
🎬 个人主页 :MSTcheng · CSDN
🌱 代码仓库 :MSTcheng · Gitee
🔥 精选专栏 : 《C语言》
《数据结构》
《算法学习》
《C++由浅入深》
💬座右铭: 路虽远行则将至,事虽难做则必成!
前言:上一篇文章中我们向大家介绍了,二分算法,本篇我们就来介绍一下前缀和算法。
我们通过一道例题来讲解前缀和:
一、【模板】前缀和
1.1题目解析
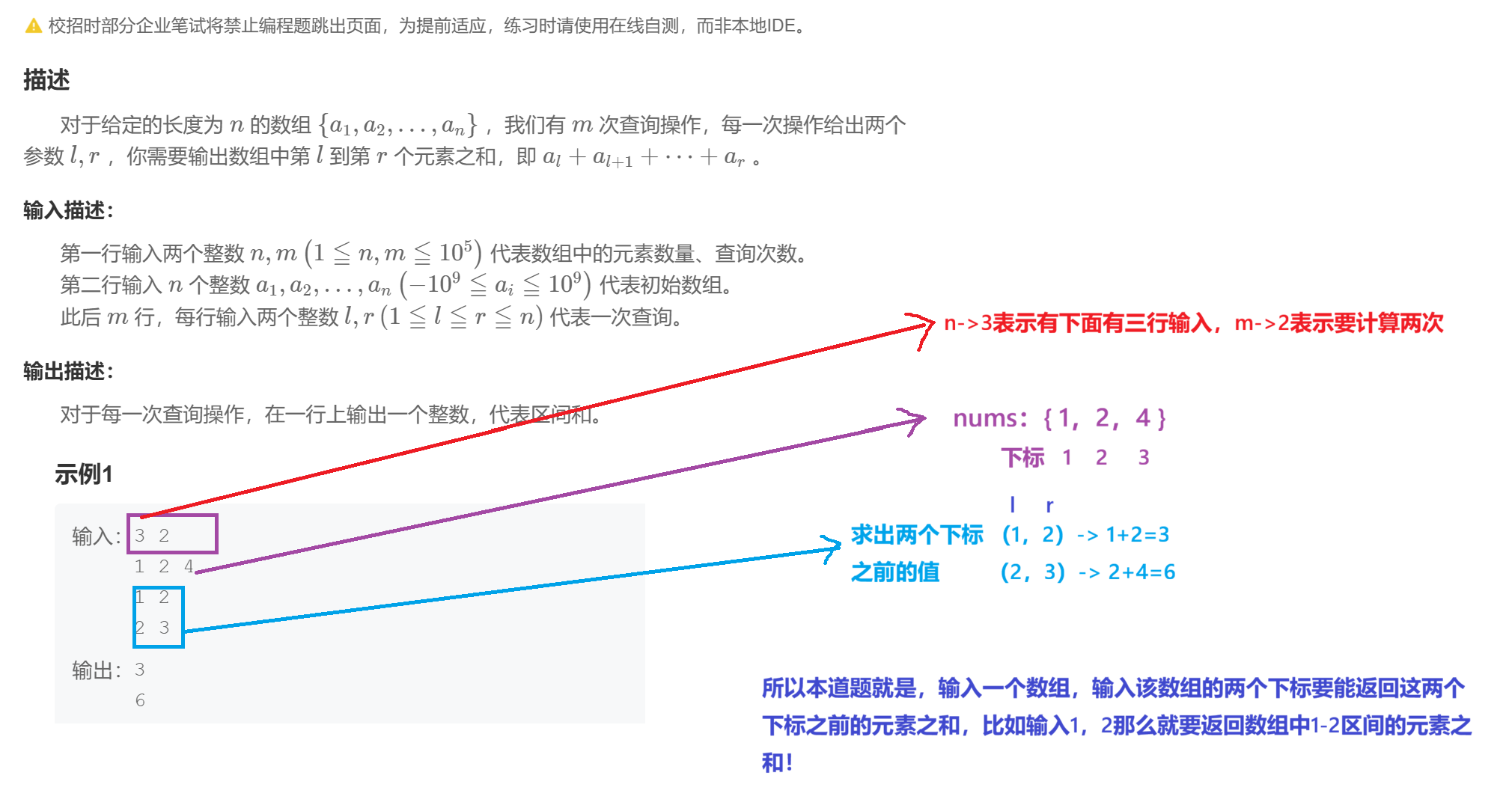
1.2算法原理
1、暴力算法
上面有一个数组,如果我们要计算某一个区间的值我们直接去暴力遍历,那么我可以计算时间复杂度为
