该MATLAB代码实现了一个基于梦境优化算法(DOA)优化的CNN-GRU神经网络分类模型,并结合SHAP进行可解释性分析。
研究背景
随着深度学习在分类任务中的广泛应用,如何自动选择网络超参数并提高模型可解释性成为研究热点。本代码以CNN-GRU混合网络为基础,引入元启发式优化算法(梦境优化算法DOA)自动优化关键超参数,并采用SHAP方法评估特征重要性,旨在构建一个高效、可解释的分类模型,适用于各类带有序列或时空特征的数据集。
主要功能
- 数据预处理:加载Excel数据集,分层抽样划分训练集与测试集,归一化并重塑为适合CNN输入的格式(序列折叠)。
- 超参数优化:利用DOA算法优化CNN-GRU网络的三个关键超参数:初始学习率、GRU层隐藏节点数、L2正则化系数。
- 模型构建与训练:搭建包含卷积层、GRU层、全连接层等的深度学习网络,并使用优化后的超参数进行训练。
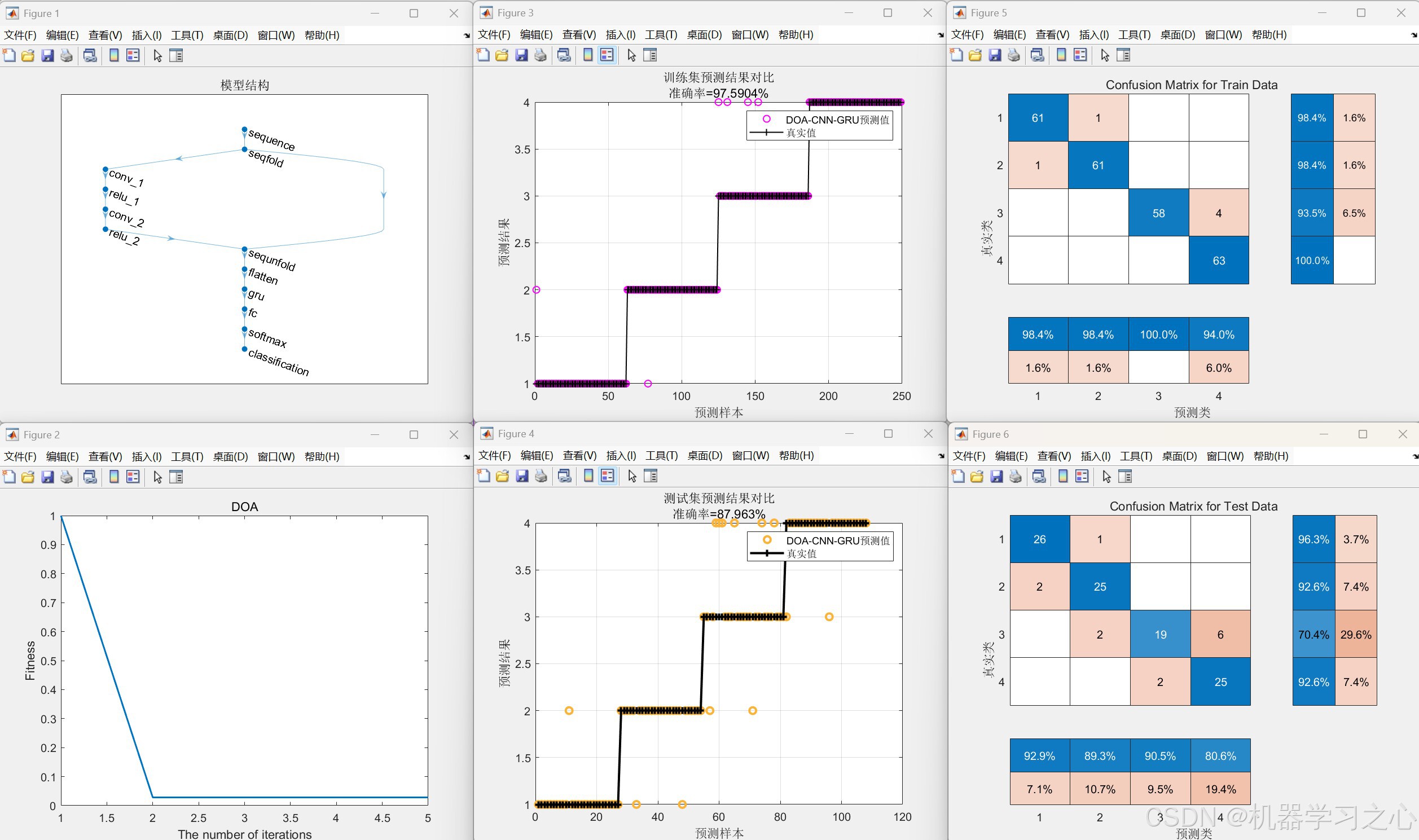
- 性能评估:计算训练集和测试集的分类准确率,绘制预测对比图、混淆矩阵及优化过程的适应度曲线。
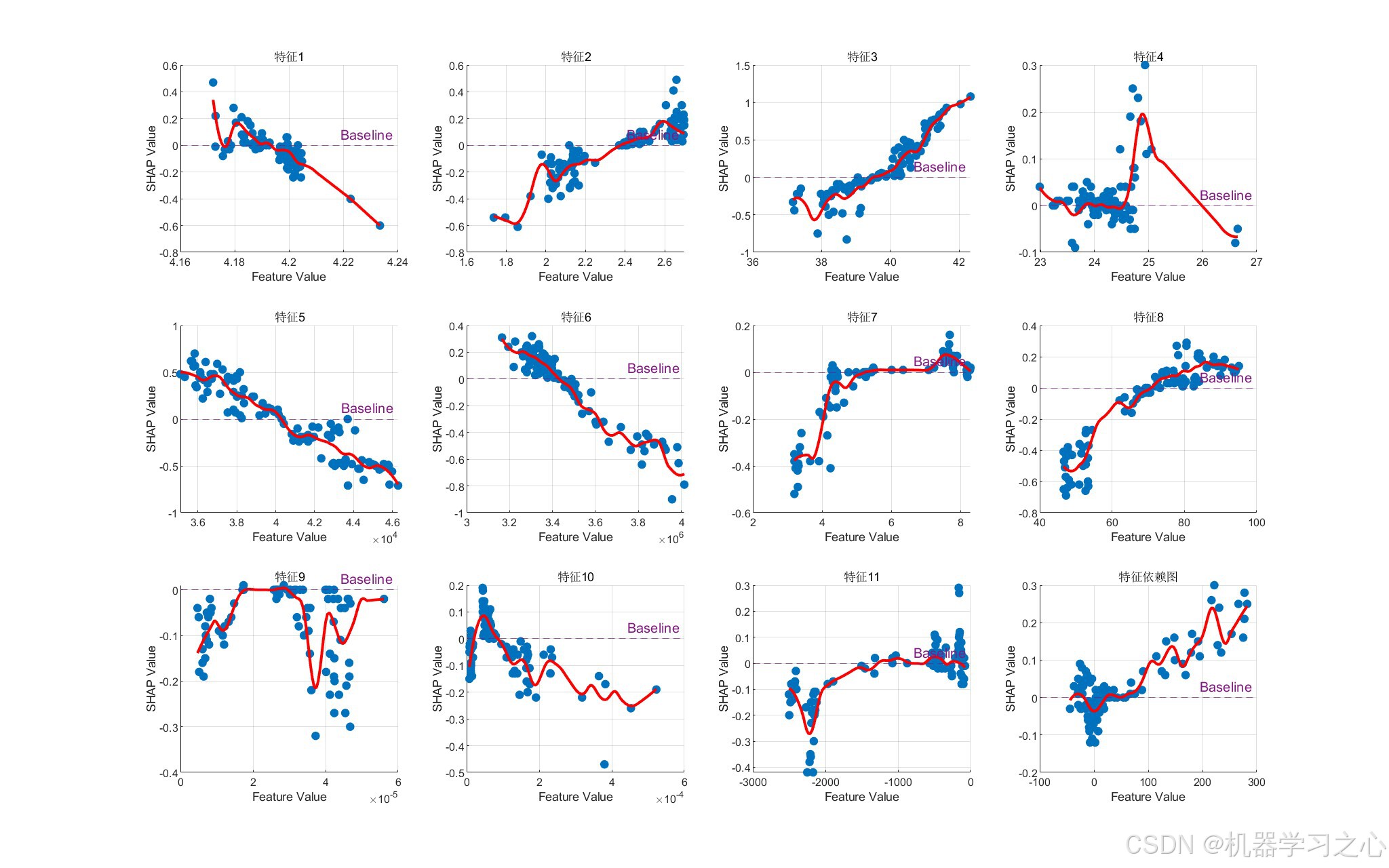
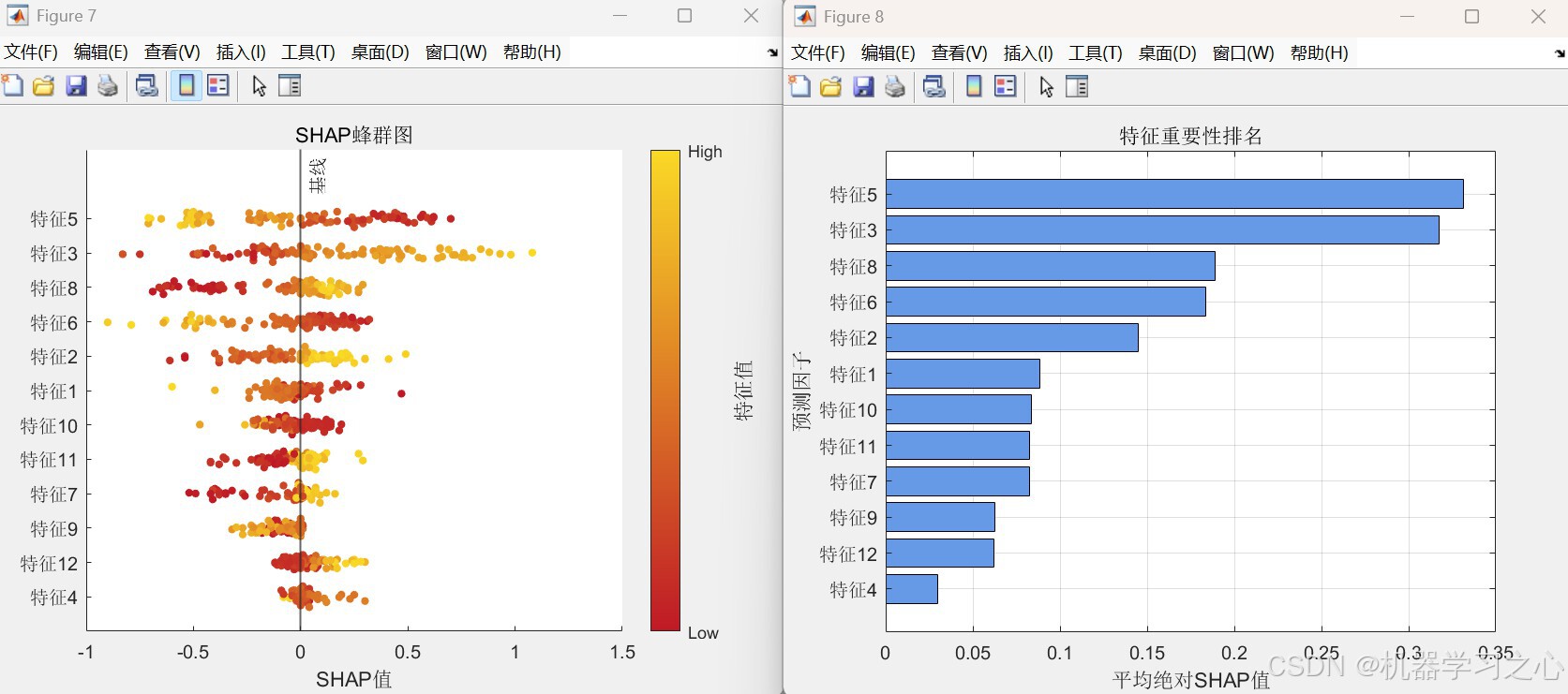
- 可解释性分析:基于测试集样本计算SHAP值,绘制特征重要性条形图、摘要图及特征依赖图,揭示各特征对模型输出的贡献。
算法步骤
