蛮力法(brute force method,也称穷举法或枚举法),是一种简单直接地解决问题的方法 。用蛮力法设计的算法其时间性能往往是最低的,典型的指数时间算法一般都是通过蛮力穷举得到的。
通常来说,蛮力法是最容易应用的方法。
例如,对于给定的整数a和非负整数n,计算的值,最直接最简单的想法就是把1和a相乘,再与a乘n-1次。
依次处理所有元素是蛮力法的关键,应用蛮力法**首先要确定穷举的范围,其次为了避免陷入重复试探,**应保证处理过的元素不再被处理。
由于蛮力法需要依次穷举待处理的元素,因此,用蛮力法设计的算法其时间性能往往是最低的。但是,基于以下原因,蛮力法也是一种重要的算法设计技术。
(1)理论上,蛮力法可以解决可计算领域的各种问题。对于一些基本的问题,例如求一个序列的最大元素,计算n个数的和等,蛮力法是一种常用的算法设计技术。
(2)蛮力法经常用来解决一些较小规模的问题。如果问题的输入规模不大,用蛮力法设计的算法其时间是可以接受的,此时,设计一个更高效算法的代价是不值得的。
(3)对于一些重要的问题(如排序、查找、串匹配),蛮力法可以设计些合理的算法,这些算法具有实用价值,而且不受问题规模的限制。
(4)**蛮力法可以作为某类问题时间性能的下界,**来衡量同样问题的其他算法是否具有更高的效率。
选择排序和冒泡排序
选择排序:
选择排序开始的时候,我们扫描整个列表,找到它的最小元素,然后和第一个元素换,将最小元素放到它在有序表中的最终位置上。然后我们从第二个元素开始扫描列表,找到最后n−1个元素中的最小元素,再和第二个元素交换位置,把第二小的元素放在它的最终位置上。一般来说,在对该列表做第i遍扫描的时候(i的值0⋯n−2),该算法在最后n−i个元素中寻找最小元素,然后拿它和交换。
SelectionSort(A[0..n-1]) //该算法用选择排序对给定的数组排序
//输入:一个可排序数组A[0..n-1]
//输出:升序排列的数组A[0..n-1]
for i←0 to n-2 do
min←i
for j←i+1 to n-1 do
if A[j]<A[min]
min←j
swap A[i] and A[min]效率分析:对于比较次数 ,依赖于数组长度,则有
如果是求交换次数,则
假如给定初始数据:(118,101,105,127,112)
一次排序:101,118,105,127,112
二次排序:101,105,118,127,112
三次排序:101,105,112,127,118
四次排序:101,105,112,118,127
冒泡排序:
比较表中的相邻元素,如果它们是逆序的话就交换它们的位置。重复多次以后,最终,最大的元素就"沉到"列表的最后一个位置。第二遍操作将第二大的元素沉下去。这样一直做,直到n−1遍以后,该列表就排好序了。
BubbleSort(A[O.n-1]) //该算法用冒泡排序对数组A[0..n-1]进行排序
//输入:一个可排序数组A[0..n-1]
//输出:非降序排列的数组A[0..n-1]
for i←0 to n-2 do
for j←0 to n-2-i do
if A[j+1]<A[j]
swap A[j] and A[j+1]效率分析:对于比较次数
当情况最糟糕的时候交换次数S(n)此时和比较次数是一致的
对 3,9,-1,10,20排序:
第一轮排序:
(1)3,9,-1,10,20 ----3跟9比较,不交换
(2)3,-1,9,10,20 ----9比 -1大,所以9跟 -1交换
(3)3,-1,9,10,20 ----9跟10比较,不交换
(4)3,-1,9,10,20 ----10跟20比较,不交换
第一轮过后,将20这个最大的元素固定到了最后的位置
第二轮排序:
因为20的位置已经固定,所以只对前4个进行排序即可:
(1)-1,3,9,10,20 ----3比 -1大,进行交换
(2)-1,3,9,10,20 ----3跟9比较,不交换
(3)-1,3,9,10,20 ----9跟10比较,不交换
第二轮过后,将第二大的元素固定到了倒数第二个位置
第三轮排序:
10和20的位置已经确定,只需对前三个进行排序
(1)-1,3,9,10,20 ----3和-1比较,不交换
(2)-1,3,9,10,20 ----3和9比较,不交换
第三轮过后,将第三大的元素位置确定
第四轮排序:
只对前两个元素进行排序
(1)-1,3,9,10,20 ----3和-1比较,不交换
值得一提的是,当某一次循环中,数组不存在任何交换操作的时候,就可以视为数组有序,从而剪枝,这也是优化冒泡排序的方法
顺序查找和蛮力字符串匹配
顺序查找:
简单地将给定列表中的连续元素和给定的查找键进行比较,直到遇到一个匹配的元素(成功查找),或者在遇到匹配元素前就遍历了整个列表(失败查找)。如果我们把查找键添加到列表的末尾,那么查找就一定会成功,所以不必在算法的每次循环时都检查是否到达了表的末尾。
SequentialSearch2(A[O..n], K) //顺序查找的算法实现,它用了查找键来作限位器
//输入:一个n个元素的数组A和一个查找键K
//输出:第一个值等于 K的元素的位置,如果找不到这样的元素,返回-1
A[n]←K
i←0
while A[i]≠K do // while i<n and A[i]≠K do
i←i+1
if i<n return i
else return -1在原版算法中,每一次while循环都会进行两次比较(越界和查询),改进后只进行一次比较。虽然只是减少了一次比较,但对于算法的执行效率仍有不少提升。
蛮力字符串匹配:
给定一个n个字符组成的串(文本),一个m个字符的串(模式),从文本中寻找匹配模式的子串。更精确地说,我们求的是i,也即文本中第一个匹配子串最左元素的下标,使得
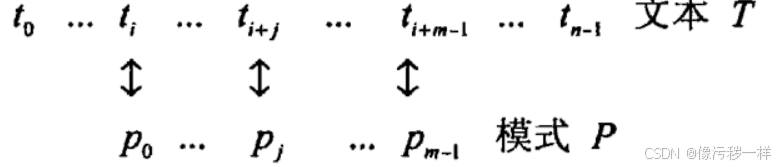
BruteForceStringMatch(T[0..n-1],P[0..m-1]) // 该算法实现了蛮力字符串匹配
// 输入:一个n个字符的数组T[0..n-1],代表一段文本
// 一个m个字符的数组P[0..m-1],代表一个模式
// 输出:如果查找成功,返回文本的第一个匹配子串中第一个字符的位置,
// 否则返回-1
for i←0 to n-m do
j←0
while j<m and P[j]=T[i+j] do
j←j+1
if j=m return i
return -1效率分析:
比较次数C(m,n)同时依赖文本的规模和模式的规模,在最差情况下需要移动n−m+1次模式串且每次移动都遍历模式,
例子如下:
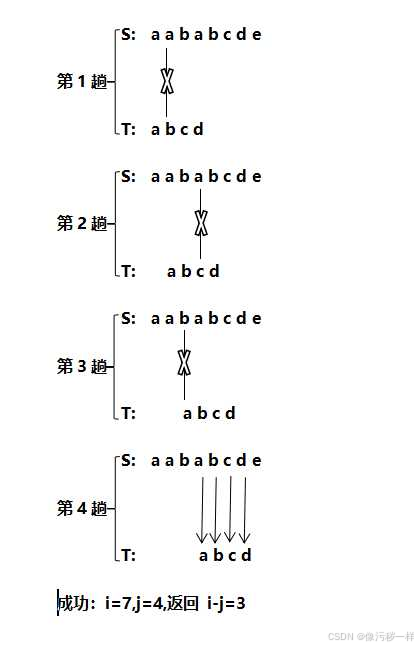
