目录
[什么是 Triton?](#什么是 Triton?)
[为什么需要 Triton?](#为什么需要 Triton?)
[Triton 编程基础](#Triton 编程基础)
[Triton 简介:](#Triton 简介:)
[核心 API 介绍:](#核心 API 介绍:)
[Triton Puzzles 实践](#Triton Puzzles 实践)
本节课将初步讲解 Triton 编程基础,理解并行计算在 GPU 上的实现方式。对比 CUDA 与 Triton 在编程复杂度上的差异,强调Triton的简洁性。
什么是 Triton?
-
• 嵌入在 Python 中的 DSL(领域特定语言)
-
• 专注于高效地实现高性能计算内核
-
• 编程环境基于 Python
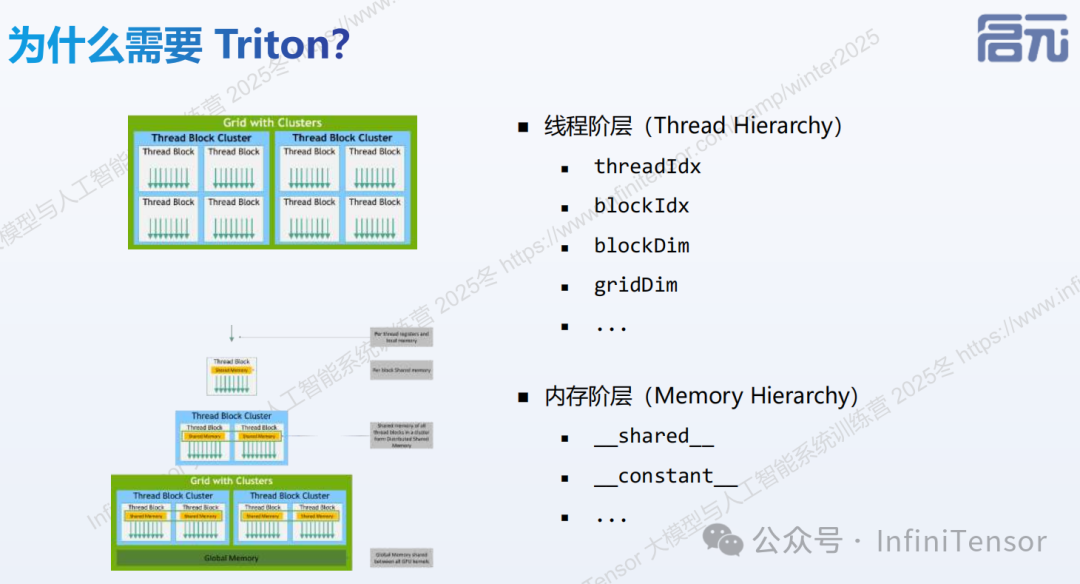
为什么需要 Triton?
