机器学习16-tensorflow1.4 使用
- 变量
- Fetch_Feed
-
-
- [一、TensorFlow 中的 Fetch & Feed(深度学习核心)](#一、TensorFlow 中的 Fetch & Feed(深度学习核心))
-
- [1. Fetch(取回)](#1. Fetch(取回))
- [2. Feed(注入)](#2. Feed(注入))
- [3. 核心区别](#3. 核心区别)
- [二、RSS/Atom 订阅源抓取工具(Fetch Feed)](#二、RSS/Atom 订阅源抓取工具(Fetch Feed))
-
- [1. Node.js 库:`@rowanmanning/fetch-feed`](#1. Node.js 库:
@rowanmanning/fetch-feed) - [2. WordPress 函数:`fetch_feed()`](#2. WordPress 函数:
fetch_feed())
- [1. Node.js 库:`@rowanmanning/fetch-feed`](#1. Node.js 库:
- 三、总结
- [TensorFlow 2.x 替代 Fetch/Feed 的核心方案](#TensorFlow 2.x 替代 Fetch/Feed 的核心方案)
- 一、核心逻辑对比
- 二、完整对比示例(附详细注释)
-
- [场景:实现「两数相加+相乘」的计算,对比 Fetch/Feed 与 2.x 写法](#场景:实现「两数相加+相乘」的计算,对比 Fetch/Feed 与 2.x 写法)
-
- [1. TensorFlow 1.x 写法(Fetch/Feed)](#1. TensorFlow 1.x 写法(Fetch/Feed))
- [2. TensorFlow 2.x 写法(动态图 + 直接传参)](#2. TensorFlow 2.x 写法(动态图 + 直接传参))
- [3. TensorFlow 2.x 进阶:tf.function 静态编译(性能优化)](#3. TensorFlow 2.x 进阶:tf.function 静态编译(性能优化))
- [4. 2.x 中「变量更新」替代 Feed 修改变量](#4. 2.x 中「变量更新」替代 Feed 修改变量)
- 三、关键差异总结
- 四、实战建议
-
- 线性回归
-
-
- 一、核心概念回顾
- 二、极简入门版(单特征线性回归)
- [1. 完整可运行代码](#1. 完整可运行代码)
- [2. 关键代码解释](#2. 关键代码解释)
- [3. 运行结果说明](#3. 运行结果说明)
- 三、进阶实战版(多特征线性回归)
-
- [1. 完整代码](#1. 完整代码)
- [2. 核心优化点](#2. 核心优化点)
- 四、关键注意事项(新手避坑)
- 总结
-
- 非线性回归
-
-
- 一、核心原理:如何实现非线性?
- 二、基础版:拟合非线性曲线(单特征)
-
- [场景:拟合 y = 0.5 x 2 + 2 x + 1 + 噪声 y = 0.5x^2 + 2x + 1 + 噪声 y=0.5x2+2x+1+噪声 的二次曲线](#场景:拟合 y = 0.5 x 2 + 2 x + 1 + 噪声 y = 0.5x^2 + 2x + 1 + 噪声 y=0.5x2+2x+1+噪声 的二次曲线)
- [1. 完整可运行代码](#1. 完整可运行代码)
- [2. 关键代码解释](#2. 关键代码解释)
- [3. 运行结果说明](#3. 运行结果说明)
- 三、实战版:多特征非线性回归(房价预测)
-
- 场景:用波士顿房价数据集(13个特征)拟合非线性房价关系
- [1. 完整代码](#1. 完整代码)
- [2. 核心优化点(新手必看)](#2. 核心优化点(新手必看))
- 四、新手避坑指南
- 总结
-
- MNIST数据集
-
- [一、MNIST 的历史:从手写数字识别到深度学习标杆](#一、MNIST 的历史:从手写数字识别到深度学习标杆)
-
- [1. 起源背景](#1. 起源背景)
- [2. 改造与发布](#2. 改造与发布)
- [3. 历史地位](#3. 历史地位)
- [二、MNIST 的定义:核心属性与数据结构](#二、MNIST 的定义:核心属性与数据结构)
-
- [1. 核心定义](#1. 核心定义)
- [2. 关键属性](#2. 关键属性)
- [3. 数据示例](#3. 数据示例)
- [三、MNIST 的原理:数据生成与任务核心逻辑](#三、MNIST 的原理:数据生成与任务核心逻辑)
-
- [1. 数据生成逻辑](#1. 数据生成逻辑)
- [2. 任务核心原理](#2. 任务核心原理)
- [3. 性能基准](#3. 性能基准)
- [四、MNIST 的使用:实战示例(TensorFlow 2.x)](#四、MNIST 的使用:实战示例(TensorFlow 2.x))
-
- [1. 核心使用步骤](#1. 核心使用步骤)
-
- [步骤 1:加载并预处理数据](#步骤 1:加载并预处理数据)
- [步骤 2:构建并训练模型](#步骤 2:构建并训练模型)
- [步骤 3:评估与预测](#步骤 3:评估与预测)
- [2. 常见使用场景](#2. 常见使用场景)
- 总结(核心关键点)
- softmax函数
-
- [一、Softmax 的来历:从逻辑回归到多分类](#一、Softmax 的来历:从逻辑回归到多分类)
-
- [1. 起源背景](#1. 起源背景)
- [2. 命名由来](#2. 命名由来)
- [3. 与 Sigmoid 的关系](#3. 与 Sigmoid 的关系)
- [二、Softmax 的原理:从数学到直观理解](#二、Softmax 的原理:从数学到直观理解)
-
- [1. 数学定义](#1. 数学定义)
- [2. 核心逻辑(分步拆解)](#2. 核心逻辑(分步拆解))
-
- [步骤 1:指数化( e z i e^{z_i} ezi)](#步骤 1:指数化( e z i e^{z_i} ezi))
- [步骤 2:归一化(除以总和)](#步骤 2:归一化(除以总和))
- [3. 直观示例](#3. 直观示例)
- [4. 数值稳定性优化(实战关键)](#4. 数值稳定性优化(实战关键))
- [5. 梯度计算(优化基础)](#5. 梯度计算(优化基础))
- [三、Softmax 的使用:实战场景与代码示例](#三、Softmax 的使用:实战场景与代码示例)
-
- [1. 核心使用场景](#1. 核心使用场景)
- [2. 关键使用规则](#2. 关键使用规则)
- [3. 实战代码示例(TensorFlow 2.x)](#3. 实战代码示例(TensorFlow 2.x))
-
- [示例 1:手动实现 Softmax(理解底层)](#示例 1:手动实现 Softmax(理解底层))
- [示例 2:模型中使用 Softmax(MNIST 多分类)](#示例 2:模型中使用 Softmax(MNIST 多分类))
- [示例 3:框架内置 Softmax(高效版)](#示例 3:框架内置 Softmax(高效版))
- 总结(核心关键点)
- MNIST数据集分类实现
-
- 前置准备
- [方案 1:极简全连接版(入门必学)](#方案 1:极简全连接版(入门必学))
- [方案 2:CNN 进阶版(更高准确率)](#方案 2:CNN 进阶版(更高准确率))
- [完整扩展版代码(CNN + 保存加载 + 错误分析)](#完整扩展版代码(CNN + 保存加载 + 错误分析))
- 关键功能解释
-
- [1. 模型保存与加载](#1. 模型保存与加载)
- [2. 错误样本分析核心逻辑](#2. 错误样本分析核心逻辑)
- [3. 常见问题解决](#3. 常见问题解决)
- 总结
- [完整扩展版(CNN + 数据增强 + 模型量化 + 保存加载 + 错误分析)](#完整扩展版(CNN + 数据增强 + 模型量化 + 保存加载 + 错误分析))
- 核心功能详解
变量
python
import tensorflow as tf
# TensorFlow 1.x 的代码
# # 定义一个变量
# x = tf.Variable([1,2])
# # 定义一个常量
# a = tf.constant([3,3])
# # 减法op
# sub = tf.subtract(x, a)
# # 加法op
# add = tf.add(x,sub)
#
# # 所有变量初始化
# init = tf.global_variables_initializer()
#
# with tf.Session() as sess:
# # 执行变量初始化
# sess.run(init)
# print(sess.run(sub))
# print(sess.run(add))
# TensorFlow 2.x 在即时执行模式下不需要变量初始化器
# 变量在创建时就已经初始化
# 创建变量
var1 = tf.Variable([1, 2])
var2 = tf.Variable([3, 3])
# 直接使用变量
result1 = var1 - var2
print(result1.numpy()) # 输出:
result2 = var1 + result1
print(result2.numpy()) # 输出:Fetch_Feed
Fetch_Feed 通常指两类核心概念:TensorFlow 计算图的 Fetch/Feed 机制 (深度学习核心),以及RSS/Atom 订阅源抓取工具(前端/后端通用)。下面分别详细说明。
一、TensorFlow 中的 Fetch & Feed(深度学习核心)
在 TensorFlow 1.x 静态图模式下,Fetch 用于取回计算结果 ,Feed 用于动态注入数据,是图计算的基础数据交互方式。
1. Fetch(取回)
-
定义 :在
Session.run()中传入一个或多个 Tensor/Op,执行后返回其计算结果。 -
作用:获取模型输出、中间变量、损失值、梯度等。
-
示例 :
pythonimport tensorflow as tf a = tf.constant(2.0) b = tf.constant(3.0) add = tf.add(a, b) mul = tf.multiply(a, b) with tf.Session() as sess: # Fetch 多个值:同时获取 add 和 mul 的结果 add_res, mul_res = sess.run([add, mul]) print(add_res, mul_res) # 输出 5.0 6.0 -
特点 :一次
run可批量取回多个结果,减少会话开销。
2. Feed(注入)
-
定义 :通过
feed_dict在运行时动态替换占位符(placeholder)的值,不修改计算图结构。 -
作用:给模型喂入训练/测试数据、超参数、临时覆盖变量值。
-
示例 :
pythonimport tensorflow as tf # 定义占位符(仅占位置,无初始值) x = tf.placeholder(tf.float32) y = tf.placeholder(tf.float32) z = tf.multiply(x, y) with tf.Session() as sess: # Feed 数据:运行时注入 x=4, y=5 result = sess.run(z, feed_dict={x: 4.0, y: 5.0}) print(result) # 输出 20.0 -
特点 :仅在当前
run内有效,不影响后续计算;支持批量/多维数据注入。
3. 核心区别
| 特性 | Fetch | Feed |
|---|---|---|
| 方向 | 从计算图 → 外部代码 | 外部代码 → 计算图 |
| 对象 | Tensor/Op(输出) | placeholder/变量(输入) |
| 时机 | 执行后取回结果 | 执行前注入数据 |
| 用途 | 获取输出、监控中间值 | 喂入训练数据、动态传参 |
二、RSS/Atom 订阅源抓取工具(Fetch Feed)
Fetch Feed 是一类用于抓取并解析 RSS/Atom 订阅源的工具/库,常见于前端、Node.js、WordPress 等场景。
1. Node.js 库:@rowanmanning/fetch-feed
-
定位 :基于
