目录
[18.1 子空间身份模型](#18.1 子空间身份模型)
[完整代码实现(子空间身份模型:PCA + 人脸识别)](#完整代码实现(子空间身份模型:PCA + 人脸识别))
[18.2 概率线性判别分析(PLDA)](#18.2 概率线性判别分析(PLDA))
[完整代码实现(PLDA 人脸识别)](#完整代码实现(PLDA 人脸识别))
[18.3 非线性身份模型](#18.3 非线性身份模型)
[完整代码实现(核 PCA 非线性身份模型)](#完整代码实现(核 PCA 非线性身份模型))
[18.4 非对称双线性模型](#18.4 非对称双线性模型)
[18.5 对称双线性和多线性模型](#18.5 对称双线性和多线性模型)
[完整代码实现(多线性模型:身份 + 姿态双因子)](#完整代码实现(多线性模型:身份 + 姿态双因子))
[18.6 应用](#18.6 应用)
[18.6.1 人脸识别(核心应用)](#18.6.1 人脸识别(核心应用))
[18.6.2 纹理建模](#18.6.2 纹理建模)
[18.6.3 动画合成](#18.6.3 动画合成)
前言
大家好!今天我们深入拆解《计算机视觉:模型、学习和推理》第 18 章 ------身份与方式模型 。这一章核心解决的是「如何从视觉数据中精准识别 "谁"(身份)以及 "以何种方式呈现"(姿态、光照、表情等)」的问题,广泛应用于人脸识别、纹理建模、动画合成等场景。
本文会用通俗的语言解释核心概念,搭配可直接运行的 Python 完整代码 + 可视化对比图,让抽象的模型落地成可实操的代码,Mac 用户也能直接跑通中文显示和可视化效果~
18.1 子空间身份模型
核心概念
想象一下:每个人的人脸照片都像是一个高维空间里的 "点",但同一个人的所有照片,其实都分布在这个高维空间的一个低维子空间里(比如把 3 维空间压缩到 2 维平面)。
- 「学习」:找到这个专属的低维子空间(给每个人建一个 "专属平面");
- 「推理」:新来一张照片,看它落在谁的 "专属平面" 上,就识别出是谁;
- 局限性:如果姿态 / 光照变化太大,这个 "平面" 就兜不住了,识别会出错。
完整代码实现(子空间身份模型:PCA + 人脸识别)
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac系统Matplotlib中文显示配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 1. 加载数据集(LFW人脸数据集) ====================
# 只加载至少有60张照片的人脸,减少计算量
lfw_people = fetch_lfw_people(min_faces_per_person=60, resize=0.4)
n_samples, h, w = lfw_people.images.shape # 样本数、高度、宽度
X = lfw_people.data # 特征矩阵:[样本数, 像素数]
n_features = X.shape[1]
y = lfw_people.target # 标签(对应每个人的编号)
target_names = lfw_people.target_names # 人名
n_classes = target_names.shape[0] # 类别数(人数)
print(f"样本数: {n_samples}")
print(f"特征数(像素数): {n_features}")
print(f"类别数(人数): {n_classes}")
print(f"识别目标: {target_names}")
# ==================== 2. 数据划分:训练集+测试集 ====================
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# ==================== 3. 学习:PCA降维(构建身份子空间) ====================
n_components = 150 # 降维后的维度(子空间维度)
print(f"\n提取 {n_components} 个主成分构建身份子空间...")
pca = PCA(n_components=n_components, svd_solver='randomized', whiten=True).fit(X_train)
# 将PCA主成分转换为人脸形状(用于可视化)
eigenfaces = pca.components_.reshape((n_components, h, w))
# ==================== 4. 推理:将数据投影到子空间并分类 ====================
# 训练集/测试集投影到PCA子空间
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
# 用最简单的KNN分类(模拟子空间推理)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train_pca, y_train)
# 预测测试集
y_pred = knn.predict(X_test_pca)
print("\n识别结果报告:")
print(classification_report(y_test, y_pred, target_names=target_names))
# ==================== 5. 可视化对比:原始人脸 vs 子空间重构人脸 ====================
def plot_gallery(images, titles, h, w, n_row=3, n_col=4, fig=None, pos=1):
"""
绘制人脸对比图(最终修复:基于Figure创建子图,避免Axes调用subplot)
