大模型的使用和Prompt-Tuning
- 如何使用通义千问大模型
-
- 获取API-KEY
- 配置API
- [使用DashScope SDK调用通义千问模型](#使用DashScope SDK调用通义千问模型)
-
- [安装DashScope SDK](#安装DashScope SDK)
- 多轮对话
- 使用HTTP接口调用通义千问模型
- Prompt-Ttuning
-
- 第一步,引进必要的库
- [第二步,创建 Prompt Tuning 微调方法对应的配置](#第二步,创建 Prompt Tuning 微调方法对应的配置)
- [第三步,通过调用 get_peft_model 方法包装基础模型](#第三步,通过调用 get_peft_model 方法包装基础模型)
- 第四步,保存高效微调部分的模型权重以供模型推理
如何使用通义千问大模型
详情: 阿里云文档链接
获取API-KEY
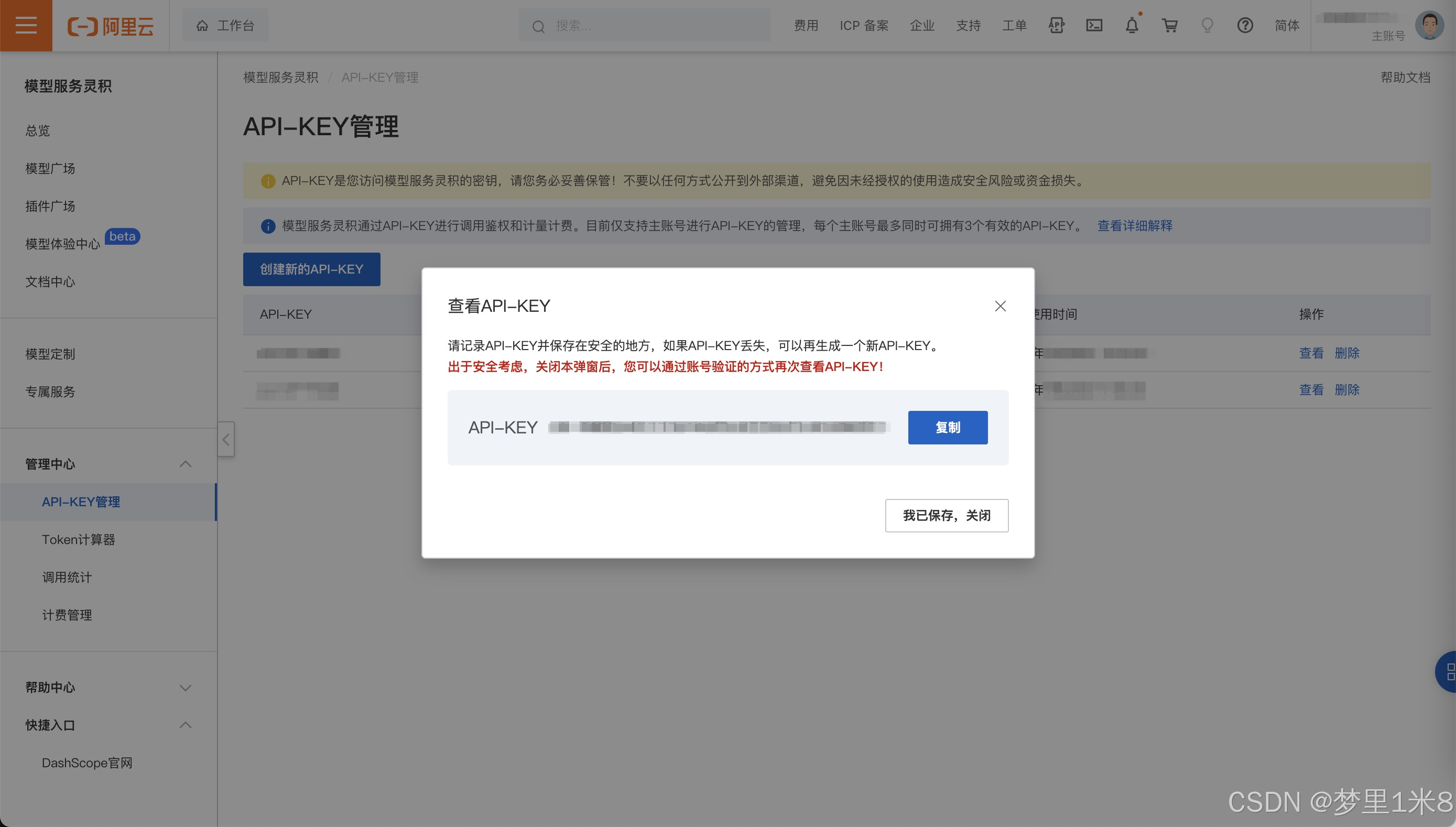
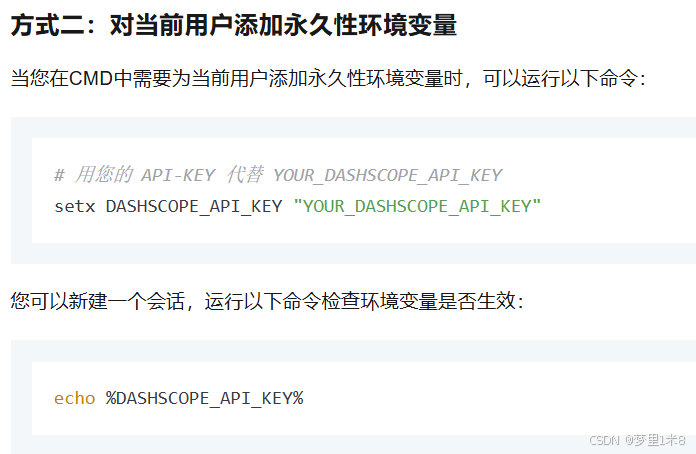
配置API
通过环境变量设置API-KEY

在代码中显式配置API-KEY
python
import dashscope
dashscope.api_key="YOUR_DASHSCOPE_API_KEY"使用DashScope SDK调用通义千问模型
安装DashScope SDK
python
pip install dashscope
python
pip install dashscope --upgrade多轮对话
python
from dashscope import Generation
def get_response(messages):
response = Generation.call(model="qwen-turbo",
messages=messages,
# 将输出设置为"message"格式
result_format='message')
return response
messages = [{'role': 'system', 'content': 'You are a helpful assistant.'}]
# 您可以自定义设置对话轮数,当前为3
for i in range(3):
user_input = input("请输入:")
messages.append({'role': 'user', 'content': user_input})
assistant_output = get_response(messages).output.choices[0]['message']['content']
messages.append({'role': 'assistant', 'content': assistant_output})
print(f'用户输入:{user_input}')
print(f'模型输出:{assistant_output}')
print('\n')使用HTTP接口调用通义千问模型
提交接口调用
python
POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation多轮对话
