前情
我们知道 LangChain是一个用于构建由 LLM 提供支持的代理和应用程序的框架。而现实AI开发中往往又是LLM + RAG的模式。前面我们也学过原生的 RAG。当然Langchain对RAG流程也做了更便捷、更好用的封装。
Data Connection
Langchain中的 Data Connection模块正是对RAG流程的封装。
我们先简单回顾下RAG整个的流程:
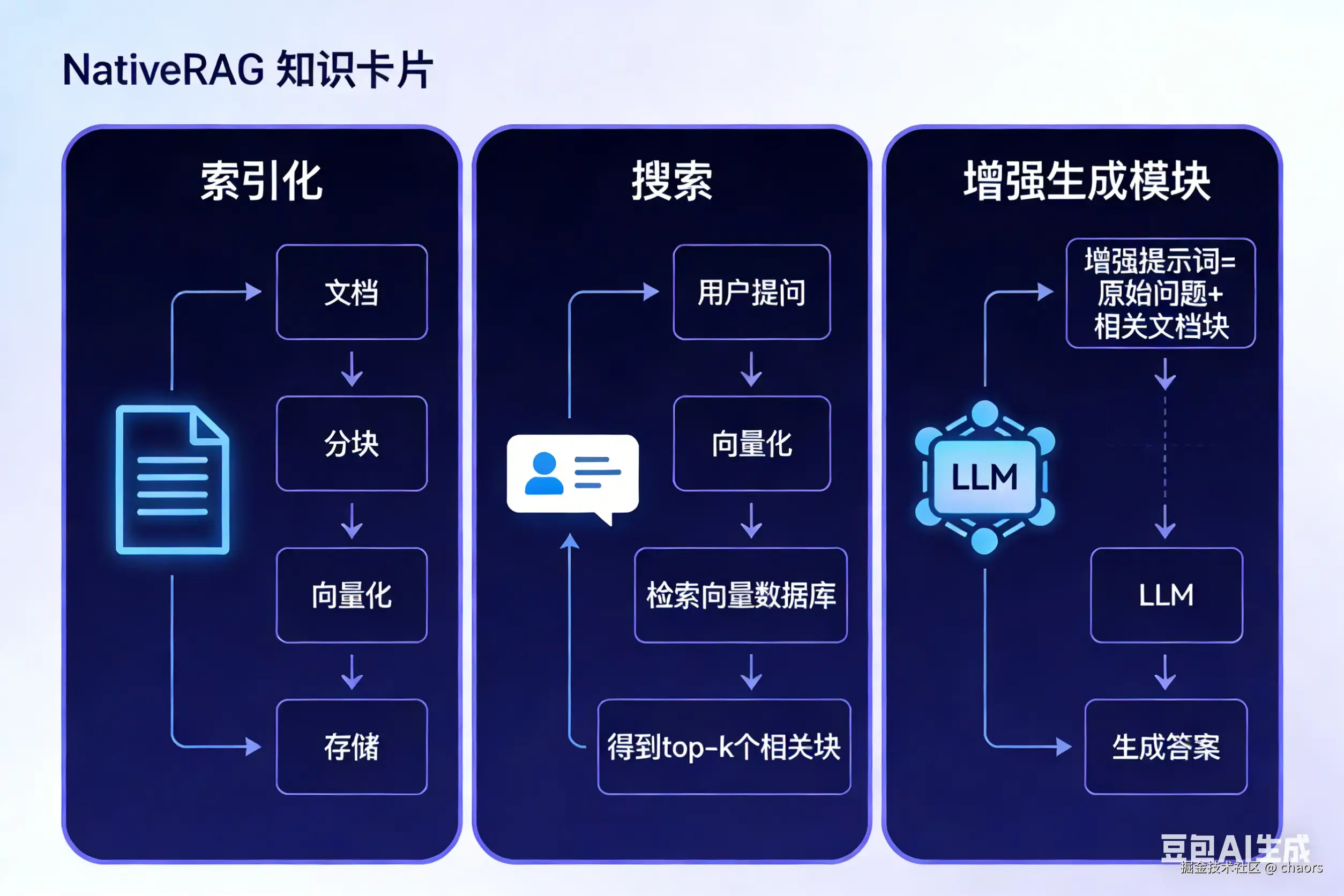
对应这几个流程,我逐个对照看看Langchain的封装。
文档加载
LangChain有很强的数据加载能力,提供了很多常见的数据格式的支持,例如CSV、文件目录、HTML、JSON、Markdown及PDF等。
加载器Loader
- TextLoader:TXT文档
- PyPDFLoader:PDF文档
- CSVLoaderCSV:文档
- JSONLoader:JSON文档
- UnstructuredHTMLLoader:HTML文档:
- UnStructuredMarkdownLoader:MD文档
- DirectoryLoader:文件目录
核心方法
- load方法,用于从指定的数据源读取数据,并将其转换成一个或多个文档。
ini
# 1.指定要加载的Word文档路径
loader = Docx2txtLoader("人事管理流程.docx")
# 加载文档、转换格式化成document
documents = loader.load()切割器Splitter
ini
# 文档切割 递归切割
# separators
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, #切块大小
