前言 :随着大语言模型(LLM)上下文窗口的不断扩展(从 4K 到 100K 甚至更长),一个关键问题随之浮现:模型真的能有效利用这么长的上下文吗? 斯坦福大学与 Samaya AI 合作的这篇论文《Lost in the Middle》给出了一个令人警醒的答案:不能 。研究发现,当关键信息位于长上下文的中间部分时,模型的性能会显著下降,呈现出明显的"U型"曲线。这一发现被称为"中间迷失(Lost in the Middle)"现象,它揭示了当前长上下文模型在信息检索和利用上的巨大缺陷,对 RAG(检索增强生成)系统的设计具有深远的指导意义。
📄 论文基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Lost in the Middle: How Language Models Use Long Contexts |
| 中文译名 | 迷失于中间:语言模型如何利用长上下文 |
| 作者 | Nelson F. Liu, Kevin Lin, John Hewitt, et al. |
| 所属机构 | Stanford University, UC Berkeley, Samaya AI |
| 发表年份 | TACL 2024 |
| 核心领域 | Long-Context LLMs, Information Retrieval, Positional Bias |
| 代码/数据开源 | GitHub - nfliu/lost-in-the-middle |
研究背景与核心发现
尽管现代 LLM(如 GPT-3.5-16K, Claude-100K, LongChat)声称支持超长上下文,但在实际任务中,它们往往表现出严重的位置偏差(Positional Bias)。
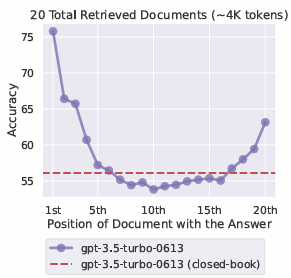
💡 核心发现:U型性能曲线
论文通过控制变量实验(改变关键信息在上下文中的位置),发现了一个普遍存在的U型性能曲线:
- 首因效应(Primacy Bias) :当关键信息位于上下文开头时,模型表现最佳。
- 近因效应(Recency Bias) :当关键信息位于上下文结尾时,模型表现也较好。
- 中间迷失(Lost in the Middle) :当关键信息位于上下文中间 时,模型性能显著下降,甚至在某些情况下低于不提供任何上下文的"闭卷(Closed-book)"模式。
典型案例 :在 20 个文档的多文档问答任务中,GPT-3.5-Turbo 在关键文档位于中间时的准确率(~54%)甚至低于其闭卷准确率(56.1%)。这意味着,提供错误的上下文位置不仅无益,反而有害。
实验设计与方法
为了验证这一现象,作者设计了两个核心任务,严格控制上下文长度和关键信息位置。
1. 多文档问答(Multi-Document QA)
- 任务描述 :给定
个文档(其中仅 1 个包含答案,其余为干扰项),要求模型回答问题。
- 变量控制 :
- 上下文长度:分别测试 10、20、30 个文档(约 2K-6K tokens)。
- 信息位置:将包含答案的文档置于第 1、5、10...直到最后一个位置。
- 数据集:NaturalQuestions-Open,使用 Contriever 检索干扰文档。
- 评估指标:答案准确率(Accuracy)。