- 数据准备:读取Excel,打乱样本顺序,按类别比例划分训练集(70%)和测试集(30%),归一化输入数据,转换为分类标签(categorical),并通过reshape将一维特征转换为适合卷积处理的四维张量(特征维度×1×1×样本数),最后利用序列折叠层(sequenceFoldingLayer)处理序列输入。
- 优化算法设置 :定义适应度函数fical(内部训练CNN-GRU并返回分类误差或损失),设置DOA算法参数(种群规模10、最大迭代次数5、优化维度3)及超参数搜索范围(学习率1e-31e-2、隐藏节点数1030、L2正则化1e-4~1e-1)。
- DOA优化:调用DOA函数迭代寻优,得到最佳超参数组合,其中隐藏节点数取整。
- 模型构建:使用layerGraph构建网络结构,依次添加序列输入层、序列折叠层、两层卷积+ReLU、序列展开层、扁平层、GRU层(节点数为优化值)、全连接层、softmax层和分类层。
- 模型训练:设置训练选项(Adam优化器、最大迭代500、初始学习率和L2正则化由优化得到、学习率下降策略等),使用trainNetwork训练网络。
- 预测与评价:对训练集和测试集进行预测,将输出概率转换为类别标签,计算准确率,绘制对比图和混淆矩阵。
- SHAP分析:从测试集中选取样本(默认全部),计算每个样本的SHAP值(调用shapley_1函数),绘制摘要图、特征重要性条形图和特征依赖图,分析特征对预测结果的影响。
技术路线
数据预处理 → 超参数优化(DOA) → CNN-GRU模型构建与训练 → 模型评估 → SHAP可解释性分析
公式原理