O(N)的,然后这只是一次计算,题目中还要进行m次查询(给出多个区间),所以时间复杂度是O(n*m)。
下面来看看基于暴力算法的优化:
2、使用前缀和
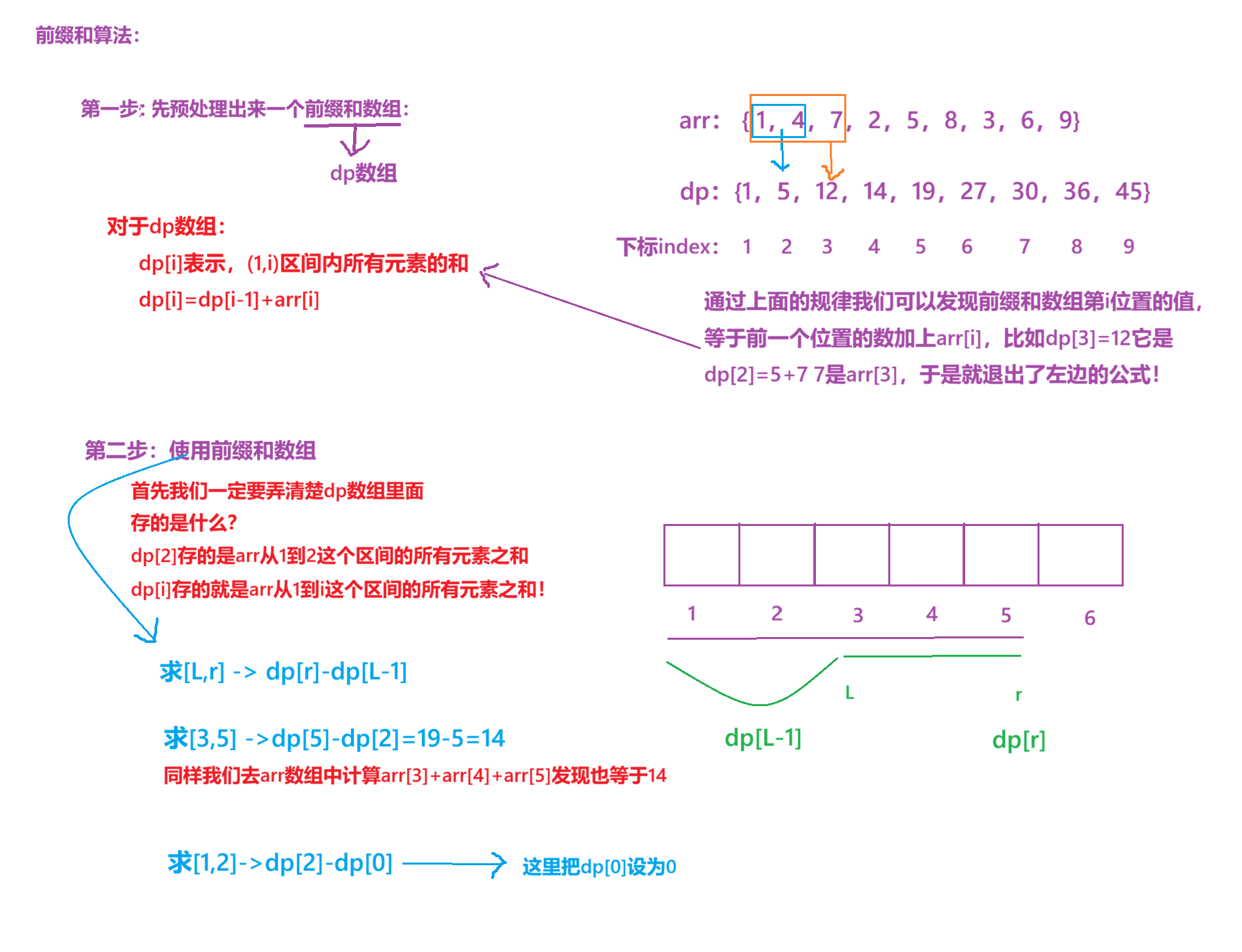
细节问题:为什么要从1开始计数?
- 为了处理边界情况,如果我们从0开始,那么要计算(0,2)区间的数不就是,
dp[2]-dp[-1]了?而-1是我们未定义的访问必然崩溃!所以dp数组下标从1开始就是为了避免这样的情况发生。 - 所以我们在设计
dp数组的时候可以给dp[0]初始化一下,将dp[0]设为0,当然不同题目的要求不同,不是所有情况都将dp[0]设为0!
