Li Jin1*, Weikai Chen2*, Yujie Wang3†, Yingda Yin2, Zeyu HU2, Runze Zhang2, Keyang Luo2, Shengju Qian2, Xin Wang2, Xueying Qin1†
1 山东大学 (SDU) 2 光速工作室 (LIGHTSPEED) 3 北卡罗来纳大学教堂山分校 (UNC Chapel Hill)
https://arxiv.org/pdf/2603.01205v1
摘要
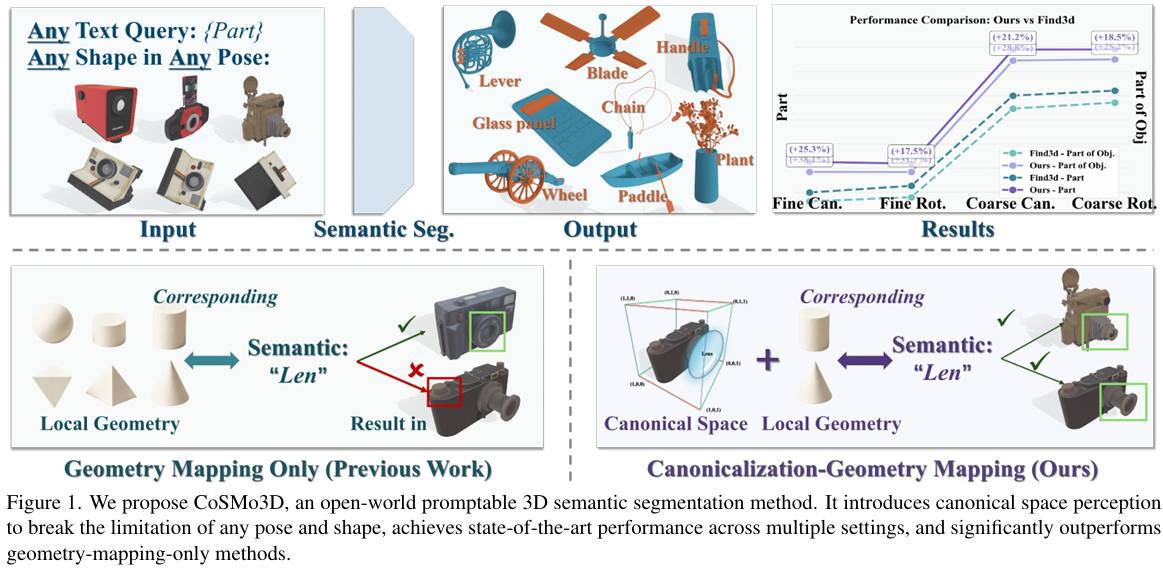
开放世界可提示的 3D 语义分割仍然非常脆弱,因为语义是在输入传感器坐标系中推断的。然而,相比之下,人类是通过规范空间中的功能角色来理解部件的------机翼向侧面延伸,把手向侧面突出,腿从下方支撑。心理物理学证据表明,我们在心理上会将物体旋转到规范框架中以揭示这些角色。为了填补这一空白,我们提出了 CoSMo3D,它通过诱导一个直接从数据中学习到的潜在规范参考系来实现规范空间感知。通过构建,我们创建了一个统一的规范数据集,通过大语言模型(LLM)引导的类别内和跨类别对齐,揭示了跨越 200 个类别的规范空间规律性。通过归纳,我们通过具有规范地图锚定(canonical map anchoring)和规范框校准(canonical box calibration)的双分支架构,在模型内部实现了规范性,将姿态变化和对称性坍缩为稳定的规范嵌入。这种从输入姿态空间到规范嵌入的转变,产生了更稳定且可迁移的部件语义。实验结果表明,CoSMo3D 在开放世界可提示 3D 分割领域确立了新的最先进水平。项目页面:https://github.com/JinLi998/CoSMo3D/tree/main
*同等贡献。†通讯作者。
1. 引言
人类通过共同推理几何和空间语义来感知 3D 物体。当我们识别"椅子的腿"时,我们不仅依赖其细长的形状,还依赖其规范位置------位于座位下方并支撑物体。心理物理学研究 17 进一步表明,人类会执行心理旋转以将观察到的物体与规范姿态对齐,从而使我们能够一致地识别不同姿态和类别下的部件。这种规范空间推理是人类 3D 理解的核心组成部分,但在当前的分割模型中仍然 largely 缺失。
开放世界 3D 理解的最新进展已开始弥合这一差距。特别是,Find3D 13 引入了开放世界可提示 3D 分割的任务,即模型根据自由形式的文本查询(例如"把手"、"机翼"或"桨")分割任何 3D 物体。这是迈向可扩展 3D 理解的重要一步:模型不再局限于固定类别的分割,而是可以解释开放式提示并将知识迁移到未见过的类别。Find3D 通过学习几何特征和语言嵌入之间的直接对齐来实现这一点,并由大规模自动标注数据集支持。它迈向了通用 3D 感知的关键一步,展示了令人印象深刻的零样本泛化能力和灵活的提示能力。
尽管取得了成功,但 Find3D 及类似方法从根本上仍受限于其对几何 - 文本匹配的依赖。它们假设几何相似的形状往往共享相似的语义,然而这种相关性在实践中经常失效。例如,椅子的扶手和腿可能在几何上相似,但功能不同;而飞机机翼和鸟翼形态不同却共享相同的语义。如果没有基于规范空间规律的显式推理,这些模型缺乏对语义部件相对于整个物体应出现位置的感知,导致在姿态变化、对称性或跨类别下预测不一致。例如,在我们的示例图(图 1)中,Find3D 错误分类了一个圆柱体。虽然数据增强提供了有限的鲁棒性,但这些模型仍然缺乏空间语义的内部概念,而这正是人类感知的核心要素。
