📖标题:Helios: Real Real-Time Long Video Generation Model
🌐来源:arXiv, 2603.04379v1
🌟摘要
我们介绍了Helios,这是第一款14B视频生成模型,在单个NVIDIA H100 GPU上以19.5 FPS的速度运行,支持分钟级生成,同时匹配强大基线的质量。我们在三个关键维度上取得了突破:(1)对长视频漂移的稳健性,无需常用的反漂移启发式方法,如自强迫、错误库或关键帧采样;(2)无需标准加速技术(如KV缓存、稀疏/线性注意力或量化)的实时生成;(3)没有并行性或分片框架的训练,支持image-diffusion-scale批量大小,同时在80 GB GPU内存内最多安装四个14B模型。具体来说,Helios是一个14B的自回归扩散模型,具有统一的输入表示,原生支持T2V、I2V和V2V任务。为了缓解长视频生成中的漂移,我们描述了典型的故障模式,并提出了简单而有效的训练策略,在训练过程中明确模拟漂移,同时从源头上消除重复运动。为了提高效率,我们大量压缩历史和嘈杂的上下文,减少采样步骤的数量,产生与1.3B视频生成模型相当或更低的计算成本。此外,我们引入了infrastructure-level优化,加速了推理和训练,同时减少了内存消耗。大量实验表明,Helios在短视频和长视频生成方面始终优于先前的方法。我们计划发布代码、基础模型和提炼模型,以支持社区的进一步开发。
🔔文章简介
🔸研究问题:如何在单张H100 GPU上实现高质量、高帧率、分钟级长度的视频自回归生成,同时避免 drifting、不依赖KV缓存与模型蒸馏等常规加速手段?
🔸主要贡献:论文提出Helios------首个14B参数量、19.5 FPS端到端推理、支持T2V/I2V/V2V统一架构的长视频生成模型,无需自强制、误差库或量化等抗漂移与加速技巧。
📝重点思路
🔸历史-噪声联合注入:将历史视频块与当前噪声块拼接为统一输入,通过历史内容的零值/单帧/多帧模式自动识别任务类型(纯文本→视频、图像→视频、视频→视频),保留预训练模型的双向建模能力。