chunk_overlap=50, # 切块重叠大小
# separators=[".", '\n', '!', '?', ';']
)
# 通过分割器获取document :create_documents split_documents 传入一个document对象,返回一个document对象列表
split_documents = text_splitter.split_documents(documents)NativeRAG
ini
splitter = RecursiveCharacterTextSplitter(
chunk_size=20, # 分割长度
chunk_overlap=5, # 重叠长度 /重叠窗口大小
separators=["\n\n", "\n", "。", ",", ""],
)
chunks = splitter.split_text(text)Document对象
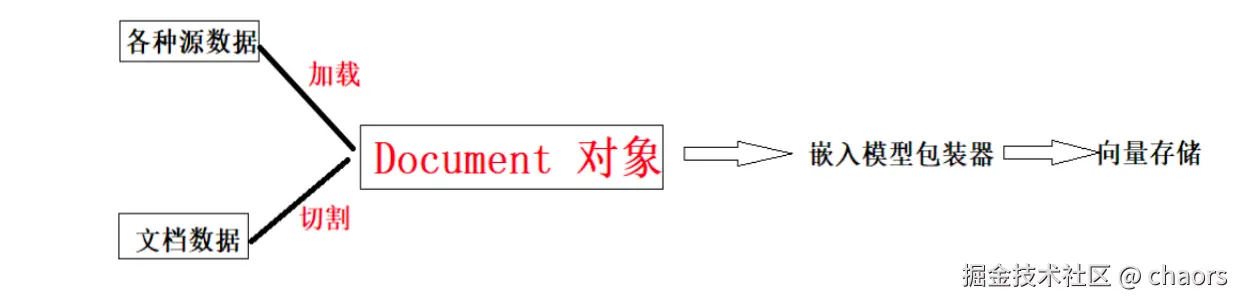
可以看到以上代码基本相同,没什么差别。但是这里要注意:在Langchain中,操作的目标都是Document对象。
Document对象是一个轻量级的容器,其核心职责是封装一段具有上下文语义的信息,并为这块信息附加可供机器处理的元数据。是后续一系列AI处理流程(如检索、切割、嵌入、推理)的统一、可操作的基本数据单元
- page_content(字符串): 文档数据。这是后续LLM直接"阅读"和处理的原材料。
- metadata(字典): 元数据。在检索后增强溯源、控制切割边界、进行精细化过滤时至关重要。
一个🌰:
python
Document(
page_content="猫是柔软可爱的动物,但相对独立",
