其实在上一节 Transformer 7. Decoder:架构选择、Teacher Forcing 与并行计算,我们已经提到过掩码注意力机制:推理时我们是一个词一个词生成的,当前词不可能已经知道后面的词;若训练时让模型看到「未来词」,就会造成信息泄露,与真实推理不一致。因此 Decoder 在 softmax 前对「未来位置」的注意力分数做掩码(通常置为负无穷),使位置 i i i 只能依赖 0 ∼ i 0\sim i 0∼i,与自回归生成逻辑一致。
所以一句话来解释掩码的意义:确保在生成当前时间步的输出时,模型不能查看未来的输入。
这篇文章中,我们希望可以更进一步,从数学的角度对于掩码(自)注意力机制进行进一步的分析和解释。
1. 掩码注意力机制以及数学推导
首先,我们回到注意力公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
d k d_k dk是向量维度,比如GPT3里面12288维。
- Q: Query
- K: Key
- V: Value
此外,Q/K/V 是通过三个不同的权重矩阵 W Q W_Q WQ、 W K W_K WK、 W V W_V WV 由同一输入 X 线性变换得到:
- Q = X W Q Q = X W_Q Q=XWQ
- K = X W K K = X W_K K=XWK
- V = X W V V = X W_V V=XWV
X 的矩阵大小 :在 Decoder 的(掩码)自注意力层中,X 就是该层的输入 ,形状为 L dec × d model L_{\text{dec}} \times d_{\text{model}} Ldec×dmodel。即:
- 行数 L dec L_{\text{dec}} Ldec:Decoder 侧的目标序列长度(当前已生成的 token 个数);
- 列数 d model d_{\text{model}} dmodel:模型维度(如 512、768、12288 等)。
因此权重矩阵的维度为: W Q , W K , W V ∈ R d model × d k W_Q,\, W_K,\, W_V \in \mathbb{R}^{d_{\text{model}} \times d_k} WQ,WK,WV∈Rdmodel×dk(若 d k = d model d_k = d_{\text{model}} dk=dmodel 则均为 d model × d model d_{\text{model}} \times d_{\text{model}} dmodel×dmodel),从而 Q , K , V Q,\, K,\, V Q,K,V 的形状均为 L dec × d k L_{\text{dec}} \times d_k Ldec×dk 。Decoder 的输入是 L dec × d model L_{\text{dec}} \times d_{\text{model}} Ldec×dmodel ,经过带掩码的多头自注意力层后,输出仍然是 L dec × d model L_{\text{dec}} \times d_{\text{model}} Ldec×dmodel 的矩阵。
这里,我们先只考虑 Q, K, V 的计算。
没有掩码时的 Q K T QK^T QKT点积计算如下:
Q K T = q 1 ⋅ k 1 T q 1 ⋅ k 2 T ⋯ q 1 ⋅ k n T q 2 ⋅ k 1 T q 2 ⋅ k 2 T ⋯ q 2 ⋅ k n T ⋮ ⋮ ⋱ ⋮ q n ⋅ k 1 T q n ⋅ k 2 T ⋯ q n ⋅ k n T QK^T = \begin{bmatrix} q_1 \cdot k_1^T & q_1 \cdot k_2^T & \cdots & q_1 \cdot k_n^T \\ q_2 \cdot k_1^T & q_2 \cdot k_2^T & \cdots & q_2 \cdot k_n^T \\ \vdots & \vdots & \ddots & \vdots \\ q_n \cdot k_1^T & q_n \cdot k_2^T & \cdots & q_n \cdot k_n^T \end{bmatrix} QKT= q1⋅k1Tq2⋅k1T⋮qn⋅k1Tq1⋅k2Tq2⋅k2T⋮qn⋅k2T⋯⋯⋱⋯q1⋅knTq2⋅knT⋮qn⋅knT
进一步,没有掩码时softmax函数计算如下:
