1. 简介
在执行救援任务时,如何尽快找到运动中的失踪目标是一个极具价值且值得深入探讨的研究课题。为在不同先验知识和干扰强度下优化无人机搜索运动失目标的飞行路径,本文提出了一种名为"融合迁移学习与丢弃机制的神经网络算法"的创新优化技术,该算法是受人工神经网络启发的神经网络算法的一种改进变体。为提升神经网络算法的全局搜索能力和收敛性能,算法引入了多重迁移机制、广义平均迁移位置,以及受迁移学习与丢弃法原理驱动的随机丢弃算子。
2. 问题描述
如文献所述,构建使用无人机搜索移动目标的问题需要目标模型、传感器模型和概率图模型。下面,根据相关文献,首先介绍这三个模型,然后定义目标函数。
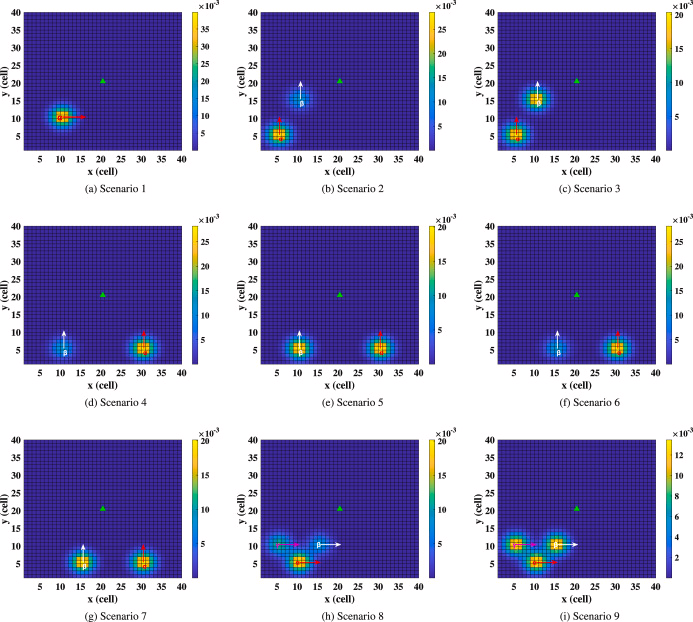
2.1. 目标模型
目标模型用于描述目标的移动特征。一种常用方法是根据目标的原始信息(例如丢失目标的时间和目标的最后位置)使用概率分布函数对目标位置进行建模。通常,所使用的概率分布函数可以是以目标最后位置为中心的正态分布。然而,当无法获得目标的最后位置时,概率分布函数可以是均匀分布。用hth^tht表示目标在时间ttt的位置,h0h^0h0表示目标的初始位置,b(ht)b(h^t)b(ht)表示时间ttt的概率图,ϕ\phiϕ表示搜索区域。搜索区域ϕ\phiϕ可以离散化为一个由ϕx×ϕy\phi_x \times \phi_yϕx×ϕy个单元格组成的二维网格。每个单元格表示目标在时间ttt的一个可能位置,并具有相应的概率b(ht)b(h^t)b(ht)。如果目标在给定的搜索区域ϕ\phiϕ内,则初始概率图满足以下方程:
∑h0∈ϕb(h0)=1.(1)\sum_{h^0 \in \phi} b(h^0) = 1. \tag{1}h0∈ϕ∑b(h0)=1.(1)
如相关文献所示,在搜索移动目标时,目标的移动可以被视为一个离散时间的马尔可夫过程。也就是说,目标的当前位置仅由目标的先前位置决定。如果目标的初始位置已知,那么整个路径也可以被计算出来。本研究也遵循这种方法。
2.2. 传感器模型
安装在无人机上的传感器执行搜索任务,在时间ttt获得一个观测值ztz^tzt。此外,每次观测都是独立的。由检测算法处理的每次观测有两个可能的结果:检测到目标,用DtD^tDt表示;未检测到目标,用Dˉt\bar{D}^tDˉt表示。注意,如果通过观测ztz^tzt检测到了目标,并不能保证目标就在hth^tht处,原因如下:在执行检测任务时,由于多种因素,如外部环境的干扰和所用算法的检测能力,误检和漏检难以避免。因此,引入观测概率,并由p(zt∣ht)p(z^t | h^t)p(zt∣ht)定义。给定目标位置hth^tht,未检测到的概率可以通过下式获得:
p(Dˉt∣ht)=1−p(Dt∣ht).(2)p(\bar{D}^t | h^t) = 1 - p(D^t | h^t). \tag{2}p(Dˉt∣ht)=1−p(Dt∣ht).(2)
2.3. 概率图模型
如前所述,概率图是所考虑问题的理论基础。当使用概率图搜索目标时,需要解决如何初始化和更新概率图的问题。概率图的初始化方法已在目标模型中说明。概率图的更新机制可以描述如下。一旦给定了初始分布b(h0)b(h^0)b(h0),观测序列z1,z2,...,ztz_1, z_2, \ldots, z_tz1,z2,...,zt可以通过递归贝叶斯估计生成,它包括一个预测阶段和一个更新阶段。根据相关文献,基于递归贝叶斯估计的预测概率图bˉ(ht)\bar{b}(h^t)bˉ(ht)可以表示为:
bˉ(ht)=∑ht−1∈ϕp(ht∣ht−1)b(ht−1).(3)\bar{b}(h^t) = \sum_{h^{t-1} \in \phi} p(h^t | h^{t-1}) b(h^{t-1}). \tag{3}bˉ(ht)=ht−1∈ϕ∑p(ht∣ht−1)b(ht−1).(3)
事实上,b(ht−1)b(h^{t-1})b(ht−1)可以看作是在获得从时间1到时间t−1t-1t−1的观测序列的条件下,目标位于ht−1h^{t-1}ht−1的条件概率。概率图的更新基于预测,可以定义为:
b(ht)=ηtp(zt∣ht)bˉ(ht),(4)b(h^t) = \eta^t p(z^t | h^t) \bar{b}(h^t), \tag{4}b(ht)=ηtp(zt∣ht)bˉ(ht),(4)
ηt=1∑ht∈ϕp(zt∣ht)bˉ(ht),(5)\eta^t = \frac{1}{\sum_{h^t \in \phi} p(z^t | h^t) \bar{b}(h^t)}, \tag{5}ηt=∑ht∈ϕp(zt∣ht)bˉ(ht)1,(5)
其中ηt\eta^tηt是一个归一化因子。式(5)遵循目标在给定搜索区域内的假设。
2.4. 目标函数
此搜索问题的目标是找到具有最大探测移动目标概率的无人机最优飞行路径。目标函数推导如下。
根据式(2)、(3),基于贝叶斯理论,未探测到目标的概率可以通过下式计算:
ρt=∑ht∈ϕp(Dˉt∣ht)bˉ(ht),(6)\rho^t = \sum_{h^t \in \phi} p(\bar{D}^t | h^t) \bar{b}(h^t), \tag{6}ρt=ht∈ϕ∑p(Dˉt∣ht)bˉ(ht),(6)
其中ρt\rho^tρt是在时间ttt未探测到目标的概率。因此,从时间1到时间ttt均未探测到目标的联合概率γt\gamma^tγt可以表示为:
γt=∏k=1tρk.(7)\gamma^t = \prod_{k=1}^t \rho^k. \tag{7}γt=k=1∏tρk.(7)
显然,在时间ttt首次探测到目标的概率PtP^tPt可以描述为:
Pt=γt−1(1−ρt).(8)P^t = \gamma^{t-1} (1 - \rho^t). \tag{8}Pt=γt−1(1−ρt).(8)
从时间1到时间ttt探测到目标的累积概率PctP_c^tPct可以通过下式计算:
Pct=∑k=1tPk=1−γt.(9)P_c^t = \sum_{k=1}^t P^k = 1 - \gamma^t. \tag{9}Pct=k=1∑tPk=1−γt.(9)
基于上述讨论,该搜索问题的目标函数可以写成如下形式:
最大化 F(OL)=∑t=1LPtF(O^L) = \sum_{t=1}^L P^tF(OL)=∑t=1LPt, \tag{10}
其中LLL是搜索周期的长度,OLO^LOL是时间LLL时无人机的飞行路径。因此,搜索时间段tpt_ptp可以表示为:tp=1,2,...,Lt_p = 1, 2, ..., Ltp=1,2,...,L,而OLO^LOL可以表示为OL=o1o2...oLO^L = o^1 o^2 ... o^LOL=o1o2...oL。
3. 预备知识
为了解决第2节中所示的优化问题,本文提出了TLDNNA。TLDNNA是NNA的一个新变体,其改进策略基于迁移学习和丢弃法。因此,在正式介绍TLDNNA之前,首先介绍NNA、迁移学习和丢弃法。
3.1. NNA
近年来,人工神经网络已广泛应用于各个领域,如时间序列预测、特征选择、知识图谱嵌入、车辆防抱死制动系统控制器、社交推荐、患者特定质量保证、水下图像增强和结肠镜检查下的结直肠息肉诊断等。人工神经网络主要有两种类型:如图1(a)所示的前馈神经网络和如图1(b)所示的反馈神经网络。NNA基于反馈神经网络。为了通过使用人工神经网络设计一种基于群体的元启发式算法,NNA的作者做出了以下假设:

- 如图1(b)所示,每个输入都有其自己的输出。
- 每个输入都被视为所解决问题的一个解。
- 每个输入的解决方案和权重由最优输入的解决方案和权重引导。
根据上述假设,NNA通过以下四个组成部分执行优化任务:
3.1.1. 生成试验种群
在执行搜索策略之前需要生成试验种群。在NNA中,生成试验种群的方式可以描述如下。假设Xt={x1t,x2t,...,xNt}X^t = \{x_1^t, x_2^t, ..., x_N^t\}Xt={x1t,x2t,...,xNt}是一个包含NNN个个体的种群。对于一个DDD维问题,个体i(i∈1,N)i (i \in 1, N)i(i∈1,N)可以表示为xit=xi,1t,xi,2t,...,xi,Dtx_i^t = x_{i,1}\^t, x_{i,2}\^t, ..., x_{i,D}\^txit=xi,1t,xi,2t,...,xi,Dt。此外,个体iii有自己的权重向量witw_i^twit,可以表示为wit=wi,1t,wi,2t,...,wi,Ntw_i^t = w_{i,1}\^t, w_{i,2}\^t, ..., w_{i,N}\^twit=wi,1t,wi,2t,...,wi,Nt。种群的权重矩阵WtW^tWt可以表示为Wt={w1t,w2t,...,wNt}W^t = \{w_1^t, w_2^t, ..., w_N^t\}Wt={w1t,w2t,...,wNt}。试验种群可以通过下式计算:
xnew,i,jt=∑k=1Nwi,kt×xk,jt,i∈1,N,j∈1,D,(11)x_{new,i,j}^t = \sum_{k=1}^{N} w_{i,k}^t \times x_{k,j}^t, \quad i \in 1, N, j \in 1, D, \tag{11}xnew,i,jt=k=1∑Nwi,kt×xk,jt,i∈1,N,j∈1,D,(11)
xnew,it={xnew,i,1t,xnew,i,2t,...,xnew,i,Dt},i∈1,N,(12)x_{new,i}^t = \{x_{new,i,1}^t, x_{new,i,2}^t, ..., x_{new,i,D}^t\}, \quad i \in 1, N, \tag{12}xnew,it={xnew,i,1t,xnew,i,2t,...,xnew,i,Dt},i∈1,N,(12)
其中xnew,itx_{new,i}^txnew,it是个体iii的试验个体。因此,试验种群XnewtX_{new}^tXnewt可以表示为Xnewt={xnew,1t,xnew,2t,...,xnew,Nt}X_{new}^t = \{x_{new,1}^t, x_{new,2}^t, ..., x_{new,N}^t\}Xnewt={xnew,1t,xnew,2t,...,xnew,Nt}。注意,witw_i^twit应满足以下公式:
∑k=1Nwi,kt=1,0<wi,kt<1,i∈1,N,k∈1,N.(13)\sum_{k=1}^{N} w_{i,k}^t = 1, \quad 0 < w_{i,k}^t < 1, \quad i \in 1, N, k \in 1, N. \tag{13}k=1∑Nwi,kt=1,0<wi,kt<1,i∈1,N,k∈1,N.(13)
3.1.2. 更新权重矩阵
在每个循环中,WtW^tWt通过下式更新:
wit+1=∣wit+2⋅λ1⋅(wbestt−wit)∣,i∈1,N,(14)w_i^{t+1} = |w_i^t + 2 \cdot \lambda_1 \cdot (w_{best}^t - w_i^t)|, \quad i \in 1, N, \tag{14}wit+1=∣wit+2⋅λ1⋅(wbestt−wit)∣,i∈1,N,(14)
其中λ1\lambda_1λ1是一个在0和1之间均匀分布的随机数,wbesttw_{best}^twbestt是所获得的最优个体的权重向量。如果所获得的最优个体xbesttx_{best}^txbestt等于xbt(b∈1,N)x_b^t (b \in 1, N)xbt(b∈1,N),那么wbesttw_{best}^twbestt等于wbtw_b^twbt。
3.1.3. 偏置算子
NNA中的偏置算子受到人工神经网络中偏置电流的启发。偏置电流的作用是使每个神经元的输出尊重周围的条件。在NNA中,偏置算子对试验种群和权重矩阵进行局部调整,这有助于增加种群多样性并增强NNA摆脱局部最优解的能力。此外,种群的偏置比例由修正因子δt\delta^tδt控制,该因子可以通过下式更新:
δt+1=0.99⋅δt.(15)\delta^{t+1} = 0.99 \cdot \delta^t. \tag{15}δt+1=0.99⋅δt.(15)
如果个体iii被选中执行偏置算子,则xnew,itx_{new,i}^txnew,it中的δt⋅D\delta^t \cdot Dδt⋅D个变量将根据变量的上限和下限随机生成的变量替换,WtW^tWt中的δt⋅N\delta^t \cdot Nδt⋅N个权重向量将根据0和1之间均匀分布随机生成的变量替换。
3.1.4. 转移算子
转移算子是将个体转移到更好的位置,可以表示为:
xit+1=xnew,it+2⋅λ2⋅(xbestt−xnew,it),i∈1,N,(16)x_i^{t+1} = x_{new,i}^t + 2 \cdot \lambda_2 \cdot (x_{best}^t - x_{new,i}^t), \quad i \in 1, N, \tag{16}xit+1=xnew,it+2⋅λ2⋅(xbestt−xnew,it),i∈1,N,(16)
其中λ2\lambda_2λ2是一个在0和1之间均匀分布的随机数。此外,NNA通过下式初始化:
xi,j0=lj+(uj−lj)⋅λ3,i∈1,N,j∈1,D,(17)x_{i,j}^0 = l_j + (u_j - l_j) \cdot \lambda_3, \quad i \in 1, N, j \in 1, D, \tag{17}xi,j0=lj+(uj−lj)⋅λ3,i∈1,N,j∈1,D,(17)
其中λ3\lambda_3λ3是一个在0和1之间均匀分布的随机数,ljl_jlj是第jjj个变量的下限,uju_juj是第jjj个变量的上限。算法1展示了NNA的伪代码。
算法 1 NNA的伪代码
1: 通过式(13)和式(17)分别初始化 W^0 和 X^0;
2: 评估种群 X^0 并选择 x_{best}^0 和 w_{best}^0;
3: while 停止条件=false do
4: 通过式(11)和式(12)生成 X_{new}^t,并通过式(13)和式(14)更新 W^{t+1};
5: for each i ∈ [1, N] do
6: if rand < δ^t then
7: 对 x_{new,i}^t 和 W^{t+1} 执行偏置算子
8: else
9: 通过式(16)对 x_{new,i}^t 执行转移算子
10: end if
11: end for
12: 通过式(15)生成 δ^{t+1};