最近对问题和凸包问题:
最近对问题:
要求在一个包含n个点的集合中,找出距离最近的两个点。任意给定两点和
,它们之间的欧几里得距离表示为
BruteForceClosestPoints(p) // 使用蛮力算法求平面中距离最近的两点
// 输入:一个n(n>2)个点的列表p,p1=(x1,y1),...,pn=(xn,yn)
// 输出:两个最近点的距离
d←∞
for i←1 to n-1 do
for j←i+1 to n do
d←min(d,sqrt((xi-xj)^2+(yi-yj)^2)) //sqrt是平方根函数
return d效率分析:平方根操作的规律依赖于点集的规模,即,算法中,平方根操作非常耗时,而对于比较两点间距离这个要求来说,即便不开根号也是能够实现的,因此直接比较平方就更有效率:
凸包问题:
定义对于平面上的一个点集合(有限的或无限的),如果以集合中任意两点p和q为端点的线段都属于该集合,我们说这个集合是凸的。现在可以介绍凸包的概念了。对于平面上n个点的集合,它的凸包就是包含所有这些点(或者在内部,或者在边界上)的最小凸多边形。
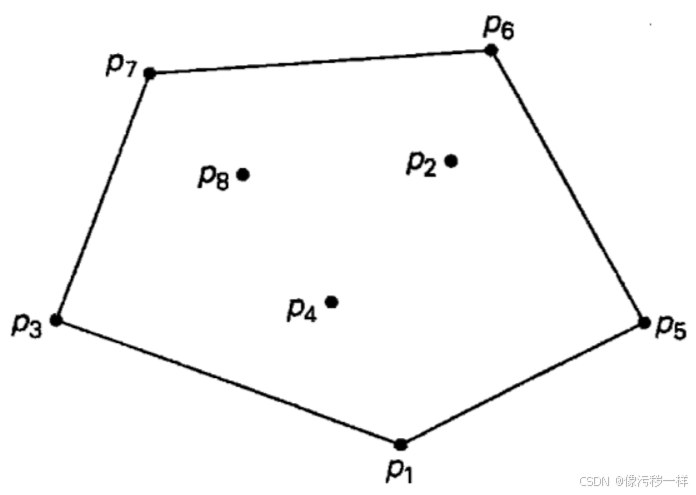
定理:
任意包含n>2个点(不共线的点)的集合S的凸包是以S中的某些点为顶点的凸多边形(如果所有的点都位于一条直线上,多边形退化为一条线段,但它的两个端点仍然包含在S中),这些顶点被称为"极点"。
由于线段构成了凸包的边界 ,对于一个n个点集合中的两个点和
,当且仅当该集合中的其他点都位于穿过这两点的直线的同一边时,它们的连线是该集合凸包边界的一部分。对每一对点都做一遍检验之后,满足条件的线段构成了该凸包的边界。
对于一条直线ax+by=c(其中 、
、
),它将一个平面分为两个半平面,其中一个半平面中的点都满足ax+by>c,另一个半平面中的点都满足ax+by<c。
ConvexSet(p) // 使用蛮力法求解凸包的极点
// 输入:一个n(n>2)个点的列表p,p1=(x1,y1),...,pn=(xn,yn)
// 输出:一个由极点构成的集合q
q←() // 初始化空集合,用于存储凸包极点
j←1 // 第二个点的索引(和i配对的点)
for i←1 to n // 遍历每个点pi(作为直线的第一个端点)
while j<=n and j≠i // 遍历每个点pj(作为直线的第二个端点,j≠i避免自己和自己配对)
s←0 // s记录"除pi、pj外的第一个点"相对于直线pi-pj的位置符号
flag←1 // 标记:是否是第一个判断的点(k≠i,j)
// 计算直线pi-pj的一般式 ax + by + c = 0 的系数
a←yj - yi // 直线pi-pj的一般式系数a = yj - yi
b←xi - xj // 直线pi-pj的一般式系数b = xi - xj
c←xi*yj - xj*yi // 直线pi-pj的一般式系数c = xi*yj - xj*yi
k←1 // 遍历所有其他点pk(判断pk在直线pi-pj的哪一侧)
while k<=n and k≠i and k≠j // 跳过pi和pj本身,检查所有其他点
if flag=1 // 第一次判断点pk(还没确定参考符号)
// sign()是符号函数:返回1(正)、-1(负)、0(在直线上)
