哈希表是数据结构中的 "快准狠" 代表,通过哈希函数映射数据与存储位置,使查找、插入、删除操作平均时间复杂度逼近 O (1)。它以 "空间换时间" 突破效率瓶颈,本文拆解其核心原理、冲突解决与优化技巧,助学习者和开发者掌握这一实用工具。
1. 哈希表的概念
不通过任何的计算,就可以得到想要搜索的数据,构造一个存储结构,通过某种函数(HashFunc)使元素的存储位置和它的关系码之间建立一个一一映射的关系,那么在查找的时候就可以通过函数来找到该元素。
2. 哈希冲突/哈希碰撞
(1) 概念
两个不同的关键字,使用同一个哈希函数,得到的确实同一个关键码。
(2) 避免哈希冲突
设计优秀的哈希函数来避免哈希冲突
- 定义域需要包含全部的关键码,如有m个地址的话,其值域最低是0,m-1。
- 哈希函数的设计可以让地址可以填充整个空间。
- 哈希函数尽可能的简单
3. 负载因子
负载因子是哈希表(Hash Table)的核心参数,用来衡量哈希表的填充程度,直接影响哈希表的性能(查询 / 插入效率)和内存使用率,是平衡 "空间" 与 "时间" 的关键。
负载因子 = 填入表中的个数 / 表的总长度
注:当负载因子趋近1的时候,需要扩容,否则发生哈希冲突的概率会更高。最好是达到一定的阈值就扩容,在Java中默认为0.75。
4.解决哈希冲突
(1) 闭散式
① 线性探测
开放地址法,当发生冲突的时候,如果哈希表没有被填满,就放在冲突的后面一个空位上面。
② 二次探测
基于线性探测,我们发现了这个线性探测很容易就把数据集中在一块,而哈希表的特点就是使表中的元素均匀的分在再表中,所以就推出了二次探测:通过二次函数分散探测位置,打破连续聚集,公式为:
POSi=(hash(key)+i^2)%size; // (i=1,2,3...)
③ 总结
采用闭散式处理哈希冲突的时候,不可以随意删除表中的任何一个数据,若删除之后,就会导致可能查找不到想要的元素了。
(2) 开散式/哈希桶(开链法)
采用的是数组 + 链表的方式来进行存储。
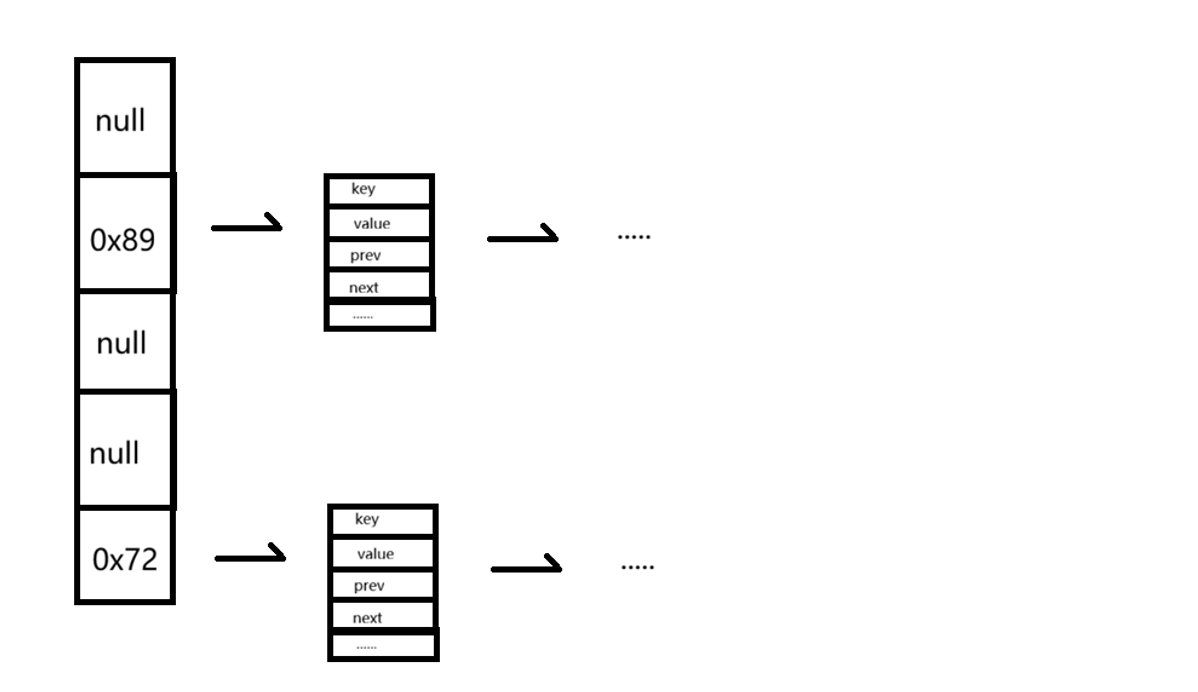
计算出来的key相同就存储在数组的一个节点后面,用链表的方式给它串起来,让数组上面来存储这链表的头结点。而且当链表长度超过阈值(如 8)时,会自动转换为红黑树,将最坏时间复杂度降低到 O (log n),从而保证高效性能。而我们认为这个链表是可以数清楚的不会达到n,所以我们认为其时间复杂度就是O(1)。
5. 哈希表和Java类的关系
- Java中是用哈希桶来解决哈希冲突的。
- 当链表的长度达到一定的阈值之后会转为红黑树。
- Java计算哈希值实际上用的是类的hashcode方法,进行key的比较的时候是调用key的equals方法。