3、代码编写
cpp
#include <iostream>
#include <vector>
using namespace std;
int main()
{
//输入数据
int n=0,m=0;
cin>>n>>m;
vector<int> arr(n+1);
for(int i=1;i<=n;i++)
{
cin>>arr[i];
}
//预处理出来一个前缀和数组
vector<long long> dp(n+1); //使用long long防止溢出
for(int i=1;i<=n;i++)
{
dp[i]=dp[i-1]+arr[i];
}
//使用前缀和数组
while(m--)
{
int l=0,r=0;
cin>>l>>r;
cout<<dp[r]-dp[l-1]<<endl;
}
}二、【模板】二维前缀和
2.1题目解析
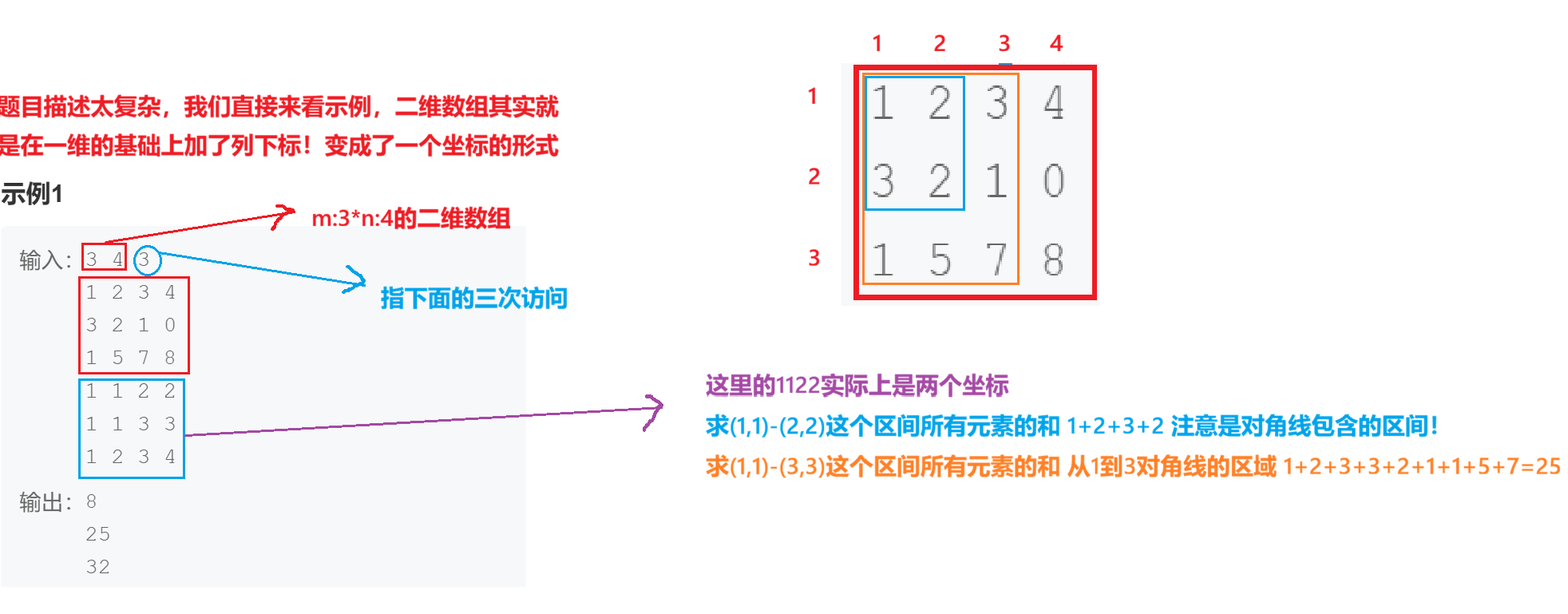
2.2算法原理
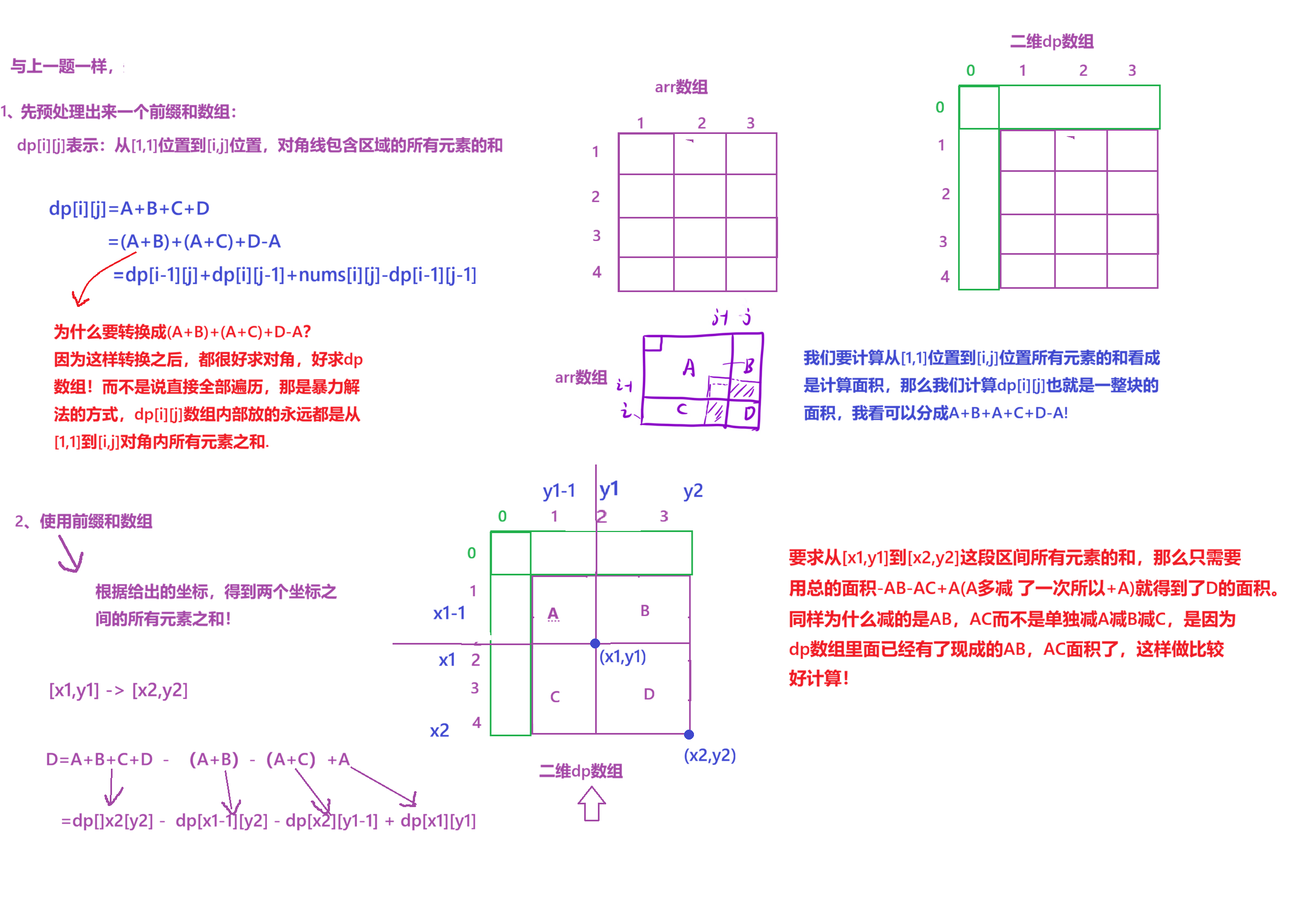
注意:
1、在二维dp数组我们在与原数组arr同等大小的规模上,在最上面和最坐标添加上一行和一列,目的就是为了防止像一维dp数组那样出现未定义的情况比如dp[-1][-1]。
2、同时我们要注意原arr数组与dp数组下面的映射关系:
- 从
dp表到arr矩阵,横纵坐标减⼀;- 从
arr矩阵到dp表,横纵坐标加⼀。
2.3代码编写
cpp
#include <iostream>
#include<vector>
using namespace std;
int main()
{
//输入数据
int n=0,m=0,q=0;
cin>>n>>m>>q;
//1、注意二维数组的初始化方式 题目要求arr数组行和列都从下标1开始
//2、使用long long 防止溢出
vector<vector<long long>> arr(n+1,vector<long long>(m+1,0));
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
cin>>arr[i][j];
}
}
//预处理出来一个前缀和数组 所以前缀和数组可以和arr数组一样大
vector<vector<long long>> dp(n+1,vector<long long>(m+1,0));
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
dp[i][j]=dp[i-1][j]+dp[i][j-1]+arr[i][j]-dp[i-1][j-1];
}
}
//使用前缀和数组 q次访问
while(q--)
{
int x1=0,y1=0,x2=0,y2=0;
cin>>x1>>y1>>x2>>y2;
long long ret=dp[x2][y2]-dp[x2][y1-1]-dp[x1-1][y2]+dp[x1-1][y1-1];
cout<<ret<<endl;
}
}注意:
但是本题的arr数组下标题目要求是从1开始的!所以与dp数组下标直接对应,我们求dp[i][j]就是求arr[1][1]到arr[i][j]所有元素的值!而不是求arr[0][0]到arr[i-1][j-1]的值! 所以本题的dp数组可以跟原数组一样大!
