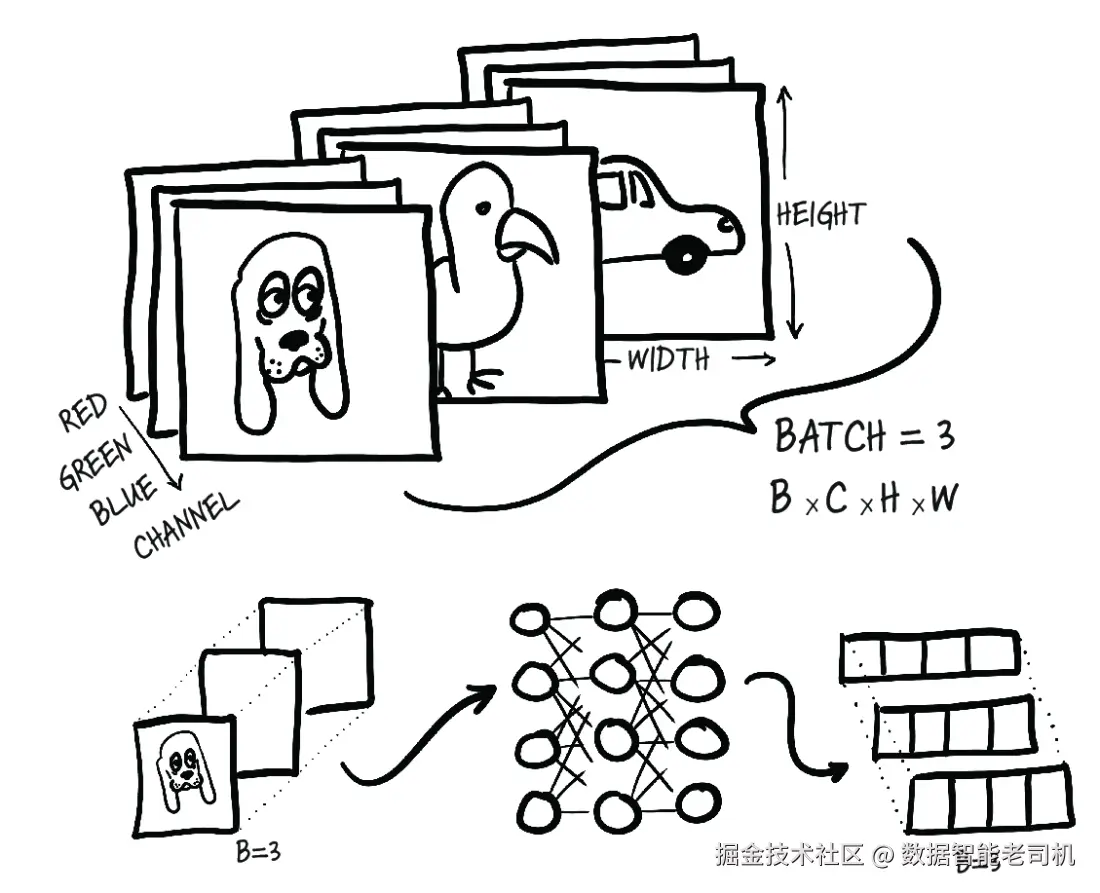
图 6.7 三张 RGB 图像被打包成一个批次并送入神经网络。输出是一个由三个长度为 4 的向量组成的批次。
为什么要对批次进行优化
我们希望这样做批处理,原因有很多。一个很重要的动机是:确保我们提交给计算设备的任务规模足够大,从而能够充分占满可用的计算资源。尤其是 GPU,它具有高度并行化的特点,因此,如果只给一个小模型喂一个输入,大部分计算单元都会闲置。通过提供一整个批次的输入,计算可以分摊到原本闲置的那些单元上,这意味着批量结果返回的速度,几乎可以和单个结果一样快。另一个好处是,一些高级模型会利用整个批次的统计信息,而批大小越大,这些统计量往往越可靠。
回到我们的温度计数据:t_u 和 t_c 原本是两个大小为 B 的一维张量。由于广播机制的存在,我们可以把线性模型写成 w * x + b,其中 w 和 b 都是标量参数。这之所以成立,是因为我们只有一个输入特征;如果有两个输入特征,我们就必须再增加一个维度,把这个一维张量变成一个矩阵,其中行表示样本,列表示特征。
而这正是我们切换到 nn.Linear 所需要做的。我们把 B 个输入重塑成 B × N_in 的形状,其中 N_in = 1。这可以很方便地通过 unsqueeze 完成:
ini
# In[2]:
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c).unsqueeze(1) #1
t_u = torch.tensor(t_u).unsqueeze(1) #1
t_u.shape
# Out[2]:
torch.Size([11, 1])
#1 在 axis 1 上增加一个额外维度这样我们就准备好了;接下来更新训练代码。首先,把原先手写的模型替换成 nn.Linear(1,1),然后我们还需要把线性模型的参数传给优化器:
ini
# In[10]:
linear_model = nn.Linear(1, 1) #1
optimizer = optim.SGD(
linear_model.parameters(), #2
lr=1e-2)
#1 重新定义,替换前面的版本
#2 这个方法会取出模型参数。它替代了我们在第 5 章中使用的 [params]。之前,是我们自己负责创建参数,并把它们作为第一个参数传给 optim.SGD。现在,我们可以使用 parameters 方法,让任意一个 nn.Module 返回它自身以及其所有子模块所拥有的参数列表:
ini
# In[11]:
linear_model.parameters()
# Out[11]:
<generator object Module.parameters at 0x7f94b4a8a750>
# In[12]:
list(linear_model.parameters())
# Out[12]:
[Parameter containing:
tensor([[0.7398]], requires_grad=True), Parameter containing:
tensor([0.7974], requires_grad=True)]这个调用会递归地进入模块的 init 构造函数中定义的各个子模块,并返回一个由所有参数扁平化组成的列表,这样我们就能像之前那样方便地把它传给优化器构造函数。
到这里,我们已经可以推断训练循环里会发生什么了。优化器拿到的是一组张量,而这些张量全都定义为 requires_grad = True。Parameter 本质上只是张量的一个子类,但它会被 nn.Module 特殊识别;由于它们需要通过梯度下降被优化,因此默认就要求计算梯度。当调用 training_loss.backward() 时,梯度会累积到计算图的叶子节点上,而这些叶子节点恰恰就是传给优化器的那些参数。
