本文是小编巩固自身而作,如有错误,欢迎指出!
目录
[一、 程序的翻译四步骤](#一、 程序的翻译四步骤)
[(1)C 程序编译(gcc):](#(1)C 程序编译(gcc):)
[(2)C++ 程序编译(g++):](#(2)C++ 程序编译(g++):)
[编辑 三、动态链接和静态链接](#编辑 三、动态链接和静态链接)
[version 1](#version 1)
- GCC (GNU Compiler Collection):GNU 编译器套件,是一套支持多种编程语言的编译器,默认编译 C 语言 程序。
- G++ :是 GCC 的一个前端,专门用于编译 C++ 程序 ,本质上也是调用 GCC 核心,但会自动链接 C++ 标准库(如
libstdc++),而 GCC 编译 C++ 时需要手动指定链接
一、 程序的翻译四步骤
-
预处理(进⾏宏替换/去注释/条件编译/头⽂件展开等)
-
编译(⽣成汇编)
-
汇编(⽣成机器可识别代码)
-
连接(⽣成可执⾏⽂件或库⽂件)
二、程序的具体编译过程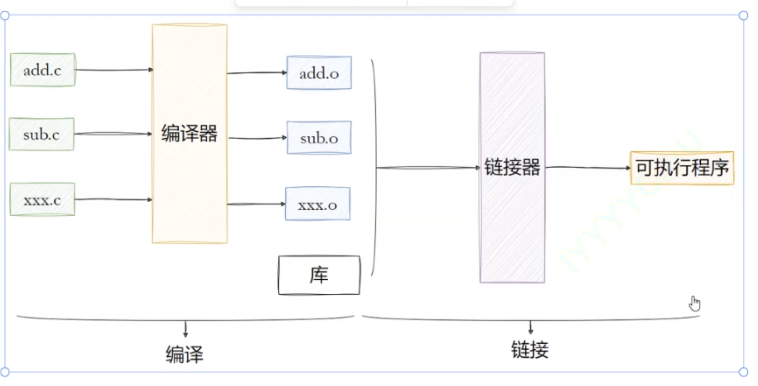
(1)C 程序编译(gcc):
cpp
// hello.c
#include <stdio.h>
int main() {
printf("Hello, GCC!\n");
return 0;
}
bash
# 编译:gcc 源文件 -o 可执行文件名
gcc hello.c -o hello
# 运行
./hello输出:Hello, GCC!
(2)C++ 程序编译(g++):
cpp
// hello.cpp
#include <iostream>
using namespace std;
int main() {
cout << "Hello, G++!" << endl;
return 0;
}(3)分步编译(更灵活,适合多文件项目)
bash
# 1. 预处理(生成 .i 文件,展开头文件、宏)
g++ -E hello.cpp -o hello.i
# 2. 编译(生成 .s 汇编文件)
g++ -S hello.i -o hello.s
# 3. 汇编(生成 .o 目标文件)
g++ -c hello.s -o hello.o
# 4. 链接(生成可执行文件)
g++ hello.o -o hello_cpp核心常用参数

三、动态链接和静态链接
在我们的实际开发中,不可能将所有代码放在⼀个源⽂件中,所以会出现多个源⽂件,⽽且多个源⽂件之间不是独⽴的,⽽会存在多种依赖关系,如⼀个源⽂件可能要调⽤另⼀个源⽂件中定义的函数,但是每个源⽂件都是独⽴编译的,即每个*.c⽂件会形成⼀个*.o⽂件。
为了满⾜前⾯说的依赖关系,则需要将这些源⽂件产⽣的⽬标⽂件进⾏链接,从⽽形成⼀个可以执⾏的程序。这个链接的过程就是静态链接。
静态链接的缺点很明显:
浪费空间:因为每个可执⾏程序中对所有需要的⽬标⽂件都要有⼀份副本,所以如果多个程序对同⼀个⽬标⽂件都有依赖,如多个程序中都调⽤了printf()函数,则这多个程序中都含有printf.o,所以同⼀个⽬标⽂件都在内存存在多个副本;
更新⽐较困难:因为每当库函数的代码修改了,这个时候就需要重新进⾏编译链接形成可执⾏程序。但是静态链接的优点就是,在可执⾏程序中已经具备了所有执⾏程序所需要的任何东西,在执⾏的时候运⾏速度快。
动态链接的出现解决了静态链接中提到问题。动态链接的基本思想是把程序按照模块拆分成各个相对独⽴部分,在程序运⾏时才将它们链接在⼀起形成⼀个完整的程序,序模块都链接成⼀个单独的可执⾏⽂件。
我们的C程序中,并没有定义"printf"的函数实现,且在预编译中包含的"stdio.h"中也只有该函数的声明,⽽没有定义函数的实现,那么,是在哪⾥实"printf"函数的呢?