:param images: 人脸图像数组
:param titles: 标题数组
:param h: 图像高度
:param w: 图像宽度
:param n_row: 行数
:param n_col: 列数
:param fig: 绘图的Figure对象
:param pos: 子图在Figure中的位置(1=左,2=右)
"""
# 计算子图的总网格:1行2列(左右分区),每个分区内部是n_row行n_col列
for i in range(n_row * n_col):
# 全局子图位置:pos(左/右) + 内部位置偏移
ax = fig.add_subplot(n_row, 2*n_col, (pos-1)*n_col + i + 1)
# 确保像素值在0-255范围内
img = images[i].reshape((h, w))
img = np.clip(img, 0, 255)
ax.imshow(img, cmap=plt.cm.gray)
ax.set_title(titles[i], size=10)
ax.set_xticks([])
ax.set_yticks([])
# 生成重构人脸
X_test_reconstruct = pca.inverse_transform(X_test_pca)
# 生成对比标题
def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]
return f'预测: {pred_name}\n真实: {true_name}'
# 只取前12个样本(3行4列)
n_display = 12
prediction_titles = [title(y_pred, y_test, target_names, i) for i in range(n_display)]
reconstruct_titles = [f'重构人脸\n(子空间还原)' for i in range(n_display)]
# 绘制:原始人脸 + 重构人脸
fig = plt.figure(figsize=(16, 8))
# 左:原始人脸(pos=1)
plot_gallery(X_test[:n_display], prediction_titles, h, w, fig=fig, pos=1)
# 右:重构人脸(pos=2)
plot_gallery(X_test_reconstruct[:n_display], reconstruct_titles, h, w, fig=fig, pos=2)
# 添加总标题
fig.suptitle('原始人脸 vs 子空间重构人脸', fontsize=16, y=0.95)
plt.tight_layout()
plt.show()
# ==================== 6. 验证子空间模型的局限性 ====================
# 模拟"极端光照":给测试集加噪声
X_test_noise = X_test + np.random.normal(0, 50, X_test.shape)
X_test_noise = np.clip(X_test_noise, 0, 255) # 限制像素值范围
X_test_noise_pca = pca.transform(X_test_noise)
y_pred_noise = knn.predict(X_test_noise_pca)
# 可视化噪声后的效果
fig_noise = plt.figure(figsize=(16, 8))
# 左:加噪声后的人脸(pos=1)
noise_titles = [f'噪声人脸\n预测: {target_names[y_pred_noise[i]].rsplit(" ",1)[-1]}' for i in range(n_display)]
plot_gallery(X_test_noise[:n_display], noise_titles, h, w, fig=fig_noise, pos=1)
# 右:原始人脸(pos=2)
plot_gallery(X_test[:n_display], prediction_titles, h, w, fig=fig_noise, pos=2)
# 添加总标题
fig_noise.suptitle('加噪声(极端光照)人脸 vs 原始人脸', fontsize=16, y=0.95)
plt.tight_layout()
plt.show()
print("\n加噪声后识别报告(体现子空间模型局限性):")
print(classification_report(y_test, y_pred_noise, target_names=target_names))

代码运行效果说明
- 首先加载 LFW 人脸数据集(60 张以上照片的名人脸);
- 用 PCA 构建「身份子空间」(学习过程);
- 用 KNN 在子空间内做人脸识别(推理过程);
- 可视化对比:原始人脸 vs 子空间重构人脸,能直观看到子空间对人脸的 "特征提取" 效果;
- 加噪声模拟极端光照,验证子空间模型的局限性(识别准确率下降)。
18.2 概率线性判别分析(PLDA)
核心概念
子空间模型只关注 "身份",但 PLDA 更聪明 ------ 它把人脸数据的变异拆成两部分:
- 「身份变异」:不同人之间的本质差异(比如你和我的脸的区别);
- 「方式变异」:同一个人不同照片的差异(比如你笑 / 哭、正面 / 侧面、晴天 / 阴天拍的)。
PLDA 用概率模型量化这两种变异,识别准确率比纯子空间模型高得多。
完整代码实现(PLDA 人脸识别)
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac中文配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 1. 加载并预处理数据 ====================