s←sign(a*xk + b*yk - c) // 记录第一个点的位置符号
flag←0 // 标记:已确定参考符号
else
// 检查当前点pk的符号是否和s不一致,且pk不在直线上
if s≠sign(a*xk + b*yk - c) and sign(a*xk + b*yk - c)≠0
break // 有點在直線另一側 → 直線pi-pj不是凸包邊,跳出循环
k←k+1 // 检查下一个点
// 循环结束后:如果k>n,说明所有点都在直线pi-pj的同一侧(或直线上)
if k>n
add pi to q // pi是凸包极点,加入集合
add pj to q // pj是凸包极点,加入集合
j←j+1 // 换下一个pj和pi配对
return q // 返回所有凸包极点效率分析:比较次数依赖于点集数量的规模,因此对于n个点组成条直线,需要比较剩下的n-2个点,也就是
穷举查找
旅行商问题:
要求找出一条n个给定的城市间的最短路径,使我们在回到出发的城市之前,对每个城市都只访问一次。这个问题可以很方便地用加权图来建模,也就是说,用图的顶点代表城市,用边的权重表示城市间的距离。这样该问题就可以表述为求一个图的最短哈密顿回路问题。很容易看出来,哈密顿回路也可以定义为n+1个相邻顶点 、
、⋯、
、
的一个序列,其中序列的第一个顶点和最后一个顶点是相同的,而其他n−1个顶点都是互不相同的。不失一般性的前提下,可以假设所有的回路都开始和结束于相同的特定顶点。因此,可以通过生成n-1个中间城市的组合来得到所有的旅行线路,计算这些线路的长度,然后求得最短的线路。

效率分析:
n−1个顶点的所有组合共有个(单方向),需要计算同样次数的权重和。
背包问题:
这是计算机科学中另一个著名的问题。给定n个重量为 、
、⋯、
价值为
、
、⋯、
的物品和一个承重为W的背包,求这些物品中一个最有价值的子集,并且要能够装到背包中。用穷举法解决这一问题需列举出所有物品的组合(物品的子集),分别计算他们的总重量和总价值并进行判断。

效率分析:
n个元素构成集合的子集个数为 (每个元素有取和不取两种状态),需要计算同样次数的总重量和总价值。
NP问题
NP问题指的是目前没有已知的效率可以用多项式来表示的算法(Non-Polynomial)。旅行商问题和背包问题就是其中的两个经典例子,一些方法可以在优于指数级的效率下解决这些问题。
分配问题:
有n个任务需要分配给n个人执行,一个任务对应一个人。对于每一对i,j=1,2,⋯,n来说,将第j个任务分配给第i个人的成本是,该问题要找出总成本最小的分配方案。

我们可以用一个n维元组来描述分配问题的一个可能的解,其中第i个分量(i=1,⋯,n)表示的是在第i行中选择的列号(也就是说,给第i个人分配的任务号)。

效率分析:n个元素构成的排列有n!个,需要计算同样次数的成本并进行比较。
深度优先查找和广度优先查找
深度优先查找
DFS(G)
//实现给定图的深度优先查找遍历
//输入:图G=<V,E>
//输出:图G的顶点,按照被DFS遍历第一次访问到的先后次序,用连续的整数标记 将V中的每个顶点标记为0,表示还"未访问"
count←0
for each vertex v in V do
if v is marked with 0
dfs (v)
dfs(v)
