文章目录
- [ClaudeCode×Elasticsearch:服务日志查询的 AI 化落地实践](#ClaudeCode×Elasticsearch:服务日志查询的 AI 化落地实践)
- 一、思路来源与ClaudeCode本文应用
-
- [1.1 整体思路来源](#1.1 整体思路来源)
- [1.2 ClaudeCode本文核心应用](#1.2 ClaudeCode本文核心应用)
- [二、ClaudeCode在WSL Ubuntu系统的安装](#二、ClaudeCode在WSL Ubuntu系统的安装)
-
- [2.1 安装前准备](#2.1 安装前准备)
- [2.2 具体安装步骤](#2.2 具体安装步骤)
- 三、Elasticsearch的Skills编写
-
- [3.1 Skills编写整体思路与架构设计](#3.1 Skills编写整体思路与架构设计)
- [3.2 Skills核心内容展示与护栏配置](#3.2 Skills核心内容展示与护栏配置)
-
- [3.2.1 注入纯净的环境上下文](#3.2.1 注入纯净的环境上下文)
- [3.2.2 强制的"字段映射与粒度约束"](#3.2.2 强制的“字段映射与粒度约束”)
- [3.2.3 "红线"操作规范](#3.2.3 “红线”操作规范)
- [3.2.4 "红线"操作规范](#3.2.4 “红线”操作规范)
- [3.3 体验 AI 的"性能最优解"](#3.3 体验 AI 的“性能最优解”)
- 四、日志采集架构与AI联动
-
- [4.1 整体采集架构思路](#4.1 整体采集架构思路)
- [4.2 Agent Skills编写与采集流程的结合](#4.2 Agent Skills编写与采集流程的结合)
- 五、结尾
- 五、结尾
ClaudeCode×Elasticsearch:服务日志查询的 AI 化落地实践
一、思路来源与ClaudeCode本文应用
1.1 整体思路来源
正如我公众号第一篇文章,方案的灵感来源于运维场景的实际需求与 AI 技术的快速发展,OpenCode、Claude Code、Cursor 本质都是代码开发工具,最初并非为运维场景设计;
在实际开发与运维工作中,我们常年面临分布式系统日志管理的核心痛点,这也是本次方案思路的核心来源。
真正耗时的,从来不是"看见日志",而是在海量日志里把有用信息捞出来,再把它们拼成结论。而这件事,恰恰是开发和运维在日常排障里最痛、最烦、也最容易出错的一环。传统 Elasticsearch 查询依赖 DSL,Kibana 又离不开 KQL,语法门槛高,分析链路长,遇到复杂问题时,排查效率和沟通成本都会迅速上升。
所以我在想:
既然 ClaudeCode 已经具备自然语言理解、命令生成和执行能力,那能不能把它真正接进运维场景里,让它帮我查 Elasticsearch、读日志、做初步分析?

答案是可以,但前提不是"直接把 ES 地址丢给 AI"。
因为一旦没有约束,AI 很可能为了查一个 404,直接生成全字段扫描、没有时间边界、没有字段约束的低效查询,轻则返回一堆无效结果,重则把 Elasticsearch 集群拖到高负载。也就是说,AI 想在运维里真正可用,靠的不是模型自己变聪明,而是要有人提前给它立规矩、画边界、喂业务上下文。
于是,我做了这次实践:
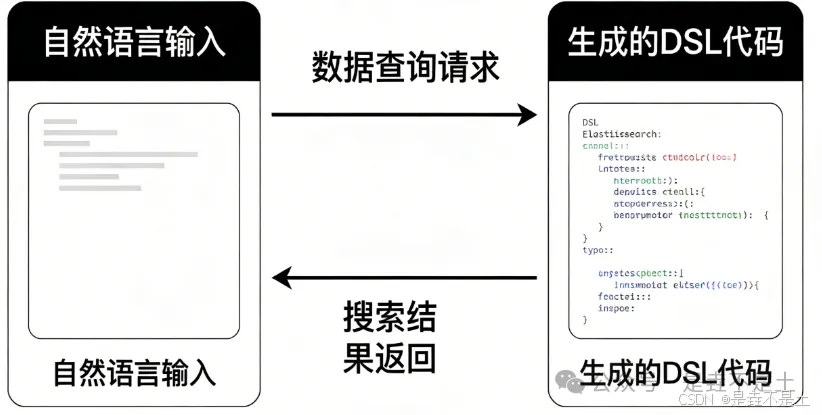
把 ClaudeCode 和 Elasticsearch 连接起来,再通过定制化 Skills,把查询规则、字段映射、时间边界、索引范围和操作红线全部提前写清楚。这样一来,原本需要手动编写 DSL 的日志查询,就可以被转化成自然语言指令;而 AI 返回的,也不再是"想当然"的答案,而是带着护栏的查询命令 + 基于结果的初步分析。
1.2 ClaudeCode本文核心应用
本次实践全程围绕nginx访问日志展开演示,因此ClaudeCode的应用均贴合该场景,重点体现在三个核心维度:
一是Skills调用与联动,通过调用后续编写的Elasticsearch专属Skills,建立与ES的稳定连接,精准获取存储在ES中的nginx访问日志(含请求地址、状态码、访问时间、客户端IP等核心字段);
二是日志分析演示,接收Skills返回的nginx日志数据后,可通过自然语言指令,让ClaudeCode完成日志筛选、统计与分析(比如筛选404/异常请求、统计热门访问接口),无需手动编写DSL查询;
三是辅助实操落地,在日志分析过程中,若遇到Skills调用异常、日志查询报错等问题,可借助ClaudeCode的调试能力定位问题,同时可生成日志分析相关的辅助脚本,为后续演示与实操提供支撑,全程服务于"nginx访问日志演示与分析"这一核心目标,也为后文Skills编写逻辑、Flunt-bit日志采集等实操内容做好铺垫。
二、ClaudeCode在WSL Ubuntu系统的安装
2.1 安装前准备
添加网络代理,"科学上网",宿主机开启系统代理:
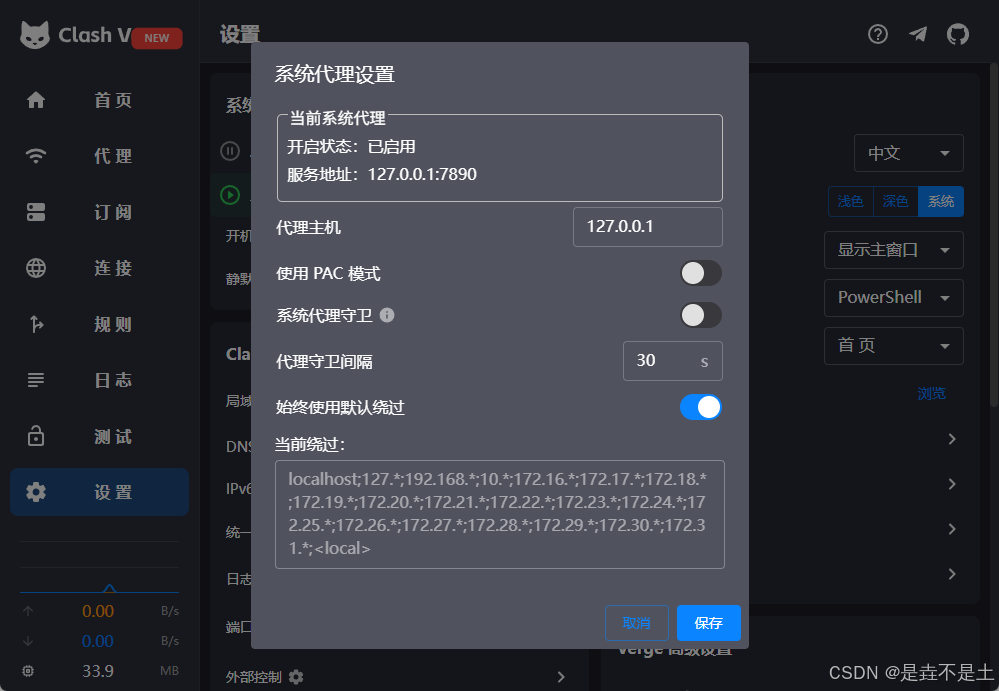
在WSL启动的ubuntu系统里配置网络代理:
bash
[root@localhost /data]$ vim /etc/profile
proxy () {
export http_proxy="http://172.19.128.1:7890"
export https_proxy=$http_proxy
export socks5_proxy="socks5://172.19.128.1:7890"
echo "HTTP Proxy on"
}
# noproxy
noproxy () {
unset http_proxy