此时,SGD 优化器已经具备了所需的一切信息。当调用 optimizer.step() 时,它会遍历每一个 Parameter,然后按照其 grad 属性中存储的值,按一定比例去更新它。这个设计非常干净利落。
现在我们来看一下训练循环:
ini
# In[13]:
def training_loop(n_epochs, optimizer, model, loss_fn, t_u_train, t_u_val,
t_c_train, t_c_val):
for epoch in range(1, n_epochs + 1):
t_p_train = model(t_u_train) #1
loss_train = loss_fn(t_p_train, t_c_train)
t_p_val = model(t_u_val)
loss_val = loss_fn(t_p_val, t_c_val)
optimizer.zero_grad()
loss_train.backward() #2
optimizer.step()
if epoch == 1 or epoch % 1000 == 0:
print(f"Epoch {epoch}, Training loss {loss_train.item():.4f},"
f" Validation loss {loss_val.item():.4f}")
#1 现在传入的是模型本身,而不是单独的 params。
#2 损失函数现在也作为参数传入。我们马上就会用到它。这个模型几乎没什么变化,只不过现在我们不再显式地把 params 传给 model,因为模型已经把自己的参数内部保存好了。
最后,torch.nn 里还有一个我们可以直接拿来用的东西:损失函数 。事实上,nn 自带了若干常见损失函数,其中就包括 nn.MSELoss(MSE 即 mean squared error,均方误差),它正是我们之前手写 loss_fn 时定义的那个损失函数。nn 中的损失函数同样也是 nn.Module 的子类,因此我们要创建一个实例,然后像函数一样调用它。在我们的例子里,我们可以去掉手写的 loss_fn,改成这样:
ini
# In[15]:
linear_model = nn.Linear(1, 1)
optimizer = optim.SGD(linear_model.parameters(), lr=1e-2)
training_loop(
n_epochs = 3000,
optimizer = optimizer,
model = linear_model,
loss_fn = nn.MSELoss(), #1
t_u_train = t_un_train,
t_u_val = t_un_val,
t_c_train = t_c_train,
t_c_val = t_c_val)
print()
print(linear_model.weight)
print(linear_model.bias)
# Out[15]:
Epoch 1, Training loss 134.9599, Validation loss 183.1707
Epoch 1000, Training loss 4.8053, Validation loss 4.7307
Epoch 2000, Training loss 3.0285, Validation loss 3.0889