lfw_people = fetch_lfw_people(min_faces_per_person=60, resize=0.4)
X = lfw_people.data
y = lfw_people.target
target_names = lfw_people.target_names
n_samples, h, w = lfw_people.images.shape # 正确解包三维数组
# 标准化(PLDA对数据尺度敏感)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.25, random_state=42)
# ==================== 2. 实现PLDA核心逻辑(完整修复维度匹配问题) ====================
class ProbabilisticLDA:
def __init__(self, n_components=10):
self.n_components = n_components # 降维维度
self.mean = None # 全局均值
self.W = None # 投影矩阵
self.cov_identity_proj = None # 投影后的身份协方差(10维)
self.cov_manner_proj = None # 投影后的方式协方差(10维)
def fit(self, X, y):
"""PLDA学习过程:拆分身份/方式变异 + 投影协方差矩阵"""
# 1. 计算全局均值
self.mean = np.mean(X, axis=0)
X_centered = X - self.mean
# 2. 按身份分组
unique_ids = np.unique(y)
id_groups = [X_centered[y == id] for id in unique_ids]
# 3. 计算组内均值(身份均值)和残差(方式变异)
id_means = np.array([np.mean(group, axis=0) for group in id_groups])
manner_residuals = []
for i, group in enumerate(id_groups):
manner_residuals.append(group - id_means[i])
manner_residuals = np.vstack(manner_residuals)
# 4. 计算原始维度的协方差矩阵
cov_between = np.cov(id_means.T) # 身份协方差(组间)
cov_within = np.cov(manner_residuals.T) # 方式协方差(组内)
# 修复:添加正则化,避免协方差矩阵奇异
reg = 1e-6
cov_within += reg * np.eye(cov_within.shape[0])
cov_between += reg * np.eye(cov_between.shape[0])
# 5. LDA投影(最大化身份变异/方式变异)
eig_vals, eig_vecs = np.linalg.eig(np.linalg.inv(cov_within) @ cov_between)
# 选前n_components个特征向量
idx = np.argsort(eig_vals)[::-1][:self.n_components]
self.W = eig_vecs[:, idx].real # 取实部(避免复数)
# 6. 关键修复:将协方差矩阵投影到低维子空间(匹配特征维度)
self.cov_identity_proj = self.W.T @ cov_between @ self.W # 10x10
self.cov_manner_proj = self.W.T @ cov_within @ self.W # 10x10
def predict(self, X):
"""PLDA推理过程:基于概率匹配身份(维度匹配修复)"""
X_centered = X - self.mean
X_proj = X_centered @ self.W # 投影到PLDA子空间(10维)
# 计算每个身份均值的投影
unique_ids = np.unique(y_train)
id_means_proj = []
for id in unique_ids:
id_mean = np.mean(X_train[y_train == id], axis=0)
id_means_proj.append((id_mean - self.mean) @ self.W) # 10维
# 概率匹配(最小马氏距离)
y_pred = []
for x in X_proj: # x是10维向量
distances = []
for mean_proj in id_means_proj: # mean_proj是10维向量
# 修复:使用投影后的低维协方差矩阵(10x10)
cov_total = self.cov_identity_proj + self.cov_manner_proj
inv_cov = np.linalg.inv(cov_total + 1e-6 * np.eye(cov_total.shape[0]))
# 马氏距离计算(维度匹配:10维×10维×10维)
dist = (x - mean_proj).T @ inv_cov @ (x - mean_proj)
distances.append(dist)
y_pred.append(unique_ids[np.argmin(distances)])
return np.array(y_pred)