unset https_proxy
echo "HTTP Proxy off"
}
[root@localhost /data]$ source /etc/profile开启网络代理,并藏问谷歌进行测试:
bash
root@localhost:/data# proxy
HTTP Proxy on
root@localhost:/data# curl -I https://www.google.com
HTTP/1.1 200 Connection established验证是否生效:
在对应终端执行验证命令,返回状态码 200(或出现 HTTP/1.1 200 / HTTP/2 200)即表示代理生效。
若验证失败,请先分别检查当前终端中的代理变量是否已设置正确,再重新测试。
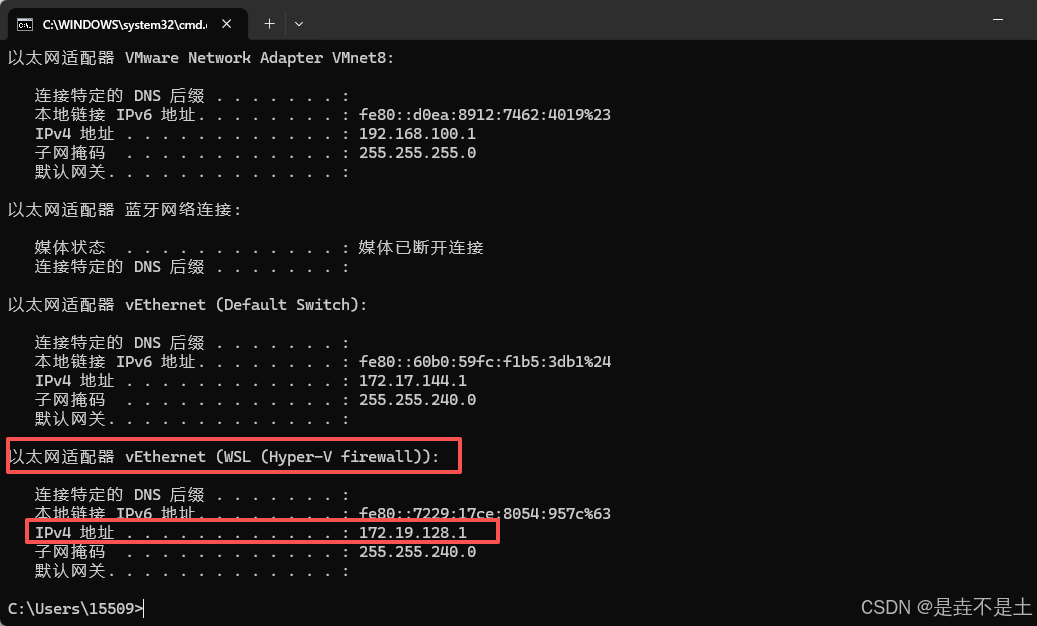
细节:由于采用的是wsl启动的系统,所以配置的网关要是WSL的vEnthernet:
2.2 具体安装步骤
下载安装脚本并执行安装:
bash
curl -fsSL https://claude.ai/install.sh | bash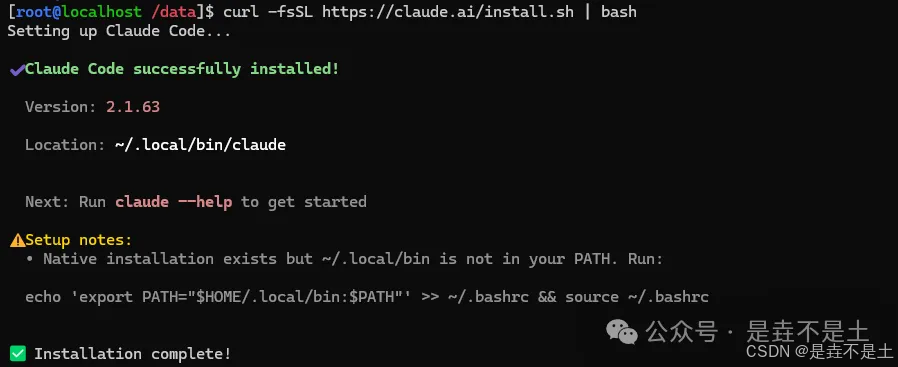
导入环境变量:
bash
[root@localhost /data]$ echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc && source ~/.bashrc
[root@localhost /data]$ claude --version
2.1.63 (Claude Code)安装完成后,执行以下命令检查 Claude CLI 是否可用:
bash
claude --version
2.1.62 (Claude Code)在环境变量当中添加以下变量
bash
# 设置 API 密钥
export ANTHROPIC_AUTH_TOKEN=sk-你的kys
# 设置 API 基础地址
export ANTHROPIC_BASE_URL=https://xxx.xxx.xx 你的api地址
# 禁用非必要流量
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1
# 指定模型(可选)
export ANTHROPIC_MODEL=claude-opus-4-6也可以直接编写settings.json:
bash
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "api_keys",
"ANTHROPIC_BASE_URL": "https://代理商",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "claude-opus-4-6-20260205",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "claude-opus-4-6-20260205",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "claude-opus-4-6-20260205",
"ANTHROPIC_MODEL": "claude-opus-4-6-20260205",
"BASH_DEFAULT_TIMEOUT_MS": "300000",
"BASH_MAX_TIMEOUT_MS": "600000",
"CLAUDE_AUTOCOMPACT_PCT_OVERRIDE": "55",
"CLAUDE_CODE_ATTRIBUTION_HEADER": "0",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1",
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1",
"CLAUDE_CODE_MAX_OUTPUT_TOKENS": "32000",
"DISABLE_AUTOUPDATER": "1",
"DISABLE_ERROR_REPORTING": "1",
"DISABLE_TELEMETRY": "1",
"MAX_THINKING_TOKENS": "16000",
"MCP_TIMEOUT": "60000",
"MCP_TOOL_TIMEOUT": "120000"
},
"hooks": {
"SessionEnd": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "ccclub sync --silent",
"timeout": 30,
"async": true
}
]
}
],
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "ccclub sync --silent",
"timeout": 30,
"async": true
}
]
}
]
}
}网上有众多中转站,大家可以任意选择相关中转站完成大模型的接入,不过本文不为大家提供,以免有打广告的嫌疑嘿嘿。
启动claude code ,选择主题后即可开始对话:
配置完成:
切换模型:
至此,安装部分完成。
三、Elasticsearch的Skills编写
让 ClaudeCode 直接操作 Elasticsearch 极易引发性能灾难,比如可能会出现如全量扫描造成超长上下文。因此,编写专属的 Elasticsearch Skills,本质上是给 AI 制定一份 "说明书"。