Epoch 3000, Training loss 2.8569, Validation loss 3.9105
Parameter containing:
tensor([[5.4319]], requires_grad=True)
Parameter containing:
tensor([-17.9693], requires_grad=True)
#1 我们不再使用前面手写的损失函数了。传入训练循环的其他所有内容都保持不变。甚至最终结果也与之前一样。当然,得到相同结果本来就是预期之中的事,因为如果两种实现结果不同,那就意味着其中至少有一个实现存在 bug。
6.3 终于来到神经网络
这一路走来花了不少篇幅------我们已经对定义并训练一个模型所需的这二十来行代码进行了相当深入的剖析。希望到现在为止,训练过程中的那层"魔法感"已经消退,取而代之的是对其运行机制的理解。到目前为止学到的内容,将使我们能够真正掌控自己写下的代码;等问题变得更复杂时,我们不再只是对着一个黑盒胡乱试探。
现在还剩最后一步:把我们的线性模型替换成一个神经网络,作为用于逼近函数的模型。我们前面说过,使用神经网络并不会得到一个质量更高的模型,因为我们的这个校准问题,其底层过程本质上就是线性的。不过,在一个可控的环境里,从线性模型迈向神经网络,是很有必要的一步。这样一来,等以后进入更复杂的场景时,我们就不会觉得无从下手了。
6.3.1 替换线性模型
我们将保持其他所有部分不变,包括损失函数,只重新定义 model。现在来构建一个尽可能简单的神经网络:一个线性模块,后接一个激活函数,再接另一个线性模块。出于历史原因,第一层"线性 + 激活"通常被称为隐藏层(hidden layer) ,因为它的输出并不会被直接观测到,而是会继续送入输出层。
虽然模型的输入和输出大小都为 1(也就是说,它只有 1 个输入特征和 1 个输出特征),但第一个线性模块的输出大小通常会大于 1。回想我们前面对激活函数作用的解释,这种设置会让不同的单元对输入的不同区间作出响应,从而提升模型的容量。最后一个线性层会接收这些激活后的输出,并将它们线性组合起来,产生最终的输出值。
神经网络并没有统一标准的画法。图 6.8 展示了两种比较典型的表示方式:左边是入门材料中常见的画法,而右边这种风格则更常见于较高级的文献和研究论文中。通常,人们会把图中的模块块状结构,画得与 PyTorch 提供的神经网络模块大致对应(当然,有时像 Tanh 激活层这样的部分不会被明确画出来)。这两种图之间一个较为微妙的区别在于:左图把圆圈中的输入和(中间)结果作为主要元素,而右图则更突出计算步骤本身。
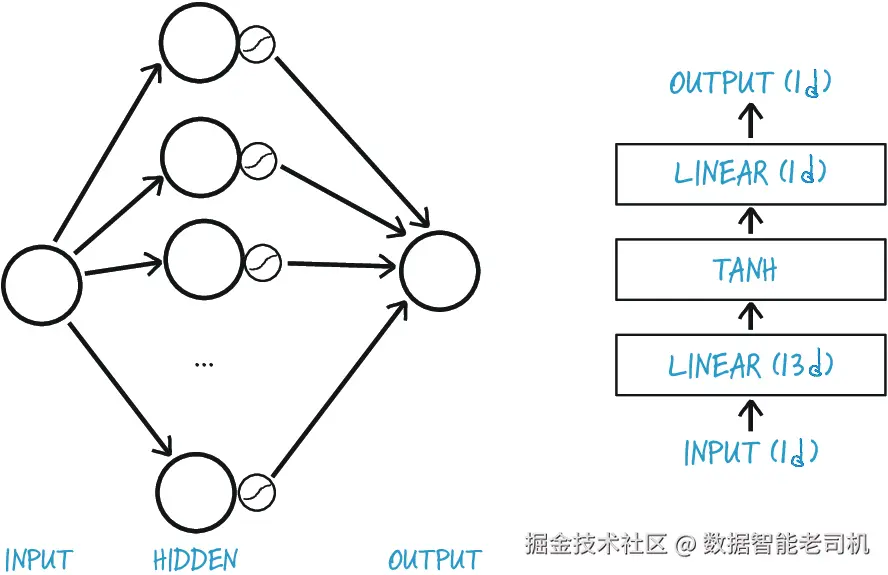
图 6.8 我们最简单的神经网络,两种视图。左:入门版。右:更高层次的表示方式。
nn 提供了一种简单的方式,通过 nn.Sequential 容器将多个模块串接起来:
ini
# In[16]:
seq_model = nn.Sequential(
nn.Linear(1, 13), #1
nn.Tanh(),
nn.Linear(13, 1)) #2
seq_model
# Out[16]:
Sequential(
(0): Linear(in_features=1, out_features=13, bias=True)
(1): Tanh()
(2): Linear(in_features=13, out_features=1, bias=True)
)
#1 我们是随意选了 13。只是想要一个和周围其他张量形状都不同的数字。