13: 评估种群 X^{t+1} 并选择 x_{best}^{t+1} 和 w_{best}^{t+1};
14: end while3.2. 迁移学习
迁移学习是一种非常经典的机器学习方法。迁移学习的基本思想如下:利用先前获得的知识可以帮助提高解决类似问题的计算效率。
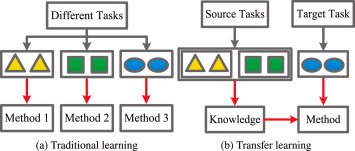
图2显示了迁移学习和传统学习之间的区别。从图2(a)可以看出,三个任务有三个不同的学习系统。在传统学习中,不同的任务是相互独立的。此外,在传统学习中,训练数据和测试数据的领域是相同的。然而,在迁移学习中,训练数据和测试数据的领域可能不同。如图2(b)所示,目标任务是基于其学习系统和来自其他两个源任务的知识来执行的。也就是说,与传统学习相比,迁移学习更关注任务之间的关系。迁移学习的有效性已被证实。
3.3. 丢弃法
作为著名且强大的机器学习系统,深度神经网络近年来发展迅速,并已被用于各种工程领域。然而,深度神经网络面临着过拟合的挑战。为了防止过拟合,有学者提出了丢弃法,其基本思想如下:在训练过程中,以一定的概率随机从原始网络中丢弃一些神经元,这些神经元连同它们所有的输入连接和输出连接被暂时从原始网络中移除。
应用丢弃法技术的一个简单例子如图3所示。从图3(a)可以看出,在应用丢弃法技术之前,神经网络是一个全连接神经网络。通过观察图3(b),在应用丢弃法技术之后,输入层、第一个隐藏层和第二个隐藏层分别丢弃了一个神经元、两个神经元和一个神经元。显然,图3(b)中的神经网络比图3(a)中的神经网络具有更高的计算效率。丢弃法的特点如下:
- 它可以在一定程度上防止网络过拟合。
- 它增加了总时间,但可以减少每次训练的时间。
- 它可以降低网络对神经元权重的敏感性。
基于这些特点,丢弃法已广泛应用于神经网络中。

4. TLDNNA
4.1. TLDNNA 的框架
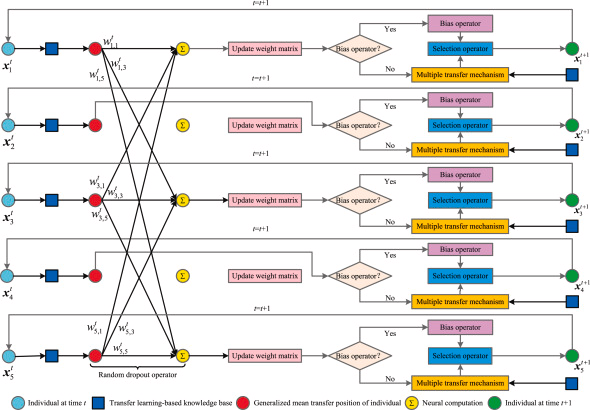
该框架通过一个由五个个体组成的种群进行说明。从图 4 可以看出,TLDNNA 的基本思想可以描述如下。
首先,每个个体通过构建的基于迁移学习的知识库被转移到其广义均值位置。然后,通过构建的随机丢弃算子将整个种群划分为两个子种群。从图 4 可以看出,第一个个体、第三个个体和第五个个体组成一个无丢弃子种群,而由其余两个个体组成一个有丢弃子种群。接下来,无丢弃子种群中的个体根据偏置条件,直接通过偏置算子或基于迁移学习知识库设计的多重转移机制进行优化。然后在完成选择算子后确定它们的下一代。对于有丢弃子种群中的个体,它们首先通过基于权重矩阵的神经计算获得相应的试验个体,然后更新它们的权重向量。最后,试验个体根据偏置条件,在构建的基于迁移学习的知识库辅助下执行偏置算子或多重转移机制。然后通过执行选择算子获得它们的下一代。
基于迁移学习的知识库、多重转移机制、广义均值转移位置和随机丢弃算子是我们的主要贡献
4.2. 基于迁移学习的知识库
迁移学习的基本原理是先前获得的知识对于解决类似问题非常重要。受此原理启发,我们创建了一个基于迁移学习的知识库,用于设计广义均值转移机制和由三个转移算子组成的多重转移机制,以提高 NNA 的优化性能。在 TLBKB 中,知识是具有竞争力解的有前途的个体。这可以解释如下。当使用基于种群的优化算法来解决问题时,具有更好适应度值的个体有更多机会获得全局最优解。也就是说,一个更好的解意味着该解的邻域包含更多关于全局最优解的有价值信息。