2. 合成键值检索(Synthetic Key-Value Retrieval)
- 任务描述 :给定一个包含
- 目的:排除自然语言语义的干扰,测试模型最基础的"查找"能力。
- 变量控制:键值对数量(75, 140, 300 对),目标 Key 的位置。
3. 评估模型
涵盖主流开源与闭源模型:
- 闭源:GPT-3.5-Turbo (4K/16K), Claude-1.3 (8K/100K), GPT-4 (8K)。
- 开源:MPT-30B-Instruct (8K), LongChat-13B (16K), Flan-T5/UL2, Llama-2 (7B/13B/70B)。
🏆 实验结果深度分析
1. 普遍存在的"中间迷失"
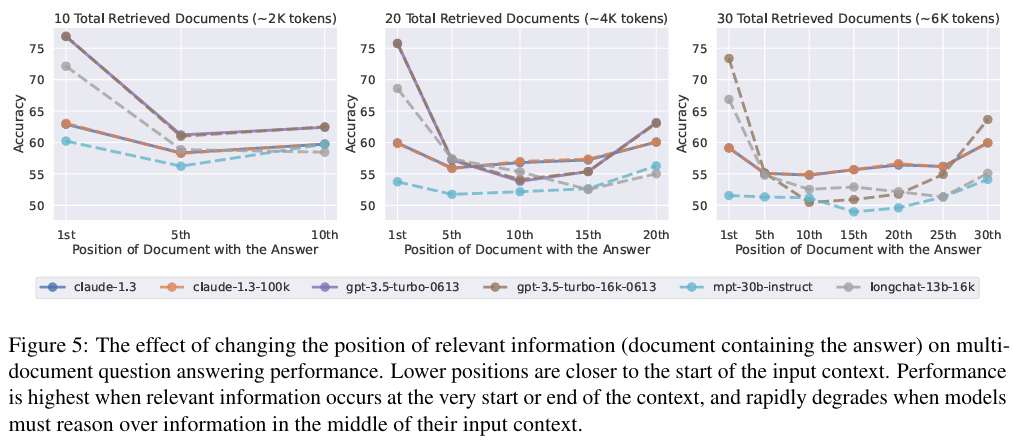
- 所有模型均受影响:无论是 GPT-3.5、Claude-100K 还是专门优化的 LongChat,无一例外地表现出 U 型曲线。
- 长窗口≠强能力 :拥有 100K 上下文的 Claude-1.3 在处理 4K 长度的输入时,其位置敏感性与普通版本无异。扩展上下文窗口并未提升模型对中间信息的利用能力。
- GPT-4 也不例外:即使是最强的 GPT-4,虽然在绝对准确率上更高,但依然遵循"两头高、中间低"的规律。
2. 键值检索任务的启示
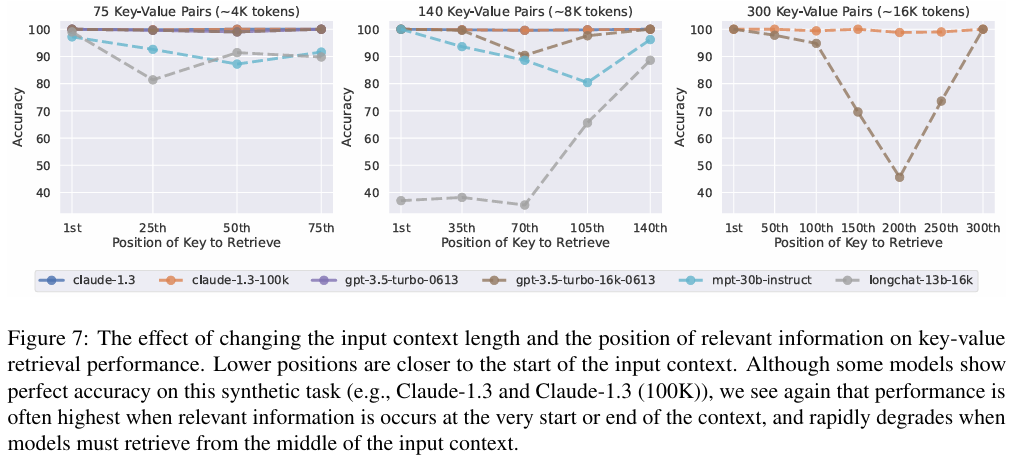
- 基础能力的缺失 :在简单的 UUID 匹配任务中,GPT-3.5 和 MPT-30B 在中间位置的错误率极高。这说明模型并非因为"理解困难"而失败,而是注意力机制本身难以聚焦于中间区域。
- 例外情况:Claude 系列在此任务上表现完美,显示出其架构或训练策略在精确检索上的独特优势,但这并未完全消除其在复杂 QA 任务中的位置偏差。
3. 影响因素探究
作者进一步分析了导致该现象的潜在原因:
(1) 模型架构(Decoder-only vs. Encoder-Decoder)
- Encoder-Decoder (如 Flan-UL2):在训练长度范围内(如 2K tokens),表现相对稳健,无明显 U 型曲线。
- 超出训练长度:一旦输入超过训练时的序列长度,Encoder-Decoder 模型也开始出现"中间迷失"。
- 结论:双向注意力机制有助于短序列的信息整合,但无法解决长序列外推时的位置偏差。
(2) 查询感知上下文(Query-Aware Contextualization)
- 策略 :将查询(Question/Key)放在文档的前面和后面(即包裹住文档),使 Decoder-only 模型能在处理文档时"看到"查询。
- 效果 :
- 键值检索:效果显著提升,几乎达到完美。
- 多文档 QA:改善微乎其微。
- 启示:简单的 Prompt 优化能解决简单检索问题,但难以解决复杂推理中的注意力分散问题。
(3) 指令微调(Instruction Fine-tuning)
- 对比:比较基座模型(Base)与指令微调模型(Instruct)。
- 发现:两者均呈现 U 型曲线。指令微调略微缩小了最佳与最差位置的差距,但未改变根本趋势。
- 规模效应:小模型(如 Llama-2-7B)主要表现为"近因偏差"(只关注结尾);大模型(13B/70B)才同时具备"首因"和"近因"偏差,形成完整的 U 型。
4. 现实场景案例:开放域问答(Open-Domain QA)