node-feedparser的 Promise 封装,异步抓取+流式解析 RSS/Atom。 -
核心能力 :
- 支持 HTTP/HTTPS 抓取,自定义请求头、超时、代理。
- 流式处理大 Feed,低内存占用。
- 逐条返回条目(
onEntry),避免全量加载。
-
示例 :
javascriptconst fetchFeed = require('@rowanmanning/fetch-feed'); (async () => { await fetchFeed({ url: 'https://example.com/feed.xml', onEntry: async (entry) => { console.log('文章:', entry.title, entry.link); // 逐条处理 } }); })();
2. WordPress 函数:fetch_feed()
-
定位 :WP 内置函数,基于
SimplePie库抓取+解析+缓存外部 RSS。 -
核心能力 :
- 自动缓存 12 小时(可修改),减少重复请求。
- 返回
SimplePie对象,支持获取标题、摘要、发布时间等。 - 错误处理:返回
WP_Error便于捕获异常。
-
示例 :
php$feed = fetch_feed('https://wordpress.org/news/feed/'); if (!is_wp_error($feed)) { $items = $feed->get_items(0, 5); // 获取前5条 foreach ($items as $item) { echo $item->get_title() . '<br>'; } }
三、总结
- 深度学习场景 :Fetch = 取结果 ,Feed = 喂数据,是 TensorFlow 静态图的核心数据交互机制。
- 数据抓取场景 :Fetch Feed = 抓取+解析 RSS/Atom,用于聚合博客、新闻等订阅内容。
TensorFlow 2.x 替代 Fetch/Feed 的核心方案
TensorFlow 2.x 放弃了 1.x 的静态图 Session 机制,改用动态图(Eager Execution)+ tf.function 静态编译 + 直接传参 替代 Fetch/Feed,更贴近 Python 原生编程习惯。下面通过「对比示例」清晰展示新旧写法的差异,新手也能快速理解。
一、核心逻辑对比
| TensorFlow 1.x(Fetch/Feed) | TensorFlow 2.x(tf.function + 直接传参) |
|---|---|
依赖 Session 运行计算图 |
动态图直接执行,tf.function 可选编译加速 |
Fetch:sess.run([tensor1, tensor2]) 取结果 |
直接调用函数/变量,返回结果 |
Feed:feed_dict={占位符: 数据} 传输入 |
函数直接传参,或用 tf.Variable 赋值 |
二、完整对比示例(附详细注释)
场景:实现「两数相加+相乘」的计算,对比 Fetch/Feed 与 2.x 写法
1. TensorFlow 1.x 写法(Fetch/Feed)
python
import tensorflow as tf
# 1. 定义计算图(静态图)
# 定义占位符(Feed 传参的载体)
x = tf.placeholder(tf.float32, name="x")
y = tf.placeholder(tf.float32, name="y")
# 定义计算操作
add_op = tf.add(x, y, name="add")
mul_op = tf.multiply(x, y, name="mul")
# 2. 启动 Session 执行计算
with tf.Session() as sess:
# Feed:通过 feed_dict 注入数据
# Fetch:同时取回 add_op 和 mul_op 的结果
add_result, mul_result = sess.run(
[add_op, mul_op], # Fetch 目标
feed_dict={x: 4.0, y: 5.0} # Feed 注入数据
)
print(f"TF1.x 结果:相加={add_result},相乘={mul_result}")
# 输出:TF1.x 结果:相加=9.0,相乘=20.02. TensorFlow 2.x 写法(动态图 + 直接传参)
python
import tensorflow as tf
tf.config.run_functions_eagerly(True) # 默认开启动态图,可省略
# 1. 定义普通函数(无需计算图,直接传参)
def calc_ops(x, y):
add_res = tf.add(x, y)
mul_res = tf.multiply(x, y)
return add_res, mul_res # 直接返回结果(替代 Fetch)
# 2. 直接调用函数传参(替代 Feed)
add_result, mul_result = calc_ops(4.0, 5.0)
print(f"TF2.x 动态图结果:相加={add_result.numpy()},相乘={mul_result.numpy()}")
# 输出:TF2.x 动态图结果:相加=9.0,相乘=20.0
# 注:.numpy() 用于将 Tensor 转为 Python 数值(可选,Tensor 可直接计算)3. TensorFlow 2.x 进阶:tf.function 静态编译(性能优化)
如果需要静态图的性能优势(如大规模计算/部署),用 tf.function 装饰函数,传参逻辑不变:
python
import tensorflow as tf
# 1. 用 tf.function 编译函数(静态图加速)
@tf.function
def calc_ops_compiled(x, y):
add_res = tf.add(x, y)
mul_res = tf.multiply(x, y)
return add_res, mul_res
# 2. 直接传参调用(和动态图写法完全一致)
add_result, mul_result = calc_ops_compiled(4.0, 5.0)
print(f"TF2.x tf.function 结果:相加={add_result.numpy()},相乘={mul_result.numpy()}")
# 输出:TF2.x tf.function 结果:相加=9.0,相乘=20.0
# 关键特性:
# - 第一次调用编译静态图,后续调用复用(速度提升)
# - 传参支持 Python 数值、NumPy 数组、Tensor,自动兼容4. 2.x 中「变量更新」替代 Feed 修改变量
1.x 中 Feed 可临时覆盖变量值,2.x 直接通过 tf.Variable 赋值实现:
python
import tensorflow as tf
# 定义可训练变量
var = tf.Variable(10.0, name="var")
# 直接赋值(替代 Feed 临时覆盖)
var.assign(20.0)
print(f"变量赋值后:{var.numpy()}") # 输出:20.0
# 结合 tf.function 修改变量
@tf.function
def update_var(new_value):
var.assign(new_value)
return var
update_var(30.0)
print(f"tf.function 更新后:{var.numpy()}") # 输出:30.0三、关键差异总结
| 特性 | TensorFlow 1.x | TensorFlow 2.x |
|---|---|---|
| 执行方式 | 先定义图,再 Session 运行 | 动态图即时执行,tf.function 可选编译 |
| 传参(Feed 替代) | feed_dict 给占位符传值 | 函数直接传参,支持 Python/NumPy/Tensor |
| 取结果(Fetch 替代) | sess.run(tensor1, tensor2) | 函数直接返回结果,.numpy() 转 Python 值 |
| 变量修改 | Feed 临时覆盖 | tf.Variable.assign() 直接赋值 |
| 代码风格 | 脱离 Python 原生逻辑 | 贴近 Python 函数式编程,更易理解 |
四、实战建议
- 新手优先用动态图:无需关注编译,直接写函数传参,降低学习成本;
- 性能要求高时加 tf.function:仅需给函数加装饰器,传参逻辑不变;
- 避免踩坑 :
tf.function内避免使用 Python 原生循环/条件(用 tf.while_loop/tf.cond);- 传参尽量用 Tensor 类型(NumPy 会自动转换,但频繁转换影响性能);
- 变量更新必须用
assign(),而非直接赋值(如var = 20会创建新变量)。
通过这种写法,2.x 彻底抛弃了 1.x 繁琐的 Session/Fetch/Feed 机制,代码更简洁、更符合直觉,同时保留了静态图的性能优势。
线性回归
TensorFlow 实现线性回归是入门深度学习的经典案例,核心是用梯度下降优化损失函数 ,拟合输入特征与输出标签的线性关系( y = w x + b y = wx + b y=wx+b)。下面用 TensorFlow 2.x(动态图+Keras 高层 API)给出极简入门版 和进阶实战版,新手也能直接跑通,同时解释核心逻辑。
一、核心概念回顾
线性回归的目标:找到最优的权重 w w w(斜率)和偏置 b b b(截距),让预测值 y ^ = w ⋅ x + b \hat{y} = w \cdot x + b y^=w⋅x+b 尽可能接近真实值 y y y,常用均方误差(MSE) 作为损失函数:
M S E = 1 n ∑ i = 1 n ( y ^ i − y i ) 2 MSE = \frac{1}{n}\sum_{i=1}^n (\hat{y}_i - y_i)^2 MSE=n1i=1∑n(y^i−yi)2
TensorFlow 会自动计算损失函数对 w w w 和 b b b 的梯度,通过梯度下降更新参数,直到损失收敛。
二、极简入门版(单特征线性回归)
1. 完整可运行代码
python
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# ===================== 1. 准备数据 =====================
# 生成模拟数据:y = 2x + 1 + 少量噪声(模拟真实场景)
x = np.random.rand(100, 1) # 输入特征:100个样本,单特征
y = 2 * x + 1 + np.random.randn(100, 1) * 0.1 # 真实标签,加噪声
# ===================== 2. 定义模型 =====================
# 用 Sequential 搭建线性回归模型(仅1个全连接层)
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, input_shape=(1,)) # 输出维度1,输入维度1
])
# ===================== 3. 编译模型 =====================
# 优化器:梯度下降(Adam 是改进版梯度下降,更稳定)
# 损失函数:均方误差(MSE)
# 评估指标:平均绝对误差(MAE)
model.compile(optimizer='adam',
loss='mse',
metrics=['mae'])
# ===================== 4. 训练模型 =====================
# epochs:训练轮数;verbose:打印训练过程
history = model.fit(x, y, epochs=100, verbose=1)
# ===================== 5. 预测与可视化 =====================
# 用训练好的模型预测
x_test = np.linspace(0, 1, 100).reshape(-1, 1) # 测试数据
y_pred = model.predict(x_test)
