🚀 本文收录于Github:AI-From-Zero 项目 ------ 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
调用OpenClaw和调用普通API有什么区别?
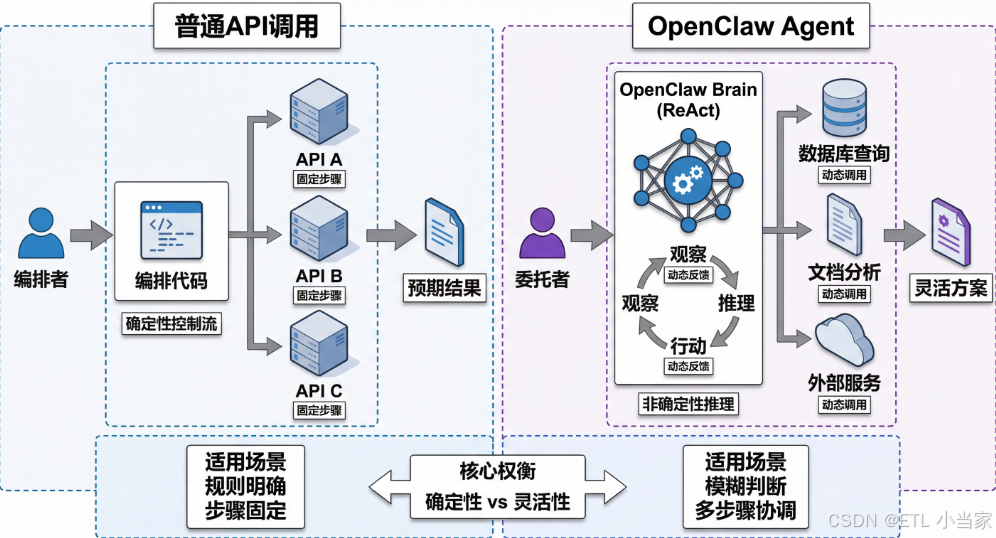
一、根本性范式转变:从编排者到委托者
普通API调用是你主动调用一个函数拿到结果,OpenClaw是你把目标告诉一个会自己决定调哪些API、按什么顺序调、出错了怎么重试的Agent,整个执行过程你不用管。
说人话就是: 想象你要去机场。传统API调用就像你详细规划好每一步:先打车到地铁站,坐3号线到市中心,换乘机场快线,步行500米到航站楼。而OpenClaw就像你告诉司机"我要去机场",司机会根据实时路况、你的偏好、当前时间等因素,自动选择最优路线,甚至在堵车时临时改道。
对一个后端工程师来说,这句话背后有一个根本性的范式转变:你不再是编排者,而是委托者。
- 以前:你写的代码决定了"先调A,再调B,如果B失败就走C"
- 现在:你只需要描述你想要的结果,OpenClaw的Brain(推理层)来做这些决策
这不是说API消失了------OpenClaw底层仍然在调用各种API。区别在于谁来决定调什么 :是你写的确定性代码,还是LLM的动态推理。
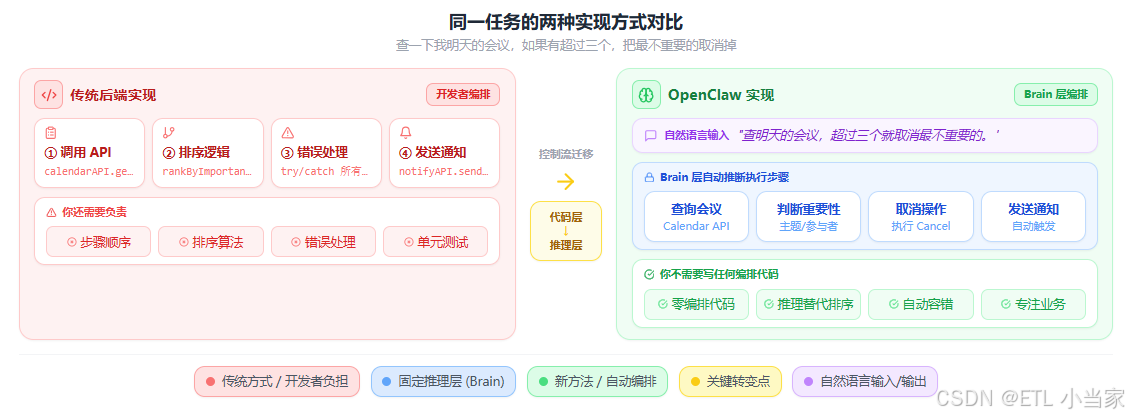
二、具体对比:同一个任务的两种实现
假设任务是:"查一下我明天的会议,如果有超过三个会议,帮我把最不重要的那个取消掉。"
传统后端实现
javascript
// 传统方式:你来编排所有逻辑
async function handleMeetingOverload() {
const meetings = await calendarAPI.getTomorrowMeetings();
if (meetings.length > 3) {
const ranked = await rankByImportance(meetings); // 你还得写这个函数
const leastImportant = ranked[ranked.length - 1];
await calendarAPI.cancelMeeting(leastImportant.id);
await notifyAPI.send(`已取消会议:${leastImportant.title}`);
}
}你需要:
- 明确写出每个步骤的顺序
- 实现重要性排序的逻辑
- 处理每个API的错误情况
- 写单元测试覆盖所有分支
OpenClaw实现
用OpenClaw,你直接用自然语言描述这个任务:
"查一下我明天的会议,如果有超过三个会议,帮我把最不重要的那个取消掉。"
Brain层自己推断出需要:
- 调用Calendar查询明天的会议
- 进行重要性判断(基于会议主题、参与者、历史行为等)
- 执行取消操作
- 发送通知
你不需要写任何编排代码。
这不是魔法,而是把控制流从代码层移到了推理层 。
三、两种模式的本质差异
| 维度 | 传统API编排 | OpenClaw Agent |
|---|---|---|
| 控制流 | 代码决定,确定性 | LLM决定,非确定性 |
| 适应新情况 | 需要改代码 | 自然语言描述即可 |