创建的 TLBKB 由两个精英档案组成,即局部精英档案和全局精英档案。局部精英档案 PtP^tPt 用于保存所有个体的历史最优解,包含 NNN 个解。假设个体 iii 在时间 ttt 的历史最优解表示为 pitp_i^tpit,则 PtP^tPt 可以写成 Pt={p1t,p2t,...,pNt}P^t = \{p_1^t, p_2^t, ..., p_N^t\}Pt={p1t,p2t,...,pNt}。因此,PtP^tPt 可以通过 P0={p10,p20,...,pN0}P^0 = \{p_1^0, p_2^0, ..., p_N^0\}P0={p10,p20,...,pN0} 初始化。全局精英档案用于保存整个种群的历史最优解,其最大保存解数设置为 NNN。假设全局精英档案表示为 GtG^tGt,其保存的解数为 L(1≤L≤N)L (1 \le L \le N)L(1≤L≤N),则 GtG^tGt 可以写成 Gt={g1t,g2t,...,gLt}G^t = \{g_1^t, g_2^t, ..., g_L^t\}Gt={g1t,g2t,...,gLt}。在这项工作中,GtG^tGt 通过 G0={xbest0}G^0 = \{x_{best}^0\}G0={xbest0} 初始化。此外,GtG^tGt 的更新方法可以描述如下。完成第 ttt 次循环后,得到 xbesttx_{best}^txbestt。如果 LLL 小于 NNN,则 xbesttx_{best}^txbestt 直接添加到 GtG^tGt 中;否则,从 GtG^tGt 中随机选择两个解,并用 xbesttx_{best}^txbestt 替换其中较差的解。
下面,介绍基于 TLBKB 的广义均值转移位置和多重转移机制。
4.2.1. 广义均值转移位置
种群多样性对于增强基于种群的元启发式算法防止早熟收敛的能力至关重要。注意,随着迭代次数的增加,所有个体都朝向获得的当前最优解移动,种群多样性的丧失是不可避免的。种群的均值位置可以描述整体信息,通常用于提高种群多样性。受此启发,基于 TLBKB 的广义均值转移位置定义为:
Mit=xit+pit+gmt3,i∈1,N,m∈1,L,(18)M_i^t = \frac{x_i^t + p_i^t + g_m^t}{3}, \quad i \in 1, N, m \in 1, L, \tag{18}Mit=3xit+pit+gmt,i∈1,N,m∈1,L,(18)
其中 MitM_i^tMit 是时间 ttt 个体 iii 的广义均值转移位置,gmtg_m^tgmt 是从 GtG^tGt 中随机选择的一个解。从式 (18) 可以看出,广义均值转移位置有两个功能:
- 由于动态特性(gmtg_m^tgmt 在一次循环中是随机选择的),它可以增强个体摆脱局部最优的能力。
- 由于 pitp_i^tpit 和 gmtg_m^tgmt 是具有竞争力的解,它可以加速收敛速度。
4.2.2. 多重转移机制
具有相似行为的搜索算子可能导致种群多样性的丧失。因此,通过设计多种学习策略来更新个体是保持种群多样性的一种可行方法。受此启发,本文设计了一个基于 TLBKB 的、由三种学习策略组成的多重转移机制,可以定义为:
xit+1={xnew,it+2δ1(xbestt−xnew,it)+Eit,if τ≤13xnew,it+2δ2(pit−xnew,it)+Eit,if 13<τ≤23xnew,it+2δ3(gmt−xnew,it)+Eit,otherwise,i∈1,N,(19)x_i^{t+1} = \begin{cases} x_{new,i}^t + 2\delta_1 (x_{best}^t - x_{new,i}^t) + E_i^t, & \text{if } \tau \le \frac{1}{3} \\ x_{new,i}^t + 2\delta_2 (p_i^t - x_{new,i}^t) + E_i^t, & \text{if } \frac{1}{3} < \tau \le \frac{2}{3} \\ x_{new,i}^t + 2\delta_3 (g_m^t - x_{new,i}^t) + E_i^t, & \text{otherwise} \end{cases}, \quad i \in 1, N, \tag{19}xit+1=⎩ ⎨ ⎧xnew,it+2δ1(xbestt−xnew,it)+Eit,xnew,it+2δ2(pit−xnew,it)+Eit,xnew,it+2δ3(gmt−xnew,it)+Eit,if τ≤31if 31<τ≤32otherwise,i∈1,N,(19)
其中 τ\tauτ 是一个在 0 和 1 之间均匀分布的随机数,δ1,δ2,δ3\delta_1, \delta_2, \delta_3δ1,δ2,δ3 是在 0 和 1 之间均匀分布的随机数,gmtg_m^tgmt 是从 GtG^tGt 中随机选择的一个解,EitE_i^tEit 是一个扰动向量。以最小化问题为例,EitE_i^tEit 可以写成:
Eit=2κ(xat−xbt),(20)E_i^t = 2\kappa (x_a^t - x_b^t), \tag{20}Eit=2κ(xat−xbt),(20)
其中 aaa 和 bbb 是 1 到 NNN 之间两个不同的整数,κ\kappaκ 是一个在 0 和 1 之间均匀分布的随机数。
通过观察式 (19),试验个体 iii 可以朝向由 xbesttx_{best}^txbestt、pitp_i^tpit 和 gmtg_m^tgmt 决定的三个不同方向,与式 (17) 所示的单一学习策略相比,这可以为生成 xit+1x_i^{t+1}xit+1 提供更多方式。此外,这三个方向对于获得 xit+1x_i^{t+1}xit+1 具有相同的重要性,并且有相同的机会被执行。此外,与式 (17) 相比,式 (19) 增加了随机扰动向量 EitE_i^tEit。根据式 (20),EitE_i^tEit 可以进一步加强式 (19) 的随机性,这有助于增强 TLDNNA 防止早熟收敛的能力。
4.3. 随机丢弃算子
如图 4 所示,受丢弃法技术启发,设计了一个随机丢弃算子来控制神经计算的输入。这可以表示为:
sit={0,if p<0.5(无丢弃)1,otherwise(丢弃),i∈1,N,(21)s_i^t = \begin{cases} 0, & \text{if } p < 0.5 \quad (\text{无丢弃}) \\ 1, & \text{otherwise} \quad (\text{丢弃}) \end{cases}, \quad i \in 1, N, \tag{21}sit={0,1,if p<0.5(无丢弃)otherwise(丢弃),i∈1,N,(21)
其中 ppp 是一个在 0 和 1 之间均匀分布的随机数,sits_i^tsit 表示个体 iii 的状态。通过执行 (21),种群被划分为无丢弃子种群 Xndt(Xndt={xnd,1t,xnd,2t,...,xnd,Lndt})X_{nd}^t (X_{nd}^t = \{x_{nd,1}^t, x_{nd,2}^t, ..., x_{nd,L_{nd}}^t\})Xndt(Xndt={xnd,1t,xnd,2t,...,xnd,Lndt}) 和有丢弃子种群 Xdt(Xdt={xd,1t,xd,2t,...,xd,Ldt})X_d^t (X_d^t = \{x_{d,1}^t, x_{d,2}^t, ..., x_{d,L_d}^t\})Xdt(Xdt={xd,1t,xd,2t,...,xd,Ldt}),其中 LndL_{nd}Lnd 和 LdL_dLd 分别是 XndtX_{nd}^tXndt 和 XdtX_d^tXdt 的长度。XndtX_{nd}^tXndt 中的个体采用与图 4 中第一、第三和第五个体相同的方法。对于 XdtX_d^tXdt 中的个体,他们采用与图 4 中第二和第四个体相同的方法。从式 (21) 可以看出,随机丢弃算子有三个功能:
- 随机选择丢弃或无丢弃意味着 TLDNNA 中的两种计算框架,可以提高种群多样性。
- 它可以降低计算复杂度。在 NNA 中,所有个体都是神经计算的输入,而在 TLDNNA 中,只有一部分个体参与神经计算。
- 从式 (21) 可以看出,个体在一次循环中执行丢弃的概率是 50%,这意味着随机丢弃算子可以保持 TLDNNA 的稳定性。
基于广义均值转移位置和随机丢弃算子,XndtX_{nd}^tXndt 的试验个体可以通过以下方式获得:
xnew,nd,i,jt=∑k=1Nwi,kt×xk,jt,i∈1,Lnd,j∈1,D,(22)x_{new, nd, i, j}^t = \sum_{k=1}^{N} w_{i,k}^t \times x_{k,j}^t, \quad i \in 1, L_{nd}, j \in 1, D, \tag{22}xnew,nd,i,jt=k=1∑Nwi,kt×xk,jt,i∈1,Lnd,j∈1,D,(22)
xnew,nd,it={xnew,nd,i,1t,xnew,nd,i,2t,...,xnew,nd,i,Dt},i∈1,Lnd,(23)x_{new, nd, i}^t = \{x_{new, nd, i,1}^t, x_{new, nd, i,2}^t, ..., x_{new, nd, i,D}^t\}, \quad i \in 1, L_{nd}, \tag{23}xnew,nd,it={xnew,nd,i,1t,xnew,nd,i,2t,...,xnew,nd,i,Dt},i∈1,Lnd,(23)
其中 FFF 是保存 XndtX_{nd}^tXndt 中个体索引的集合。此外,XndtX_{nd}^tXndt 中个体的权重向量可以通过下式更新:
wit+1=∣wit+2δ(wbestt−wit)∣,i∈1,Lnd,(24)w_i^{t+1} = |w_i^t + 2\delta (w_{best}^t - w_i^t)|, \quad i \in 1, L_{nd}, \tag{24}wit+1=∣wit+2δ(wbestt−wit)∣,i∈1,Lnd,(24)
其中 δ\deltaδ 是一个在 0 和 1 之间均匀分布的随机数。
XdtX_d^tXdt 的试验个体可以通过下式计算:
xnew,d,it=xit,i∈1,Ld,(25)x_{new, d, i}^t = x_i^t, \quad i \in 1, L_d, \tag{25}xnew,d,it=xit,i∈1,Ld,(25)
其中 QQQ 是保存 XdtX_d^tXdt 中个体索引的集合。
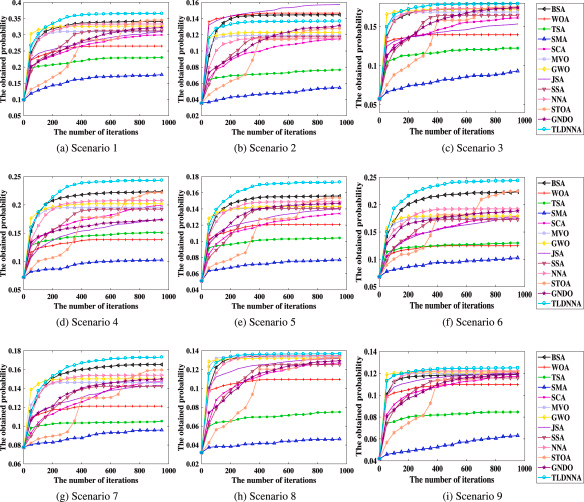
Zhang Y. A neural network algorithm with transfer learning and dropout for moving target search using UAVJ. Knowledge-Based Systems, 2024, 305: 112632. 10.1016/j.knosys.2024.112632