本篇文章是基于平时工作和日常学习总结整理的K8s相关知识点,供同行者和自己参考。
一、K8s高级资源对象之pod
label标签(键=值)
K8s中所有资源的关联都是通过标签实现的,标签是唯一标识
添加、删除、修改标签,基于标签检索
eg:
添加
kubectl label node 192.168.15.169 disk=ssd
基于标签检索(多标签检索用,隔开)
kubectl get nodes -l disk=ssd
查看
kubectl get nodes --show-labels
删除
kubectl label node 192.168.15.169 disk=ssd-
修改
kubectl label node 192.168.15.169 disk=hdd --overwrite创建资源对象:run、create、apply
kubectl create ns sre
kubectl run pod linux_pod -n sre --image=nginx:1.25
kubectl delete pod linux_pod(一)pod
kubectl run pod linux_pod -n sre --image=nginx:1.25 #创建pod
--dry-run= 尝试运行创建pod
[root@master ~]# kubectl api-resources
[root@master ~]# kubectl run pod my-pod --image=nginx:1.25 -o yaml -n my-namespace
apiVersion: v1
kind: Pod
#元数据:标签、注解、名称、命名空间
metadata:
creationTimestamp: "2025-11-28T16:46:03Z"
labels:
run: pod
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:labels:
.: {}
f:run: {}
f:spec:
f:containers:
k:{"name":"pod"}:
.: {}
f:args: {}
f:image: {}
f:imagePullPolicy: {}
f:name: {}
f:resources: {}
f:terminationMessagePath: {}
f:terminationMessagePolicy: {}
f:dnsPolicy: {}
f:enableServiceLinks: {}
f:restartPolicy: {}
f:schedulerName: {}
f:securityContext: {}
f:terminationGracePeriodSeconds: {}
manager: kubectl-run
operation: Update
time: "2025-11-28T16:46:03Z"
name: pod
namespace: my-namespace
resourceVersion: "76834"
uid: 78b76bdd-7db4-4d54-a3b1-cd349deb4635
#描述
spec:
containers:
- args:
- my-pod
image: nginx:1.25
imagePullPolicy: IfNotPresent
name: pod
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-ddllh
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: default-token-ddllh
secret:
defaultMode: 420
secretName: default-token-ddllh
status:
phase: Pending
qosClass: BestEffortrun命令行运行pod
apply只能通过文件创建对象,资源可以反复创建(相当于在修改)
create可通过文件和命令行创建,但一旦资源存在,不能再次创建
注意:一个pod中,容器全起来了这个pod才是正常启动的
一个pod中的所有容器都共用一个地址,所以要注意端口是否冲突
1.重启策略restartPolicy
Always #pod中定义(默认策略)
