在 48GB L20 单卡部署 Qwen3.5-27B 时,我发现 GGUF 仓库里不止一个文件------这背后是一个非常实用的架构设计。
起因:一个模型,两个文件?
最近在用 llama.cpp 部署 Qwen3.5-27B 做本地推理。从 unsloth/Qwen3.5-27B-GGUF 下载模型时,我注意到目录里有这么几个文件:
unsloth/Qwen3.5-27B-GGUF/
├── Qwen3.5-27B-UD-Q8_K_XL.gguf (34GB) ← 语言模型
├── mmproj-BF16.gguf (889MB) ← 这是什么?
├── mmproj-F16.gguf (928MB)
└── mmproj-F32.gguf (1.84GB)34GB 的主模型好理解,但 mmproj 是什么?为什么一个模型要拆成两个 GGUF 文件?
带着这个问题研究了一下,发现这是 llama.cpp / GGUF 生态里一个非常巧妙的设计。
传统方案:模型是一个整体
在 safetensors、GPTQ 等主流格式中,多模态模型是打包在一起的。以 Qwen3.5-27B 为例,它实际上由两部分组成:
| 组件 | 作用 | 参数量 |
|---|---|---|
| 语言模型 (LLM) | 文本理解和生成 | ~27B |
| 视觉编码器 (Vision Encoder) | 将图像转换为模型能理解的 token | 数亿参数 |
传统格式下,即使你只做纯文本对话,视觉编码器也会一起被加载到显存中。对于显存紧张的场景(比如单卡 24GB/48GB),这些多出来的几百 MB 到几 GB 显存可能就是"能跑"和"OOM"的区别。
GGUF 的拆分设计:按需加载
llama.cpp 的 GGUF 格式采用了一个不同的策略------将语言模型和视觉编码器拆分为独立文件。
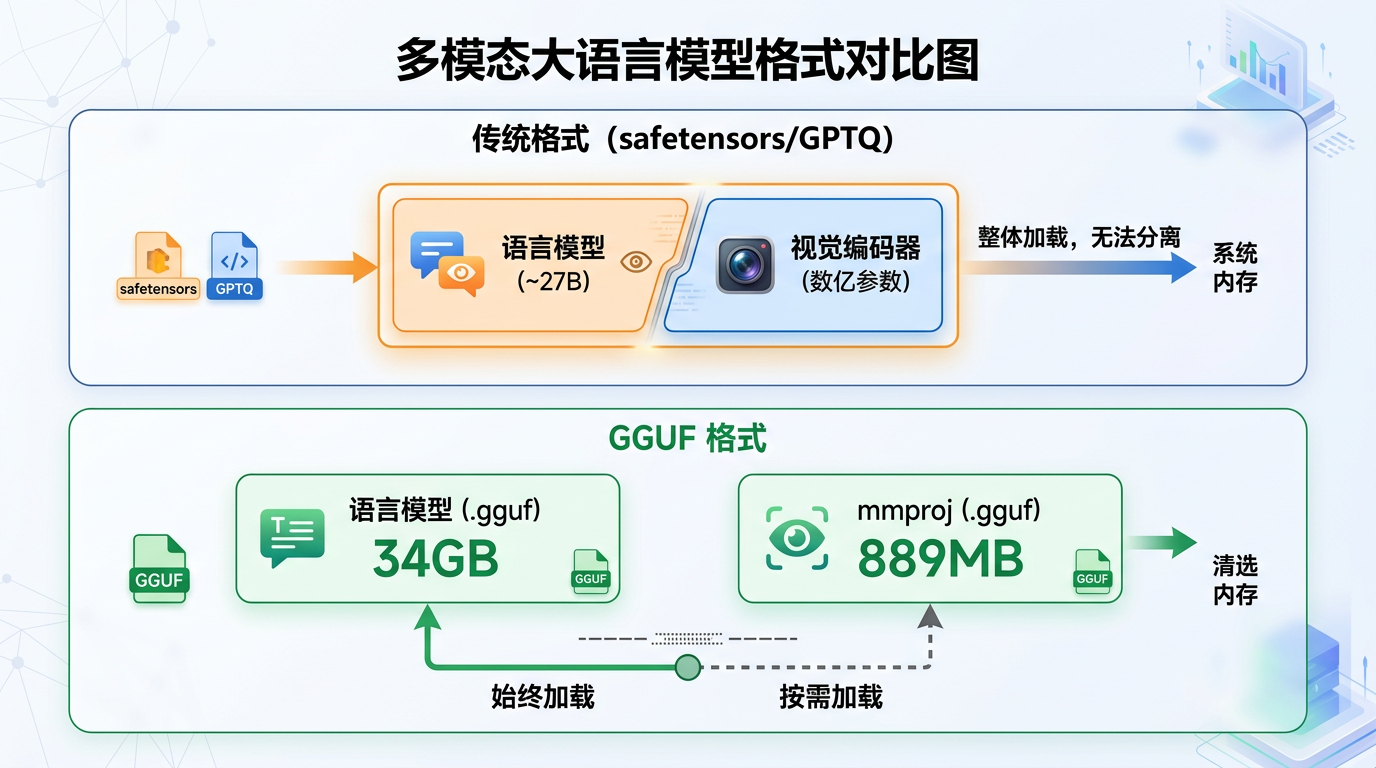
其中 mmproj 的全称是 Multimodal Projector (多模态投射器),它的核心作用是:将视觉编码器输出的图像特征,映射到语言模型的 embedding 空间。简单说就是一座"翻译桥梁",让语言模型能"看懂"图片。
拆分之后,推理时有两种加载模式:
纯文本推理 ------ 只加载语言模型:
bash
llama-server \
-m Qwen3.5-27B-UD-Q8_K_XL.gguf \
-ngl 999 --port 8080多模态推理 ------ 语言模型 + 视觉编码器一起加载:
bash
llama-server \
-m Qwen3.5-27B-UD-Q8_K_XL.gguf \
--mmproj mmproj-BF16.gguf \
-ngl 999 --port 8080区别仅仅是一个 --mmproj 参数。
实际收益:显存对比
我的部署环境是单卡 NVIDIA L20(48GB),以 Qwen3.5-27B UD-Q8_K_XL 量化为例:
| 加载模式 | 模型占用 | 剩余显存(给 KV Cache) |
|---|---|---|
| 纯文本(不加载 mmproj) | ~34 GB | ~14 GB |
| 多模态(加载 mmproj BF16) | ~34.9 GB | ~13.1 GB |
| 差值 | +889 MB |