我们认为,实现类人的 3D 理解需要规范空间感知:即内化一个跨形状和类别共享的规范参考空间的能力,并相对于该参考系(而非原始输入姿态)来解释部件语义。为此,我们介绍了 CoSMo3D,这是一个 LLM 引导的开放世界可提示 3D 分割框架,它通过从数据中诱导潜在参考系来实现规范空间感知。这一原则在 CoSMo3D 中体现在两个层面:1) 外部 ,我们通过 LLM 引导的类别内和跨类别规范化流水线构建了一个统一的规范数据集,使得规范性不再仅在类别内定义,而是在对象家族间共享。这为我们提供了一个超越类别边界的通用基底。2) 内部,我们通过直接从数据中诱导潜在规范参考系来实例化规范性,而不是手动规定规范姿态。在此框架内,我们提出了一种双分支架构:主分支保留了 Find3D 的几何 - 语言对齐,而规范分支则通过两个规范空间目标(规范地图锚定和规范框校准)将点嵌入拉向规范代码并收紧部件级的空间范围。因此,规范空间成为一个涌现的吸引子流形:同一功能部件的不同姿态、对称性和形状变体坍缩为单一的规范嵌入,使得语义在空间上扎根且本质上姿态不变。
大量实验表明,CoSMo3D 显著优于现有方法。通过在统一框架下集成语言驱动的语义、几何理解和规范空间推理,CoSMo3D 弥合了几何 - 文本对齐与类人空间感知之间的差距。总体而言,我们的贡献总结如下:
- 我们将开放世界 3D 分割重构为基于规范空间规律的推理,而不是在输入姿态中将几何与文本进行匹配。
- 我们将规范性转化为可学习的潜在结构,通过 LLM 对齐的规范数据集和双分支规范正则化来实例化。
- CoSMo3D 在准确性、空间稳定性和跨类别泛化方面,确立了开放世界 3D 分割的新最先进水平。
2. 相关工作
传统的数据驱动部件分割 5, 12, 29, 30 以 2D 图像或 3D 形状作为输入。其核心在于预定义物体类别和部件标签,随后进行像素级或点级分类。然而,由于严重依赖预定义标签,其泛化能力有限,无法适应开放世界场景。在开放世界场景的背景下,2D 分割技术首先取得了突破。其中,以 SAM 8, 16 为代表的类无关分割不需要预定义类别,平衡了分割精度和泛化能力。SAM3 进一步引入了提示语义分割,通过开放词汇与部件之间的映射,提高了与人类语义认知的对齐度和可控性,为 3D 分割技术的发展提供了参考。
类无关 3D 分割以 3D 形状作为输入,旨在基于几何特征实现物体的多级分解,而无需预定义类别。它主要包括两条技术路径:一是基于 2D 转换的方法 19, 25,通过渲染将 3D 形状转换为 2D 图像,使用 SAM 等 2D 模型进行分割,然后将结果反投影回 3D 空间,最后通过后处理缓解多视图一致性和自遮挡等问题。然而,这条路径依赖转换和后处理,导致速度慢且不可避免存在多视图一致性问题。二是纯 3D 方法 4, 11, 24, 26, 33:Sampart3D 26 通过 3D 特征提取器结合测试时自适应(TTA)实现分割,但 TTA 增加了计算成本;Partfield 11 及其后续改进方法 4, 24, 33 通过对比学习扩大部件间的特征差异,然后通过聚类完成分割。尽管它们凭借更强的网络架构和更多数据取得了更好的性能,但都局限于低级部件分割,缺乏高级语义理解,交互性和可控性较差。此外,物体特征在任意姿态下不具备一致性,难以与语义建立映射。
可提示 3D 语义分割以 3D 形状和语义文本作为输入,核心是通过文本条件建立语义与 3D 部件之间的映射,以输出目标分割结果。它分为两类方法:一是基于 2D 的方法 1, 10, 18, 20, 31, 32,采用 Glip 15 等 2D 语义分割模型,重点解决将 2D 结果聚合到 3D 空间时的一致性问题。然而,由于依赖 2D 分割,它们只能处理直立姿态的物体(例如,当物体倒置时会失败),且转换过程显著增加了时间成本。二是纯 3D 方法 13,基于 3D 数据集训练语义提示模型,支持"任意文本、任意物体、任意姿态"的分割,具有强大的鲁棒性且无需 2D 转换,从而实现了显著的速度提升。然而,在打破规范空间的约束后,网络仅通过"文本 - 部件相似性"的约束学习了"文本与几何结构"之间的对应关系。虽然相似的语义部件通常具有相似的几何结构(例如,椅子的腿大多是细长的),但相似的几何结构可能对应不同的语义(例如,椅子的扶手和腿都是细长的,但属于不同的语义)。因此,仍然需要额外的感知能力来解决开放世界分割中的语义歧义。