OnFailure #在job/cronjob资源对象中会遇到
Nerver #在job/cronjob资源对象中会遇到
pod的dns策略 dnsPolicy
Default #如果一个容器使用的是宿主机IP,则默认的dns策略是Default
ClusterFirst #默认策略,使用K8s内置dns(解析到pod的ip)
ClusterWithHostnet #对于与 hostNetwork(网络接口使用的是宿主机的) 一起运行的 Pod,应显式设置其DNS策略,将同时解决default和ClusterFirst的DNS解析。如果不加上dnsPolicy: ClusterFirstWithHostNet ,Pod默认使用所在宿主主机使用的DNS,这样也会导致容器内不能通过service name 访问k8s集群中其他Pod)
None #不定义dns策略,此时的pod没有dns配置:该策略必须与dnsconfig配合使用k8s中的command参数对应docker的entrypoint参数,用于定义容器启动时执行的程序命令
k8s中的args参数对应 docker 的 CMD参数,用于定义传递给 ENTRYPOINT 的默认参数
2.资源配额
resource:
requests: #调度器资源预留(实际上pod是用多少占多少)
cpu:"0.2"
memory:"128Mi"
limits: #资源限制
cpu:"0.5"
memory:"256Mi"
如果内存超过限制,pod会被杀掉,pod的状态被标记为OOM(out of memory)
如果CPU超出限制,pod不会被杀掉,会触发cpu限流(在没有多余cpu可分配的情况下)CPU按时间切片,1核=1s
resources可以定义pod的服务等级:
BestEffort:有多少空余就可以用多少(未指定resources限制,默认是这个)
Burstable:介于effort和grantee之间(设置了resources,但是request和limits不相等)
grantee:最高优先级(设置了resources,但是request和limits相等)3.容器的健康检查
探活阶段:
startupProbe:容器启动阶段探测,预期探测失败;如果成功,则该阶段结束,该探测器退出。
livenessProbe:容器运行阶段探测,预期探测成功;如果失败,则杀掉容器。(当startupProbe正常退出后,该阶段才启动探测)
10s3次标记为失败杀掉30s(在这时间内,业务会访问失败) 10s 3次 标记为失败 杀掉 30s (在这时间内,业务会访问失败) 10s3次标记为失败杀掉30s(在这时间内,业务会访问失败)
ReadinessProbe:容器运行阶段探测,预期探测成功;如果失败,则将容器标记为未就绪
2s3次标为未就绪(流量不会到这个容器的pod来) 2s 3次 标为未就绪 (流量不会到这个容器的pod来) 2s3次标为未就绪(流量不会到这个容器的pod来)
探活方法:
·tcp
tcpSocket:
port:80·http
cmd
参数:
多长时间探测一次
连续几次失败算失败
连续几次成功算成功
失败了怎么处理
什么时候开始启动探活
探活超时时间静态pod
kubelet不经过调度器,自己运行在本机的pod就是静态pod,静态pod无法被master管理。
master组件的pod就是静态pod
pod要放在节点/etc/kubernetes/mainfests的路径下
静态pod名:yaml文件名-节点IP
4.持久化卷
pod停止后,再次启动可能会调度到不同的节点上,所以pod停止就会杀掉容器,所以也不会存储数据。
hostpath方式:

emptyDir 临时存储
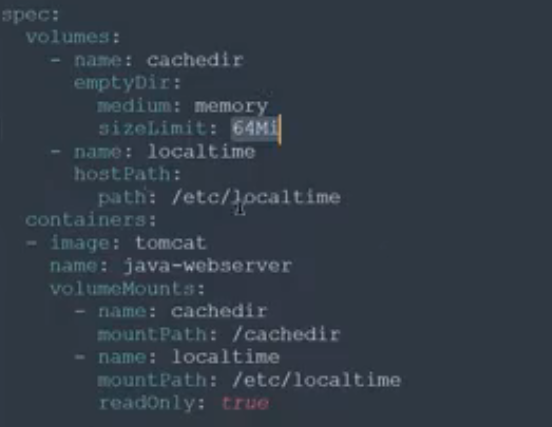
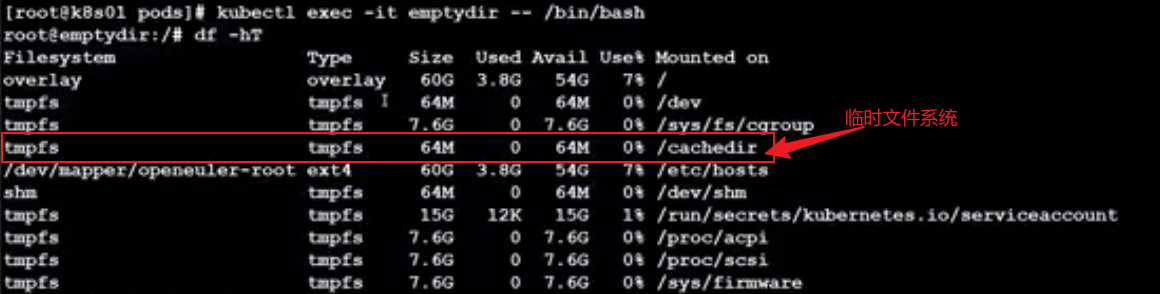
一个pod中,容器的IP地址是公用的,但是他们的存储不是共享的,得有一个共享储存空间,该pod存储的内容不需要持久化,只维持pod的整个生命周期,则可以使用emptydir类型的临时存储。
(二)控制器
1.deployment(无状态集)
replicaset
(1)支持pod的多副本,通过标签监视pod副本的状态
replicas:5