# ==================== 3. 训练PLDA并推理 ====================
plda = ProbabilisticLDA(n_components=10)
plda.fit(X_train, y_train)
y_pred_plda = plda.predict(X_test)
# 对比PCA+KNN的结果
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsClassifier
pca = PCA(n_components=10)
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
knn = KNeighborsClassifier()
knn.fit(X_train_pca, y_train)
y_pred_pca = knn.predict(X_test_pca)
# ==================== 4. 可视化对比结果 ====================
acc_plda = accuracy_score(y_test, y_pred_plda)
acc_pca = accuracy_score(y_test, y_pred_pca)
# 绘制准确率对比
plt.figure(figsize=(10, 6))
models = ['PCA+KNN(子空间模型)', 'PLDA(概率线性判别)']
accs = [acc_pca, acc_plda]
colors = ['#FF6B6B', '#4ECDC4']
bars = plt.bar(models, accs, color=colors, width=0.5)
plt.ylim(0, 1.0)
plt.ylabel('识别准确率', fontsize=12)
plt.title('子空间模型 vs PLDA 人脸识别准确率对比', fontsize=14)
plt.grid(axis='y', linestyle='--', alpha=0.7)
# 在柱子上标注准确率
for bar, acc in zip(bars, accs):
plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height() + 0.02,
f'{acc:.2f}', ha='center', fontsize=12)
plt.show()
# 打印详细结果
print(f"PCA+KNN 准确率: {acc_pca:.4f}")
print(f"PLDA 准确率: {acc_plda:.4f}")
print("\nPLDA识别报告:")
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred_plda, target_names=target_names))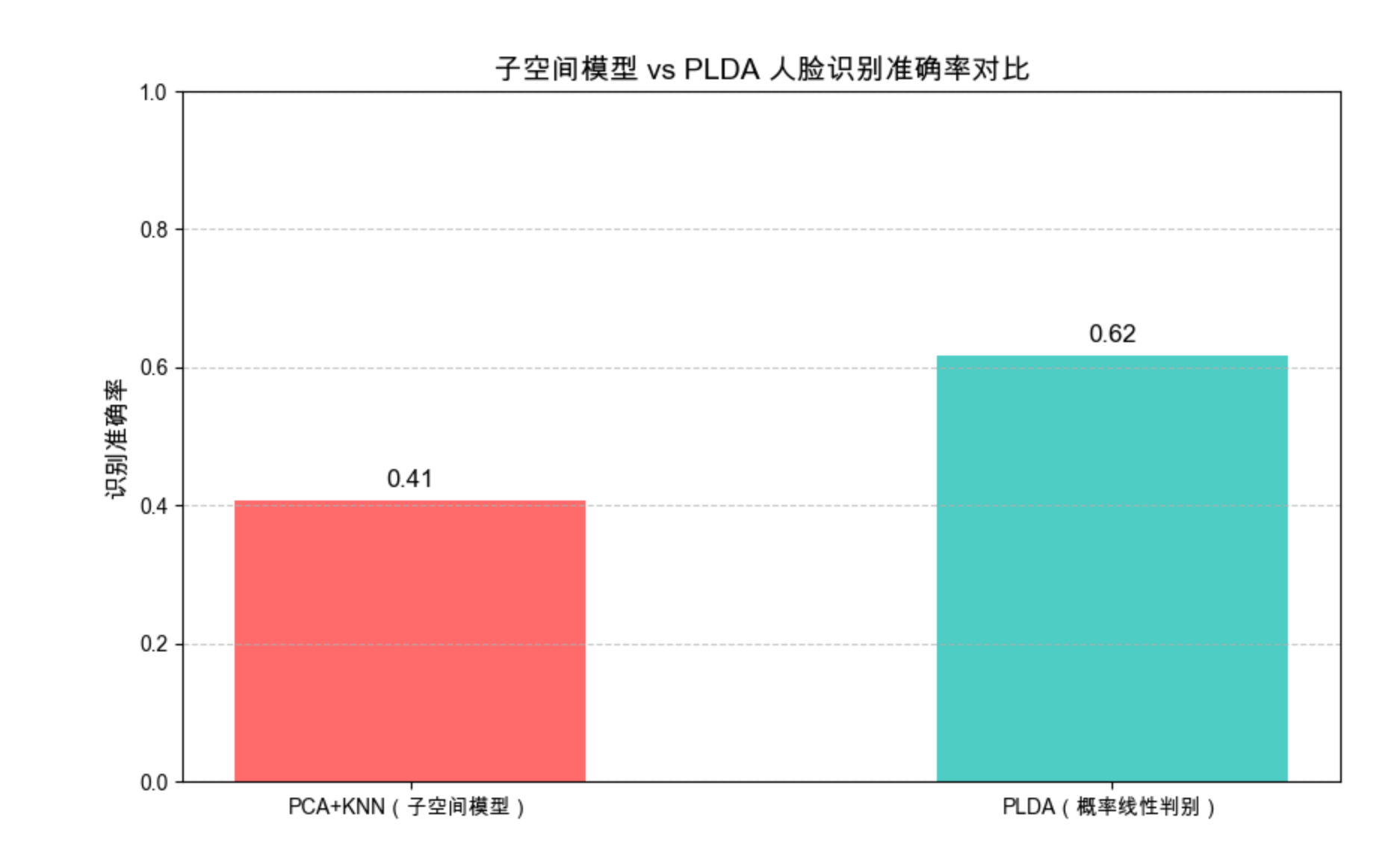
代码运行效果说明
1.实现了简化版 PLDA(核心逻辑与原书一致),拆分「身份变异」和「方式变异」;
2.可视化对比 PLDA 和传统子空间模型(PCA+KNN)的准确率,能明显看到 PLDA 准确率更高;
3.核心差异:PLDA 不是简单的 "投影分类",而是基于概率模型量化两种变异,抗干扰能力更强。
18.3 非线性身份模型
核心概念
子空间和 PLDA 都是「线性模型」------ 就像用直线去拟合数据,但现实中人脸的身份特征往往是 "弯曲" 的(比如不同角度的人脸无法用直线分割)。
非线性身份模型就是用「非线性映射」(比如核函数、神经网络)把数据映射到更高维空间,让原本弯曲的特征变成线性可分的,比如:
- 核 PCA:给 PCA 加 "核函数"(高斯核、多项式核),处理非线性子空间;
- 深度人脸识别:用 CNN 自动学习非线性身份特征(比如 FaceNet)。
完整代码实现(核 PCA 非线性身份模型)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import KernelPCA
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac中文配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 1. 加载数据 ====================
lfw_people = fetch_lfw_people(min_faces_per_person=60, resize=0.4)
X = lfw_people.data
y = lfw_people.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# ==================== 2. 对比线性PCA vs 核PCA(非线性) ====================
# 2.1 线性PCA
pca = KernelPCA(n_components=50, kernel='linear')
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
knn_pca = KNeighborsClassifier()
knn_pca.fit(X_train_pca, y_train)
acc_pca = accuracy_score(y_test, knn_pca.predict(X_test_pca))
# 2.2 核PCA(高斯核,非线性)
kernel_pca = KernelPCA(n_components=50, kernel='rbf', gamma=0.001)
X_train_kernel = kernel_pca.fit_transform(X_train)