(本篇文章的 Skills 内容较多,核心思路已完整呈现,文末附 SKILL.md 核心骨架与 references 目录示例,可直接复用。)
bash
~/.claude/skills/elasticsearch-skill/
├── SKILL.md # 主说明书(基础规则+字段约束)
└── references/ # 深度语法文档(按高级域分类)
├── aggregations.md # 聚合分析语法
├── cluster-api.md # 集群诊断API
├── document-api.md # 文档CRUD语法
├── index-api.md # 索引/映射管理语法
├── kibana-api.md # Kibana操作语法
├── otel-data.md # OTel链路追踪查询语法
├── query-dsl.md # Query DSL语法
└── search-api.md # 搜索API语法3.1 Skills编写整体思路与架构设计
如果你只给 AI 一个 ES 地址,它为了查一个 404 错误,往往会使用性能极差的 query_string 进行全字段跨区扫描,由于没有时间边界,这一条语句就能拉满整个 ES 集群的 CPU,导致业务瘫痪。
设计原则 :为了省 Token 并防止乱来,我们将 ES 的能力做成三层渐进式披露架构,其核心运行流程如下:
text
┌─────────────────────────────────┐
│ 用户问题 │
└────────────┬────────────────────┘
│
▼
┌─────────────────────────────────┐
│ 加载 SKILL.md 到上下文 │ (Level 2: 高频基础知识)
│ - 环境变量及 Auth 认证方式 │
│ - 核心字段管控表(防坑护栏) │
│ - 日常 80% 基础查询示例 │
└────────────┬────────────────────┘
│
▼
┌────────────────────────┐
│ 识别:问题属于哪个高级域? │
└────────────────────────┘
│
├─ 搜索/Query DSL? ────→ 加载 references/query-dsl.md + search-api.md
│
├─ 聚合分析? ──────────→ 加载 references/aggregations.md + aggregations-api.md
│
├─ 索引/映射管理? ──────→ 加载 references/index-api.md + mapping-api.md
│
├─ 文档CRUD? ──────────→ 加载 references/document-api.md
│
├─ 集群诊断? ──────────→ 加载 references/cluster-api.md
│
├─ Kibana 操作? ───────→ 加载 references/kibana-api.md
│
└─ OTEL 查询? ─────────→ 加载 references/otel-data.md
│
▼
┌──────────────────────────────────┐
│ 组合 SKILL.md (基础规则) + │
│ 匹配到的 references/ (深度语法) │
│ → 构造出精准、安全的 curl 命令 │
└──────────────────────────────────┘
流程解析:
- 基础打底(Level 1/2) :ClaudeCode调用Skills时,默认仅读取主说明书
SKILL.md,文中强制规定了nginx日志查询的"安全红线"------比如查询必须带时间参数、必须使用正确的字段名(如http.response.status_code),同时包含ES认证信息和基础查询示例。对于简单查询AI直接在此层面完成响应,无需加载深层语法,节省Token且提升效率。 - 意图分发(Level 3) :当用户提出复杂查询需求(如"统计最近30分钟nginx不同状态码的访问量,并用composite聚合分析请求趋势"),AI会根据
SKILL.md中的指引,精准识别需求所属的高级域(聚合分析+Query DSL),仅加载对应的aggregations.md和query-dsl.md,避免加载无关的API文档。 - 最终组合(出结果) :AI将
SKILL.md中的基础规则与加载的深层语法结合,生成可直接在终端执行的curl命令,既保证查询精准性(贴合nginx日志字段),又确保查询安全性,同时最大化节省Token。
3.2 Skills核心内容展示与护栏配置
Skills的核心价值在于"划定安全边界、适配业务场景",结合本次nginx访问日志查询需求,我们在Level 2的SKILL.md中,植入了与nginx日志高度绑定的护栏配置,从环境、字段、操作三个维度,强制规范AI的查询行为,确保每一次查询都安全、高效。
3.2.1 注入纯净的环境上下文
为避免ClaudeCode每次查询时重复询问ES账号、密码等信息,同时规范认证方式,我们在Skills中直接指定环境变量读取规则,所有curl查询命令均严格遵循统一格式,确保与ES集群连接的安全性和一致性,适配nginx日志索引查询场景:
bash
# 所有 curl 示例必须严格遵循此格式:
curl -s "${ES_URL%/}/nginx-*/_search" \
-H "Authorization: ApiKey $(printenv ES_API_KEY)" \
-H "Content-Type: application/json" \
...