s o f t m a x ( Q K T ) = e q 1 ⋅ k 1 T ∑ j = 1 n e q 1 ⋅ k j T e q 1 ⋅ k 2 T ∑ j = 1 n e q 1 ⋅ k j T ⋯ e q 1 ⋅ k n T ∑ j = 1 n e q 1 ⋅ k j T e q 2 ⋅ k 1 T ∑ j = 1 n e q 2 ⋅ k j T e q 2 ⋅ k 2 T ∑ j = 1 n e q 2 ⋅ k j T ⋯ e q 2 ⋅ k n T ∑ j = 1 n e q 2 ⋅ k j T ⋮ ⋮ ⋱ ⋮ e q n ⋅ k 1 T ∑ j = 1 n e q n ⋅ k j T e q n ⋅ k 2 T ∑ j = 1 n e q n ⋅ k j T ⋯ e q n ⋅ k n T ∑ j = 1 n e q n ⋅ k j T softmax(QK^T) = \begin{bmatrix} \frac{e^{q_1 \cdot k_1^T}}{\sum_{j=1}^n e^{q_1 \cdot k_j^T}} & \frac{e^{q_1 \cdot k_2^T}}{\sum_{j=1}^n e^{q_1 \cdot k_j^T}} & \cdots & \frac{e^{q_1 \cdot k_n^T}}{\sum_{j=1}^n e^{q_1 \cdot k_j^T}} \\ \frac{e^{q_2 \cdot k_1^T}}{\sum_{j=1}^n e^{q_2 \cdot k_j^T}} & \frac{e^{q_2 \cdot k_2^T}}{\sum_{j=1}^n e^{q_2 \cdot k_j^T}} & \cdots & \frac{e^{q_2 \cdot k_n^T}}{\sum_{j=1}^n e^{q_2 \cdot k_j^T}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{e^{q_n \cdot k_1^T}}{\sum_{j=1}^n e^{q_n \cdot k_j^T}} & \frac{e^{q_n \cdot k_2^T}}{\sum_{j=1}^n e^{q_n \cdot k_j^T}} & \cdots & \frac{e^{q_n \cdot k_n^T}}{\sum_{j=1}^n e^{q_n \cdot k_j^T}} \end{bmatrix} softmax(QKT)= ∑j=1neq1⋅kjTeq1⋅k1T∑j=1neq2⋅kjTeq2⋅k1T⋮∑j=1neqn⋅kjTeqn⋅k1T∑j=1neq1⋅kjTeq1⋅k2T∑j=1neq2⋅kjTeq2⋅k2T⋮∑j=1neqn⋅kjTeqn⋅k2T⋯⋯⋱⋯∑j=1neq1⋅kjTeq1⋅knT∑j=1neq2⋅kjTeq2⋅knT⋮∑j=1neqn⋅kjTeqn⋅knT
有掩码时,我们使用的掩码矩阵:
M = 0 − ∞ − ∞ ⋯ − ∞ 0 0 − ∞ ⋯ − ∞ 0 0 0 ⋯ − ∞ ⋮ ⋮ ⋮ ⋱ ⋮ 0 0 0 ⋯ 0 M = \begin{bmatrix} 0 & -\infty & -\infty & \cdots & -\infty \\ 0 & 0 & -\infty & \cdots & -\infty \\ 0 & 0 & 0 & \cdots & -\infty \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \cdots & 0 \end{bmatrix} M= 000⋮0−∞00⋮0−∞−∞0⋮0⋯⋯⋯⋱⋯−∞−∞−∞⋮0
掩码矩阵 M M M 上半部分全部是负无穷、下半部分全部是零。
我们更新 Q K T → Q K T + M QK^T \rightarrow QK^T + M QKT→QKT+M:
Q K T + M = q 1 ⋅ k 1 T + 0 q 1 ⋅ k 2 T − ∞ ⋯ q 1 ⋅ k n T − ∞ q 2 ⋅ k 1 T + 0 q 2 ⋅ k 2 T + 0 ⋯ q 2 ⋅ k n T − ∞ ⋮ ⋮ ⋱ ⋮ q n ⋅ k 1 T + 0 q n ⋅ k 2 T + 0 ⋯ q n ⋅ k n T + 0 QK^T + M = \begin{bmatrix} q_1 \cdot k_1^T + 0 & q_1 \cdot k_2^T - \infty & \cdots & q_1 \cdot k_n^T - \infty \\ q_2 \cdot k_1^T + 0 & q_2 \cdot k_2^T + 0 & \cdots & q_2 \cdot k_n^T - \infty \\ \vdots & \vdots & \ddots & \vdots \\ q_n \cdot k_1^T + 0 & q_n \cdot k_2^T + 0 & \cdots & q_n \cdot k_n^T + 0 \end{bmatrix} QKT+M= q1⋅k1T+0q2⋅k1T+0⋮qn⋅k1T+0q1⋅k2T−∞q2⋅k2T+0⋮qn⋅k2T+0⋯⋯⋱⋯q1⋅knT−∞q2⋅knT−∞⋮qn⋅knT+0