//递归访问所有和v相连接的未访问顶点,然后按照全局变量count的值
//根据遇到它们的先后顺序,给它们赋上相应的数字
count←count+1;
mark v with count
for each vertex w in V adjacent to v do
if w is marked with 0
dfs(w)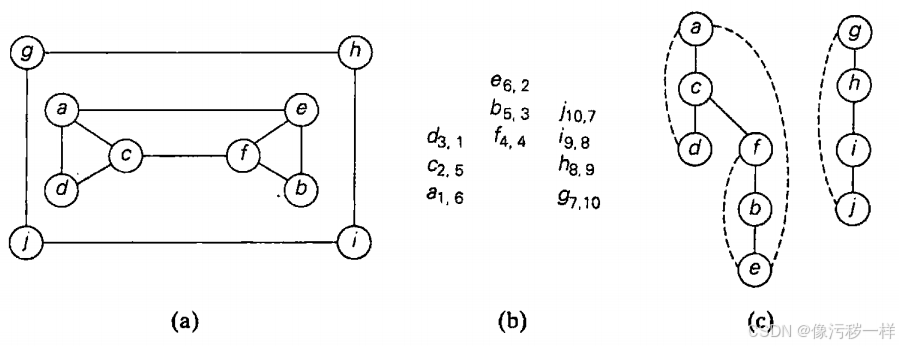
DFS重要的基本应用包括检查图的连通性和无环性,除此之外还可以用来求关节点(如果从图中移走一个节点和所有它附带的边之后,图被分为若干个不相交的部分,我们说这样的节点是图的关节点)。
连通性:DFS在访问了所有和初始顶点有路径相连的顶点之后就会停下来,所以我们可以这样检查判断:从任意一个节点开始DFS遍历,在该算法停下来以后,检查一下是否所有的顶点都被访问过了。如果都访问过了,那么这个图是连通的;否则,它是不连通的。再推广一步,我们可以用DFS来找到一个图的连通分量(一次 DFS = 一个连通分量,多次 DFS = 所有连通分量)。
无环性:如果要检查一个图中是否包含回路,我们可以利用图的DFS森林形式的表示法。如果DFS森林不包含回边,这个图显然是无回路的。如果从某些节点u到它的祖先v之间有一条回边,则该图有一个回路,这个回路是由DFS森林中从u到v的路径上的一系列树向边以及从u到v的回边构成的,当遍历时遇到已经访问的节点且该节点不为当前节点的父节点(直接前驱)的时候存在回路(遍历时需要标记当前节点的前一个结点)。
效率分析:所有顶点和所有边均被访问一次,对邻接矩阵来说,时间效率属于Θ( );对邻接表来说,时间效率属于Θ(∣V∣+∣E∣)。
广度优先查找:
BFS(G)
// 实现给定图的广度优先查找遍历
// 输入:图G=<V,E>
// 输出:图G的顶点,按照被BFS遍历访问到的先后次序,用连续的整数标记 将V中的每个顶点标记为0,表示还"未访问"
count←0
for each vertex vin Vdo
if v is marked with 0
bfs(v)
bfs(v)
// 访问所有和v相连接的未访问顶点,然后按照全局变量count的值
// 根据访问它们的先后顺序,给它们赋上相应的数字
count←count+1;
mark v with count and initialize a queue with v
while the queue is not empty do
for each vertex w in V adjacent to the front vertex do
if w is marked with 0
count←count+1;
mark w with count
add w to the queue
remove the front vertex from the queue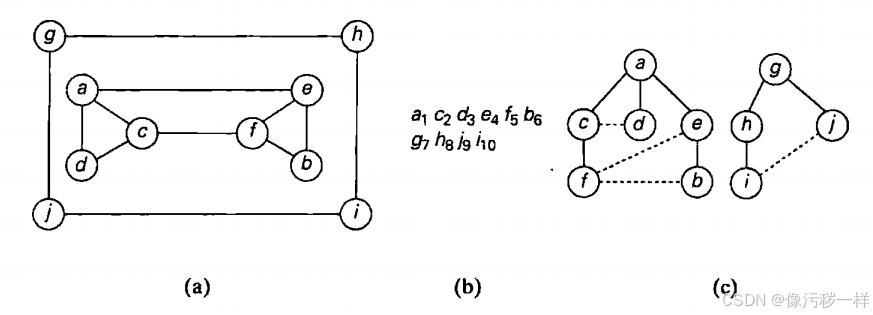
可以用BFS来检查图的连通性和无环性,做法在本质上和DFS是一样的。BFS不能解决关节点问题,但可以用来处理一些DFS无法处理的情况。
例如,BFS可以用来求两个给定顶点间边的数量最少的路径(最短路径)。
效率分析:
所有顶点和所有边均被访问一次,对邻接矩阵来说,时间效率属于Θ( );对邻接表来说,时间效率属于Θ(∣V∣+∣E∣)。