nginx-*索引匹配规则,对应后续Fluent-bit采集nginx日志时的索引命名规范,确保AI仅操作nginx相关日志索引,避免误操作其他业务索引。
3.2.2 强制的"字段映射与粒度约束"
AI缺乏nginx日志的业务常识,无法识别合理的查询字段与查询方式,因此我们将Fluent-bit采集落盘后,ES中nginx访问日志的真实字段表,强制植入Skills,明确规定每个字段的查询方式和用途,从根源上避免低效查询(如用query_string全字段扫描)。以下是nginx访问日志专属字段约束表:
| ES 字段名 | 类型 | 查询方式 | 说明 |
|---|---|---|---|
@timestamp |
date |
range |
日志时间,始终用于时间过滤 |
client.ip |
keyword |
term |
客户端 IP,精确匹配 |
http.request.method |
keyword |
term |
HTTP 方法:GET / POST / PUT 等 |
http.request.referrer |
keyword |
term |
Referer 头 |
http.response.body.bytes |
long |
range |
响应体大小(字节) |
http.response.status_code |
keyword |
term / terms |
HTTP 状态码,如 "200" / "404" / "500" |
http.version |
keyword |
term |
HTTP 协议版本:1.1 / 2.0 |
url.original |
keyword |
term / wildcard |
完整请求路径(含查询参数) |
user_agent.original |
keyword |
term / wildcard |
User-Agent 原始字符串 |
message |
text |
match |
原始日志行全文 |
service.name |
keyword |
term |
服务名 |
host.name |
keyword |
term |
部署节点主机名 |
log.file.path |
keyword |
term / wildcard |
日志文件路径 |
event.dataset |
keyword |
term |
数据集名称(如 nginx.access) |
当然,这是针对于nginx的日志来说,要是针对于生产场景下的微服务来说,就可以参考下面的内容:
补充说明:上述字段均由Fluent-bit采集nginx日志时,按规范解析后写入ES(具体采集与解析逻辑,在第四部分详细讲解)。
若为生产环境微服务日志,可参考此格式,自定义字段映射表,核心是"明确字段用途、规范查询方式"。
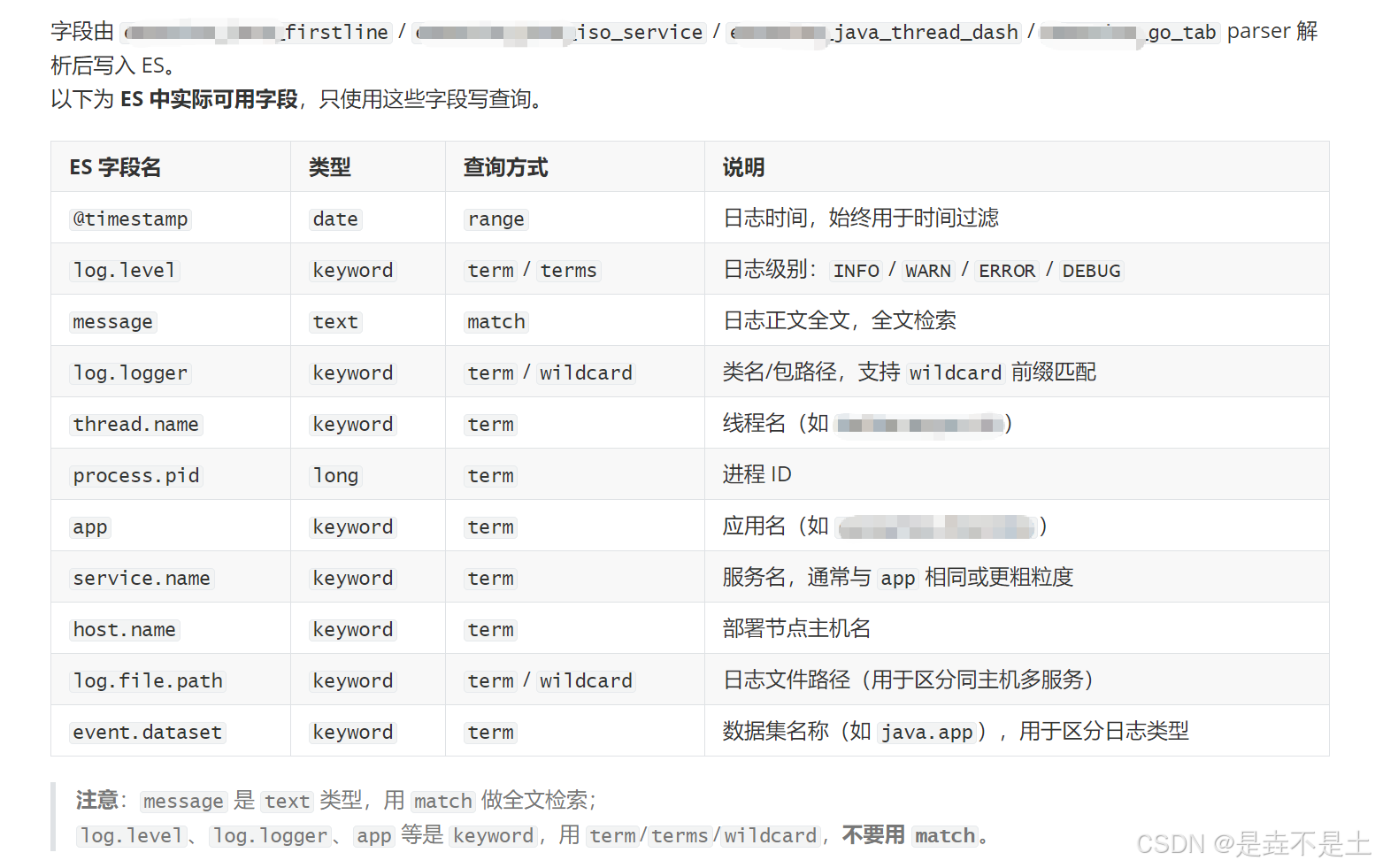
至于这里面的"字段由xxxxxx解析后写入es",这是本文的核心思想,会在后面进行详细讲述。
3.2.3 "红线"操作规范
由于Skills中植入了字段约束、时间边界要求和操作规范,AI会瞬间绕过query_string全字段扫描的误区,输出带有完美护栏的最优查询命令,无需手动干预,可直接在终端执行,具体如下:
bash
# ClaudeCode输出的查询命令(自动遵循Skills约束)
curl -s "${ES_URL%/}/nginx-*/_search" \
-H "Authorization: ApiKey $(printenv ES_API_KEY)" \
-H "Content-Type: application/json" \
-d '{
"query": {
"bool": {
"filter": [
{ "range": { "@timestamp": { "gte": "now-10m", "lte": "now" } } }, # 强制时间边界
{ "term": { "http.response.status_code": "500" } }, # 精准匹配状态码(符合字段约束)
{ "term": { "event.dataset": "nginx.access" } } # 仅查询nginx访问日志
]
}
},
"size": 100 # 限制返回条数,避免数据过多