| 可测试性 | 单元测试覆盖完整 | 难以穷举测试用例 |
| 调试难度 | 堆栈清晰 | 推理过程不透明 |
| 适合场景 | 规则明确的重复任务 | 复杂、模糊、多步骤任务 |
核心权衡
- 确定性 vs 灵活性:传统API给你确定的结果,OpenClaw给你灵活的解决方案
- 可预测性 vs 适应性:传统API的行为完全可预测,OpenClaw能适应新情况但行为可能变化
- 开发成本 vs 维护成本:传统API前期开发成本高,OpenClaw前期简单但后期调试复杂
四、OpenClaw的ReAct推理循环
OpenClaw的Brain使用的是ReAct(Reasoning + Acting)模式。理解这个模式,才能真正理解它和普通函数调用的区别:
观察(Observation) → 推理(Reasoning) → 行动(Action) → 观察...关键在于每一步的结果都会反馈回Brain,让它决定下一步怎么做。这个循环一直持续到Brain判断任务完成为止。
普通API调用 vs ReAct循环
| 特性 | 普通API调用 | ReAct循环 |
|---|---|---|
| 执行模式 | 线性执行 | 闭环反馈 |
| 决策点 | 编码时确定 | 运行时动态决定 |
| 错误处理 | 预定义策略 | 动态调整策略 |
| 状态管理 | 显式变量 | 上下文记忆 |
普通API调用没有这个"观察-推理-行动"的闭环,它只是执行你写好的流程。
五、什么时候该用哪种?
理解了区别,就能理解适用场景:
继续用传统API编排,当:
- 任务规则明确:比如支付流程、订单状态机
- 步骤固定:数据ETL pipeline、定时报表生成
- 对一致性要求极高:金融交易、医疗记录处理
- 需要严格审计:合规性要求高的场景
这些场景你绝不希望LLM自由发挥。
考虑OpenClaw这类Agent,当:
- 任务涉及模糊判断:"整理工作进展"、"分析用户反馈"
- 多步骤协调:跨多个系统的复杂工作流
- 需求经常变化:业务规则频繁调整的场景
- 主观性较强:需要理解用户意图而非执行固定逻辑
比如"帮我整理这周的工作进展发给老板"------你很难用固定代码描述"整理"和"重要性判断"这类主观操作。
六、对后端工程师的启示
OpenClaw代表的不只是一个工具,而是一种新的系统设计思路:把不确定性封装在Agent层,让下游系统依然保持确定性。
你的系统架构不需要大改
- 数据库:保持原有设计
- API:保持原有接口
- 基础设施:保持原有部署
改变的是上游的编排层------从硬编码的Controller变成动态推理的Agent。
技能重心的转移
作为后端工程师,你未来更重要的技能不是写更复杂的编排逻辑,而是设计更好的Skill接口------让Agent能准确、安全地使用你提供的能力。
| 传统重点 | 新重点 |
|---|---|
| 复杂的业务逻辑编排 | 清晰的接口契约设计 |
| 详细的错误处理 | 安全的权限控制 |
| 性能优化 | 可观测性设计 |
接口设计的重要性不降反升,只是使用者从"前端/业务代码"变成了"LLM"。
这意味着你需要考虑:
- 如何让LLM准确理解你的API能力?
- 如何防止LLM误用你的API?
- 如何提供足够的上下文让LLM做出正确决策?
这既是挑战,也是机会------你正在从"功能实现者"转变为"能力提供者"。