889MB 看起来不多,但在显存吃紧的场景下,这些空间直接影响 KV Cache 容量,也就是能支持的上下文长度。更重要的是------绝大多数使用场景只需要文本对话,为什么要为一个用不到的视觉编码器买单呢?
如果使用更大的视觉编码器精度(F32),差值会达到 1.84GB,影响更加明显。
动手验证
假设你已经用 llama.cpp 编译好了 llama-server,可以快速验证两种模式。
纯文本模式
bash
# 启动(不加 --mmproj)
llama-server -m Qwen3.5-27B-UD-Q8_K_XL.gguf -ngl 999 --port 8080
# 测试
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.5",
"messages": [{"role": "user", "content": "用一句话解释什么是量子计算"}]
}'多模态模式
bash
# 启动(加上 --mmproj)
llama-server -m Qwen3.5-27B-UD-Q8_K_XL.gguf \
--mmproj mmproj-BF16.gguf -ngl 999 --port 8080
# 测试图片理解
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.5",
"messages": [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "https://example.com/photo.jpg"}},
{"type": "text", "text": "描述一下这张图片"}
]
}]
}'llama-server 提供的是 OpenAI 兼容 API,会根据是否加载了 mmproj 自动适配------加载了就支持图片输入,没加载就是纯文本模型。对接代码无需修改。
延伸:这个设计还带来了什么
1. 量化策略可以独立优化
语言模型可以根据显存预算选择不同的量化等级(Q4、Q6、Q8 等),而视觉编码器独立保持 BF16/F16 高精度。这很合理------视觉编码器的参数量相对小,没必要为了省几百 MB 去牺牲图像理解的质量。
语言模型: Q8 量化 (34GB) ← 压缩比高,节省空间
视觉编码: BF16 原始精度 (889MB) ← 参数少,保持质量2. 类似 LoRA 的"热插拔"思路
这种拆分和 LoRA adapter 的设计哲学异曲同工------核心模型保持不变,功能模块按需挂载。未来如果有更好的视觉编码器,只需替换 mmproj 文件,语言模型不用动。
3. 不止 Qwen3.5
目前 GGUF 生态中,主流多模态模型都采用了这种拆分设计:
- Qwen3.5 系列(27B、35B-A3B 等)
- LLaVA 系列(最早采用这种拆分的模型之一)
- Pixtral(Mistral 的多模态版本)
- InternVL 等
只要在 HuggingFace 的 GGUF 仓库里看到 mmproj*.gguf,就说明它支持这种按需加载。
总结
一个看似简单的文件拆分,背后体现的是"只为你用到的功能付费"的设计哲学。在显存寸土寸金的 GPU 推理场景下,这种按需加载的能力让开发者可以在同样的硬件上跑更大的模型、支持更长的上下文。
下次你在 GGUF 仓库里看到 mmproj-BF16.gguf 的时候,就知道它是什么了------一座连接视觉和语言的桥梁,用到时才过桥。