-
• 底层并行编程语言往往比较复杂
-
• 需要开发者对硬件有极佳的了解

Triton 编程基础
Triton 简介:
一种用于 GPU 编程的领域特定语言(DSL),简化并行计算开发。
核心 API 介绍:
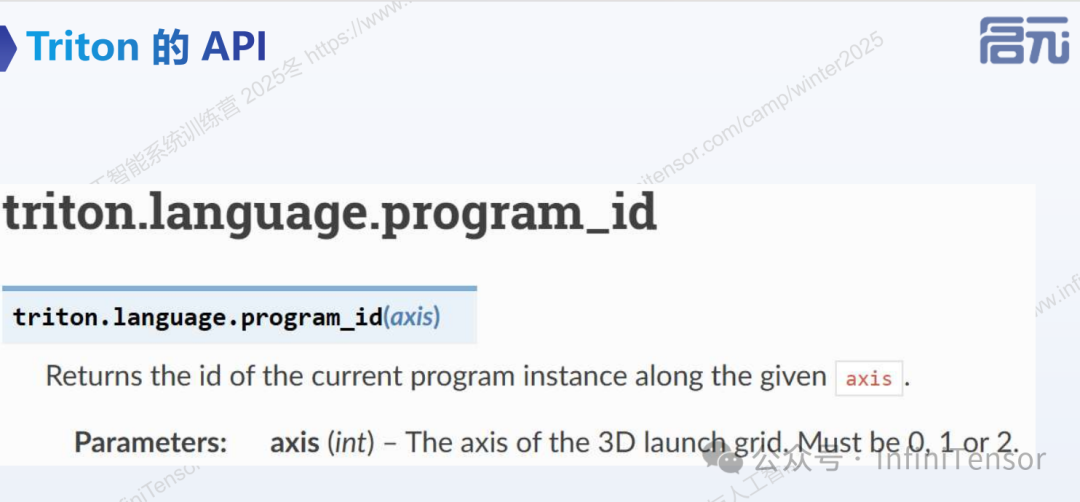
1. program_id:
-
• 获取当前程序实例的索引。
-
• 类比工厂中的工人编号,用于区分不同的并行单元。
-
• 示例代码:
tl.program_id(axis)(axis 通常为0, 1, 2对应 x, y, z 维度)。
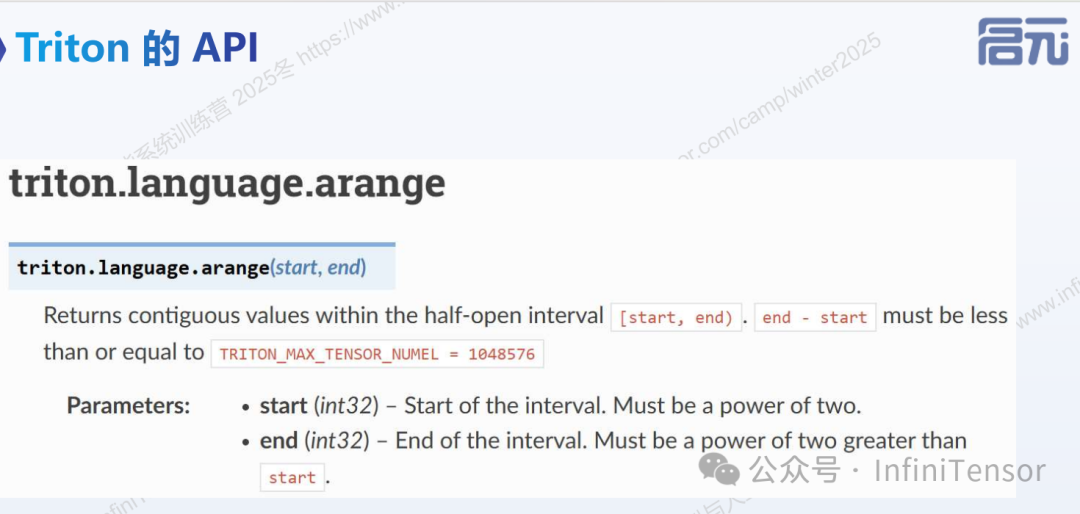
2. arange:
生成一个从 start 到 end 的连续整数向量。
示例:tl.arange(0, 8)生成向量。
3. load:
-
• 从内存中读取数据。
-
• 关键参数:pointer、mask(掩码,用于选择性读取)、other(掩码为 false 时的填充值)。
-