#2 不过这里的 13 必须和前一个层的输出大小一致。最终得到的这个模型,会接收 nn.Sequential 中第一个模块所期望的输入,把中间结果依次传给后续模块,并输出最后一个模块返回的结果。这个模型会先把 1 个输入特征扩展成 13 个隐藏特征,对它们施加 tanh 激活,然后再把这 13 个数线性组合成 1 个输出特征。
6.3.2 检查参数
调用 model.parameters() 会收集第一个和第二个线性模块中的 weight 与 bias。在这种情况下,通过打印这些参数的形状来查看它们是很有启发意义的:
ini
# In[17]:
[param.shape for param in seq_model.parameters()]
# Out[17]:
[torch.Size([13, 1]), torch.Size([13]), torch.Size([1, 13]), torch.Size([1])]这些就是会传递给优化器的张量。和之前一样,在我们调用 loss_train.backward() 之后,所有参数都会得到各自的 grad;随后,优化器会在 optimizer.step() 调用时据此更新它们的值。和我们前面的线性模型相比,其实也没什么本质不同,对吧?毕竟它们都是可微模型,都可以用梯度下降来训练。
关于 nn.Module 的参数,还有几点需要说明。当我们检查一个由多个子模块组成的模型时,能够通过名字识别参数会很方便。PyTorch 为此提供了一个方法,叫作 named_parameters:
css
# In[18]:
for name, param in seq_model.named_parameters():
print(name, param.shape)
# Out[18]:
0.weight torch.Size([13, 1])
0.bias torch.Size([13])
2.weight torch.Size([1, 13])
2.bias torch.Size([1])注意 你可能已经注意到,虽然 nn.Tanh 明明定义在模型中,但它却没有出现在参数列表里。原因是 tanh 和大多数激活函数一样,本身并不带参数。它只是一个固定的数学运算,会按照预先定义好的方式变换输入,因此不像线性层那样在训练过程中被调优。
在 Sequential 中,每个模块的名字默认就是它在参数列表中出现的序号。有意思的是,Sequential 也接受一个 OrderedDict,这样我们就可以给传入 Sequential 的每个模块命名:
注意 并不是所有 Python 版本都对 dict 的迭代顺序作出明确规定,因此这里使用 OrderedDict,一方面是为了确保层的顺序,另一方面也是为了强调:层的顺序是有意义的。
css
# In[19]:
from collections import OrderedDict
seq_model = nn.Sequential(OrderedDict([
('hidden_linear', nn.Linear(1, 8)),
('hidden_activation', nn.Tanh()),
('output_linear', nn.Linear(8, 1))
]))
seq_model
# Out[19]:
Sequential(
(hidden_linear): Linear(in_features=1, out_features=8, bias=True)
(hidden_activation): Tanh()
(output_linear): Linear(in_features=8, out_features=1, bias=True)