metadata={"source": "常见动物宠物文档"},
)其他切割器
- CharacterTextSplitter:基于字符切割
- MarkdownHeaderTextSplitter:可以根据指定的一组标题来切割一个Markdown 文档
- HTMLSectionSplitter:基于HTML的段切割
- LatexTextSplitter:按照 LaTeX 格式的布局元素来拆分文本
- ...更多详见 官方文档
向量化存储
ini
llm_embeddings = get_ali_embeddings()
# 实例化向量空间,向量化+向量存储到向量数据库中
vector_store = Chroma.from_documents(documents=split_documents,embedding=llm_embeddings)NativeRAG
python
# 向量化
def get_embeddings(self, texts, model=ALI_TONGYI_EMBEDDING_V4):
'''封装 OpenAI 的 Embedding 模型接口'''
data = self.client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]
# 添加文档与向量
def add_documents(self, instructions, outputs):
'''向 collection 中添加文档与向量'''
# 问题进行向量化,答案保持源文档
embeddings = self.get_embeddings(instructions)
self.collection.add(
embeddings=embeddings, # 每个文档的向量
documents=outputs, # 文档的原文
ids=[f"id{i}" for i in range(len(outputs))] # 每个文档的 id
)
print("self.collection.count():", self.collection.count())对比
可见,Langchain封装之后代码更简洁了。我们可以更多地关注业务逻辑,而不是底层操作。
检索器retriever
shell
# 1. # "similarity", 默认,向量相似度检索 默认top-k=4
retriever = vector_store.as_retriever()
# 2. 配置top_k
# retriever = vector_store.as_retriever(
# search_type="similarity", # 相似度检索
# search_kwargs={"k": 3} # 返回前4个最相关文档
# )
# 检索调用
# result = retriever.invoke("晋升")NativeRAG
python
# 检索向量数据库
def search(self, query, n_results):
''' 检索向量数据库
query是用户的查询,
n_results:查出n个相似最高的记录
'''
results = self.collection.query(
query_embeddings=self.get_embeddings([query]),
n_results=n_results
)
return results对比
同样,Langchain方式不仅更简洁,还提供了更丰富的封装接口以满足更广阔的需求。
相似度阈值检索
similarity_score_threshold:相似度阈值检索
