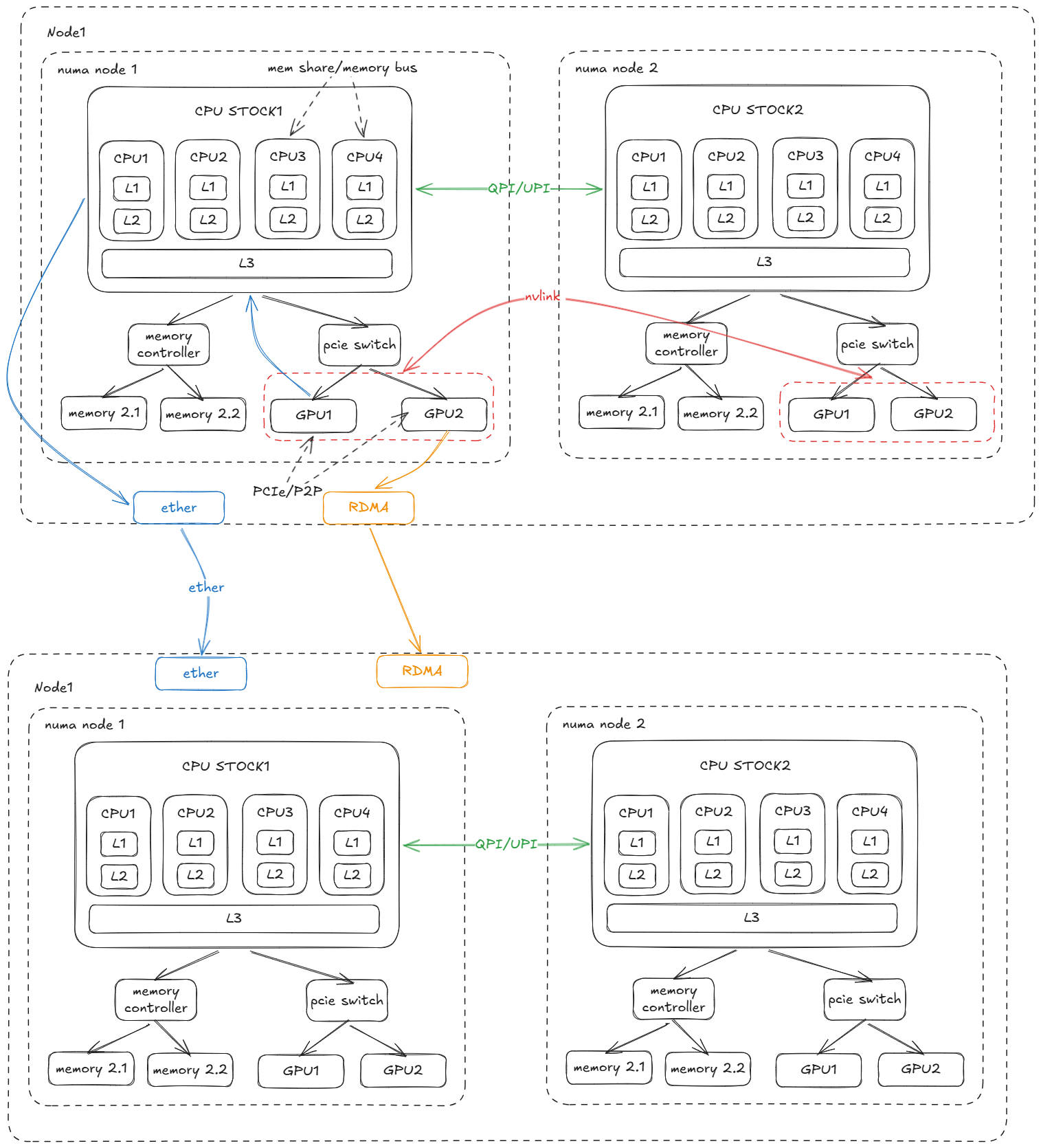
通信路径大梳理
- 同一 NUMA 节点内的 GPU 间通信走 PCIe/P2P 路径,经由 CPU 片上交换结构,但不经过 CPU 核心,数据直接在显存之间拷贝。
- 同 NUMA 节点内的 CPU 通信直接通过节点内部的共享内存与高速互连(UPI/Infinity Fabric),不依赖外部网络或总线。
- 不同numa节点的GPU通信,需要CPU参与,在系统总线中通过QPI/UPI通信
- 不同numa节点,使用nvlink设备连接的GPU 提供 GPU‑to‑GPU 的高速直连。通信时数据直接在 GPU 之间跳过 CPU,CPU 只负责指挥而不当"邮差"
- 不同物理节点间的GPU通信,且物理节点间使用ether连接。GPU数据将通过CPU,并最终通过以太网传输。
- 不同物理节点间的GPU,且物理节点使用RDMA连接,GPU数据绕过CPU,直接通过RMDA进行跨物理节点通信。
通信速率对比
| 通信类型 | 典型带宽 | 说明 |
|---|---|---|
| 同一 NUMA 节点内 GPU‑to‑GPU P2P | PCIe 4.0 x16 ≈ 32 GB/s<br>PCIe 5.0 x16 ≈ 64 GB/s | 通过 PCIe lanes 直连,取决于 CPU 提供的 lanes 速率。 |
| 跨 NUMA 节点 GPU‑to‑GPU | ≈ 20‑40 GB/s* | 数据须通过另一颗 CPU 的互连(UPI/Infinity Fabric),实际会被分割/共享,略低。 |
| NVLink(GPU‑to‑GPU) | NVLink 2.0 ≈ 50 GB/s/链路<br>NVLink 3.0 ≈ 75 GB/s/链路<br>多链路可叠加(例如 A100 6 链路≈ 600 GB/s) | 专用点对点互连,直接在 GPU 之间,不经过 CPU。 |
| RDMA(GPU‑to‑GPU 跨节点) | Infiniband HDR 200 Gb/s≈ 25 GB/s<br>Infiniband NDR 400 Gb/s≈ 50 GB/s | 使用 GPUDirect‑RDMA,通过网络传输,CPU 不参与数据拷贝。 |
| 以太网(无 RDMA) | 25 GbE≈ 3 GB/s<br>100 GbE≈ 12 GB/s<br>400 GbE≈ 50 GB/s | 若采用传统 TCP/IP,数据先过主机内存/CPU,延迟高且带宽受限。 |