python
import requests
import os
api_key = os.getenv("DASHSCOPE_API_KEY")
url = 'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation'
headers = {'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'}
messages = [
{
"role": "system",
"content": "You are a helpful assistant."
}
]
# 封装模型的响应函数
def get_response(last_messages):
body = {
'model': 'qwen-turbo',
"input": {
"messages": last_messages
},
"parameters": {
"result_format": "message"
}
}
response = requests.post(url, headers=headers, json=body)
return response.json()
# 您可以在此修改对话轮数,当前为3轮对话
for i in range(3):
UserInput = input('请输入:')
messages.append({
"role": "user",
"content": UserInput
})
response = get_response(messages)
assistant_output = response['output']['choices'][0]['message']
print("用户输入:", UserInput)
print(f"模型输出:{assistant_output['content']}\n")
messages.append(assistant_output)Prompt-Ttuning
详情: 大模型微调原理与代码实战案例(一):Prompt Tuning
第一步,引进必要的库
如:Prompt Tuning 配置类 PromptTuningConfig
python
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType第二步,创建 Prompt Tuning 微调方法对应的配置
python
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=model_name_or_path,
)第三步,通过调用 get_peft_model 方法包装基础模型
python
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()第四步,保存高效微调部分的模型权重以供模型推理
模型训练的其余部分均无需更改,当模型训练完成之后,保存高效微调部分的模型权重以供模型推理即可。
python
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