3. 方法
3.1. 概述
给定一个 3D 形状和一个文本提示,我们的方法通过对形状编码几何特征、对文本编码语义特征,计算跨模态相似度以将文本与形状区域关联起来,并将这些关联解码为部件级标签。概览见图 2。
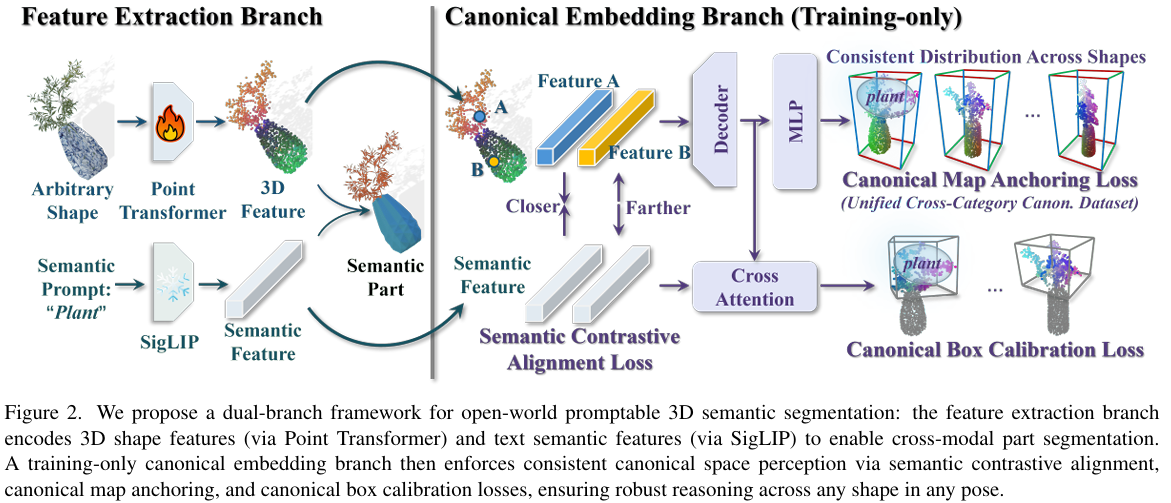
为了使框架具备跨类别的可迁移规范空间理解能力,以用于开放世界 3D 语义部件推理,我们通过外部和内部两个 fronts 来实现这一目标。数据与监督(外部) (第 3.2 节)。我们利用 LLM 引导的类别内和跨类别规范化流水线构建了一个跨类别规范数据集。该语料库提供了监督信号,包括规范地图、部件框和语义关联,使模型能够从数据中诱导潜在规范参考系。双分支框架与规范空间目标(内部)(第 3.3 节)。如图 2 所示,我们的双分支架构包括:(i) 一个在训练和推理期间都使用的特征提取分支,以及 (ii) 一个仅用于训练的规范分支,用于预测规范地图和部件级框。我们的训练损失结合了几何 - 文本对齐项(用于稳定跨模态映射)和两个规范空间正则化项,即规范地图锚定和规范框校准,它们通过将点嵌入拉向规范代码并在规范空间中收紧语义部件的空间范围,来强制与诱导的参考系保持一致。
3.2. 统一的跨类别规范数据集
学习可迁移的规范空间先验对于在开放世界设置中泛化到多样且可能未见过的类别至关重要。然而,现有的规范数据集 3, 21 单独处理各个类别,缺乏跨类别对齐(如图 3(a) 所示),限制了其在开放世界场景中的可扩展性。为了解决这个问题,我们构建了一个涵盖大多数常见物体类别并具有跨类别对齐的统一规范数据集(图 3(b))。该过程涉及两个关键步骤:(i) 类别内规范化,将每个类别内的实例对齐到共享的规范空间;(ii) 跨类别规范化,跨类别对齐语义对应的部件或地标。
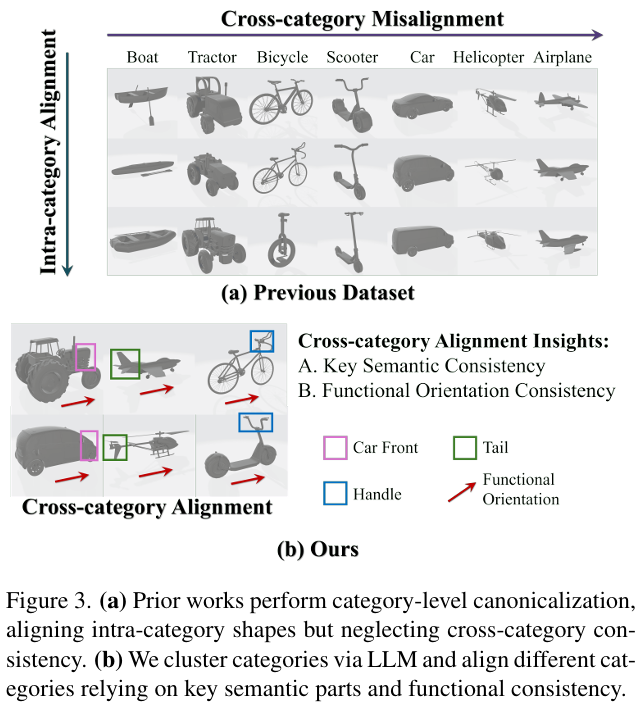
由于类别内规范化已在现有工作中得到广泛研究 2, 7, 22,我们主要关注更具挑战性的跨类别规范化任务。由于不同类别之间几何和功能的巨大差异,这非常困难。例如,叉子、自行车和树干等类别在形状和用途上都有显著差异。为了解决这个问题,我们设计了一种分层对齐策略:首先根据共享的功能或使用上下文将物体类别分组为语义连贯的类别簇;然后依次执行簇内和簇间对齐,逐步在所有类别之间构建统一的规范空间。
具体而言,我们构建了一个包含 200 个常见类别和 17K 形状的类别级规范数据集 2。首先,我们利用大语言模型(如 GPT)将这 200 个类别聚类为 19 个语义连贯的组(例如,交通工具、工具)。在每个簇内,基于共享的功能特征执行对齐。例如,交通工具簇内自行车和飞机的转向相关部件被对齐以确保方向一致。由于数据集 2 已经在每个类别内统一了核心语义方向,因此对齐同一簇内的多个类别通常只需要简单的离散旋转(例如 90°、180° 或 270°),使得该过程计算高效。接下来,通过验证高层语义一致性来执行簇间对齐。例如,我们确保交通工具和动物簇共享一致的前进方向。此外,为了进一步丰富形状多样性,我们对物体应用了轴对齐变形。最终,我们获得了一个在类别间和类别内具有一致对齐的统一规范数据集。我们在补充材料中提供了额外的数据集细节和样本可视化。
3.3. 规范感知双分支框架
架构。 我们为可提示 3D 语义理解设计了一个双分支框架。如图 2 所示,我们采用特征提取分支,在单次推理过程中从输入点云预测 3D 特征,这与依赖 2D 渲染的先前 3D 聚合方法形成对比。规范嵌入分支是我们设计的独特部分,仅在训练期间引入,生成由规范空间相关信号监督的中间表示。这增强了模型对规范空间的感知,改善了形状和提示之间的对齐。特征提取分支很大程度上遵循了 Find3D 的设计。它采用 Pt3 23 作为点云编码的主干,采用 SigLIP 28 进行文本特征提取。一个轻量级的 3 层 MLP 将点特征投影到与文本特征相同的嵌入空间中。