• 示例:加载一个向量,并根据 mask 选择性读取有效数据。
4. store:
-
• 将数据写入内存。
-
• 关键参数:pointer(目标地址指针)、value(要写入的值)、mask(掩码,控制写入位置)。
-
• 示例:将计算结果根据 mask 写入指定内存位置。
Triton编程实践
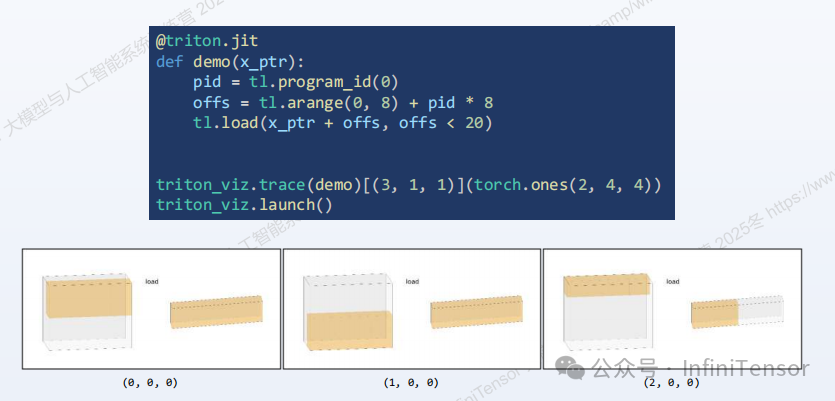
1. 基础操作演示:
-
• 使用
arange生成偏移量向量。 -
• 使用
load和store进行内存读写操作。 -
• 结合
program_id实现并行任务分配。
2. 案例分析:
-
• 向量加法:
演示如何使用 Triton 实现两个向量的逐元素加法。
强调
program_id在并行任务分配中的作用。 -
• 矩阵转置与广播:
展示如何使用多个
arange生成多维偏移量。利用广播机制实现矩阵的复杂操作。
-
• 并行计算优化:
通过
mask实现数据的选择性处理和边界条件处理。结合
program_id和arange实现高效的数据划分和并行计算。