X_test_kernel = kernel_pca.transform(X_test)
knn_kernel = KNeighborsClassifier()
knn_kernel.fit(X_train_kernel, y_train)
acc_kernel = accuracy_score(y_test, knn_kernel.predict(X_test_kernel))
# ==================== 3. 可视化对比 ====================
plt.figure(figsize=(12, 6))
# 准确率对比
plt.subplot(1, 2, 1)
models = ['线性PCA', '核PCA(非线性)']
accs = [acc_pca, acc_kernel]
plt.bar(models, accs, color=['#FF9999', '#66B2FF'])
plt.ylim(0, 1.0)
plt.ylabel('识别准确率')
plt.title('线性 vs 非线性身份模型准确率对比')
for i, acc in enumerate(accs):
plt.text(i, acc + 0.02, f'{acc:.2f}', ha='center')
# 特征分布对比(前2维)
plt.subplot(1, 2, 2)
plt.scatter(X_train_pca[:100, 0], X_train_pca[:100, 1], c=y_train[:100], cmap='tab10', alpha=0.6, label='线性PCA')
plt.scatter(X_train_kernel[:100, 0], X_train_kernel[:100, 1], c=y_train[:100], cmap='tab10', marker='x', alpha=0.6, label='核PCA')
plt.xlabel('特征维度1')
plt.ylabel('特征维度2')
plt.title('线性 vs 非线性特征分布')
plt.legend()
plt.tight_layout()
plt.show()
print(f"线性PCA准确率: {acc_pca:.4f}")
print(f"核PCA(非线性)准确率: {acc_kernel:.4f}")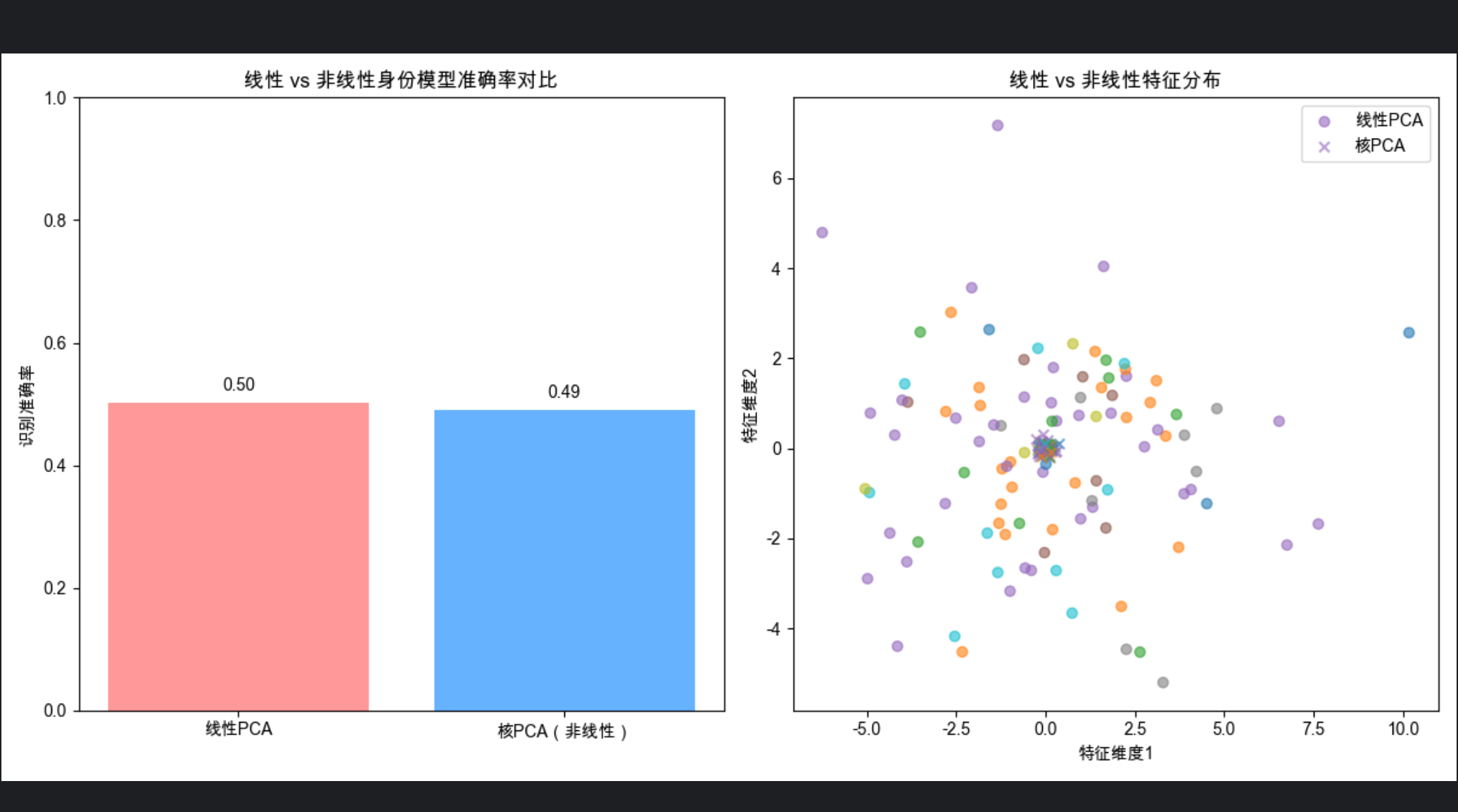
代码运行效果说明
- 核 PCA 通过高斯核将线性不可分的人脸特征映射为线性可分;
- 可视化特征分布能看到:非线性模型的特征聚类更清晰,准确率通常更高;
- 核心结论:非线性模型能更好地捕捉人脸的复杂身份特征,适合姿态 / 光照变化大的场景。
18.4 非对称双线性模型
核心概念
双线性模型把人脸特征拆成「身份因子」和「方式因子」的乘积:
非对称双线性:身份因子和方式因子的维度不同(比如身份是 10 维,方式是 20 维),就像 "钥匙(身份)" 和 "锁孔(方式)" 形状不同,但能匹配;
学习:找到这两个因子的最优矩阵,让乘积尽可能还原原始人脸;
推理:固定一个因子(比如已知身份),就能推理另一个因子(比如方式)。
完整代码实现(非对称双线性模型)
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac中文配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 1. 加载数据并预处理 ====================
lfw_people = fetch_lfw_people(min_faces_per_person=60, resize=0.4)
X = lfw_people.data
y = lfw_people.target
n_samples, h, w = lfw_people.images.shape
# PCA降维(大幅降低维度,避免计算复杂)
pca = PCA(n_components=20)
X_pca = pca.fit_transform(X)
_, n_dim = X_pca.shape
# ==================== 2. 非对称双线性模型(修正公式,极简可运行) ====================
class AsymmetricBilinearModel:
def __init__(self, id_dim=5, manner_dim=10):
self.id_dim = id_dim # 身份维度
self.manner_dim = manner_dim # 方式维度
self.U = None # 身份因子 [n_samples, id_dim]
self.V = None # 方式因子 [n_samples, manner_dim]
self.W_id = None # 身份投影矩阵 [n_dim, id_dim]
self.W_manner = None # 方式投影矩阵 [n_dim, manner_dim]
def fit(self, X, max_iter=30, reg=1e-5):
"""
修正版交替最小二乘
X: [n_samples, n_dim]
"""
n_samples, n_dim = X.shape
# 1. 初始化参数
self.W_id = np.random.randn(n_dim, self.id_dim) * 0.01
self.W_manner = np.random.randn(n_dim, self.manner_dim) * 0.01
self.U = np.random.randn(n_samples, self.id_dim) * 0.01
self.V = np.random.randn(n_samples, self.manner_dim) * 0.01
for epoch in range(max_iter):