规范嵌入分支包含两个头:一个用于规范地图预测,另一个用于语义边界框预测。对于规范地图预测,我们使用 3D 形状特征作为输入,受 3D 生成方法 6, 9 的启发,回归三个连续标量场(编码为 RGB 颜色图),而不是离散的逐点值,以更好地保持空间连续性。对于语义边界框预测,文本特征作为查询从形状特征中提取相关区域,输出为表示边界框的 6 维向量。
3.3.1. 语义对比对齐损失
在开放世界可提示部件分割中,语义是非排他的:单个部件可以通过材料、功能、同义词选择或标签粒度来指代。瓶子颈部的一个点可以有效地标记为"颈部"(细粒度)或"主体"(粗粒度),使得单点单标签监督变得脆弱。遵循 Find3D 13,我们可以采用对比学习来编码软点 - 文本亲和力:
Lh=1M∑i=1M−logf(pˉi,ti)∑k∈Bf(pˉi,tk),\mathcal{L}{h}=\frac{1}{M}\sum{i=1}^{M}-\log\frac{f(\bar{\mathbf{p}}{i},\mathbf{t}{i})}{\sum_{k\in\mathcal{B}}f(\bar{\mathbf{p}}{i},\mathbf{t}{k})},Lh=M1i=1∑M−log∑k∈Bf(pˉi,tk)f(pˉi,ti),
其中 pˉi\bar{\mathbf{p}}{i}pˉi 表示第 iii 个语义部件掩码内点样本的平均特征,ti\mathbf{t}{i}ti 是文本嵌入。MMM 是部件标签的数量,B\mathcal{B}B 表示小批量中的语义标签集合,且 f(pˉi,ti)=exp(pˉi⊤⋅ti/τ)f(\bar{\mathbf{p}}{i},\mathbf{t}{i})= \exp(\bar{\mathbf{p}}{i}^{\top}\cdot\mathbf{t}{i}/\tau)f(pˉi,ti)=exp(pˉi⊤⋅ti/τ),其中 τ\tauτ 为温度参数。我们在每个部件中策略性地采样点,详情如下。
我们观察到,在每个部件内进行均匀点采样会使公式 (2) 偏向于块 - 文本一致性,而可能忽略单个点的偏差,导致部件边界附近的掩码噪声较大且收敛较慢。为了解决这个问题,我们引入了一种硬负采样策略,即从部件间边界采样更多具有判别力的负样本,以提高分割精度。硬双向对比损失定义为:
Lh=12M∑i=1M−logf(pˉi,ti)∑k∈Bif(pˉi,tk)−logf(ti,pˉi)∑n∈Pif(tn,p^n),p^n=1Wn(∑pj∈Ωnpj+(1+α)∑pe∈Enpe),(2)\begin{aligned}{\mathcal{L}{h}}&{{}=\frac{1}{2M}\sum{i=1}^{M}-\operatorname{l o g}\frac{f(\bar{\mathbf{p}}{i},\mathbf{t}{i})}{\sum_{k\in\mathcal{B}{i}}f(\bar{\mathbf{p}}{i},\mathbf{t}{k})}-\operatorname{l o g}\frac{f(\mathbf{t}{i},\bar{\mathbf{p}}{i})}{\sum{n\in\mathcal{P}{i}}f(\mathbf{t}{n},\hat{\mathbf{p}}{n})},}\\ {\hat{\mathbf{p}}{n}}&{{}=\frac{1}{W_{n}}\left(\sum_{\mathbf{p}{j}\in\Omega{n}}\mathbf{p}{j}+(1+\alpha)\sum{\mathbf{p}{e}\in\mathcal{E}{n}}\mathbf{p}_{e}\right),\quad(2)}\\ \end{aligned}Lhp^n=2M1i=1∑M−log∑k∈Bif(pˉi,tk)f(pˉi,ti)−log∑n∈Pif(tn,p^n)f(ti,pˉi),=Wn1 pj∈Ωn∑pj+(1+α)pe∈En∑pe ,(2)