Triton Puzzles 实践
1. 项目介绍:
-
• Triton Puzzles 是一个包含 Triton 编程示例和练习的 GitHub 仓库。
-
• 提供 Jupyter Notebook 格式的代码示例和可视化工具。
2. 实践:
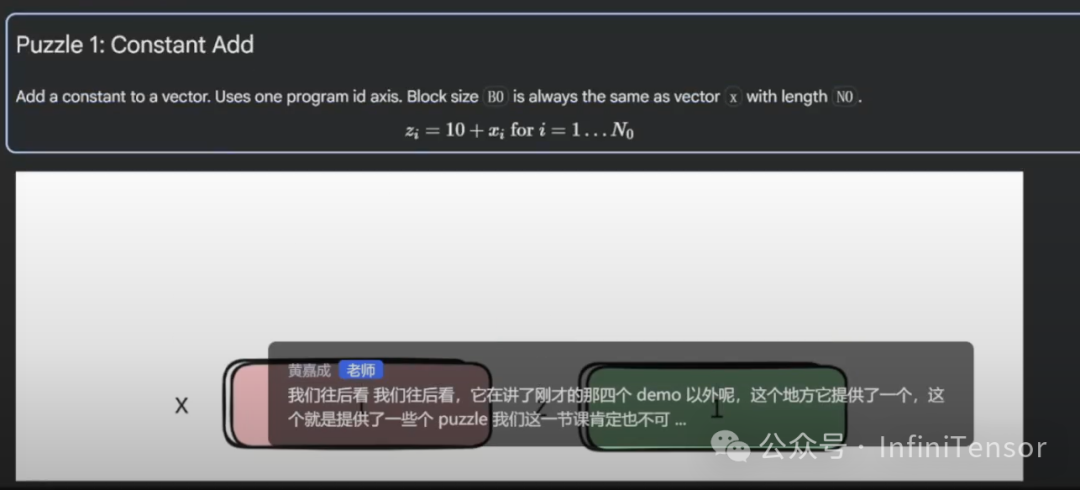
- • Constant Add:实现向量与常数的加法。
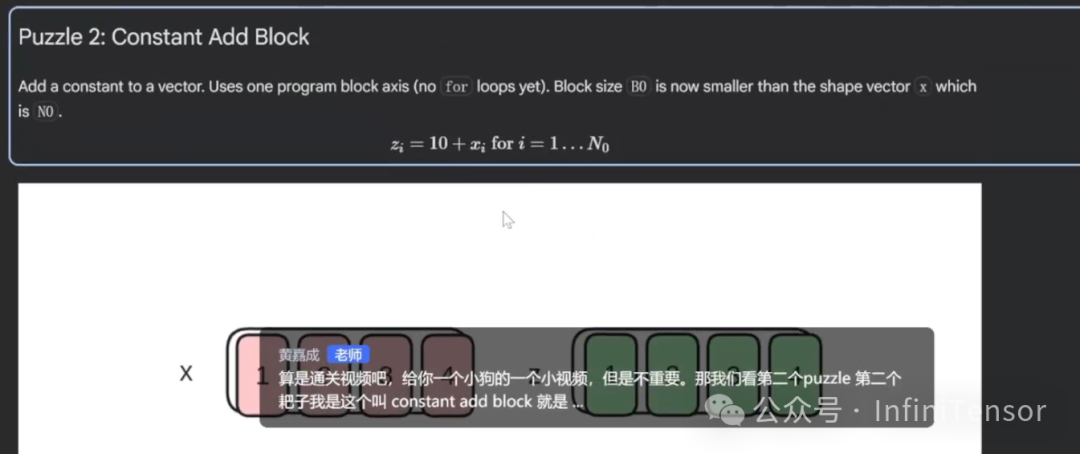
- • Constant Add Block:引入并行概念,实现分块向量加法。
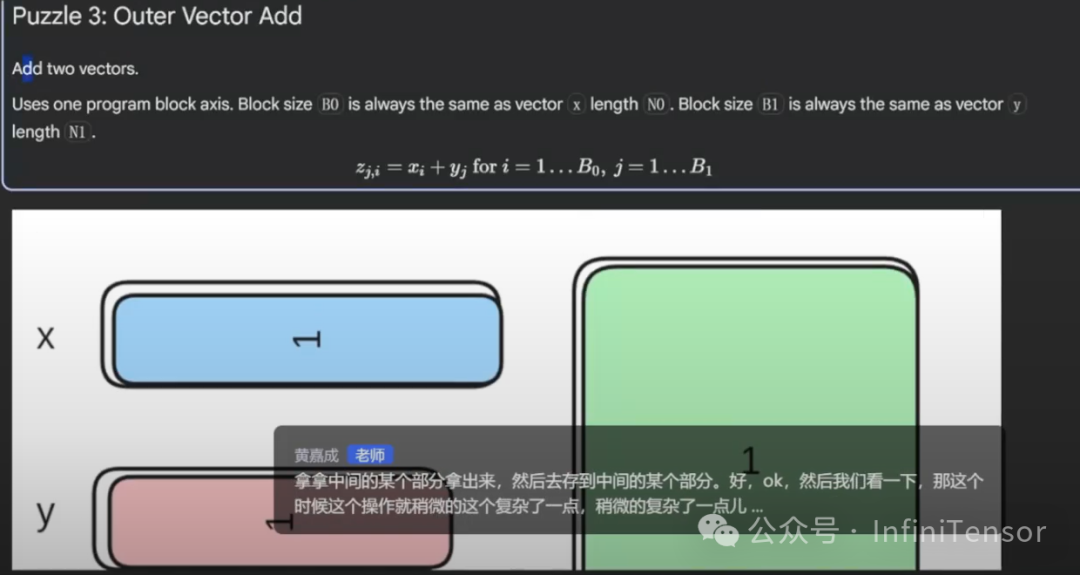
- • Outer Vector Add
- • Outer Vector Add Block

总结
本节课讲解了 Triton 的核心 API 和编程基础,强调并行计算在 GPU 编程中的重要性。建议多实践,通过编写 Triton 代码加深理解。