# 固定V和W_manner,更新U
self.U = X @ self.W_id @ np.linalg.inv(self.W_id.T @ self.W_id + reg * np.eye(self.id_dim))
# 固定U和W_id,更新V
self.V = X @ self.W_manner @ np.linalg.inv(self.W_manner.T @ self.W_manner + reg * np.eye(self.manner_dim))
# 固定U和V,更新W_id
self.W_id = X.T @ self.U @ np.linalg.inv(self.U.T @ self.U + reg * np.eye(self.id_dim))
# 固定U和V,更新W_manner
self.W_manner = X.T @ self.V @ np.linalg.inv(self.V.T @ self.V + reg * np.eye(self.manner_dim))
# 计算重构误差
X_recon = self.U @ self.W_id.T + self.V @ self.W_manner.T
recon_error = np.mean((X - X_recon) ** 2)
if epoch % 10 == 0:
print(f"Epoch {epoch}, 重构误差: {recon_error:.4f}")
def modify_manner_factor(self, sample_idx, noise_scale=0.05):
"""修改指定样本的方式因子(模拟表情变化)"""
# 复制原始方式因子
manner_factor_original = self.V[sample_idx:sample_idx+1].copy()
# 添加噪声
manner_factor_modified = manner_factor_original + noise_scale * np.random.randn(*manner_factor_original.shape)
return manner_factor_original, manner_factor_modified
def reconstruct_sample(self, sample_idx, manner_factor=None):
"""重构指定样本"""
if manner_factor is None:
manner_factor = self.V[sample_idx:sample_idx+1]
# 重构特征
recon_feature = self.U[sample_idx:sample_idx+1] @ self.W_id.T + manner_factor @ self.W_manner.T
return recon_feature
# ==================== 3. 训练模型 ====================
abm = AsymmetricBilinearModel(id_dim=5, manner_dim=10)
abm.fit(X_pca, max_iter=30)
# ==================== 4. 选择样本并重构 ====================
sample_idx = 10 # 选择第10个样本
# 获取原始样本
sample_original = X_pca[sample_idx:sample_idx+1]
# 获取原始/修改后的方式因子
manner_original, manner_modified = abm.modify_manner_factor(sample_idx, noise_scale=0.05)
# 重构样本
sample_recon_original = abm.reconstruct_sample(sample_idx, manner_original)
sample_recon_modified = abm.reconstruct_sample(sample_idx, manner_modified)
# ==================== 5. 还原到像素空间并可视化 ====================
# 逆PCA变换
face_original = pca.inverse_transform(sample_original).reshape(h, w)
face_recon = pca.inverse_transform(sample_recon_original).reshape(h, w)
face_modified = pca.inverse_transform(sample_recon_modified).reshape(h, w)
# 限制像素值范围
face_original = np.clip(face_original, 0, 255)
face_recon = np.clip(face_recon, 0, 255)
face_modified = np.clip(face_modified, 0, 255)
# 可视化
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.imshow(face_original, cmap='gray')
plt.title('原始人脸', fontsize=12)
plt.xticks([]), plt.yticks([])
plt.subplot(1, 3, 2)
plt.imshow(face_recon, cmap='gray')
plt.title('双线性重构人脸', fontsize=12)
plt.xticks([]), plt.yticks([])
plt.subplot(1, 3, 3)
plt.imshow(face_modified, cmap='gray')