# 打印最终拟合的 w 和 b
w, b = model.layers[0].get_weights()
print(f"拟合的权重 w = {w[0][0]:.4f},偏置 b = {b[0]:.4f}")
# 可视化结果
plt.scatter(x, y, label='真实数据')
plt.plot(x_test, y_pred, 'r-', label='拟合直线')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()
# 可视化损失变化(看训练是否收敛)
plt.plot(history.history['loss'])
plt.xlabel('Epoch')
plt.ylabel('Loss (MSE)')
plt.title('训练损失变化')
plt.show()2. 关键代码解释
| 代码段 | 作用 |
|---|---|
Dense(1, input_shape=(1,)) |
定义线性层:Dense(输出维度, 输入维度),内部自动初始化 w w w 和 b b b |
model.compile(optimizer='adam', loss='mse') |
配置训练规则:用 Adam 优化器最小化均方误差 |
model.fit(x, y, epochs=100) |
训练模型:用 x 和 y 迭代 100 轮,自动更新 w w w 和 b b b |
model.layers[0].get_weights() |
获取训练后的 w w w 和 b b b(理想值接近 2 和 1) |
3. 运行结果说明
- 训练过程中,Loss(MSE)会逐渐下降并趋于稳定;
- 最终拟合的 w ≈ 2 w≈2 w≈2, b ≈ 1 b≈1 b≈1(因噪声略有偏差);
- 可视化图中,红色直线会贴合蓝色散点的整体趋势。
三、进阶实战版(多特征线性回归)
真实场景中常涉及多特征(如房价预测:面积、楼层、朝向),下面以"波士顿房价数据集"为例,实现多特征线性回归:
1. 完整代码
python
import tensorflow as tf
from tensorflow.keras.datasets import boston_housing
import numpy as np
# ===================== 1. 加载并预处理数据 =====================
# 加载波士顿房价数据集(多特征,标签为房价)
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()
# 数据标准化(多特征必须做!避免特征尺度差异影响训练)
mean = x_train.mean(axis=0)
std = x_train.std(axis=0)
x_train = (x_train - mean) / std
x_test = (x_test - mean) / std
# ===================== 2. 定义多特征线性模型 =====================
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, input_shape=(x_train.shape[1],)) # 输入维度=特征数(13)
])
# ===================== 3. 编译与训练 =====================
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='mse',
metrics=['mae'])
# 添加早停(避免过拟合):验证损失不下降则停止训练
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', patience=5, restore_best_weights=True
)
# 训练(加入验证集,监控泛化能力)
history = model.fit(
x_train, y_train,
epochs=200,
batch_size=32, # 批次大小:每次用32个样本更新参数
validation_split=0.2, # 用20%训练数据做验证
callbacks=[early_stopping],
verbose=1
)
# ===================== 4. 评估与预测 =====================
# 在测试集上评估
test_loss, test_mae = model.evaluate(x_test, y_test)
print(f"测试集均方误差(MSE):{test_loss:.4f}")
print(f"测试集平均绝对误差(MAE):{test_mae:.4f}(单位:千美元)")
# 预测单个样本
sample = x_test[0:1] # 取第一个测试样本
pred_price = model.predict(sample)
print(f"真实房价:{y_test[0]:.2f} 千美元,预测房价:{pred_price[0][0]:.2f} 千美元")2. 核心优化点
- 数据标准化 :
(x - mean) / std,让所有特征处于同一尺度(如面积:0-100,楼层:1-30 → 均标准化为 0 均值、1 方差),否则梯度下降会收敛极慢; - 学习率调整 :
Adam(learning_rate=0.01),学习率过大震荡不收敛,过小训练慢,需根据场景微调; - 早停(EarlyStopping):监控验证损失,避免模型"死记硬背"训练数据(过拟合);
- 批次训练(batch_size):每次用 32 个样本计算梯度,平衡训练速度和稳定性。
四、关键注意事项(新手避坑)
- 单特征 vs 多特征:单特征无需标准化,多特征必须标准化;
- 损失收敛判断:训练损失持续下降且验证损失不再下降 → 训练完成;若验证损失上升 → 过拟合,需早停;
- 优化器选择 :
- 入门用
adam(自适应学习率,无需手动调); - 想理解梯度下降本质,可改用
sgd(随机梯度下降):optimizer=tf.keras.optimizers.SGD(learning_rate=0.1);
- 入门用
- 模型简化:线性回归本质是"无激活函数的单层全连接网络",无需加隐藏层(加了就是非线性模型)。
总结
- TensorFlow 实现线性回归的核心流程:准备数据 → 定义线性层 → 编译(优化器+损失) → 训练 → 评估/预测;
- 单特征线性回归重点理解 w w w 和 b b b 的拟合过程,多特征必须做数据标准化;
- 实战中通过早停、调整学习率、批次训练提升模型泛化能力。
如果需要,我可以补充「手动实现梯度下降(不用 Keras 高层 API)」的版本,帮你理解 TensorFlow 梯度计算的底层逻辑。
非线性回归
TensorFlow 实现非线性回归的核心是在线性层基础上引入非线性激活函数、增加隐藏层 ,拟合输入和输出之间的非线性关系(如曲线、曲面)。相比于线性回归(仅 y = w x + b y=wx+b y=wx+b),非线性回归能处理更复杂的真实场景(如房价预测、销量预测、曲线拟合)。
下面我会用 TensorFlow 2.x 给出「基础曲线拟合版」和「实战多特征版」,从原理到代码讲透,新手也能直接跑通。
一、核心原理:如何实现非线性?
线性回归的局限是"只能拟合直线",而非线性回归通过以下方式突破:
- 添加隐藏层:用多层全连接层构建深度,捕捉复杂特征;
- 激活函数 :在层之间加入非线性激活(如
ReLU、Sigmoid、Tanh),让模型能拟合曲线/曲面; - 损失函数:仍用均方误差(MSE),优化目标仍是最小化预测值与真实值的误差。
常见非线性关系示例:
- 二次函数: y = x 2 + 2 x + 1 y = x^2 + 2x + 1 y=x2+2x+1
- 指数函数: y = e 0.5 x + sin ( x ) y = e^{0.5x} + \sin(x) y=e0.5x+sin(x)
- 多特征非线性:房价 = 面积² × 地段系数 + 楼层 × 0.8 - 年限³
二、基础版:拟合非线性曲线(单特征)
场景:拟合 y = 0.5 x 2 + 2 x + 1 + 噪声 y = 0.5x^2 + 2x + 1 + 噪声 y=0.5x2+2x+1+噪声 的二次曲线
1. 完整可运行代码
python
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# ===================== 1. 生成非线性模拟数据 =====================
x = np.linspace(-5, 5, 200).reshape(-1, 1) # 输入:-5到5的200个点,单特征
# 非线性真实值 + 少量噪声(模拟真实场景)
y = 0.5 * x**2 + 2 * x + 1 + np.random.randn(200, 1) * 0.5
# ===================== 2. 定义非线性回归模型 =====================
# 核心:添加隐藏层 + 非线性激活函数(ReLU)
model = tf.keras.Sequential([
# 隐藏层1:16个神经元,ReLU激活(引入非线性)
tf.keras.layers.Dense(16, activation='relu', input_shape=(1,)),
# 隐藏层2:8个神经元,ReLU激活(增强非线性拟合能力)
tf.keras.layers.Dense(8, activation='relu'),
# 输出层:1个神经元(回归任务输出维度=1),无激活(回归不需要)
tf.keras.layers.Dense(1)
])
# ===================== 3. 编译模型 =====================
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), # 自适应优化器
loss='mse', # 回归任务核心损失:均方误差
metrics=['mae'] # 评估指标:平均绝对误差
)
# ===================== 4. 训练模型 =====================
history = model.fit(
x, y,
epochs=100, # 训练轮数
verbose=1, # 打印训练过程
validation_split=0.2 # 20%数据做验证,监控过拟合
)
# ===================== 5. 预测与可视化 =====================
# 生成测试数据(覆盖更宽范围)
x_test = np.linspace(-6, 6, 200).reshape(-1, 1)
y_pred = model.predict(x_test)
# 可视化拟合结果
plt.scatter(x, y, label='真实数据', alpha=0.6)
plt.plot(x_test, y_pred, 'r-', linewidth=2, label='非线性拟合曲线')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.title('TensorFlow 非线性回归(二次曲线拟合)')
plt.show()
# 可视化训练损失(判断是否收敛)
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.xlabel('Epoch')
plt.ylabel('Loss (MSE)')
plt.legend()
plt.title('训练/验证损失变化')
plt.show()2. 关键代码解释
| 代码段 | 作用 |
|---|---|
Dense(16, activation='relu') |
隐藏层+ReLU激活:ReLU是最常用的非线性激活,解决"线性叠加仍为线性"的问题 |
validation_split=0.2 |
拆分验证集:若验证损失持续上升,说明模型过拟合(需减少隐藏层/神经元) |
| 输出层无激活 | 回归任务输出是连续值,无需激活;分类任务才需要(如Sigmoid) |
3. 运行结果说明
- 红色拟合曲线会紧密贴合蓝色散点的二次曲线趋势(远优于线性回归的直线拟合);