三、560. 和为 K 的子数组
3.1题目解析
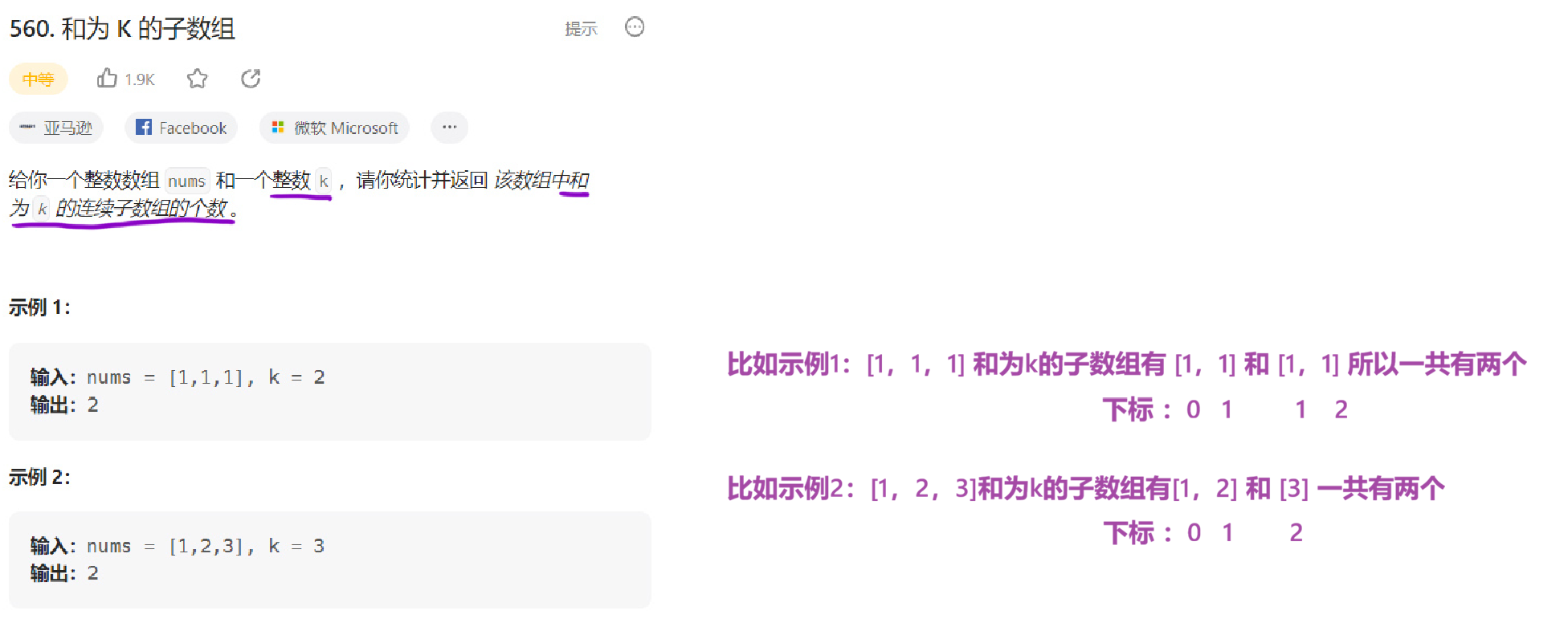
3.2算法原理
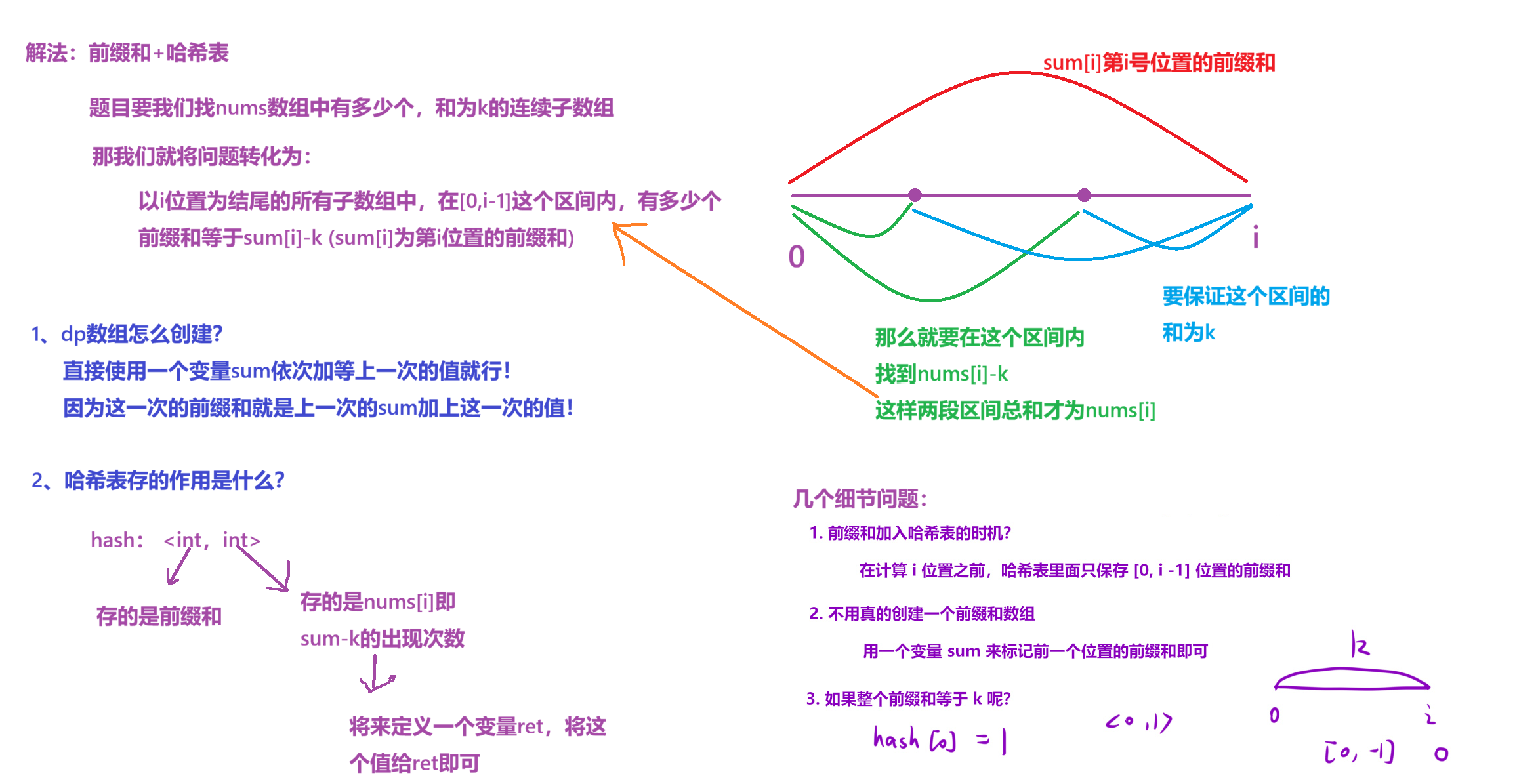
3.3代码编写
cpp
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
unordered_map<int,int> hash;
//默认第一个前缀和为1 当给出的数组已经等于k时就是一种情况 所以哈希表0的位置默认给成1
hash[0]=1;
int sum=0,ret=0; //sum计算前缀和 ret统计最终结果
for(auto& x:nums)
{
sum+=x;//sum加等x后就变成了下一次的前缀和
if(hash.count(sum-k))
{
//此时判断一下 哈希表里有没有满足sum-k 的前缀和存在 有的话ret就加等于满足sum-k 所有前缀和的次数