}' | jq '.hits.hits[]._source | {time: .["@timestamp"], client_ip: .["client.ip"], url: .["url.original"], status: .["http.response.status_code"]}' # 输出瘦身对应的ES查询DSL核心过滤条件(AI自动生成,符合性能最优原则):
json
{
"filter": [
{ "range": { "@timestamp": { "gte": "now-10m", "lte": "now" } } }, # 时间边界不可少
{ "term": { "http.response.status_code": "500" } } # 精准匹配,替代低效的query_string
]
}3.2.4 "红线"操作规范
核心skills片段展示:
bash
---
name: elasticsearch
description: >
通过 REST API(curl)操作 Elasticsearch 和 Kibana。适用于查询、索引、管理索引、
检查集群健康状态、编写聚合、部署 Dashboard,以及排查 Elasticsearch 问题。
支持从环境变量加载连接配置(URL、API Key 或用户名/密码)。
涵盖:搜索(Query DSL / ES|QL)、CRUD、索引管理、Mapping、聚合、集群健康、
ILM、Kibana API(Dashboard、数据视图、Saved Objects)、OpenTelemetry 数据模式。
---
# Elasticsearch
所有 Elasticsearch 操作均通过 REST API 使用 `curl` 完成,无需 SDK 或客户端库。
## 环境变量配置
使用前请先设置连接配置,支持两种认证方式:
```bash
# ── 必填 ──────────────────────────────────────────────
ES_URL="https://your-cluster.es.cloud.elastic.co:443"
# ── 认证方式一:API Key(推荐,适用于 Elastic Cloud)──
ES_API_KEY="your-base64-api-key"
# ── 认证方式二:用户名/密码(适用于自建集群)──────────
ES_USER="elastic"
ES_PASS="your-password"
# ── Kibana(仅使用 Kibana API 时需要)─────────────────
KIBANA_URL="https://your-deployment.kb.us-east-1.aws.elastic.cloud"
```
> 优先使用 `ES_API_KEY`;若未设置,自动回退到 `ES_USER` + `ES_PASS`。
### 认证请求模板
```bash
# API Key 认证
curl -s "${ES_URL%/}/<endpoint>" \
-H "Authorization: ApiKey $(printenv ES_API_KEY)" \
-H "Content-Type: application/json" \
-d '<json-body>'
# 用户名/密码认证
curl -s "${ES_URL%/}/<endpoint>" \
-u "$(printenv ES_USER):$(printenv ES_PASS)" \
-H "Content-Type: application/json" \
-d '<json-body>'
```
**重要说明:**
- 始终用 `$(printenv ES_API_KEY)` 而非 `$ES_API_KEY`,防止变量在 curl 中展开失败导致 401 错误
- 始终用 `${ES_URL%/}` 去除末尾斜杠,防止路径出现双斜杠(如 `//_cluster/health`)
## 快速健康检查
```bash
# 集群健康状态(green/yellow/red)------Serverless 不可用
curl -s "${ES_URL%/}/_cluster/health" \
-H "Authorization: ApiKey $(printenv ES_API_KEY)" | jq .