其中当 n=in=in=i 时 α=0\alpha=0α=0,当 n≠in \neq in=i 时 α>0\alpha>0α>0。pj\mathbf{p}{j}pj 和 pe\mathbf{p}epe 表示单个点特征。Ωn\Omega{n}Ωn 和 En\mathcal{E}{n}En 分别表示与语义标签 nnn 关联的部件的内部区域和边缘区域。归一化权重定义为 Wn=∣Ωn∣+(1+α)∣En∣W_{n}=|\Omega_{n}|+(1+\alpha)|\mathcal{E}_{n}|Wn=∣Ωn∣+(1+α)∣En∣。
3.3.2. 规范空间正则化
基于双分支设计和精心策划的跨类别规范数据集,我们的方法利用规范空间线索正则化点特征。我们引入了以下两个损失,以对齐每部件的规范分布并强制执行鲁棒的空间范围。
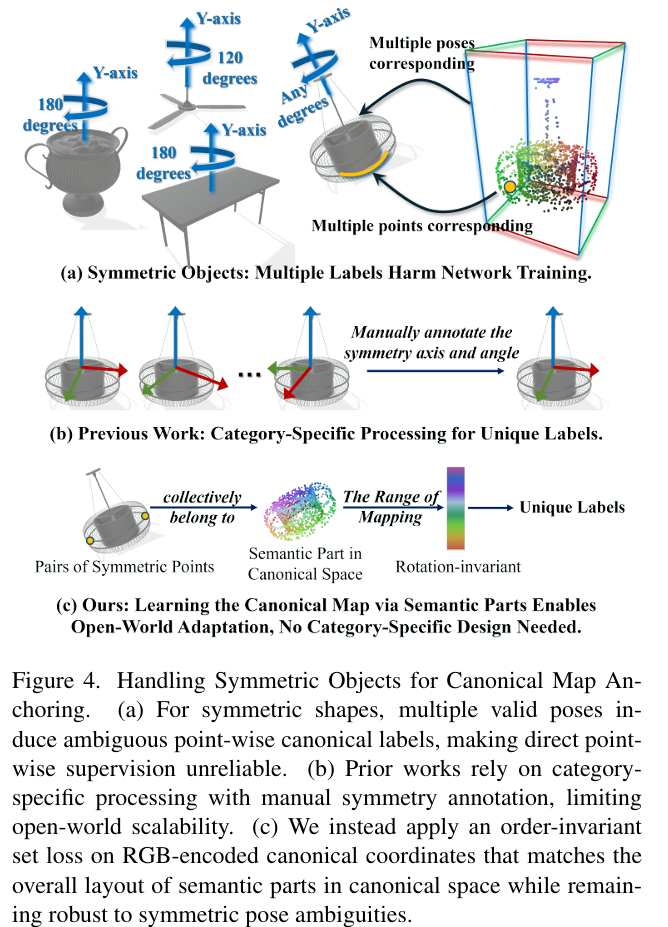
规范地图锚定损失。 我们的目标是强制具有相同(或密切相关)语义的语义部件在规范空间中表现出一致的空间分布,无论是在物体类别内部还是跨类别。我们通过使用我们策划的数据集中提供的规范化元数据和语义部件标签来锚定每部件的规范地图从而实现这一目标。然而,在实践中,我们观察到轴向和平面对称性经常引入对应歧义(图 4(a)):对称物体的多个姿态在规范空间中同样有效,使得逐点规范监督不可靠。现有的规范空间感知方法试图通过手动标注对称轴或强制执行特定于类别的约束来解决这个问题(图 4(b)),但这种设计无法扩展到开放世界分割。
我们的关键见解是完全避免对应关系。我们不是逐点监督规范坐标,而是将每个语义部件视为规范空间中的一个分布。然后,我们使用双向 Chamfer 距离将预测的规范地图与真实规范分布进行匹配来正则化。由于该目标比较的是分布的形状而不是单个坐标,对称构型在规范空间中变得等价。因此,对称点自动收敛到相同的规范区域,绕过了对对称标签或每类别轴标注的需求。
形式上,令 Gmp = {ai}\mathcal{G}{m}^{p}\:=\:\{\mathbf{a}{i}\}Gmp={ai} 和 Gmt = {bj}\mathcal{G}{m}^{t}\:=\:\{\mathbf{b}{j}\}Gmt={bj} 分别表示规范空间 Ω⊂Rd\Omega\subset\mathbb{R}^{d}Ω⊂Rd(通常 d∈{2,3}d\in\{2,3\}d∈{2,3})中部件 mmm 的预测点集和真实点集。我们将规范地图锚定损失定义为:
Lca=1M∑m=1M(1∣Gmp∣∑ai∈Gmpminbj∈Gmt∥ai−bj∥p+1∣Gmt∣∑bj∈Gmtminai∈Gmp∥bj−ai∥p).\begin{aligned}{\mathcal{L}{c a}=\frac{1}{M}\textstyle\sum{m=1}^{M}}&{{}\Big(\frac{1}{|\mathcal{G}{m}^{p}|}\textstyle\sum{\mathbf{a}{i}\in\mathcal{G}{m}^{p}}\operatorname*{m i n}{\mathbf{b}{j}\in\mathcal{G}{m}^{t}}\|\mathbf{a}{i}-\mathbf{b}{j}\|{p}+}\\ {}&{{}\frac{1}{|\mathcal{G}{m}^{t}|}\textstyle\sum{\mathbf{b}{j}\in\mathcal{G}{m}^{t}}\operatorname*{m i n}{\mathbf{a}{i}\in\mathcal{G}{m}^{p}}\|\mathbf{b}{j}-\mathbf{a}{i}\|{p}\Big).}\\ \end{aligned}Lca=M1∑m=1M(∣Gmp∣1∑ai∈Gmpminbj∈Gmt∥ai−bj∥p+∣Gmt∣1∑bj∈Gmtminai∈Gmp∥bj−ai∥p).