- CNN :通过卷积核提取局部特征,公式为 y=f(W∗x+b)y = f(W * x + b)y=f(W∗x+b),其中*表示卷积操作,f为ReLU激活函数。
- GRU :门控循环单元通过更新门和重置门控制信息流动,公式如下:
zt=σ(Wzxt+Uzht−1+bz)rt=σ(Wrxt+Urht−1+br)h~t=tanh(Whxt+Uh(rt⊙ht−1)+bh)ht=(1−zt)⊙ht−1+zt⊙h~t \begin{aligned} z_t &= \sigma(W_z x_t + U_z h_{t-1} + b_z) \\ r_t &= \sigma(W_r x_t + U_r h_{t-1} + b_r) \\ \tilde{h}t &= \tanh(W_h x_t + U_h (r_t \odot h{t-1}) + b_h) \\ h_t &= (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t \end{aligned} ztrth~tht=σ(Wzxt+Uzht−1+bz)=σ(Wrxt+Urht−1+br)=tanh(Whxt+Uh(rt⊙ht−1)+bh)=(1−zt)⊙ht−1+zt⊙h~t - DOA:梦境优化算法(Dream Optimization Algorithm)是一种群体智能优化方法,模拟梦境中的随机想象、记忆重构等机制,通过种群迭代更新寻找最优解。其具体迭代公式未在代码中给出,通常包含随机扰动、个体记忆和群体信息交换等操作。
- SHAP :基于博弈论中的Shapley值,计算每个特征对预测结果的边际贡献,公式为:
ϕj=∑S⊆F∖{j}∣S∣!(∣F∣−∣S∣−1)!∣F∣!fS∪{j}(xS∪{j})−fS(xS) \phi_j = \sum_{S \subseteq F \setminus \{j\}} \frac{|S|!(|F|-|S|-1)!}{|F|!} f_{S \\cup \\{j\\}}(x_{S \\cup \\{j\\}}) - f_S(x_S) ϕj=S⊆F∖{j}∑∣F∣!∣S∣!(∣F∣−∣S∣−1)!fS∪{j}(xS∪{j})−fS(xS)
其中F为所有特征集合,S为特征子集,f为模型预测值。
参数设定
- 数据集相关:训练集比例0.7,打乱数据(可注释),标志位flag_conusion=1开启混淆矩阵。
- DOA优化:种群数10,迭代次数5,优化维度3,下界1e-3,10,1e-4,上界1e-2,30,1e-1。
- 网络训练:最大迭代500,学习率下降因子0.1,下降周期400,无验证,训练过程可视化。
- SHAP分析:分析样本数numShapSamples = N(测试集样本数),特征名称默认12个(需根据实际数据修改)。
运行环境
- MATLAB R2020及以上版本
- 数据集格式:Excel文件,最后一列为类别标签,其余列为特征。
应用场景
本代码适用于需要高精度分类且对模型解释性有要求的领域,例如:
- 工业设备故障诊断(振动信号分类)
- 医疗信号处理(如心电图分类)
- 金融时间序列预测(如股票涨跌分类)
- 传感器数据模式识别
- 任何包含多维特征的小样本分类问题