# 索引概览(Serverless 和传统部署均可用)
curl -s "${ES_URL%/}/_cat/indices?v&s=store.size:desc&h=index,health,status,docs.count,store.size" \
-H "Authorization: ApiKey $(printenv ES_API_KEY)"
```
**Serverless 注意:** 若收到 `api_not_available_exception` 错误,说明是 Serverless 模式。以下 API 在 Serverless 中**不可用**:
- `_cluster/health`、`_cluster/settings`、`_cluster/allocation/explain`
- `_cat/nodes`、`_cat/shards`
- `_nodes/hot_threads`、`_nodes/stats`
- ILM 相关 API(`_ilm/*`)
...省略1w字...
---
## 搜索(Query DSL)
```bash
# 简单 match 查询
curl -s "${ES_URL%/}/my-index/_search" \
-H "Authorization: ApiKey $(printenv ES_API_KEY)" \
-H "Content-Type: application/json" \
-d '{
"query": { "match": { "message": "error timeout" } },
"size": 10,
"sort": [ { "@timestamp": { "order": "desc" } } ]
}' | jq .
# Bool 组合查询(must + filter + must_not)
curl -s "${ES_URL%/}/my-index/_search" \
-H "Authorization: ApiKey $(printenv ES_API_KEY)" \
-H "Content-Type: application/json" \
-d '{
"query": {
"bool": {
"must": [ { "match": { "message": "error" } } ],
"filter": [ { "range": { "@timestamp": { "gte": "now-1h" } } } ],
"must_not":[ { "term": { "level": "debug" } } ]
}
},
"size": 20
}' | jq .
```
完整 Query DSL 参考(term、range、wildcard、nested、multi_match 等)→ [references/query-dsl.md](references/query-dsl.md)
完整 Search API 参考(ES|QL、EQL、分页、高亮等)→ [references/search-api.md](references/search-api.md)3.3 体验 AI 的"性能最优解"
我们进行测试:
前提我们已经写在skills里了,就是es的配置信息,需要写在环境变量里,我们写在了settings.json的env字段里:
bash
{
"env": {
...
"ES_URL": "http://127.0.0.1:9200",
"ES_USER": "elastic",
"ES_PASS": "password"
},接下来我们让它分析一下,今天访问前三的请求路径是什么:
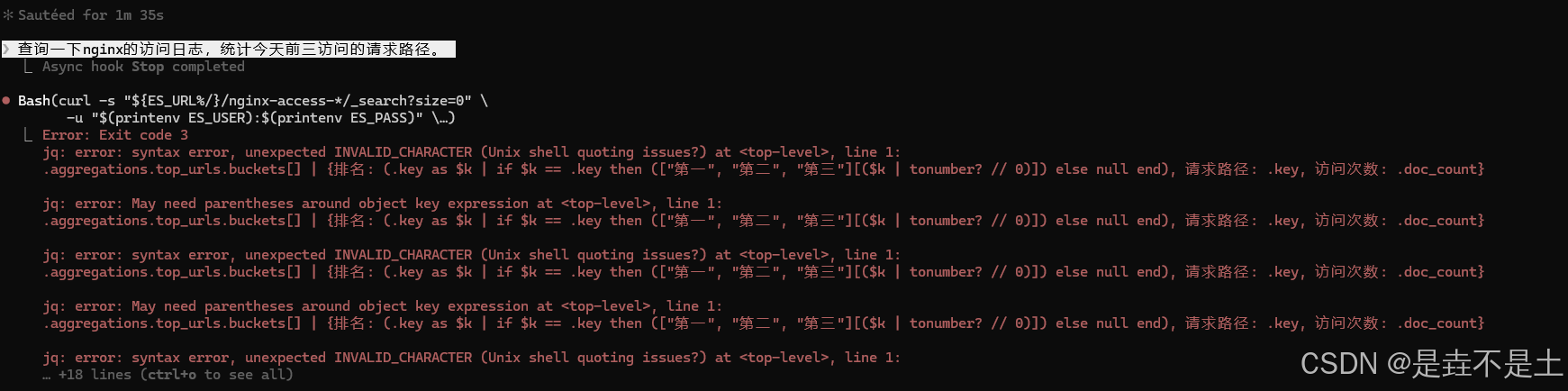
首先,它生成了一条查询命令,但是显然,它生成的命令是存在一部分小问题,并未拿到正确结果,接下来重新生成了一条:
bash
curl -s "${ES_URL%/}/nginx-access-*/_search?size=0" \
-u "$(printenv ES_USER):$(printenv ES_PASS)" \
-H "Content-Type: application/json" \
-d '{
"query": {
"range": { "@timestamp": { "gte": "now/d", "lte": "now" } }
},
"aggs": {
"top_urls": {
"terms": {
"field": "url.original.keyword",
"size": 3,
"order": { "_count": "desc" }
}
}
}
