因为代码合并部署原因导致代码丢失
最终致使一张target表整体缺失code字段,表自增id已经达到 6000w+条数据
要从info表拿数据根据对应关系去补充target表,这张表大概70w数据
直接执行可能会出现试试就逝世的情况
js
update target a
join info b
set a.code = b.code
where a.info_id = b.info_id
and IFNULL(a.code,'') != ''
and a.major_id = b.major_id先确定出现这种情况的具体时间吧
查了五个业务主体缺失字段的时间,推测出缺失时间是2024-10-30 上午10点左右开始的
这么久的坑 也是让我踩上了 
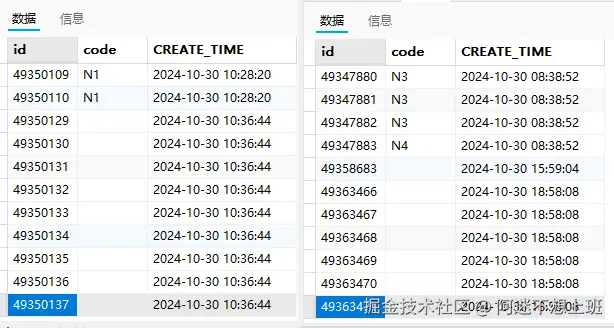
通过日期跟缺失数量再确认一下
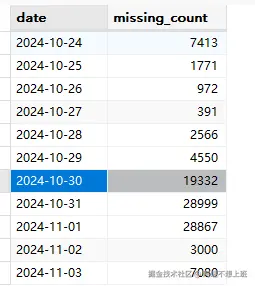
嗯,判断正确,从10月30号开始激增的
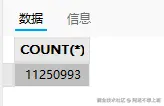
接下来count一下看看大概有多少缺失数据------1000w+
先备份 数据库,在本地环境预演一下
 改一下sql 执行
改一下sql 执行10000条看看-----111s
js
UPDATE target a
INNER JOIN info b ON a.info_id = b.info_id AND a.major_id = b.major_id
INNER JOIN (
SELECT id FROM target
WHERE IFNULL(code, '') = ''
AND create_time >= '2024-10-30 00:00:00'
LIMIT 10000
) c ON a.id = c.id
SET a.code = b.code;100w条-----159s  影响行数 是因为部分数据就是没有code,所以不是处理条数 的
影响行数 是因为部分数据就是没有code,所以不是处理条数 的10000条或者100w条
直接不加限制处理问题应该也不大,但是保险起见,还是备份 好后,晚点直接上存储过程分批处理吧
js
DROP PROCEDURE IF EXISTS batch_update_tier_with_date;
DELIMITER $$
CREATE PROCEDURE batch_update_tier_with_date(IN batch_size INT)
BEGIN
DECLARE affected_rows INT DEFAULT 1;
DECLARE total_updated INT DEFAULT 0;
DECLARE batch_num INT DEFAULT 0;
-- 创建临时表
DROP TEMPORARY TABLE IF EXISTS tmp_update_ids;
CREATE TEMPORARY TABLE tmp_update_ids (
id BIGINT PRIMARY KEY,
info_id BIGINT,
major_id BIGINT,
INDEX idx_info (info_id),
INDEX idx_major (major_id)
);
-- 一次性插入待更新 ID
INSERT INTO tmp_update_ids (id, info_id, major_id)
SELECT a.id, a.info_id, a.major_id
FROM target a
INNER JOIN info b ON a.info_id = b.info_id AND a.major_id = b.major_id
WHERE IFNULL(a.code, '') = ''
AND a.create_time >= '2024-10-30 00:00:00';
SELECT CONCAT('开始: ', NOW(), '| 总数: ', (SELECT COUNT(*) FROM tmp_update_ids)) AS start_info;
WHILE affected_rows > 0 DO
START TRANSACTION;
UPDATE target a
INNER JOIN info b ON a.info_id = b.info_id AND a.major_id = b.major_id
INNER JOIN tmp_update_ids c ON a.id = c.id
SET a.code = b.code;
LIMIT batch_size;
SET affected_rows = ROW_COUNT();
SET total_updated = total_updated + affected_rows;
SET batch_num = batch_num + 1;
DELETE FROM tmp_update_ids LIMIT batch_size;
COMMIT;
IF batch_num % 100 = 0 THEN
SELECT CONCAT('批次:', batch_num, '| 累计:', total_updated, '| 剩余:', (SELECT COUNT(*) FROM tmp_update_ids)) AS progress;
END IF;
END WHILE;
SELECT CONCAT('完成: ', NOW(), '| 批次:', batch_num, '| 总计:', total_updated) AS final_result;
DROP TEMPORARY TABLE IF EXISTS tmp_update_ids;
END$$
DELIMITER ;
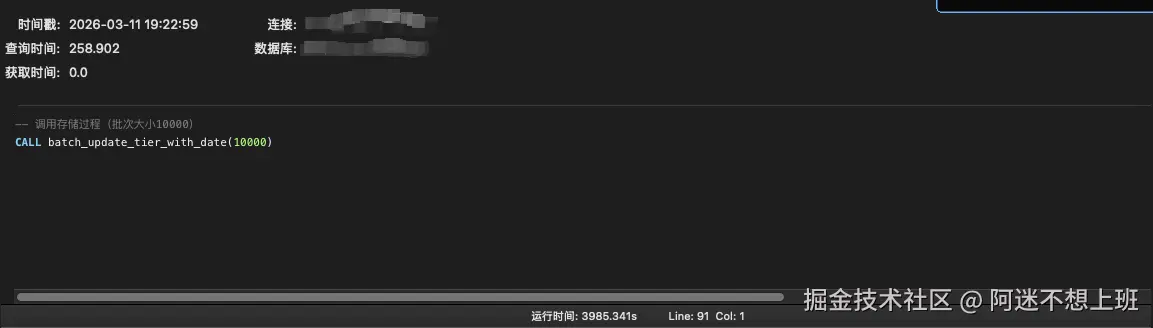
CALL batch_update_tier_with_date(10000);还蛮久的 3985s也就是66min
如果不嫌麻烦可以直接多跑几次sql,比过程要快很多