= q 1 ⋅ k 1 T − ∞ − ∞ ⋯ − ∞ q 2 ⋅ k 1 T q 2 ⋅ k 2 T − ∞ ⋯ − ∞ ⋮ ⋮ ⋱ ⋮ − ∞ q n ⋅ k 1 T q n ⋅ k 2 T ⋯ q n ⋅ k n − 1 T q n ⋅ k n T = \begin{bmatrix} q_1 \cdot k_1^T & -\infty & -\infty & \cdots & -\infty \\ q_2 \cdot k_1^T & q_2 \cdot k_2^T & -\infty & \cdots & -\infty \\ \vdots & \vdots & \ddots & \vdots & -\infty \\ q_n \cdot k_1^T & q_n \cdot k_2^T & \cdots & q_n \cdot k_{n-1}^T & q_n \cdot k_n^T \end{bmatrix} = q1⋅k1Tq2⋅k1T⋮qn⋅k1T−∞q2⋅k2T⋮qn⋅k2T−∞−∞⋱⋯⋯⋯⋮qn⋅kn−1T−∞−∞−∞qn⋅knT
softmax函数的值更新如下:
softmax ( Q K T + M ) = e q 1 ⋅ k 1 T e q 1 ⋅ k 1 T 0 0 0 e q 2 ⋅ k 1 T e q 2 ⋅ k 1 T + e q 2 ⋅ k 2 T e q 2 ⋅ k 2 T e q 2 ⋅ k 1 T + e q 2 ⋅ k 2 T 0 0 e q 3 ⋅ k 1 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T e q 3 ⋅ k 2 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T e q 3 ⋅ k 3 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T 0 e q 4 ⋅ k 1 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 2 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 3 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 4 T ∑ j = 1 4 e q 4 ⋅ k j T \text{softmax}(QK^T + M) = \begin{bmatrix} \frac{e^{q_1 \cdot k_1^T}}{e^{q_1 \cdot k_1^T}} & 0 & 0 & 0 \\ \frac{e^{q_2 \cdot k_1^T}}{e^{q_2 \cdot k_1^T} + e^{q_2 \cdot k_2^T}} & \frac{e^{q_2 \cdot k_2^T}}{e^{q_2 \cdot k_1^T} + e^{q_2 \cdot k_2^T}} & 0 & 0 \\ \frac{e^{q_3 \cdot k_1^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & \frac{e^{q_3 \cdot k_2^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & \frac{e^{q_3 \cdot k_3^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & 0 \\ \frac{e^{q_4 \cdot k_1^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_2^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_3^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_4^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} \end{bmatrix} softmax(QKT+M)= eq1⋅k1Teq1⋅k1Teq2⋅k1T+eq2⋅k2Teq2⋅k1Teq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k1T∑j=14eq4⋅kjTeq4⋅k1T0eq2⋅k1T+eq2⋅k2Teq2⋅k2Teq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k2T∑j=14eq4⋅kjTeq4⋅k2T00eq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k3T∑j=14eq4⋅kjTeq4⋅k3T000∑j=14eq4⋅kjTeq4⋅k4T
