本文主要是对比游戏开发时的建模渲染过程来简单理解,尽量不涉及学术和数学原理
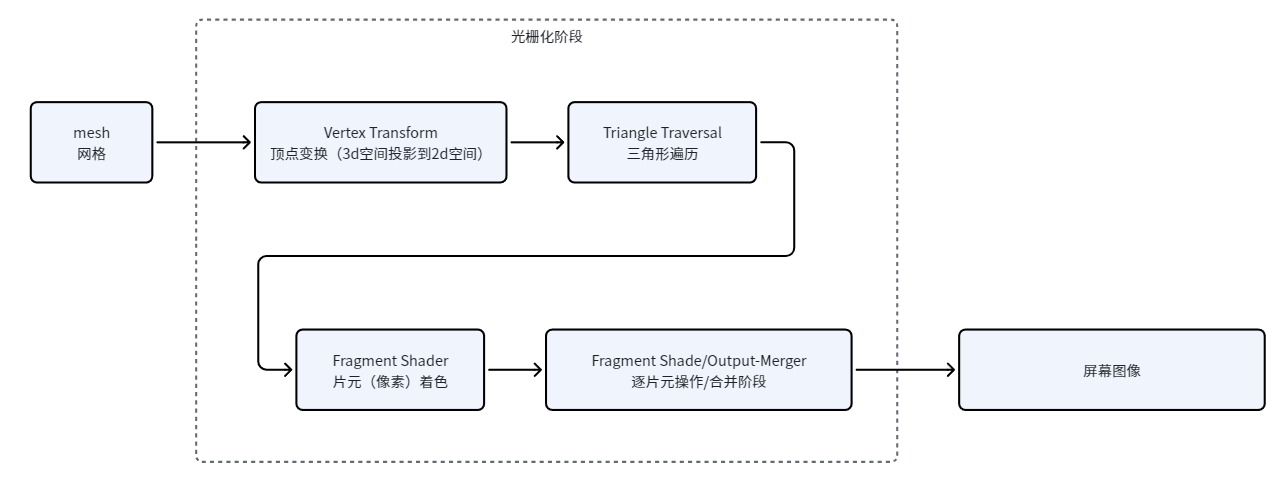
传统建模渲染过程
https://zhuanlan.zhihu.com/p/137780634
可以看上面这个大佬的复习一下
3DGS(3D Gaussian Splatting)

假设重建一棵树,绿色的点就是特征点(点云),绿色的椭圆体就是高斯体(个人觉得理解成任揉任搓的柔边椭圆体就行)

-
稀疏点云初始化: 通常使用 SfM (Structure from Motion) 算法(一种几何数学公式驱动的算法)从多张照片 (通常要几百张)中提取特征点 ,生成一个非常简陋的初始点云。
ps.点云就是点,每个点最基本的信息就是 (x, y, z)坐标。
-
点云变高斯体: 算法在每个"点"的位置,放上一个高斯体
-
投影与光栅化: 将这些 3D 高斯体投影到 2D 屏幕平面上渲染。
-
投影 (Projection): 把 3D 的椭球体"拍扁"到 2D 屏幕上,变成一个带渐变的圆环或椭圆。
-
排序 (Sorting):gpu会将这些"圆环"按离相机的远近进行排序。
-
Alpha 混合 (Alpha Blending): 这步是 3DGS 的核心。
它不像 Mesh 那样"非黑即白"(要么在三角形内,要么在外面)。
每一个高斯点都有透明度。渲染时,它会像叠多层半透明胶片一样,把远近不同的高斯点颜色叠在一起。
-
接下来的阶段是模型训练上的东西可无视,可以简单理解成它就是能自己迭代出一个比较好的版本输出一个3d模型
高斯点/体:
高斯点(Gaussian Point)和高斯体(Gaussian Spheroid/Ellipsoid)在 3DGS 的语境下其实是指同一个东西。
称它为"点"时: 侧重于它在空间中的中心位置,即它继承自原始点云的那个坐标。
称它为"体"时: 侧重于它具有体积、形状和透明度,它不再是一个无限小的几何点,而是一个有范围的概率分布。
-
计算误差: 将渲染出来的图像与真实的摄影照片对比,计算 Loss。
-
反向传播: 通过梯度下降调整每个高斯点的位置、形状、颜色和透明度。
-
致密化(Adaptive Density Control):如果某个地方太模糊,算法会自动分裂(Split)高斯点。如果某个地方点太多没用,算法会修剪(Clone/Remove)多余的点。
目前有一个比较火的方向是根据较少数量照片/提示词输出一个3d的模型
较少数量照片
扩散模型驱动 (Generative/Diffusion Based)
就是 AI 先根据你的一张照片,生成出 6-8 张不同角度(左、右、背、顶)的"幻觉照片"。
然后继续走3dgs多视角重建的流程
前馈神经网路 (Feed-forward / DUSt3R)
-
坐标映射: AI 直接预测每个像素在 3D 空间里的相对坐标 (x, y, z)。
-
点云 对齐: 如果是视频或几张照片,它直接在 3D 空间里把这些预测出来的点"吸附"在一起。
-
模型输出的就是带深度的点云或者高斯体,再去和原始图像比较迭代出合理的构成。
提示词创建模型
这个过程不需要任何真实的 3D 模型或照片,只需要两个 AI 组件:
-
打分员(2D 扩散模型): 比如 Stable Diffusion。它在几亿张图片上训练过,它非常清楚"一只赛博朋克风格的猫"长什么样。
-
学生(3DGS 场景): 一个随机扔在空间里的、乱七八糟的 3D 高斯团。
生成流程(迭代循环)
-
随机观察: 算法随机选一个视角(比如俯视 45 度),让 3DGS 渲染出一张当前的图片。刚开始,这张图只是一团模糊的彩色噪音。
-
加噪与去噪: 算法给这张渲染图加一点点噪声,然后扔给 Stable Diffusion,并告诉它提示词:"这是一只赛博朋克猫"。
-
打分(计算梯度): Stable Diffusion 会尝试把这张图"修"得更像猫。它会告诉 3DGS:"按照我的理解,左上角这块像素应该更亮一点,颜色应该更蓝一点,这样才像赛博朋克。"
-
反向传播 : 3DGS 收到这个"修改意见",通过反向传播去调整空间中几百万个高斯 体的位置、形状和颜色。
-
循环往复: 换个视角(比如平视、背面),重复上述过程。
结果: 经过几千次迭代,3DGS 为了在每一个视角下都能通过 Stable Diffusion 的"审美检查",被迫把自己排列组合成了一个符合提示词描述的 3D 形状。