- 只返回相似度大于score_threshold的结果
我们修改检索器代码:
shell
# # 3. "similarity_score_threshold", 向量相似度阈值检索
# retriever = vector_store.as_retriever(
# search_type="similarity_score_threshold",
# search_kwargs={
# "score_threshold": 0.4,
# }
# )📢📢📢:我们这里是只是对比三种检索方式,所以执行的不是最终代码,只是中间测试代码。直接检索向量数据库。
scss
# 中间测试
result = retriever.invoke("晋升")
print(result)
exit()-
similarity,page_content = 4个
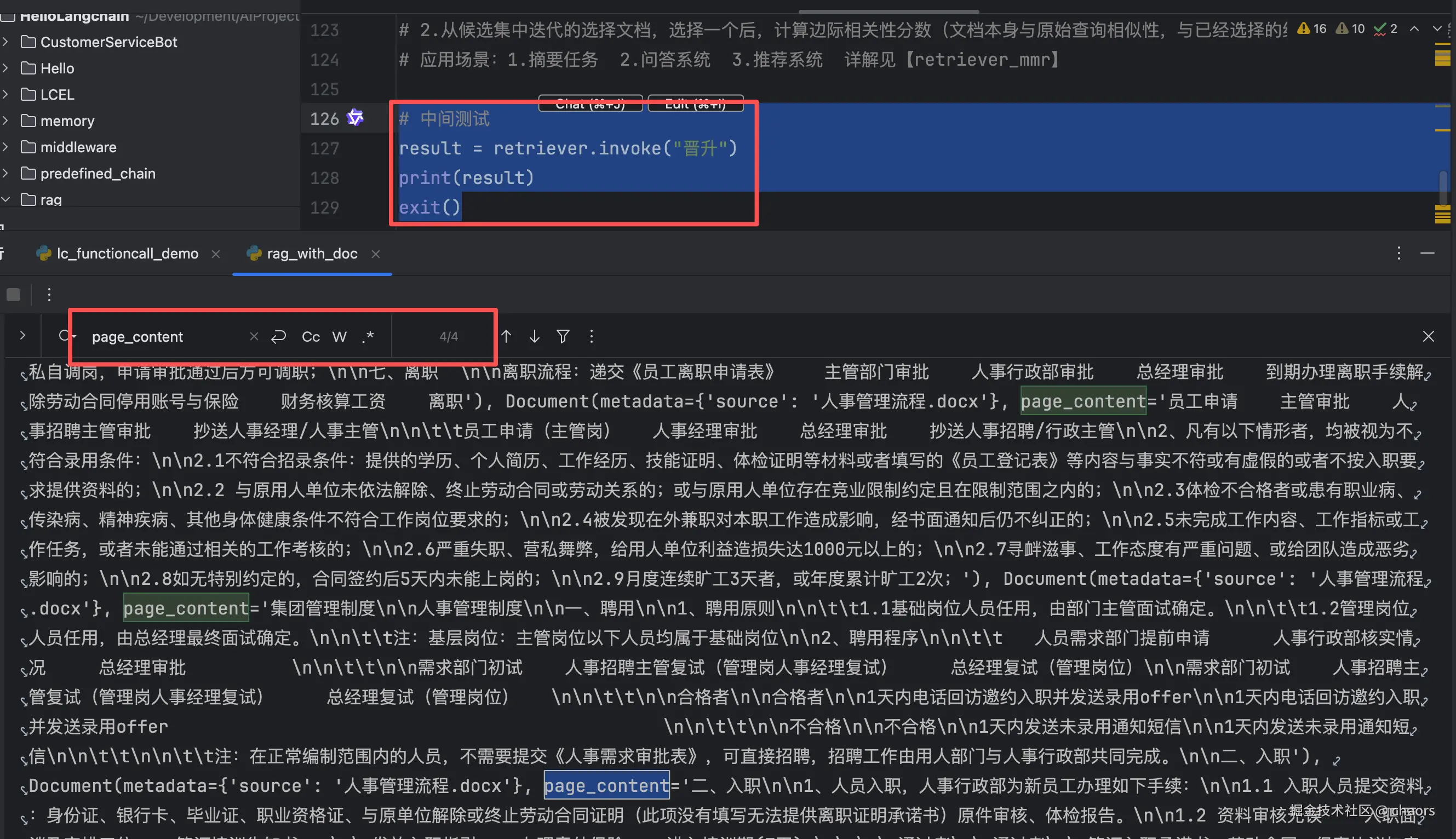
-
score_threshold = 0.4,page_content = 1个
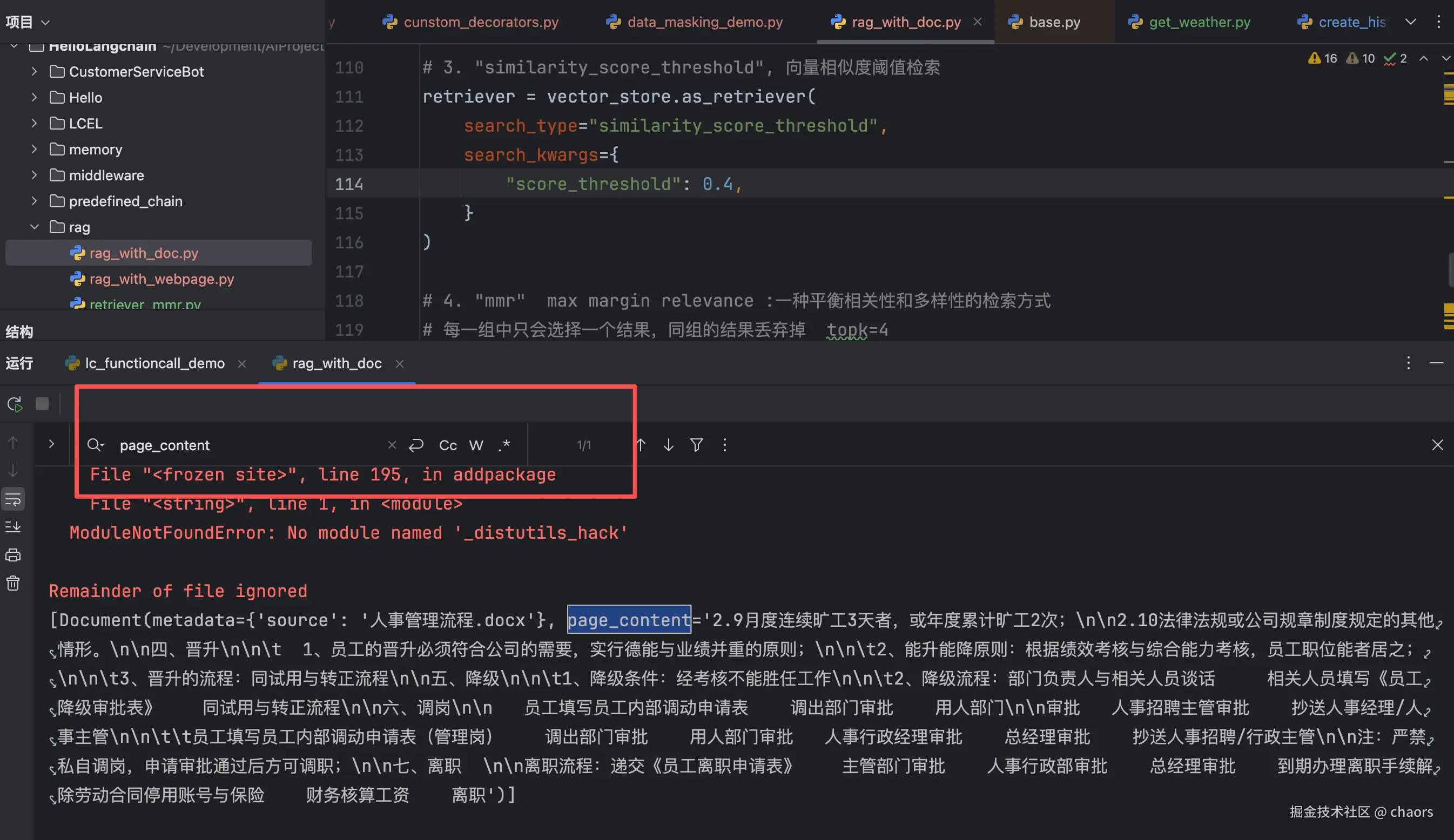
- score_threshold = 0.34,page_content = 2个
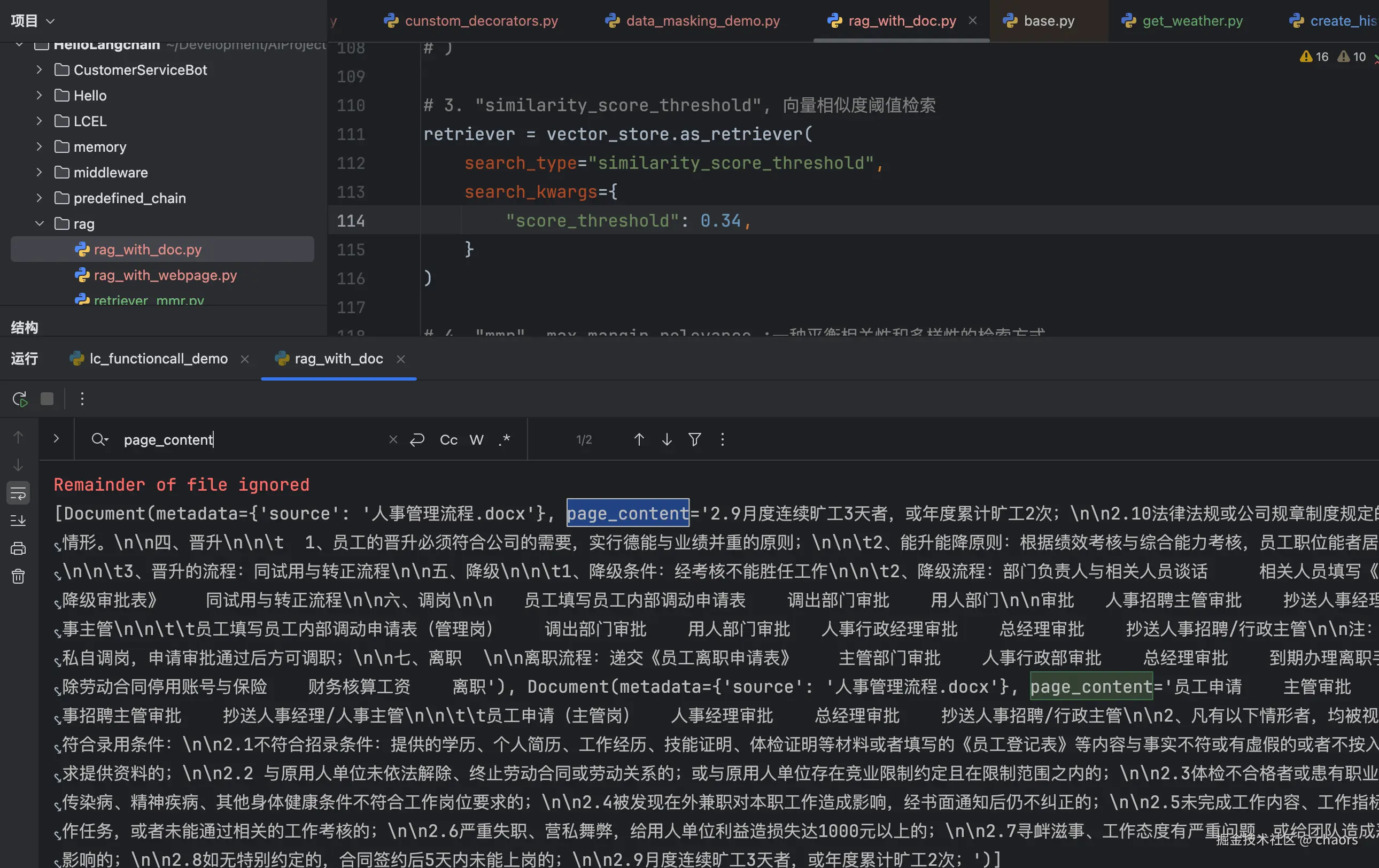
由此可见,score_threshold越高返回的相似块就会越少,也容易导致召回率过低。实际开发中阈值调优往往是最难也最重要的。
-
阈值过高(如0.8):可能导致召回不足,许多相关文档因未达严苛标准而被遗漏,检索结果可能为空。
-
阈值过低(如0.1):可能导致召回过多无关噪音,污染大模型的上下文窗口。
-
建议 :通过抽样观察,人工评估不同分数区间(如