softmax输出的函数右上角都是0的原因是,对于负无穷,softmax的值是0。
为什么 Q K T QK^T QKT矩阵的右上角代表模型在观察未来的信息呢?回到最初的QK相乘的图像上,假设现在Q是4行3列、K.T是3行4列,不难发现QK.T矩阵的16个因子分别是这样构成的:
Q K T = q 1 k 1 T q 1 k 2 T q 1 k 3 T q 1 k 4 T q 2 k 1 T q 2 k 2 T q 2 k 3 T q 2 k 4 T q 3 k 1 T q 3 k 2 T q 3 k 3 T q 3 k 4 T q 4 k 1 T q 4 k 2 T q 4 k 3 T q 4 k 4 T QK^T = \begin{bmatrix} q_1 k_1^T & q_1 k_2^T & q_1 k_3^T & q_1 k_4^T \\ q_2 k_1^T & q_2 k_2^T & q_2 k_3^T & q_2 k_4^T \\ q_3 k_1^T & q_3 k_2^T & q_3 k_3^T & q_3 k_4^T \\ q_4 k_1^T & q_4 k_2^T & q_4 k_3^T & q_4 k_4^T \end{bmatrix} QKT= q1k1Tq2k1Tq3k1Tq4k1Tq1k2Tq2k2Tq3k2Tq4k2Tq1k3Tq2k3Tq3k3Tq4k3Tq1k4Tq2k4Tq3k4Tq4k4T
(第 i i i 行、第 j j j 列 = 位置 i i i 对位置 j j j 的分数;下三角及对角线 i ≥ j i \geq j i≥j 为允许,上三角 j > i j>i j>i 为「看未来」)
使用更简化的写法,你会发现脚标是这样构成的:
Q K T = 1 ⋅ 1 1 ⋅ 2 1 ⋅ 3 1 ⋅ 4 2 ⋅ 1 2 ⋅ 2 2 ⋅ 3 2 ⋅ 4 3 ⋅ 1 3 ⋅ 2 3 ⋅ 3 3 ⋅ 4 4 ⋅ 1 4 ⋅ 2 4 ⋅ 3 4 ⋅ 4 QK^T = \begin{bmatrix} \boldsymbol{\color{green}{1}}\cdot\boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{1}} \cdot\boldsymbol{\color{red}{2}} & \boldsymbol{\color{green}{1}} \cdot\boldsymbol{\color{red}{3}} & \boldsymbol{\color{green}{1}} \cdot\boldsymbol{\color{red}{4}} \\ \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{red}{3}} & \boldsymbol{\color{green}{2}} \cdot \boldsymbol{\color{red}{4}} \\ \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{green}{3}} & \boldsymbol{\color{green}{3}} \cdot \boldsymbol{\color{red}{4}} \\ \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{1}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{2}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{3}} & \boldsymbol{\color{green}{4}} \cdot \boldsymbol{\color{green}{4}} \end{bmatrix} QKT= 1⋅12⋅13⋅14⋅11⋅22⋅23⋅24⋅21⋅32⋅33⋅34⋅31⋅42⋅43⋅44⋅4
下三角 保留,上三角 掩码。 \quad \text{下三角 } \text{ 保留,上三角 } \text{ 掩码。} 下三角 保留,上三角 掩码。