ret+=hash[sum-k];
}
hash[sum]++;//不断将前缀和放入哈希表
}
return ret;
}
};4、1314. 矩阵区域和
4.1题目解析
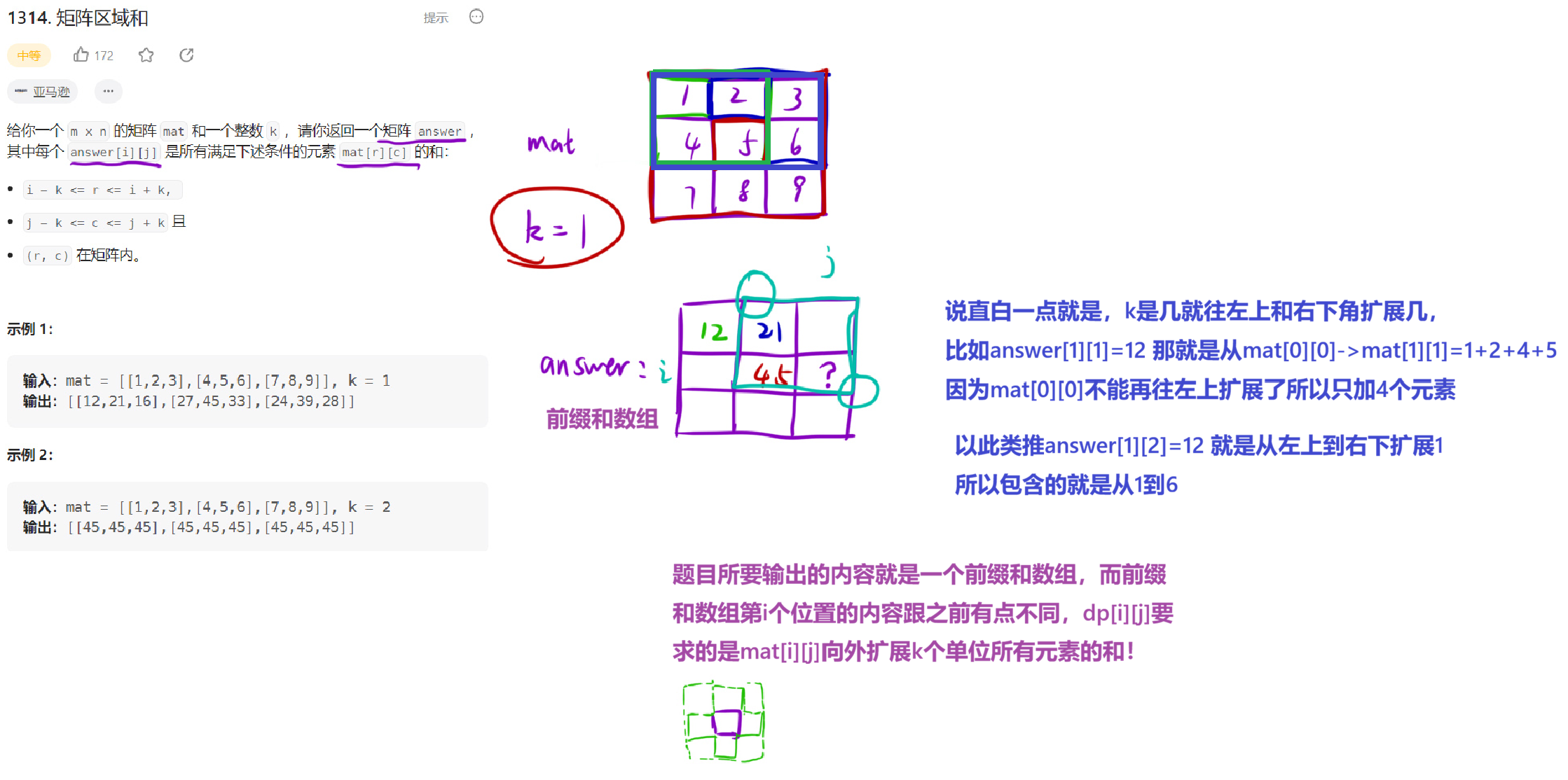
4.2算法原理
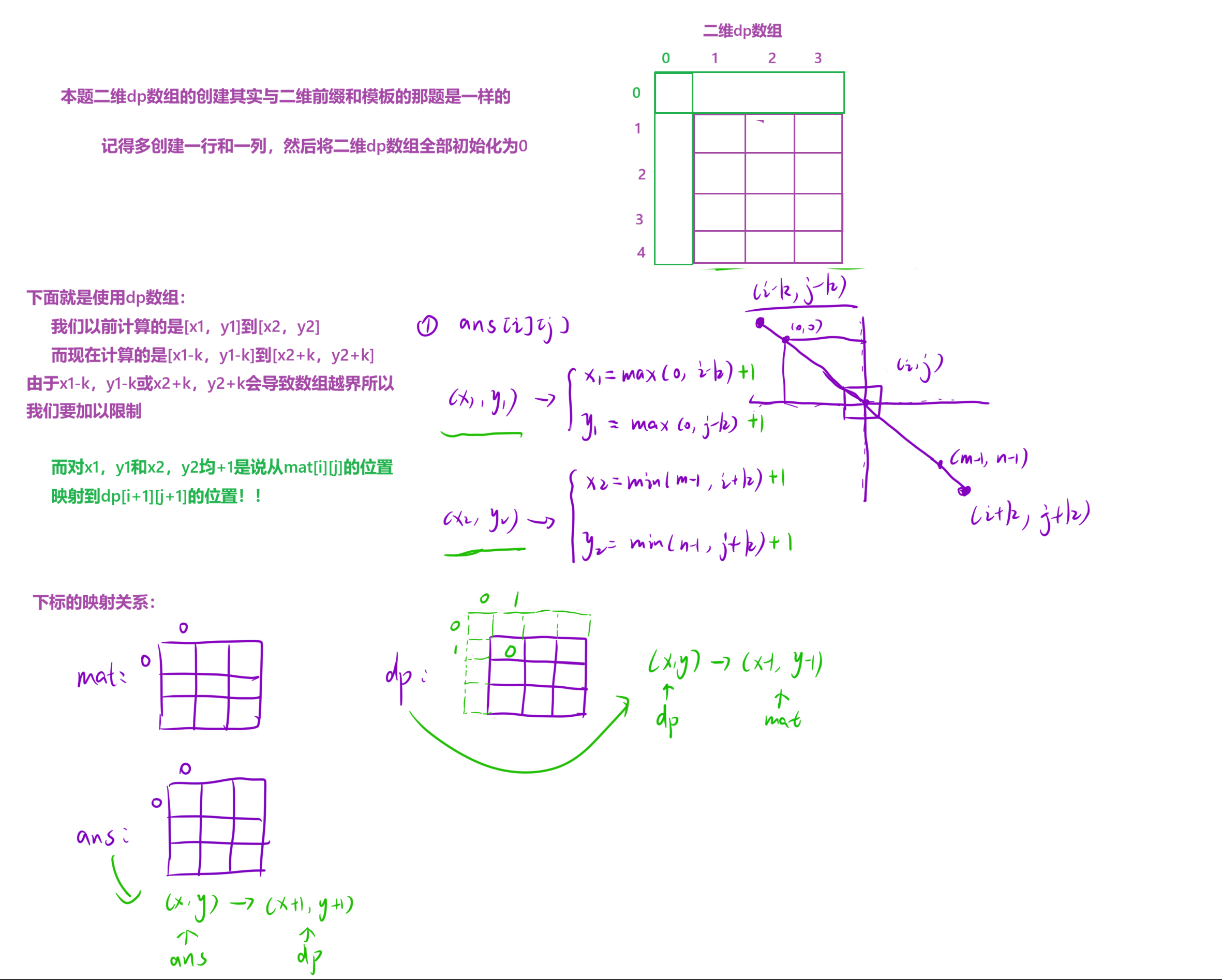
4.3编写代码
cpp
class Solution {
public:
vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k) {
//搞出一个dp数组
int m=mat.size();//m是行大小!
int n=mat[0].size();//n是列大小!
//二维数组就相当于拿n个一维(vector)来初始化
//注意dp数组要多一行多一列 因为dp数组默认从1开始
//而dp[1]存的是mat[0]周围k个元素的和