)这样一来,我们就能为子模块获得更具说明性的名字:
css
# In[20]:
for name, param in seq_model.named_parameters():
print(name, param.shape)
# Out[20]:
hidden_linear.weight torch.Size([8, 1])
hidden_linear.bias torch.Size([8])
output_linear.weight torch.Size([1, 8])
output_linear.bias torch.Size([1])这种方式的描述性更强,但它并不会让我们在网络中的数据流控制上获得更大的灵活性;数据仍然只是按顺序一层层向前传递------nn.Sequential 这个名字起得确实很贴切。若想对数据的处理方式拥有更高的控制力和灵活性,例如支持非线性的数据流、自定义层之间的交互,或条件分支式的处理路径,你就需要通过继承 nn.Module 来创建自定义网络架构。这个内容会在第 8 章中展开。
我们也可以通过子模块属性来访问某个特定的 Parameter:
ini
# In[21]:
seq_model.output_linear.bias
# Out[21]:
Parameter containing:
tensor([-0.0173], requires_grad=True)访问这些 Parameter,有助于我们检查参数本身或它们的梯度------例如像本章开头那样,在训练过程中监控梯度。假设我们想打印隐藏层中线性部分的 weight 梯度。我们可以先运行这个新的神经网络模型的训练循环,然后在最后一个 epoch 结束后查看得到的梯度:
ini
# In[22]:
optimizer = optim.SGD(seq_model.parameters(), lr=1e-3) #1
training_loop(
n_epochs = 5000,
optimizer = optimizer,
model = seq_model,
loss_fn = nn.MSELoss(),
t_u_train = t_un_train,
t_u_val = t_un_val,
t_c_train = t_c_train,
t_c_val = t_c_val)
print('output', seq_model(t_un_val))
print('answer', t_c_val)
print('hidden', seq_model.hidden_linear.weight.grad)
# Out[22]:
Epoch 1, Training loss 182.9724, Validation loss 231.8708
Epoch 1000, Training loss 6.6642, Validation loss 3.7330
Epoch 2000, Training loss 5.1502, Validation loss 0.1406
Epoch 3000, Training loss 2.9653, Validation loss 1.0005
Epoch 4000, Training loss 2.2839, Validation loss 1.6580
Epoch 5000, Training loss 2.1141, Validation loss 2.0215
output tensor([[-1.9930],
[20.8729]], grad_fn=<AddmmBackward>)
answer tensor([[-4.],
[21.]])