下三角 i ≥ j i\geq j i≥j 保留,上三角 j > i j>i j>i 掩码。
详细解释:
我们先回到 Q = X W Q Q = X W_Q Q=XWQ, K = X W K K = X W_K K=XWK, V = X W V V = X W_V V=XWV。这里,
- X X X 就是输入 (单词经过embedding后编码),形状为 L dec × d model L_{\text{dec}} \times d_{\text{model}} Ldec×dmodel
- W Q , W K , W V ∈ R d model × d k W_Q,\, W_K,\, W_V \in \mathbb{R}^{d_{\text{model}} \times d_k} WQ,WK,WV∈Rdmodel×dk 是需要训练的矩阵
- Q , K , V ∈ R L dec × d model Q,\, K,\, V \in \mathbb{R}^{L_{\text{dec}} \times d_{\text{model}}} Q,K,V∈RLdec×dmodel
如果 d k = d m o d e l = 12288 d_k=d_{model}=12288 dk=dmodel=12288, L dec = 1300 L_{\text{dec}}=1300 Ldec=1300,那么:
- X ∈ R 1300 × 12288 X \in \mathbb{R}^{1300 \times 12288} X∈R1300×12288
- W Q , W K , W V ∈ R 12288 × 12288 W_Q,\, W_K,\, W_V \in \mathbb{R}^{12288 \times 12288} WQ,WK,WV∈R12288×12288
- Q , K , V ∈ R 1300 × 12288 Q,\, K,\, V \in \mathbb{R}^{1300 \times 12288} Q,K,V∈R1300×12288
X X X 由于是单词经过embedding后编码的结果,所以 X X X 从上至下的顺序就是"从过去到未来、按句子阅读顺序"排列的顺序。极端假定 W Q = I W_Q = I WQ=I,那么 Q , K , V Q,\, K,\, V Q,K,V 和 X X X 一样,从上至下的顺序就是"从过去到未来、按句子阅读顺序"排列的顺序。以此类推, K K K 的转置 K T K^T KT 从左到右的顺序就是"从过去到未来、按句子阅读顺序"排列的顺序。
这个时候,当我们使用信息Q去询问信息K时,就有了:
- Q的脚标 = K的脚标,则Q在询问和自己在同一位置/同一时间点的信息
- Q的脚标 > K的脚标,则Q在询问在句子前方的/过去的时间点的信息
- Q的脚标 < K的脚标,则Q在询问在句子后方的/未来时间点的信息
很显然,Q的脚标 < K的脚标的情况都集中在 Q K T QK^T QKT矩阵的右上角。因此,我们为右上角加上负无穷,并在softmax函数后将该部分信息化为0,就可以避免"未来的信息"泄漏给Transformer算法。
到这里,你就明白−∞的引入、掩码矩阵的引入所具有的意义了:
- 阻止信息泄露 :在解码过程中,为了保持输出的自回归性质(即每个输出仅依赖于先前的输出),模型不能提前访问未来位置的信息。在 Q K T QK^T QKT矩阵中添加负无穷正是为了这一点,将负无穷加到某些位置上,是为了在计算注意力权重时,这些位置的影响被完全忽略。
- 影响softmax函数 :在自注意力机制中,注意力权重是通过对 Q K T QK^T QKT应用softmax函数计算得出的。当softmax函数作用于包含负无穷的值时,这些位置的指数值会趋于零,导致它们在计算最终的注意力权重时的贡献也趋于零。因此,这些未来的位置不会对当前或之前的输出产生影响。
- 保持生成顺序性:通过这种方式,Transformer能够按顺序逐个生成输出序列中的元素,每个元素的生成只依赖于之前的元素,从而有效地模拟序列生成任务中的时间顺序性和因果关系。
简而言之,将矩阵 Q K T + M QK^T + M QKT+M中的上半部分变成负无穷实际上是一种控制措施,用于保证解码器在处理如机器翻译或文本生成等任务时,不会由于未来信息的干扰而产生错误或不自然的输出。这是确保模型生成行为的正确性和效率的关键技术手段。
最后,让我们回到注意力公式,然后把 V V V 加进来:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
刚才我们推导到:softmax函数的值如下:
softmax ( Q K T + M ) = e q 1 ⋅ k 1 T e q 1 ⋅ k 1 T 0 0 0 e q 2 ⋅ k 1 T e q 2 ⋅ k 1 T + e q 2 ⋅ k 2 T e q 2 ⋅ k 2 T e q 2 ⋅ k 1 T + e q 2 ⋅ k 2 T 0 0 e q 3 ⋅ k 1 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T e q 3 ⋅ k 2 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T e q 3 ⋅ k 3 T e q 3 ⋅ k 1 T + e q 3 ⋅ k 2 T + e q 3 ⋅ k 3 T 0 e q 4 ⋅ k 1 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 2 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 3 T ∑ j = 1 4 e q 4 ⋅ k j T e q 4 ⋅ k 4 T ∑ j = 1 4 e q 4 ⋅ k j T \text{softmax}(QK^T + M) = \begin{bmatrix} \frac{e^{q_1 \cdot k_1^T}}{e^{q_1 \cdot k_1^T}} & 0 & 0 & 0 \\ \frac{e^{q_2 \cdot k_1^T}}{e^{q_2 \cdot k_1^T} + e^{q_2 \cdot k_2^T}} & \frac{e^{q_2 \cdot k_2^T}}{e^{q_2 \cdot k_1^T} + e^{q_2 \cdot k_2^T}} & 0 & 0 \\ \frac{e^{q_3 \cdot k_1^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & \frac{e^{q_3 \cdot k_2^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & \frac{e^{q_3 \cdot k_3^T}}{e^{q_3 \cdot k_1^T} + e^{q_3 \cdot k_2^T} + e^{q_3 \cdot k_3^T}} & 0 \\ \frac{e^{q_4 \cdot k_1^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_2^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_3^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} & \frac{e^{q_4 \cdot k_4^T}}{\sum_{j=1}^{4} e^{q_4 \cdot k_j^T}} \end{bmatrix} softmax(QKT+M)= eq1⋅k1Teq1⋅k1Teq2⋅k1T+eq2⋅k2Teq2⋅k1Teq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k1T∑j=14eq4⋅kjTeq4⋅k1T0eq2⋅k1T+eq2⋅k2Teq2⋅k2Teq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k2T∑j=14eq4⋅kjTeq4⋅k2T00eq3⋅k1T+eq3⋅k2T+eq3⋅k3Teq3⋅k3T∑j=14eq4⋅kjTeq4⋅k3T000∑j=14eq4⋅kjTeq4⋅k4T
d k \sqrt{d_k} dk 是一个常数,我们简化一下:
s o f t m a x ( Q K T + M d k ) = a 1 × 1 0 0 0 0 a 2 × 1 a 2 × 2 0 0 0 a 3 × 1 a 3 × 2 a 3 × 3 0 0 ⋯ ⋯ ⋯ ⋱ 0 a 1300 × 1 a 1300 × 2 a 1300 × 3 ⋯ a 1300 × 1300 softmax(\frac{QK^{T}+M}{\sqrt{d_k}}) = \begin{bmatrix} a_{1\times1} & 0 & 0 & 0 & 0 \\ a_{2\times1} & a_{2\times2} & 0 & 0 & 0 \\ a_{3\times1} & a_{3\times2} & a_{3\times3} & 0 & 0 \\ \dotsb & \dotsb & \dotsb & \ddots & 0 \\ a_{1300\times1} & a_{1300\times2} & a_{1300\times3} & \dotsb & a_{1300\times1300} \end{bmatrix} softmax(dk QKT+M)= a1×1a2×1a3×1⋯a1300×10a2×2a3×2⋯a1300×200a3×3⋯a1300×3000⋱⋯0000a1300×1300