vector<vector<int>> dp(m+1,vector<int>(n+1,0));
for(int i=1;i<=m;i++)
{
for(int j=1;j<=n;j++)
{
//这里要尤为注意mat[i-1][j-1]
dp[i][j]=dp[i-1][j]+dp[i][j-1]-dp[i-1][j-1]+mat[i-1][j-1];
}
}
//使用dp数组
//创建一个ans数组
//int x1=0,y1=0,x2=0,y2=0;
vector<vector<int>> ans(m,vector<int>(n));
for(int i=0;i<m;i++)
{
for(int j=0;j<n;j++)
{
//这里的x1,x2,y1,y2都加一是因为加一才能与
//dp数组的下标对应
int x1=max(0,i-k)+1;
int y1=max(0,j-k)+1;
int x2=min(m-1,i+k)+1;
int y2=min(n-1,j+k)+1;
ans[i][j]=dp[x2][y2]-dp[x1-1][y2]-dp[x2][y1-1]+dp[x1-1][y1-1];
}
}
return ans;
}
};五、总结
一、最典型适用场景(必用前缀和)
1、多次查询区间和
给一个数组,问很多次:l, r 的和是多少→ 前缀和 O (1) 回答,不用每次遍历。
2、求有多少个子数组和 = k
最经典:nums 中有多少个子数组和为 target→ 前缀和 + 哈希表 O (n)。
3、求子数组和 ≥ k / ≤ k 的最短 / 最长长度
正数组时:前缀和 + 双指针 / 二分。
4、环形数组、连续子数组和问题 、
拆成两段和,用前缀和快速算。
5、二维矩阵里求子矩阵和
求矩形区域和 → 二维前缀和。
6、需要快速比较多个区间的和
比如判断哪段和最大 / 最小、是否相等。
看到区间和、子数组和、多次查询和 → 前缀和
会改数组 → 不用前缀和