∥⋅∥p\|\cdot\|_{p}∥⋅∥p 表示 ppp-范数(默认使用 p=2p{=}2p=2)。通过对齐分布而不是点,该损失驱动了旋转不变、对称鲁棒的规范布局。
规范框校准损失。 在推理时,部件通过将逐点特征与用户提示的文本嵌入匹配来进行分割。虽然灵活,但该过程容易受到局部噪声的影响,并可能产生模糊或不规则的边界,部分原因是前面的损失强调部件级分布对齐而非逐点精度。为了加强边界一致性,规范分支预测规范空间中每个语义部件的 3D 边界框。这些框提供了一个粗略但稳定的空间先验,可以锐化边界并抑制虚假激活(见图 5 中间)。损失公式化为:
Lcb=1M∑m=1M16∥bmp−bmt∥1,bm(⋅)∈R6.\mathcal{L}{\mathrm{c b}}=\frac{1}{M}\sum{m=1}^{M}\frac{1}{6}\left\|\mathbf{b}{m}^{\mathrm{p}}-\mathbf{b}{m}^{\mathrm{t}}\right\|{1},\quad\mathbf{b}{m}^{(\cdot)}\in\mathbb{R}^{6}.Lcb=M1m=1∑M61 bmp−bmt 1,bm(⋅)∈R6.
这里 MMM 表示语义部件的数量。对于部件 mmm,预测框和真实框为 bmp,bmt∈R6\mathbf{b}{m}^{\mathrm{p}},\mathbf{b}{m}^{\mathrm{t}}\in\mathbb{R}^{6}bmp,bmt∈R6,参数化为 xmin,ymin,zmin,xmax,ymax,zmaxx_{min}, y_{min}, z_{min}, x_{max}, y_{max}, z_{max}xmin,ymin,zmin,xmax,ymax,zmax。该损失鼓励部件在规范空间中占据连贯的空间范围,用更紧密的几何正则化补充分布级锚定。
3.3.3. 完整训练目标
完整训练目标公式化为:
Ltotal=λh⋅Lh+λca⋅Lca+λcb⋅Lcb,\mathcal{L}{\mathrm{t o t a l}}=\lambda{h}\cdot\mathcal{L}{h}+\lambda{c a}\cdot\mathcal{L}{c a}+\lambda{c b}\cdot\mathcal{L}_{c b},Ltotal=λh⋅Lh+λca⋅Lca+λcb⋅Lcb,
其中 λh = 1, λca = 10, and λcb = 3\lambda_{h}\;=\;1,\;\lambda_{c a}\;=\;10,\;\mathrm{a n d}\;\lambda_{c b}\;=\;3λh=1,λca=10,andλcb=3 表示平衡权重。为了稳定收敛,我们采用两阶段训练方案:在第一阶段,我们首先仅使用对齐损失 Lh\mathcal{L}{h}Lh 训练框架直到收敛。然后在第二阶段加入 Lca\mathcal{L}{c a}Lca(规范地图锚定损失)和 Lcb\mathcal{L}_{c b}Lcb(规范框校准损失)并继续训练直到收敛。
4. 实验
4.1. 实现细节
训练数据集。 我们在 3Dcompat200 语料库 2 的基础上构建了统一的规范数据集,该语料库提供了跨越 200 个类别的约 17K 个形状,并带有语义部件标注。这覆盖了日常物体类别,支持强大的泛化能力。为了训练我们的框架,我们将每个物体归一化为单位边界框,并对每个物体均匀采样 5,000 个表面点,保留 RGB 颜色和法向量。