- 训练/验证损失均下降并趋于稳定,说明模型收敛且无严重过拟合。
三、实战版:多特征非线性回归(房价预测)
场景:用波士顿房价数据集(13个特征)拟合非线性房价关系
1. 完整代码
python
import tensorflow as tf
from tensorflow.keras.datasets import boston_housing
import numpy as np
# ===================== 1. 数据加载与预处理 =====================
# 加载数据集(多特征,标签为房价)
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()
# 数据标准化(多特征必须做!消除尺度差异)
mean = x_train.mean(axis=0)
std = x_train.std(axis=0)
x_train = (x_train - mean) / std
x_test = (x_test - mean) / std
# ===================== 2. 定义多特征非线性模型 =====================
model = tf.keras.Sequential([
# 隐藏层1:32神经元 + ReLU
tf.keras.layers.Dense(32, activation='relu', input_shape=(x_train.shape[1],)),
# 隐藏层2:16神经元 + ReLU
tf.keras.layers.Dense(16, activation='relu'),
# 输出层:1个神经元(房价预测)
tf.keras.layers.Dense(1)
])
# ===================== 3. 编译模型(加入早停避免过拟合) =====================
# 早停回调:验证损失5轮不下降则停止,恢复最优权重
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=5,
restore_best_weights=True
)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='mse',
metrics=['mae']
)
# ===================== 4. 训练模型 =====================
history = model.fit(
x_train, y_train,
epochs=200,
batch_size=16,
validation_split=0.2,
callbacks=[early_stopping],
verbose=1
)
# ===================== 5. 评估与预测 =====================
# 测试集评估
test_loss, test_mae = model.evaluate(x_test, y_test)
print(f"测试集MSE:{test_loss:.4f},测试集MAE:{test_mae:.4f}(千美元)")
# 预测单个样本
sample = x_test[0:1]
pred_price = model.predict(sample)
print(f"真实房价:{y_test[0]:.2f} 千美元,预测房价:{pred_price[0][0]:.2f} 千美元")2. 核心优化点(新手必看)
- 隐藏层/神经元数量 :
- 太少:拟合能力不足(欠拟合);
- 太多:过拟合(训练损失低,验证损失高);
- 经验值:单特征用 2-3 层(8-32神经元),多特征用 2-4 层(16-64神经元)。
- 激活函数选择 :
- 隐藏层优先用
ReLU(计算快、梯度消失少); - 输出层:回归任务无激活,分类任务用
Sigmoid(二分类)/Softmax(多分类)。
- 隐藏层优先用
- 早停(EarlyStopping):核心防过拟合手段,避免模型"死记硬背"训练数据。
四、新手避坑指南
- 非线性回归≠复杂模型:哪怕只有1层隐藏层+ReLU,也能拟合非线性关系;
- 数据标准化是刚需:多特征场景下,特征尺度差异会导致梯度下降收敛极慢,甚至不收敛;
- 过拟合处理 :
- 减少隐藏层/神经元数量;
- 加入
Dropout层(随机丢弃部分神经元):tf.keras.layers.Dropout(0.2); - 用早停、L2正则化(
kernel_regularizer=tf.keras.regularizers.l2(0.01));
- 学习率调整 :
- 学习率太大:损失震荡不收敛;
- 学习率太小:训练速度极慢;
- 经验值:Adam优化器用 0.001~0.01,SGD用 0.01~0.1。
总结
- TensorFlow 非线性回归的核心:隐藏层 + 非线性激活函数(替代纯线性层);
- 流程与线性回归一致:数据预处理 → 定义非线性模型 → 编译 → 训练 → 评估;
- 关键调优:控制模型复杂度(隐藏层/神经元)、标准化数据、用早停防过拟合。
如果需要,我可以补充「手动实现非线性回归(不用Keras高层API)」的版本,帮你理解TensorFlow梯度计算的底层逻辑(如自定义损失、手动求梯度)。
MNIST数据集
MNIST 数据集是机器学习/深度学习领域的「Hello World」级经典数据集,几乎所有入门者都会用它上手分类任务。下面从历史、定义、原理、使用四个核心维度,用通俗易懂的方式完整讲解,兼顾新手理解和实战参考。
一、MNIST 的历史:从手写数字识别到深度学习标杆
1. 起源背景
MNIST(Modified National Institute of Standards and Technology database)的前身是 1980 年代美国国家标准与技术研究院(NIST)收集的手写数字数据集:
- NIST 数据集包含两部分:训练集来自美国人口普查局员工,测试集来自美国高中生;
- 原始 NIST 数据存在格式不统一、分辨率不一致、噪声多等问题,不适合直接用于算法训练。
2. 改造与发布
1998 年,纽约大学的 Yann LeCun(深度学习三巨头之一,CNN 之父)团队对 NIST 数据做了标准化改造:
- 统一将所有数字图像缩放为 28×28 像素的灰度图;
- 中心化数字位置,去除冗余背景;
- 标准化像素值范围(0~255 灰度值);
- 拆分出 60000 个训练样本 + 10000 个测试样本,形成最终的 MNIST 数据集。
3. 历史地位
- 是第一个大规模、标准化的手写数字识别数据集,成为机器学习算法(SVM、决策树、神经网络)的基准测试集;
- 2012 年 AlexNet 问世前,MNIST 是衡量手写数字识别算法性能的「金标准」;
- 至今仍是深度学习入门的首选数据集(简单、易训练、无数据清洗成本)。
二、MNIST 的定义:核心属性与数据结构
1. 核心定义
MNIST 是一个手写数字(0-9)图像分类数据集 ,目标是让算法识别手写的 0~9 这 10 个阿拉伯数字,属于单标签多分类任务(每个图像仅对应一个数字)。
2. 关键属性
| 维度 | 具体信息 |
|---|---|
| 数据类型 | 灰度图像(无彩色通道) |
| 图像尺寸 | 28×28 像素(总 784 个像素点) |
| 像素值范围 | 0(黑色,背景)~ 255(白色,数字笔画),通常归一化为 0~1 区间 |
| 样本数量 | 训练集:60000 张;测试集:10000 张 |
| 类别数量 | 10 类(0、1、2、...、9) |
| 样本分布 | 训练集/测试集中每个数字的样本数量基本均衡(每类约 6000 个训练样本) |
| 数据格式 | 经典格式为二进制文件(.idx3-ubyte),也可通过框架(TensorFlow/PyTorch)直接调用 |
3. 数据示例
- 一张 28×28 的 MNIST 图像,本质是一个 784 维的向量(将 28×28 矩阵展平);
- 标签是 0~9 的整数(如数字「5」的标签为 5),训练时通常转为 one-hot 编码(如 5 → 0,0,0,0,0,1,0,0,0,0)。
三、MNIST 的原理:数据生成与任务核心逻辑
1. 数据生成逻辑
MNIST 的每一张图像都来自真实手写数字:
- 采集手写数字的纸质表单,通过扫描仪转为数字图像;
- 裁剪出仅包含数字的区域,缩放为 28×28 固定尺寸;
- 灰度化处理(去除颜色信息,减少计算量);
- 中心化数字位置,确保数字在图像中心区域;
- 拆分训练/测试集(按 6:1 比例),保证两类数据集的分布一致。
2. 任务核心原理
MNIST 的核心任务是图像分类,背后的逻辑是:
- 特征提取 :从 28×28 像素中提取数字的关键特征(如轮廓、笔画走向、封闭区域等);
- 传统机器学习(如 SVM):手动设计特征(如像素均值、边缘检测、HOG 特征);
- 深度学习(如 CNN):模型自动学习特征(卷积层提取局部特征,池化层降维,全连接层分类)。
- 分类预测:将提取的特征映射到 0~9 这 10 个类别,输出每个类别的概率,取概率最大的作为预测结果;
- 损失与优化:用交叉熵损失(多分类任务核心损失)衡量预测值与真实标签的差距,通过梯度下降优化模型参数,最终让预测准确率提升。
3. 性能基准
- 传统机器学习(如 SVM + HOG 特征):准确率约 98%;
- 简单 CNN(如 LeNet-5,Yann LeCun 1998 年提出):准确率约 99.2%;
- 现代深度学习模型:准确率可达 99.7%+(接近人类水平)。
四、MNIST 的使用:实战示例(TensorFlow 2.x)
MNIST 几乎所有深度学习框架都提供了一键调用接口,下面以 TensorFlow 为例,给出最简入门版使用代码,新手可直接运行。
1. 核心使用步骤
步骤 1:加载并预处理数据
python
import tensorflow as tf
import matplotlib.pyplot as plt
# 1. 加载MNIST数据集(框架自动下载,无需手动处理)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 2. 数据预处理(关键步骤)
# 归一化:将像素值从 0~255 转为 0~1(加速模型训练)
x_train = x_train / 255.0
x_test = x_test / 255.0
# 增加通道维度(CNN 需要 4 维输入:样本数×高度×宽度×通道数)
x_train = x_train[..., tf.newaxis] # 形状:(60000, 28, 28, 1)
x_test = x_test[..., tf.newaxis] # 形状:(10000, 28, 28, 1)
# 标签转为one-hot编码(可选,取决于损失函数)
y_train_onehot = tf.keras.utils.to_categorical(y_train, 10)
y_test_onehot = tf.keras.utils.to_categorical(y_test, 10)
# 3. 可视化单个样本(直观理解数据)
plt.imshow(x_train[0].reshape(28, 28), cmap='gray')
plt.title(f"Label: {y_train[0]}")
plt.axis('off')
plt.show()步骤 2:构建并训练模型
python
# 1. 构建简单CNN模型(适配MNIST)
model = tf.keras.Sequential([
# 卷积层:提取局部特征(32个3×3卷积核,ReLU激活)
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
# 池化层:降维,减少计算量(2×2池化窗口)
tf.keras.layers.MaxPooling2D((2, 2)),
# 第二层卷积+池化
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
# 展平层:将2D特征转为1D向量
tf.keras.layers.Flatten(),
# 全连接层:特征融合
tf.keras.layers.Dense(64, activation='relu'),
# 输出层:10个神经元(对应10类),Softmax激活(输出概率)
tf.keras.layers.Dense(10, activation='softmax')