🔸引导式注意力机制:历史部分视为干净锚点,固定其时间步为0;在自注意力中对历史键向量进行头级别动态缩放,使其精准引导未来帧生成;文本交叉注意力仅作用于噪声部分,避免语义重复注入。
🔸三重轻量抗漂移:用相对位置编码替代绝对时间索引,消除周期性导致的循环重置;始终保留首帧作为全局视觉锚点,稳定色彩与分布;训练时对每帧历史独立施加曝光调整、噪声添加或缩放扰动,提前模拟真实推理误差。
🔸分层历史压缩:将历史视频划分为近、中、远三期,分别用不同大小的时空卷积核压缩,越远的历史压缩越强,使总token数恒定,显著降低显存与计算开销。
🔸粗到细多尺度采样:将去噪过程分为低/中/高三阶段,先在小分辨率下构建整体结构,再逐级上采样细化细节,大幅减少高分辨率下的计算量。
🔸三级渐进式蒸馏:以自研的高质量长视频教师模型为基准,仅用单段生成+分阶段反向模拟+动态噪声调度+对抗增强,将50步采样压缩至3步,且全程无需真实数据回滚。
🔎分析总结
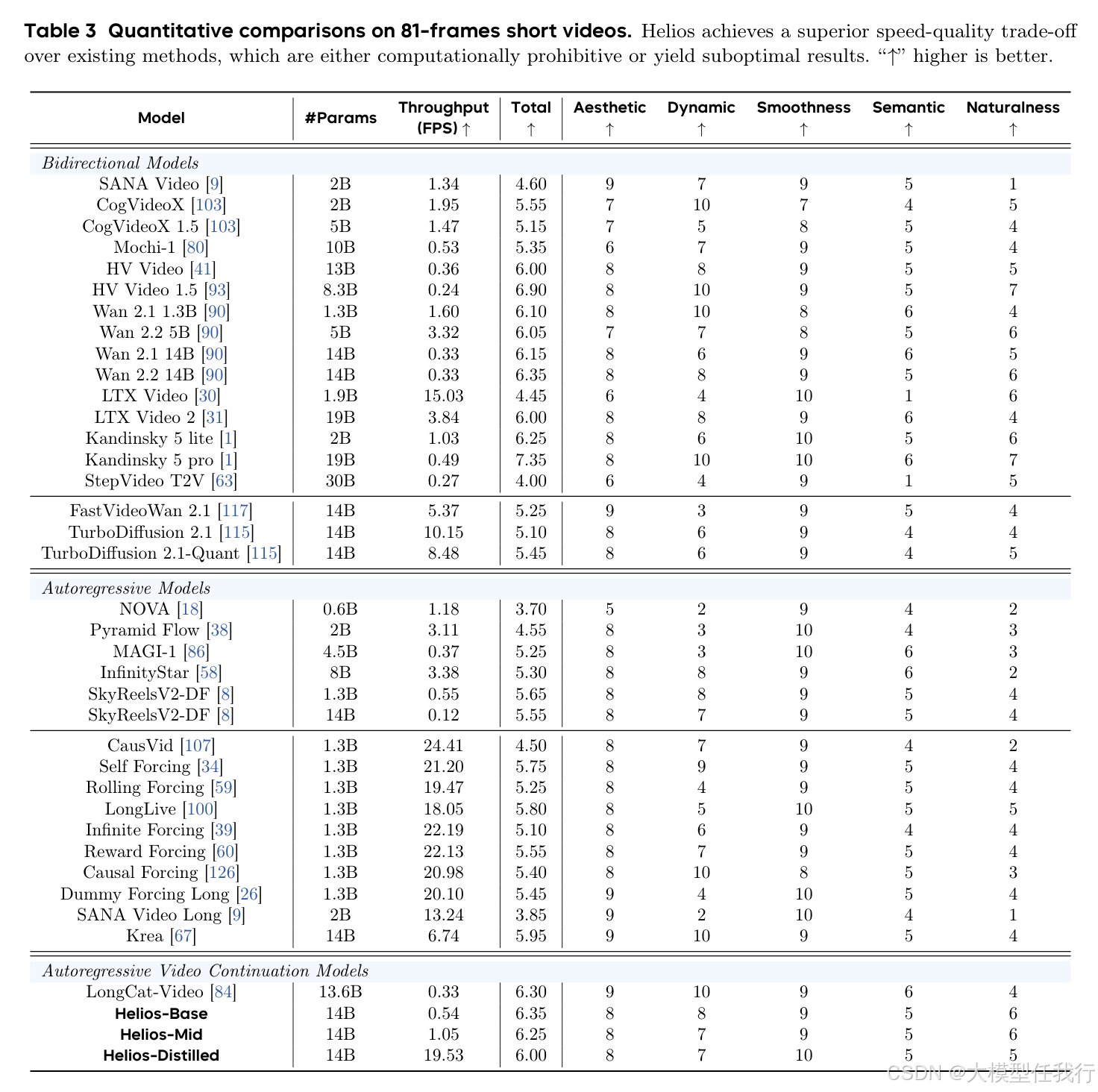
🔸Helios在1440帧(1分钟)视频上仍保持强时序一致性,无明显位置/颜色/恢复漂移,显著优于Krea-RealTime-14B等基线。
🔸端到端19.5 FPS超越多数1.3B蒸馏模型,且未使用KV-cache、稀疏注意力、量化等任何标准加速技术。
🔸单卡80GB显存可训练四套14B模型,归功于Patchification与Pyramid采样带来的token量下降(历史减8×,噪声减2.29×)及Cache Grad等内存优化。
🔸HeliosBench涵盖240个LLM精炼提示与四档时长,验证其在短/中/长视频上全面领先现有方法。
💡个人观点
论文拒绝"打补丁式优化":不靠蒸馏降步数、不靠掩码改范式、不靠分片绕瓶颈,而是从建模本质(历史注入方式)、训练策略(漂移前置模拟)、计算结构(多尺度token流)三方面协同重构。
🧩附录