最后的答案是:系统把这些函数实现都被做到名为 libc.so.6 的库⽂件中去了,在没有特别指定,gcc 会到系统默认的搜索路径"/usr/lib"下进⾏查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数"printf"了,⽽这也就是链接的作⽤。
四、makefile的使用
什么是构建
代码构建(Build)是指将人类可读的源代码(如 .c, .cpp, .java, .py 等)及其相关资源文件(如头文件 .h,配置文件,图像,库文件等),通过一系列自动化工具和步骤,转换、组合和打包成计算机可以直接执行或部署的目标形式的过程
构建的步骤
预处理、编译、汇编、链接、代码生成、资源处理、代码优化、打包、测试、文档生成
make是⼀条命令,makefile是⼀个⽂件,两个搭配使⽤,完成项⽬⾃动化构建。
(1)makefile的使用方法
简而言之make更像一个钥匙,而makefile则是储存东西的箱子,当我们使用make时,就会把箱子里的东西拿出来,具体演示可以看看下例:
bash
#include <stdio.h>
int main()
{
printf("hello Makefile!\n");
return 0;
}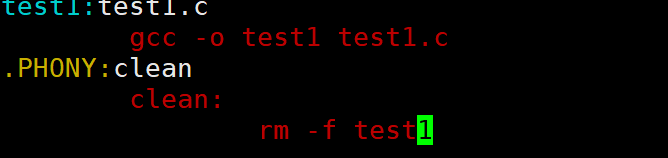
test1.exe由test.c产生,这就是他们其中依赖关系,使用:关联

(2)第一个系统项目------进度条
下面我们进行第一个运用makefile的项目的编写。
所谓的进度条,其实也就是将一些特殊符号打印在屏幕中,但是我们总会在其中遇到一些问题,我们接下来就来看看这些问题具体怎么解决
行缓冲区
我们分别将下列两行代码运行以下看看有什么区别
bash
#include <stdio.h>
int main()
{
printf("hello world!\n");
sleep(3);
return 0;
}
bash
#include <stdio.h>
int main()
{
printf("hello world!");
sleep(3);
return 0;
}在运行后我们会发现一个问题,就是为什么第一个程序是先打印出字符串然后三秒后结束程序,而第二个程序是三秒后打印出字符串然后结束程序。
原因:标准输出stdout默认采用行缓冲模式。行缓冲规则为遇到换行符\n时自动刷新缓冲区。
简单了解一下我们创建项目需要解决的较重要的问题,现在我们看看项目的具体编写过程
version 1
cpp
// version 1:控制台进度条实现
void Process()
{
// 定义旋转动画的字符序列(| / - \),用于加载动态效果
const char *lable="|/-\\";
// 获取动画字符序列的长度(这里是4)
int len=strlen(lable);
// 定义进度条缓冲区,长度为SIZE(需提前定义,比如#define SIZE 101)
char processbuff[SIZE];
// 将缓冲区初始化为全空字符'\0',确保初始状态为空
memset(processbuff, '\0', sizeof(processbuff));
// 进度计数器,从0到100表示0%到100%
int cnt = 0;
// 循环:进度从0%到100%
while(cnt <= 100)
{
// 打印进度条:
// %-100s:左对齐占100字符宽度的进度条
// %d%%:显示当前进度百分比
// %c:显示当前动画字符(循环切换| / - \)
// \r:回车符,让光标回到行首,实现覆盖更新
printf("[%-100s][%d%%][%c]\r", processbuff, cnt, lable[cnt%len]);
// 强制刷新输出缓冲区,确保进度条实时显示
fflush(stdout);
// 进度缓冲区的第cnt位置填充STYLE(比如'#'或'='),然后cnt自增
processbuff[cnt++] = STYLE;
// 暂停50毫秒(50000微秒),控制进度条动画速度
usleep(50000);
}
// 进度完成后换行,避免后续输出和进度条重叠
printf("\n");
}version2
cpp