- 设置:模拟真实 RAG 场景,检索 Top-K 个维基百科文档供模型回答。
- 发现 :
- 检索召回率(Recall)随文档数增加持续上升。
- 模型准确率(Accuracy)在 Top-20 文档后迅速饱和,不再提升。
- 结论:提供更多文档(如从 20 增至 50)只会增加噪声和计算成本,模型无法有效利用新增的中间文档。这直接证明了"更多上下文 ≠ 更好效果"。
💡 主要创新点与洞察
- 揭示"中间迷失"现象:首次系统性地量化了 LLM 在长上下文中间区域的信息丢失问题,打破了"窗口越大越好"的迷思。
- 提出新的评估协议 :主张未来的长上下文模型评估必须包含位置敏感性测试,仅报告平均准确率是不够的,必须展示最佳与最差位置的性能差异。
- 架构与训练的影响:发现 Encoder-Decoder 架构在训练长度内更稳健,且大模型比小模型更容易受到首因效应的影响。
- RAG 系统的警示:指出当前 RAG 系统中,简单的按相关性排序检索可能不够,**重排序(Reranking)**至关重要。
⚠️ 局限性与未来展望
- 未完全解释机理:论文主要呈现实验现象,对 Transformer 注意力机制为何在中间区域失效的理论解释尚浅。
- 解码策略单一:实验主要使用 Greedy Decoding,未探索 Beam Search 或其他采样策略是否缓解该问题。
- 未来方向 :
- 改进架构:设计对长序列位置更敏感的注意力机制。
- 训练优化:在预训练或微调阶段引入更多长序列中间信息的监督信号。
- 应用层对策:开发智能的分块、摘要或递归检索策略,避免将关键信息置于上下文中间。
📝 总结与工程建议
《Lost in the Middle》是一篇对 LLM 应用领域具有里程碑意义 的论文。它提醒我们,当前的"长上下文"能力在很大程度上是虚幻的。模型虽然能"吃下"长文本,却无法"消化"中间的内容。
🚀 对 RAG 系统开发的实战建议:
-
重排序(Rerank)是关键:
- 检索到的文档不能直接按原始顺序输入模型。
- 必须使用重排序模型(如 Cross-Encoder)将最相关 的文档移至上下文的开头或结尾。
- 参考前文提到的 RAG-Fusion 技术,利用 RRF 算法优化排序。
-
控制上下文长度:
- 不要盲目堆砌文档。如果 Top-10 文档已包含答案,强行加入 Top-50 只会降低性能并增加延迟。
- 实施动态截断策略,根据查询复杂度决定上下文大小。
-
Prompt 优化:
- 尝试将查询(Query)放在上下文的前后两端(Query-Aware Contextualization),虽对复杂 QA 提升有限,但在简单检索任务中效果显著。
-
模型选择:
- 在需要处理极长上下文且对中间信息依赖较强的场景中,需谨慎评估模型表现,优先考虑经过长上下文专项优化或架构更稳健的模型(如某些 Encoder-Decoder 变体)。
一句话总结 :在长上下文时代,信息的位置比信息的存在更重要。如果不加处理地将关键信息"埋"在中间,模型大概率会视而不见。
参考文献 :
1 Liu N F, Lin K, Hewitt J, et al. Lost in the Middle: How Language Models Use Long ContextsJ. arXiv preprint arXiv:2307.03172, 2023.