}' | jq -r '.aggregations.top_urls.buckets | to_entries | .[] | "第\(.key + 1)名: \(.value.key) - 访问次数: \(.value.doc_count)"'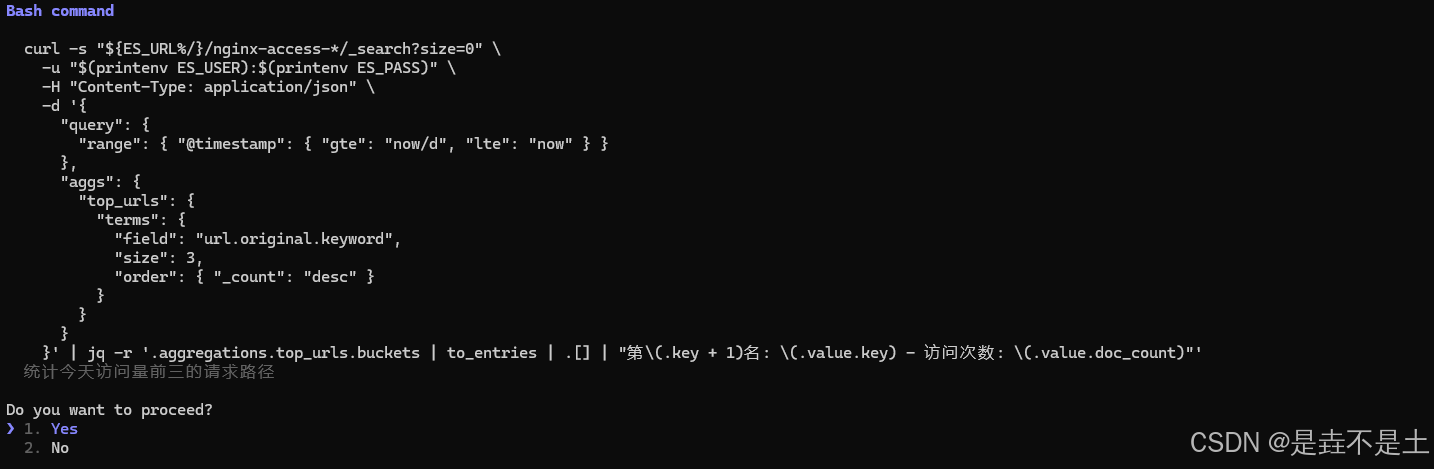
很显然这次拿到了分析结果,并且还帮助我们分析了结果:
由于不想拿简单的服务进行测试,直接用nginx的80端口反向代理了Kibana的端口,所以都是访问Kibana的参数

再测试一个相对较难的内容:
我用Kibana创建一个数据视图,去匹配一个不存在的索引,导致日志会出现404问题,我们让AI分析为何会404这个问题。
bash
curl -s "${ES_URL%/}/nginx-error-*/_search" \
-u "$(printenv ES_USER):$(printenv ES_PASS)" \
-H "Content-Type: application/json" \
-d '{
"query": {
"bool": {
"filter": [
{ "range": { "@timestamp": { "gte": "now-5m" } } },
{ "term": { "http.response.status_code": "404" } }
]
}
},
"size": 10,
"sort": [ { "@timestamp": { "order": "desc" } } ]
}' | jq -r '.hits.hits[]._source | "\(.["@timestamp"]) | IP: \(.["client.ip"]) | \(.["http.request.method"]) \(.["url.original"]) | 状态: \(.["http.response.status_code"]) | UA:
\(.["user_agent.original"] // "none")"'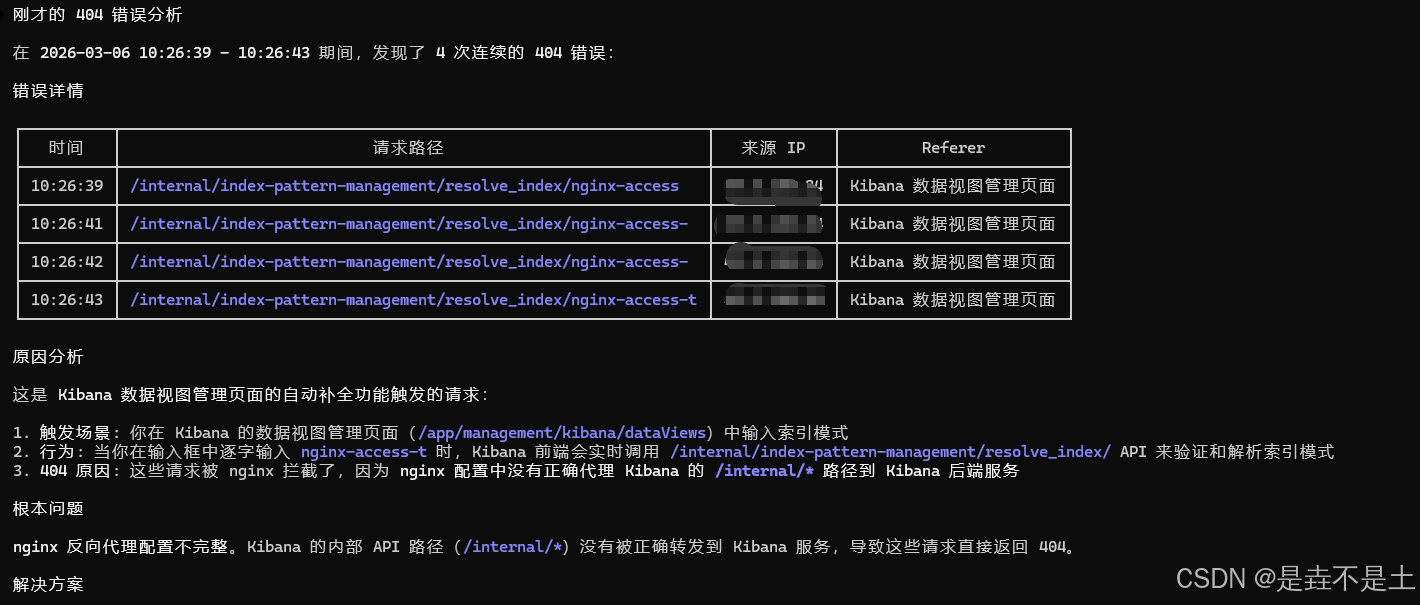
很显然AI分析失败了,这也就是说,AI有时候是真的不懂业务;其实也不能这么说,主要是你提供的skills里得真的有和你业务相关状态的内容提示,当你Skills里定义的不详细或业务过于复杂但并未让AI明确的时候就会出现类似的问题。
不过我想了一下,其实也可以定义一个skills进行联网查询,让它从广泛数据中进行查询,然后获得更加精准的结果,当然这也意味着token会在天上飞。
不管怎样,我们的核心功能还是实现了的。
四、日志采集架构与AI联动
4.1 整体采集架构思路
讲完了AI部分,我们来谈一谈,数据采集,我的数据采集流程是"EFK":
- E:Elasticsearch
- F:Fluent-bit
- K:Kibana
Fluent Bit 作为日志采集核心(F 环节),核心作用是:实时采集 Nginx 访问/错误日志,经过简单过滤、解析和字段增强后,将标准化日志输出至 Elasticsearch(E 环节),为后续 Kibana(K 环节)可视化分析提供数据支撑。
那么核心就是Fluent,它如何能够把日志精准的采集到的呢:
Fluent Bit通过加载/etc/fluent-bit/目录下的全套模板文件(主配置fluent-bit.conf、环境变量fluent-bit.env、解析模板parsers.conf和multiline_parsers.conf、字段增强脚本enrich.lua),以tail插件监听Nginx访问及错误日志,经过滤标准化、格式解析、字段增强后,按指定格式将结构化日志稳定输出至Elasticsearch,全程自动化完成**"采集→处理→输出"**,无需额外开发,仅需微调少量关键参数即可复用。
当然,市面上日志采集工具有很多,比如Filebeta、Logstash,但是我还是选择了Fluent Bit,一个字:轻。它资源占用低、配置简洁,无需复杂部署,仅凭一套可复用的模板就能完成日志采集全流程,远比同类工具更轻便、更高效,当然配置上可能稍显复杂,但是还在可接受范围之内,对比一下就晓得了:
| 采集工具 | 资源占用 | 配置复杂度 | 性能 | 易用性 | 适用场景 |
|---|---|---|---|---|---|
| Fluent Bit | 极低(MB 级内存) | 中等 | 高(百万日志 / 秒) | 中等 | 容器 / 轻量服务器 / 边缘节点 |
| Logstash | 高(GB 级内存) | 低 | 中 | 高 | 复杂日志处理 / 中台级采集 |
| Filebeat | 低 | 低 | 中 | 高 | 简单日志采集(无复杂处理) |
4.2 Agent Skills编写与采集流程的结合
为什么要说这里?