>0.5,0.3~0.5,<0.3)下文档的相关性,找到一个在"查全率"和"查准率"之间的平衡点。
其他检索器
- FAISS 检索器
python
retriever_faiss = FAISS.from_texts(texts, embeddings).as_retriever()- Chroma 检索器
python
retriever_chroma = Chroma.from_documents(docs, embeddings).as_retriever()- 关键词检索器
python
retriever_bm25 = BM25Retriever.from_texts(texts)- 混合检索器 (结合语义+关键词)
python
ensemble_retriever = EnsembleRetriever(
retrievers=[retriever_faiss, retriever_bm25],
weights=[0.7, 0.3] # 权重分配MMR
为什么需要?
除了以上两种相似度检索,Langchain还提供了另一种更高级的方式------------mmr。那么为什么还会有这种检索方式呢?
试想有这样一个简单的🌰:
- 用户提问:AI大模型高效运行的关键要素有哪些?
- 相似度检索(可能结果):《什么是GPU》、《GPU并行计算原理》、《NVIDIA GPU架构详解》------
有没有发现,这三篇都在讲硬件,信息高度冗余。传统相似度检索可能导致检索结果单一、生成答案片面化这一问题。而mmr正是解决这一痛点的,其核心目标在于在确保结果"相关"的前提下,最大限度地引入"新信息",从而让后续的大模型能基于一组"既相关又互补"的上下文,生成更全面、更具洞见的回答。
是什么?
