这一节的目标很明确:不用 nn.Linear、不用 CrossEntropyLoss、不用 optim ,只用张量运算 + autograd 手写出 Softmax 回归在 Fashion-MNIST 上的训练闭环。
你会把整个链条彻底跑通:
数据 → 线性层(手写)→ softmax(手写)→ 交叉熵(手写)→ SGD(手写)→ accuracy
1. 准备数据:Fashion-MNIST + DataLoader
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
batch_size = 256
trans = transforms.ToTensor()
train_dataset = datasets.FashionMNIST(root="./data", train=True, download=True, transform=trans)
test_dataset = datasets.FashionMNIST(root="./data", train=False, download=True, transform=trans)
# Windows 如果卡住,把 num_workers 改成 0
train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
test_iter = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)2. 初始化参数:W、b(这是"模型"本体)

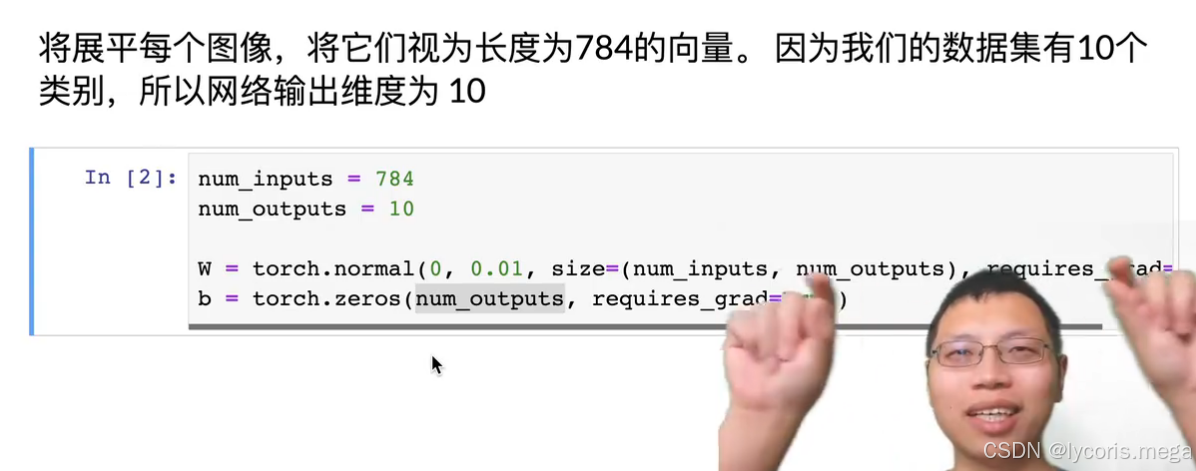
num_inputs = 28 * 28
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)3. 手写 softmax(数值稳定版)
def softmax(X):
X_shift = X - X.max(dim=1, keepdim=True).values # 防止 exp 溢出
exp = torch.exp(X_shift)
return exp / exp.sum(dim=1, keepdim=True)输入 X 的形状应为 (batch, 10),输出是每行和为 1 的概率。
4. 定义模型:把图片拉直 + 线性变换 + softmax
def net(X):
X = X.reshape((-1, num_inputs)) # (N,1,28,28) -> (N,784)
logits = X @ W + b # (N,10)
return softmax(logits)注意:这里我们返回的是概率。后面你会看到:工程上更推荐直接返回 logits,然后用稳定版 CE。
5. 手写交叉熵损失(Cross Entropy)
真实标签 y 是 (N,) 的整数类别索引。
交叉熵: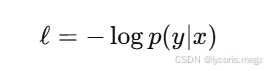
实现技巧:直接用索引取出每个样本的正确类概率。
def cross_entropy(y_hat, y):
# y_hat: (N,10) 概率; y: (N,) 类别索引
return -torch.log(y_hat[torch.arange(y_hat.shape[0]), y])6. 计算准确率 accuracy(分类必须看指标)
def accuracy(y_hat, y):
# y_hat: (N,10) 概率
pred = y_hat.argmax(dim=1)
return (pred == y).float().sum().item()7. 手写 SGD(别忘了 no_grad + 清梯度)
def sgd(params, lr, batch_size):
with torch.no_grad():
for p in params:
p -= lr * p.grad / batch_size
p.grad.zero_()8. 训练与评估循环(完整闭环)
def evaluate_accuracy(data_iter):
total_correct, total_num = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
total_correct += accuracy(net(X), y)
total_num += y.numel()
return total_correct / total_num
lr = 0.1
num_epochs = 10
for epoch in range(num_epochs):
total_loss, total_correct, total_num = 0.0, 0.0, 0
for X, y in train_iter:
y_hat = net(X)
l = cross_entropy(y_hat, y) # (batch,)
l_sum = l.sum()
l_sum.backward()
sgd([W, b], lr, batch_size=X.shape[0])
total_loss += l.sum().item()
total_correct += accuracy(y_hat, y)
total_num += y.numel()
train_loss = total_loss / total_num
train_acc = total_correct / total_num
test_acc = evaluate_accuracy(test_iter)
print(f"epoch {epoch+1}: loss {train_loss:.4f}, train acc {train_acc:.4f}, test acc {test_acc:.4f}")你通常会看到 test acc 在 0.80 左右(取决于 lr、epoch、实现细节),这就说明从零实现的 Softmax 回归是正确的。
9. 这一节最容易踩的坑(务必写进博客)
-
忘记把图像拉直
X.reshape((-1, 784))必须有,否则X @ W会报维度错。 -
log(0) 导致 NaN
如果
y_hat里出现 0,-log(0)=inf。解决:softmax 做稳定 + 也可加
1e-12:return -torch.log(y_hat[torch.arange(y_hat.shape[0]), y] + 1e-12)
-
梯度累加忘了清零
手写 SGD 里必须
p.grad.zero_()。 -
学习率过大
Softmax 回归对 lr 很敏感,loss 震荡就降 lr。
-
只看 loss 不看 acc
分类要看 acc(或 F1),不然你不知道模型到底有没有学会。
10. 小结:你从零实现到底学到了什么?
-
Softmax 回归的本质:线性层输出 logits,再归一化为概率
-
交叉熵的本质:最大化正确类概率(最大似然)
-
训练闭环:forward → loss → backward → SGD update → metric