是因为我感受到了一些不一样的东西,就是前瞻思想。
如果我不这样按照严格的模板化采集日志,那么前文编写的 Elasticsearch Skills 就会彻底失去价值 ,AI 基于 Skills 里的字段约束生成的查询命令,会因为ES中日志字段命名不统一、格式不规范、关键信息缺失,最终要么查不到数据,要么返回无效结果,所谓 "AI 赋能日志分析" 也就成了空谈。
| 层级 | 采集侧(Fluent Bit)动作 | Skills 侧对应设计 | 最终效果 |
|---|---|---|---|
| 字段命名层 | 通过parsers.conf解析日志时,将 nginx 原生字段(如remote_addr)映射为 ES 标准字段(如client.ip),并严格遵循 ECS(Elastic Common Schema)规范 |
Skills 的 "字段映射与粒度约束表" 直接复用 ECS 标准字段名,明确client.ip为keyword类型、仅支持term查询 |
AI 生成的查询命令中,字段名与 ES 中存储的字段完全一致,避免 "查错字段" |
| 格式规范层 | 强制解析@timestamp字段为 ISO8601 格式,状态码status转为字符串类型,url.original保留完整请求路径 |
Skills 中规定@timestamp必须用range做时间过滤,http.response.status_code(对应采集侧status)仅支持term/terms查询 |
AI 生成的查询命令能精准命中数据类型,避免 "字符串字段用数值查询""时间字段格式不兼容" 等语法错误 |
| 索引隔离层 | Fluent Bit 输出日志时,按 "nginx-access-YYYY.MM.DD""nginx-error-YYYY.MM.DD" 命名索引 | Skills 中限定查询索引为nginx-*,并区分event.dataset: nginx.access/nginx.error |
AI 仅操作指定索引,避免误查其他业务日志,同时可精准区分访问 / 错误日志场景 |
五、结尾
受AI的影响,现在做方案都会考虑一些后手,也就是所谓的AI赋能,究竟应该如何把AI融入到运维去实现高效运维,提高生产效率,已经成为今年共同探索的核心方向了,当然,现在很多大厂都有相关产品,比如某公司的SREAgent,刚出来的时候真的很吓人,但是吓人归吓人,日子还得一天天的过,一个人探索未来,跟着大厂的思想走,何尝不是一种快乐呢?
这个文章其实也只是探索过程中的一部分,结合第一篇文章,其实已经落地了现代微服务三大监控中的两个了,还缺少一个分布式链路追踪。
但是真的缺少么?有细心的人其实能在我放的截图里看到了一个OTel的skills 了,一套基于Elasticsearch、Jaeger、OpenTelemetry实现分布式链路追踪的方案其实早已写完并且完成测试了,只不过skills还没有定义的非常详细,链路追踪真的是重头戏,那个skills必须要完全懂得业务逻辑才能去让AI变得刚高效,所以,每天提升自己刻不容缓哈哈哈,那就写到这里了,拜拜,我们评论区见。
s 中限定查询索引为nginx-*,并区分event.dataset: nginx.access/nginx.error | AI 仅操作指定索引,避免误查其他业务日志,同时可精准区分访问 / 错误日志场景 |
五、结尾
受AI的影响,现在做方案都会考虑一些后手,也就是所谓的AI赋能,究竟应该如何把AI融入到运维去实现高效运维,提高生产效率,已经成为今年共同探索的核心方向了,当然,现在很多大厂都有相关产品,比如某公司的SREAgent,刚出来的时候真的很吓人,但是吓人归吓人,日子还得一天天的过,一个人探索未来,跟着大厂的思想走,何尝不是一种快乐呢?
这个文章其实也只是探索过程中的一部分,结合第一篇文章,其实已经落地了现代微服务三大监控中的两个了,还缺少一个分布式链路追踪。
但是真的缺少么?有细心的人其实能在我放的截图里看到了一个OTel的skills 了,一套基于Elasticsearch、Jaeger、OpenTelemetry实现分布式链路追踪的方案其实早已写完并且完成测试了,只不过skills还没有定义的非常详细,链路追踪真的是重头戏,那个skills必须要完全懂得业务逻辑才能去让AI变得刚高效,所以,每天提升自己刻不容缓哈哈哈,那就写到这里了,拜拜,我们评论区见。