MMR (Maximal Marginal Relevance),最大边际相关性,其核心是一个排序公式,用于在候选文档池中做迭代式选择:
MMR = argmax [λ * Sim(Q, Di) - (1-λ) * max Sim(Dj, Di)]
简单来说,它每次选择下一个文档时,会权衡两个因素:
- 与问题的相关性 :新文档
Di和你提的问题Q有多像。 - 与已选结果的差异性 :新文档
Di和当前已选出的结果Dj们有多不像。
其中的 λ参数是这个权衡的"调节旋钮":
- λ 接近 1:更看重相关性,结果趋近于普通相似性搜索。
- λ 接近 0:更看重多样性,可能会为了引入新角度而牺牲一点点最相关的文档。
- 调参经验:从0.5开始,向0.7(更相关)或0.3(更多样)微调。
Codding
我们重新构造一个更合适的代码案例。
准备工作
1. 数据构造
ini
# 1. 模拟一个包含多领域AI知识的小型文档库
documents = [
Document(page_content="GPU,尤其是NVIDIA的系列产品,通过CUDA架构提供大规模并行计算能力,是训练大模型的基石。"),
Document(page_content="TPU是谷歌专门为神经网络训练设计的张量处理单元,在特定模型上能效比极高。"),
Document(page_content="注意力机制是Transformer模型的核心,它允许模型在处理序列时动态关注不同部分。"),
Document(page_content="混合精度训练(FP16/BF16)可显著减少显存占用并提升计算吞吐,是加速训练的关键工程手段。"),
Document(page_content="模型剪枝和量化是模型压缩的主要技术,用于减少模型大小和推理延迟,便于部署。"),
Document(page_content="分布式训练框架,如PyTorch DDP和DeepSpeed,解决了单卡显存不足问题,实现了超大规模模型训练。"),
]2. 数据库构造
ini
# 2. 文本分割与向量化存储
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
split_docs = text_splitter.split_documents(documents)
# 使用本地Chroma向量数据库
vector_store = Chroma.from_documents(
documents=split_docs,
embedding=get_ali_embeddings() # 或使用开源Embeddings模型
)
# 3. 定义检索器:重点对比普通检索 vs MMR检索
query = "训练大型AI模型有哪些技术挑战和解决方案?"3. 相似度检索
python
# 方法A:普通相似性检索
print("=== 普通相似性检索结果 ==")
retriever_standard = vector_store.as_retriever(
search_kwargs={"k": 3}
)
standard_docs = retriever_standard.invoke(query)
for i, doc in enumerate(standard_docs):
print(f"[Doc {i+1}]: {doc.page_content}...")