∈ R 1300 × 1300 \in \mathbb{R}^{1300 \times 1300} ∈R1300×1300。
现在,我们把 V V V 加进来( V ∈ R 1300 × 12288 V \in \mathbb{R}^{1300 \times 12288} V∈R1300×12288):
A t t e n t i o n ( Q , K , V ) = a 1 × 1 0 0 0 0 a 2 × 1 a 2 × 2 0 0 0 a 3 × 1 a 3 × 2 a 3 × 3 0 0 ⋯ ⋯ ⋯ ⋱ 0 a 1300 × 1 a 1300 × 2 a 1300 × 3 ⋯ a 1300 × 1300 v 1 × 1 v 1 × 2 v 1 × 3 ⋯ v 1 × 12288 v 2 × 1 v 2 × 2 v 2 × 3 ⋯ v 2 × 12288 v 3 × 1 v 3 × 2 v 3 × 3 ⋯ v 3 × 12288 ⋯ ⋯ ⋯ ⋯ ⋯ v 1300 × 1 v 1300 × 2 v 1300 × 3 ⋯ v 1300 × 12288 Attention(Q,K,V) = \begin{bmatrix} a_{1\times1} & 0 & 0 & 0 & 0 \\ a_{2\times1} & a_{2\times2} & 0 & 0 & 0 \\ a_{3\times1} & a_{3\times2} & a_{3\times3} & 0 & 0 \\ \dotsb & \dotsb & \dotsb & \ddots & 0 \\ a_{1300\times1} & a_{1300\times2} & a_{1300\times3} & \dotsb & a_{1300\times1300} \end{bmatrix} \begin{bmatrix} v_{1\times1} & v_{1\times2} & v_{1\times3} & \dotsb & v_{1\times12288} \\ v_{2\times1} & v_{2\times2} & v_{2\times3} & \dotsb & v_{2\times12288} \\ v_{3\times1} & v_{3\times2} & v_{3\times3} & \dotsb & v_{3\times12288} \\ \dotsb & \dotsb & \dotsb & \dotsb & \dotsb \\ v_{1300\times1} & v_{1300\times2} & v_{1300\times3} & \dotsb & v_{1300\times12288} \end{bmatrix} Attention(Q,K,V)= a1×1a2×1a3×1⋯a1300×10a2×2a3×2⋯a1300×200a3×3⋯a1300×3000⋱⋯0000a1300×1300 v1×1v2×1v3×1⋯v1300×1v1×2v2×2v3×2⋯v1300×2v1×3v2×3v3×3⋯v1300×3⋯⋯⋯⋯⋯v1×12288v2×12288v3×12288⋯v1300×12288
计算后 :左矩阵第 i i i 行只在前 i i i 列非零,故第 i i i 行与 V V V 相乘 = 用前 i i i 行 V V V 的加权和,即位置 i i i 的输出只依赖位置 1 ∼ i 1\sim i 1∼i 的 value,与因果掩码一致。结果形状为 R 1300 × 12288 \mathbb{R}^{1300 \times 12288} R1300×12288:
A t t e n t i o n ( Q , K , V ) = a 1 × 1 v 1 × 1 a 1 × 1 v 1 × 2 ⋯ a 1 × 1 v 1 × 12288 a 2 × 1 v 1 × 1 + a 2 × 2 v 2 × 1 a 2 × 1 v 1 × 2 + a 2 × 2 v 2 × 2 ⋯ a 2 × 1 v 1 × 12288 + a 2 × 2 v 2 × 12288 a 3 × 1 v 1 × 1 + a 3 × 2 v 2 × 1 + a 3 × 3 v 3 × 1 ⋯ ⋯ ⋯ ⋮ ⋮ ⋱ ⋮ ∑ j = 1 1300 a 1300 × j v j × 1 ∑ j = 1 1300 a 