void FlushProcess(double total, double current)
{
char buffer[NUM];
memset(buffer, 0, sizeof(buffer));
const char *lable="|/-\\";
int len = strlen(lable);
static int cnt = 0;
// 新增:标记进度是否已完成(静态变量,多次调用保持状态)
static int is_finished = 0;
// ========== 核心修复1:边界处理 ==========
// 防止current超过total导致进度条越界,同时避免浮点精度问题
if (current >= total) {
current = total; // 强制将进度锁定为100%
// 仅在第一次完成时执行结束逻辑,避免重复换行
if (!is_finished) {
// 填充100%的进度条
int i = 0;
for (; i < 100; i++) {
buffer[i] = STYLE;
}
// 打印最终100%进度条,用\n替代\r,结束刷新并换行
printf("[%-100s][100.0%%][%c]\n", buffer, lable[cnt % len]);
fflush(stdout);
is_finished = 1; // 标记为已完成,后续调用不再刷新
}
return; // 进度完成后直接返回,不再执行后续刷新逻辑
}
// ========== 核心修复2:重置完成标记(如果进度回退) ==========
if (is_finished) {
is_finished = 0;
}
// ========== 原有逻辑保留(仅优化) ==========
// 计算进度百分比(0~100),避免负数(比如current为0时)
int num = (int)(current * 100 / total);
// 限制num不超过100(双重保险)
num = num > 100 ? 100 : num;
int i = 0;
for(; i < num; i++)
{
buffer[i] = STYLE;
}
double rate = current / total;
cnt %= len;
// 正常进度仍用\r覆盖刷新
printf("[%-100s][%.1f%%][%c]\r", buffer, rate * 100, lable[cnt]);
cnt++;
fflush(stdout);
}version3
cpp
//version3
//相较于version2,这也是一种特殊的代码
//实际业务的时候,这种方法可以复用,代码维护性较好
//函数指针
typedef void (*callback_t)(double, double);
//网络浮动
// 基本网速 浮动网速
double speedfloat(double start, double range)//示例(1.0,3.0)->[1.0,4.0]
{
int int_range = (int)range;
return start + rand() % int_range + (range + int_range);
}
//cb:回调函数
void download(int total, callback_t cd)
{
srand(time(NULL));
double cur = 0.0;
while (1)//(cur<=total)
{
if (cur > total)
{
cur = total;//模拟下载完成
cd(total, cur);//更新进度:按照下载进度更新进度
break;
}
cd(total, cur);//更新进度:按照下载进度更新进度
//cur+=speed;//模拟下载行为
cur += speedfloat(speed, 30.3);
Sleep(300);//模拟网络延迟
//如果在Linux系统下,可以使用usleep代替Sleep,单位为微秒
}
}运行结果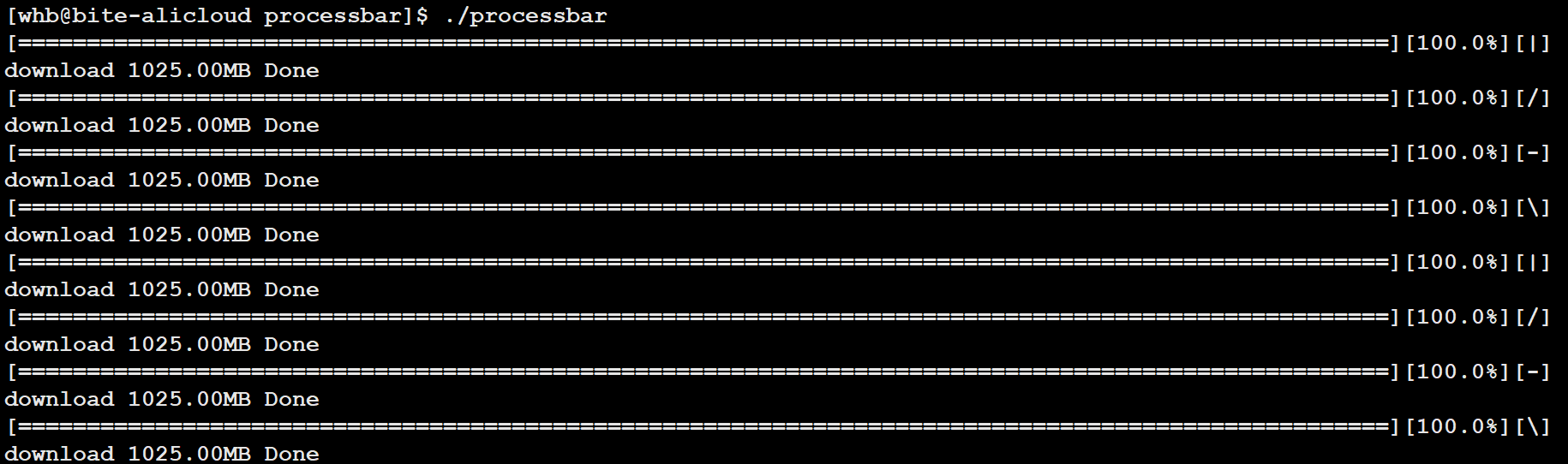 本次分享就到这里结束了,后续会继续更新,感谢阅读!
本次分享就到这里结束了,后续会继续更新,感谢阅读!