print("==" * 60)mmr
- k:top_k个,最终返回的文档数量
- fetch_k:视野广度,fetch_k必须大于 k
- 算法会先从库中召回
fetch_k个(如10个)最相关的候选文档,然后在这10个里用MMR公式精选出k个(3个)最终结果。
- 算法会先从库中召回
- lambda_mult:MMR公式中的
λ,λ越小越偏重多样性,λ越大越偏重相似性
ini
retriever_mmr = vector_store.as_retriever(
search_type="mmr", # 关键参数
search_kwargs={"k": 3, "fetch_k": 10, "lambda_mult": 0.5}
)running
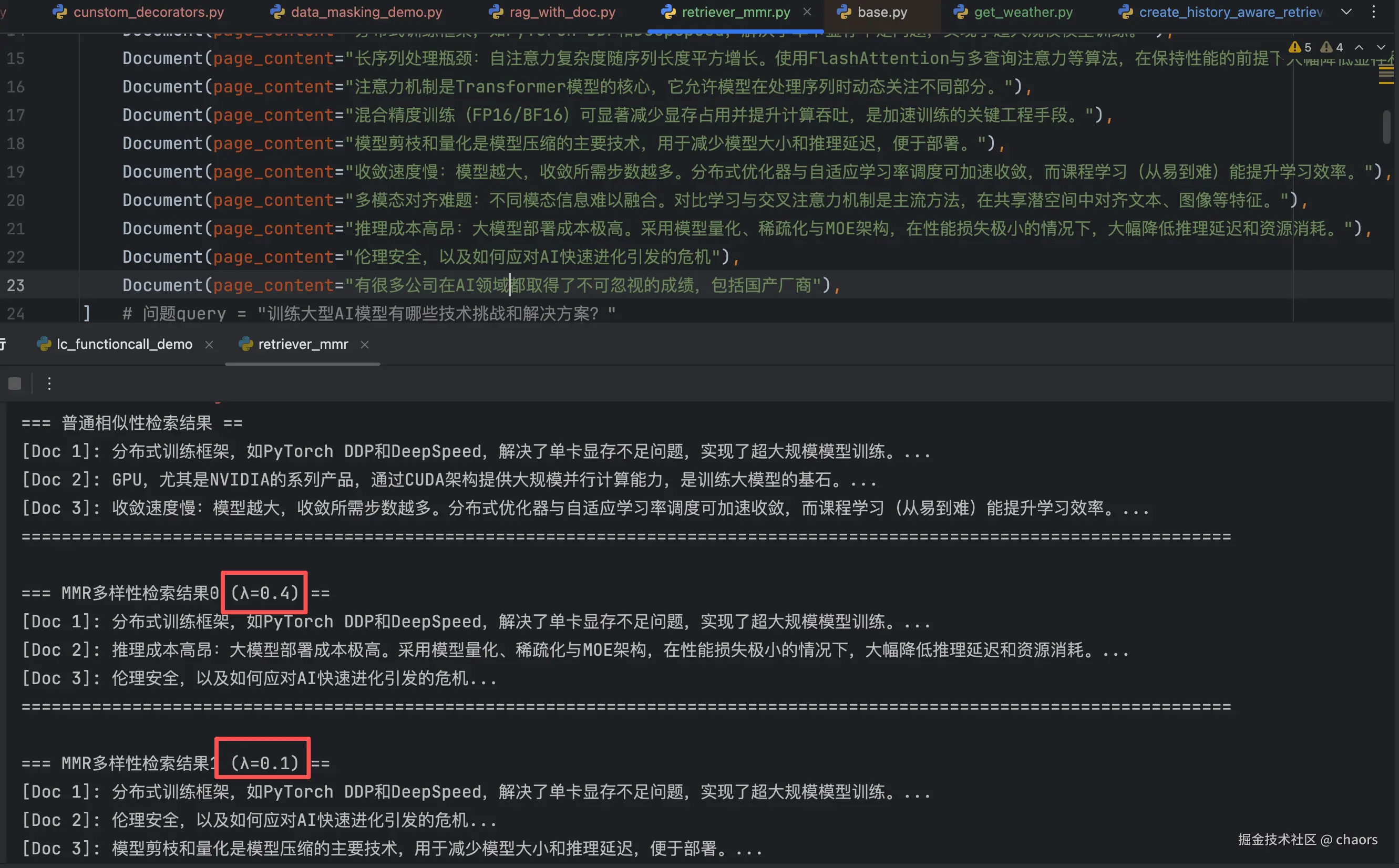
可见,mmr确实让检索答案变得更加丰富了。
大模型生成
ini
message = """
仅使用提供的上下文回答下面的问题:
{question}
上下文:
{context}
"""
prompt_template = ChatPromptTemplate.from_messages([('human',message)])
# 定义这个链的时候,还不知道问题是什么,
# 用RunnablePassthrough允许我们将用户的具体问题在实际使用过程中进行动态传入
chain = {"question":RunnablePassthrough(),"context":retriever} | prompt_template | client
#用大模型生成答案
resp = chain.invoke("晋升")
print(resp.content)大差不差,没有什么可对比的。
至此,使用Langchain框架构建RAG的基本流程就完成了。