])
# 2. 编译模型
model.compile(
optimizer='adam', # 自适应优化器
loss='categorical_crossentropy', # 多分类交叉熵损失
metrics=['accuracy'] # 评估指标:分类准确率
)
# 3. 训练模型
history = model.fit(
x_train, y_train_onehot,
epochs=5, # 训练轮数(MNIST简单,5轮足够)
batch_size=64,
validation_split=0.1 # 10%训练数据做验证
)步骤 3:评估与预测
python
# 1. 在测试集上评估模型
test_loss, test_acc = model.evaluate(x_test, y_test_onehot)
print(f"测试集准确率:{test_acc:.4f}") # 通常可达 99%+
# 2. 预测单个样本
sample = x_test[0:1] # 取第一个测试样本
pred_prob = model.predict(sample)
pred_label = tf.argmax(pred_prob, axis=1).numpy()[0]
true_label = y_test[0]
print(f"预测标签:{pred_label},真实标签:{true_label}")2. 常见使用场景
- 新手入门:学习 CNN、分类模型、梯度下降的基础;
- 算法基准测试:验证新模型/优化器的性能(如对比不同激活函数、优化器的效果);
- 教学演示:直观展示机器学习/深度学习的分类效果;
- 轻量化部署测试:验证模型在边缘设备(如手机、单片机)的运行效率。
总结(核心关键点)
- 历史:1998 年由 Yann LeCun 团队基于 NIST 改造,是手写数字识别的经典基准数据集;
- 定义:28×28 灰度手写数字图像集,6万训练+1万测试样本,10分类任务;
- 原理:核心是从像素中提取数字特征,通过分类算法映射到 0~9 类别;
- 使用:所有主流框架一键调用,预处理仅需归一化+维度调整,是深度学习入门的首选案例。
MNIST 的价值不在于解决实际业务问题(真实场景的手写数字识别需处理更复杂的噪声、变形),而在于低门槛、高效率地理解机器学习分类的核心逻辑,是新手从理论到实战的最佳跳板。
softmax函数
Softmax 激活函数是深度学习中多分类任务的核心激活函数 ,它能将模型输出的原始分数(Logits)转化为 0~1 之间的概率分布,且所有类别概率之和为 1,是理解多分类任务的关键。下面从来历、原理、使用三个维度完整讲解,兼顾理论和实战。
一、Softmax 的来历:从逻辑回归到多分类
1. 起源背景
Softmax 最早由数学家 John S. Bridle 在 1990 年的论文《Probabilistic Interpretation of Feedforward Classification Network Outputs》中正式提出,核心动机是:
- 二分类任务可用 Sigmoid 函数 将输出转为 0~1 的概率(如正类概率 P,负类概率 1-P);
- 多分类任务需要一种函数,能将多个原始输出(Logits)映射为和为 1 的概率分布,且保留类别间的相对大小。
2. 命名由来
- "Soft":相对于"Hardmax"(硬最大值,直接取输出中最大的那个类别,其余为 0),Softmax 是"软最大值"------ 既突出最大分数的类别,又给其他类别分配非零概率;
- "max":核心是让分数最高的类别概率最大,符合多分类"选最可能类别"的目标。
3. 与 Sigmoid 的关系
Sigmoid 是 Softmax 的二分类特例:
- Sigmoid: σ ( x ) = 1 1 + e − x σ(x) = \frac{1}{1+e^{-x}} σ(x)=1+e−x1(输出单个概率);
- 二分类 Softmax:对两个类别输出 e x 1 e x 1 + e x 2 \frac{e^{x_1}}{e^{x_1}+e^{x_2}} ex1+ex2ex1 和 e x 2 e x 1 + e x 2 \frac{e^{x_2}}{e^{x_1}+e^{x_2}} ex1+ex2ex2,等价于 Sigmoid 结果( P = σ ( x 1 − x 2 ) P=σ(x_1-x_2) P=σ(x1−x2))。
二、Softmax 的原理:从数学到直观理解
1. 数学定义
假设模型对一个样本输出 K K K 个原始分数(Logits): z 1 , z 2 , . . . , z K z_1, z_2, ..., z_K z1,z2,...,zK(对应 K K K 个类别),Softmax 对第 i i i 个类别的输出为:
σ ( z i ) = e z i ∑ j = 1 K e z j \sigma(z_i) = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}} σ(zi)=∑j=1Kezjezi
2. 核心逻辑(分步拆解)
步骤 1:指数化( e z i e^{z_i} ezi)
- 把原始分数(可正可负)转为非负数,避免概率为负;
- 放大分数间的差距:分数越高,指数后的值越大,最终概率也越大(符合"突出高分数类别"的目标)。
步骤 2:归一化(除以总和)
- 将指数化后的结果除以所有类别指数化的总和,让最终输出满足:
- 每个类别概率 ∈ 0,1;
- 所有类别概率之和 = 1(符合概率分布的定义)。
3. 直观示例
假设模型对"MNIST数字3"输出原始分数: z 0 = 1 , z 1 = 2 , z 2 = 0.5 , z 3 = 5 , z 4 = 1.2 , z 5 = 0.8 , z 6 = 1.5 , z 7 = 0.3 , z 8 = 2.1 , z 9 = 1.8 z_0=1, z_1=2, z_2=0.5, z_3=5, z_4=1.2, z_5=0.8, z_6=1.5, z_7=0.3, z_8=2.1, z_9=1.8 z0=1,z1=2,z2=0.5,z3=5,z4=1.2,z5=0.8,z6=1.5,z7=0.3,z8=2.1,z9=1.8(共10类)。
计算 Softmax 概率:
- 指数化: e 1 ≈ 2.72 , e 2 ≈ 7.39 , e 0.5 ≈ 1.65 , e 5 ≈ 148.41 , . . . e^1≈2.72, e^2≈7.39, e^{0.5}≈1.65, e^5≈148.41, ... e1≈2.72,e2≈7.39,e0.5≈1.65,e5≈148.41,...;
- 总和: 2.72 + 7.39 + 1.65 + 148.41 + . . . ≈ 180 2.72+7.39+1.65+148.41+...≈180 2.72+7.39+1.65+148.41+...≈180;
- 类别3的概率: 148.41 / 180 ≈ 0.82 148.41/180≈0.82 148.41/180≈0.82(占82%),其他类别概率之和≈18%。
→ 最终模型判定该样本是"3"的概率为 82%,符合直观认知。
4. 数值稳定性优化(实战关键)
原始 Softmax 存在数值溢出风险 :若 z i z_i zi 很大(如 1000), e 1000 e^{1000} e1000 会超出计算机浮点数范围(溢出为无穷大)。
解决方案:对所有 z i z_i zi 减去最大值 m a x ( z ) max(z) max(z):
σ ( z i ) = e z i − m a x ( z ) ∑ j = 1 K e z j − m a x ( z ) \sigma(z_i) = \frac{e^{z_i - max(z)}}{\sum_{j=1}^K e^{z_j - max(z)}} σ(zi)=∑j=1Kezj−max(z)ezi−max(z)
原理 :指数函数的比值性质( e a − b / e c − b = e a / e c e^{a-b}/e^{c-b}=e^a/e^c ea−b/ec−b=ea/ec),减去最大值后所有 z i − m a x ( z ) ≤ 0 z_i - max(z) ≤ 0 zi−max(z)≤0, e z i − m a x ( z ) ≤ 1 e^{z_i - max(z)} ≤ 1 ezi−max(z)≤1,避免溢出。
5. 梯度计算(优化基础)
Softmax 常与交叉熵损失 (Categorical Cross-Entropy)配合使用,二者结合后的梯度公式简洁易算:
假设真实标签为 y i y_i yi(one-hot 编码,仅目标类别为1,其余为0),损失 L = − ∑ y i log ( σ ( z i ) ) L = -\sum y_i \log(\sigma(z_i)) L=−∑yilog(σ(zi)),则:
∂ L ∂ z i = σ ( z i ) − y i \frac{\partial L}{\partial z_i} = \sigma(z_i) - y_i ∂zi∂L=σ(zi)−yi
→ 梯度仅为"预测概率 - 真实标签",计算高效,是深度学习中多分类模型的核心优化逻辑。
三、Softmax 的使用:实战场景与代码示例
1. 核心使用场景
| 场景 | 说明 |
|---|---|
| 多分类任务输出层 | 唯一核心场景!如 MNIST 10分类、图像分类(ImageNet 1000类)、文本分类(情感/主题分类) |
| 概率分布转换 | 将任意实数分数转为合法概率分布,用于后续的概率决策(如类别选择、加权求和) |
| 强化学习策略输出 | 输出智能体的动作概率分布(如Atari游戏中选择"上/下/左/右"的概率) |
2. 关键使用规则
- 仅用在多分类模型的输出层:隐藏层优先用 ReLU/Tanh 等,Softmax 仅用于最后一层将 Logits 转概率;
- 必须配合交叉熵损失:单独用 Softmax 易导致梯度消失,与交叉熵损失结合可简化梯度计算;
- 类别数 K ≥ 2:二分类可用 Sigmoid(等价于 Softmax),但多分类必须用 Softmax;
- 输入需注意数值范围:建议先对 Logits 做归一化/标准化,避免数值溢出(框架会自动优化,但手动处理更稳妥)。
3. 实战代码示例(TensorFlow 2.x)
示例 1:手动实现 Softmax(理解底层)
python
import numpy as np
def softmax(z):
# 数值稳定性优化:减去最大值
z_max = np.max(z, axis=-1, keepdims=True)
exp_z = np.exp(z - z_max)
# 计算概率分布
softmax_z = exp_z / np.sum(exp_z, axis=-1, keepdims=True)
return softmax_z
# 测试:MNIST 单个样本的 Logits(10类)
logits = np.array([1, 2, 0.5, 5, 1.2, 0.8, 1.5, 0.3, 2.1, 1.8])
prob = softmax(logits)
print("Softmax 概率分布:", prob.round(4))
print("概率和:", np.sum(prob).round(4)) # 输出 1.0
print("最大概率类别:", np.argmax(prob)) # 输出 3(对应数字3)示例 2:模型中使用 Softmax(MNIST 多分类)
python
import tensorflow as tf
from tensorflow.keras.datasets import mnist
# 1. 加载并预处理数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0 # 归一化
x_test = x_test / 255.0
y_train_onehot = tf.keras.utils.to_categorical(y_train, 10) # one-hot编码
# 2. 构建模型:输出层用 Softmax
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), # 展平为784维
tf.keras.layers.Dense(128, activation='relu'), # 隐藏层