框架。 我们采用 PointTransformerV3 23 作为主干来提取 768-D 逐点特征,并使用 SigLIP-Base/16-224 28 获取 768-D 文本嵌入。更多实现细节见补充材料。
4.2. 比较
对于可提示语义分割的比较,我们设计了涵盖数据分布、输入状态和查询形式的评估,详情如下:
评估数据集。 我们在几个公共 3D 部件分割基准上评估我们的方法和代表性的最先进基线。我们首先报告 3Dcompat200 数据集 2 的 3Dcompat-Coarse 和 3Dcompat-Fine 测试集上的结果,该数据集包含 200 个物体类别和约 2,000 个形状,分别标注了粗粒度和细粒度的部件标签。我们进一步在两个常用基准 ShapeNet-Part 27 和 PartNet-E 14 上评估性能,它们分别包含 16 和 45 个物体类别。
测试设置。 为了在开放世界条件下全面评估所提出的方法,我们考虑了实践中常见的两个关键因素:提示变化和物体姿态不确定性。为了评估对提示歧义的鲁棒性,我们为文本查询设计了两种输入模式:"{Part}"表示单词提示(例如 leg),而"{part} of a {category}"表示组合短语提示(例如 leg of a chair)。为了模拟开放世界场景中的姿态变化,我们在两种设置下评估分割:Canonical (规范),物体处于规范姿态;Rotated(旋转),物体随机旋转以模拟任意方向。
3Dcompat-Coarse 和 3Dcompat-Fine 上的结果。 表 1 报告了 3Dcompat200 数据集粗粒度和细粒度测试集上的定量结果。性能使用平均交并比(mIoU)进行评估,计算方法是对每个物体的部件 IoU 取平均,然后再对所有实例取平均。我们的方法始终优于所有基线,相比第二好的方法 Find3D 平均提升了 25.55%。与基于 2D 渲染的方法(例如 PartSLIP++ 31, PointCLIPV2 32)相比,我们的模型不仅由于其前馈机制实现了显著更快的推理速度(每个形状 0.9 秒 vs PartSLIP++ 的 2.5 分钟),而且实现了更高的分割精度。此外,与 3D 前馈方法 Find3D 13 相比(为了公平起见,我们报告了原始作者发布的模型和在我们策划的数据集上重新训练的变体的结果),我们的方法在所有测试设置中都表现出一致的改进。在粗粒度数据集上,我们的模型在规范姿态和旋转姿态下都比 Find3D 实现了 8%-11% 的绝对 mIoU 提升。在细粒度数据集上,我们在相同设置下观察到 4%-7% 的提升。这些改进突显了我们规范空间引导学习策略在增强语义理解方面的有效性,特别是在姿态变化和不同提示形式下。
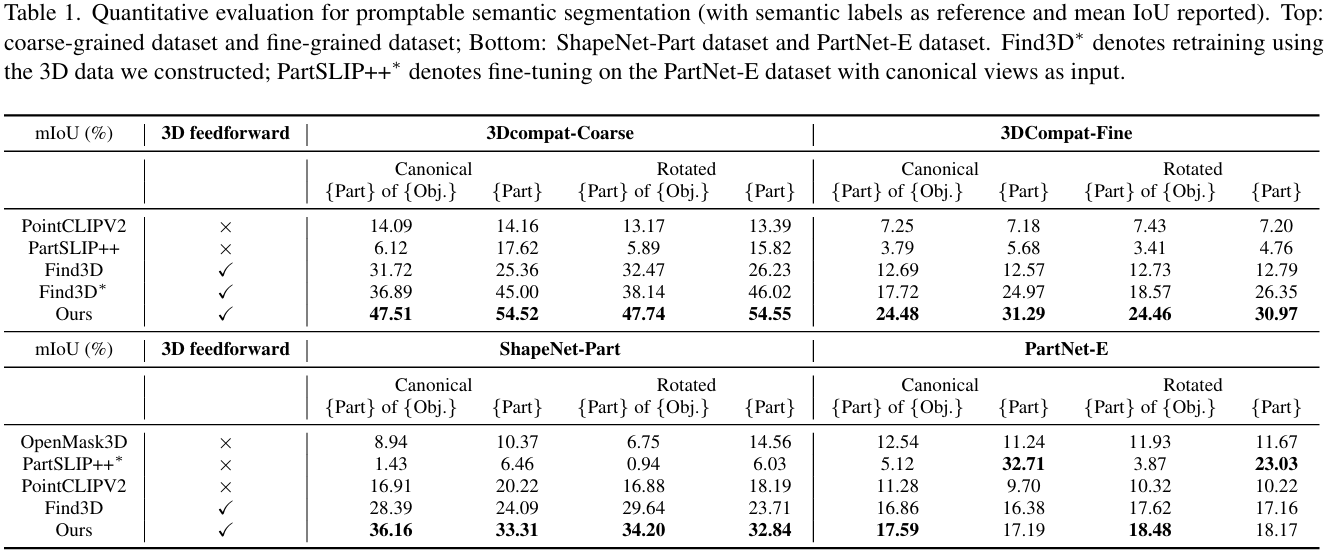
ShapeNet-Part 和 PartNet-E 上的结果。 表 1 还报告了在 ShapeNet-Part 和 PartNet-E 数据集上的实验结果。我们的方法在这两个基准上都实现了最先进(SOTA)的性能,相比表现最好的基线,在 ShapeNet-Part 上平均提升了 29.89%,在 PartNet-E 上提升了 5.01%。值得注意的是,大多数方法在 PartNet-E 上表现中等,因为其标注侧重于物体材料和细粒度细节------这些特征通常在其他 3D 语义数据集中不存在。有趣的是,PartSLIP++ 作为一种基于 2D 渲染的方法,在单词提示设置下取得了相对较好的性能。这可能归因于其骨干模型 GLIP,该模型在约 2700 万图像 - 文本对上进行了预训练,并在 PartNet-E 数据集的规范数据上进行了微调。虽然基于 2D 渲染的方法受到速度和多视图不一致性的限制,但这些观察结果强调了需要更好地从大型 2D 数据集中挖掘结构化语义先验,同时考虑其噪声标签和领域差距,并有效地利用这些知识以及有限但标注良好的 3D 分割数据。