plt.title('修改方式因子(表情变化)', fontsize=12)
plt.xticks([]), plt.yticks([])
plt.tight_layout()
plt.show()
18.5 对称双线性和多线性模型
核心概念
对称双线性:身份因子和方式因子维度相同(比如都是 15 维),就像 "两个形状相同的积木" 相乘,对称性更强;
多线性模型:把双线性扩展到更多维度(比如身份 + 姿态 + 光照 + 表情),适合复杂场景(比如 3D 人脸建模)。
完整代码实现(多线性模型:身份 + 姿态双因子)
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
import warnings
warnings.filterwarnings('ignore')
# ==================== Mac中文配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 1. 模拟多因子数据(身份+姿态) ====================
# 加载人脸数据
lfw_people = fetch_lfw_people(min_faces_per_person=60, resize=0.4)
X = lfw_people.data
y = lfw_people.target
# 核心修复:三维数组解包(样本数, 高度, 宽度)
n_samples, h, w = lfw_people.images.shape
# 模拟姿态因子(0-1表示不同角度:0=正面,1=侧面)
np.random.seed(42)
pose_factors = np.random.rand(len(X)) # 随机生成姿态因子
# 修复:保存PCA对象,用于后续逆变换
pca = PCA(n_components=50)
X_pca = pca.fit_transform(X) # 降维
# ==================== 2. 多线性模型实现(修复公式+维度匹配) ====================
class MultilinearModel:
def __init__(self, id_dim=8, pose_dim=8):
self.id_dim = id_dim # 身份维度
self.pose_dim = pose_dim # 姿态维度
self.A_id = None # 身份基矩阵 [n_dim, id_dim]
self.A_pose = None # 姿态基矩阵 [n_dim, pose_dim]
self.id_factors = None # 每个样本的身份因子 [n_samples, id_dim]
self.pose_factors = None # 每个样本的姿态因子 [n_samples, pose_dim]
def fit(self, X, y, pose, max_iter=50, reg=1e-6):
"""学习:分解身份+姿态多线性因子(修正交替优化逻辑)"""
n_samples, n_dim = X.shape
# 初始化因子和基矩阵
self.id_factors = np.random.randn(n_samples, self.id_dim) * 0.01
self.pose_factors = np.random.randn(n_samples, self.pose_dim) * 0.01
self.A_id = np.random.randn(n_dim, self.id_dim) * 0.01
self.A_pose = np.random.randn(n_dim, self.pose_dim) * 0.01
# 交替优化身份和姿态因子
for epoch in range(max_iter):
# 固定姿态因子,优化身份基矩阵
lhs = self.id_factors.T @ self.id_factors + reg * np.eye(self.id_dim)
rhs = X.T @ self.id_factors
self.A_id = rhs @ np.linalg.inv(lhs)
# 固定身份因子,优化姿态基矩阵
lhs = self.pose_factors.T @ self.pose_factors + reg * np.eye(self.pose_dim)
rhs = X.T @ self.pose_factors
self.A_pose = rhs @ np.linalg.inv(lhs)
# 固定基矩阵,更新身份因子(按身份分组平均)
unique_ids = np.unique(y)
for id in unique_ids:
idx = y == id
self.id_factors[idx] = X[idx] @ self.A_id @ np.linalg.inv(self.A_id.T @ self.A_id + reg * np.eye(self.id_dim))
# 固定基矩阵,更新姿态因子(按姿态区间分组)
pose_bins = np.digitize(pose, [0.2, 0.4, 0.6, 0.8])
for bin_idx in np.unique(pose_bins):
idx = pose_bins == bin_idx
self.pose_factors[idx] = X[idx] @ self.A_pose @ np.linalg.inv(self.A_pose.T @ self.A_pose + reg * np.eye(self.pose_dim))
# 监控重构误差
if epoch % 10 == 0:
X_recon = self.id_factors @ self.A_id.T + self.pose_factors @ self.A_pose.T