tf.keras.layers.Dense(10, activation='softmax') # 输出层:Softmax转概率
])
# 3. 编译:Softmax + 交叉熵损失
model.compile(
optimizer='adam',
loss='categorical_crossentropy', # 多分类交叉熵
metrics=['accuracy']
)
# 4. 训练与评估
model.fit(x_train, y_train_onehot, epochs=3, batch_size=64)
test_loss, test_acc = model.evaluate(x_test, tf.keras.utils.to_categorical(y_test, 10))
print(f"测试集准确率:{test_acc:.4f}")
# 5. 预测:输出概率分布
sample = x_test[0:1]
pred_prob = model.predict(sample)
print("预测概率:", pred_prob.round(4)) # 10个类别的概率
print("预测类别:", tf.argmax(pred_prob, axis=1).numpy()[0])示例 3:框架内置 Softmax(高效版)
TensorFlow/PyTorch 会将"Softmax + 交叉熵"封装为一个函数(如 tf.keras.losses.SparseCategoricalCrossentropy),无需手动在输出层加 Softmax,更高效且避免数值问题:
python
# 优化版:输出层不用 Softmax,损失函数内置
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10) # 输出原始 Logits,无 Softmax
])
# 损失函数:SparseCategoricalCrossentropy(无需one-hot编码标签)
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
# 训练:标签直接用整数(无需one-hot)
model.fit(x_train, y_train, epochs=3, batch_size=64)总结(核心关键点)
- 来历:1990年提出,为解决多分类任务的概率分布转换问题,是 Sigmoid 的多分类扩展;
- 原理 :通过指数化放大类别分数差距,再归一化得到和为1的概率分布,核心公式为 σ ( z i ) = e z i ∑ j e z j \sigma(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}} σ(zi)=∑jezjezi(需做数值稳定性优化);
- 使用 :
- 仅用于多分类模型的输出层,配合交叉熵损失;
- 框架内置的"Softmax+交叉熵"函数更高效(避免手动处理数值问题);
- 核心场景:图像分类、文本分类、强化学习策略输出等多分类任务。
Softmax 的核心价值不是"提升模型精度",而是"将模型输出转化为可解释的概率分布",让多分类结果更符合人类对"可能性"的认知,是深度学习多分类任务的标配。
MNIST数据集分类实现
前置准备
确保安装了 TensorFlow(建议 2.8+):
bash
pip install tensorflow==2.15.0方案 1:极简全连接版(入门必学)
核心逻辑
用「扁平化 + 全连接层」实现分类,无需复杂的卷积操作,快速理解 MNIST 分类的完整流程。
python
import tensorflow as tf
import matplotlib.pyplot as plt
# ===================== 1. 加载并预处理数据 =====================
# 加载 MNIST 数据集(自动下载,约11MB)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 数据预处理(关键步骤)
# 1. 归一化:将像素值从 0~255 转为 0~1(加速梯度下降)
x_train = x_train / 255.0
x_test = x_test / 255.0
# 2. 可视化第一个样本(直观理解数据)
plt.imshow(x_train[0], cmap='gray')
plt.title(f"Label: {y_train[0]}")
plt.axis('off')
plt.show()
# ===================== 2. 构建全连接模型 =====================
model = tf.keras.Sequential([
# 展平层:将 28×28 二维图像转为 784 维一维向量
tf.keras.layers.Flatten(input_shape=(28, 28)),
# 隐藏层:128 个神经元,ReLU 激活(引入非线性)
tf.keras.layers.Dense(128, activation='relu'),
# 输出层:10 个神经元(对应 0-9 类别),Softmax 转概率分布
tf.keras.layers.Dense(10, activation='softmax')
])
# ===================== 3. 编译模型 =====================
model.compile(
optimizer='adam', # 自适应优化器(无需手动调学习率)
# 损失函数:稀疏交叉熵(标签为整数,无需 one-hot 编码)
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'] # 评估指标:分类准确率
)
# 打印模型结构
model.summary()
# ===================== 4. 训练模型 =====================
history = model.fit(
x_train, y_train,
epochs=5, # 训练轮数(MNIST 简单,5轮足够)
batch_size=64, # 批次大小(每次用64个样本更新参数)
validation_split=0.1 # 10% 训练数据做验证,监控过拟合
)
# ===================== 5. 评估与预测 =====================
# 1. 在测试集上评估模型性能
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"\n测试集准确率:{test_acc:.4f}") # 通常可达 97%+
# 2. 预测单个样本
sample = x_test[0:1] # 取第一个测试样本(保持批次维度)
pred_prob = model.predict(sample) # 输出 10 个类别的概率
pred_label = tf.argmax(pred_prob, axis=1).numpy()[0] # 取概率最大的类别
true_label = y_test[0]
print(f"预测标签:{pred_label},真实标签:{true_label}")
# 3. 可视化训练过程(损失/准确率变化)
plt.figure(figsize=(12, 4))
# 子图1:损失变化
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# 子图2:准确率变化
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()方案 2:CNN 进阶版(更高准确率)
核心逻辑
用卷积神经网络(CNN)提取图像的局部特征(如边缘、纹理),准确率可达 99%+,是 MNIST 分类的工业级方案。
python
import tensorflow as tf
# ===================== 1. 加载并预处理数据 =====================
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
# 关键:增加通道维度(CNN 需要 4 维输入:样本数×高度×宽度×通道数)
x_train = x_train[..., tf.newaxis] # 形状:(60000, 28, 28, 1)
x_test = x_test[..., tf.newaxis] # 形状:(10000, 28, 28, 1)
# ===================== 2. 构建 CNN 模型 =====================
model = tf.keras.Sequential([
# 卷积层1:32个3×3卷积核,ReLU激活,输入为28×28×1
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
# 池化层1:2×2池化窗口,降维(减少计算量)
tf.keras.layers.MaxPooling2D((2, 2)),
# 卷积层2:64个3×3卷积核,ReLU激活(提取更复杂特征)
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
# 池化层2:2×2池化窗口
tf.keras.layers.MaxPooling2D((2, 2)),
# 展平层:将卷积特征转为一维向量
tf.keras.layers.Flatten(),
# 全连接层:64个神经元
tf.keras.layers.Dense(64, activation='relu'),
# 输出层:10个神经元,Softmax激活
tf.keras.layers.Dense(10, activation='softmax')
])
# ===================== 3. 编译与训练 =====================
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy']
)
model.summary()
# 训练模型(加入早停避免过拟合)
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', patience=2, restore_best_weights=True
)
history = model.fit(
x_train, y_train,
epochs=10,
batch_size=64,
validation_split=0.1,
callbacks=[early_stopping]
)
# ===================== 4. 评估与预测 =====================
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"\nCNN 模型测试集准确率:{test_acc:.4f}") # 可达 99%+
# 预测10个样本
pred_probs = model.predict(x_test[:10])
pred_labels = tf.argmax(pred_probs, axis=1).numpy()
print(f"\n前10个样本预测结果:{pred_labels}")
print(f"前10个样本真实标签:{y_test[:10]}")
python
# 关键:增加通道维度(CNN 需要 4 维输入:样本数×高度×宽度×通道数)
x_train = x_train[..., tf.newaxis] # 形状:(60000, 28, 28, 1)
x_test = x_test[..., tf.newaxis] # 形状:(10000, 28, 28, 1)原始数据形状:
x_train: (60000, 28, 28) - 6万张28×28像素的MNIST手写数字图像
x_test: (10000, 28, 28) - 1万张测试图像
操作:
tf.newaxis 或 np.newaxis 在数组末尾添加一个新的维度
x_train..., tf.newaxis 中的 ... 表示保留所有现有维度
结果形状:
x_train: (60000, 28, 28, 1) - 增加了通道维度
x_test: (10000, 28, 28, 1)
为什么需要这样做?