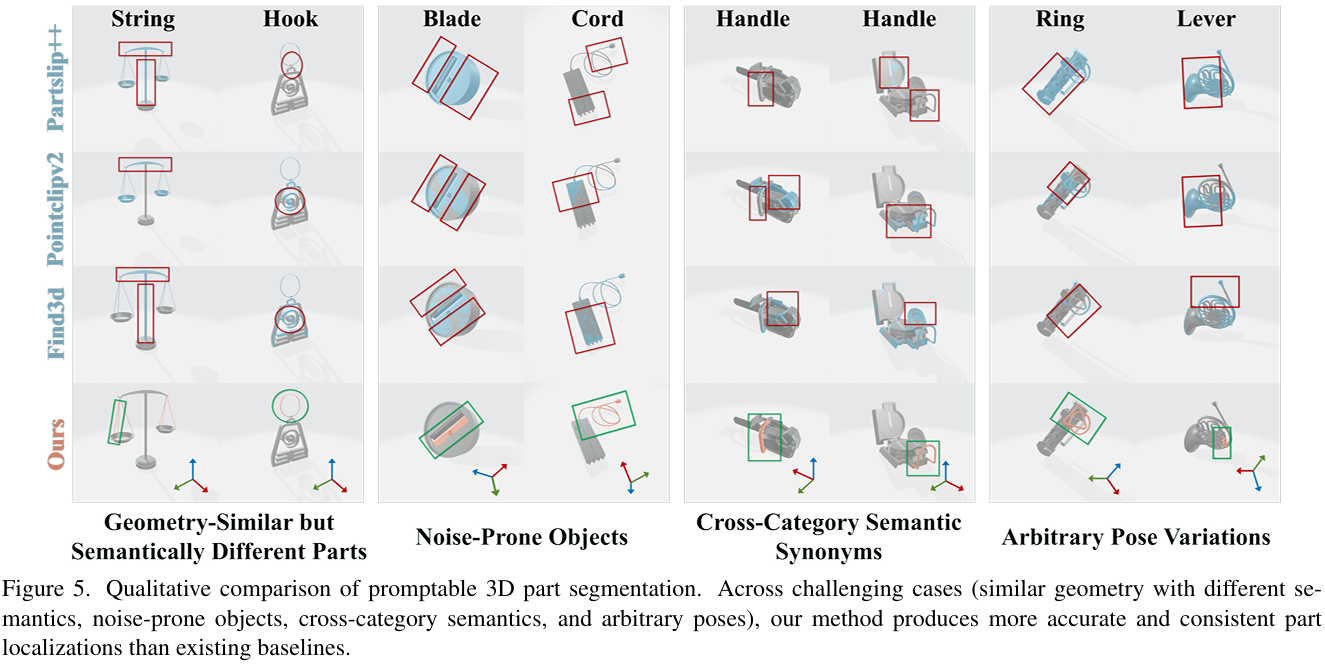
定性比较。 图 5 展示了在四种场景下与 Find3D 和基于 2D 渲染的基线的定性比较。对于几何相似但语义不同的部件(左),现有方法经常由于相似的细长形状而将字符串和钩子与物体主体混淆,而我们的模型准确地定位了每个目标部件。在易受噪声影响的物体上,小而薄的部件容易受到附近杂波的干扰,基线要么错过部件,要么预测过大的区域,而我们的预测保持紧密和稳定。对于跨类别的语义同义词,如出现在不同物体类别上的"把手",先前的方法难以跨形状迁移,经常漂移到附近区域,而我们的方法产生了与预期语义提示对齐的一致分割。最后,在任意姿态变化下,竞争方法对姿态变化敏感,而我们的框架得益于规范空间指导,在各种姿态下保持了鲁棒的定位。
4.3. 消融研究与分析
消融研究。 我们通过评估变体 A-D 和完整模型来调查每个关键组件的贡献。结果总结在表 2 中,其中变体 A 作为基线。硬负采样(变体 B)适度提高了对比对齐的鲁棒性,而规范地图锚定损失(变体 C)通过强制执行姿态鲁棒、规范空间感知的部件特征带来了更大的增益。虽然变体 A-C 都是在类别内规范化的实例上训练的,但在训练数据上进一步应用我们的跨类别规范化流水线(变体 D)在所有测试设置中 consistently 提升了性能,突显了跨类别规范监督的好处。最后,添加规范框校准损失通过约束规范分支预测的每部件规范边界框来正则化提取的特征,从而获得了最佳的整体结果。不同变体的定性分析见补充材料。
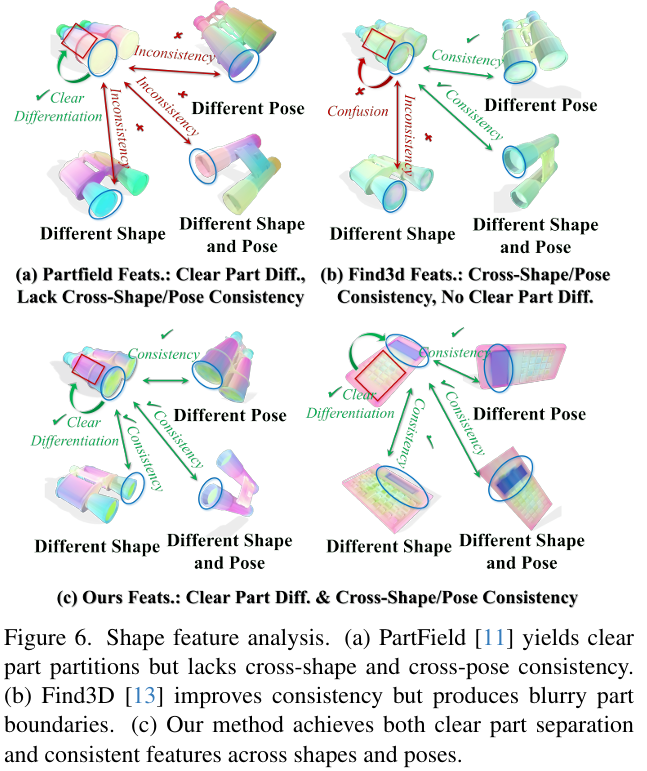
3D 形状特征分析。 为了更好地理解学习到的表示,我们在图 6 中可视化了不同方法的逐点特征。类无关分解方法 PartField 11 产生了清晰的部件划分,但其特征在形状或姿态之间不一致。Find3D 13 显示了更强的跨形状和跨姿态一致性,但特征仍未完全跨形状对齐。此外,Find3D 在单个物体内的特征缺乏清晰的部件边界,相邻部件的点经常混合。相比之下,我们的框架产生的特征既在语义上对齐又在结构上良好分离:不同部件表现出清晰的边界,并且跨形状和姿态的对应部件共享高度相似的特征模式。这种行为源于将语义部件分割与我们的规范空间正则化一起训练,这明确鼓励网络在共享的规范空间中将几何与语义对齐。因此,学习到的逐点特征表现出跨形状和跨姿态的一致性以及细粒度的部件区分,表明我们的架构有潜力作为超越特定语义分割任务的强大 3D 形状特征学习骨干。
5. 结论
我们重新审视了开放世界可提示 3D 分割,并确定规范空间是缺失的表示变量。虽然我们的公式通过潜在规范参考系实例化了这一思想,但我们相信其影响超越了可提示分割。一旦规范性成为一个可学习的对象,规范空间感知就能启用更丰富的任务:组合式 3D 问答、跨 CAD/视频领域的跨模态接地,以及在欧几里得空间行动之前先在规范空间操作的下一代 3D 智能体。我们将 CoSMo3D 不仅仅视为一个系统,而是迈向更原则性的 3D 理解栈的一步,其中规范参考是第一类的表示层。