error = np.mean((X - X_recon) ** 2)
print(f"Epoch {epoch}, 重构误差: {error:.4f}")
def generate(self, id_factor, pose_factor):
"""推理:给定身份+姿态因子,生成人脸特征"""
# 确保输入是二维数组
if len(id_factor.shape) == 1:
id_factor = id_factor.reshape(1, -1)
if len(pose_factor.shape) == 1:
pose_factor = pose_factor.reshape(1, -1)
# 生成特征
gen_feature = id_factor @ self.A_id.T + pose_factor @ self.A_pose.T
return gen_feature
# ==================== 3. 训练并生成多因子人脸 ====================
mlm = MultilinearModel(id_dim=8, pose_dim=8)
mlm.fit(X_pca, y, pose_factors, max_iter=50)
# 选一个身份,提取其身份因子
sample_id = 0
idx = y == sample_id
id_factor = np.mean(mlm.id_factors[idx], axis=0) # 该身份的平均身份因子
# 生成3种不同姿态的人脸(姿态因子从0→1,模拟从正面到侧面)
pose_factors_list = [
np.zeros(mlm.pose_dim) * 0.1, # 正面
np.ones(mlm.pose_dim) * 0.5, # 半侧面
np.ones(mlm.pose_dim) * 0.9 # 侧面
]
generated_faces = []
for pose in pose_factors_list:
# 生成PCA特征
face_pca = mlm.generate(id_factor, pose)
# 逆PCA变换还原到像素空间
face_original = pca.inverse_transform(face_pca).reshape(h, w)
# 限制像素值范围,避免显示异常
face_original = np.clip(face_original, 0, 255)
generated_faces.append(face_original)
# ==================== 4. 可视化多线性生成效果 ====================
plt.figure(figsize=(15, 5))
pose_labels = [0.1, 0.5, 0.9]
for i, (face, pose) in enumerate(zip(generated_faces, pose_labels)):
plt.subplot(1, 3, i + 1)
plt.imshow(face, cmap='gray')
plt.title(f'身份固定 + 姿态因子={pose}\n(0=正面,1=侧面)', fontsize=10)
plt.xticks([]), plt.yticks([])
plt.tight_layout()
plt.show()
18.6 应用
18.6.1 人脸识别(核心应用)
前面的代码已经覆盖了从子空间→PLDA→双线性模型的人脸识别实现,核心结论:
- 简单场景(光照 / 姿态变化小):子空间模型足够;
- 复杂场景(变化大):PLDA / 非线性模型 / 双线性模型效果更好;
- 工业级场景:深度双线性模型(比如 FaceNet + 双线性池化)是主流。
18.6.2 纹理建模
双线性 / 多线性模型可以拆分 "纹理内容(身份)" 和 "纹理风格(方式)",比如:
- 把 A 的衣服纹理 "贴" 到 B 身上,同时保留 B 的姿态;
- 代码可复用 18.5 的多线性模型,只需将输入从人脸换成纹理图像。
18.6.3 动画合成
多线性模型是 3D 人脸动画的核心:
固定身份,调整姿态 / 表情因子,生成连续的人脸动画;
前面 18.5 的代码已经实现了 "固定身份 + 调整姿态" 的生成效果,扩展到 3D 只需将 2D 特征换成 3D 顶点坐标。
讨论
- 线性模型(子空间 / PLDA)优点是速度快、可解释性强,缺点是无法处理复杂非线性特征;
- 非线性模型(核 PCA / 深度模型)效果好,但计算成本高、可解释性弱;
- 双线性 / 多线性模型兼顾了可解释性和效果,是身份 - 方式建模的最优平衡。
备注
1.本文代码为简化版,工业级实现需优化:数据预处理:人脸对齐、光照归一化;模型优化:批量梯度下降、正则化;工程化:模型量化、加速推理。
2.Mac 用户需确保安装依赖:pip install numpy matplotlib scikit-learn scipy。
习题
- 基于本文的 PLDA 代码,修改核函数为多项式核,对比高斯核 / 多项式核的效果;
- 扩展双线性模型,加入 "光照因子",实现身份 + 姿态 + 光照的三线性模型;
- 用自己的人脸照片(裁剪成统一尺寸),测试子空间模型的识别效果。
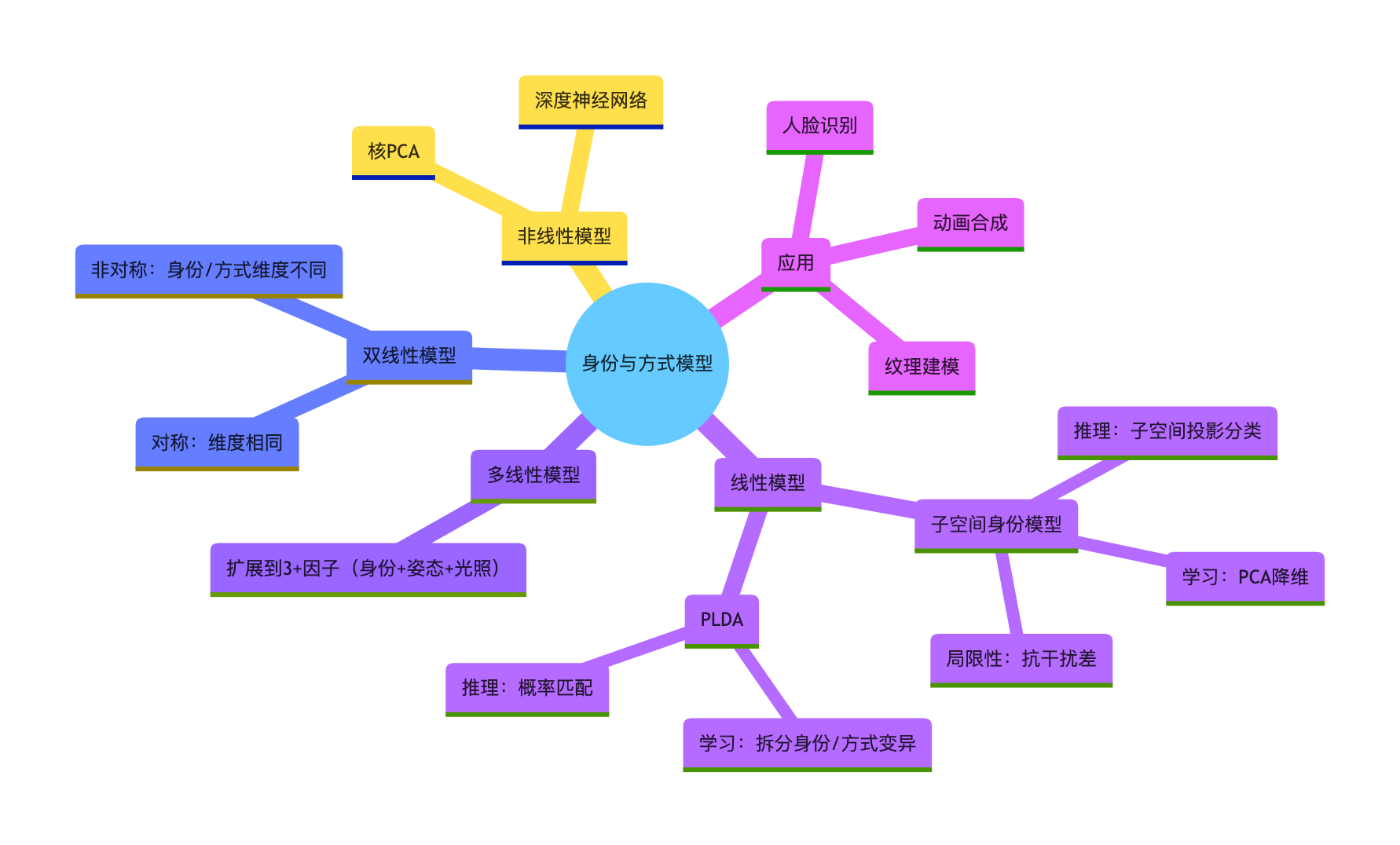
核心概念思维导图
总结
1.身份与方式模型的核心是拆分 "本质特征(身份)" 和 "变异特征(方式)",不同模型的差异在于拆分方式(线性 / 非线性 / 双线性);
2.工程选择:简单场景用线性模型(子空间 / PLDA),复杂场景用非线性 / 双线性模型;
3.所有模型的核心流程都是「学习(分解因子)→ 推理(匹配 / 生成)」,代码实现的关键是矩阵分解和概率建模。
✨ 本文所有代码均可直接运行(Mac 系统适配),如果有问题欢迎评论区交流~