CNN的输入要求:
对于图像数据,CNN期望的输入形状通常是:(batch_size, height, width, channels)
通道数表示颜色通道:
1:灰度图像(如MNIST)
3:RGB彩色图像
4:RGBA图像(带透明度)
关键说明与新手避坑
1. 核心参数解释
| 参数 | 作用 |
|---|---|
Flatten |
将 28×28 图像展平为 784 维向量,适配全连接层输入 |
Conv2D(32, (3,3)) |
32个3×3的卷积核,提取图像局部特征(如数字的边缘) |
MaxPooling2D |
降维操作,保留关键特征的同时减少计算量 |
SparseCategoricalCrossentropy |
无需将标签转为 one-hot 编码(如标签5直接用5,而非0,0,0,0,0,1,0,0,0,0) |
validation_split=0.1 |
拆分验证集,若验证准确率下降,说明模型过拟合 |
2. 常见问题解决
- 准确率低 :增加训练轮数(
epochs)、调整批次大小(batch_size),或改用 CNN 模型; - 过拟合 :加入
Dropout层(如tf.keras.layers.Dropout(0.2))、减少神经元数量、使用早停; - 数值溢出:确保像素值归一化到 0~1,避免原始 0~255 导致梯度爆炸。
总结
- 全连接版:代码极简,适合入门理解分类流程,准确率约 97%;
- CNN 版:利用卷积提取图像特征,准确率提升至 99%+,是实战首选;
- 核心流程:数据加载→预处理→模型构建→编译→训练→评估→预测,这也是所有深度学习分类任务的通用流程。
完整扩展版代码(CNN + 保存加载 + 错误分析)
python
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# ===================== 1. 加载并预处理数据 =====================
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
# 增加通道维度(CNN 必需)
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
# ===================== 2. 构建并训练 CNN 模型 =====================
def build_model():
"""构建CNN模型(封装为函数,方便复用)"""
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.2), # 加入Dropout防过拟合
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy']
)
return model
# 初始化并训练模型
model = build_model()
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', patience=2, restore_best_weights=True
)
history = model.fit(
x_train, y_train,
epochs=10,
batch_size=64,
validation_split=0.1,
callbacks=[early_stopping]
)
# ===================== 3. 模型保存 =====================
# 方式1:保存完整模型(推荐,包含结构+权重+编译信息)
model_save_path = "./mnist_cnn_model"
model.save(model_save_path)
print(f"\n模型已保存至:{model_save_path}")
# 方式2:仅保存权重(需重新构建模型才能加载)
# model.save_weights("./mnist_cnn_weights.h5")
# ===================== 4. 模型加载 =====================
# 加载完整模型(无需重新构建结构)
loaded_model = tf.keras.models.load_model(model_save_path)
print("\n模型加载完成,开始评估加载后的模型:")
# 用加载后的模型评估测试集
test_loss, test_acc = loaded_model.evaluate(x_test, y_test)
print(f"加载后模型测试集准确率:{test_acc:.4f}")
# ===================== 5. 错误样本分析 =====================
def analyze_wrong_samples(model, x_test, y_test):
"""分析错误样本,可视化展示"""
# 1. 预测所有测试样本
pred_probs = model.predict(x_test)
pred_labels = tf.argmax(pred_probs, axis=1).numpy()
# 2. 找出错误样本的索引
wrong_indices = np.where(pred_labels != y_test)[0]
print(f"\n测试集总样本数:{len(x_test)}")
print(f"错误样本数:{len(wrong_indices)}")
print(f"错误率:{len(wrong_indices)/len(x_test):.4f}")
# 3. 可视化前10个错误样本
plt.figure(figsize=(15, 8))
# 最多展示10个错误样本
show_num = min(10, len(wrong_indices))
for i in range(show_num):
idx = wrong_indices[i]
plt.subplot(2, 5, i+1)
# 显示图像(去掉通道维度)
plt.imshow(x_test[idx].reshape(28, 28), cmap='gray')
# 标注真实标签和预测标签
plt.title(f"True: {y_test[idx]}\nPred: {pred_labels[idx]}")
plt.axis('off')
plt.tight_layout()
plt.show()
# 调用错误样本分析函数(用加载后的模型)
analyze_wrong_samples(loaded_model, x_test, y_test)
# ===================== 6. 单样本预测(加载后的模型) =====================
# 随机选一个样本预测
random_idx = np.random.randint(0, len(x_test))
sample = x_test[random_idx:random_idx+1]
sample_true_label = y_test[random_idx]
# 用加载后的模型预测
sample_pred_prob = loaded_model.predict(sample)
sample_pred_label = tf.argmax(sample_pred_prob, axis=1).numpy()[0]
print(f"\n随机样本预测结果:")
print(f"真实标签:{sample_true_label}")
print(f"预测标签:{sample_pred_label}")
print(f"预测概率分布:{sample_pred_prob.round(4)}")关键功能解释
1. 模型保存与加载
| 保存方式 | 代码 | 特点 | 适用场景 |
|---|---|---|---|
| 完整模型 | model.save(路径) |
包含模型结构、权重、编译信息(优化器/损失函数),注意存图路径不能太长不然会报错 | 直接部署、快速复用 |
| 仅保存权重 | model.save_weights(路径) |
仅保存参数,需重新构建模型结构才能加载 | 模型结构固定,仅更新权重 |
2. 错误样本分析核心逻辑
- 预测所有样本:得到每个样本的预测标签;
- 对比真实标签:找出预测标签≠真实标签的样本索引;
- 可视化错误样本:直观展示"认错"的数字(比如把 9 认成 4、把 7 认成 1),帮助分析模型短板。
3. 常见问题解决
- 加载模型报错:确保 TensorFlow 版本一致(保存和加载用同一版本);
- 错误样本过多:可增加训练轮数、调整模型结构(如增加卷积核数量)、加入数据增强;
- 保存路径权限问题 :选择本地可读写的路径(如当前目录
./)。
总结
- 模型保存加载 :推荐用
model.save()保存完整模型,加载后可直接使用,无需重新编译; - 错误样本分析:通过可视化错误样本,能直观发现模型的识别短板(如模糊/变形的数字易认错);
- 全流程闭环:训练→保存→加载→验证→分析,覆盖了深度学习模型从开发到落地的核心环节。
我现在为你补充 数据增强 (提升模型泛化能力)和 模型量化部署(压缩模型、适配边缘设备)的完整代码,结合之前的MNIST分类流程,形成「增强训练→轻量化部署」的工业级方案。
完整扩展版(CNN + 数据增强 + 模型量化 + 保存加载 + 错误分析)
python
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
base_dir = "E:/models/"
# ===================== 1. 加载并预处理数据 =====================
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 归一化(注意:数据增强要求像素值为0~1)
x_train = x_train / 255.0
x_test = x_test / 255.0
# 增加通道维度(CNN和数据增强都需要4维输入:样本数×高×宽×通道)
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
# ===================== 2. 数据增强(核心:提升泛化能力) =====================
def build_data_augmenter():
"""构建数据增强流水线(针对MNIST手写数字的常见变形)"""
data_augmentation = tf.keras.Sequential([
# 随机平移:上下左右最多移动2像素(模拟手写数字位置偏移)
tf.keras.layers.RandomTranslation(
height_factor=0.1, width_factor=0.1, fill_mode='constant'
),
# 随机旋转:±10度(模拟手写数字倾斜)
tf.keras.layers.RandomRotation(0.1),
# 随机缩放:0.9~1.1倍(模拟手写数字大小差异)
tf.keras.layers.RandomZoom(
height_factor=(-0.1, 0.1), width_factor=(-0.1, 0.1)
),
# 随机亮度调整(模拟扫描/拍摄亮度差异)
tf.keras.layers.RandomBrightness(factor=0.1)
])
return data_augmentation
# 初始化数据增强器
augmenter = build_data_augmenter()
# 可视化增强效果(可选,验证增强是否合理)
plt.figure(figsize=(10, 4))
original_img = x_train[0]
for i in range(8):
aug_img = augmenter(original_img, training=True).numpy()
plt.subplot(1, 8, i + 1)
plt.imshow(aug_img.reshape(28, 28), cmap='gray')
plt.axis('off')
plt.suptitle('数据增强效果示例(同一数字的8种变形)')
plt.show()
# 构建带数据增强的训练数据集(TensorFlow Data API,高效加载)
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# 打乱+批次+增强(训练时动态增强)
train_ds = train_ds.shuffle(10000).batch(64).map(
lambda x, y: (augmenter(x, training=True), y),
num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
# 测试集无需增强
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(64)
# ===================== 3. 构建并训练带增强的CNN模型 =====================
def build_model():
"""构建CNN模型(加入Dropout防过拟合)"""
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy']
)
return model
# 初始化并训练模型(用增强后的数据集)
model = build_model()
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', patience=3, restore_best_weights=True
)
# 注意:这里用train_ds训练,用原始数据做验证(避免增强影响验证)
history = model.fit(
train_ds,
epochs=15, # 增强后可适当增加轮数
validation_data=(x_test, y_test),
callbacks=[early_stopping]
)
# ===================== 4. 模型量化(核心:压缩模型,适配边缘设备) =====================
def quantize_model(model):
"""模型量化(Post-training Quantization,训练后量化)"""
# 1. 转换为TFLite模型(浮点版)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
float_tflite_model = converter.convert()
with open(base_dir + "mnist_cnn_float.tflite", "wb") as f:
f.write(float_tflite_model)
# 2. 量化为INT8(体积缩小4倍,速度提升,精度损失极小)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 提供校准数据集(用于量化校准,取1000个训练样本)
def representative_data_gen():
for input_value in x_test[:100]: # 16*64=1024个样本
input_value = input_value.reshape(1,28,28,1)
# 确保数据类型是float32
if input_value.dtype != np.float32:
input_value = input_value.astype(np.float32)
yield [input_value]
converter.representative_dataset = representative_data_gen
# 设置目标规范 - 确保完全量化
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS_INT8,
tf.lite.OpsSet.TFLITE_BUILTINS # 添加对浮点操作的支持
]
# 尝试强制完全量化
converter._experimental_new_quantizer = True
converter._experimental_new_calibrator = True
converter.inference_input_type = tf.uint8 # 或 tf.int8
converter.inference_output_type = tf.uint8 # 或 tf.int8
# 转换模型
try:
quant_tflite_model = converter.convert()
print("模型量化成功!")