1300 × j v j × 2 ⋯ ∑ j = 1 1300 a 1300 × j v j × 12288 ∈ R 1300 × 12288 Attention(Q,K,V) = \begin{bmatrix} a_{1\times1}v_{1\times1} & a_{1\times1}v_{1\times2} & \dotsb & a_{1\times1}v_{1\times12288} \\ a_{2\times1}v_{1\times1}+a_{2\times2}v_{2\times1} & a_{2\times1}v_{1\times2}+a_{2\times2}v_{2\times2} & \dotsb & a_{2\times1}v_{1\times12288}+a_{2\times2}v_{2\times12288} \\ a_{3\times1}v_{1\times1}+a_{3\times2}v_{2\times1}+a_{3\times3}v_{3\times1} & \dotsb & \dotsb & \dotsb \\ \vdots & \vdots & \ddots & \vdots \\ \sum_{j=1}^{1300}a_{1300\times j}v_{j\times1} & \sum_{j=1}^{1300}a_{1300\times j}v_{j\times2} & \dotsb & \sum_{j=1}^{1300}a_{1300\times j}v_{j\times12288} \end{bmatrix} \in \mathbb{R}^{1300 \times 12288} Attention(Q,K,V)= a1×1v1×1a2×1v1×1+a2×2v2×1a3×1v1×1+a3×2v2×1+a3×3v3×1⋮∑j=11300a1300×jvj×1a1×1v1×2a2×1v1×2+a2×2v2×2⋯⋮∑j=11300a1300×jvj×2⋯⋯⋯⋱⋯a1×1v1×12288a2×1v1×12288+a2×2v2×12288⋯⋮∑j=11300a1300×jvj×12288 ∈R1300×12288
(第 i i i 行 = ∑ j = 1 i a i × j v j × ⋅ \sum_{j=1}^{i} a_{i\times j}\, v_{j\times\cdot} ∑j=1iai×jvj×⋅,即仅由位置 1 ∼ i 1\sim i 1∼i 的 value 加权得到,不包含未来信息。)
观察这个矩阵,你发现了什么?在这个矩阵中,v上携带的信息的时间点不会超出分数a中携带的信息的时间点,权重和句子信息在交互时都只能与"过去"的信息交互,而不能与"未来"的信息交互。比如,Attention(Q,K,V)的第一行是由 a a a 的第一行( a 1 × 1 a_{1\times1} a1×1)与 v v v 的第一行产生交集(不会涉及到 v v v 的第二,三行),也就是说, a a a 的现在时不会和 v v v 的未来式产生交集。
通过这种方式,你可以看到最终带掩码的注意力机制是如何实现未来信息的不泄露的。
2. 普通掩码 vs 前瞻掩码
在NLP的世界中,掩码最被人熟知的作用就是掩盖未来的信息、避免序列中未来的信息被泄露到算法中,然而掩码(Masking)是一种多功能的机制,其本质是为了"掩盖信息",但并不局限于掩盖未来的信息。在注意力机制中、掩盖未来信息、不允许Q向未来的K发问的掩码被叫做"前瞻掩码"(look-ahead Masking),这里的"前瞻"正是代表了"未来"(对时间序列来说是未来的时间点、对文字序列来说是右侧的信息)。然而,掩码在Transformer中还有另一个巨大的作用,就是掩盖噪音信息,避免噪音影响注意力机制的计算。掩盖噪音的掩码是最普通的掩码之一,在NLP中它主要负责掩盖填充句子时产生的padding。
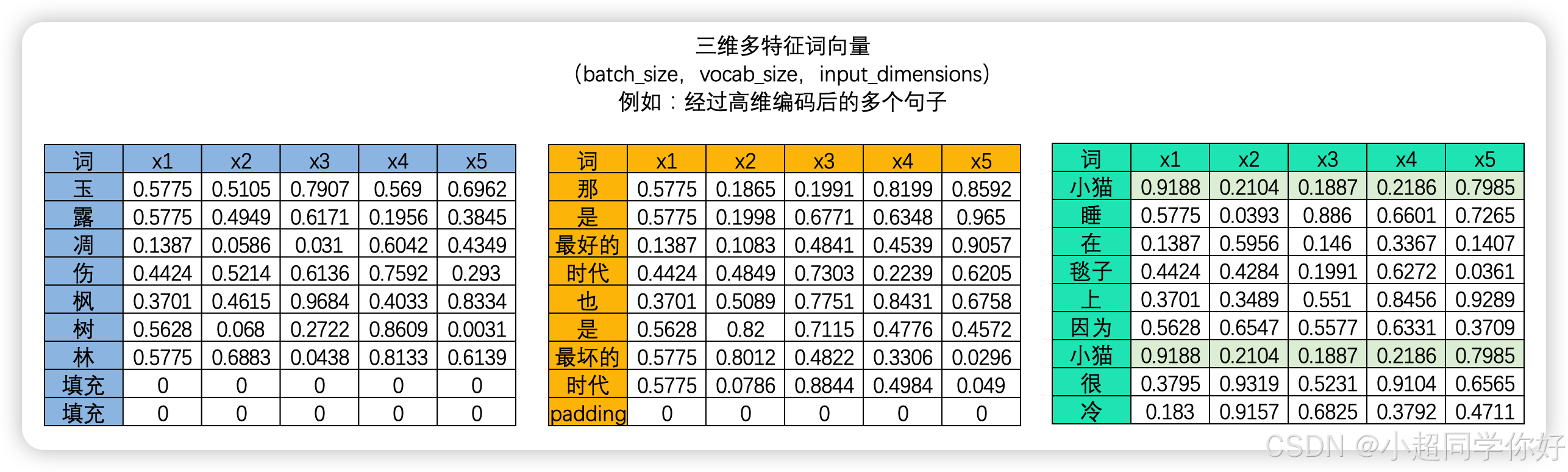
Transformer的输入数据结构为(batch_size, seq_len, input_dimensions),不同句子的seq_len必须保持一致,然而在现实中我们不太可能让每个句子的长度都一致,因此句子过长的部分我们就会截断句子、句子太短的部分我们就会使用填充。这些填充大部分都是0填充,这些0填充与其他token正常编码的结果计算之后,就会在注意力分数中留下许多的噪音值,因此在将这些信息输出之前,我们就会需要在QK.T矩阵上进行"填充掩码",来帮助注意力机制减少噪音带来的影响。
很显然,前瞻掩码通常只是解码器专属的,但是填充掩码是解码器和编码器都可以使用的。在编码器的多头注意力机制中,那个"可选的掩码"就是填充掩码机制。