selector:
matchLabels:
app: webserver
name: webserver(2)支持pod的更新策略(删除pod再更新)
重建:删除现有的所有pod,再创建新的(会造成服务中断),在有且只有一个pod的场景可以使用这个策略
滚动更新:在多副本情况下,依次更新pod
先删后建:先删多少再创建多少
先创建再删除:先创建多少再删多少
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: #先建后删
maxUnavaliable: #先删后建(3)能通过控制器校正pod状态
(4)要求pod完全无状态(删除、更新都是无顺序的)
(5)支持共享卷
2.statefulset(有状态集)
(1)相对于deployment,statefulset创建的pod都有唯一名称
(2)支持多副本
(3)支持pod的更新策略
为了保证pod状态,pod多副本的情况下,串行启动保证。(删一个创建一个)
(4)支持持久存储的多副本
3.daemonset
(1)确保每一个节点都会运行一个副本,而且有且只有一个副本
(2)更新:一个节点一个节点的更新,总是先删除再创建
应用场景:比如监控的agent、kube-proxy、calico等
二、K8s的调度器(与container同级)
注意:pod状态若为pending,一定是标签选择器有问题。
kube-scheduler:调度器组件
内置调度器:default-scheduler
多种调度策略:
1、预选:排除不满足条件节点(可在该阶段完成干预调度:让我们要调度的节点才满足条件,其他节点都不满足)
干预调度方法:
①nodeSelector标签选择器:
(1)编写yaml文件,定义容器的nodeSelector调度到哪些标签上
(2)为指定节点打标签,并指定pod运行在带特定标签的节点上。
若定义多个标签,则需全部满足才会调度到对应节点;
nodeSelector:
disk:ssd
app:test若一个pod已经运行于该节点,此时节点标签发生变化,pod不会重新调度;
若一个pod已经运行于该节点,pod的标签选择器发生变化,则会重新调度;
②污点和容忍
污点:默认任何pod都不会运行到带有污点的节点上。
kubectl taint node node名 (污点标签)键=值:级别 #给节点打污点
kubectl taint node node名 (污点标签)键=值:级别- #取消节点打污点
查看污点只能describe节点
相同的标签,不同的effect,是增加污点。级别effect:
PreferNoSchedule:尽可能不调度;如果在调度后有了满足条件的节点,pod不会被重新调度,直至生命周期结束。
NoSchedule:不调度;已经运行于其上的pod不会被重新调度,直至生命周期结束。
NoExecute:不调度,已经运行于其上的pod会被直接驱逐,状态为pending。污点的等级优于标签选择器
容忍:只有能够容忍污点的pod才能运行到该节点上;如果一个节点有多个污点,pod需要能够容忍所有的污点才能在其节点上运行;即使一个pod能够容忍所有的污点,也不一定运行到带有这些污点的节点上。
tolerations:
- key: xx #污点的键
operator: Equal/Exsists
value: yy #污点的值
effect: NoSchedule #污点的级别
#容忍所有污点(比如网络插件)
tolerations:
operator: Exists这三个副本会运行在标签选择器为disk=ssd、app=test的节点上。(污点容忍和标签选择器配合使用)
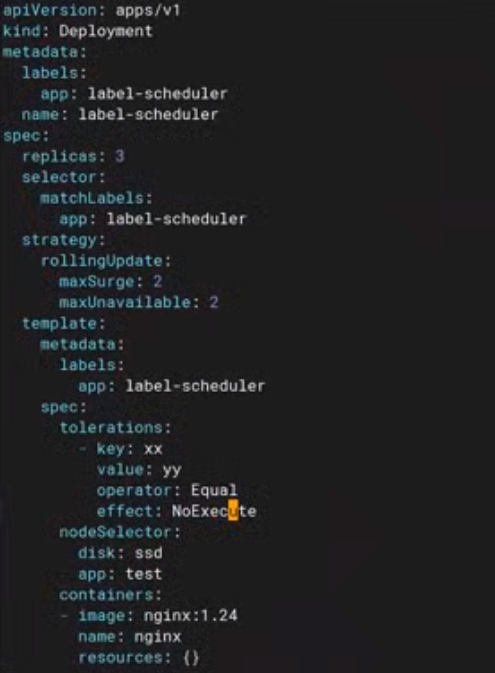
③指定节点调度:
nodeName: "节点名称"
④节点亲和性(node)
将pod运行在带有特定标签的节点上,支持对标签选择更多的条件
硬策略:必须满足的条件
软策略:尽可能满足的条件
⑤pod亲和性和反亲和性
pod亲和性:不能调度到该节点上
pod反亲和性:尽可能不调度到该节点上
⑥拓扑分布式约束
跨区容灾

2、优选:对满足条件的节点进行打分
3、终选:基于分数做排序,选择最优节点
第三方调度:
valcano:火山调度 (要成功 全成功;失败全失败)
DeScheduler:基于真实负载,做可预测调度