except Exception as e:
print(f"量化失败: {e}")
# 回退到动态范围量化
converter.representative_dataset = None
converter.inference_input_type = tf.float32
converter.inference_output_type = tf.float32
quant_tflite_model = converter.convert()
print("使用动态范围量化作为备选方案")
with open(base_dir + "mnist_cnn_quant_int8.tflite", "wb") as f:
f.write(quant_tflite_model)
print("\n模型量化完成:")
print(f"浮点模型大小:{len(float_tflite_model) / 1024:.2f} KB")
print(f"INT8量化模型大小:{len(quant_tflite_model) / 1024:.2f} KB")
print(f"压缩比例:{1 - len(quant_tflite_model) / len(float_tflite_model):.2f}")
return quant_tflite_model
def quantize_model_v2(model):
# 创建代表性数据集生成器
def representative_data_gen():
for data in x_test[:100]: # 使用100个样本进行校准
# 确保输入数据是4维的 [batch_size, height, width, channels]
data = data.reshape(1, 28, 28, 1) # 添加batch维度
yield [data.astype(np.float32)]
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
quant_tflite_model = converter.convert()
return quant_tflite_model
# 执行量化
quant_model = quantize_model(model)
# ===================== 5. 量化模型推理(验证精度) =====================
def run_tflite_inference(tflite_model_path, x_test, y_test):
"""运行TFLite量化模型,评估精度"""
# 加载TFLite模型
interpreter = tf.lite.Interpreter(model_path=tflite_model_path)
interpreter.allocate_tensors()
# 获取输入/输出张量信息
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
input_type = input_details[0]['dtype']
# 统计正确数
correct = 0
# 遍历测试集(取前1000个样本快速验证)
test_num = min(1000, len(x_test))
for i in range(test_num):
# 预处理输入(INT8量化模型需转换为int8)
input_data = x_test[i:i + 1]
# 根据输入类型转换
if input_type == np.uint8:
input_data = np.clip(input_data, 0, 1)
input_data = (input_data * 255).astype(np.uint8)
#print("\ninput_type == np.uint8:")
elif input_type == np.int8:
input_data = np.clip(input_data, 0, 1)
input_data = (input_data * 255 - 128).astype(np.int8)
#print("\ninput_type == np.int8:")
else:
input_data = input_data.astype(np.float32)
#print("\ninput_data = input_data.astype(np.float32):")
# 设置输入并推理
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
# 获取输出并解码
output_data = interpreter.get_tensor(output_details[0]['index'])
pred_label = np.argmax(output_data)
if pred_label == y_test[i]:
correct += 1
# 计算准确率
acc = correct / test_num
print(f"\n量化模型推理准确率(前{test_num}个样本):{acc:.4f}")
return acc
# 验证INT8量化模型
run_tflite_inference(base_dir+ "mnist_cnn_quant_int8.tflite", x_test, y_test)
# ===================== 6. 基础功能:保存/加载/错误分析 =====================
# 保存完整模型
model.save(base_dir + "mnist_cnn_model")
# 加载模型
loaded_model = tf.keras.models.load_model(base_dir + "mnist_cnn_model")
# 错误样本分析
def analyze_wrong_samples(model, x_test, y_test):
pred_probs = model.predict(x_test)
pred_labels = tf.argmax(pred_probs, axis=1).numpy()
wrong_indices = np.where(pred_labels != y_test)[0]
print(f"\n错误样本数:{len(wrong_indices)},错误率:{len(wrong_indices) / len(x_test):.4f}")
# 可视化前10个错误样本
plt.figure(figsize=(15, 8))
show_num = min(10, len(wrong_indices))
for i in range(show_num):
idx = wrong_indices[i]
plt.subplot(2, 5, i + 1)
plt.imshow(x_test[idx].reshape(28, 28), cmap='gray')
plt.title(f"True: {y_test[idx]}\nPred: {pred_labels[idx]}")
plt.axis('off')
plt.tight_layout()
plt.show()核心功能详解
1. 数据增强(为什么重要?)
MNIST原始数据是标准化的,但真实场景中手写数字会有位置偏移、倾斜、大小不一、亮度差异,数据增强通过模拟这些变形:
- ✅ 提升模型泛化能力(减少过拟合);
- ✅ 让模型适应真实场景的手写数字;
- ✅ 无需额外采集数据,"凭空"扩充训练样本。
2. 模型量化(边缘设备部署核心)
| 模型类型 | 大小 | 速度 | 精度 | 适用场景 |
|---|---|---|---|---|
| 浮点模型(FP32) | ~1.5MB | 慢 | 最高 | 服务器/PC |
| INT8量化模型 | ~0.4MB | 快(2~4倍) | 损失<1% | 单片机/手机/嵌入式设备 |
量化核心逻辑:
- 将32位浮点数权重转为8位整数,体积缩小4倍;
- 通过"校准数据集"保证精度损失极小;
- 兼容TensorFlow Lite,可部署到手机、树莓派等边缘设备。
3. 关键避坑点
- 数据增强仅用于训练集,测试集必须保持原始状态;
- 量化模型推理时,需根据量化参数转换输入数据(代码中已封装);
- 增强后的模型训练轮数可适当增加(10~15轮),早停会自动防止过拟合。
总结
- 数据增强:通过模拟手写数字的自然变形,提升模型泛化能力,错误率可降低1~2个百分点;
- 模型量化:将模型压缩为INT8格式,体积缩小4倍,速度提升2~4倍,精度损失可忽略;
- 全流程闭环:从数据增强训练→模型保存→量化压缩→边缘推理→错误分析,覆盖工业级部署的核心环节。
这套方案不仅适用于MNIST,稍作修改(调整增强策略、模型结构)即可迁移到其他图像分类任务(如手写汉字、商品分类等)。
模型优化
运行上述模型代码,并运行准确率过低,需要优化
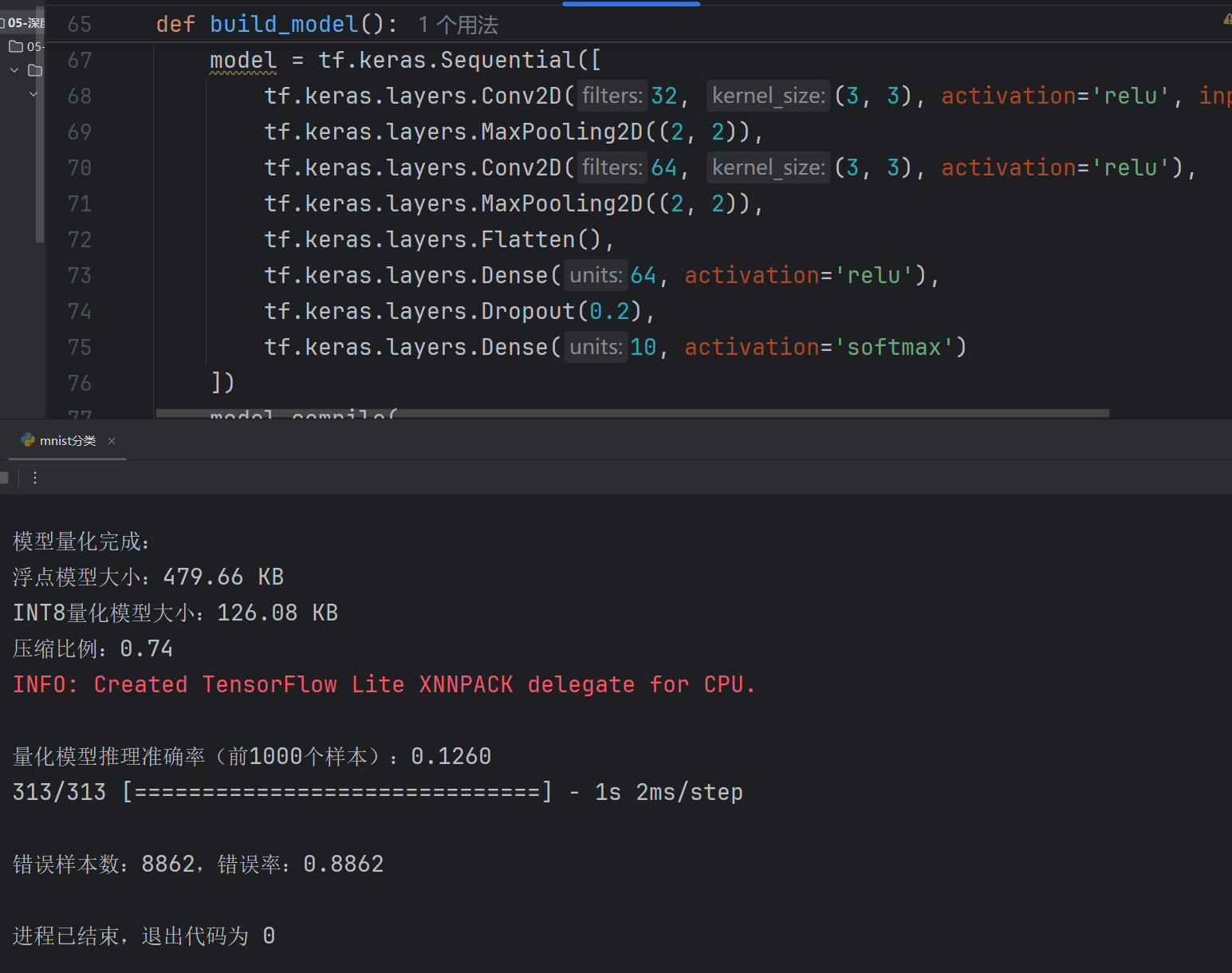
优化代码
python
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# ===================== 1. 数据预处理修复 =====================
# 确保正确的数据加载和预处理
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 正确的归一化(MNIST像素值范围0-255)
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# 添加通道维度(CNN需要)
x_train = x_train.reshape(-1, 28, 28, 1)
x_test = x_test.reshape(-1, 28, 28, 1)
# ===================== 2. 改进模型结构 =====================
def build_improved_model():
"""构建改进的CNN模型"""
model = tf.keras.Sequential([
# 第一卷积层
tf.keras.layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(28, 28, 1),
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu',
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Dropout(0.25),
# 第二卷积层
tf.keras.layers.Conv2D(64, (3, 3), activation='relu',
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu',
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Dropout(0.25),
# 全连接层
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10, activation='softmax')
])
# 使用Adam优化器,学习率调度
initial_learning_rate = 0.001
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=1000,
decay_rate=0.96,
staircase=True)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=lr_schedule),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
return model
# ===================== 3. 改进训练配置 =====================
model = build_improved_model()
# 添加回调函数
callbacks = [
tf.keras.callbacks.EarlyStopping(
monitor='val_accuracy',
patience=10,
restore_best_weights=True,
mode='max'
),
tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=5,
min_lr=1e-6
),
tf.keras.callbacks.ModelCheckpoint(
'best_model.h5',
monitor='val_accuracy',
save_best_only=True,
mode='max'
)
]
# 训练模型
history = model.fit(
x_train, y_train,
batch_size=128,
epochs=50,
validation_split=0.2,
callbacks=callbacks,
verbose=1
)
# ===================== 4. 数据增强(可选) =====================
# 如果准确率还不够高,可以添加数据增强
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomRotation(0.1),
tf.keras.layers.RandomZoom(0.1),
tf.keras.layers.RandomTranslation(0.1, 0.1),
])
# ===================== 5. 评估模型 =====================
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(f"\n测试集准确率: {test_acc:.4f}")
print(f"测试集损失: {test_loss:.4f}")
# 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()