hidden tensor([[ 0.0272],
[ 0.0139],
[ 0.1692],
[ 0.1735],
[-0.1697],
[ 0.1455],
[-0.0136],
[-0.0554]])
#1 我们把学习率稍微调低了一些,以帮助训练稳定。6.3.3 与线性模型进行比较
我们还可以在全部数据上评估这个模型,看看它与一条直线相比有何不同:
css
# In[23]:
from matplotlib import pyplot as plt
t_range = torch.arange(20., 90.).unsqueeze(1)
fig = plt.figure(dpi=600)
plt.xlabel("Fahrenheit")
plt.ylabel("Celsius")
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.plot(t_range.numpy(), seq_model(0.1 * t_range).detach().numpy(), 'c-')
plt.plot(t_u.numpy(), seq_model(0.1 * t_u).detach().numpy(), 'kx')结果如图 6.9 所示。我们可以看出,这个神经网络确实表现出了一定的过拟合倾向,正如我们在第 5 章讨论过的那样:它试图去追逐这些测量值,连其中带噪声的点也不放过。即使是这样一个很小的神经网络,对于我们手头这少量的测量数据来说,也已经拥有了太多参数。不过,总体来看,它做得也并不算差。
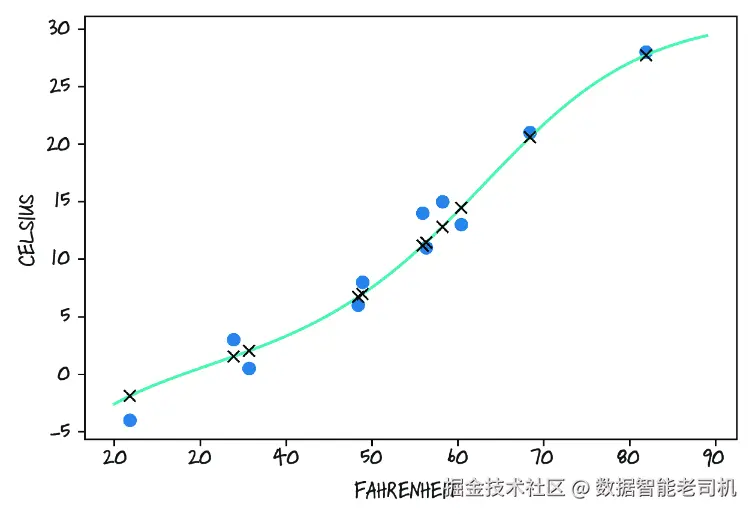
图 6.9 我们的神经网络模型曲线图。其中圆点表示输入数据,叉号表示模型输出,连续曲线则展示了神经网络在样本点之间所捕捉到的行为。
6.4 小结
虽然我们处理的是一个非常简单的问题,但在第 5 章和第 6 章中,我们其实已经覆盖了很多内容。我们把如何构建可微模型、以及如何通过梯度下降来训练这些模型,层层拆解了一遍:一开始直接使用原始的 autograd,之后又借助 nn 来完成。到现在为止,你应该已经对这些机制在幕后是如何运作的有了足够的信心。希望这一点点 PyTorch 的体验,已经激起了你继续深入学习的兴趣!
6.5 练习
试着在我们这个简单的神经网络模型中,调整隐藏层神经元的数量,以及学习率:
- 哪些改动会让模型的输出变得更接近线性?
- 你能否让模型明显地对数据发生过拟合?
在物理学中,第三难的问题是为庆祝发现挑选一瓶合适的葡萄酒。请载入第 4 章中的葡萄酒数据,并创建一个新的模型,使其具有合适数量的输入参数:
- 与我们一直在使用的温度数据相比,训练需要多长时间?
- 你能解释是什么因素导致了训练时间的差异吗?
- 你能否让模型在这个数据集上训练时使损失下降?
- 你会如何为这个数据集作图?
总结
- 神经网络能够自动调整自身,从而专门适应当前要解决的问题。
- 神经网络使我们能够方便地获得损失函数相对于模型中任意参数的解析导数,这使得参数的迭代优化变得非常高效。借助其自动微分引擎,PyTorch 可以毫不费力地提供这些导数。
- 将激活函数与线性变换结合起来,能够让神经网络具备逼近高度非线性函数的能力,同时又保持结构足够简单,从而仍然可以通过基于梯度的方法进行优化。
nn模块连同张量标准库一起,提供了构建神经网络所需的全部基础构件。- 你可以使用
.parameters()和.named_parameters()来检查神经网络的参数。